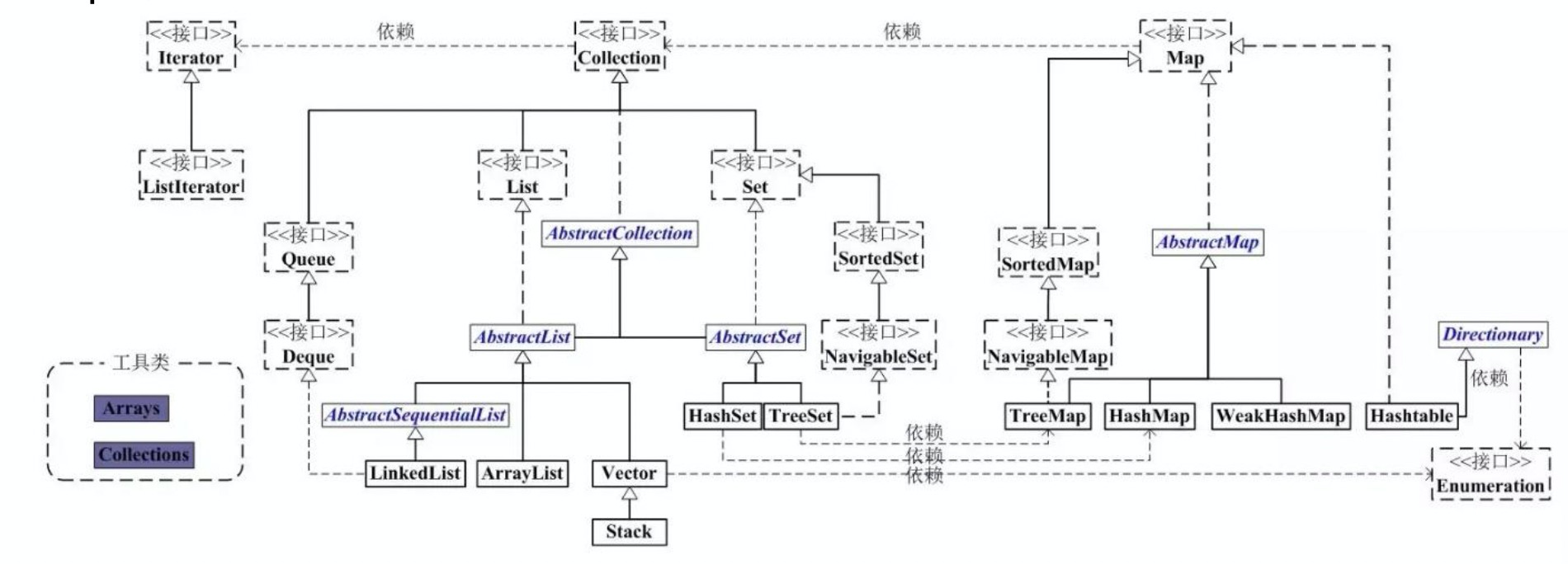
类图
集合类存放于 Java.util 包中,主要有 3 种:set(集)、list(列表包含 Queue)和 map(映射)。
Collection:Collection 是集合 List、Set、Queue 的最基本的接口。
Iterator:迭代器,可以通过迭代器遍历集合中的数据
- Map:是映射表的基础接口
ArrayList
ArrayList 的底层是数组队列,相当于动态数组。与 Java 中的数组相比,它的容量能动态增长。在添加大量元素前,应用程序可以使用ensureCapacity操作来增加 ArrayList 实例的容量。这可以减少递增式再分配的数量。
它继承于 AbstractList,实现了 List, RandomAccess, Cloneable, java.io.Serializable 这些接口。
在我们学数据结构的时候就知道了线性表的顺序存储,插入删除元素的时间复杂度为O(n),求表长以及增加元素,取第 i 元素的时间复杂度为O(1)ArrayList 继承了AbstractList,实现了List。它是一个数组队列,提供了相关的添加、删除、修改、遍历等功能。
ArrayList 实现了RandomAccess 接口, RandomAccess 是一个标志接口,表明实现这个这个接口的 List 集合是支持快速随机访问的。在 ArrayList 中,我们即可以通过元素的序号快速获取元素对象,这就是快速随机访问。
补充内容:RandomAccess接口
public interface RandomAccess {}
查看源码我们发现实际上 RandomAccess 接口中什么都没有定义。所以,在我看来 RandomAccess 接口不过是一个标识罢了。标识什么? 标识实现这个接口的类具有随机访问功能。
在 binarySearch()方法中,它要判断传入的list 是否 RamdomAccess 的实例,如果是,调用indexedBinarySearch()方法,如果不是,那么调用iteratorBinarySearch()方法
public static <T>int binarySearch(List<? extends Comparable<? super T>> list, T key) {if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD)return Collections.indexedBinarySearch(list, key);elsereturn Collections.iteratorBinarySearch(list, key);}
ArrayList 实现了 RandomAccess 接口, 而 LinkedList 没有实现。为什么呢?我觉得还是和底层数据结构有 关!ArrayList 底层是数组,而 LinkedList 底层是链表。数组天然支持随机访问,时间复杂度为 O(1),所以称为快速随机访问。链表需要遍历到特定位置才能访问特定位置的元素,时间复杂度为 O(n),所以不支持快速随机访问。,ArrayList 实现了 RandomAccess 接口,就表明了他具有快速随机访问功能。 RandomAccess 接口只是标识,并不是说 ArrayList 实现 RandomAccess 接口才具有快速随机访问功能的!
下面再总结一下 list 的遍历方式选择:
实现了 RandomAccess 接口的list,优先选择普通 for 循环 ,其次 foreach, 未实现 RandomAccess接口的list,优先选择iterator遍历(foreach遍历底层也是通过iterator实现的,),大size的数据,千万不要使用普通for循环 ArrayList 实现了Cloneable 接口,即覆盖了函数 clone(),能被克隆。 ArrayList 实现java.io.Serializable 接口,这意味着ArrayList支持序列化,能通过序列化去传输。 和 Vector 不同,ArrayList 中的操作不是线程安全的!所以,建议在单线程中才使用 ArrayList,而在多线程中可以选择 Vector 或者 CopyOnWriteArrayList。
- 先从 ArrayList 的构造函数说起
ArrayList有三种方式来初始化,构造方法源码如下:
/*** 默认初始容量大小*/private static final int DEFAULT_CAPACITY = 10;private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};/***默认构造函数,使用初始容量10构造一个空列表(无参数构造)*/public ArrayList() {this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;}/*** 带初始容量参数的构造函数。(用户自己指定容量)*/public ArrayList(int initialCapacity) {if (initialCapacity > 0) {//初始容量大于0//创建initialCapacity大小的数组this.elementData = new Object[initialCapacity];} else if (initialCapacity == 0) {//初始容量等于0//创建空数组this.elementData = EMPTY_ELEMENTDATA;} else {//初始容量小于0,抛出异常throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);}}/***构造包含指定collection元素的列表,这些元素利用该集合的迭代器按顺序返回*如果指定的集合为null,throws NullPointerException。*/public ArrayList(Collection<? extends E> c) {elementData = c.toArray();if ((size = elementData.length) != 0) {// c.toArray might (incorrectly) not return Object[] (see 6260652)if (elementData.getClass() != Object[].class)elementData = Arrays.copyOf(elementData, size, Object[].class);} else {// replace with empty array.this.elementData = EMPTY_ELEMENTDATA;}}
细心的同学一定会发现 :以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为10。 下面在我们分析 ArrayList 扩容时会讲到这一点内容!
- 一步一步分析 ArrayList 扩容机制
这里以无参构造函数创建的 ArrayList 为例分析
1. 先来看 add 方法
/*** 将指定的元素追加到此列表的末尾。*/public boolean add(E e) {//添加元素之前,先调用ensureCapacityInternal方法ensureCapacityInternal(size + 1); // Increments modCount!!//这里看到ArrayList添加元素的实质就相当于为数组赋值elementData[size++] = e;return true;}
2. 再来看看 ensureCapacityInternal() 方法
可以看到 add 方法 首先调用了ensureCapacityInternal(size + 1)
//得到最小扩容量private void ensureCapacityInternal(int minCapacity) {if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {// 获取默认的容量和传入参数的较大值minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);}ensureExplicitCapacity(minCapacity);}
当 要 add 进第1个元素时,minCapacity为1,在Math.max()方法比较后,minCapacity 为10。
3. ensureExplicitCapacity() 方法
如果调用 ensureCapacityInternal() 方法就一定会进过(执行)这个方法,下面我们来研究一下这个方法的源码!
//判断是否需要扩容private void ensureExplicitCapacity(int minCapacity) {modCount++;// overflow-conscious codeif (minCapacity - elementData.length > 0)//调用grow方法进行扩容,调用此方法代表已经开始扩容了grow(minCapacity);}
我们来仔细分析一下:
- 当我们要 add 进第1个元素到 ArrayList 时,elementData.length 为0 (因为还是一个空的 list),因为执行了
ensureCapacityInternal()方法 ,所以 minCapacity 此时为10。此时,minCapacity - elementData.length > 0成立,所以会进入grow(minCapacity)方法。 - 当add第2个元素时,minCapacity 为2,此时e lementData.length(容量)在添加第一个元素后扩容成 10 了。此时,
minCapacity - elementData.length > 0不成立,所以不会进入 (执行)grow(minCapacity)方法。 - 添加第3、4···到第10个元素时,依然不会执行grow方法,数组容量都为10。
直到添加第11个元素,minCapacity(为11)比elementData.length(为10)要大。进入grow方法进行扩容。
4. grow() 方法
/*** 要分配的最大数组大小*/private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;/*** ArrayList扩容的核心方法。*/private void grow(int minCapacity) {// oldCapacity为旧容量,newCapacity为新容量int oldCapacity = elementData.length;//将oldCapacity 右移一位,其效果相当于oldCapacity /2,//我们知道位运算的速度远远快于整除运算,整句运算式的结果就是将新容量更新为旧容量的1.5倍,int newCapacity = oldCapacity + (oldCapacity >> 1);//然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量,if (newCapacity - minCapacity < 0)newCapacity = minCapacity;// 如果新容量大于 MAX_ARRAY_SIZE,进入(执行) `hugeCapacity()` 方法来比较 minCapacity 和 MAX_ARRAY_SIZE,//如果minCapacity大于最大容量,则新容量则为`Integer.MAX_VALUE`,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 `Integer.MAX_VALUE - 8`。if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// minCapacity is usually close to size, so this is a win:elementData = Arrays.copyOf(elementData, newCapacity);}
int newCapacity = oldCapacity + (oldCapacity >> 1),所以 ArrayList 每次扩容之后容量都会变为原来的 1.5 倍!(JDK1.6版本以后) JDk1.6版本时,扩容之后容量为 1.5 倍+1!详情请参考源码
“>>”(移位运算符):>>1 右移一位相当于除2,右移n位相当于除以 2 的 n 次方。这里 oldCapacity 明显右移了1位所以相当于oldCapacity /2。对于大数据的2进制运算,位移运算符比那些普通运算符的运算要快很多,因为程序仅仅移动一下而已,不去计算,这样提高了效率,节省了资源
我们再来通过例子探究一下grow() 方法 :
- 当add第1个元素时,oldCapacity 为0,经比较后第一个if判断成立,newCapacity = minCapacity(为10)。但是第二个if判断不会成立,即newCapacity 不比 MAX_ARRAY_SIZE大,则不会进入
hugeCapacity方法。数组容量为10,add方法中 return true,size增为1。 - 当add第11个元素进入grow方法时,newCapacity为15,比minCapacity(为11)大,第一个if判断不成立。新容量没有大于数组最大size,不会进入hugeCapacity方法。数组容量扩为15,add方法中return true,size增为11。
- 以此类推······
这里补充一点比较重要,但是容易被忽视掉的知识点:
- java 中的
length属性是针对数组说的,比如说你声明了一个数组,想知道这个数组的长度则用到了 length 这个属性. - java 中的
length()方法是针对字符串说的,如果想看这个字符串的长度则用到length()这个方法. - java 中的
size()方法是针对泛型集合说的,如果想看这个泛型有多少个元素,就调用此方法来查看!
5. hugeCapacity() 方法。
从上面 grow() 方法源码我们知道: 如果新容量大于 MAX_ARRAY_SIZE,进入(执行) hugeCapacity() 方法来比较 minCapacity 和 MAX_ARRAY_SIZE,如果minCapacity大于最大容量,则新容量则为Integer.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 Integer.MAX_VALUE - 8。
private static int hugeCapacity(int minCapacity) {if (minCapacity < 0) // overflowthrow new OutOfMemoryError();//对minCapacity和MAX_ARRAY_SIZE进行比较//若minCapacity大,将Integer.MAX_VALUE作为新数组的大小//若MAX_ARRAY_SIZE大,将MAX_ARRAY_SIZE作为新数组的大小//MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;return (minCapacity > MAX_ARRAY_SIZE) ?Integer.MAX_VALUE :MAX_ARRAY_SIZE;}
System.arraycopy()和Arrays.copyOf()方法
阅读源码的话,我们就会发现 ArrayList 中大量调用了这两个方法。比如:我们上面讲的扩容操作以及add(int index, E element)、toArray() 等方法中都用到了该方法!
System.arraycopy() 方法
/*** 在此列表中的指定位置插入指定的元素。*先调用 rangeCheckForAdd 对index进行界限检查;然后调用 ensureCapacityInternal 方法保证capacity足够大;*再将从index开始之后的所有成员后移一个位置;将element插入index位置;最后size加1。*/public void add(int index, E element) {rangeCheckForAdd(index);ensureCapacityInternal(size + 1); // Increments modCount!!//arraycopy()方法实现数组自己复制自己//elementData:源数组;index:源数组中的起始位置;elementData:目标数组;index + 1:目标数组中的起始位置; size - index:要复制的数组元素的数量;System.arraycopy(elementData, index, elementData, index + 1, size - index);elementData[index] = element;size++;}
我们写一个简单的方法测试以下:
public class ArraycopyTest {public static void main(String[] args) {// TODO Auto-generated method stubint[] a = new int[10];a[0] = 0;a[1] = 1;a[2] = 2;a[3] = 3;System.arraycopy(a, 2, a, 3, 3);a[2]=99;for (int i = 0; i < a.length; i++) {System.out.println(a[i]);}}}
结果:
0 1 99 2 3 0 0 0 0 0
Arrays.copyOf()方法
/**以正确的顺序返回一个包含此列表中所有元素的数组(从第一个到最后一个元素); 返回的数组的运行时类型是指定数组的运行时类型。*/public Object[] toArray() {//elementData:要复制的数组;size:要复制的长度return Arrays.copyOf(elementData, size);}
个人觉得使用 Arrays.copyOf()方法主要是为了给原有数组扩容,测试代码如下:
public class ArrayscopyOfTest {public static void main(String[] args) {int[] a = new int[3];a[0] = 0;a[1] = 1;a[2] = 2;int[] b = Arrays.copyOf(a, 10);System.out.println("b.length"+b.length);}}
结果:
10
两者联系和区别
联系:
看两者源代码可以发现 copyOf() 内部实际调用了 System.arraycopy() 方法
区别:
arraycopy() 需要目标数组,将原数组拷贝到你自己定义的数组里或者原数组,而且可以选择拷贝的起点和长度以及放入新数组中的位置 copyOf() 是系统自动在内部新建一个数组,并返回该数组。
ensureCapacity方法
ArrayList 源码中有一个 ensureCapacity 方法不知道大家注意到没有,这个方法 ArrayList 内部没有被调用过,所以很显然是提供给用户调用的,那么这个方法有什么作用呢?
