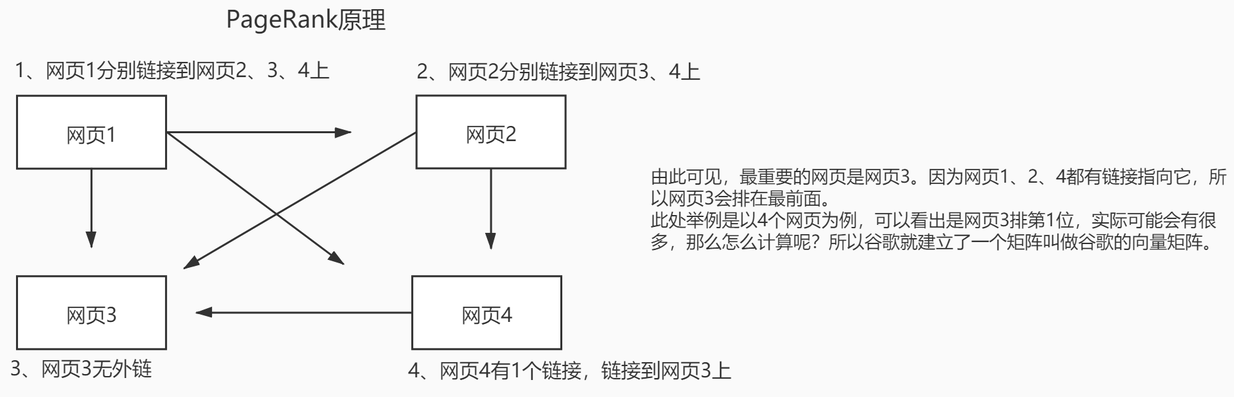
PageRank
PageRank,网页排名,又称网页级别、Google左侧排名或佩奇排名,是一种由根据网页之间相互的超链接计算的技术,而作为网页排名的要素之一,以Google公司创办人拉里·佩奇(Larry Page)之姓来命名。Google用它来体现网页的相关性和重要性,在搜索引擎优化操作中是经常被用来评估网页优化的成效因素之一。Google的创始人拉里·佩奇和谢尔盖·布林于1998年在斯坦福大学发明了这项技术。
如何计算?此处以4个网页为例:
向量矩阵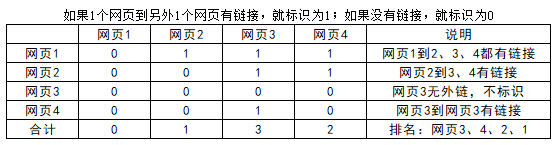 **
**
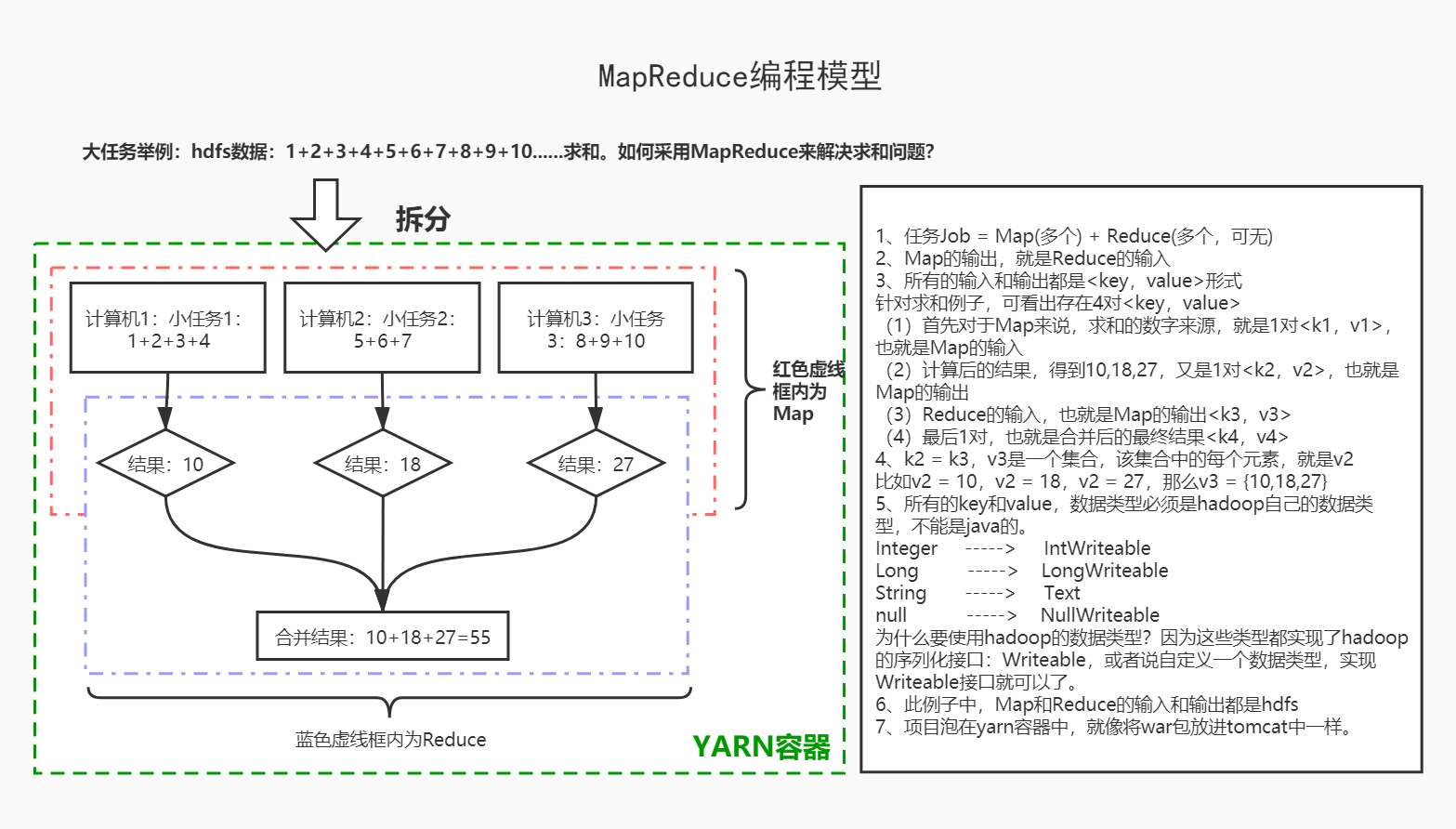
以4个网页为例,建立的是44的矩阵。如果爬虫每天爬1亿个网页,那矩阵就比较大了。如何计算大数据量的矩阵,谷歌提出一个计算模型MapReduce。*MapReduce的核心思想:先拆分,再合并。不管矩阵多大,都能够计算出来。也就是先将一个大矩阵,拆分成多个小矩阵,分散开进行计算,计算后将计算结果合并。
角色1:ResourceManager(资源管理器)
角色2:NodeManager(节点管理器:运行任务MapReduce)
① 从DataNode上获取数据,执行任务
MapReduce编程模型
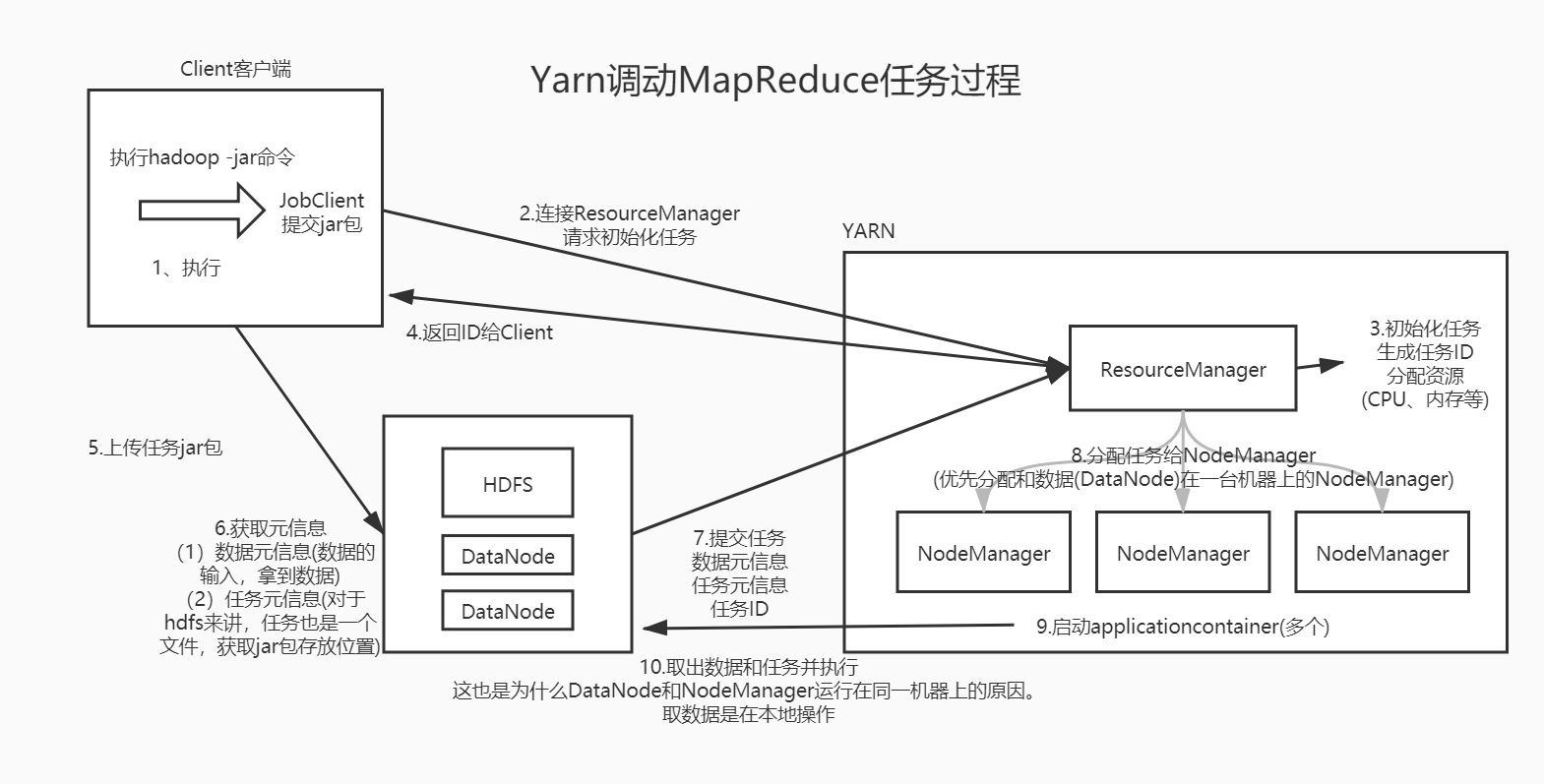
Yarn调用MapReduce任务过程
WordCount执行过程
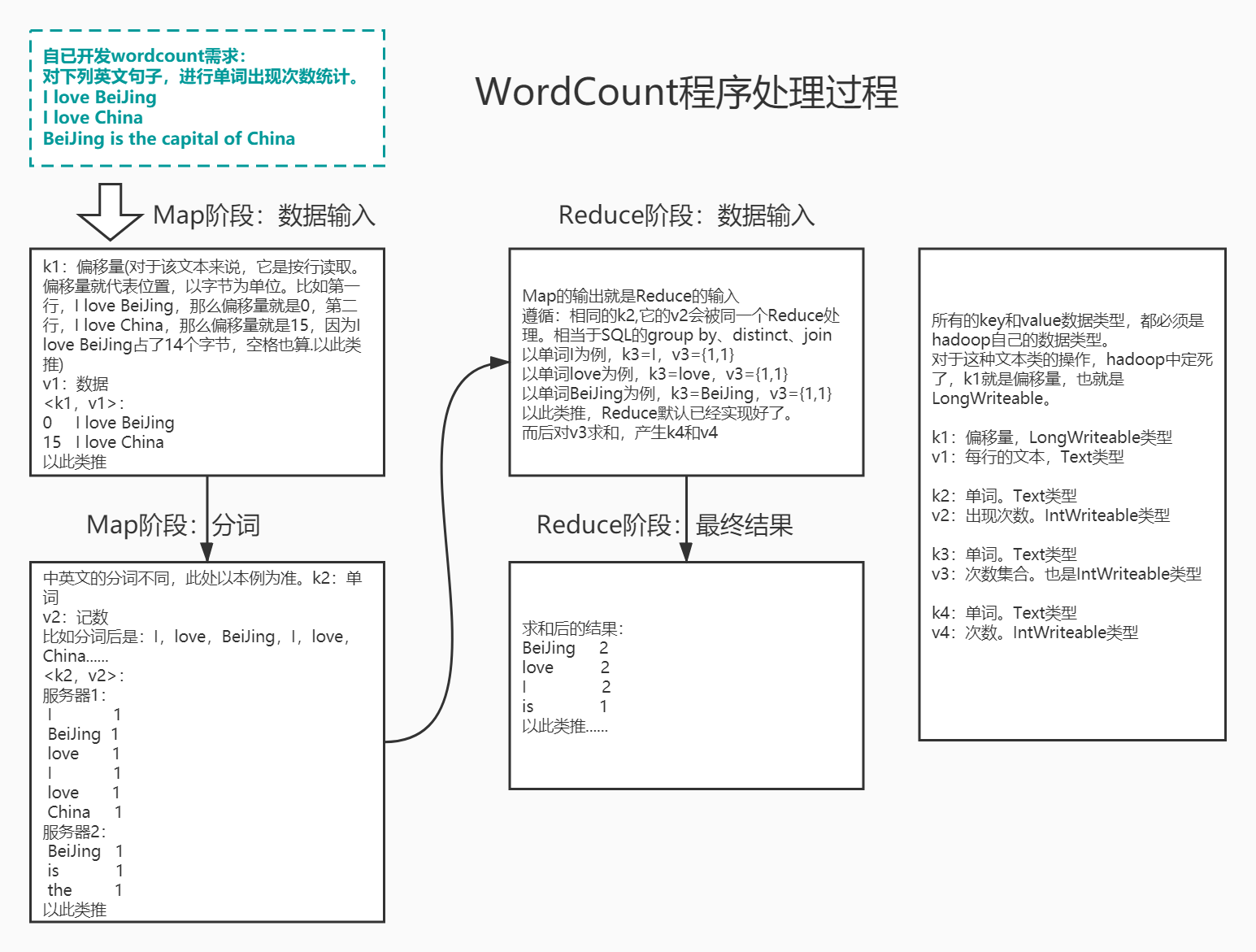
java开发WordCount程序
pom依赖
<!-- hadoop-client --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.3</version></dependency>
Map:WordCountMapper.java
package com.example.hbase.mapreduce;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;// k1:偏移量 v1:一行 k2:单词 v2:计数public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {/*** @param k1* @param v1* @param context - 代表Map的上下文* 上文:HDFS - 数据来源于hdfs* 下文:Reduce - 拆分数据后交给reduce计算* @throws IOException* @throws InterruptedException*/@Overrideprotected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException {String data = v1.toString();//取出I love BeiJing......String [] words = data.split(" ");//以空格进行分词for (String str : words) {// k2:单词 , v2:计数context.write(new Text(str),new IntWritable(1));}}}
Reduce:WordCountReduce.java
