- java基本8种数据类型
- 装箱和拆箱
- 小结
- Integer比较相等问题
- Java 源码分析 — String 的设计
- 1. 面向对象和面向过程的区别
- 11. Java 面向对象编程三大特性: 封装 继承 多态
- 12. String StringBuffer 和 StringBuilder 的区别是什么? String 为什么是不可变的?
- 13. 自动装箱与拆箱
- 14. 在一个静态方法内调用一个非静态成员为什么是非法的?
- 15. 在 Java 中定义一个不做事且没有参数的构造方法的作用
- 16. import java和javax有什么区别?
- 17. 接口和抽象类的区别是什么?
- 18. 成员变量与局部变量的区别有哪些?
- 19. 创建一个对象用什么运算符?对象实体与对象引用有何不同?
- 20. 什么是方法的返回值?返回值在类的方法里的作用是什么?
- 21. 一个类的构造方法的作用是什么? 若一个类没有声明构造方法,该程序能正确执行吗? 为什么?
- 22. 构造方法有哪些特性?
- 23. 静态方法和实例方法有何不同
- 24. 对象的相等与指向他们的引用相等,两者有什么不同?
- 25. 在调用子类构造方法之前会先调用父类没有参数的构造方法,其目的是?
- 26. == 与 equals(重要)
- 27. hashCode 与 equals (重要)
- 28. 为什么Java中只有值传递?
- 29. 简述线程、程序、进程的基本概念。以及他们之间关系是什么?
- 30. 线程有哪些基本状态?
- 31 关于 final 关键字的一些总结
- 32 Java 中的异常处理
- 33 Java序列化中如果有些字段不想进行序列化,怎么办?
- 34 获取用键盘输入常用的两种方法
- 35 Java 中 IO 流
- 36. 常见关键字总结:static,final,this,super
- 37. Collections 工具类和 Arrays 工具类常见方法总结
- 参考
- 公众号
- 反射中,Class.forName和ClassLoader区别
- JVM 的一些知识
- finalize的作用
- finalize函数的调用机制
- 使用场景
- finalize 的执行过程(生命周期)
- Object有哪些方法?
- 2- 线程间通信
