Kylin概述
Apache Kylin是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。Apache Kylin也是中国人主导的、唯一的Apache顶级开源项目,在开源社区有世界级的影响力。
Kylin特点
- Kylin 的主要特点包括支持 SQL 接口、支持超大规模数据集、亚秒级响应、可伸缩性、高吞吐率、BI 工具集成等
- 可扩展超快 OLAP(On-Line Analytical Processing:联机分析处理过程) 引擎 Kylin是为减少在 Hadoop/Spark 上百亿规模数据查询延迟而设计
- Hadoop ANSI SQL 接口 Kylin为Hadoop提供标准SQL支持大部分查询功能
- 交互式查询能力 通过 Kylin,用户可以与 Hadoop 数据进行亚秒级交互,在同样的数据集上提供比Hive 更好的性能多维立方体(MOLAP Cube) 用户能够在 Kylin 里为百亿以上数据集定义数据模型并构建立方体
- 与 BI (商业智能Business Intelligence:商业智能作为一个工具,是用来处理企业中现有数据,并将其转换成知识、分析和结论,辅助业务或者决策者做出正确且明智的决定,帮助企业更好地利用数据提高决策质量的技术,包含了从数据仓库到分析系统等。)工具无缝整合 Kylin 提供与 BI 工具的整合能力,如 Tableau,PowerBI/Excel,MSTR,QlikSense,Hue 和 SuperSet
架构
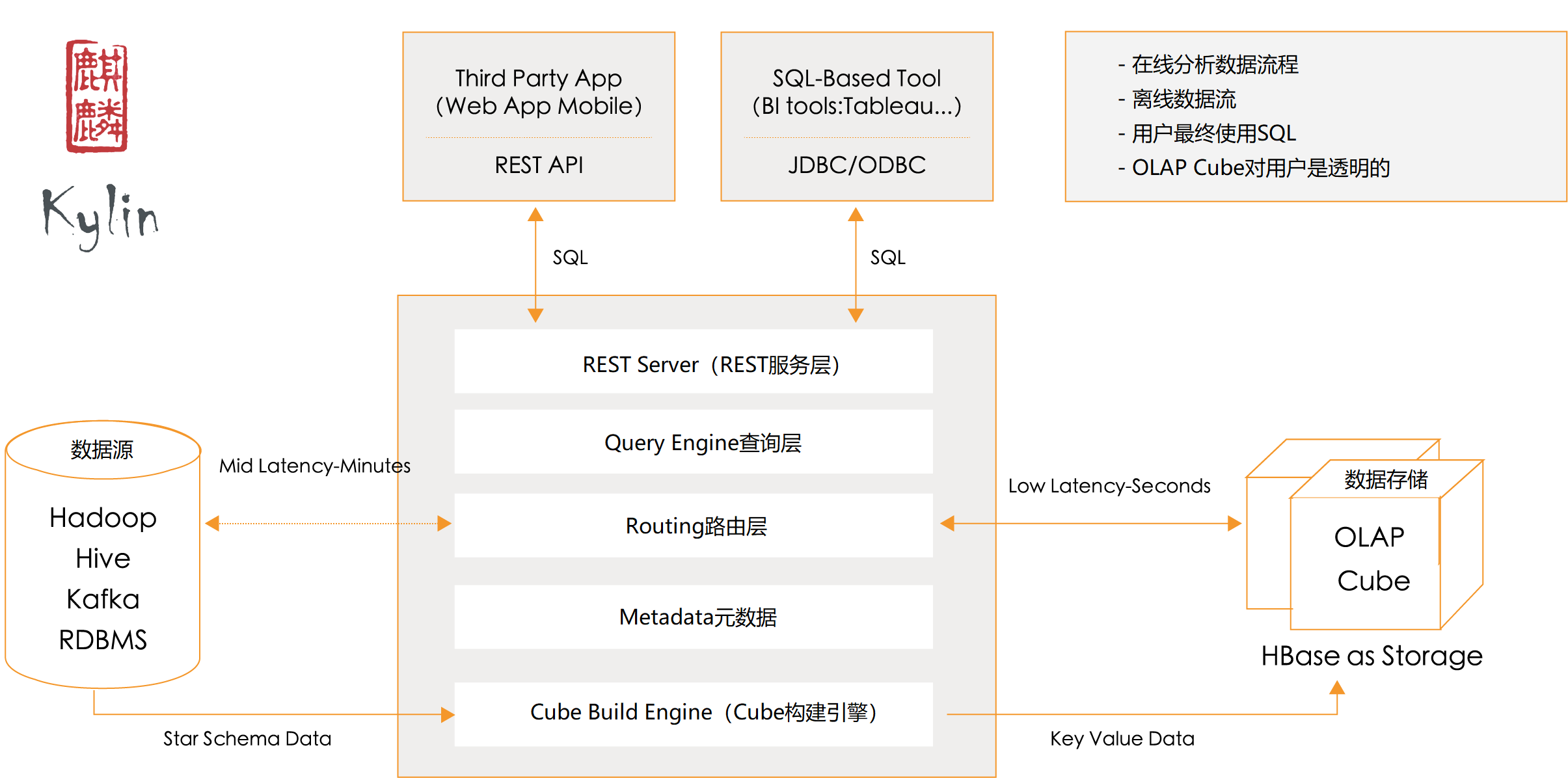
1. 数据源
我们首先来看看离线构建的部分。从上图可以看出, 数据源在左侧,保存着待分析的用户数据。数据源可以是:Hadoop, Hive, Kafka, RDBMS。但是 Hive 是用的最多的一种数据源。
2. Cube 构建引擎
Cube 构建引擎根据元数据的定义, 从数据源抽取数据, 并构建 Cube.
这套引擎的设计目的在于处理所有离线任务,其中包括 shell 脚本、Java API 以及 Map Reduce 任务等等。
任务引擎对 Kylin 当中的全部任务加以管理与协调,从而确保每一项任务都能得到切实执行并解决其间出现的故障。
3. 元数据管理工具(Metadata)
Kylin 是一款元数据驱动型应用程序。元数据管理工具是一大关键性组件,用于对保存在 Kylin 当中的所有元数据进行管理,其中包括最为重要的 Cube 元数据。
其它全部组件的正常运作都需以元数据管理工具为基础。 Kylin 的元数据存储在 Hbase中。
4. REST Server
