RocketMQ概述
RocketMQ是一款开源的、分布式的消息投递与流数据。2016年11月,阿里巴巴将RocketMQ捐献给 Apache基金会。2017年9月25日。RocketMQ成功”毕业”(Apache社区项目孵化成功即为毕业),成为Apache顶级项目,它是国内首个互联网中间件在Apache的顶级项目,也是继ActiveMQ、Kafka后Apache家族中全新的一代消息队列引擎。
消息队列适合解决哪些问题
异步处理:加快业务响应时间,相对于RPC来说,异步通信使得生产者和消费者得以充分执行自己的逻辑而无需等待。例如下单业务需要风险控制、库存锁定、生成订单、短信通知等操作,相对于这几个步骤来说,能否下单成功,实际上只有风险控制和库存锁定这 2 个步骤,只要用户的下单请求通过风险控制,并在服务端完成库存锁定,就可以给用户返回下单结果了,对于后续的操作并不一定需要在本次请求中完成,可以放入消息队列中异步的处理。
流量控制:当短时间内大量的请求到达网关时,不会直接冲击到后端的服务,而是先堆积在消息队列中,后端服务按照自己的最大处理能力,从消息队列中消费请求进行处理。运维人员还可以随时增加服务的实例数量进行水平扩容,而不用对系统的其他部分做任何更改。存在弊端:增加了系统调用链环节,导致总体的响应时延变长,上下游系统都要将同步调用改为异步消息,增加了系统的复杂度。更简单一点的流量控制方式就是采用令牌桶来控制,如果能预估出服务的处理能力,就可以用消息队列实现一个令牌桶,更简单地进行流量控制。
服务解耦:例如订单业务需要发送短信、推送通知信息等,如果把这些全部写在订单业务代码中,订单代码将会变得十分臃肿,不利于修改维护,事物管理十分麻烦,使用消息队列就不会有上述问题。
RocketMQ 部署架构
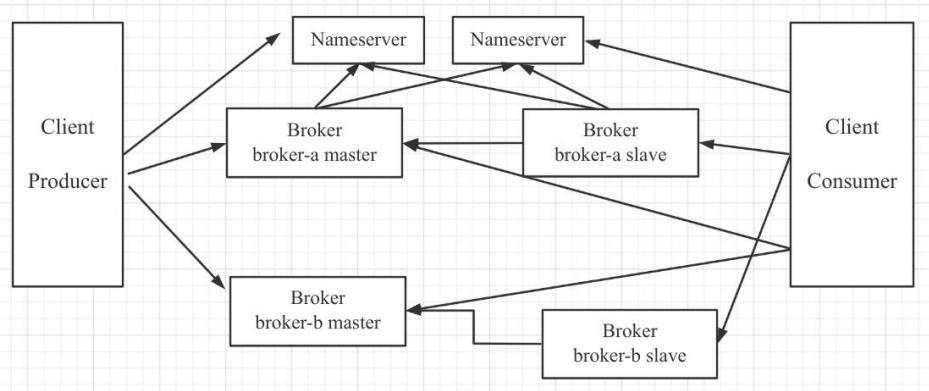
Nameserver:Nameserver集群,Topic的路由注册中心,为客户端根据Topic提供路由服务,从而引导客户端向Broker发送消息。Nameserver之间的节点不通信。路由信息在Nameserver集群中数据一致性采取的最终一致性。
Broker:消息存储服务器,分为两种角色:Master与Slave,上图中呈现的就是2主2从的部署架构,在RocketMQ中,主服务承担读写操作,从服务器作为一个备份,当主服务器存在压力时,从服务器可以承担读服务(消息消费)。所有Broker,包含Slave服务器每隔30s会向Nameserver发送心跳包,心跳包中会包含存在在Broker上所有的Topic的路由信息。
Client:消息客户端,包括Producer(消息发送者)和Consumer(消费消费者)。客户端在同一时间只会连接一台Nameserver,只有在连接出现异常时才会向尝试连接另外一台。客户端每隔30s向Nameserver发起Topic的路由信息查询。
主题和队列
队列(Queue):是一种数据结构,有完整而严格的定义。队列是先进先出(FIFO, First-In-First-Out)的线性表(Linear List)。在具体应用中通常用链表或者数组来实现。队列只允许在后端(称为 rear)进行插入操作,在前端(称为 front)进行删除操作。
早期的消息队列,就是按照“队列”的数据结构来设计的。