- 3- 垃圾清理
- 4- 其他
- Cloneable 接口
- Java死锁排查和Java CPU 100% 排查的步骤整理
- 二、Java CPU 100% 排查
- 三、压力测试使用jstack找到系统的代码性能问题
- 参考
- Java String类为什么是final的?
- 字节码增强技术
- for、foreach、Iterator 比较
java基本8种数据类型
基本数据类型的相关特点
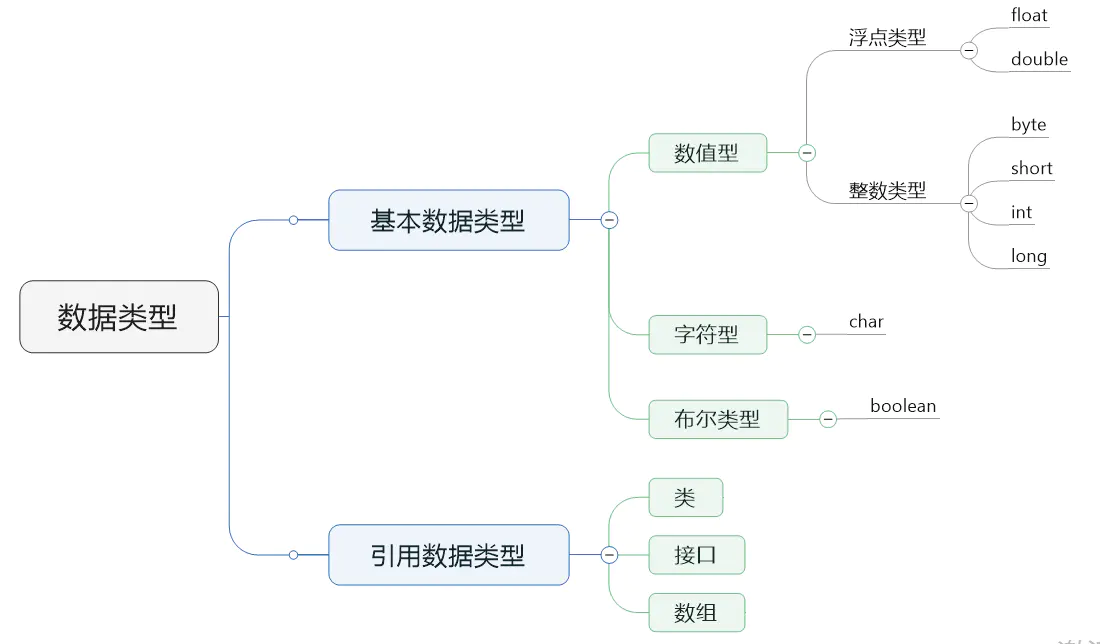
8种基本数据类型
一张图概括全部的数据类型,主要的研究的是上面的基本数据类型,下面再以各种数据类型所占字节数大小再重新分类一遍帮助记忆: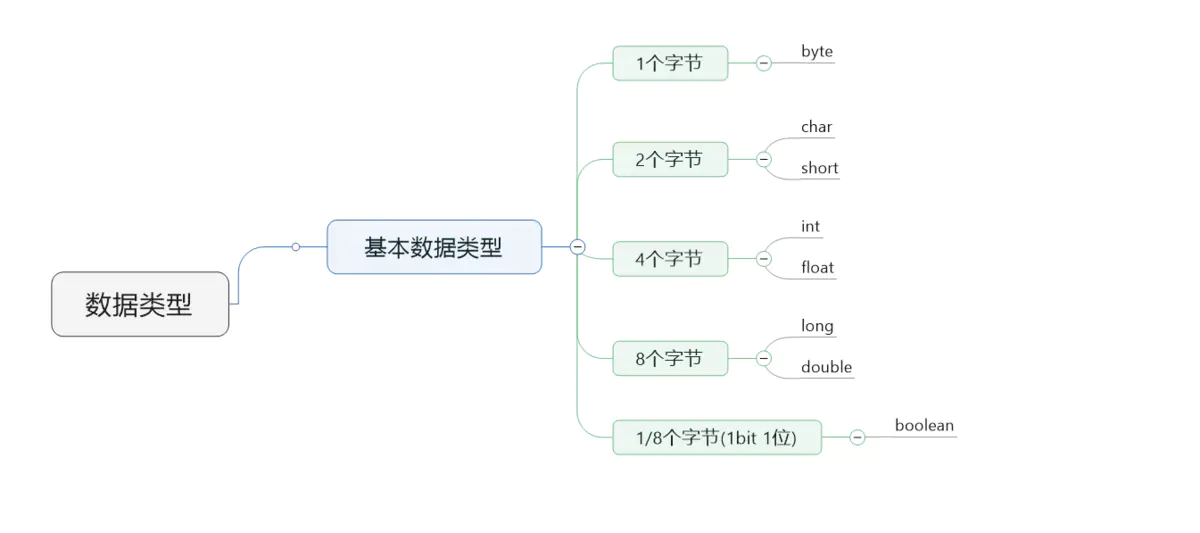
基本数据类型所占字节数
boolean

布尔类型
byte
1位(是数据的最小单位) ,但是大多数情况下数据最小单位为1个字节(byte)因为1 bit 的信息量太少了。要表示一个有用的信息,需要好几个bit一起表示。我们的其他基本数据类型都是由byte组成。
那么讲到字节就稍微提一下字符编码 ASCII,Unicode和UTF-8之间的概念和由来。
ASCII是上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码,一直沿用至今。它由一个字节组成也就是8位,一共表示128个字符。因为西方的英文就26个字母,再加上大写字母各种其他的符号。128也是够用的了(因为第一位规定为0 所以就只表示128个字符啦)
ASCII字符表
但是西方国家还有很多,比如德国法国等,他们的语言也需要一套字符编码,不过都是在一个字节之内就能解决的事情。每个国家就定义了自己的一套标准
其中最常见的ISO/IEC 8859-1就是法语,芬兰语所用的西欧字符集
但是中文就比较复杂,有10万多个汉字,那么这意义着要更多的字节去表示这些汉字
然后同一段字节流到了不同的国家可能因为标准不同,导致会变出各种奇怪的符号,也就是不统一了。
那么最终还是要统一的,就出现了unicode全世界每个不同语言的不同字符都统一编码,全球通行。默认unicode采用2个字节,先讲这么多。不要跑题了。
char

char的基本特点
有一道面试题:java中的一个char变量能否表示一个汉字,为什么?