package com.example.hbase.mapreduce;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;// k3:单词 v3:计数集合 k4:单词 v4:结果public class WordCountReduce extends Reducer<Text, IntWritable,Text,IntWritable> {/*** @param k3* @param v3* @param context Reduce的上下文* 上文:Map* 下文:HDFS - 输出到HDFS* @throws IOException* @throws InterruptedException*/@Overrideprotected void reduce(Text k3, Iterable<IntWritable> v3, Context context) throws IOException, InterruptedException {int total = 0;//求和for (IntWritable v : v3){total += v.get();}// 单词 总数context.write(k3,new IntWritable(total));}}
任务主程序:WordCountMain.java
package com.example.hbase.mapreduce;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCountMain {//MapReduce主程序模板public static void main(String[] args) throws Exception{//创建配置,Configuration conf = new Configuration();//1、创建任务,指定任务的入口Job job = Job.getInstance(conf);job.setJarByClass(WordCountMain.class);//2、指定任务的Map,Map的输出job.setMapperClass(WordCountMapper.class);job.setMapOutputKeyClass(Text.class);//k2:单词job.setMapOutputValueClass(IntWritable.class);//v2:计数集合//3、指定任务的Reduce,Reduce的输出job.setReducerClass(WordCountReduce.class);job.setOutputKeyClass(Text.class);//k4:单词job.setOutputValueClass(IntWritable.class);//v4:计数结果//4、指定任务的输入和输出FileInputFormat.setInputPaths(job, new Path("/输入路径"));FileOutputFormat.setOutputPath(job, new Path("/输出路径"));//5、执行任务,true代表执行任务时,打印相关的日志job.waitForCompletion(true);}}
MapReduce特性
- 序列化:Writable,自定义数据类型。
- 排序:运行的结果,字符串字典序排序,数值升序。按照key2排序(也可以是对象),也可以自定义。
