Hadoop的起源与背景知识
什么是大数据?
大数据(Big Data),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据的5个特征(IBM提出)
- l Volume (大量)
- l Velocity(高速)
- l Variety (多样)
- l Value (价值)
- Veracity(真实性)
大数据的典型案例
电商网站的商品推荐
例如商品推荐:大量订单如何存储?大量订单如何计算?
基于大数据的天气预报
大量的天气数据如何存储?大量的天气数据如何计算?
解决的核心问题
数据存储
采用的方案:分布式文件系统
数据计算
采用的方案:分布式计算,hadoop不适用实时计算<br /> (1)离线计算:MapReduce、Spark Core、Flink DataSet<br /> (2)实时计算(流式计算):Storm、Spark Streaming、Flink DataStream
Hadoop的思想来源
思想来源于谷歌(Google),Google搜索引擎,Gmail,安卓,AppspotGoogle Maps,Google earth,Google学术, Google翻译,Google+等等。
Google的三篇论文(Hadoop的思想来源)
GFS(Google File System:Google的文件系统) -> 衍生出HDFS
BigTable(大表):BigTable是Google设计的分布式数据存储系统,用来处理海量的数据的一种非关系型的数据库。 -> 衍生出HBase
Page Rank(排名先后)、倒排索引 -> 衍生出MapReduce
什么是数据仓库
数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。它的本质,就是一个数据库,可以使mysql、oracle等等。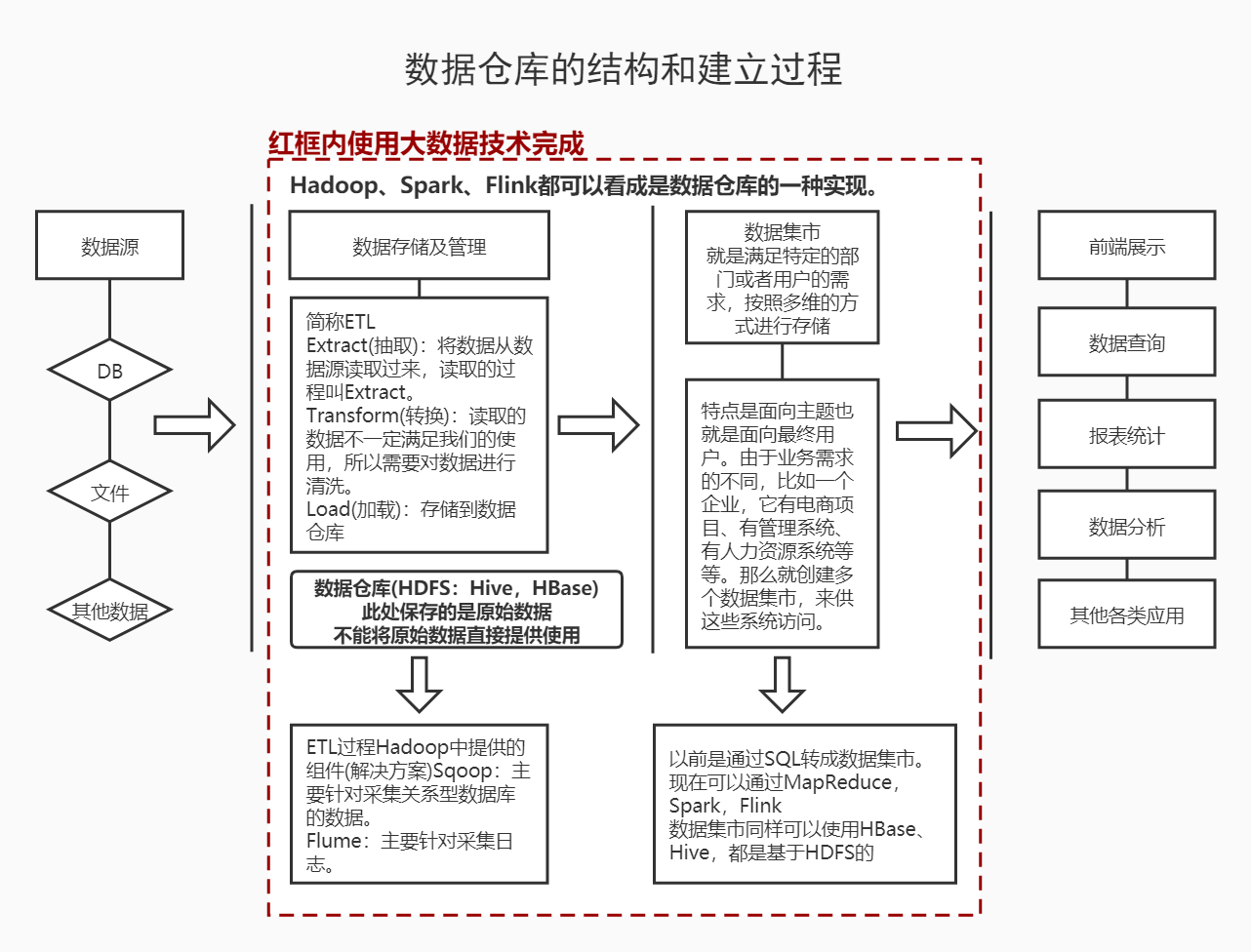
OLTP与OLAP
- OLTP:On-Line Transaction Processing(联机事务处理过程)。就是事务操作(insert、update、delete、commit、rollback),也称为面向交易的处理过程,其基本特征是前台接收的用户数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果,是对用户操作快速响应的方式之一。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。一般在大数据中不考虑OLTP。典型案例:银行转账。
- OLAP:On-Line Analytic Processing(联机分析处理过程)。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供 直观易懂的查询结果。典型案例:商品推荐。
Hadoop目录结构

Hadoop部署的4种方式
- 本地模式:没有HDFS和YARN。
- 伪分布模式:在单机上,模拟分布式环境。学习使用。
- 全分布模式:3台
- HA(High availability高可用)模式:解决主从架构单点故障问题。HDFS的主节点NameNode和YARN的主节点ResourceManager宕机会造成整体无法使用。所以需要HA模式,依赖于zookeeper。包括hbase、spark等都是依赖zookeeper。思想是搞2个NameNode,1个active状态,1个是standBy状态,正常情况下都通过active状态的NameNode去操作,当active的NameNode宕机,standBy状态的NameNode,将接管顶替,完成这个接管顶替,需要借助zookeeper来完成。
Hadoop版本比较(学习时强烈推荐Apache社区版)
目前Hadoop发行版非常多,有华为发行版、Intel发行版、Cloudera发行版(CDH)等,所有这些发行版均是基于Apache Hadoop衍生出来的,之所以有这么多的版本,完全是由Apache Hadoop的开源协议决定的:任何人可以对其进行修改,并作为开源或商业产品发布/销售。