多个生产者往同一个队列中发送消息,那么这个队列中可以消费到的消息就是这些生产者所有消息的合集。消息的顺序就是生产者发送消息的自然顺序。如果有多个消费者接收同一队列的消息,那他们实际上是竞争的关系,每个消费者只能收到队列中的一部分消息,也就是任何一条消息只能被其中的一个消费者收到。如果需要将一份消息数据分发给多个消费者,要求每个消费者都能收到全量的消息,这时单个队列就满足不了需求。
一个比较蠢的解决办法是同样的消息发送多份到多个队列。但这会浪费资源,而且生产者必须知道有多少个消费者,才能为每个消费者单独发送一份消息,这就违背了消息队列“解耦”的设计初衷。为了解决这个问题,衍化出了另外一种消息模型:“发布 - 订阅模型(Publish-Subscribe Pattern)”。
发布 - 订阅模型(Publish-Subscribe Pattern):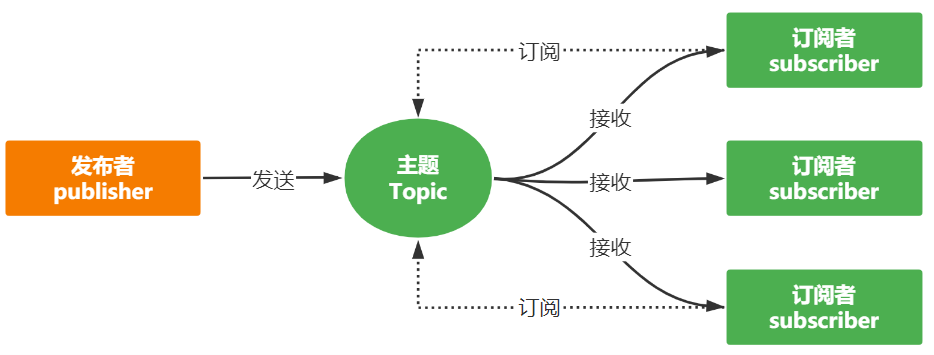
在发布 - 订阅模型中,消息的发送方称为发布者(Publisher),消息的接收方称为订阅者(Subscriber),服务端存放消息的容器称为主题(Topic)。发布者将消息发送到主题中,订阅者在接收消息之前需要先“订阅主题”。“订阅”在这里既是一个动作,同时还可以认为是主题在消费时的一个逻辑副本,每份订阅中,订阅者都可以接收到主题的所有消息。
RocketMQ 的消息模型
RocketMQ 使用的消息模型是标准的发布 - 订阅模型。但是,在 RocketMQ 也有队列(Queue)这个概念,并且队列在 RocketMQ 中是一个非常重要的概念。
消息队列的消费机制:几乎所有的消息队列产品都使用“请求 - 确认”机制,确保消息不会在传递过程中由于网络或服务器故障丢失。具体的做法也非常简单:
在生产端,生产者先将消息发送给服务端也就是Broker,服务端在收到消息并将消息写入主题或者队列中后,会给生产者发送确认的响应。如果生产者没有收到服务端的确认或者收到失败的响应,则会重新发送消息;
在消费端,消费者在收到消息并完成自己的消费业务逻辑(比如,将数据保存到数据库中)后,也会给服务端发送消费成功的确认,服务端只有收到消费确认后,才认为一条消息被成功消费,否则它会给消费者重新发送这条消息,直到收到对应的消费成功确认。
这个机制带来的问题:为了确保消息的有序性,在某一条消息被成功消费之前,下一条消息是不能被消费的,也就是说,每个主题在任意时刻,至多只能有一个消费者实例在进行消费,那就没法通过水平扩展消费者的数量来提升消费端总体的消费性能。
为了解决这个问题,RocketMQ 在主题下面增加了队列的概念。
每个主题包含多个队列,通过多个队列来实现多实例并行生产和消费。需要注意RocketMQ只在队列上保证消息的有序性,主题层面是无法保证消息的严格顺序的。
RocketMQ中,订阅者的概念是通过消费组(Consumer Group)来体现的,由消费组来订阅Topic(可订阅多个Topic),每个消费组都能消费主题中一份完整的消息,不同消费组之间的消费进度相互不受影响。如一条消息被Consumer Group1 消费过,也会再给Consumer Group2 消费。
在消费组中又包含多个消费者,同一组内的消费者是竞争消费关系,每个消费者负责消费组内一部分消息。如果一条消息倍消费者Consumer1消费了,那同组的其他消费者就不会再收到这条消息了。
在 Topic 的消费过程中,由于消息需要被不同的组进行多次消费,所以消费完的消息并不会立即被删除,这就需要 RocketMQ 为每个消费组在每个队列上维护一个消费位置(Consumer Offset),这个位置之前的消息都被消费过,之后的消息都没有被消费过,每成功消费一条消息,消费位置就加一。这个消费位置是非常重要的概念,在使用消息队列的时候,丢消息的原因大多是由于消费位置处理不当导致的。