/**如有必要,增加此 ArrayList 实例的容量,以确保它至少可以容纳由minimum capacity参数指定的元素数。** @param minCapacity 所需的最小容量*/public void ensureCapacity(int minCapacity) {int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)// any size if not default element table? 0// larger than default for default empty table. It's already// supposed to be at default size.: DEFAULT_CAPACITY;if (minCapacity > minExpand) {ensureExplicitCapacity(minCapacity);}}
最好在 add 大量元素之前用 ensureCapacity 方法,以减少增量重新分配的次数
我们通过下面的代码实际测试以下这个方法的效果:
public class EnsureCapacityTest {public static void main(String[] args) {ArrayList<Object> list = new ArrayList<Object>();final int N = 10000000;long startTime = System.currentTimeMillis();for (int i = 0; i < N; i++) {list.add(i);}long endTime = System.currentTimeMillis();System.out.println("使用ensureCapacity方法前:"+(endTime - startTime));}}
运行结果:
使用ensureCapacity方法前:2158
public class EnsureCapacityTest {public static void main(String[] args) {ArrayList<Object> list = new ArrayList<Object>();final int N = 10000000;list = new ArrayList<Object>();long startTime1 = System.currentTimeMillis();list.ensureCapacity(N);for (int i = 0; i < N; i++) {list.add(i);}long endTime1 = System.currentTimeMillis();System.out.println("使用ensureCapacity方法后:"+(endTime1 - startTime1));}}
运行结果:
使用ensureCapacity方法前:1773
通过运行结果,我们可以看出向 ArrayList 添加大量元素之前最好先使用ensureCapacity 方法,以减少增量重新分配的次数。
LinkedList
LinkedList是一个实现了List接口和Deque接口的双端链表。
LinkedList底层的链表结构使它支持高效的插入和删除操作,另外它实现了Deque接口,使得LinkedList类也具有队列的特性;
LinkedList不是线程安全的,如果想使LinkedList变成线程安全的,可以调用静态类Collections类中的synchronizedList方法:
List list=Collections.synchronizedList(new LinkedList(...));
内部结构分析
如下图所示: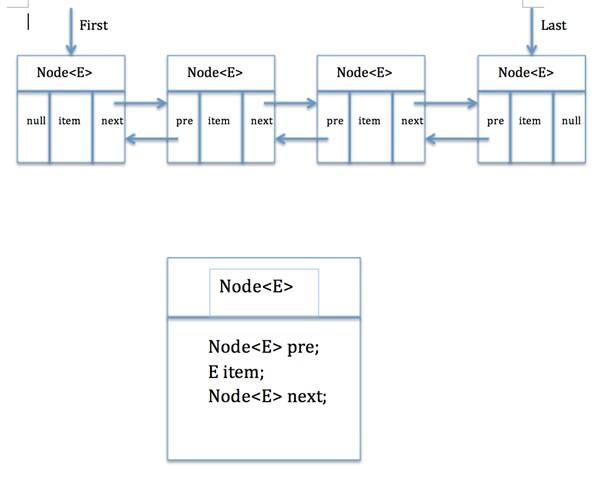
看完了图之后,我们再看LinkedList类中的一个内部私有类Node就很好理解了:
private static class Node<E> {E item;//节点值Node<E> next;//后继节点Node<E> prev;//前驱节点Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}}
这个类就代表双端链表的节点Node。这个类有三个属性,分别是前驱节点,本节点的值,后继结点。
LinkedList源码分析
构造方法
空构造方法:
public LinkedList() {}
用已有的集合创建链表的构造方法:
public LinkedList(Collection<? extends E> c) {this();addAll(c);}
add方法
add(E e) 方法:将元素添加到链表尾部
public boolean add(E e) {linkLast(e);//这里就只调用了这一个方法return true;}
/*** 链接使e作为最后一个元素。*/void linkLast(E e) {final Node<E> l = last;final Node<E> newNode = new Node<>(l, e, null);last = newNode;//新建节点if (l == null)first = newNode;elsel.next = newNode;//指向后继元素也就是指向下一个元素size++;modCount++;}
add(int index,E e):在指定位置添加元素
public void add(int index, E element) {checkPositionIndex(index); //检查索引是否处于[0-size]之间if (index == size)//添加在链表尾部linkLast(element);else//添加在链表中间linkBefore(element, node(index));}
linkBefore方法需要给定两个参数,一个插入节点的值,一个指定的node,所以我们又调用了Node(index)去找到index对应的node
addAll(Collection c ):将集合插入到链表尾部
public boolean addAll(Collection<? extends E> c) {return addAll(size, c);}
addAll(int index, Collection c): 将集合从指定位置开始插入
public boolean addAll(int index, Collection<? extends E> c) {//1:检查index范围是否在size之内checkPositionIndex(index);//2:toArray()方法把集合的数据存到对象数组中Object[] a = c.toArray();int numNew = a.length;if (numNew == 0)return false;//3:得到插入位置的前驱节点和后继节点Node<E> pred, succ;//如果插入位置为尾部,前驱节点为last,后继节点为nullif (index == size) {succ = null;pred = last;}//否则,调用node()方法得到后继节点,再得到前驱节点else {succ = node(index);pred = succ.prev;}// 4:遍历数据将数据插入for (Object o : a) {@SuppressWarnings("unchecked") E e = (E) o;//创建新节点Node<E> newNode = new Node<>(pred, e, null);//如果插入位置在链表头部if (pred == null)first = newNode;elsepred.next = newNode;pred = newNode;}//如果插入位置在尾部,重置last节点if (succ == null) {last = pred;}//否则,将插入的链表与先前链表连接起来else {pred.next = succ;succ.prev = pred;}size += numNew;modCount++;return true;}
上面可以看出addAll方法通常包括下面四个步骤:
- 检查index范围是否在size之内
- toArray()方法把集合的数据存到对象数组中
- 得到插入位置的前驱和后继节点
- 遍历数据,将数据插入到指定位置
addFirst(E e): 将元素添加到链表头部
public void addFirst(E e) {linkFirst(e);}
private void linkFirst(E e) {final Node<E> f = first;final Node<E> newNode = new Node<>(null, e, f);//新建节点,以头节点为后继节点first = newNode;//如果链表为空,last节点也指向该节点if (f == null)last = newNode;//否则,将头节点的前驱指针指向新节点,也就是指向前一个元素elsef.prev = newNode;size++;modCount++;}
addLast(E e): 将元素添加到链表尾部,与 add(E e) 方法一样
public void addLast(E e) {linkLast(e);}
根据位置取数据的方法
get(int index): 根据指定索引返回数据
public E get(int index) {//检查index范围是否在size之内checkElementIndex(index);//调用Node(index)去找到index对应的node然后返回它的值return node(index).item;}
获取头节点(index=0)数据方法:
public E getFirst() {final Node<E> f = first;if (f == null)throw new NoSuchElementException();return f.item;}public E element() {return getFirst();}public E peek() {final Node<E> f = first;return (f == null) ? null : f.item;}public E peekFirst() {final Node<E> f = first;return (f == null) ? null : f.item;}
区别:
getFirst(),element(),peek(),peekFirst()
这四个获取头结点方法的区别在于对链表为空时的处理,是抛出异常还是返回null,其中getFirst() 和element() 方法将会在链表为空时,抛出异常
element()方法的内部就是使用getFirst()实现的。它们会在链表为空时,抛出NoSuchElementException
获取尾节点(index=-1)数据方法:
public E getLast() {final Node<E> l = last;if (l == null)throw new NoSuchElementException();return l.item;}public E peekLast() {final Node<E> l = last;return (l == null) ? null : l.item;}
两者区别:
getLast() 方法在链表为空时,会抛出NoSuchElementException,而peekLast() 则不会,只是会返回 null。
根据对象得到索引的方法
int indexOf(Object o): 从头遍历找
public int indexOf(Object o) {int index = 0;if (o == null) {//从头遍历for (Node<E> x = first; x != null; x = x.next) {if (x.item == null)return index;index++;}} else {//从头遍历for (Node<E> x = first; x != null; x = x.next) {if (o.equals(x.item))return index;index++;}}return -1;}
int lastIndexOf(Object o): 从尾遍历找
public int lastIndexOf(Object o) {int index = size;if (o == null) {//从尾遍历for (Node<E> x = last; x != null; x = x.prev) {index--;if (x.item == null)return index;}} else {//从尾遍历for (Node<E> x = last; x != null; x = x.prev) {index--;if (o.equals(x.item))return index;}}return -1;}
检查链表是否包含某对象的方法:
contains(Object o): 检查对象o是否存在于链表中
public boolean contains(Object o) {return indexOf(o) != -1;}
删除方法
remove() ,removeFirst(),pop(): 删除头节点
public E pop() {return removeFirst();}public E remove() {return removeFirst();}public E removeFirst() {final Node<E> f = first;if (f == null)throw new NoSuchElementException();return unlinkFirst(f);}
removeLast(),pollLast(): 删除尾节点
public E removeLast() {final Node<E> l = last;if (l == null)throw new NoSuchElementException();return unlinkLast(l);}public E pollLast() {final Node<E> l = last;return (l == null) ? null : unlinkLast(l);}
区别: removeLast()在链表为空时将抛出NoSuchElementException,而pollLast()方法返回null。
remove(Object o): 删除指定元素
public boolean remove(Object o) {//如果删除对象为nullif (o == null) {//从头开始遍历for (Node<E> x = first; x != null; x = x.next) {//找到元素if (x.item == null) {//从链表中移除找到的元素unlink(x);return true;}}} else {//从头开始遍历for (Node<E> x = first; x != null; x = x.next) {//找到元素if (o.equals(x.item)) {//从链表中移除找到的元素unlink(x);return true;}}}return false;}
当删除指定对象时,只需调用remove(Object o)即可,不过该方法一次只会删除一个匹配的对象,如果删除了匹配对象,返回true,否则false。
unlink(Node x) 方法:
E unlink(Node<E> x) {// assert x != null;final E element = x.item;final Node<E> next = x.next;//得到后继节点final Node<E> prev = x.prev;//得到前驱节点//删除前驱指针if (prev == null) {first = next;//如果删除的节点是头节点,令头节点指向该节点的后继节点} else {prev.next = next;//将前驱节点的后继节点指向后继节点x.prev = null;}//删除后继指针if (next == null) {last = prev;//如果删除的节点是尾节点,令尾节点指向该节点的前驱节点} else {next.prev = prev;x.next = null;}x.item = null;size--;modCount++;return element;}
remove(int index):删除指定位置的元素
public E remove(int index) {//检查index范围checkElementIndex(index);//将节点删除return unlink(node(index));}
LinkedList类常用方法测试
package list;import java.util.Iterator;import java.util.LinkedList;public class LinkedListDemo {public static void main(String[] srgs) {//创建存放int类型的linkedListLinkedList<Integer> linkedList = new LinkedList<>();/************************** linkedList的基本操作 ************************/linkedList.addFirst(0); // 添加元素到列表开头linkedList.add(1); // 在列表结尾添加元素linkedList.add(2, 2); // 在指定位置添加元素linkedList.addLast(3); // 添加元素到列表结尾System.out.println("LinkedList(直接输出的): " + linkedList);System.out.println("getFirst()获得第一个元素: " + linkedList.getFirst()); // 返回此列表的第一个元素System.out.println("getLast()获得第最后一个元素: " + linkedList.getLast()); // 返回此列表的最后一个元素System.out.println("removeFirst()删除第一个元素并返回: " + linkedList.removeFirst()); // 移除并返回此列表的第一个元素System.out.println("removeLast()删除最后一个元素并返回: " + linkedList.removeLast()); // 移除并返回此列表的最后一个元素System.out.println("After remove:" + linkedList);System.out.println("contains()方法判断列表是否包含1这个元素:" + linkedList.contains(1)); // 判断此列表包含指定元素,如果是,则返回trueSystem.out.println("该linkedList的大小 : " + linkedList.size()); // 返回此列表的元素个数/************************** 位置访问操作 ************************/System.out.println("-----------------------------------------");linkedList.set(1, 3); // 将此列表中指定位置的元素替换为指定的元素System.out.println("After set(1, 3):" + linkedList);System.out.println("get(1)获得指定位置(这里为1)的元素: " + linkedList.get(1)); // 返回此列表中指定位置处的元素/************************** Search操作 ************************/System.out.println("-----------------------------------------");linkedList.add(3);System.out.println("indexOf(3): " + linkedList.indexOf(3)); // 返回此列表中首次出现的指定元素的索引System.out.println("lastIndexOf(3): " + linkedList.lastIndexOf(3));// 返回此列表中最后出现的指定元素的索引/************************** Queue操作 ************************/System.out.println("-----------------------------------------");System.out.println("peek(): " + linkedList.peek()); // 获取但不移除此列表的头System.out.println("element(): " + linkedList.element()); // 获取但不移除此列表的头linkedList.poll(); // 获取并移除此列表的头System.out.println("After poll():" + linkedList);linkedList.remove();System.out.println("After remove():" + linkedList); // 获取并移除此列表的头linkedList.offer(4);System.out.println("After offer(4):" + linkedList); // 将指定元素添加到此列表的末尾/************************** Deque操作 ************************/System.out.println("-----------------------------------------");linkedList.offerFirst(2); // 在此列表的开头插入指定的元素System.out.println("After offerFirst(2):" + linkedList);linkedList.offerLast(5); // 在此列表末尾插入指定的元素System.out.println("After offerLast(5):" + linkedList);System.out.println("peekFirst(): " + linkedList.peekFirst()); // 获取但不移除此列表的第一个元素System.out.println("peekLast(): " + linkedList.peekLast()); // 获取但不移除此列表的第一个元素linkedList.pollFirst(); // 获取并移除此列表的第一个元素System.out.println("After pollFirst():" + linkedList);linkedList.pollLast(); // 获取并移除此列表的最后一个元素System.out.println("After pollLast():" + linkedList);linkedList.push(2); // 将元素推入此列表所表示的堆栈(插入到列表的头)System.out.println("After push(2):" + linkedList);linkedList.pop(); // 从此列表所表示的堆栈处弹出一个元素(获取并移除列表第一个元素)System.out.println("After pop():" + linkedList);linkedList.add(3);linkedList.removeFirstOccurrence(3); // 从此列表中移除第一次出现的指定元素(从头部到尾部遍历列表)System.out.println("After removeFirstOccurrence(3):" + linkedList);linkedList.removeLastOccurrence(3); // 从此列表中移除最后一次出现的指定元素(从尾部到头部遍历列表)System.out.println("After removeFirstOccurrence(3):" + linkedList);/************************** 遍历操作 ************************/System.out.println("-----------------------------------------");linkedList.clear();for (int i = 0; i < 100000; i++) {linkedList.add(i);}// 迭代器遍历long start = System.currentTimeMillis();Iterator<Integer> iterator = linkedList.iterator();while (iterator.hasNext()) {iterator.next();}long end = System.currentTimeMillis();System.out.println("Iterator:" + (end - start) + " ms");// 顺序遍历(随机遍历)start = System.currentTimeMillis();for (int i = 0; i < linkedList.size(); i++) {linkedList.get(i);}end = System.currentTimeMillis();System.out.println("for:" + (end - start) + " ms");// 另一种for循环遍历start = System.currentTimeMillis();for (Integer i : linkedList);end = System.currentTimeMillis();System.out.println("for2:" + (end - start) + " ms");// 通过pollFirst()或pollLast()来遍历LinkedListLinkedList<Integer> temp1 = new LinkedList<>();temp1.addAll(linkedList);start = System.currentTimeMillis();while (temp1.size() != 0) {temp1.pollFirst();}end = System.currentTimeMillis();System.out.println("pollFirst()或pollLast():" + (end - start) + " ms");// 通过removeFirst()或removeLast()来遍历LinkedListLinkedList<Integer> temp2 = new LinkedList<>();temp2.addAll(linkedList);start = System.currentTimeMillis();while (temp2.size() != 0) {temp2.removeFirst();}end = System.currentTimeMillis();System.out.println("removeFirst()或removeLast():" + (end - start) + " ms");}}
Vector
ArrayList与Vector的区别
- Vector是线程安全的, 也就是线程同步的, 而ArrayList是线程序不安全的. 对于Vector&ArrayList, Hashtable&HashMap, 要记住线程安全的问题, 记住Vector与Hashtable是旧的, 是java一诞生就提供了的, 它们是线程安全的, ArrayList与HashMap是java2时才提供的, 它们是线程不安全的.
- ArrayList与Vector都有一个初始的容量大小, 当存储进它们里面的元素的个数超过了容量时, 就需要增加ArrayList与Vector的存储空间, Vector默认增长为原来两倍,而ArrayList的增长策略在文档中没有明确规定(从源代码看到的是增长为原来的1.5倍).ArrayList与Vector都可以设置初始的空间大小, Vector还可以设置增长的空间大小, 而ArrayList没有提供设置增长空间的方法.
总结:即Vector增长原来的一倍,ArrayList增加原来的0.5倍. Vector 线程安全, ArrayList 不是.
**
同步容器(如Vector)的所有操作一定是线程安全的吗?