- 分区:(MapReduce默认分区、Spark的核心是RDD:由分区组成)根据key2和value2建立。MapReduce默认只有一个分区(一个输出的文件);如果有多个分区,就有多个输出文件。分区号必须从0开始,逐1累加,不能溢出(假设3个分区,就不可以出现分配到第4个分区的情况)。
- 合并:Combiner是一个特殊的Reducer。它是在Map端先执行一次Reduce,用于减少输出到Reduce端的数据,通过这样的方式提高性能。它是和Map运行在一起。但不是所有的情况都可以使用Combiner。
序列化:Writable,自定义数据类型。
package com.example.hbase.definitionwriteable;import org.apache.hadoop.io.Writable;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;/*** 自定义数据类型序列化和反序列化*/public class DataPojo implements Writable {private int empno;//员工号private String ename;//员工姓名private String job;//员工职位private int mgr;//对应老板工号private String hiredate;//入职日期private int sal;//月薪private int comm;//奖金private int deptno;//部门号/*** 序列化 - 不管怎么写,保证序列化和反序列化的顺序一样就可以* @param out* @throws IOException*/@Overridepublic void write(DataOutput out) throws IOException {//定义的字段类型,与之相对应即可 - 反序列化保证此顺序即可out.writeInt(this.empno);//顺序1out.writeUTF(this.ename);//顺序2out.writeUTF(this.job);//顺序3out.writeInt(this.mgr);//顺序4out.writeUTF(this.hiredate);//顺序5out.writeInt(this.sal);//顺序6out.writeInt(this.comm);//顺序7out.writeInt(this.deptno);//顺序8}/*** 反序列化 - 不管怎么写,保证序列化和反序列化的顺序一样就可以* @param input* @throws IOException*/@Overridepublic void readFields(DataInput input) throws IOException {//保证与序列化顺序一致即可this.empno = input.readInt();//顺序1this.ename = input.readUTF();//顺序2this.job = input.readUTF();//顺序3this.mgr = input.readInt();//顺序4this.hiredate = input.readUTF();//顺序5this.sal = input.readInt();//顺序6this.comm = input.readInt();//顺序7this.deptno = input.readInt();//顺序8}public