下载地址:http://kylin.apache.org/cn/download/
注意:需要在/etc/profile文件中配置HADOOP_HOME,HIVE_HOME,HBASE_HOME并将其对应的sbin(如果有这个目录的话)和bin目录配置到Path,最后需要source使其生效。
kylin没有什么要安装的,解压了tar包就算安装好了。
一、启动与关闭
注意:启动Kylin之前要保证HDFS,YARN,ZK,HBASE相关进程是正常运行的。
启动:bin/kylin.sh start访问页面:http://master:7070/kylin用户名为:ADMIN,密码为:KYLIN(系统已填)关闭:bin/kylin.sh stop
二、kylin 运行实例使用测试
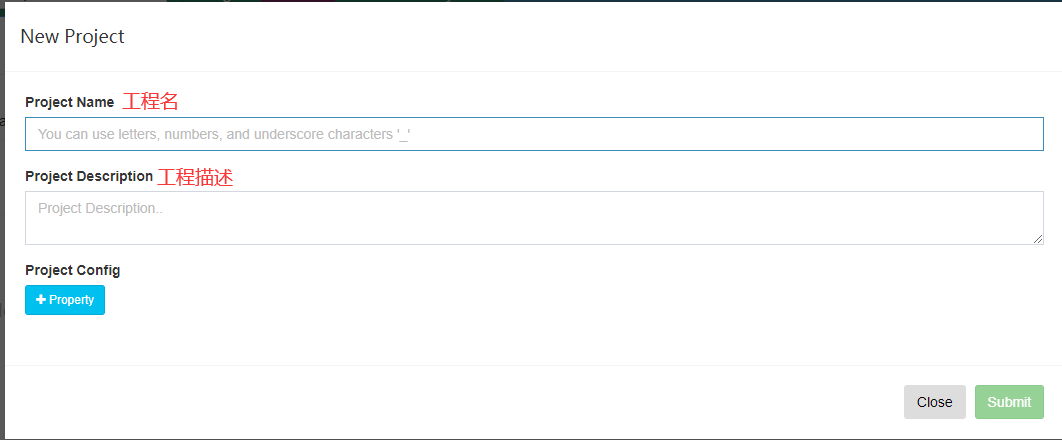
1.创建工程
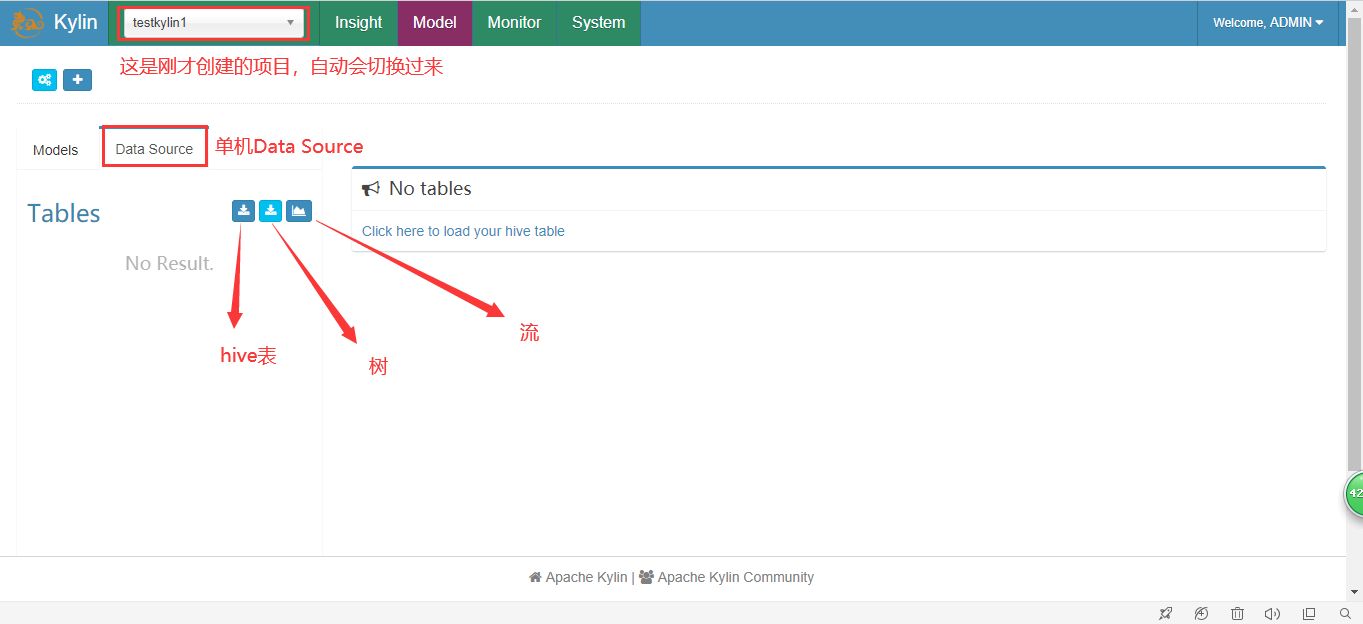
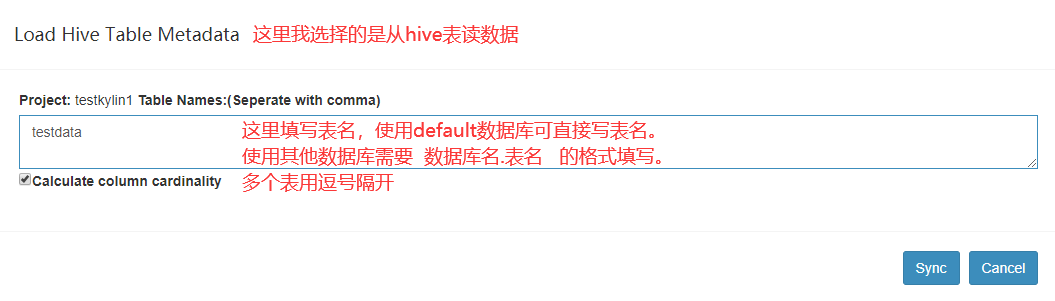
2.选择数据源
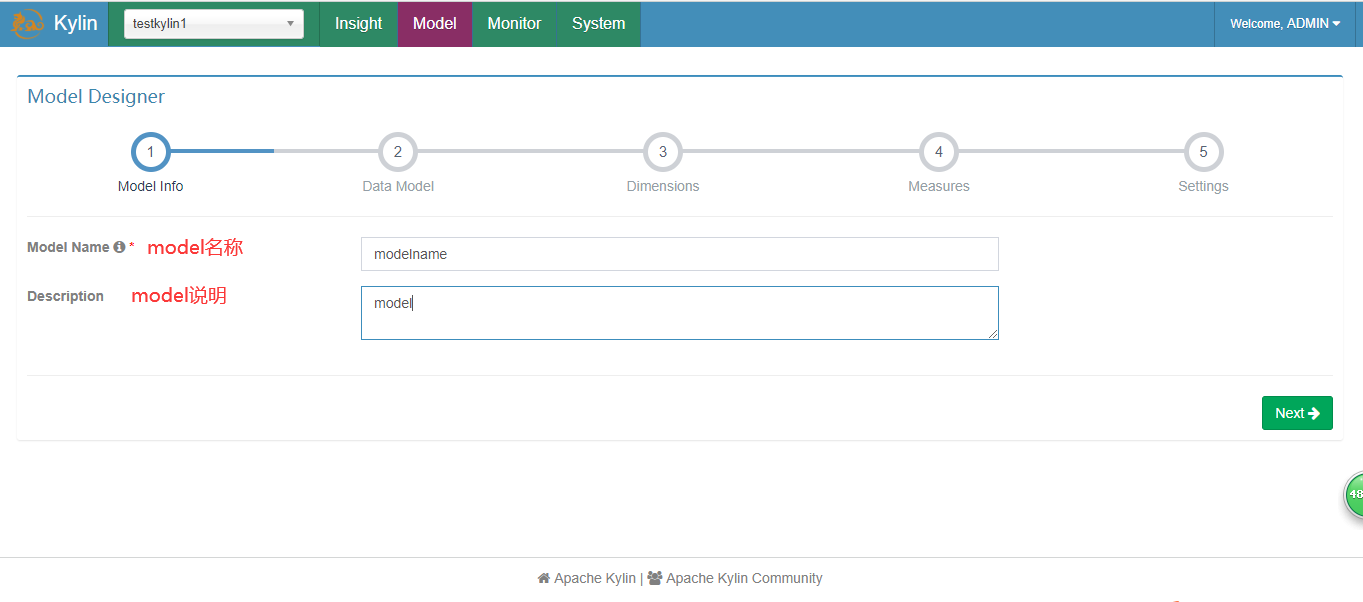
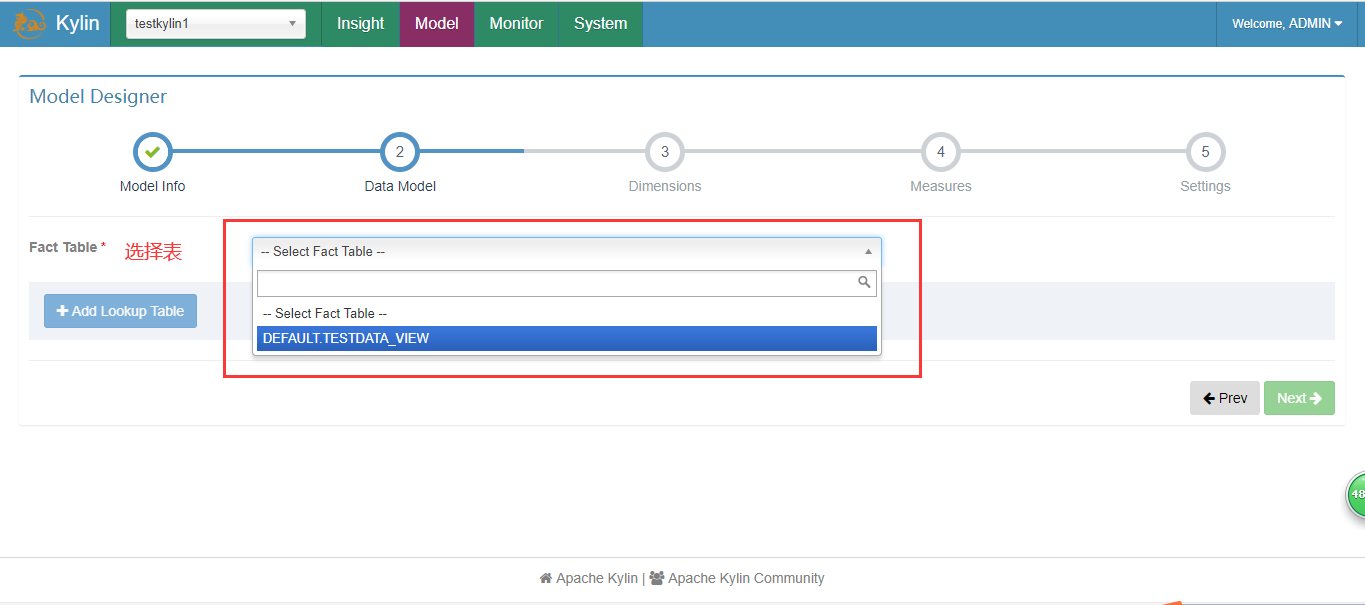