Vector这样的同步容器的所有公有方法全都是synchronized的,也就是说,我们可以在多线程场景中放心的使用单独这些方法,因为这些方法本身的确是线程安全的。
但是,请注意上面这句话中,有一个比较关键的词:单独
因为,虽然同步容器的所有方法都加了锁,但是对这些容器的复合操作无法保证其线程安全性。需要客户端通过主动加锁来保证。
简单举一个例子,我们定义如下删除Vector中最后一个元素方法:
public Object deleteLast(Vector v){int lastIndex = v.size()-1;v.remove(lastIndex);}复制代码
上面这个方法是一个复合方法,包括size()和remove(),乍一看上去好像并没有什么问题,无论是size()方法还是remove()方法都是线程安全的,那么整个deleteLast方法应该也是线程安全的。
但是时,如果多线程调用该方法的过程中,remove方法有可能抛出ArrayIndexOutOfBoundsException。
Exception in thread "Thread-1" java.lang.ArrayIndexOutOfBoundsException: Array index out of range: 879at java.util.Vector.remove(Vector.java:834)at com.hollis.Test.deleteLast(EncodeTest.java:40)at com.hollis.Test$2.run(EncodeTest.java:28)at java.lang.Thread.run(Thread.java:748)复制代码
我们上面贴了remove的源码,我们可以分析得出:当index >= elementCount时,会抛出ArrayIndexOutOfBoundsException ,也就是说,当当前索引值不再有效的时候,将会抛出这个异常。
因为removeLast方法,有可能被多个线程同时执行,当线程2通过index()获得索引值为10,在尝试通过remove()删除该索引位置的元素之前,线程1把该索引位置的值删除掉了,这时线程一在执行时便会抛出异常。 

为了避免出现类似问题,可以尝试加锁:
public void deleteLast() {synchronized (v) {int index = v.size() - 1;v.remove(index);}}复制代码
如上,我们在deleteLast中,对v进行加锁,即可保证同一时刻,不会有其他线程删除掉v中的元素。
另外,如果以下代码会被多线程执行时,也要特别注意:
for (int i = 0; i < v.size(); i++) {v.remove(i);}复制代码
由于,不同线程在同一时间操作同一个Vector,其中包括删除操作,那么就同样有可能发生线程安全问题。所以,在使用同步容器的时候,如果涉及到多个线程同时执行删除操作,就要考虑下是否需要加锁。
同步容器的问题
前面说过了,同步容器直接保证耽搁操作的线程安全性,但是无法保证复合操作的线程安全,遇到这种情况时,必须要通过主动加锁的方式来实现。
而且,除此之外,同步容易由于对其所有方法都加了锁,这就导致多个线程访问同一个容器的时候,只能进行顺序访问,即使是不同的操作,也要排队,如get和add要排队执行。这就大大的降低了容器的并发能力。
HashMap
- HashMap 简介
- 底层数据结构分析
- HashMap源码分析
- HashMap常用方法测试
感谢 changfubai 对本文的改进做出的贡献!
HashMap 简介
HashMap 主要用来存放键值对,它基于哈希表的Map接口实现,是常用的Java集合之一。
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突).JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树),以减少搜索时间,具体可以参考 treeifyBin方法。
底层数据结构分析
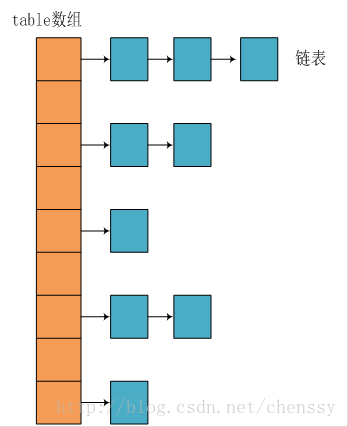
JDK1.8之前
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
JDK 1.8 HashMap 的 hash 方法源码:
JDK 1.8 的 hash方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
static final int hash(Object key) {int h;// key.hashCode():返回散列值也就是hashcode// ^ :按位异或// >>>:无符号右移,忽略符号位,空位都以0补齐return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
对比一下 JDK1.7的 HashMap 的 hash 方法源码.
static int hash(int h) {// This function ensures that hashCodes that differ only by// constant multiples at each bit position have a bounded// number of collisions (approximately 8 at default load factor).h ^= (h >>> 20) ^ (h >>> 12);return h ^ (h >>> 7) ^ (h >>> 4);}
相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
所谓 “拉链法” 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
JDK1.8之后
相比于之前的版本,jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
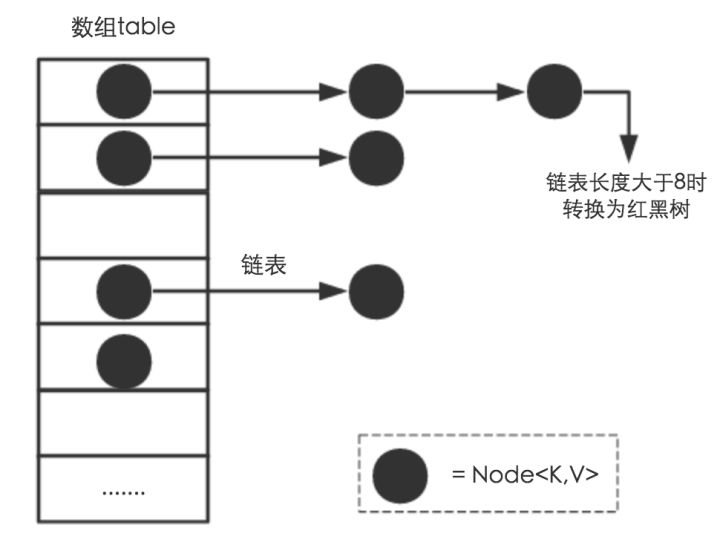
类的属性:
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {// 序列号private static final long serialVersionUID = 362498820763181265L;// 默认的初始容量是16static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;// 最大容量static final int MAXIMUM_CAPACITY = 1 << 30;// 默认的填充因子static final float DEFAULT_LOAD_FACTOR = 0.75f;// 当桶(bucket)上的结点数大于这个值时会转成红黑树static final int TREEIFY_THRESHOLD = 8;// 当桶(bucket)上的结点数小于这个值时树转链表static final int UNTREEIFY_THRESHOLD = 6;// 桶中结构转化为红黑树对应的table的最小大小static final int MIN_TREEIFY_CAPACITY = 64;// 存储元素的数组,总是2的幂次倍transient Node<k,v>[] table;// 存放具体元素的集transient Set<map.entry<k,v>> entrySet;// 存放元素的个数,注意这个不等于数组的长度。transient int size;// 每次扩容和更改map结构的计数器transient int modCount;// 临界值 当实际大小(容量*填充因子)超过临界值时,会进行扩容int threshold;// 加载因子final float loadFactor;}
- loadFactor加载因子
loadFactor加载因子是控制数组存放数据的疏密程度,loadFactor越趋近于1,那么 数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,loadFactor越小,也就是趋近于0,数组中存放的数据(entry)也就越少,也就越稀疏。
loadFactor太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor的默认值为0.75f是官方给出的一个比较好的临界值。
给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。 - threshold
threshold = capacity loadFactor,当Size>=threshold的时候,那么就要考虑对数组的扩增了,也就是说,这个的意思就是 衡量数组是否需要扩增的一个标准**。
Node节点类源码:
// 继承自 Map.Entry<K,V>static class Node<K,V> implements Map.Entry<K,V> {final int hash;// 哈希值,存放元素到hashmap中时用来与其他元素hash值比较final K key;//键V value;//值// 指向下一个节点Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}public final K getKey() { return key; }public final V getValue() { return value; }public final String toString() { return key + "=" + value; }// 重写hashCode()方法public final int hashCode() {return Objects.hashCode(key) ^ Objects.hashCode(value);}public final V setValue(V newValue) {V oldValue = value;value = newValue;return oldValue;}// 重写 equals() 方法public final boolean equals(Object o) {if (o == this)return true;if (o instanceof Map.Entry) {Map.Entry<?,?> e = (Map.Entry<?,?>)o;if (Objects.equals(key, e.getKey()) &&Objects.equals(value, e.getValue()))return true;}return false;}}
树节点类源码:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {TreeNode<K,V> parent; // 父TreeNode<K,V> left; // 左TreeNode<K,V> right; // 右TreeNode<K,V> prev; // needed to unlink next upon deletionboolean red; // 判断颜色TreeNode(int hash, K key, V val, Node<K,V> next) {super(hash, key, val, next);}// 返回根节点final TreeNode<K,V> root() {for (TreeNode<K,V> r = this, p;;) {if ((p = r.parent) == null)return r;r = p;}
HashMap源码分析
构造方法
HashMap 中有四个构造方法,它们分别如下:
// 默认构造函数。public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted}// 包含另一个“Map”的构造函数public HashMap(Map<? extends K, ? extends V> m) {this.loadFactor = DEFAULT_LOAD_FACTOR;putMapEntries(m, false);//下面会分析到这个方法}// 指定“容量大小”的构造函数public HashMap(int initialCapacity) {this(initialCapacity, DEFAULT_LOAD_FACTOR);}// 指定“容量大小”和“加载因子”的构造函数public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " + loadFactor);this.loadFactor = loadFactor;this.threshold = tableSizeFor(initialCapacity);}
putMapEntries方法:
