浏览器中的文件传输过程
如何保证页面文件能被完整送到浏览器?
在传输数据时,数据会经过应用层、传输层、网络层、数据链路层等包装数据(给数据加相应的头),最后通过物理层传输比特流到达目的地。
整个过程就像快递公司,装好货物 -> 填写收货人、寄货人地址 -> 选好寄送路线 -> 出发 -> 收货人拿到货物 -> 取货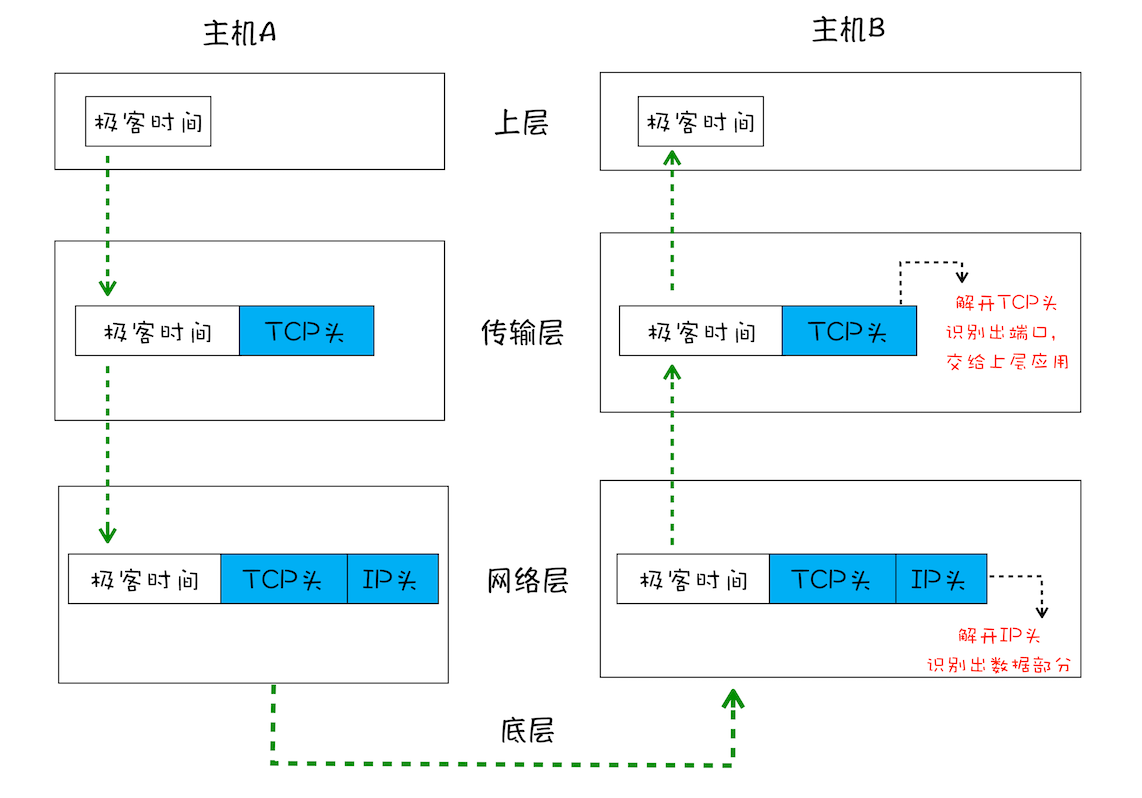
IP(网络层): 负责把数据包送达目的主机
既然要送出去,那就要知道送给谁;So IP 头中必然存放源 IP 地址与目标 IP 地址;除此之外,还存在一些版本、生存时间信息;
UDP(传输层): 把数据包送达应用程序
UDP 存放端口号,到达指定电脑后,根据端口号把数据包发给对应的程序;
UDP 可以校验数据包是否正确,但对错误的只丢弃,不重发,所以速度快;
适用领域:在线视频、互动游戏
TCP(传输层): 把数据包完整送达应用程序
TCP 特点:
- 对于丢包情况,提供重传机制
- 引入数据包排序机制,可以把乱序的数据包组成完整文件
TCP 生命周期:
建立连接(3 次握手) -> 传输数据 -> 断开连接(4 次挥手)
HTTP 和 TCP 的关系
在 TCP/IP 五层结构中,http 协议属于应用层,应用层主要是来为操作系统和应用程序提供网络服务。而 TCP 属于传输层,传输层用来处理全部信息和提供可靠的数据传输服务。
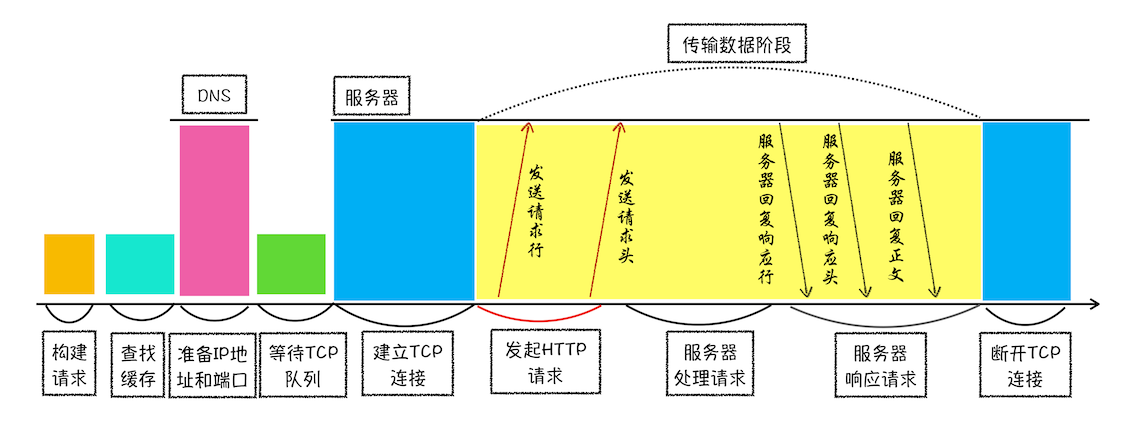