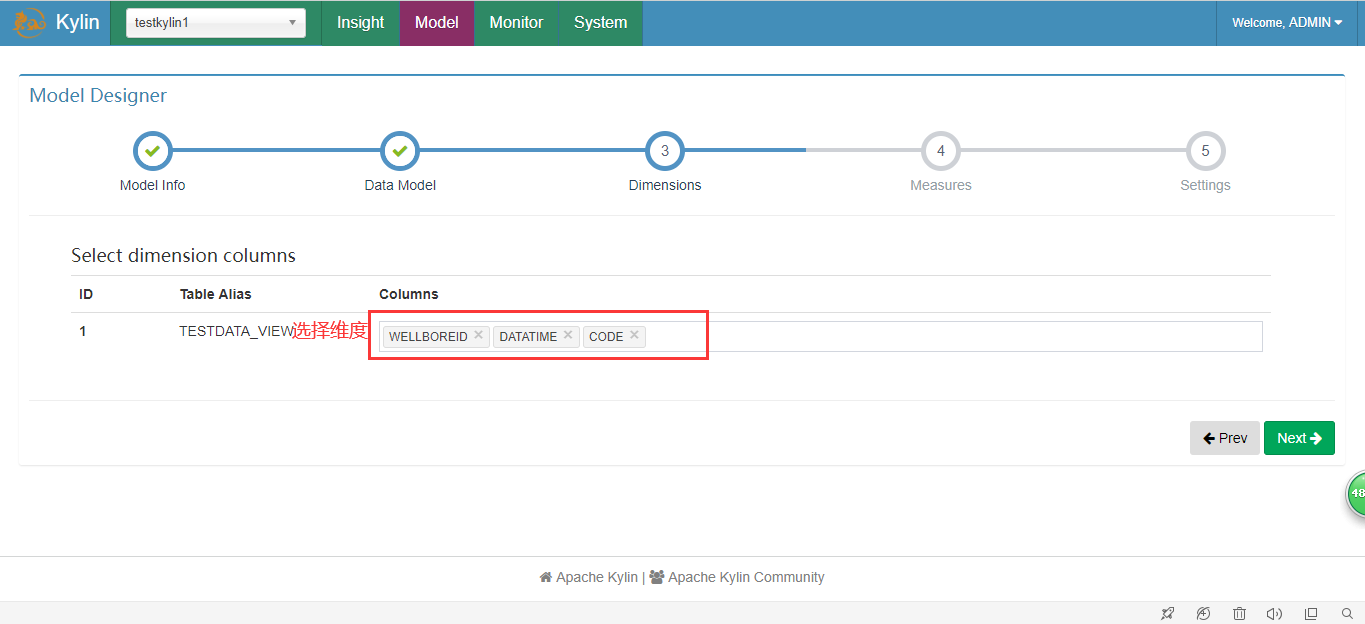
3.创建Mode
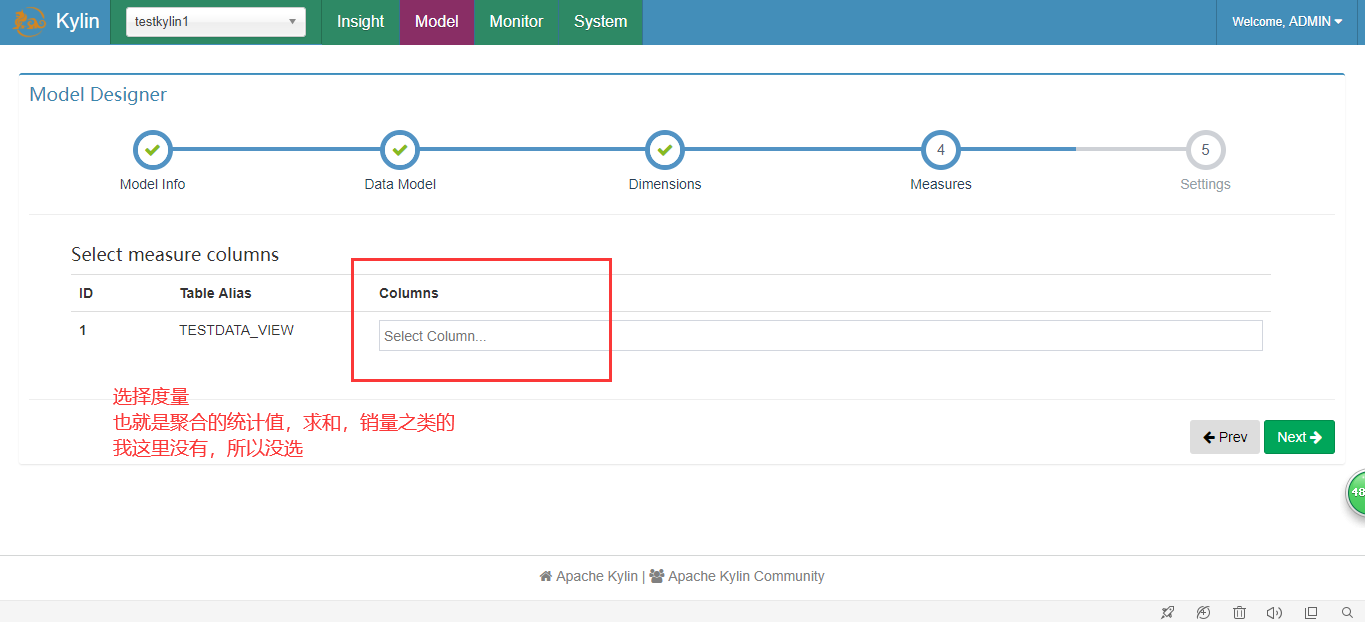
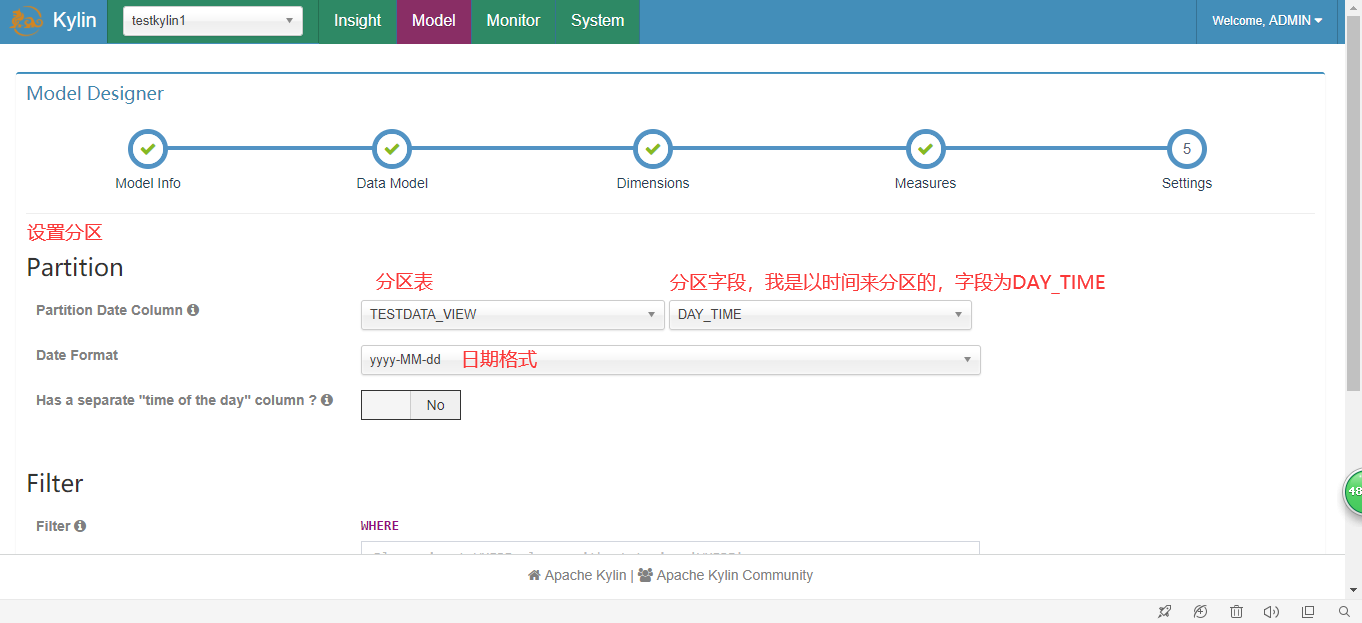
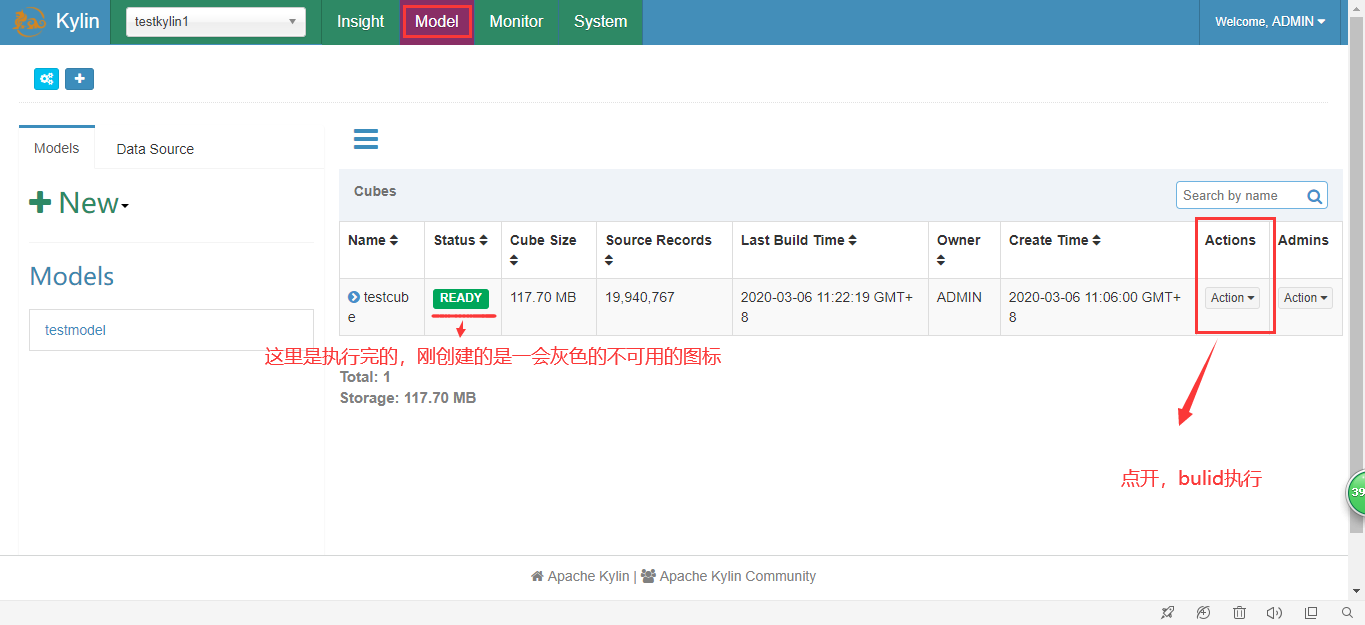
4.创建Cube
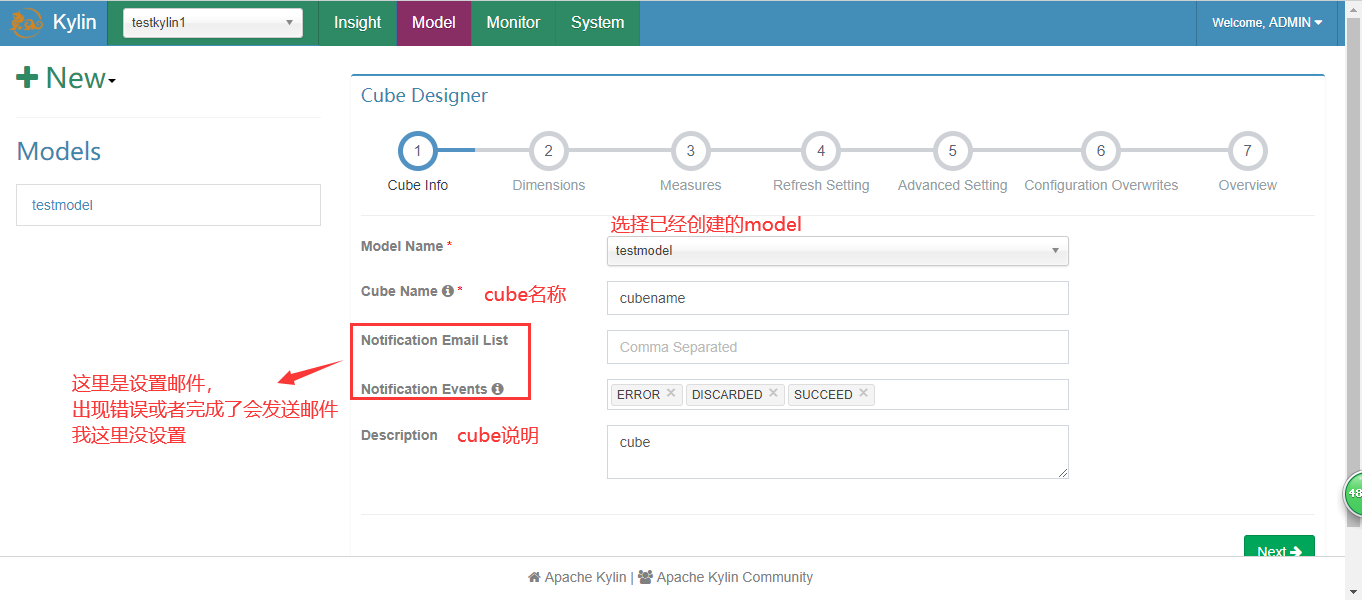
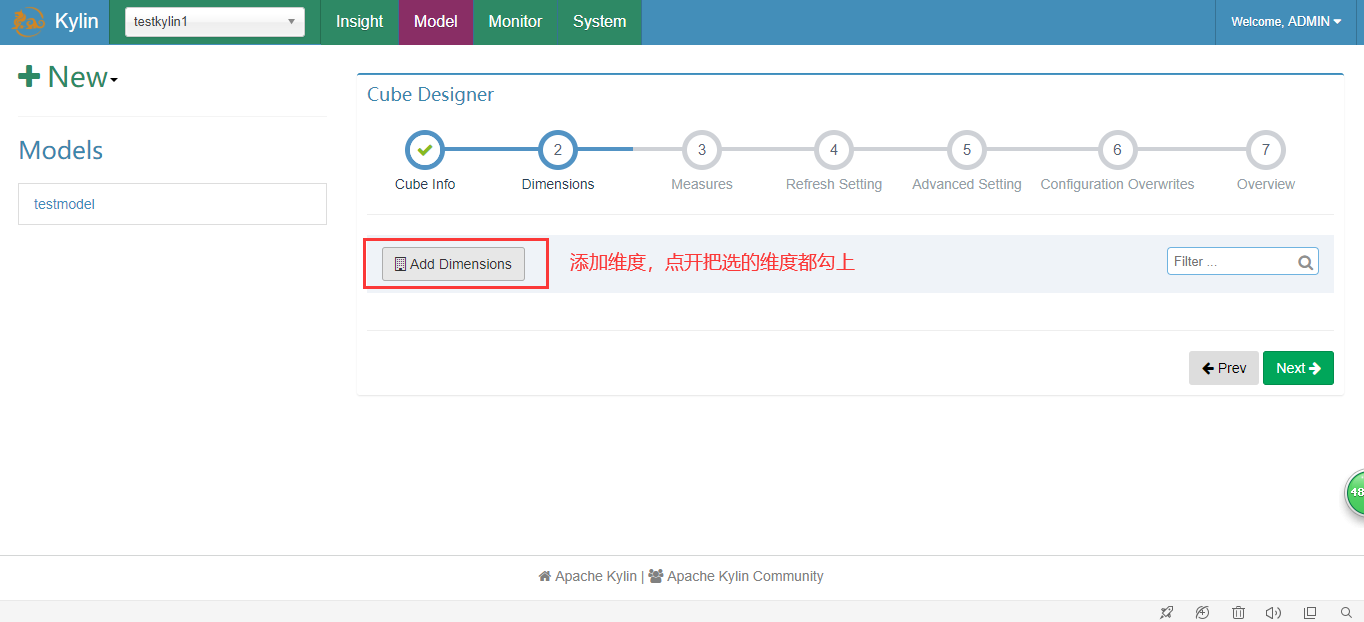
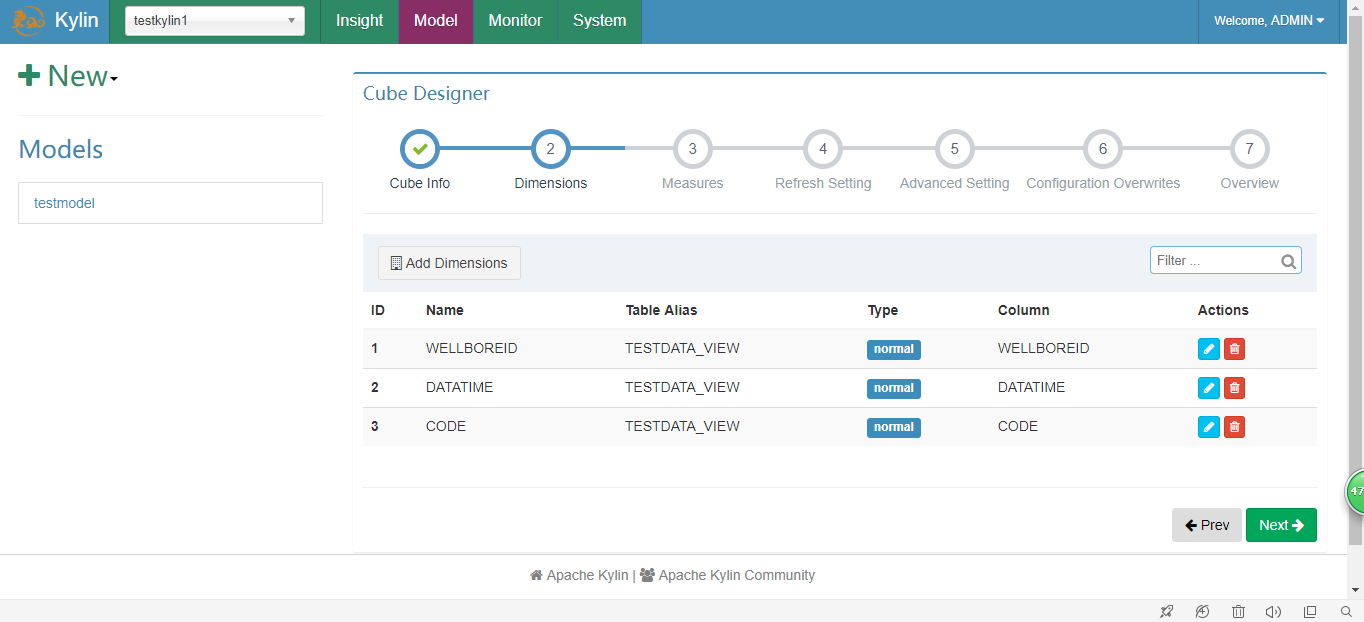
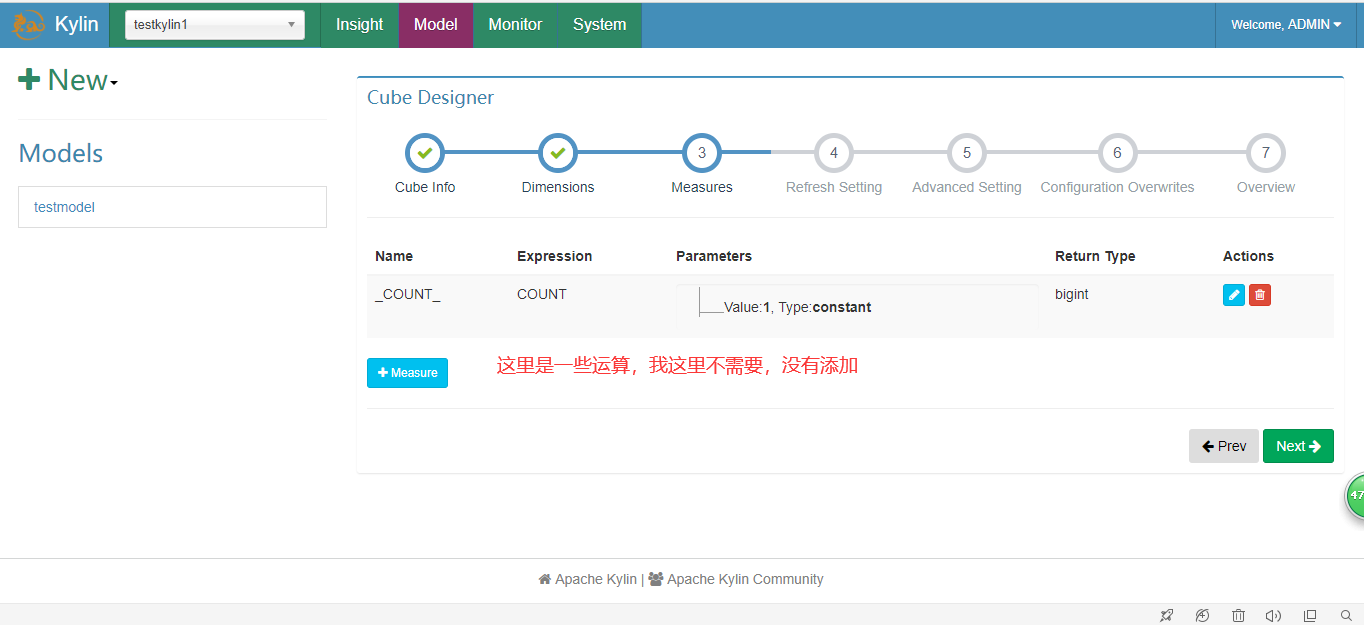
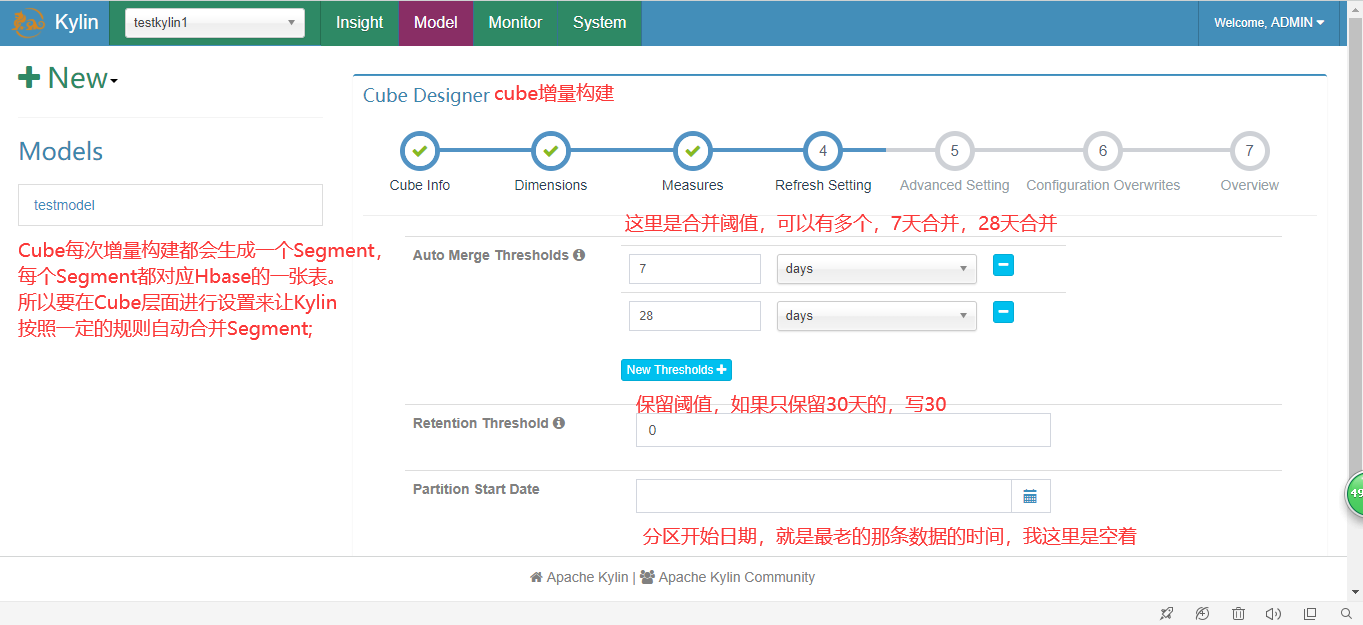
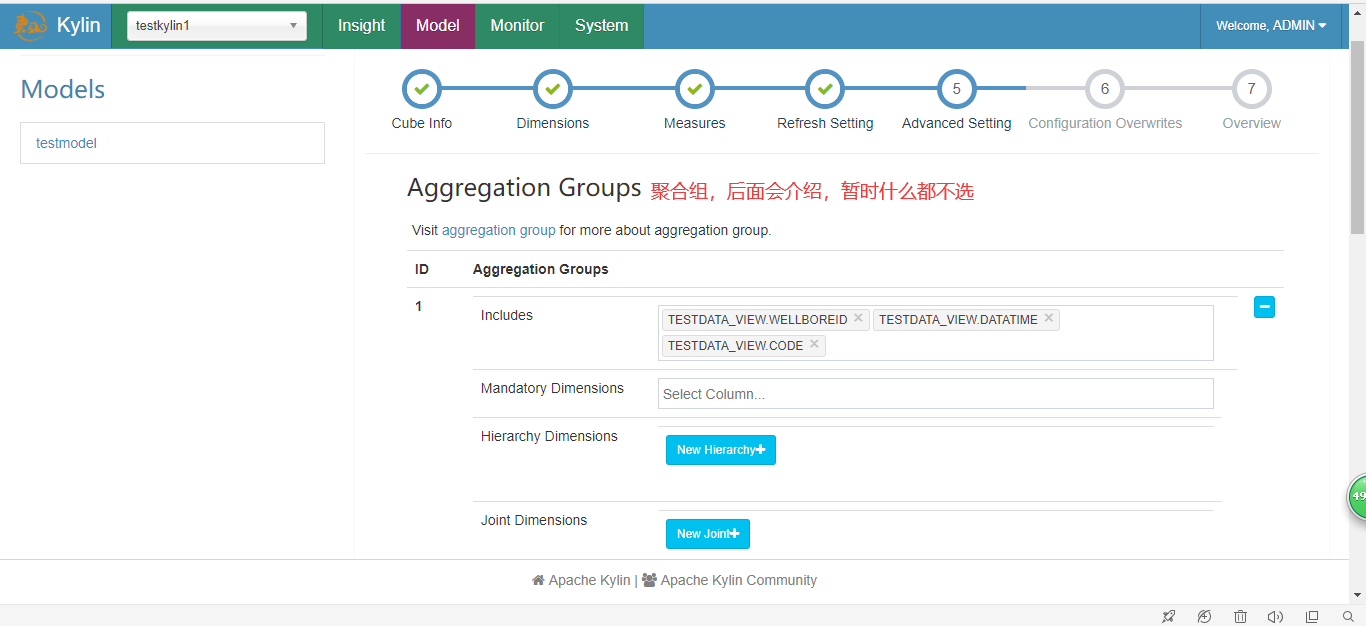
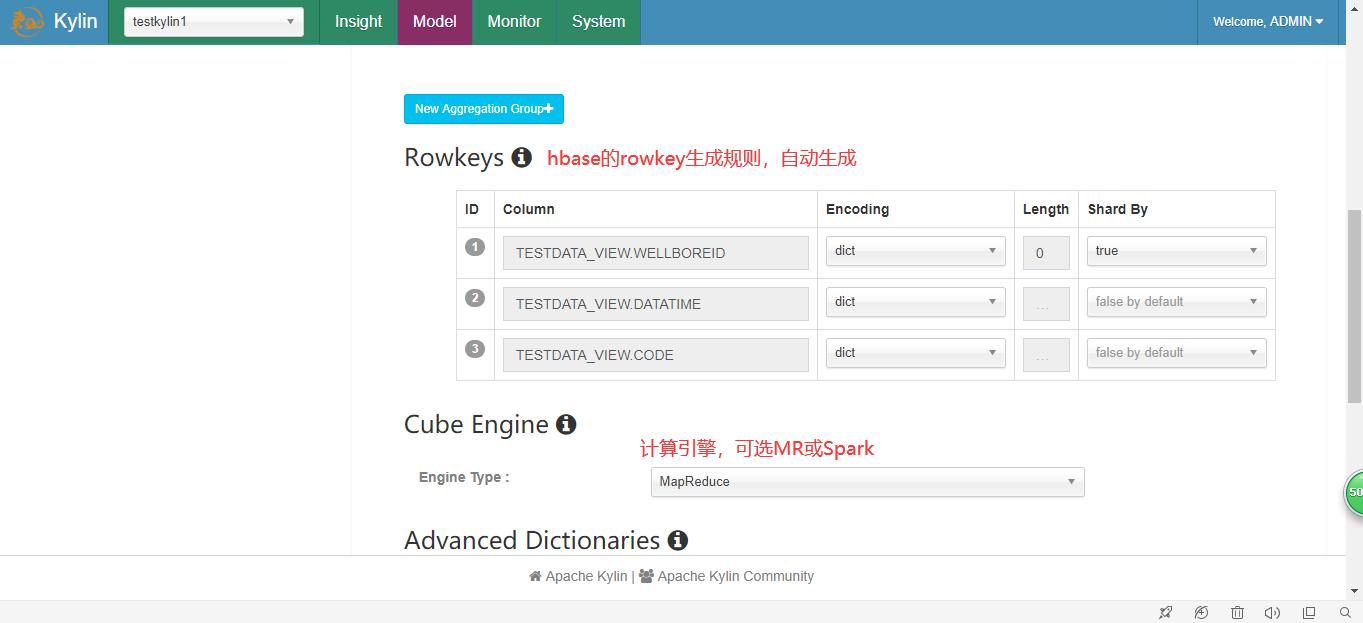
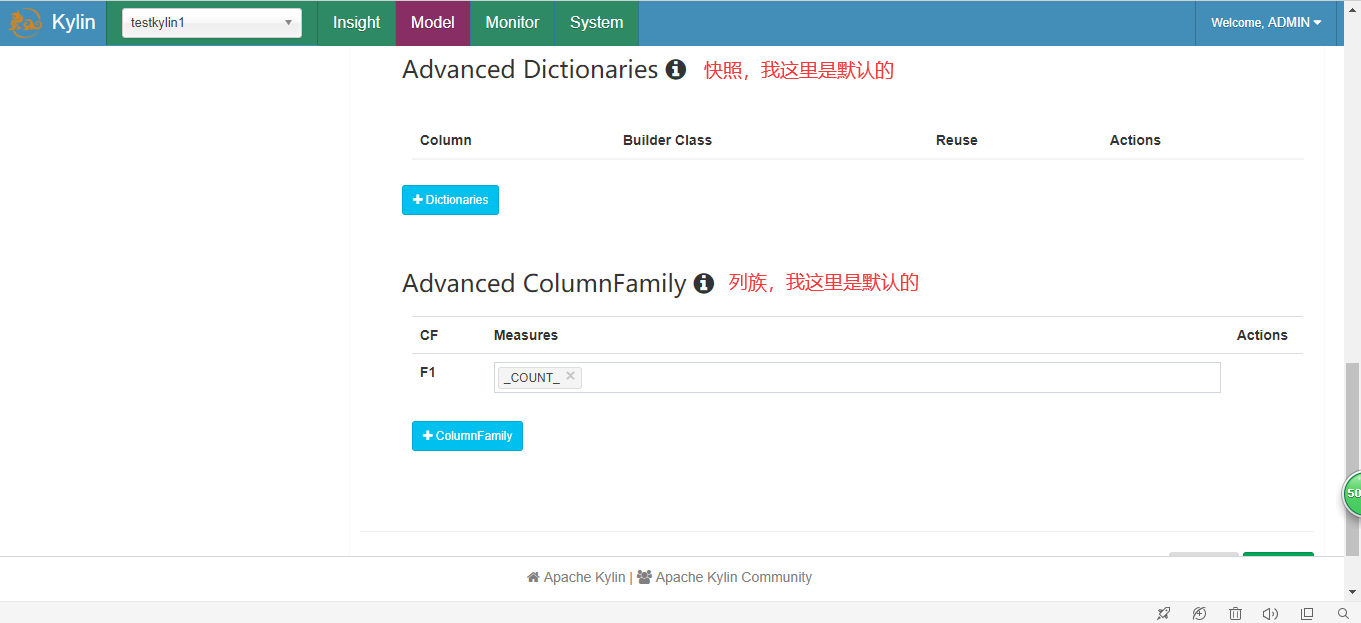
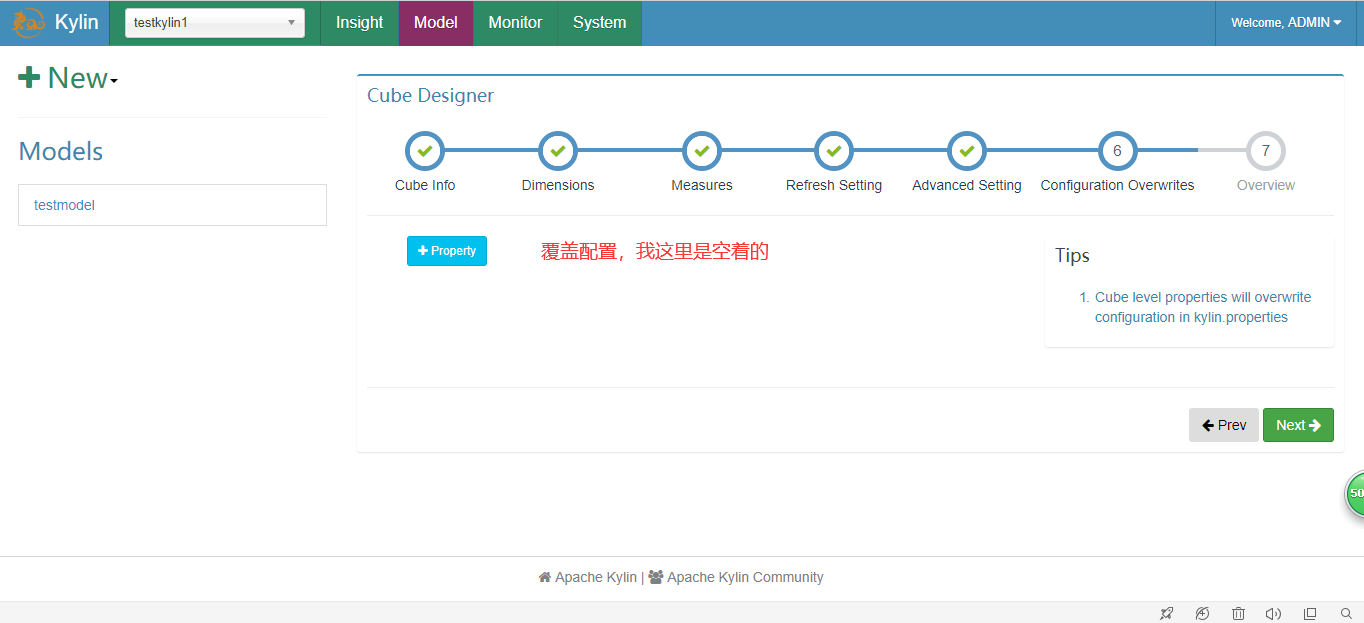