当时我是有点懵逼的,到底可以还是不可以呢?(希望有大神能详细解答一下)
我查了一下正确答案是可以的 unicode是2个字节 (16位)可以表示汉字。
整型常量和浮点型常量

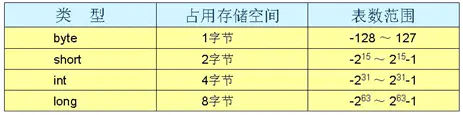
整型常量的范围和占用空间
浮点型常量的范围和占用空间
补充一下相关字节和位的知识:
1个字节=8位 8位代表256个数字 第一位符号位 0 正 1负 其余7位代表数字 2^7=127 因为只有一个0
当1 0000000时表示-128 所以 byte为 -128-127 其他类型以此类推
问题1:在不同的位数的操作系统上 是否基本数据类型所表示的范围相同呢?
答:在C/C++上是不同的,但是在java上是相同的。
32位编译器:char :1个字节char*(即指针变量): 4个字节(32位的寻址空间是2^32, 即32个bit,也就是4个字节。同理64位编译器)short int : 2个字节int: 4个字节unsigned int : 4个字节float: 4个字节double: 8个字节long: 4个字节long long: 8个字节unsigned long: 4个字节
64位编译器:char :1个字节char*(即指针变量): 8个字节short int : 2个字节int: 4个字节unsigned int : 4个字节float: 4个字节double: 8个字节long: 8个字节long long: 8个字节unsigned long: 8个字节
以上占用字节数其实是针对c/c++语言而言的,对于java来说由于其JVM具有跨平台性因此java在32位和64位机下基本数据类型占字节数是一致的(这样才能达到跨平台通信)。
问题2:
如果是在不同位数的jvm上呢?32位的jvm和64位的jvm是否表示范围相同?
看到这个问题的我,是一脸懵逼的。
个人感觉应该不同吧,毕竟java是跑在jvm上的所以和操作系统的位数没关。那么jvm的位数应该就有关了吧。(希望有大神能解答)
数据类型注意事项
1.自动类型转换
本数据类型中,布尔类型boolean占有一个字节,由于其本身所代码的特殊含义,boolean类型与其他基本类型不能进行类型的转换(既不能进行自动类型的提升,也不能强制类型转换), 否则,将编译出错。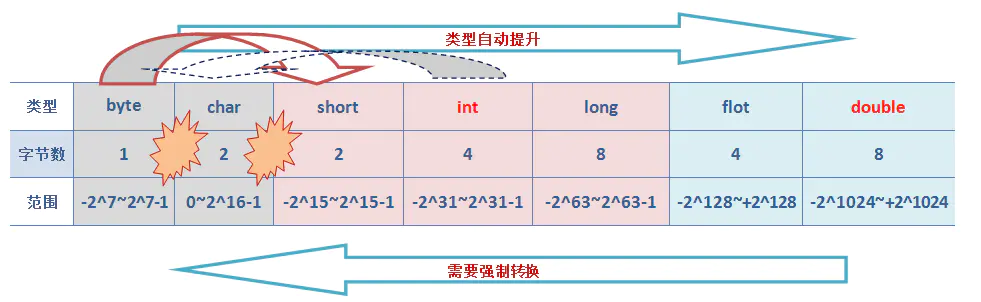
转换图
转换图的几点说明:
1.红色的int和double代表,在Java中,整数类型(byte/short/int/long)中,对于未声明数据类型的整形,其默认类型为int型。在浮点类型(float/double)中,对于未声明数据类型的浮点型,默认为double型。
2.上下两个大的蓝色箭头表示,从低到高类型自动转换,高到低需要强制转换,原因很简单,高位表示的范围大,低位表示的范围小。
3.在byte char short之间的爆炸符号,代表的意思虽然类型从小到大自动转换,但是byte不能转成char,char也不能转成short。因为byte和short是是数值型的变量,char字符型的变量。数值型变量有符号(第一位)而在char中则无正负之分。byte转short自然就是可以的了。
例题引出问题:
package com.corn.testcast;public class TestCast {public static void main(String[] args) {long a = 10000000000; //编译出错: The literal 10000000000 of type int is out of rangelong b = 10000000000L; //编译正确int c = 1000;long d = c;float e = 1.5F;double f = e;}}
a错的原因是,整型数默认为int型,而这个数字大小已经超过了int的范围,又没有在后面加L表示为long所以就错了。b就是很好的修正例子。
例题引出问题2:
package com.corn.testcast;public class TestCast {public static void main(String[] args) {byte p = 3; // 编译正确:int到byte编译过程中发生隐式类型转换int a = 3;byte b = a; // 编译出错:cannot convert from int to bytebyte c = (byte) a; // 编译正确float d = (float) 4.0;}}
p正确的原因是首先3是一个int型的数值,并且没有超过int的范围,其次再看这个p的类型为byte,在进行隐式转换没有溢出,包含在byte的范围中。所以正确。
b错误的原因是a是int型的3,虽然这个大小也在byte的范围中。但是在编译过程中,b被赋值的是变量a,事先不知道是否a的大小能在byte范围中。保险起见编译出错。
c正确的原因是加了强制转换
d也是,默认4.0为double型,然后强制转换当然就正确了。可是为什么不像p一样,做隐式转换呢(求大神详解)。好像是浮点存在精度问题,而整型没有。
例题引出问题3:
package com.corn.testcast;public class TestCast {public static void main(String[] args) {int a = 233;byte b = (byte) a;System.out.println("b:" + b); // 输出:-23}}
看到这里的b输出是一个负数,那么这里的原因是因为,看到int的a=233这个是超过了byte的范围了。然后a强制转换成b,我们先把a换成二进制24位0 + 11101001(int为4个字节 32位) 只取最低的8位,一共截取8位(byte所占用的空间大小)。然后因为最高位为1代表负数 所以b为-23
问题来了,我们看11101001这个二进制表示的不是-23呀,这是怎么得来的-23呢?
原因是计算机中的数据运算都是通过补码来运行的。两个数通过各自补码进行加减运算,得出的补码结果再转成原码就是正确的计算结果。我们看到11101001是溢出的,其实是补码。转成原码后就是-23了。第一位符号位不变,然后取反加1.、
- 不能对boolean类型进行类型转换。
- 不能把对象类型转换成不相关类的对象。
long a=123;//long类型 不加L默认是int 当数字范围在int之内 int自动转long不报错long b=11111111111;//报错 因为超过了int的范围又不加L

相关考题解析
1.short s1 = 1; s1 = s1 + 1;对还是错 为什么? short s1 = 1; s1 +=1;对还是错 为什么?
2.int 和 Integer 有什么区别?
3.我们能将 int 强制转换为 byte 类型的变量吗?如果该值大于 byte 类型的范围,将会出现什么现象?
4.a = a + b 与 a += b 的区别
- 存在使i + 1 < i的数吗()
答案:存在
解析:如果i为int型,那么当i为int能表示的最大整数时,i+1就溢出变成负数了,此时不就
答案:存在
解析:比如Double.NaN或Float.NaN - 0.6332的数据类型是()
A float B double C Float D Double
答案:B
解析:默认为double型,如果为float型需要加上f显示说明,即0.6332f装箱和拆箱
包装类、装箱、拆箱
Java 中为每一种基本数据类型提供了相应的包装类,如下:
引入包装类的目的就是:提供一种机制,使得基本数据类型可以与引用类型互相转换。Byte <-> byteShort <-> shortInteger <-> intLong <-> longFloat <-> floatDouble <-> doubleCharacter <-> charBoolean <-> boolean复制代码
基本数据类型与包装类的转换被称为装箱和拆箱。
装箱(boxing)是将值类型转换为引用类型。例如:int转Integer- 装箱过程是通过调用包装类的
valueOf方法实现的。
- 装箱过程是通过调用包装类的
拆箱(unboxing)是将引用类型转换为值类型。例如:Integer转int- 拆箱过程是通过调用包装类的