浏览器发起 HTTP 请求流程
- 构建请求:构建请求行信息 GET /index.html HTTP1.1
- 查找缓存:若缓存中又副本,拦截请求,返回副本资源
- 准备 IP 地址和端口:通过 DNS 拿到域名对应的 IP,顺便缓存在本地
- 等待 TCP 队列:Chorme 机制,每次最多建立 6 个 TCP 连接,多出来的要等
- 建立 TCP 连接:3 次握手
- 发送 HTTP 请求:发送数据,带上浏览器基础信息(域名、cookie、os、内核)
服务端处理 HTTP 请求流程
- 返回请求:响应头 + 行 + 体
- 断开连接:返回完数据,就要关闭;若加 connection: keep-alive 则不断开
- 重定向:301 + 响应头中有 Location
keep-alive
keep-alive:保持 TCP 连接可以省去下次请求时需要建立连接的时间,提升资源加载速度;
- 几个大厂除了百度,其余都没用 keep-alive, why?
Keep-Alive 会增加服务器负载,这就是某些共享主机提供商禁用它的原因。每个开放连接都消耗内存以及文件描述符(linux),在极端情况下(某些 Apache 配置),它可能具有从连接到进程的 1:1 映射。
https://stackoverflow.com/questions/3441075/pros-and-cons-of-keep-alive-from-web-server-side
欢迎补充…
开头问题
- 为什么很多站点第二次打开速度很快?