REST Server是一套面向应用程序开发的入口点,旨在实现针对Kylin平台的应用开发工作。 此类应用程序可以提供查询、获取结果、触发cube构建任务、获取元数据以及获取用户权限等等。另外可以通过Restful接口实现SQL查询。
5. 查询引擎(Query Engine)
当 Cube 准备就绪后,查询引擎就能够获取并解析用户查询。它随后会与系统中的其它组件进行交互,从而向用户返回对应的结果。
6. Routing(路由选择)
负责将解析的 SQL 生成的执行计划转换成 Cube 缓存的查询。Cube 是通过预计算缓存在 Hbase 中,这部分查询可以在秒级甚至毫秒级完成。而且还有一些操作查询原始数据(存储在 Hadoop 的 hdfs 中通过 hive 查询)。这部分查询延迟较高。
7. 任务引擎(Cube Build Engine)
这套引擎的设计目的在于处理所有离线任务,其中包括shell脚本、Java API以及Map Reduce任务等等。任务引擎对Kylin当中的全部任务加以管理与协调,从而确保每一项任务都能得到切实执行并解决其间出现的故障。
Kylin 工作原理
Apache Kylin 的工作原理本质上是 MOLAP(Multidimensional Online Analytical Processing)Cube,也就是多维立方体分析。这是数据分析中相当经典的理论,在关系数据库年代就已经有了广泛的应用.在说明 MOLAP Cube 之前需要先介绍一下维度(Dimension)和度量(Measure)这两个概念。
维度(Dimension)和度量(Measure)简介
维度
简单来讲,维度就是观察数据的角度。它通常是数据记录的一个属性,例如时间、地点等。比如电商的销售数据,可以从时间的维度来观察, 也可以进一步细化,从时间和地区的维度来观察。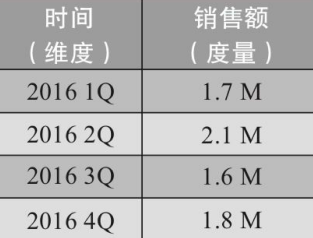
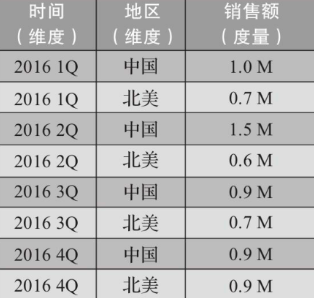
度量
度量就是被聚合后的统计值,也是聚合运算的结果,如图中的销售额,抑或是销售商品的总件数。
度量是基于数据所计算出来的考量值;它通常是一个数值,如总销售额、不同的用户数等。
在一个 SQL 查询中,Group By 的属性通常就是维度,而所计算的值则是度量
Cube 和 Cuboid
有了维度和度量,一个数据表或数据模型上的所有字段就可以分类了,它们要么是维度,要么是度量(可以被聚合)。于是就有了根据维度和度量做预计算的Cube理论。
给定一个数据模型,我们可以对其上的所有维度进行组合。对于N个维度来说,组合的所有可能性共有 2^n 种。
对于每一种维度的组合,将度量做聚合运算,然后将运算的结果保存为一个物化视图,称为Cuboid。
所有维度组合的Cuboid作为一个整体,被称为Cube。