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {int s = m.size();if (s > 0) {// 判断table是否已经初始化if (table == null) { // pre-size// 未初始化,s为m的实际元素个数float ft = ((float)s / loadFactor) + 1.0F;int t = ((ft < (float)MAXIMUM_CAPACITY) ?(int)ft : MAXIMUM_CAPACITY);// 计算得到的t大于阈值,则初始化阈值if (t > threshold)threshold = tableSizeFor(t);}// 已初始化,并且m元素个数大于阈值,进行扩容处理else if (s > threshold)resize();// 将m中的所有元素添加至HashMap中for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {K key = e.getKey();V value = e.getValue();putVal(hash(key), key, value, false, evict);}}}
put方法
HashMap只提供了put用于添加元素,putVal方法只是给put方法调用的一个方法,并没有提供给用户使用。
对putVal方法添加元素的分析如下:
- ①如果定位到的数组位置没有元素 就直接插入。
- ②如果定位到的数组位置有元素就和要插入的key比较,如果key相同就直接覆盖,如果key不相同,就判断p是否是一个树节点,如果是就调用
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value)将元素添加进入。如果不是就遍历链表插入(插入的是链表尾部)。
ps:下图有一个小问题,来自 issue#608指出:直接覆盖之后应该就会 return,不会有后续操作。参考 JDK8 HashMap.java 658 行。
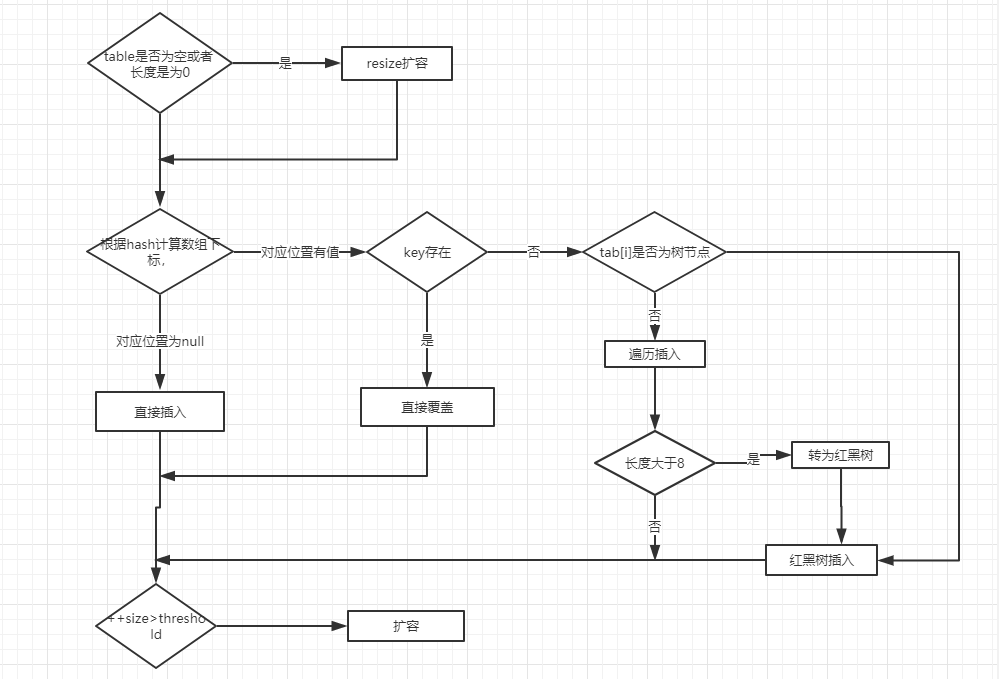
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;// table未初始化或者长度为0,进行扩容if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;// (n - 1) & hash 确定元素存放在哪个桶中,桶为空,新生成结点放入桶中(此时,这个结点是放在数组中)if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);// 桶中已经存在元素else {Node<K,V> e; K k;// 比较桶中第一个元素(数组中的结点)的hash值相等,key相等if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))// 将第一个元素赋值给e,用e来记录e = p;// hash值不相等,即key不相等;为红黑树结点else if (p instanceof TreeNode)// 放入树中e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);// 为链表结点else {// 在链表最末插入结点for (int binCount = 0; ; ++binCount) {// 到达链表的尾部if ((e = p.next) == null) {// 在尾部插入新结点p.next = newNode(hash, key, value, null);// 结点数量达到阈值,转化为红黑树if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);// 跳出循环break;}// 判断链表中结点的key值与插入的元素的key值是否相等if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))// 相等,跳出循环break;// 用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表p = e;}}// 表示在桶中找到key值、hash值与插入元素相等的结点if (e != null) {// 记录e的valueV oldValue = e.value;// onlyIfAbsent为false或者旧值为nullif (!onlyIfAbsent || oldValue == null)//用新值替换旧值e.value = value;// 访问后回调afterNodeAccess(e);// 返回旧值return oldValue;}}// 结构性修改++modCount;// 实际大小大于阈值则扩容if (++size > threshold)resize();// 插入后回调afterNodeInsertion(evict);return null;}
我们再来对比一下 JDK1.7 put方法的代码
对于put方法的分析如下:
- ①如果定位到的数组位置没有元素 就直接插入。
- ②如果定位到的数组位置有元素,遍历以这个元素为头结点的链表,依次和插入的key比较,如果key相同就直接覆盖,不同就采用头插法插入元素。
public V put(K key, V value)if (table == EMPTY_TABLE) {inflateTable(threshold);}if (key == null)return putForNullKey(value);int hash = hash(key);int i = indexFor(hash, table.length);for (Entry<K,V> e = table[i]; e != null; e = e.next) { // 先遍历Object k;if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {V oldValue = e.value;e.value = value;e.recordAccess(this);return oldValue;}}modCount++;addEntry(hash, key, value, i); // 再插入return null;}
get方法
public V get(Object key) {Node<K,V> e;return (e = getNode(hash(key), key)) == null ? null : e.value;}final Node<K,V> getNode(int hash, Object key) {Node<K,V>[] tab; Node<K,V> first, e; int n; K k;if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {// 数组元素相等if (first.hash == hash && // always check first node((k = first.key) == key || (key != null && key.equals(k))))return first;// 桶中不止一个节点if ((e = first.next) != null) {// 在树中getif (first instanceof TreeNode)return ((TreeNode<K,V>)first).getTreeNode(hash, key);// 在链表中getdo {if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;} while ((e = e.next) != null);}}return null;}
resize方法
进行扩容,会伴随着一次重新hash分配,并且会遍历hash表中所有的元素,是非常耗时的。在编写程序中,要尽量避免resize。
final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length;int oldThr = threshold;int newCap, newThr = 0;if (oldCap > 0) {// 超过最大值就不再扩充了,就只好随你碰撞去吧if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}// 没超过最大值,就扩充为原来的2倍else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold}else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;else {// signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}// 计算新的resize上限if (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE);}threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;if (oldTab != null) {// 把每个bucket都移动到新的buckets中for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null)newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else {Node<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;// 原索引if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}// 原索引+oldCapelse {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);// 原索引放到bucket里if (loTail != null) {loTail.next = null;newTab[j] = loHead;}// 原索引+oldCap放到bucket里if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;}
HashMap常用方法测试
package map;import java.util.Collection;import java.util.HashMap;import java.util.Set;public class HashMapDemo {public static void main(String[] args) {HashMap<String, String> map = new HashMap<String, String>();// 键不能重复,值可以重复map.put("san", "张三");map.put("si", "李四");map.put("wu", "王五");map.put("wang", "老王");map.put("wang", "老王2");// 老王被覆盖map.put("lao", "老王");System.out.println("-------直接输出hashmap:-------");System.out.println(map);/*** 遍历HashMap*/// 1.获取Map中的所有键System.out.println("-------foreach获取Map中所有的键:------");Set<String> keys = map.keySet();for (String key : keys) {System.out.print(key+" ");}System.out.println();//换行// 2.获取Map中所有值System.out.println("-------foreach获取Map中所有的值:------");Collection<String> values = map.values();for (String value : values) {System.out.print(value+" ");}System.out.println();//换行// 3.得到key的值的同时得到key所对应的值System.out.println("-------得到key的值的同时得到key所对应的值:-------");Set<String> keys2 = map.keySet();for (String key : keys2) {System.out.print(key + ":" + map.get(key)+" ");}/*** 另外一种不常用的遍历方式*/// 当我调用put(key,value)方法的时候,首先会把key和value封装到// Entry这个静态内部类对象中,把Entry对象再添加到数组中,所以我们想获取// map中的所有键值对,我们只要获取数组中的所有Entry对象,接下来// 调用Entry对象中的getKey()和getValue()方法就能获取键值对了Set<java.util.Map.Entry<String, String>> entrys = map.entrySet();for (java.util.Map.Entry<String, String> entry : entrys) {System.out.println(entry.getKey() + "--" + entry.getValue());}/*** HashMap其他常用方法*/System.out.println("after map.size():"+map.size());System.out.println("after map.isEmpty():"+map.isEmpty());System.out.println(map.remove("san"));System.out.println("after map.remove():"+map);System.out.println("after map.get(si):"+map.get("si"));System.out.println("after map.containsKey(si):"+map.containsKey("si"));System.out.println("after containsValue(李四):"+map.containsValue("李四"));System.out.println(map.replace("si", "李四2"));System.out.println("after map.replace(si, 李四2):"+map);}}