int getEmpno() {return empno;}public void setEmpno(int empno) {this.empno = empno;}public String getEname() {return ename;}public void setEname(String ename) {this.ename = ename;}public String getJob() {return job;}public void setJob(String job) {this.job = job;}public int getMgr() {return mgr;}public void setMgr(int mgr) {this.mgr = mgr;}public String getHiredate() {return hiredate;}public void setHiredate(String hiredate) {this.hiredate = hiredate;}public int getSal() {return sal;}public void setSal(int sal) {this.sal = sal;}public int getComm() {return comm;}public void setComm(int comm) {this.comm = comm;}public int getDeptno() {return deptno;}public void setDeptno(int deptno) {this.deptno = deptno;}}
自定义数据类型使用
package com.example.hbase.definitionwriteable;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;// k1:偏移量 v1:一行 k2:员工号 v2:员工实体类public class EmpMapper extends Mapper<LongWritable, Text, IntWritable, DataPojo> {@Overrideprotected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException {//将数据一行一行读出来//数据格式csv文件:7654,zhangsan,salesman,7698,1981/9/28,1250,1400,30DataPojo dt = new DataPojo();//解析数据并赋值String data = v1.toString();String [] words = data.split(",");dt.setEmpno(Integer.parseInt(words[0]));//赋值省略......// k2:员工号 v2:员工实体类context.write(new IntWritable(dt.getEmpno()),dt);}}
自定义排序规则
package com.example.hbase.definitionwriteable;import org.apache.hadoop.io.Text;/*** 针对字符串类型 自定义排序规则 Text.Comparator* 如果是数值,IntWritable.Comparator*/public class MyTextComparator extends Text.Comparator {@Overridepublic int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {//字符串默认字典序,在super前加一个负号,就变为了字典序倒序return -super.compare(b1, s1, l1, b2, s2, l2);}}