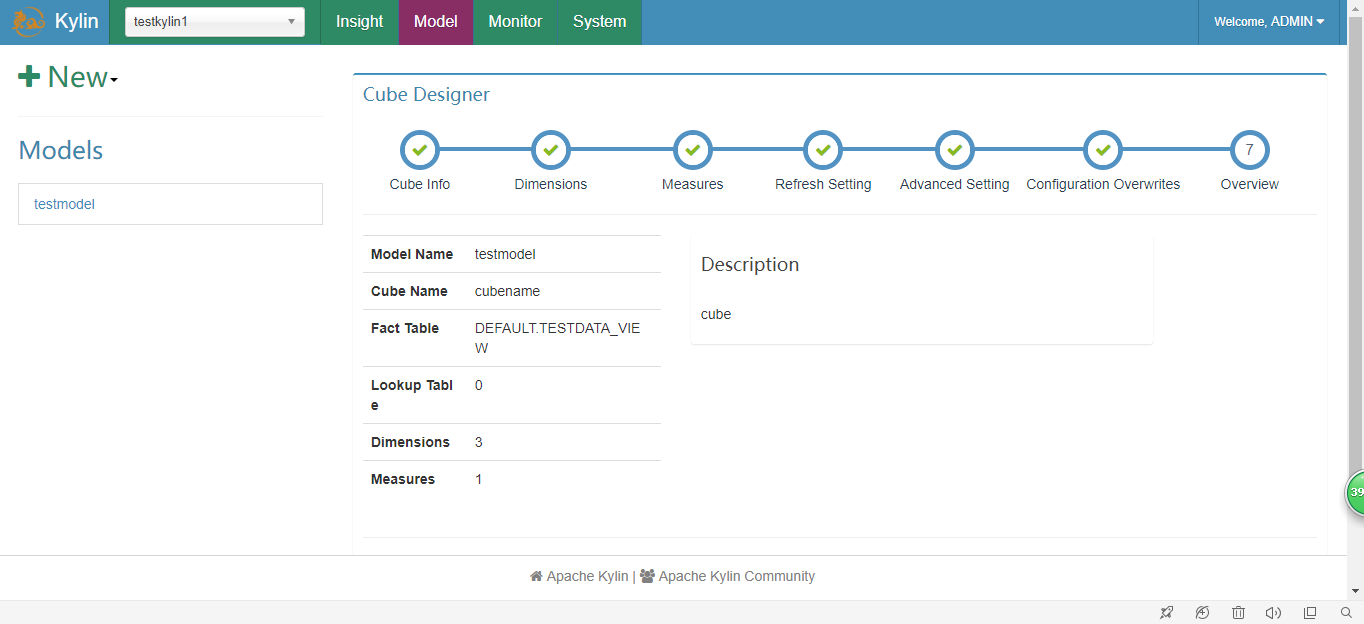
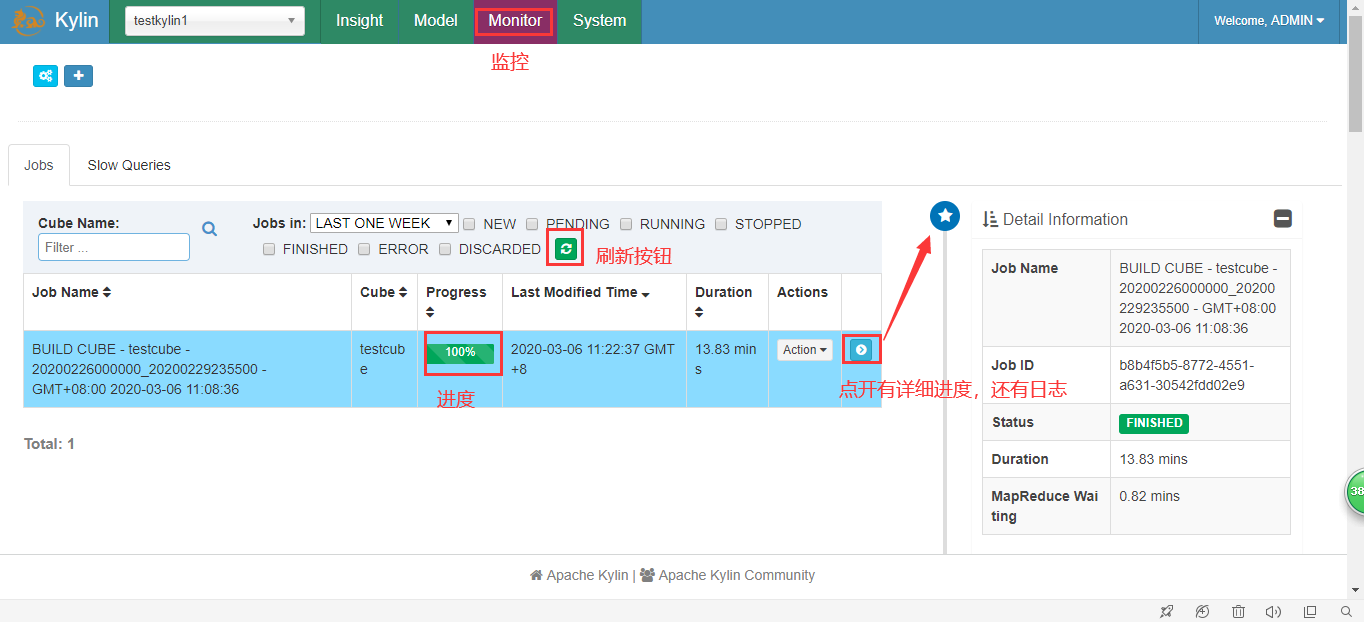
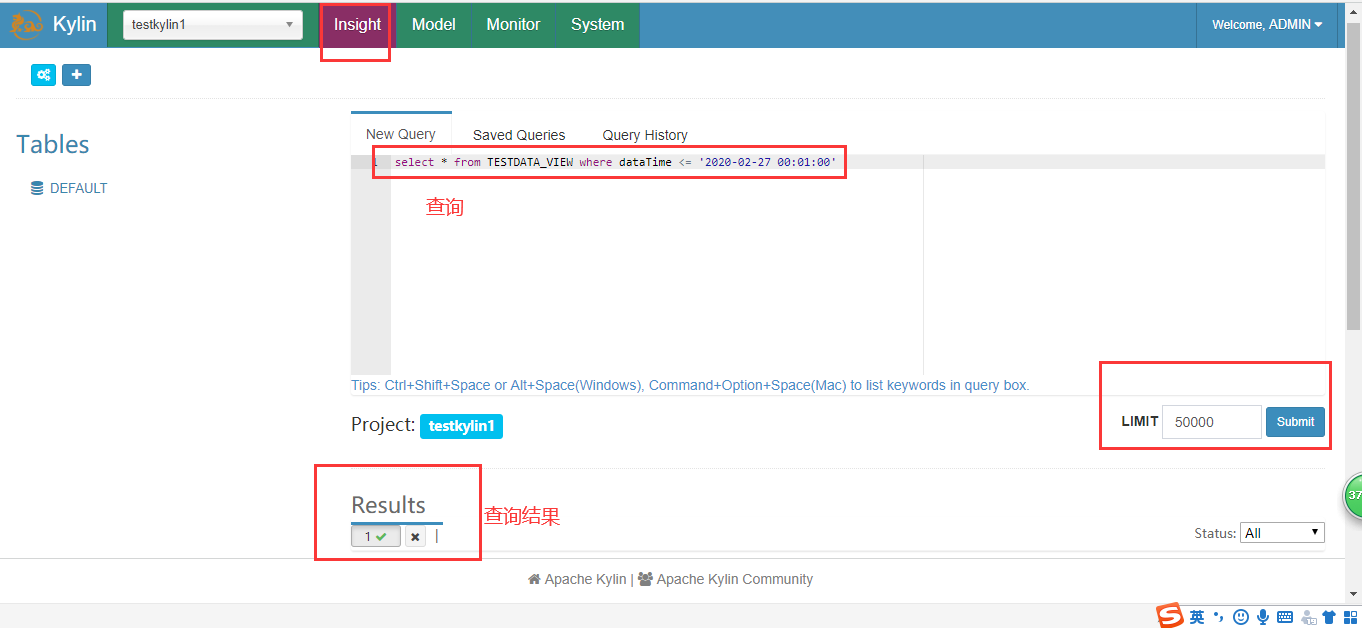
5.执行并查询
三、kylin优化
在没有采取任何优化措施的情况下,Kylin会对每一种维度的组合进行预计算,每种维度的组合的预计算结果被称为Cuboid。假设有4个维度,最终会有2 =16个Cuboid需要计算。但在现实情况中,用户的维度数量一般远远大于4个。假设用户有10 个维度,那么没有经过任何优化的Cube就会存在2 =1024个Cuboid;而如果用户有20个维度,那么Cube中总共会存在2 =1048576个Cuboid。虽然每个Cuboid的大小存在很大的差异,但是单单想到Cuboid的数量就足以让人想象到这样的Cube对构建引擎、存储引擎来说压力有多么巨大。因此,在构建维度数量较多的Cube时,尤其要注意Cube的剪枝优化(即减少Cuboid的生成)。
Kylin的维度优化
- 使用聚合组
聚合组(Aggregation Group)是一种强大的剪枝工具。聚合组假设一个Cube的所有维度均可以根据业务需求划分成若干组(当然也可以是一个组),由于同一个组内的维度更可能同时被同一个查询用到,因此会表现出更加紧密的内在关联。