评估假设<br />一旦我们通过以下方式对预测中的错误进行了一些故障排除:<br />获取更多训练示例<br />尝试更小的功能集<br />尝试附加功能<br />尝试多项式特征<br />增加或减少 λ<br />我们可以继续评估我们的新假设。<br />假设对于训练示例可能具有较低的误差,但仍然不准确(因为过度拟合)。 因此,为了评估一个假设,给定一个训练示例数据集,我们可以将数据分成两组:训练集和测试集。 通常,训练集包含 70% 的数据,测试集包含剩余的 30%。<br />使用这两组的新程序则是:<br />使用训练集学习和最小化<br />计算测试集误差<br />**The test set error**<br />1、对于线性回归:<br />2、对于分类 ~ 错误分类错误(又名 0/1 错误分类错误):<br />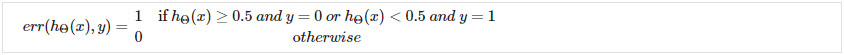<br />这给了我们一个基于错误分类的二进制 0 或 1 错误结果。 测试集的平均测试误差为:<br /><br />这给了我们错误分类的测试数据的比例。
模型选择和训练/验证/测试集
仅仅因为学习算法非常适合训练集,并不意味着它是一个好的假设。 它可能会过度拟合,因此您对测试集的预测会很差。 在训练参数的数据集上测量的假设误差将低于任何其他数据集的误差。
给定许多具有不同多项式次数的模型,我们可以使用系统方法来确定“最佳”函数。 为了选择假设的模型,您可以测试多项式的每个次数并查看错误结果。
将我们的数据集分解为三组的一种方法是:
训练集:60%
交叉验证集:20%
测试集:20%
我们现在可以使用以下方法为三个不同的集合计算三个单独的误差值:
1、使用每个多项式次数的训练集优化 Θ 中的参数。
2、使用交叉验证集找出误差最小的多项式次数 d。
3、使用带有 的测试集估计泛化误差,(d = 来自具有较低误差的多项式的 theta);
的测试集估计泛化误差,(d = 来自具有较低误差的多项式的 theta);
这样,多项式 d 的次数还没有使用测试集进行训练。

若有收获,就点个赞吧
0 人点赞