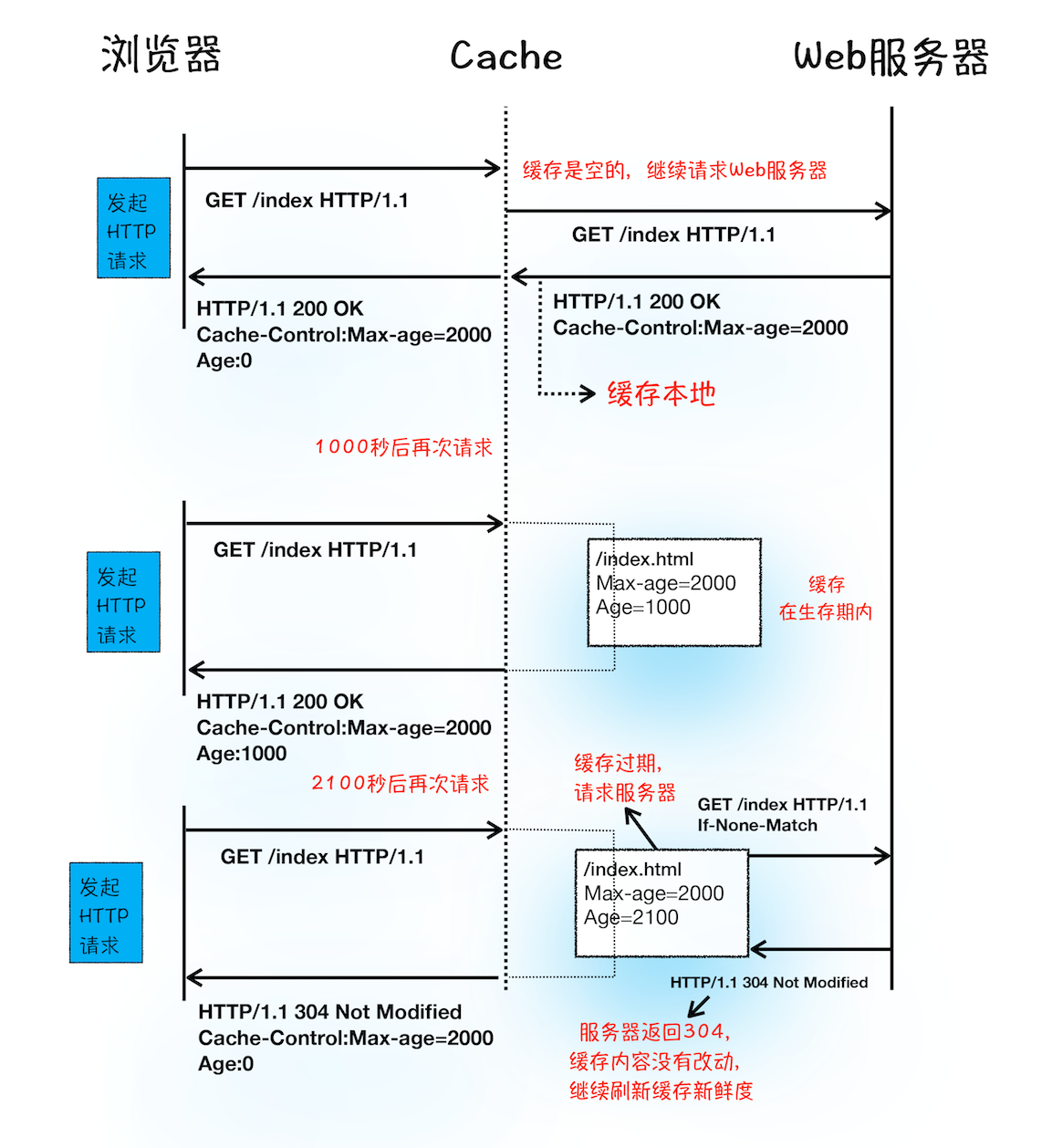
因为有缓存:DNS 缓存,页面资源缓存(强缓存与协商缓存) - 几种缓存字段
expires: 绝对时间(格林尼治时间),因服务器与浏览器端时间很容易不一致,故不常用;
max-age: 接上,于是就有了相对时间 max-age;
Etag/If-None-Match 和 Last-Modified/If-Modified-Since 都是协商缓存;
区别在于 Last-Modified 是根据时间,etag 是根据内容的 hash 值来判断是否用缓存;
Etag适合于经常不变的资源;
last-modified适合于经常改变的资源,比如图片等;
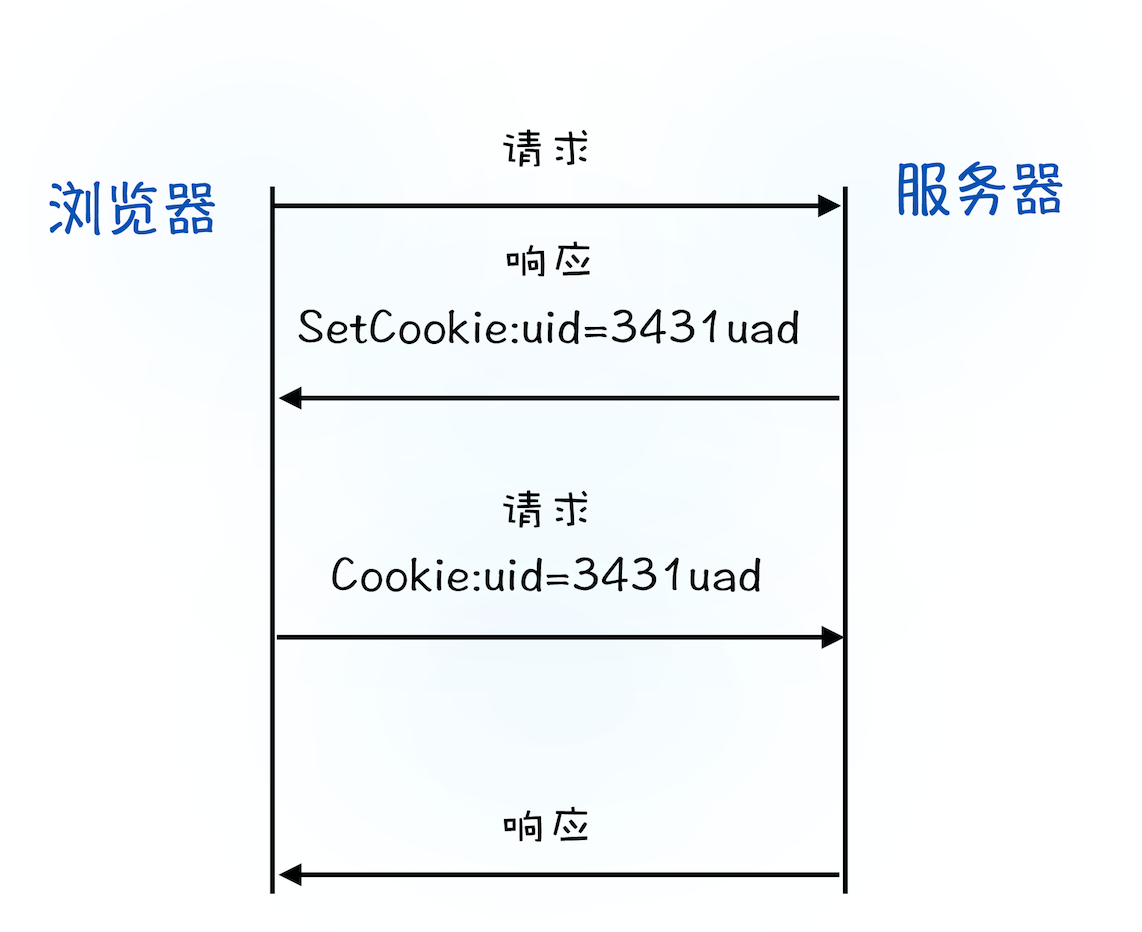
- 登录状态如何保持?
第一次登录时,reuqest 将数据传给服务端,reponse 中带上 set-cookie 头,浏览器读取后保存在本地,以后此域名发起请求时都带上;
思考题
- 如果一个页面的网络加载时间过久,如何分析卡在哪个阶段?
结合 network 面板分析,看哪部分请求耗时最长;
结合 performance 面板分析各个渲染阶段的耗时;
精选问答
- 浏览器同时打开多个标签,如果端口一样,数据怎么知道去哪个标签?
端口一样的,网络进程中知道每个 tcp 链接对应的标签是哪个,所以接收到数据后,会分发给对应的渲染进程。 - 浏览器何时开始渲染页面?数据包的顺序是如何处理的?
浏览器接收到 http 响应头的 content-type 类型时,开始准备渲染进程;响应体数据一旦到位便开始解析 DOM;
丢包与重传都是在 TCP 层解决的,http 保证数据是按照顺序接受的。(下层为上层提供服务。) - F5 与 ctrl + F5 区别?
F5 刷新走正常流程,该读缓存照样读缓存;
ctrl + F5 忽略缓存,直接发起网络请求

若有收获,就点个赞吧
0 人点赞