每个分组的维度集合均是Cube所有维度的一个子集,不同的分组各自拥有一套维度集合,它们可能与其他分组有相同的维度,也可能没有相同的维度。每个分组各自独立地根据自身的规则贡献出一批需要被物化的Cuboid,所有分组贡献的Cuboid的并集就成为了当前Cube中所有需要物化的Cuboid的集合。不同的分组有可能会贡献出相同的Cuboid,构建引擎会察觉到这点,并且保证每一个Cuboid无论在多少个分组中出现,它都只会被物化一次。
对于每个分组内部的维度,用户可以使用如下三种可选的方式定义,它们之间的关系,具体如下:
1.强制维度
假设有a,b,c三个字段,不做强制维度构建为a,b,c,ab,ac,bc,abc,0D(0D也就是没有维度)等。如果以a作为强制维度,最终的维度结果为a,ab,ac,abc。也就是维度中必须包含a字段。
2.层级维度
比如省->市->县的层级,a(省),b(市),c(县)三个字段,不做层级维度构建为a,b,c,ab,ac,bc,abc,0D等。如果以a->b(省到市)作为层级维度,也就是上级为省,下级为市的层级,最终的维度结果为a(省自己),ab(省到市),ac(省到县),abc(省市县),c(县),0D。可以看出减少了市到县(bc)的维度构建。