1.Apache社区版
优点:
- 完全开源免费
- 社区活跃
- 文档、资料详实
缺点:
- 版本管理比较混乱,各种版本层出不穷,很难选择,选择生态组件时需要大量考虑兼容性问题、版本匹配问题、组件冲突问题、编译问题等。
- 集群的部署安装配置复杂,需要编写大量配置文件,分发到每台节点,容易出错,效率低。
- 集群运维复杂,需要安装第三方软件辅助。
2.第三方发行版
优点:
- 基于Apache协议,100%开源。
- 版本管理清晰,相比于Apache Hadoop在兼容性、安全性、稳定性上有增强。第三方发行版通常都经过了大量的测试验证,有众多部署实例,大量的运行到各种生产环境。
- 版本更新快。通常情况,比如CDH每个季度会有一个update,每一年会有一个release。
- 基于稳定版本Apache Hadoop,并应用了最新Bug修复或Feature的patch。
- 提供了部署、安装、配置工具,大大提高了集群部署的效率
- 运维简单。提供了管理、监控、诊断、配置修改的工具,管理配置方便,定位问题快速、准确,使运维工作简单,有效。
缺点:
- 涉及到厂商锁定的问题。
第三方发行版的比较
Cloudera:最成型的发行版本,拥有最多的部署案例。提供强大的部署、管理和监控工具。Cloudera开发并贡献了可实时处理大数据的Impala项目。目前较常用的是CDH3以上的版本,CDH3对应于hadoop 1.0,而CDH4和CDH5对应于hadoop2.0.Cloudera,版本层次明确,代码也是完全开源,并且集群部署工具比较完善以及教程等相对较多,社区活跃。
Hortonworks:Hortonworks提供的hadoop发行版称为HDP(Hortonworks Data Platform),也是全开源的系统。HDP除了包含常见的项目外还包含了Ambari,一款开源的安装和管理系统。一个元数据管理系统HCatlog,还包含HBase、Hive、Pig等一整套大数据解决方案技术。Hortonworks在管理工具和集群部署方面有其独特优势。
MapR:与竞争者相比,它使用了一些不同的概念,特别是为了获取更好的性能和易用性而支持本地Unix文件系统而不是HDFS(使用非开源的组件)。可以使用本地Unix命令来代替Hadoop命令。除此之外,MapR还凭借诸如快照、镜像或有状态的故障恢复之类的高可用性特性来与其他竞争者相区别。该公司也领导着Apache Drill项目,本项目是Google的Dremel的开源项目的重新实现,目的是在Hadoop数据上执行类似SQL的查询以提供实时处理。
IBM:IBM不提供只针对Hadoop的发行版,而是在原生hadoop的基础上进行了增强,例如增强了安全认证、作业调度等,采用Pig,Hive,HBase等技术开发了IBM的InfoSphere BigInsights大数据平台,一般面向IBM企业用户。
华为:华为在国内大数据领域也是走在前列的,其在Apache Hadoop的基础上利用本身的硬件能力进行了一些增强,例如故障自动Failover,增强HA功能等,其发布的版本为FusionInsight Hadoop。
版本选择
众多版本应该如何选择?综上所述,Apache Hadoop原生版本以及Cloudera CDH版本无论在开源或者社区活跃度,学习资料等方面都位列前茅,如果是用于生产环境部署,则可根据情况选择稳定的版本,或者选择Hortonworks可以使用ambari等管理工具较为方便地进行部署。
当我们选择是否采用某个软件用于开源环境时,通常需要考虑:
(1)是否为开源软件,即是否免费。
(2)是否有稳定版,这个一般软件官方网站会给出说明。
(3)是否经实践验证,这个可通过检查是否有一些大点的公司已经在生产环境中使用知道。
(4)是否有强大的社区支持,当出现一个问题时,能够通过社区、论坛等网络资源快速获取解决方法。
Hadoop体系结构
分布式存储:HDFS(Hadoop Distributed File System)
YARN: 分布式计算(MapReduce)
HBase:分布式、面向列的NoSQL数据库

若有收获,就点个赞吧
0 人点赞