并发情况下HASHMAP的死循环
正常的ReHash的过程
画了个图做了个演示。
- 我假设了我们的hash算法就是简单的用key mod 一下表的大小(也就是数组的长度)。
- 最上面的是old hash 表,其中的Hash表的size=2, 所以key = 3, 7, 5,在mod 2以后都冲突在table[1]这里了。
- 接下来的三个步骤是Hash表 resize成4,然后所有的
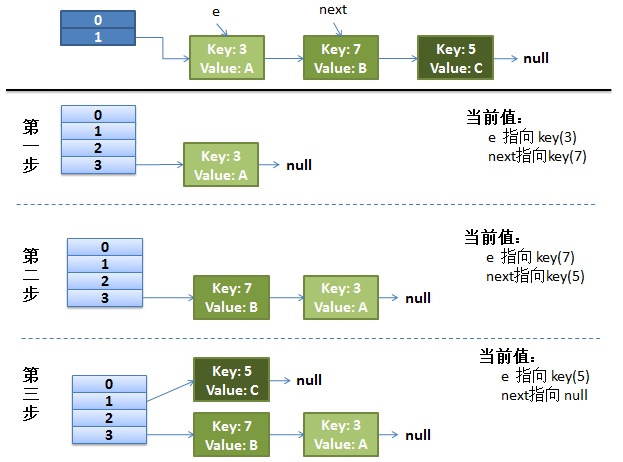
并发下的Rehash
1)假设我们有两个线程。我用红色和浅蓝色标注了一下。
我们再回头看一下我们的 transfer代码中的这个细节:
do {``Entry<K,V> next = e.next; ``// <--假设线程一执行到这里就被调度挂起了``int i = indexFor(e.hash, newCapacity);``e.next = newTable[i];``newTable[i] = e;``e = next;} ``while (e != ``null``); |
|---|
而我们的线程二执行完成了。于是我们有下面的这个样子。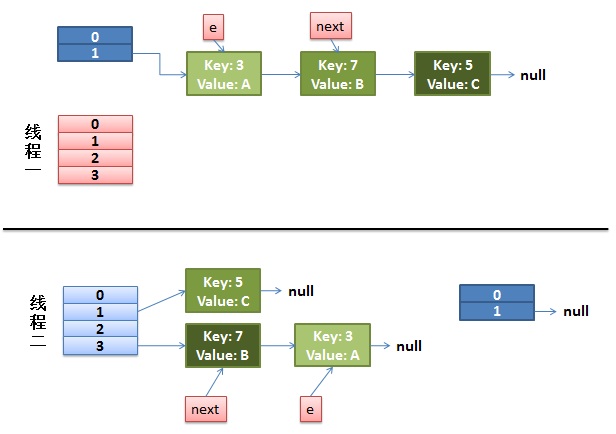
注意,因为Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。我们可以看到链表的顺序被反转后。
2)线程一被调度回来执行。
- 先是执行 newTalbe[i] = e;
- 然后是e = next,导致了e指向了key(7),
- 而下一次循环的next = e.next导致了next指向了key(3)
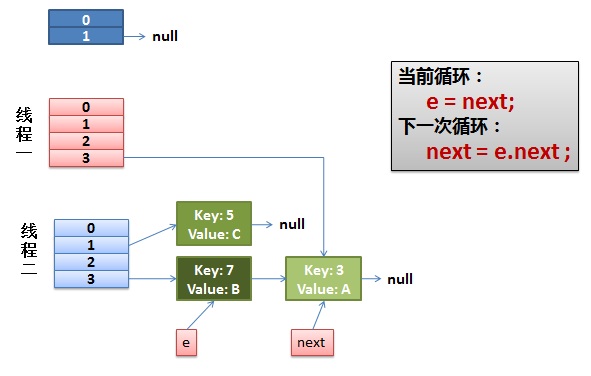
3)一切安好。
线程一接着工作。把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。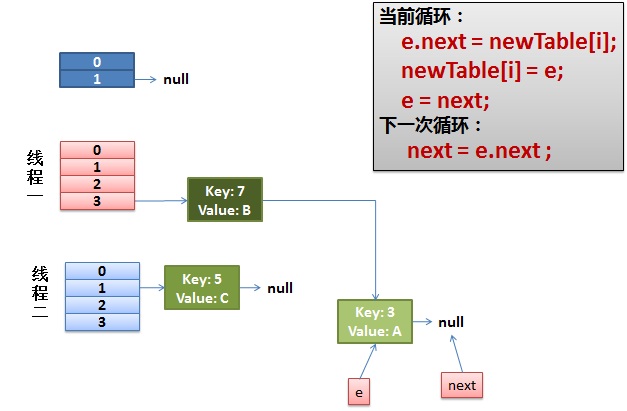
4)环形链接出现。
e.next = newTable[i] 导致 key(3).next 指向了 key(7)
注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。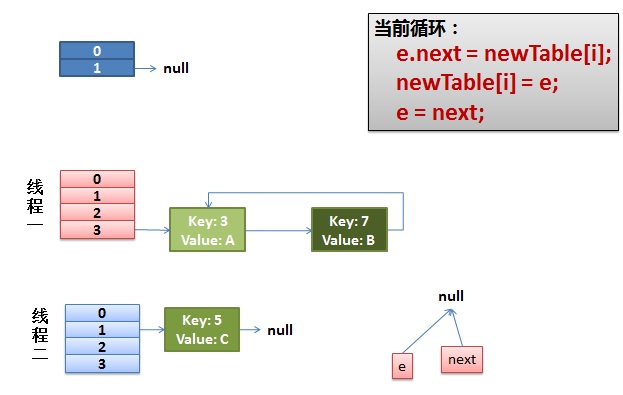
于是,当我们的线程一调用到,HashTable.get(11)时,悲剧就出现了——Infinite Loop。
LinkedHashMap
1. 概述
LinkedHashMap 继承自 HashMap,在 HashMap 基础上,通过维护一条双向链表,解决了 HashMap 不能随时保持遍历顺序和插入顺序一致的问题。除此之外,LinkedHashMap 对访问顺序也提供了相关支持。在一些场景下,该特性很有用,比如缓存。在实现上,LinkedHashMap 很多方法直接继承自 HashMap,仅为维护双向链表覆写了部分方法。所以,要看懂 LinkedHashMap 的源码,需要先看懂 HashMap 的源码。关于 HashMap 的源码分析,本文并不打算展开讲了。大家可以参考我之前的一篇文章“HashMap 源码详细分析(JDK1.8)”。在那篇文章中,我配了十多张图帮助大家学习 HashMap 源码。
本篇文章的结构与我之前两篇关于 Java 集合类(集合框架)的源码分析文章不同,本文将不再分析集合类的基本操作(查找、遍历、插入、删除),而是把重点放在双向链表的维护上。包括链表的建立过程,删除节点的过程,以及访问顺序维护的过程等。好了,接下里开始分析吧。
2. 原理
上一章说了 LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构。该结构由数组和链表或红黑树组成,结构示意图大致如下: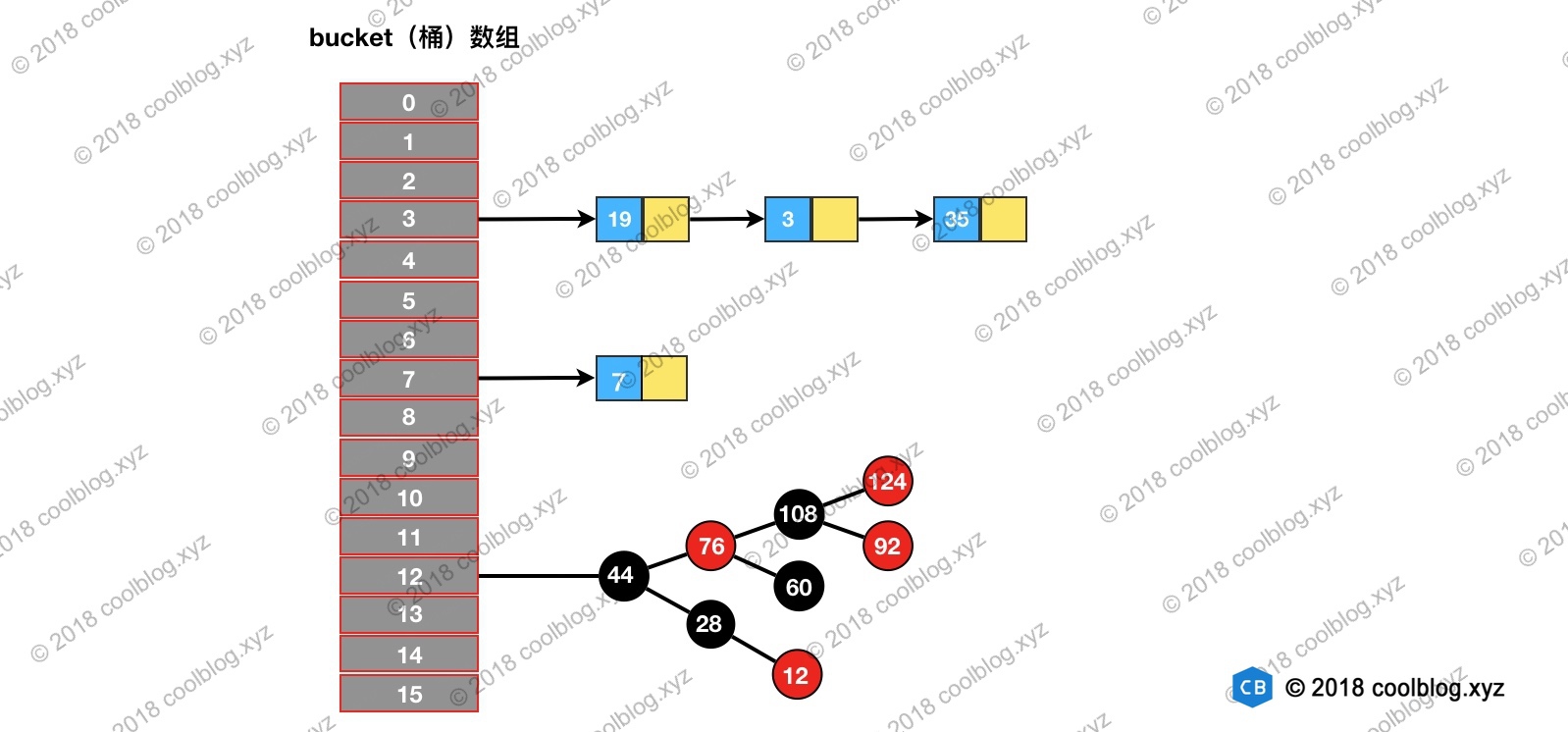
LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。其结构可能如下图: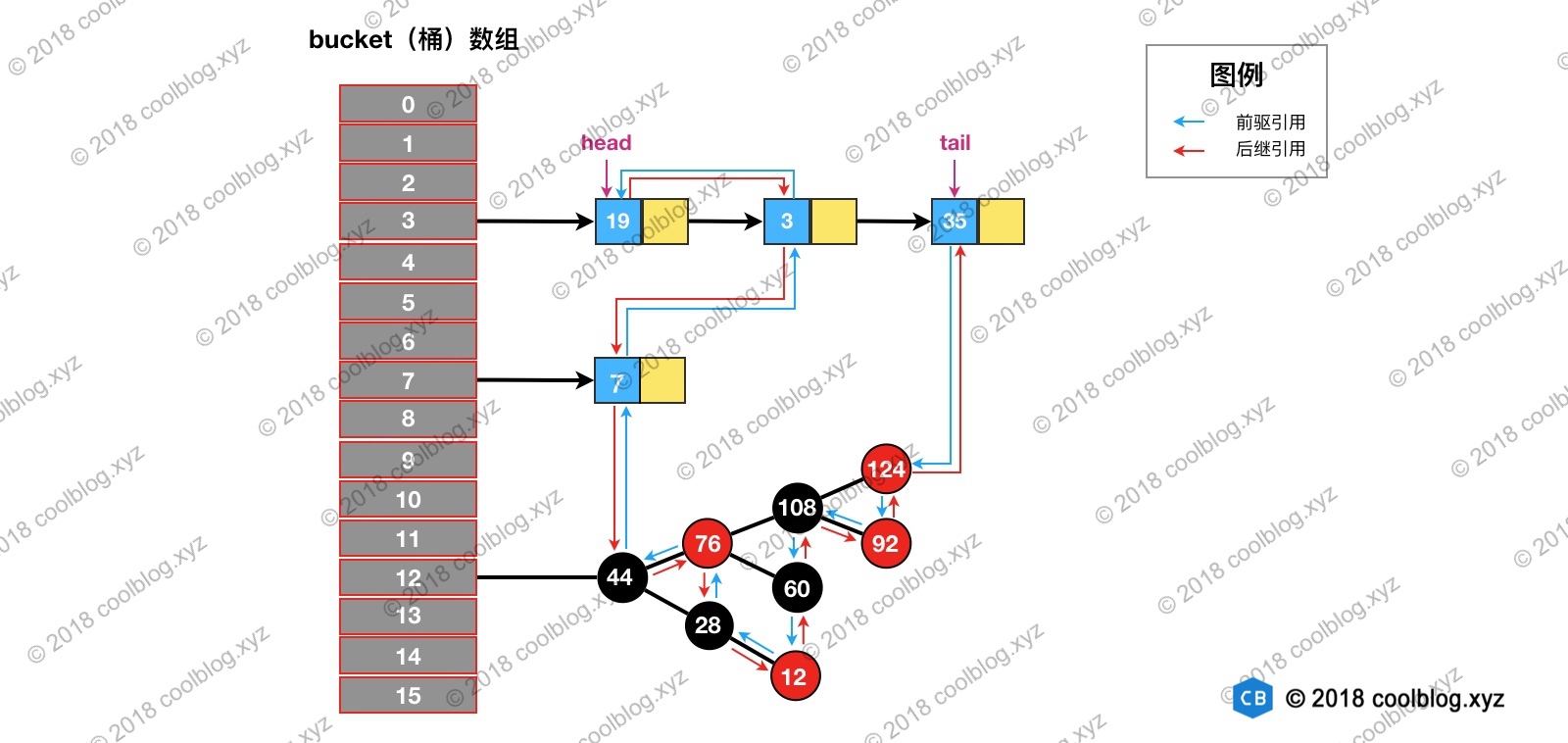
上图中,淡蓝色的箭头表示前驱引用,红色箭头表示后继引用。每当有新键值对节点插入,新节点最终会接在 tail 引用指向的节点后面。而 tail 引用则会移动到新的节点上,这样一个双向链表就建立起来了。
上面的结构并不是很难理解,虽然引入了红黑树,导致结构看起来略为复杂了一些。但大家完全可以忽略红黑树,而只关注链表结构本身。好了,接下来进入细节分析吧。
3. 源码分析
3.1 Entry 的继承体系
在对核心内容展开分析之前,这里先插队分析一下键值对节点的继承体系。先来看看继承体系结构图: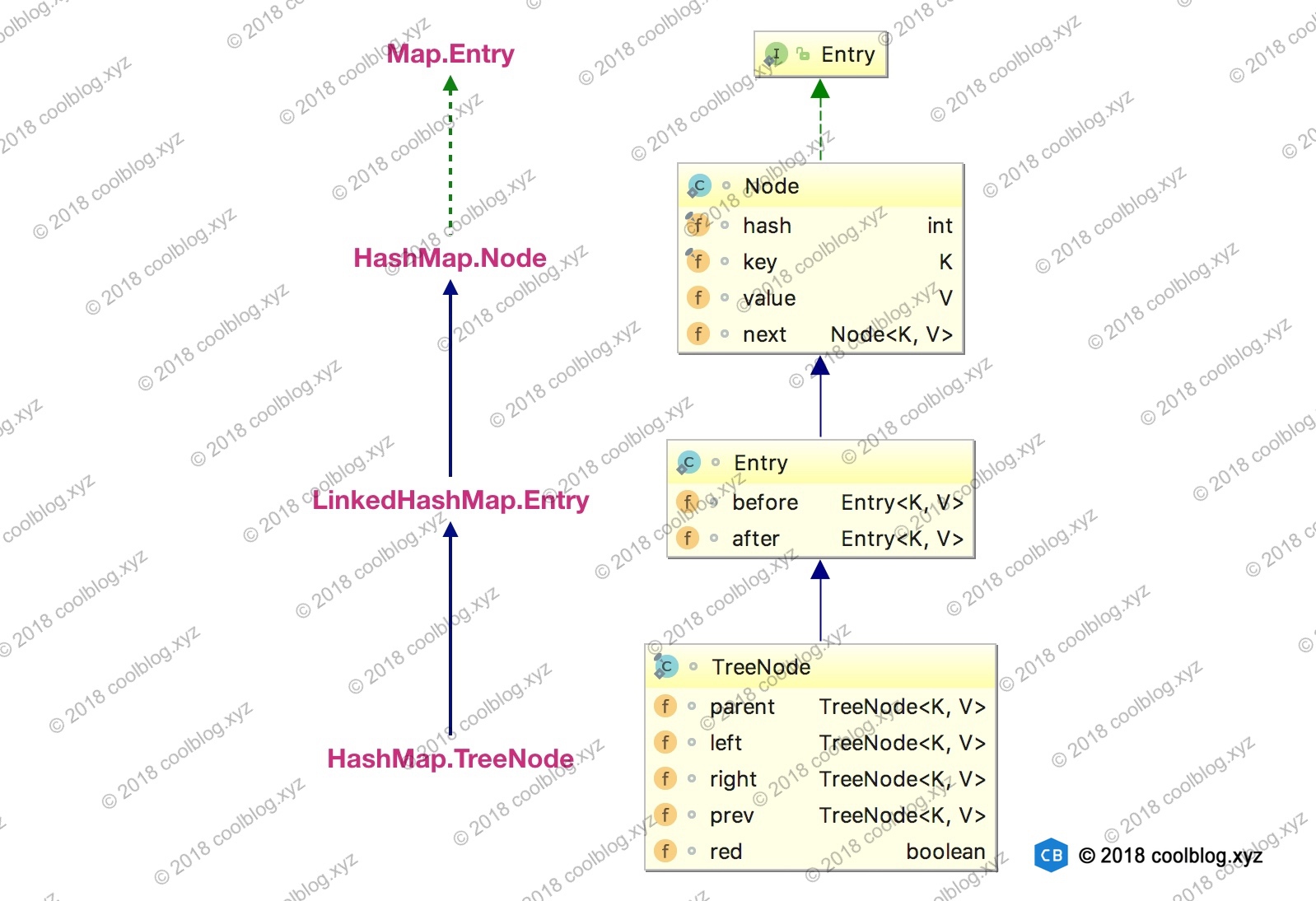
上面的继承体系乍一看还是有点复杂的,同时也有点让人迷惑。HashMap 的内部类 TreeNode 不继承它的了一个内部类 Node,却继承自 Node 的子类 LinkedHashMap 内部类 Entry。这里这样做是有一定原因的,这里先不说。先来简单说明一下上面的继承体系。LinkedHashMap 内部类 Entry 继承自 HashMap 内部类 Node,并新增了两个引用,分别是 before 和 after。这两个引用的用途不难理解,也就是用于维护双向链表。同时,TreeNode 继承 LinkedHashMap 的内部类 Entry 后,就具备了和其他 Entry 一起组成链表的能力。但是这里需要大家考虑一个问题。当我们使用 HashMap 时,TreeNode 并不需要具备组成链表能力。如果继承 LinkedHashMap 内部类 Entry ,TreeNode 就多了两个用不到的引用,这样做不是会浪费空间吗?简单说明一下这个问题(水平有限,不保证完全正确),这里这么做确实会浪费空间,但与 TreeNode 通过继承获取的组成链表的能力相比,这点浪费是值得的。在 HashMap 的设计思路注释中,有这样一段话:
Because TreeNodes are about twice the size of regular nodes, we use them only when bins contain enough nodes to warrant use (see TREEIFY_THRESHOLD). And when they become too small (due to removal or resizing) they are converted back to plain bins. In usages with well-distributed user hashCodes, tree bins are rarely used.
大致的意思是 TreeNode 对象的大小约是普通 Node 对象的2倍,我们仅在桶(bin)中包含足够多的节点时再使用。当桶中的节点数量变少时(取决于删除和扩容),TreeNode 会被转成 Node。当用户实现的 hashCode 方法具有良好分布性时,树类型的桶将会很少被使用。
通过上面的注释,我们可以了解到。一般情况下,只要 hashCode 的实现不糟糕,Node 组成的链表很少会被转成由 TreeNode 组成的红黑树。也就是说 TreeNode 使用的并不多,浪费那点空间是可接受的。假如 TreeNode 机制继承自 Node 类,那么它要想具备组成链表的能力,就需要 Node 去继承 LinkedHashMap 的内部类 Entry。这个时候就得不偿失了,浪费很多空间去获取不一定用得到的能力。
说到这里,大家应该能明白节点类型的继承体系了。这里单独拿出来说一下,为下面的分析做铺垫。叙述略为啰嗦,见谅。
3.1 链表的建立过程
链表的建立过程是在插入键值对节点时开始的,初始情况下,让 LinkedHashMap 的 head 和 tail 引用同时指向新节点,链表就算建立起来了。随后不断有新节点插入,通过将新节点接在 tail 引用指向节点的后面,即可实现链表的更新。
Map 类型的集合类是通过 put(K,V) 方法插入键值对,LinkedHashMap 本身并没有覆写父类的 put 方法,而是直接使用了父类的实现。但在 HashMap 中,put 方法插入的是 HashMap 内部类 Node 类型的节点,该类型的节点并不具备与 LinkedHashMap 内部类 Entry 及其子类型节点组成链表的能力。那么,LinkedHashMap 是怎样建立链表的呢?在展开说明之前,我们先看一下 LinkedHashMap 插入操作相关的代码:
// HashMap 中实现public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}// HashMap 中实现final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0) {...}// 通过节点 hash 定位节点所在的桶位置,并检测桶中是否包含节点引用if ((p = tab[i = (n - 1) & hash]) == null) {...}else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode) {...}else {// 遍历链表,并统计链表长度for (int binCount = 0; ; ++binCount) {// 未在单链表中找到要插入的节点,将新节点接在单链表的后面if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) {...}break;}// 插入的节点已经存在于单链表中if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null) {...}afterNodeAccess(e); // 回调方法,后续说明return oldValue;}}++modCount;if (++size > threshold) {...}afterNodeInsertion(evict); // 回调方法,后续说明return null;}// HashMap 中实现Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {return new Node<>(hash, key, value, next);}// LinkedHashMap 中覆写Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {LinkedHashMap.Entry<K,V> p =new LinkedHashMap.Entry<K,V>(hash, key, value, e);// 将 Entry 接在双向链表的尾部linkNodeLast(p);return p;}// LinkedHashMap 中实现private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {LinkedHashMap.Entry<K,V> last = tail;tail = p;// last 为 null,表明链表还未建立if (last == null)head = p;else {// 将新节点 p 接在链表尾部p.before = last;last.after = p;}}
上面就是 LinkedHashMap 插入相关的源码,这里省略了部分非关键的代码。我根据上面的代码,可以知道 LinkedHashMap 插入操作的调用过程。如下: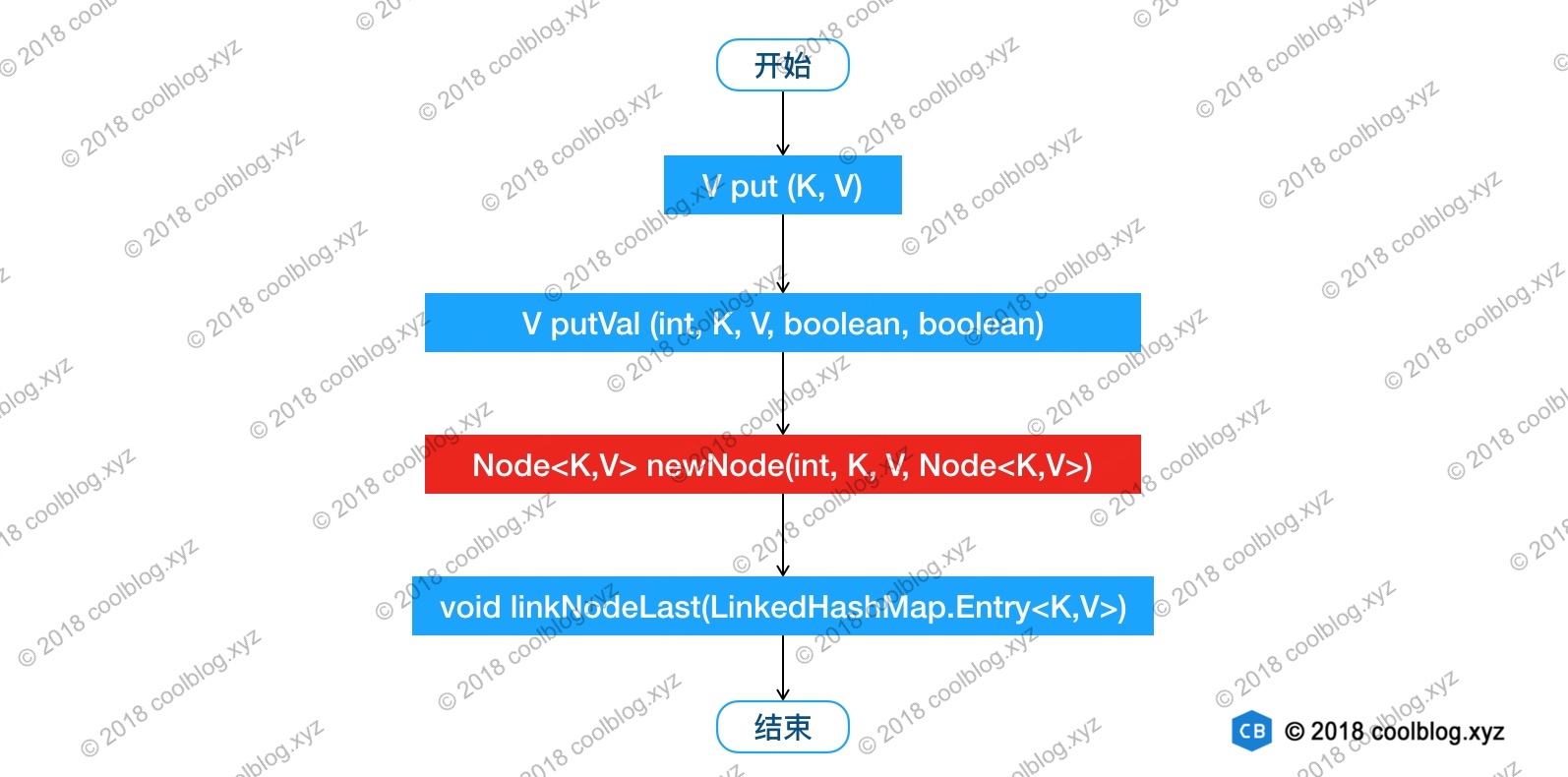
我把 newNode 方法红色背景标注了出来,这一步比较关键。LinkedHashMap 覆写了该方法。在这个方法中,LinkedHashMap 创建了 Entry,并通过 linkNodeLast 方法将 Entry 接在双向链表的尾部,实现了双向链表的建立。双向链表建立之后,我们就可以按照插入顺序去遍历 LinkedHashMap,大家可以自己写点测试代码验证一下插入顺序。
以上就是 LinkedHashMap 维护插入顺序的相关分析。本节的最后,再额外补充一些东西。大家如果仔细看上面的代码的话,会发现有两个以after开头方法,在上文中没有被提及。在 JDK 1.8 HashMap 的源码中,相关的方法有3个:
// Callbacks to allow LinkedHashMap post-actionsvoid afterNodeAccess(Node<K,V> p) { }void afterNodeInsertion(boolean evict) { }void afterNodeRemoval(Node<K,V> p) { }