举例阐述:例如我们在开发一个订单系统,其中有一个子系统:order-service-app,在该项目中会创建一个消费组order_consumer来订阅order_topic,并且基于分布式部署,order-service-app的部署情况如下,即order-service-app部署了 3 台服务器: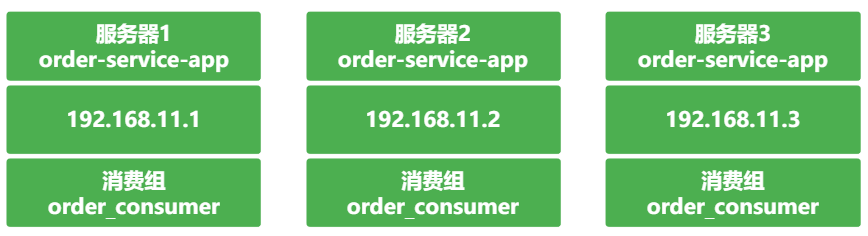
如何消费:在RocketMQ中支持广播模式与集群模式。
广播模式:一个消费组内的所有消费者每个消费者都会处理Topic中的每一条消息,通常用于刷新内存缓存。
集群模式(普遍):一个消费组内的所有消费者共同消费一个Topic中的消息,即分工协作,一个消费者消费一部分数据。启动负载均衡。符合分布式架构的基本理念,即横向扩容,当前消费者如果无法快速及时处理消息时,可以通过增加消费者的个数横向扩容,快速提高消费能力,及时处理挤压的消息。
消费队列负载算法与重平衡机制:负载算法:平均分配(AllocateMessageQueueAveragely)和轮流平均分配(AllocateMessageQueueAveragelyByCircle)。重平衡机制:在RocketMQ客户端中会每隔20s去查询当前Topic的所有队列、消费者的个数,运用队列负载算法进行重新分配,然后与上一次的分配结果进行对比,如果发生了变化,则进行队列重新分配;如果没有发生变化,则忽略。
常见术语
- Producer Group(生产者组):一个逻辑概念,在使用生产者实力的时候需要指定一个组名,一个生产者组可以生产多个Topic的消息。
- Producer(生产者):消息生产者,负责产生消息。
- Topic(主题):主题名字,一个Topic由若干Queue组成。
- Consumer:消息消费者,负责消费消息,一般是后台系统负责异步消费。
- Push Consumer:Consumer 的一种,应用通常向Consumer对象注册一个Listener接口,一旦收到消息,Consumer对象立刻回调Listener接口方法。
- Pull Consumer:Consumer的一种,应用通常主动调用Consumer的拉消息方法从Broker拉消息,主动权由应用控制。
- Consumer Group:一类Consumer的集合名称,这类Consumer通常消费一类消息,且消费逻辑一致。
- Broker:消息中转角色,负责存储消息,转发消息,一般也称为Server。在JMS规范中称为Provider。
消息队列使用常见功能及解决方案
一、利用事务消息实现分布式事务
①开启事务 -> ②发送半消息 -> ③执行本地事务 -> ④提交事务
消息队列是如何实现分布式事务的:例如商品系统中调用搜索服务添加该商品的搜索信息,首先商品系统在消息队列上开启一个事务,然后商品系统给消息服务器发送一个“半消息”,半消息并不是指消息内容不完整,它包含的内容就是完整的消息内容,半消息和普通消息的唯一区别是,在事务提交之前,对于消费者来说,这个消息是不可见的。半消息发送成功后,商品系统就可以执行本地事务了,如操作商品数据库插入商品等操作,操作成功就提交事务消息,搜索服务就可以消费到这条消息继续后续的流程。操作失败就回滚事务消息,搜索服务则不会收到这条消息。衍生问题:如果提交事务消息(第④步)失败如何处理?