3.联合维度
每个联合中包含两个或更多个维度,如果某些列形成一个联合,那么在该分组产生的任何Cuboid中,这些联合维度要么一起出现,要么都不出现。每个分组中可以有0个或多个联合,但是不同的联合之间不应当有共享的维度(否则它们可以合并成一个联合)。比如a,b,c三个字段,不做联合维度构建为a,b,c,ab,ac,bc,abc,0D(0D也就是没有维度)等。如果将ab联合,作为联合维度,最终的维度结果为ab,abc,c,0D。可以看出结果中,ab要么同时出现,要么同时都不出现。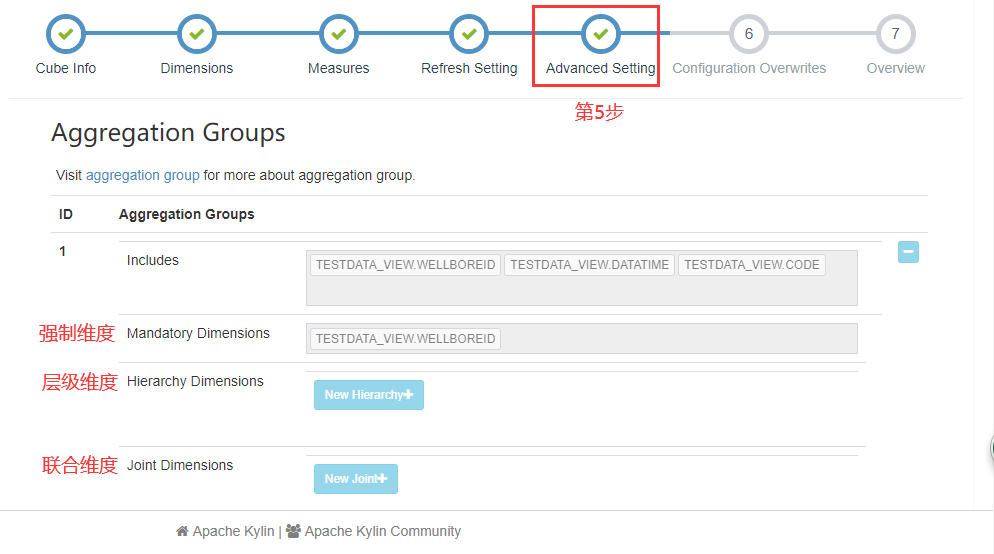
- 并发粒度优化
当Segment中某一个Cuboid的大小超出一定的阈值时,系统会将该Cuboid的数据分片到多个分区中,以实现Cuboid数据读取的并行化,从而优化Cube的查询速度。具体的实现方式如下:
构建引擎根据Segment估计的大小,以及参数“kylin.hbase.region.cut”的设置决定Segment在存储引擎中总共需要几个分区来存储,如果存储引擎是HBase,那么分区的数量就对应于HBase中的Region数量。kylin.hbase.region.cut的默认值是5.0,单位是GB,也就是说对于一个大小估计是50GB的Segment,构建引擎会给它分配10个分区。