所以简单来说,一个 Cube 就是许多按维度聚合的物化视图的集合。
下面来列举一个具体的例子。
假定有一个电商的销售数据集,其中维度包括:
- 时间(Time)
- 商品(Item)
- 地点(Location)
- 供应商(Supplier)
度量:
- 销售额(GMV)。
那么所有维度的组合就有2^4=16种
- 一维度(1D)的组合有[Time]、[Item]、[Location]、[Supplier]4种;
- 二维度(2D)的组合有[Time,Item]、[Time,Location]、[Time、Supplier]、 [Item,Location]、[Item,Supplier]、[Location,Supplier]6种;
- 三维度(3D)的组合也有4种;
- 最后零维度(0D)和四维度(4D)的组合各有1种
总共 16种。
计算 Cuboid,即按维度来聚合销售额。如果用SQL语句来表达计算 Cuboid[Time,Loca-tion],那么SQL语句如下: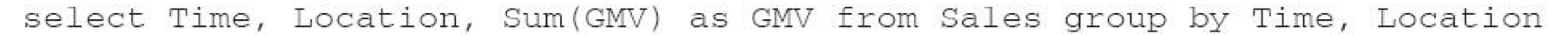
将计算的结果保存为物化视图,所有
Cuboid物化视图的总称就是Cube。 每一种维度组合就是一个Cuboid,16个Cuboid整体就是一个Cube。
工作原理
Apache Kylin 的工作原理就是对数据模型做Cube预计算,并利用计算的结果加速查询,具体工作过程如下。
- 指定数据模型, 定义维度和度量。
- 预计算Cube, 计算所有Cuboid并保存为物化视图。
- 执行查询时, 读取Cuboid运算, 产生查询结果。
由于 Kylin 的查询过程不会扫描原始记录,而是通过预计算预先完成表的关联、聚合等复杂运算,并利用预计算的结果来执行查询,因此相比非预计算的查询技术,其速度一般要快一到两个数量级,并且这点在超大的数据集上优势更明显。当数据集达到千亿乃至万亿级别时,Kylin的速度甚至可以超越其他非预计算技术 1000 倍以上。
总结:Kylin从Hive拿到数**据,进行多维度的预计算处理,预计算的过程采用MapReduce来做,也可以选择Spark作为计算引擎。一次build的结果(Cube),我们称为一个Segment。构建过程中会涉及多个Cuboid的创建,具体创建过程由kylin.cube.algorithm参数决定,参数值可选 auto,layer 和 inmem, 默认值为 auto。最后**将结果输出到hbase,接下来获取数据时,直接通过SQL从hbase读取数据。它的核心就是与计算。这是一种典型的空间换时间的方式。
核心算法
1. 逐层构建算法(layer)