根据这三个方法的注释可以看出,这些方法的用途是在增删查等操作后,通过回调的方式,让 LinkedHashMap 有机会做一些后置操作。上述三个方法的具体实现在 LinkedHashMap 中,本节先不分析这些实现,相关分析会在后续章节中进行。
3.2 链表节点的删除过程
与插入操作一样,LinkedHashMap 删除操作相关的代码也是直接用父类的实现。在删除节点时,父类的删除逻辑并不会修复 LinkedHashMap 所维护的双向链表,这不是它的职责。那么删除及节点后,被删除的节点该如何从双链表中移除呢?当然,办法还算是有的。上一节最后提到 HashMap 中三个回调方法运行 LinkedHashMap 对一些操作做出响应。所以,在删除及节点后,回调方法 afterNodeRemoval 会被调用。LinkedHashMap 覆写该方法,并在该方法中完成了移除被删除节点的操作。相关源码如下:
// HashMap 中实现public V remove(Object key) {Node<K,V> e;return (e = removeNode(hash(key), key, null, false, true)) == null ?null : e.value;}// HashMap 中实现final Node<K,V> removeNode(int hash, Object key, Object value,boolean matchValue, boolean movable) {Node<K,V>[] tab; Node<K,V> p; int n, index;if ((tab = table) != null && (n = tab.length) > 0 &&(p = tab[index = (n - 1) & hash]) != null) {Node<K,V> node = null, e; K k; V v;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))node = p;else if ((e = p.next) != null) {if (p instanceof TreeNode) {...}else {// 遍历单链表,寻找要删除的节点,并赋值给 node 变量do {if (e.hash == hash &&((k = e.key) == key ||(key != null && key.equals(k)))) {node = e;break;}p = e;} while ((e = e.next) != null);}}if (node != null && (!matchValue || (v = node.value) == value ||(value != null && value.equals(v)))) {if (node instanceof TreeNode) {...}// 将要删除的节点从单链表中移除else if (node == p)tab[index] = node.next;elsep.next = node.next;++modCount;--size;afterNodeRemoval(node); // 调用删除回调方法进行后续操作return node;}}return null;}// LinkedHashMap 中覆写void afterNodeRemoval(Node<K,V> e) { // unlinkLinkedHashMap.Entry<K,V> p =(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;// 将 p 节点的前驱后后继引用置空p.before = p.after = null;// b 为 null,表明 p 是头节点if (b == null)head = a;elseb.after = a;// a 为 null,表明 p 是尾节点if (a == null)tail = b;elsea.before = b;}
删除的过程并不复杂,上面这么多代码其实就做了三件事:
- 根据 hash 定位到桶位置
- 遍历链表或调用红黑树相关的删除方法
- 从 LinkedHashMap 维护的双链表中移除要删除的节点
举个例子说明一下,假如我们要删除下图键值为 3 的节点。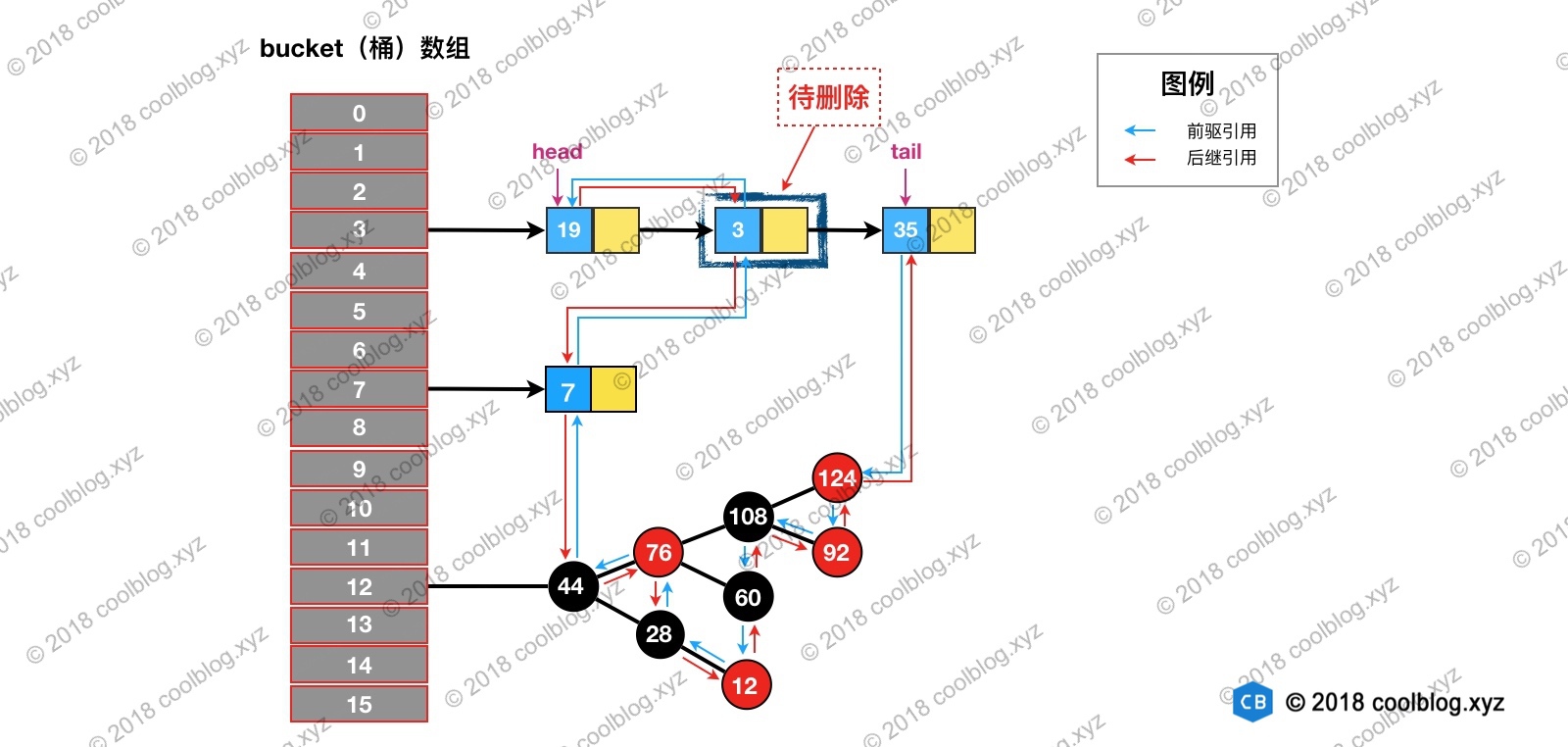
根据 hash 定位到该节点属于3号桶,然后在对3号桶保存的单链表进行遍历。找到要删除的节点后,先从单链表中移除该节点。如下: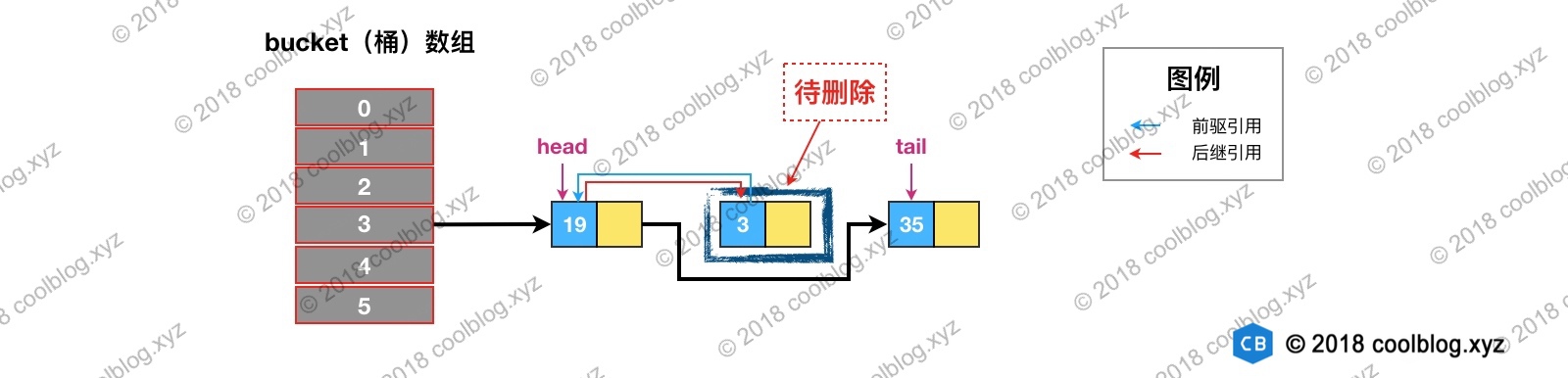
然后再双向链表中移除该节点:
删除及相关修复过程并不复杂,结合上面的图片,大家应该很容易就能理解,这里就不多说了。
3.3 访问顺序的维护过程
前面说了插入顺序的实现,本节来讲讲访问顺序。默认情况下,LinkedHashMap 是按插入顺序维护链表。不过我们可以在初始化 LinkedHashMap,指定 accessOrder 参数为 true,即可让它按访问顺序维护链表。访问顺序的原理上并不复杂,当我们调用get/getOrDefault/replace等方法时,只需要将这些方法访问的节点移动到链表的尾部即可。相应的源码如下:
// LinkedHashMap 中覆写public V get(Object key) {Node<K,V> e;if ((e = getNode(hash(key), key)) == null)return null;// 如果 accessOrder 为 true,则调用 afterNodeAccess 将被访问节点移动到链表最后if (accessOrder)afterNodeAccess(e);return e.value;}// LinkedHashMap 中覆写void afterNodeAccess(Node<K,V> e) { // move node to lastLinkedHashMap.Entry<K,V> last;if (accessOrder && (last = tail) != e) {LinkedHashMap.Entry<K,V> p =(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;p.after = null;// 如果 b 为 null,表明 p 为头节点if (b == null)head = a;elseb.after = a;if (a != null)a.before = b;/** 这里存疑,父条件分支已经确保节点 e 不会是尾节点,* 那么 e.after 必然不会为 null,不知道 else 分支有什么作用*/elselast = b;if (last == null)head = p;else {// 将 p 接在链表的最后p.before = last;last.after = p;}tail = p;++modCount;}}
上面就是访问顺序的实现代码,并不复杂。下面举例演示一下,帮助大家理解。假设我们访问下图键值为3的节点,访问前结构为: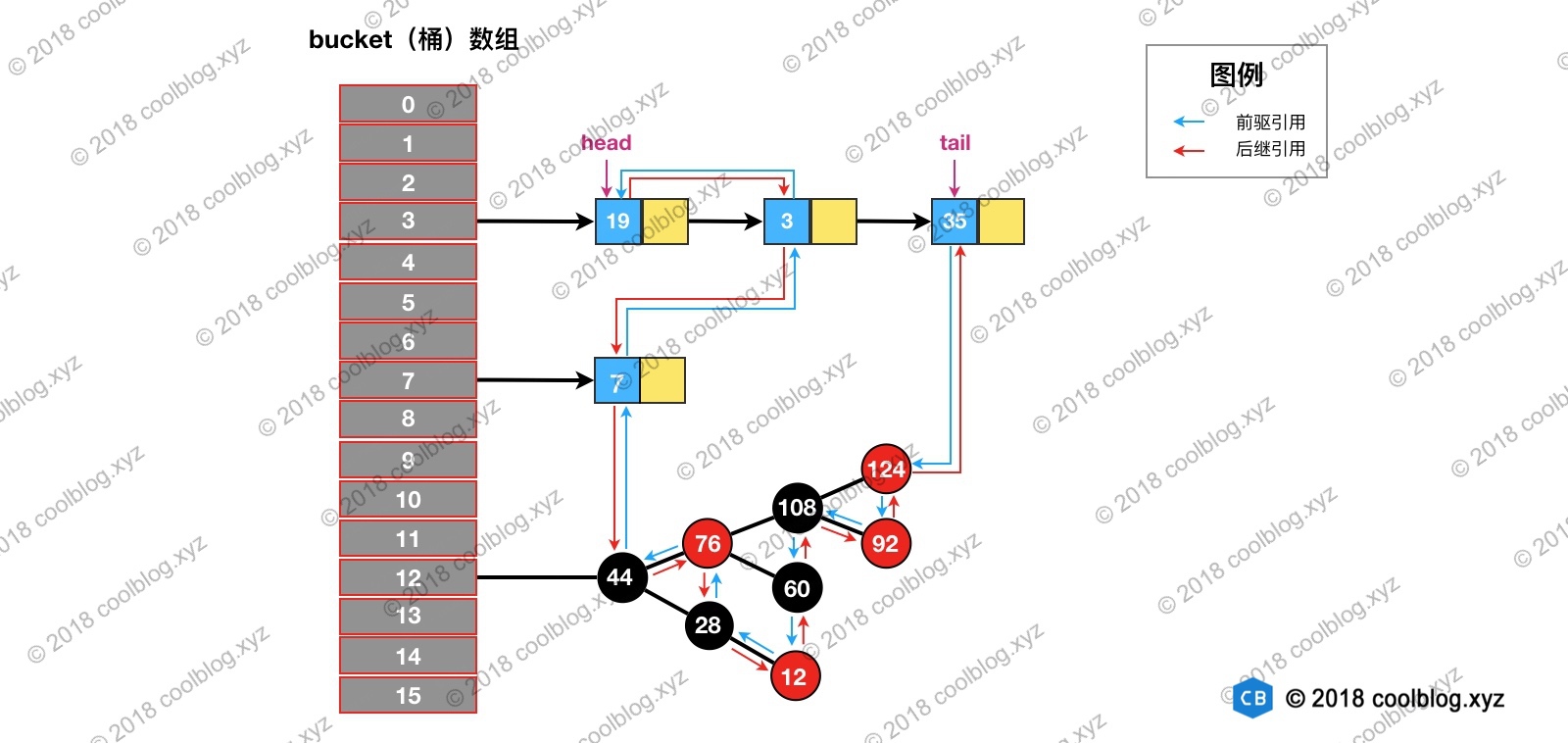
访问后,键值为3的节点将会被移动到双向链表的最后位置,其前驱和后继也会跟着更新。访问后的结构如下: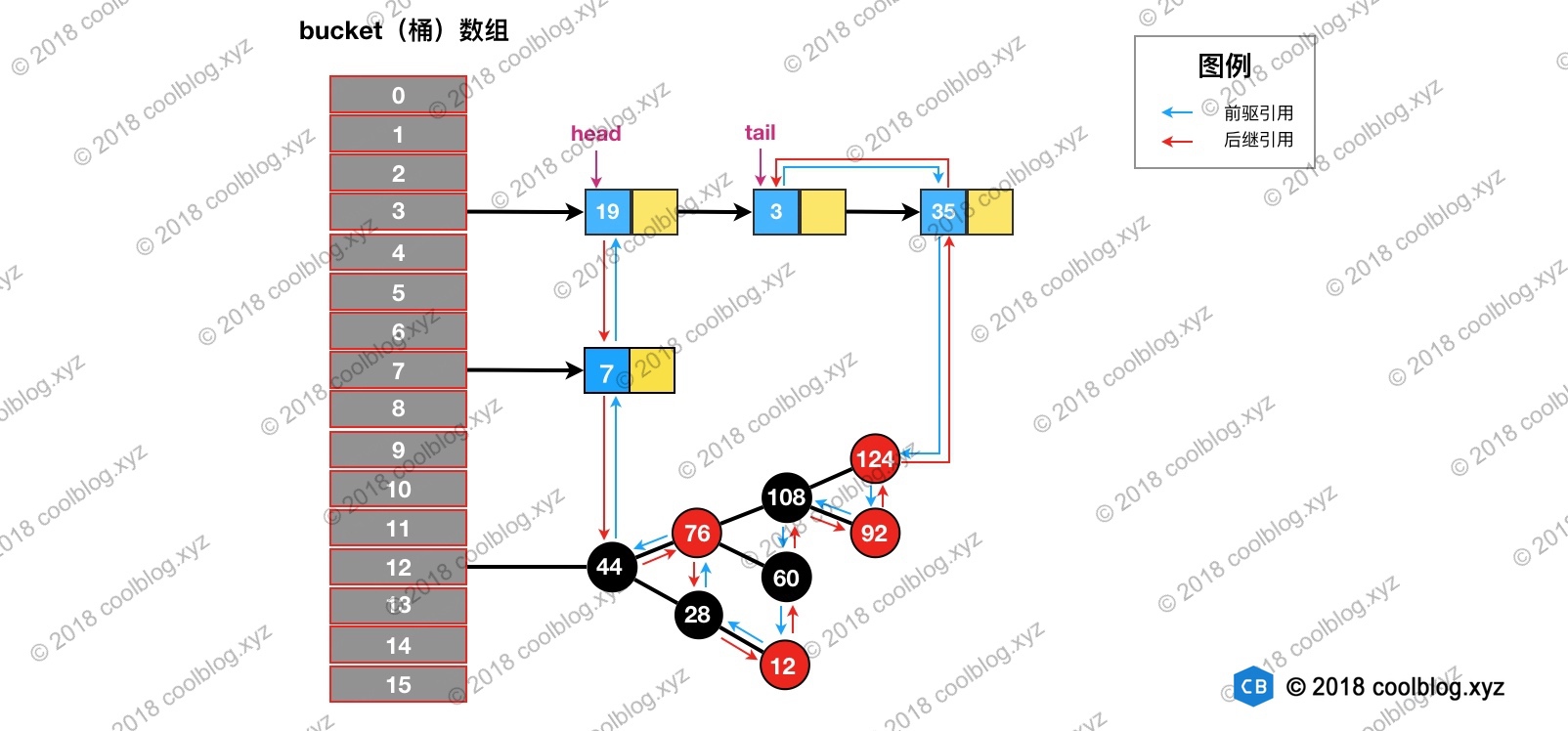
3.4 基于 LinkedHashMap 实现缓存
前面介绍了 LinkedHashMap 是如何维护插入和访问顺序的,大家对 LinkedHashMap 的原理应该有了一定的认识。本节我们来写一些代码实践一下,这里通过继承 LinkedHashMap 实现了一个简单的 LRU 策略的缓存。在写代码之前,先介绍一下前置知识。
在3.1节分析链表建立过程时,我故意忽略了部分源码分析。本节就把忽略的部分补上,先看源码吧:
void afterNodeInsertion(boolean evict) { // possibly remove eldestLinkedHashMap.Entry<K,V> first;// 根据条件判断是否移除最近最少被访问的节点if (evict && (first = head) != null && removeEldestEntry(first)) {K key = first.key;removeNode(hash(key), key, null, false, true);}}// 移除最近最少被访问条件之一,通过覆盖此方法可实现不同策略的缓存protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {return false;}
上面的源码的核心逻辑在一般情况下都不会被执行,所以之前并没有进行分析。上面的代码做的事情比较简单,就是通过一些条件,判断是否移除最近最少被访问的节点。看到这里,大家应该知道上面两个方法的用途了。当我们基于 LinkedHashMap 实现缓存时,通过覆写removeEldestEntry方法可以实现自定义策略的 LRU 缓存。比如我们可以根据节点数量判断是否移除最近最少被访问的节点,或者根据节点的存活时间判断是否移除该节点等。本节所实现的缓存是基于判断节点数量是否超限的策略。在构造缓存对象时,传入最大节点数。当插入的节点数超过最大节点数时,移除最近最少被访问的节点。实现代码如下:
public class SimpleCache<K, V> extends LinkedHashMap<K, V> {private static final int MAX_NODE_NUM = 100;private int limit;public SimpleCache() {this(MAX_NODE_NUM);}public SimpleCache(int limit) {super(limit, 0.75f, true);this.limit = limit;}public V save(K key, V val) {return put(key, val);}public V getOne(K key) {return get(key);}public boolean exists(K key) {return containsKey(key);}/*** 判断节点数是否超限* @param eldest* @return 超限返回 true,否则返回 false*/@Overrideprotected boolean removeEldestEntry(Map.Entry<K, V> eldest) {return size() > limit;}}
测试代码如下:
public class SimpleCacheTest {@Testpublic void test() throws Exception {SimpleCache<Integer, Integer> cache = new SimpleCache<>(3);for (int i = 0; i < 10; i++) {cache.save(i, i * i);}System.out.println("插入10个键值对后,缓存内容:");System.out.println(cache + "\n");System.out.println("访问键值为7的节点后,缓存内容:");cache.getOne(7);System.out.println(cache + "\n");System.out.println("插入键值为1的键值对后,缓存内容:");cache.save(1, 1);System.out.println(cache);}}
测试结果如下: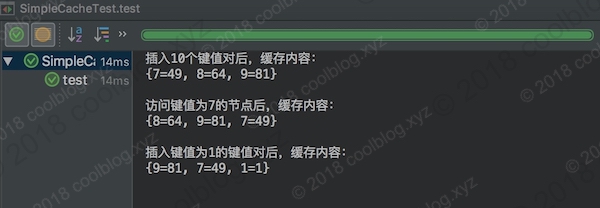
在测试代码中,设定缓存大小为3。在向缓存中插入10个键值对后,只有最后3个被保存下来了,其他的都被移除了。然后通过访问键值为7的节点,使得该节点被移到双向链表的最后位置。当我们再次插入一个键值对时,键值为7的节点就不会被移除。
本节作为对前面内的补充,简单介绍了 LinkedHashMap 在其他方面的应用。本节内容及相关代码并不难理解,这里就不在赘述了。
4. 总结
本文从 LinkedHashMap 维护双向链表的角度对 LinkedHashMap 的源码进行了分析,并在文章的结尾基于 LinkedHashMap 实现了一个简单的 Cache。在日常开发中,LinkedHashMap 的使用频率虽不及 HashMap,但它也个重要的实现。在 Java 集合框架中,HashMap、LinkedHashMap 和 TreeMap 三个映射类基于不同的数据结构,并实现了不同的功能。HashMap 底层基于拉链式的散列结构,并在 JDK 1.8 中引入红黑树优化过长链表的问题。基于这样结构,HashMap 可提供高效的增删改查操作。LinkedHashMap 在其之上,通过维护一条双向链表,实现了散列数据结构的有序遍历。TreeMap 底层基于红黑树实现,利用红黑树的性质,实现了键值对排序功能。我在前面几篇文章中,对 HashMap 和 TreeMap 以及他们均使用到的红黑树进行了详细的分析,有兴趣的朋友可以去看看。
TreeMap
按照惯例,我简单翻译了一下顶部的注释(我英文水平渣,如果有错的地方请多多包涵~欢迎在评论区下指正)
接着我们来看看类继承图: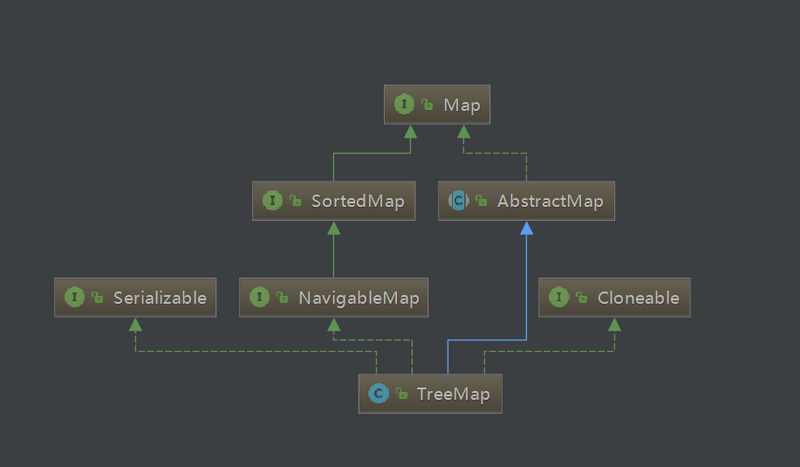
在注释中提到的要点,我来总结一下:
- TreeMap实现了NavigableMap接口,而NavigableMap接口继承着SortedMap接口,致使我们的TreeMap是有序的!