使用自定义排序规则(在Map输出Reduce输入之间加入)
package com.example.hbase.mapreduce;import com.example.hbase.definitionwriteable.MyTextComparator;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCountMain {//MapReduce主程序模板public static void main(String[] args) throws Exception{//创建配置,Configuration conf = new Configuration();//1、创建任务,指定任务的入口Job job = Job.getInstance(conf);job.setJarByClass(WordCountMain.class);//2、指定任务的Map,Map的输出job.setMapperClass(WordCountMapper.class);job.setMapOutputKeyClass(Text.class);//k2:单词job.setMapOutputValueClass(IntWritable.class);//v2:计数集合//***************此处指定自定义排序规则*****************job.setSortComparatorClass(MyTextComparator.class);//3、指定任务的Reduce,Reduce的输出job.setReducerClass(WordCountReduce.class);job.setOutputKeyClass(Text.class);//k4:单词job.setOutputValueClass(IntWritable.class);//v4:计数结果//4、指定任务的输入和输出FileInputFormat.setInputPaths(job, new Path("/输入路径"));FileOutputFormat.setOutputPath(job, new Path("/输出路径"));//5、执行任务,true代表执行任务时,打印相关的日志job.waitForCompletion(true);}}
什么是分区(Partitioner)
要求将统计结果按照条件输出到不同文件中(分区),比如:将统计结果按照手机归属地不同省份输出到不同文件中。(分区)。默认的分区是根据key的hashCode对ReduceTasks个数取模得到的。用户没法控制哪个key存储到哪个分区。
自定义分区规则