用户还可以通过设置kylin.hbase.region.count.min(默认为1)和kylin.hbase.region.count.max(默认为500)两个配置来决定每个Segment最少或最多被划分成多少个分区。
由于每个Cube的并发粒度控制不尽相同,因此建议在Cube Designer 的Configuration Overwrites(上图所示)中为每个Cube量身定制控制并发粒度的参数。
假设将把当前Cube的kylin.hbase.region.count.min设置为2,kylin.hbase.region.count.max设置为100。这样无论Segment的大小如何变化,它的分区数量最小都不会低于2,最大都不会超过100。相应地,这个Segment背后的存储引擎(HBase)为了存储这个Segment,也不会使用小于两个或超过100个的分区。我们还调整了默认的kylin.hbase.region.cut,这样50GB的Segment基本上会被分配到50个分区,相比默认设置,我们的Cuboid可能最多会获得5倍的并发量。
检查Cube大小
把光标移到该Cube的Cube Size列时,Web GUI会提示Cube的源数据大小,以及当前Cube的大小除以源数据大小的比例,称为膨胀率(Expansion Rate)。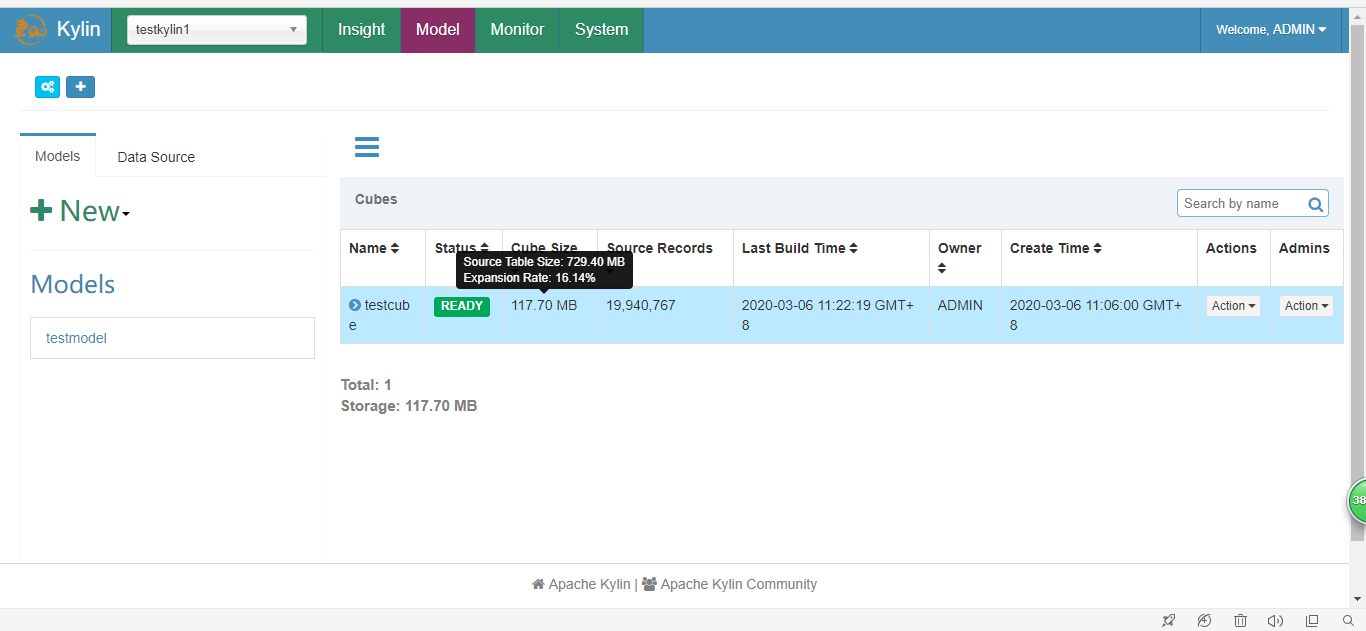 一般来说,Cube的膨胀率应该在0%~1000%之间,如果一个Cube的膨胀率超过1000%,那么Cube管理员应当开始挖掘其中的原因。通常,膨胀率高有以下几个方面的原因。
一般来说,Cube的膨胀率应该在0%~1000%之间,如果一个Cube的膨胀率超过1000%,那么Cube管理员应当开始挖掘其中的原因。通常,膨胀率高有以下几个方面的原因。
1)Cube中的维度数量较多,且没有进行很好的Cuboid剪枝优化,导致Cuboid数量极多;
2)Cube中存在较高基数的维度,导致包含这类维度的每一个Cuboid占用的空间都很大,这些Cuboid累积造成整体Cube体积变大;
清理无用的HBASE Table
1.检查哪些资源可以清理,这一步不会删除任何东西./kylin.sh org.apache.kylin.tool.StorageCleanupJob --delete false2.加上“–-delete true”选项进行清理./kylin.sh org.apache.kylin.tool.StorageCleanupJob --delete true
四、报错点
- Error: Could not find or load main class org.apache.hadoop.hbase.util.GetJavaProperty

因为 Hbase 没有将它自身的依赖包添加到 classpath 路径所以才会导致找不到类的报错, 添加上就可以了。1.执行如下命令 (注意路径只作为参考, 不要复制粘贴)vim /usr/local/hbase/bin/hbase2.找到上图部分 , 将红框部分的内容追加上 (红框部分注意路径):/usr/local/hbase/lib/*
- Please set kylin.env.hdfs-working-dir in kylin.properties

看样子是在kylin.properties配置文件中获取不到某个值。我这里是获取不到kylin.env.hdfs-working-dir也可能是获取不到其他的值,即使在配置文件加上了这个值,也无济于事。后来我这里的解决办法是,版本问题,我下载的版本过于高,要求hadoop和hbase的版本要很高,导致kylin.sh里面的一些环境检测出了问题,重新去官网下载kylin,寻找符合自己环境的kylin即可。

若有收获,就点个赞吧
0 人点赞