xxxValue方法实现的。(xxx 代表对应的基本数据类型)。自动装箱、自动拆箱
基本数据(Primitive)型的自动装箱(boxing)拆箱(unboxing)自 JDK 5 开始提供的功能。
自动装箱与拆箱的机制可以让我们在 Java 的变量赋值或者是方法调用等情况下使用原始类型或者对象类型更加简单直接。 因为自动装箱会隐式地创建对象,如果在一个循环体中,会创建无用的中间对象,这样会增加 GC 压力,拉低程序的性能。所以在写循环时一定要注意代码,避免引入不必要的自动装箱操作。
JDK 5 之前的形式:
JDK 5 之后:Integer i1 = new Integer(10); // 非自动装箱复制代码
Java 对于自动装箱和拆箱的设计,依赖于一种叫做享元模式的设计模式(有兴趣的朋友可以去了解一下源码,这里不对设计模式展开详述)。Integer i2 = 10; // 自动装箱复制代码
👉 扩展阅读:深入剖析 Java 中的装箱和拆箱 结合示例,一步步阐述装箱和拆箱原理。
- 拆箱过程是通过调用包装类的
装箱、拆箱的应用和注意点
装箱、拆箱应用场景
- 一种最普通的场景是:调用一个含类型为
Object参数的方法,该Object可支持任意类型(因为Object是所有类的父类),以便通用。当你需要将一个值类型(如 int)传入时,需要使用Integer装箱。 - 另一种用法是:一个非泛型的容器,同样是为了保证通用,而将元素类型定义为
Object。于是,要将值类型数据加入容器时,需要装箱。 - 当
==运算符的两个操作,一个操作数是包装类,另一个操作数是表达式(即包含算术运算)则比较的是数值(即会触发自动拆箱的过程)。
示例:
Integer i1 = 10; // 自动装箱Integer i2 = new Integer(10); // 非自动装箱Integer i3 = Integer.valueOf(10); // 非自动装箱int i4 = new Integer(10); // 自动拆箱int i5 = i2.intValue(); // 非自动拆箱System.out.println("i1 = [" + i1 + "]");System.out.println("i2 = [" + i2 + "]");System.out.println("i3 = [" + i3 + "]");System.out.println("i4 = [" + i4 + "]");System.out.println("i5 = [" + i5 + "]");System.out.println("i1 == i2 is [" + (i1 == i2) + "]");System.out.println("i1 == i4 is [" + (i1 == i4) + "]"); // 自动拆箱// Output:// i1 = [10]// i2 = [10]// i3 = [10]// i4 = [10]// i5 = [10]// i1 == i2 is [false]// i1 == i4 is [true]复制代码
示例说明: 上面的例子,虽然简单,但却隐藏了自动装箱、拆箱和非自动装箱、拆箱的应用。从例子中可以看到,明明所有变量都初始化为数值 10 了,但为何会出现
i1 == i2 is [false而i1 == i4 is [true]? 原因在于:
- i1、i2 都是包装类,使用
==时,Java 将它们当做两个对象,而非两个 int 值来比较,所以两个对象自然是不相等的。正确的比较操作应该使用equals方法。- i1 是包装类,i4 是基础数据类型,使用
==时,Java 会将两个 i1 这个包装类对象自动拆箱为一个int值,再代入到==运算表达式中计算;最终,相当于两个int进行比较,由于值相同,所以结果相等。
装箱、拆箱应用注意点
Integer比较相等问题
前阵子在群上看有人在讨论关于Integer的true或者false问题,我本以为我已经懂了这方面的知识点了。但还是做错了,后来去请教了一下朋友。朋友又给我发了另一张图: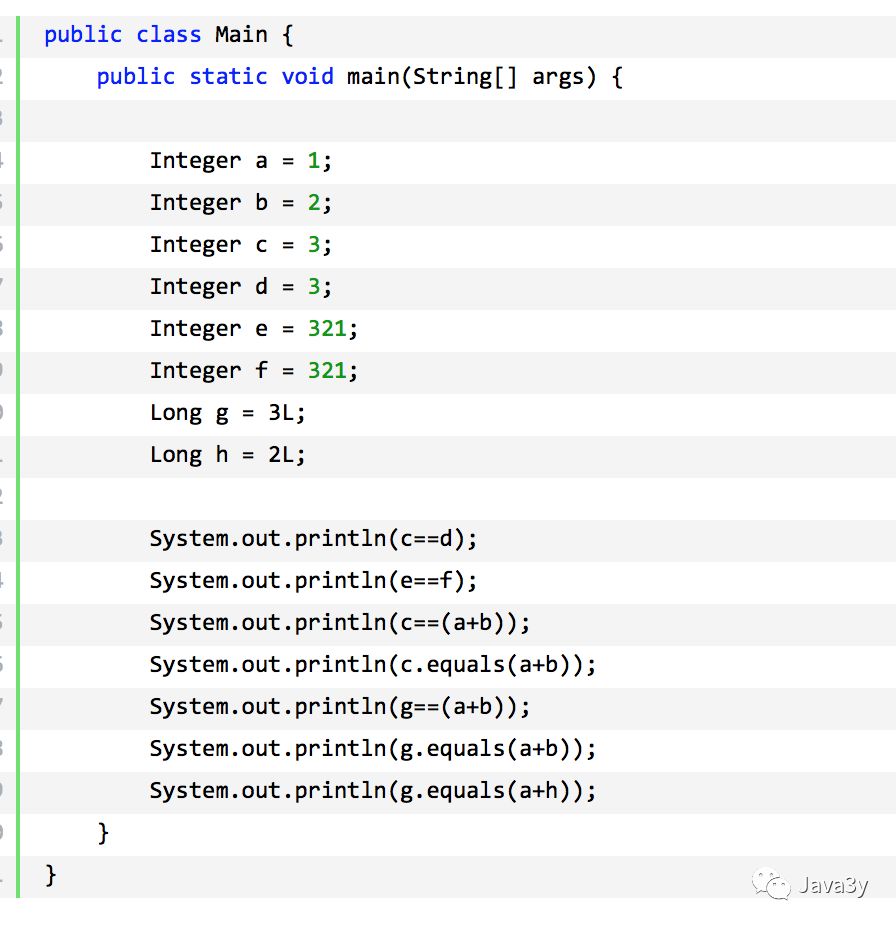