package com.example.hbase.definitionwriteable;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.mapreduce.Partitioner;/*** 自定义分区规则*/// k2 v2public class MyPartitioner extends Partitioner<IntWritable,DataPojo> {/**** @param k2* @param v2* @param numTask 分区的个数* @return*/@Overridepublic int getPartition(IntWritable k2, DataPojo v2, int numTask) {//取出部门号int deptno = v2.getDeptno();//假设分区个数为3,分区不能溢出,采用取余的方式防止分区号溢出if(deptno == 10){return 1%numTask;} else if(deptno == 20){return 2%numTask;} else {return 3%numTask;}}}
使用自定义分区规则(在Map输出Reduce输入之间加入)
package com.example.hbase.mapreduce;
import com.example.hbase.definitionwriteable.MyPartitioner;
import com.example.hbase.definitionwriteable.MyTextComparator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountMain {
//MapReduce主程序模板
public static void main(String[] args) throws Exception{
//创建配置,
Configuration conf = new Configuration();
//1、创建任务,指定任务的入口
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountMain.class);
//2、指定任务的Map,Map的输出
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);//k2:单词
job.setMapOutputValueClass(IntWritable.class);//v2:计数集合
//此处指定自定义排序规则
job.setSortComparatorClass(MyTextComparator.class);
//****************指定自定义分区*******************
job.setPartitionerClass(MyPartitioner.class);
job.setNumReduceTasks(3);//这个3会传递给MyPartitioner,参数就是numTask
//3、指定任务的Reduce,Reduce的输出
job.setReducerClass(WordCountReduce.class);
job.setOutputKeyClass(Text.class);//k4:单词
job.setOutputValueClass(IntWritable.class);//v4:计数结果
//4、指定任务的输入和输出
FileInputFormat.setInputPaths(job, new Path("/输入路径"));
FileOutputFormat.setOutputPath(job, new Path("/输出路径"));
//5、执行任务,true代表执行任务时,打印相关的日志
job.waitForCompletion(true);