就是一层一层的计算。先拿到数据,先对所有维度进行计算,每个层级的计算(除了第一层,它是从原始数据聚合而来),是基于它上一层级的结果来计算的。比如,[Group by A, B]的结果,可以基于[Group by A, B, C]的结果,通过去掉C后聚合得来的;这样可以减少重复计算;当 0维度Cuboid计算出来的时候,整个Cube的计算也就完成了。
每一轮的计算都是一个MapReduce任务,且串行执行;一个N维的Cube,至少需要N+1次MapReduce Job。
算法优点:
- 此算法充分利用了MapReduce的能力,处理了中间复杂的排序和洗牌工作,故而算法代码清晰简单,易于维护;
- 受益于Hadoop的日趋成熟,此算法对集群要求低,运行稳定;在内部维护Kylin的过程中,很少遇到在这几步出错的情况;即便是在Hadoop集群比较繁忙的时候,任务也能完成。
算法缺点:
- 当Cube有比较多维度的时候,所需要的MapReduce任务也相应增加;由于Hadoop的任务调度需要耗费额外资源,特别是集群较庞大的时候,反复递交任务造成的额外开销会相当可观;
- 此算法会对Hadoop MapReduce输出较多数据; 虽然已经使用了Combiner来减少从Mapper端到Reducer端的数据传输,所有数据依然需要通过Hadoop MapReduce来排序和组合才能被聚合,无形之中增加了集群的压力;
- 对HDFS的读写操作较多:由于每一层计算的输出会用做下一层计算的输入,这些Key-Value需要写到HDFS上;当所有计算都完成后,Kylin还需要额外的一轮任务将这些文件转成HBase的HFile格式,以导入到HBase中去;
总体而言,该算法的效率较低,尤其是当Cube维度数较大的时候。
快速构建算法(inmem)
也被称作“逐段”(By Segment) 或“逐块”(By Split) 算法,从1.5.x开始引入该算法,利用Mapper端计算先完成大部分聚合,再将聚合后的结果交给Reducer,从而降低对网络瓶颈的压力。该算法的主要思想是,对Mapper所分配的数据块,将它计算成一个完整的小Cube 段(包含所有Cuboid);每个Mapper将计算完的Cube段输出给Reducer做合并,生成大Cube,也就是最终结果。(假设两个字段,age和sex,那么在Map阶段,依次传递age聚合、sex聚合、age和sex的聚合,在Reduce,对相同的key(age、sex……)进行合并完成各个维度的聚合)。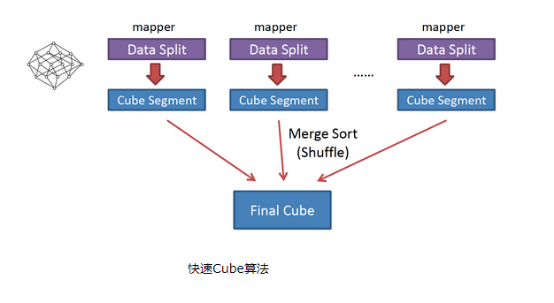
与旧算法相比,快速算法主要有两点不同:
- Mapper会利用内存做预聚合,算出所有组合;Mapper输出的每个Key都是不同的,这样会减少输出到Hadoop MapReduce的数据量;
- 一轮MapReduce便会完成所有层次的计算,减少Hadoop任务的调配。

若有收获,就点个赞吧
0 人点赞