- TreeMap底层是红黑树,它方法的时间复杂度都不会太高:log(n)~
- 非同步
- 使用Comparator或者Comparable来比较key是否相等与排序的问题~
对我而言,Comparator和Comparable我都忘得差不多了~~~下面就开始看TreeMap的源码来看看它是怎么实现的,并且回顾一下Comparator和Comparable的用法吧!
1.1TreeMap的域
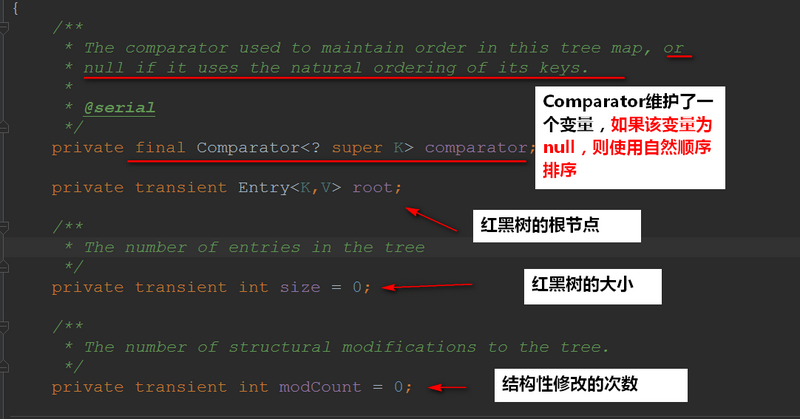
1.2TreeMap构造方法
TreeMap的构造方法有4个: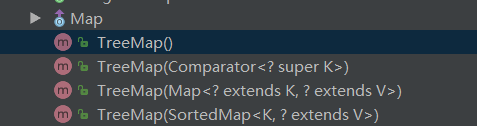
可以发现,TreeMap的构造方法大多数与comparator有关:
也就是顶部注释说的:TreeMap有序是通过Comparator来进行比较的,如果comparator为null,那么就使用自然顺序~
打个比方:
如果value是整数,自然顺序指的就是我们平常排序的顺序(1,2,3,4,5..)~
TreeMap<Integer, Integer> treeMap = new TreeMap<>();treeMap.put(1, 5);treeMap.put(2, 4);treeMap.put(3, 3);treeMap.put(4, 2);treeMap.put(5, 1);for (Entry<Integer, Integer> entry : treeMap.entrySet()) {String s = entry.getKey() +"关注公众号:Java3y---->" + entry.getValue();System.out.println(s);}
1.3put方法
我们来看看TreeMap的核心put方法,阅读它就可以获取不少关于TreeMap特性的东西了~
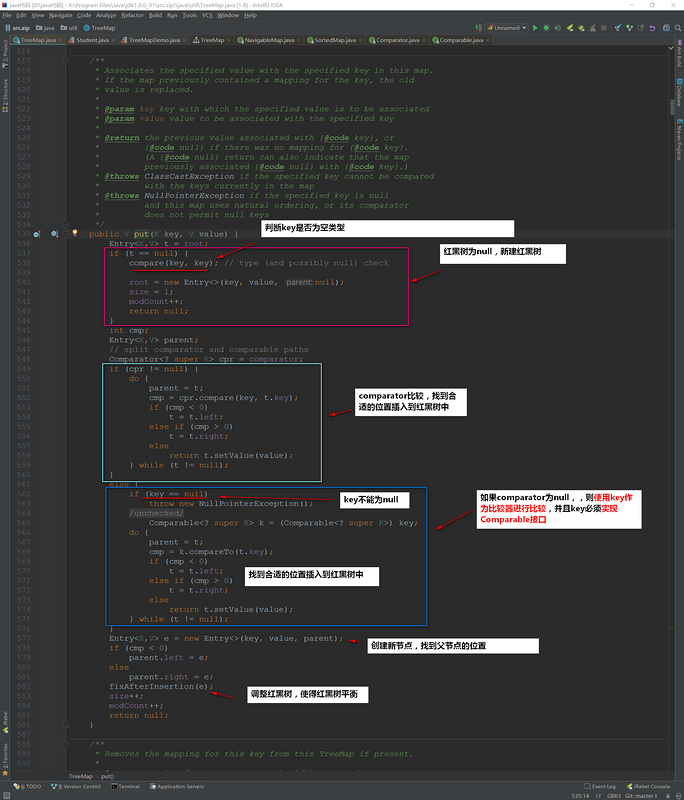
下面是compare(Object k1, Object k2)方法/*** Compares two keys using the correct comparison method for this TreeMap.*/@SuppressWarnings("unchecked")final int compare(Object k1, Object k2) {return comparator==null ? ((Comparable<? super K>)k1).compareTo((K)k2): comparator.compare((K)k1, (K)k2);}
如果我们设置key为null,会抛出异常的,就不执行下面的代码了。

1.4get方法
接下来我们来看看get方法的实现:
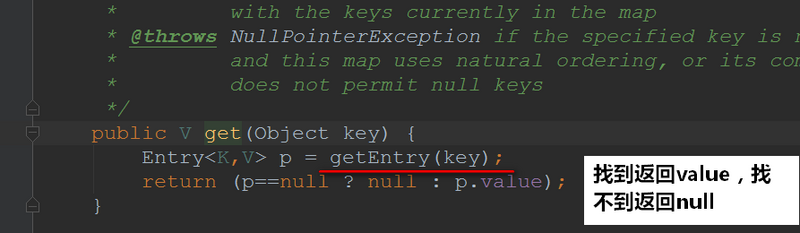
点进去getEntry()看看实现: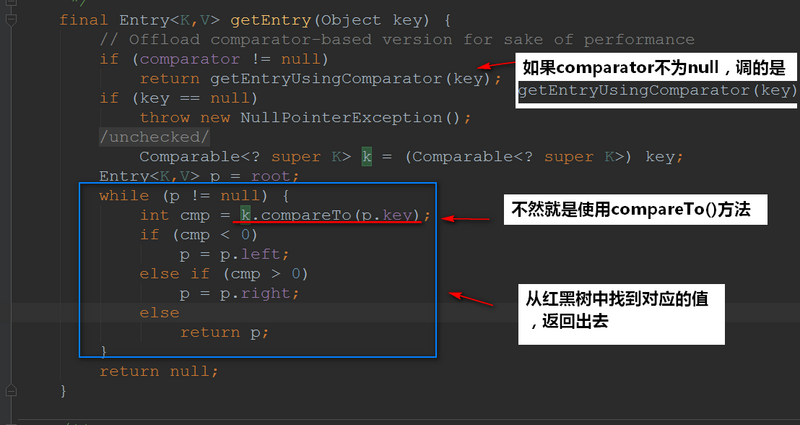
如果Comparator不为null,接下来我们进去看看getEntryUsingComparator(Object key),是怎么实现的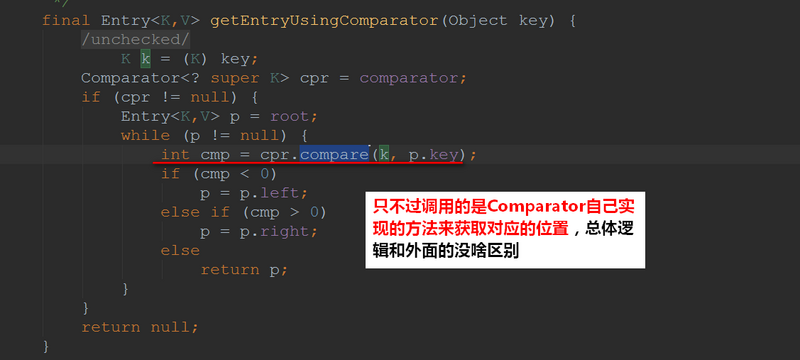
1.5remove方法
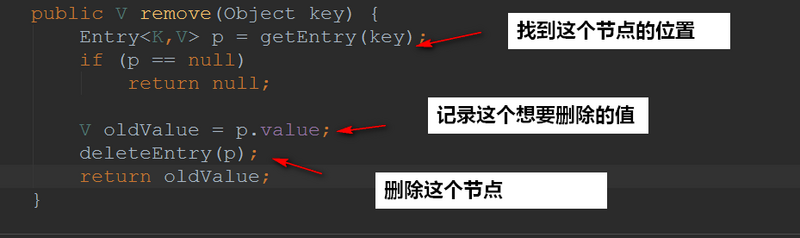
删除节点的时候调用的是deleteEntry(Entry<K,V> p)方法,这个方法主要是删除节点并且平衡红黑树
平衡红黑树的代码是比较复杂的,我就不说了,你们去看吧(反正我看不懂)….1.6遍历方法
在看源码的时候可能不知道哪个是核心的遍历方法,因为Iterator有非常非常多~
此时,我们只需要debug一下看看,跟下去就好!