}
}
什么是Combiner
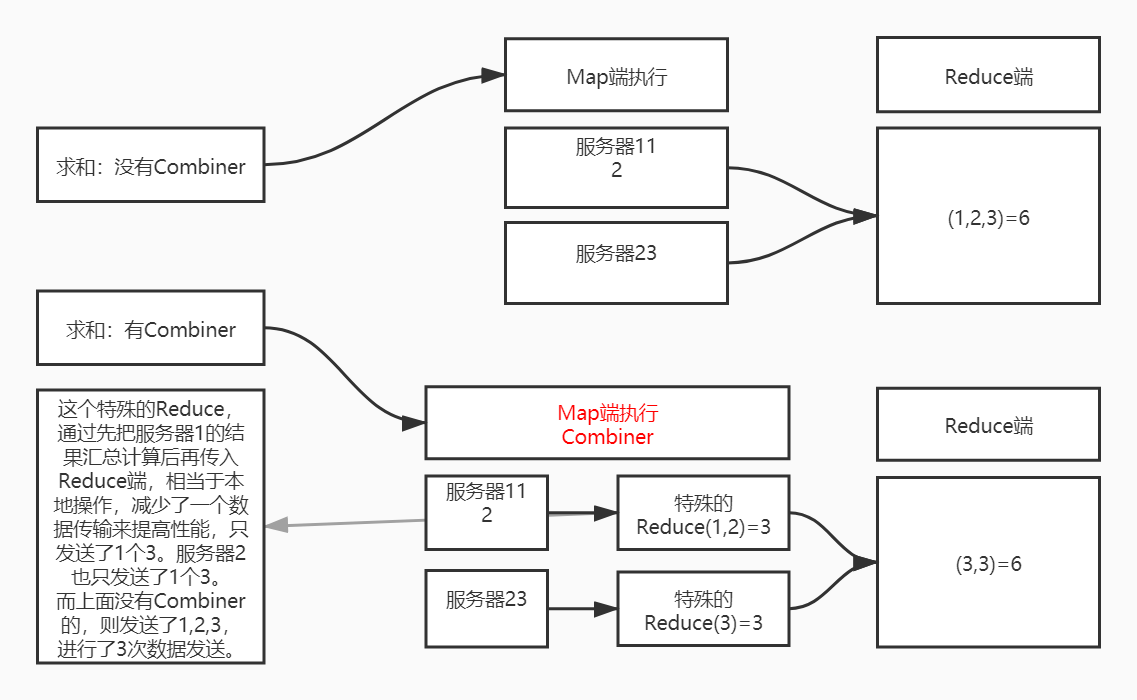
使用Combiner(在Map输出Reduce输入之间加入)
package com.example.hbase.mapreduce;
import com.example.hbase.definitionwriteable.MyPartitioner;
import com.example.hbase.definitionwriteable.MyTextComparator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountMain {
//MapReduce主程序模板
public static void main(String[] args) throws Exception{
//创建配置,
Configuration conf = new Configuration();
//1、创建任务,指定任务的入口
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountMain.class);
//2、指定任务的Map,Map的输出
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);//k2:单词
job.setMapOutputValueClass(IntWritable.class);//v2:计数集合
//引入Combiner,此计数程序的Reduce和Combiner中的Reduce一样,可直接使用WordCountReduce
//但也可以和Reduce端的不一样,不一样的时候就需要单独写一个作为Combiner
//当数据量巨大时,有没有这句话,性能是不一样的,数据量大时效率明显提升
job.setCombinerClass(WordCountReduce.class);
//3、指定任务的Reduce,Reduce的输出
job.setReducerClass(WordCountReduce.class);
job.setOutputKeyClass(Text.class);//k4:单词
job.setOutputValueClass(IntWritable.class);//v4:计数结果
//4、指定任务的输入和输出
FileInputFormat.setInputPaths(job, new Path("/输入路径"));
FileOutputFormat.setOutputPath(job, new Path("/输出路径"));
//5、执行任务,true代表执行任务时,打印相关的日志
job.waitForCompletion(true);
}
}
MapReduce工作流程
- 输入文件分片,每一片都由一个MapTask来处理
- Map输出的中间结果会先放在内存缓冲区中,这个缓冲区的大小默认是100M,当缓冲区中的内容达到80%时(80M)会将缓冲区的内容写到磁盘上。也就是说,一个map会输出一个或者多个这样的文件,如果一个map输出的全部内容没有超过限制,那么最终也会发生这个写磁盘的操作,只不过是写几次的问题。
- 从缓冲区写到磁盘的时候,会进行分区并排序,分区指的是某个key应该进入到哪个分区,同一分区中的key会进行排序,如果定义了Combiner的话,也会进行combine操作