RocketMQ中的分布式事务实现
在RocketMQ中的事务实现中,增加了事务反查的机制来解决事务消息提交失败的问题。如果Producer(商品系统)在提交或者回滚事务消息时发生网络异常,RocketMQ的Broker没有收到提交或者回滚的请求,Broker会定期去Producer(商品系统)上反查这个事务对应的本地事务的状态,然后根据反查结果决定提交或者回滚这个事务。为了支撑这个事务反查机制,需要在商品系统中添加一个实现反查本地事务状态的接口,告知RocketMQ本地事务是成功还是失败。在这个例子中反查的逻辑也很简单,只需要根据消息中的商品ID,在数据库中查询是否存在即可。反查的实现并不依赖发送方(商品系统某个实例),也就是即使该服务宕机,依然可以通过其他节点来执行反查来确定事务的完整性。
衍生问题:如果商品系统执行本地事务成功并提交了事务消息,在搜索服务中操作出现了异常,此时需要回滚商品系统中的事务,这种情况需要采用其他分布式事务解决方案。
代码示例:
待补充。。。
二、如何确保消息不丢失
用消息队列最尴尬的情况不是丢消息,而是消息丢了还不知道
检测消息丢失的方法
可以利用消息队列的有序性来验证是否有消息丢失。在Producer端,给每个发出的消息附加一个连续递增的序号,然后Consumer端来检查这个序号的连续性。如果没有消息丢失,Consumer收到消息的序号必然是连续递增的,如果序号不连续了说明丢消息了,还可以根据序号定位到具体是哪条消息。
在分布式系统中需要注意的问题:RocketMQ中不保证Topic上的严格顺序,只保证Topic中的队列是有序的,所以在发消息时,必须指定队列,而后检测是否连续。如果系统中存在多个Producer实例,并不好协调多个Producer的发送顺序,那么就需要为每个Producer分别生成各自的序号并附带Producer标识,在Consumer端按照每个Producer分别来检测序号的连续性。
确保消息可靠传递
使用消息队列时,一条消息从生产到消费可以划分为3个阶段:
①生产阶段:从消息在 Producer 创建出来,经过网络传输发送到 Broker 端。(采取同步发送消息来解决这个阶段的消息丢失,同步发送时注意捕获异常。如果异步发送,需要在回调方法中检查发送结果。)
②存储阶段:消息在Broker端存储,如果是集群,消息会在这个阶段被复制到其他的副本上。(在这个阶段,只要Broker是正常运行的,就不会丢失消息。如果出现了故障如进程卡死或宕机,就可能丢失消息。单机可以采用为Broker配置参数来解决,需要将刷盘方式 flushDiskType 配置为 SYNC_FLUSH 同步刷盘,在收到消息后,将消息写入磁盘后在给Producer返回确认响应。如果是集群,则需要将Broker集群配置成至少发送到2个节点以上才返回确认响应。)