后来发现这是出自《深入理解Java虚拟机——JVM高级特性与最佳实践(第2版)》中的10.3.2小节中~
public class Main_1 {public static void main(String[] args) {Integer a = 1;Integer b = 2;Integer c = 3;Integer d = 3;Integer e = 321;Integer f = 321;Long g = 3L;System.out.println(c == d);System.out.println(e == f);System.out.println(c == (a + b));System.out.println(c.equals(a + b));System.out.println(g == (a + b));System.out.println(g.equals(a + b));System.out.println(g.equals(a + h));}}
1.1解题思路
在解这道题之前,相信很多人都已经知道了,在Java中会有一个Integer缓存池,缓存的大小是:-128~127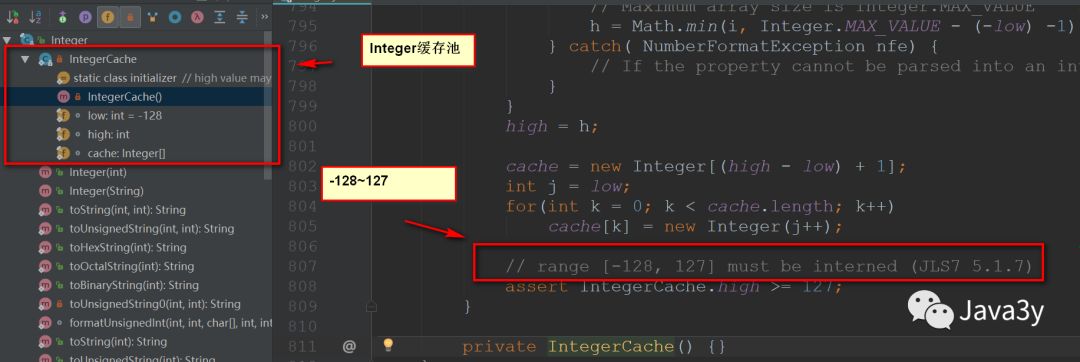
答案是:
- true
- false
- true
- true
- true
- false
- true
简单解释一下:
- 使用
==的情况:- 如果比较Integer变量,默认比较的是地址值。
- Java的Integer维护了从
-128~127的缓存池 - 如果比较的某一边有操作表达式(例如a+b),那么比较的是具体数值
- 使用
equals()的情况:- 无论是Integer还是Long中的
equals()默认比较的是数值。 - Long的
equals()方法,JDK的默认实现:会判断是否是Long类型
- 无论是Integer还是Long中的
- 注意自动拆箱,自动装箱问题。
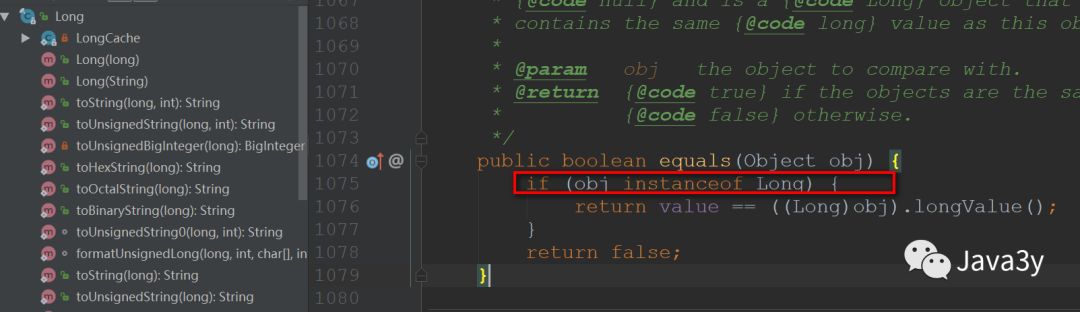
反编译一下看看:
import java.io.PrintStream;public class Main_1 {public static void main(String[] paramArrayOfString) {Integer localInteger1 = Integer.valueOf(1);Integer localInteger2 = Integer.valueOf(2);Integer localInteger3 = Integer.valueOf(3);Integer localInteger4 = Integer.valueOf(3);Integer localInteger5 = Integer.valueOf(321);Integer localInteger6 = Integer.valueOf(321);Long localLong = Long.valueOf(3L);// 缓存池System.out.println(localInteger3 == localInteger4);// 超出缓存池范围System.out.println(localInteger5 == localInteger6);// 存在a+b数值表达式,比较的是数值System.out.println(localInteger3.intValue() == localInteger1.intValue() + localInteger2.intValue());// equals比较的是数值System.out.println(localInteger3.equals(Integer.valueOf(localInteger1.intValue() + localInteger2.intValue())));// 存在a+b数值表达式,比较的是数值System.out.println(localLong.longValue() == localInteger1.intValue() + localInteger2.intValue());// Long的equals()先判断传递进来的是不是Long类型,而a+b自动装箱的是Integer类型System.out.println(localLong.equals(Integer.valueOf(localInteger1.intValue() + localInteger2.intValue())));// ... 最后一句在这里漏掉了,大家应该可以推断出来}}