于是乎,我们可以找到:TreeMap遍历是使用EntryIterator这个内部类的
首先来看看EntryIterator的类结构图吧: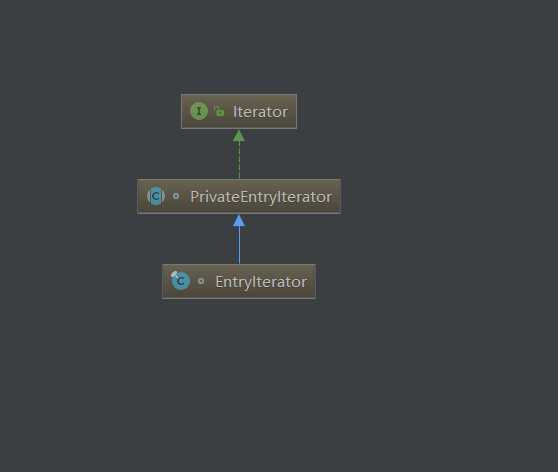
可以发现,EntryIterator大多的实现都是在父类中: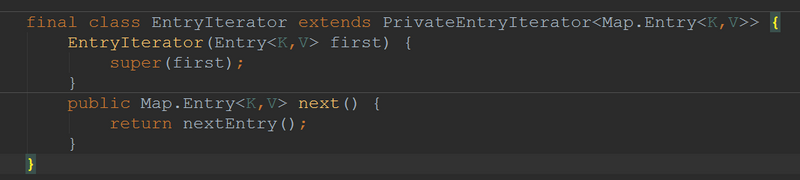
那接下来我们去看看PrivateEntryIterator比较重要的方法: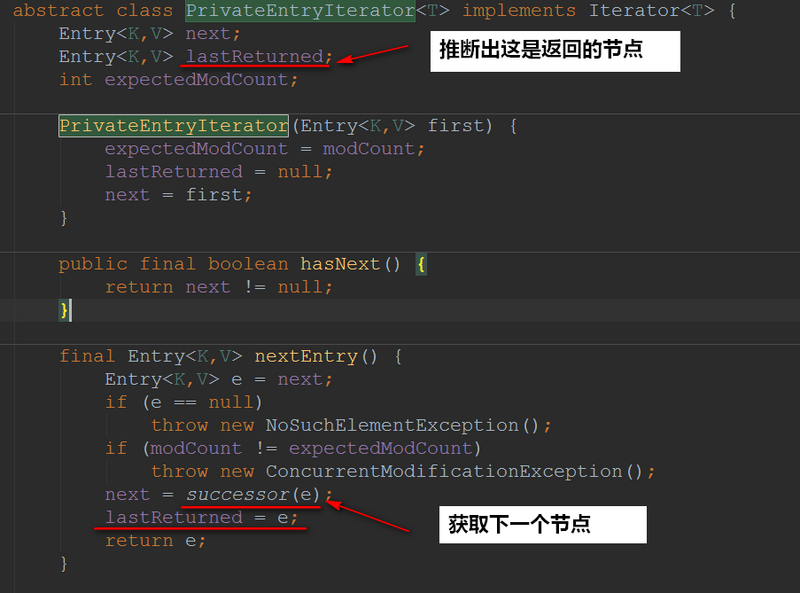
我们进去successor(e)方法看看实现: successor 其实就是一个结点的 下一个结点,所谓 下一个,是按次序排序后的下一个结点。从代码中可以看出,如果右子树不为空,就返回右子树中最小结点。如果右子树为空,就要向上回溯了。在这种情况下,t 是以其为根的树的最后一个结点。如果它是其父结点的左孩子,那么父结点就是它的下一个结点,否则,t 就是以其父结点为根的树的最后一个结点,需要再次向上回溯。一直到 ch 是 p 的左孩子为止。 来源:https://blog.csdn.net/on_1y/article/details/27231855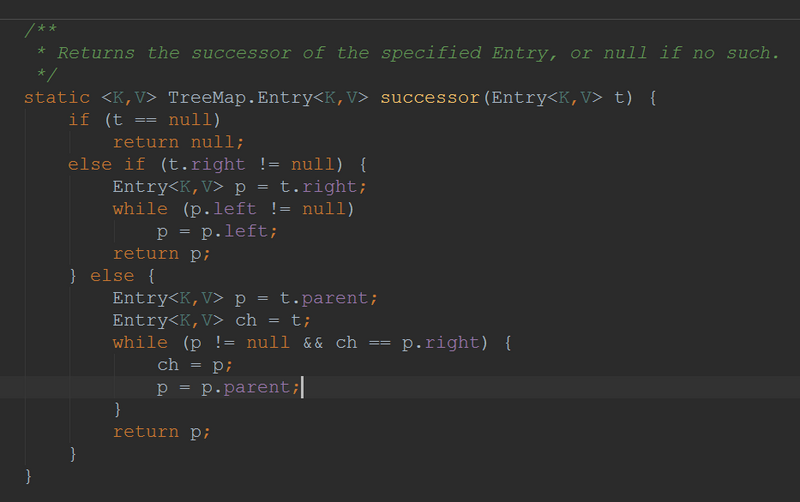
总结
TreeMap底层是红黑树,能够实现该Map集合有序~
如果在构造方法中传递了Comparator对象,那么就会以Comparator对象的方法进行比较。否则,则使用Comparable的compareTo(T o)方法来比较。值得说明的是:如果使用的是
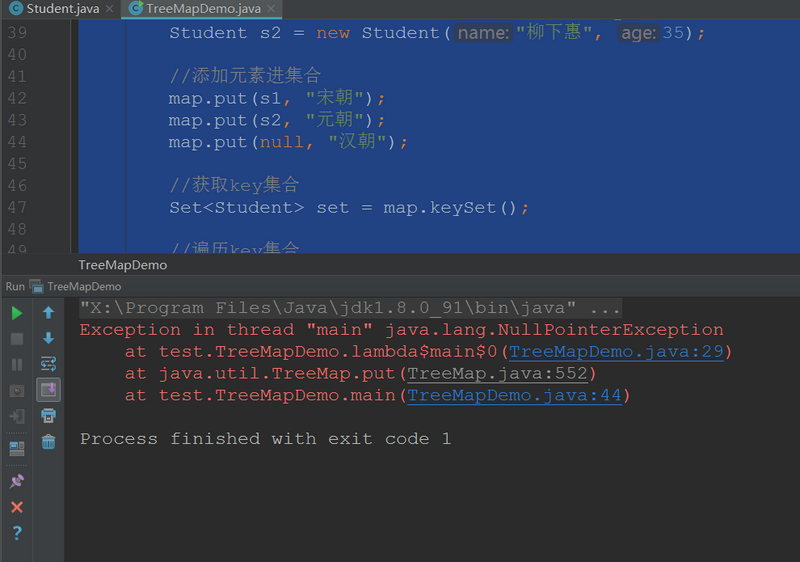
compareTo(T o)方法来比较,key一定是不能为null,并且得实现了Comparable接口的。- 即使是传入了Comparator对象,不用
compareTo(T o)方法来比较,key也是不能为null的public static void main(String[] args) {TreeMap<Student, String> map = new TreeMap<Student, String>((o1, o2) -> {//主要条件int num = o1.getAge() - o2.getAge();//次要条件int num2 = num == 0 ? o1.getName().compareTo(o2.getName()) : num;return num2;});//创建学生对象Student s1 = new Student("潘安", 30);Student s2 = new Student("柳下惠", 35);//添加元素进集合map.put(s1, "宋朝");map.put(s2, "元朝");map.put(null, "汉朝");//获取key集合Set<Student> set = map.keySet();//遍历key集合for (Student student : set) {String value = map.get(student);System.out.println(student + "---------" + value);}}
我们从源码中的很多地方中发现:Comparator和Comparable出现的频率是很高的,因为TreeMap实现有序要么就是外界传递进来Comparator对象,要么就使用默认key的Comparable接口(实现自然排序)
最后我就来总结一下TreeMap要点吧:
- 由于底层是红黑树,那么时间复杂度可以保证为log(n)
- key不能为null,为null为抛出NullPointException的
- 想要自定义比较,在构造方法中传入Comparator对象,否则使用key的自然排序来进行比较
TreeMap非同步的,想要同步可以使用Collections来进行封装
自己实现一个一致性 Hash 算法(基于TreeMap)
前言
在前文分布式理论(八)—— Consistent Hash(一致性哈希算法)中,我们讨论了一致性 hash 算法的原理,并说了,我们会自己写一个简单的算法。今天就来写一个。
普通 hash 的结果
先看看普通 hash 怎么做。
首先,需要缓存节点对象,缓存中的存储对象,还有一个缓存节点集合,用于保存有效的缓存节点。实际存储对象,很简单的一个类,只需要获取他的 hash 值就好:
static class Obj {String key;Obj(String key) {this.key = key;}@Overridepublic int hashCode() {return key.hashCode();}@Overridepublic String toString() {return "Obj{" +"key='" + key + '\'' +'}';}}复制代码
缓存节点对象,用于存储实际对象:
static class Node {Map<Integer, Obj> node = new HashMap<>();String name;Node(String name) {this.name = name;}public void putObj(Obj obj) {node.put(obj.hashCode(), obj);}Obj getObj(Obj obj) {return node.get(obj.hashCode());}@Overridepublic int hashCode() {return name.hashCode();}}复制代码
也很简单,内部使用了一个 map 保存节点。
缓存节点集合,用于保存有效的缓存节点:
static class NodeArray {Node[] nodes = new Node[1024];int size = 0;public void addNode(Node node) {nodes[size++] = node;}Obj get(Obj obj) {int index = obj.hashCode() % size;return nodes[index].getObj(obj);}void put(Obj obj) {int index = obj.hashCode() % size;nodes[index].putObj(obj);}}复制代码
内部一个数组,取数据时,通过取余机器数量获取缓存节点,再从节点中取出数据。
测试:当增减节点时,还能不能找到原有数据:
/*** 验证普通 hash 对于增减节点,原有会不会出现移动。*/public static void main(String[] args) {NodeArray nodeArray = new NodeArray();Node[] nodes = {new Node("Node--> 1"),new Node("Node--> 2"),new Node("Node--> 3")};for (Node node : nodes) {nodeArray.addNode(node);}Obj[] objs = {new Obj("1"),new Obj("2"),new Obj("3"),new Obj("4"),new Obj("5")};for (Obj obj : objs) {nodeArray.put(obj);}validate(nodeArray, objs);}复制代码
private static void validate(NodeArray nodeArray, Obj[] objs) {for (Obj obj : objs) {System.out.println(nodeArray.get(obj));}nodeArray.addNode(new Node("anything1"));nodeArray.addNode(new Node("anything2"));System.out.println("========== after =============");for (Obj obj : objs) {System.out.println(nodeArray.get(obj));}}复制代码
测试步骤如下:
向集合中添加 3 个节点。
- 向
集群中添加 5 个对象,这 5 个对象会根据 hash 值散列到不同的节点中。 - 打印
未增减前的数据。 - 打印
增加 2 个节点后数据,看看还能不能访问到数据。
结果: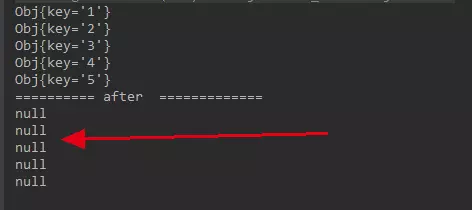
一个都访问不到了。这就是普通的取余的缺点,在增减机器的情况下,这种结果无法接收。
再看看一致性 hash 如何解决。
一致性 Hash 的结果
关键的地方来了。
缓存节点对象和实际保存对象不用更改,改的是什么?
改的是保存对象的方式和取出对象的方式,也就是不使用对机器进行取余的算法。
新的 NodeArray 对象如下:
static class NodeArray {/** 按照 键 排序*/TreeMap<Integer, Node> nodes = new TreeMap<>();void addNode(Node node) {nodes.put(node.hashCode(), node);}void put(Obj obj) {int objHashcode = obj.hashCode();Node node = nodes.get(objHashcode);if (node != null) {node.putObj(obj);return;}// 找到比给定 key 大的集合SortedMap<Integer, Node> tailMap = nodes.tailMap(objHashcode);// 找到最小的节点int nodeHashcode = tailMap.isEmpty() ? nodes.firstKey() : tailMap.firstKey();nodes.get(nodeHashcode).putObj(obj);}Obj get(Obj obj) {Node node = nodes.get(obj.hashCode());if (node != null) {return node.getObj(obj);}// 找到比给定 key 大的集合SortedMap<Integer, Node> tailMap = nodes.tailMap(obj.hashCode());// 找到最小的节点int nodeHashcode = tailMap.isEmpty() ? nodes.firstKey() : tailMap.firstKey();return nodes.get(nodeHashcode).getObj(obj);}}复制代码
该类和之前的类的不同之处在于:
- 内部没有使用数组,而是使用了有序 Map。
- put 方法中,对象如果没有落到缓存节点上,就找比他小的节点且离他最近的。这里我们使用了 TreeMap 的 tailMap 方法,具体 API 可以看文档。
- get 方法中,和 put 步骤相同,否则是取不到对象的。
具体寻找节点的方式如图: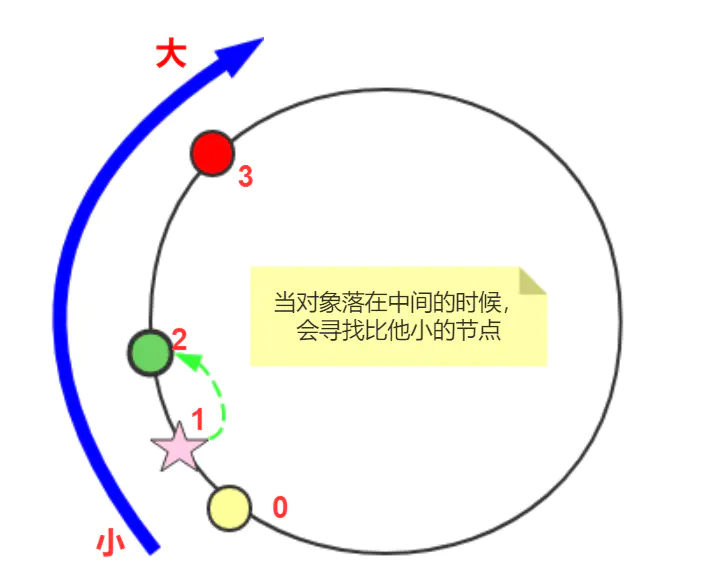
相同的测试用例,执行结果如下: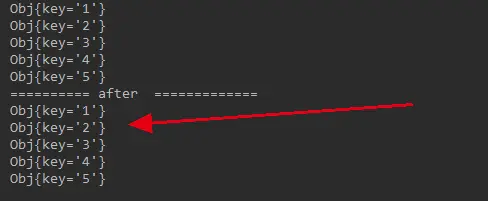
找到了之前所有的节点。解决了普通 hash 的问题。
总结
代码比较简单,主要是通过 JDK 自带的 TreeMap 实现的寻找临近节点。当然,我们这里也只是测试了添加,关于修改还没有测试,但思路是一样的。这里只是做一个抛砖引玉。
同时,我们也没有实现虚拟节点,感兴趣的朋友可以尝试一下。
good luck!!!!
HashSet
HashSet 源码只有短短的 300 行,上文也阐述了实现依赖于 HashMap,这一点充分体现在其构造方法和成员变量上。我们来看下 HashSet 的构造方法和成员变量:
// HashSet 真实的存储元素结构private transient HashMap<E,Object> map;// 作为各个存储在 HashMap 元素的键值对中的 Valueprivate static final Object PRESENT = new Object();//空参数构造方法 调用 HashMap 的空构造参数//初始化了 HashMap 中的加载因子 loadFactor = 0.75fpublic HashSet() {map = new HashMap<>();}//指定期望容量的构造方法public HashSet(int initialCapacity) {map = new HashMap<>(initialCapacity);}//指定期望容量和加载因子public HashSet(int initialCapacity, float loadFactor) {map = new HashMap<>(initialCapacity, loadFactor);}//使用指定的集合填充Setpublic HashSet(Collection<? extends E> c) {//调用 new HashMap<>(initialCapacity) 其中初始期望容量为 16 和 c 容量 / 默认 load factor 后 + 1的较大值map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));addAll(c);}// 该方法为 default 访问权限,不允许使用者直接调用,目的是为了初始化 LinkedHashSet 时使用HashSet(int initialCapacity, float loadFactor, boolean dummy) {map = new LinkedHashMap<>(initialCapacity, loadFactor);}
通过 HashSet 的构造参数我们可以看出每个构造方法,都调用了对应的 HashMap 的构造方法用来初始化成员变量 map ,因此我们可以知道,HashSet 的初始容量也为 1<<4 即16,加载因子默认也是 0.75f。
我们都知道 Set 不允许存储重复元素,又由构造参数得出结论底层存储结构为 HashMap,那么这个不可重复的属性必然是有 HashMap 中存储键值对的 Key 来实现了。在分析 HashMap 的时候,提到过 HashMap 通过存储键值对的 Key 的 hash 值(经过扰动函数hash()处理后)来决定键值对在哈希表中的位置,当 Key 的 hash 值相同时,再通过 equals 方法判读是否是替换原来对应 key 的 Value 还是存储新的键值对。那么我们在使用 Set 方法的时候也必须保证,存储元素的 HashCode 方法以及 equals 方法被正确覆写。
HashSet 中的添加元素的方法也很简单,我们来看下实现:
public boolean add(E e) {return map.put(e, PRESENT)==null;}
可以看出 add 方法调用了 HashMap 的 put 方法,构造的键值对的 key 为待添加的元素,而 Value 这时有全局变量 PRESENT 来充当,这个PRESENT只是一个 Object 对象。
除了 add 方法外 HashSet 实现了 Set 接口中的其他方法这些方法有:
public int size() {return map.size();}public boolean isEmpty() {return map.isEmpty();}public boolean contains(Object o) {return map.containsKey(o);}//调用 remove(Object key) 方法去移除对应的键值对public boolean remove(Object o) {return map.remove(o)==PRESENT;}public void clear() {map.clear();}// 返回一个 map.keySet 的 HashIterator 来作为 Set 的迭代器public Iterator<E> iterator() {return map.keySet().iterator();}
关于 HashSet 中的源码分析就这些,其实除了一些序列化和克隆的方法以外,我们已经列举了所有的 HashSet 的源码,有没有感觉巨简单,其实下面的 LinkedHashSet 由于继承自 HashSet 使得其代码更加简单只有短短100多行不信继续往下看。
LinkedHashSet
在上述分析 HashSet 构造方法的时候,有一个 default 权限的构造方法没有讲,只说了其跟 LinkedHashSet 构造有关系,该构造方法内部调用的是 LinkedHashMap 的构造方法。
LinkedHashMap 较之 HashMap 内部多维护了一个双向链表用来维护元素的添加顺序:
// dummy 参数没有作用这里可以忽略HashSet(int initialCapacity, float loadFactor, boolean dummy) {map = new LinkedHashMap<>(initialCapacity, loadFactor);}//调用 LinkedHashMap 的构造方法,该方法初始化了初始起始容量,以及加载因子,//accessOrder = false 即迭代顺序不等于访问顺序public LinkedHashMap(int initialCapacity, float loadFactor) {super(initialCapacity, loadFactor);accessOrder = false;}
LinkedHashSet的构造方法一共有四个,统一调用了父类的 HashSet(int initialCapacity, float loadFactor, boolean dummy)构造方法。
//初始化 LinkedHashMap 的初始容量为诶 16 加载因子为 0.75fpublic LinkedHashSet() {super(16, .75f, true);}//初始化 LinkedHashMap 的初始容量为 Math.max(2*c.size(), 11) 加载因子为 0.75fpublic LinkedHashSet(Collection<? extends E> c) {super(Math.max(2*c.size(), 11), .75f, true);addAll(c);}//初始化 LinkedHashMap 的初始容量为参数指定值 加载因子为 0.75fpublic LinkedHashSet(int initialCapacity) {super(initialCapacity, .75f, true);}//初始化 LinkedHashMap 的初始容量,加载因子为参数指定值public LinkedHashSet(int initialCapacity, float loadFactor) {super(initialCapacity, loadFactor, true);}
完了..没错,LinkedHashSet 源码就这几行,所以可以看出其实现依赖于 LinkedHashMap 内部的数据存储结构。
原文地址:https://www.yuque.com/lobotomy/java/tep84p

若有收获,就点个赞吧
0 人点赞