③消费阶段:Consumer 从 Broker 上拉取消息,经过网络传输发送到 Consumer 上。(消费阶段采用和生产阶段类似的确认机制来保证消息的可靠传递,在编写消费端代码时注意不要在收到消息后就立即发送消费确认,而是应该在执行完所有消费业务逻辑之后,再发送消费确认。)
三、消费过程中的重复消息
一般解决重复消息的办法是,在消费端让消费消息的操作具备幂等性。常用的设计幂等操作的方法:
- 数据库的唯一约束实现幂等。
- 为更新的数据设置前置条件。如版本号,更新前检查版本号与消息中的版本号是否一致
- 记录并检查操作。在发送消息时指定全局唯一ID,消费时先检测这个ID是否被消费过,如果没有消费过,则进行操作而后将消费状态置为已消费,在分布式系统中需要保证这些操作的原子性才可以,一般采用分布式锁。
四、消息积压了该如何处理
消息积压的直接原因,一定是系统中的某个部分出现了性能问题,来不及处理上游发送的消息,才会导致消息积压。
优化性能来避免消息积压:主要体现在生产者与消费者两端的业务逻辑中,再明确一点的话可以说体现在消费端。
生产者:生产者的业务逻辑的处理往往是先处理自己的业务逻辑然后才是发送消息,一般问题不大。如果说,代码发送消息的性能上不去,需要优先检查一下,是不是发消息之前的业务逻辑耗时太多导致的。
消费者:大部分的性能问题都出现在消费端,如果消费的速度跟不上发送端生产消息的速度,就会造成消息积压。要是消费速度一直比生产速度慢,时间长了,整个系统就会出现问题,要么,消息队列的存储被填满无法提供服务,要么消息丢失,这对于整个系统来说都是严重故障。所以一定要保证消费端的消费性能要高于生产端的发送性能,这样的系统才能健康的持续运行。消费端除了优化消费代码外还可以水平扩容。注意:在扩容 Consumer 的实例数量的同时,必须同步扩容主题中的队列数量,确保 Consumer 的实例数和队列数量是相等的。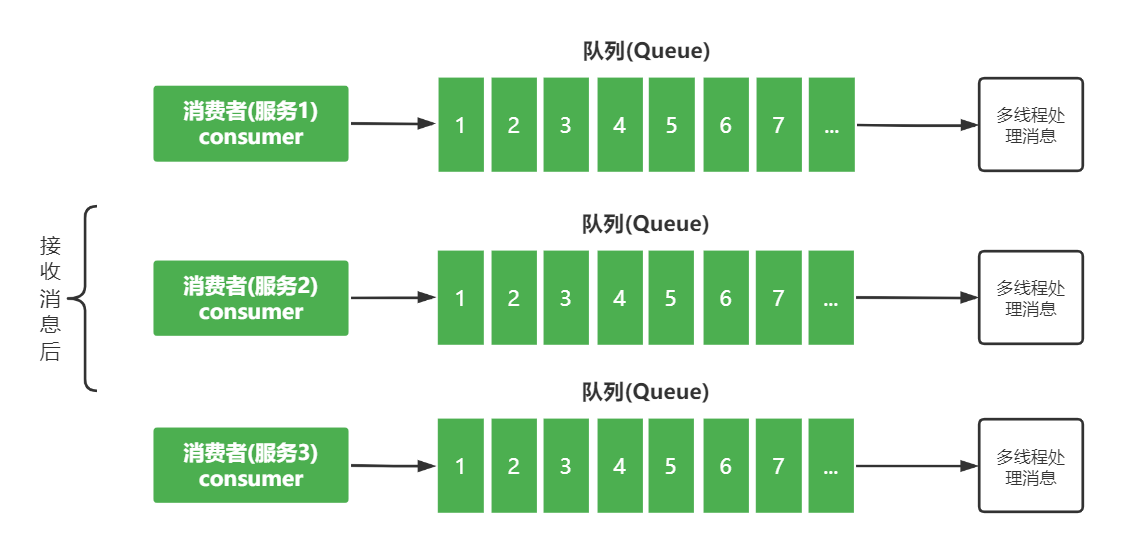
常见的错误方法:上图显示收到消息后,将消息先存储到内存队列中,然后开启多线程去处理消息。这种方法看似完美,实际可能会丢失消息(消息在内存中宕机就会丢失)。总结:要么是发送变快了,要么是消费变慢了
消息结构和消息类型
public class Message implements Serializable {private static final long serialVersionUID = 8445773977080406428L;//主题名字private String topic;//目前没用private int flag;//消息扩展信息, Tag keys 延迟级别都保存在这里private Map<String, String> properties;//消息体,字节数组,需注意编码方式private byte[] body;//事务IDprivate String transactionId;public Message() { }}

若有收获,就点个赞吧
0 人点赞