- 如果一个map产生的中间结果存放到多个文件,那么这些文件最终会合并成一个文件,这个合并过程不会改变分区数量,只会减少文件数量。例如,假设分了3个区,4个文件,那么最终会合并成1个文件,3个区
- 以上只是一个map的输出,接下来进入reduce阶段
- 每个reducer对应一个ReduceTask,在真正开始reduce之前,先要从分区中抓取数据
- 相同的分区的数据会进入同一个reduce。这一步中会从所有map输出中抓取某一分区的数据,在抓取的过程中伴随着排序、合并。
- reduce输出
shuffle机制
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。过程分为两个阶段,Map端的shuffle阶段和Reduce端的shuffle阶段。MapReduce确保每个reducer的输入都是按键排序的。系统执行排序、将map输出作为输入传给reducer的过程称为Shuffle。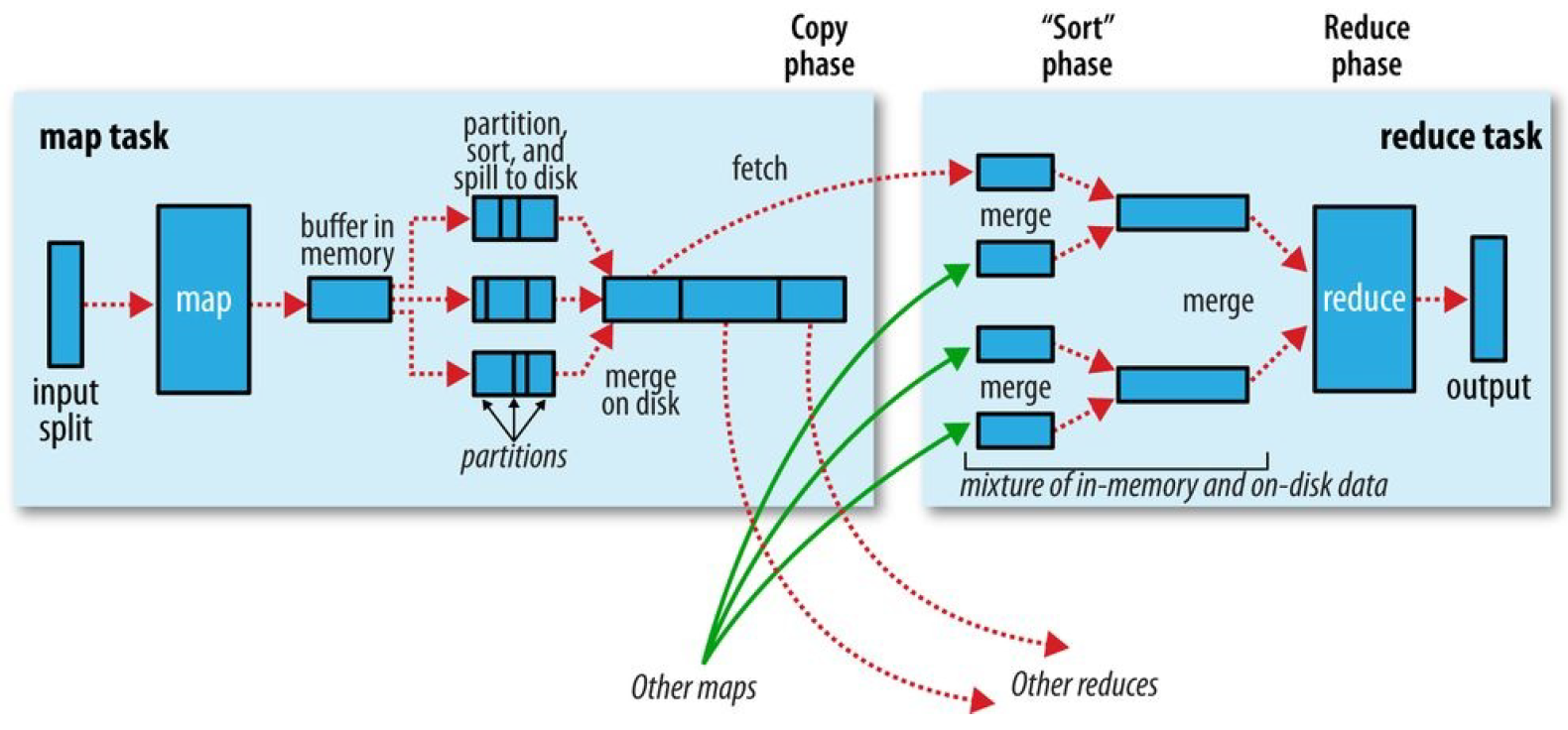
map端
- map数据分片:把输入数据源进行分片,根据分片来决定有多少个map,每个map任务都有一个环形内存缓冲区用于存储任务输出,默认情况下缓冲区大小为100MB,可通过mapreduce.task.io.sort.mb来调整。
- map排序:当map缓冲区大小达到阈值时(mapreduce.map.sort.spill.percent),就会将内存的数据溢写到磁盘,根据reducer的来划分成相应的partition,在内存中按键值进行排序,如果有combiner函数,在排序后就会应用,排序后写入分区磁盘文件中。溢写的过程中,map会阻塞直到写磁盘过程完成。每次内存缓冲区到达溢出阈值,就会新建一个溢出文件件,在map写完最后一个输出记录之后,会有几个溢出文件,在任务完成之前溢出文件会被合并成一个已分区且已经排序的输出文件。mapreduce.task.io.sort.factor控制着一次最多能合并多少溜,默认10。mapreduce.map.output.compress进行压缩,提高写磁盘速度。
reduce端
1.reduce复制:reducer通过http得到输出文件的分区,用于文件分区的工作线程数量由任务的mapreduce.shuffle.max.threads属性控制。每个map任务的完成时间不同,在每个任务完成时,reduce任务就开始复制其输出,这就是reduce任务的复制阶段,reduce的复制线程数量mapreduce.reduce.shuffle.parallelcopies决定。
复制详解:如果map输出很小,会被复制到reduce任务JVM的内存,否则输出被复制到磁盘。如果内存缓冲区达到阈值大小(mapreduce.reduce.shuffle.merge.percent)或达到map输出阈值(mapreduce.reduce.merge.inmem.threshold),则合并溢出写到磁盘中,如果指定combiner,则在合并期间运行它。随着磁盘上副本增多,后台线程会将他们合并为更大的,排序的文件。
2.reduce合并排序:这个阶段合并map输出,维持其顺序排序,这是循环进行的,如果有50个map输出,合并因子是10(mapreduce.task.io.sort.factor),合并将进行5次,最后有5个中间文件。
3.reduce:直接把数据输入reduce函数,从而省略了一次磁盘的往返行程。

若有收获,就点个赞吧
0 人点赞