Java 源码分析 — String 的设计
问题的引入
关于 String 字符串,对于Java开发者而言,这无疑是一个非常熟悉的类。也正是因为经常使用,其内部代码的设计才值得被深究。所谓知其然,更得知其所以然。
举个例子,假如想要写个类去继承 String,这时 IDE 提示 String 为final类型不允许被继承。
此时最先想到的肯定是 java 中类被 final 修饰的效果,其实由这一点也可以引出更多思考:
比如说 String 类被设计成 final 类型是出于哪些考虑?
在Java中,被 final 类型修饰的类不允许被其他类继承,被 final 修饰的变量赋值后不允许被修改
定义
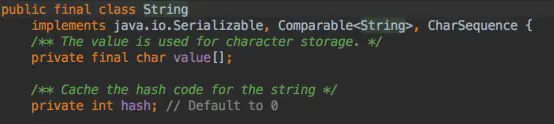
查看 String 类在 JDK 7 源码中的定义:
public final class String implements java.io.Serializable, Comparable<String>, CharSequence{...}
可以看出 String 是 final 类型的,表示该类不能被其他类继承,同时该类实现了三个接口:java.io.Serializable Comparable<String> CharSequence
对于 Sting 类,官方有如下注释说明:
/*Strings are constant;their values can not be changed after they are created.Stringbuffers support mutable strings.Because String objects are immutable they can be shared. Forexample:*/
String 字符串是常量,其值在实例创建后就不能被修改,但字符串缓冲区支持可变的字符串,因为缓冲区里面的不可变字符串对象们可以被共享。(其实就是使对象的引用发生了改变)
属性
/**The value isused for character storage.*/private final char value[];
这是一个字符数组,并且是 final 类型,用于存储字符串内容。从 fianl 关键字可以看出,String 的内容一旦被初始化后,其不能被修改的。
看到这里也许会有人疑惑,String 初始化以后好像可以被修改啊。比如找一个常见的例子:
String str = “hello”; str = “hi”其实这里的赋值并不是对 str 内容的修改,而是将str指向了新的字符串。另外可以明确的一点:String 其实是基于字符数组 char[] 实现的。
下面再来看 String 其他属性:
比如缓存字符串的 hash Code,其默认值为 0:
/**Cache the hashcode for the string*/private int hash; //Default to 0
关于序列化 serialVersionUID:
/**use serialVersionUID from JDK 1.0.2 for interoperability*/private static final long serialVersionUID = -6849794470754667710L;/**Class String is special cased with in the Serialization Stream Protocol.*/privates tatic final ObjectStreamField[] serialPersistentFields = new ObjectStreamField[0]
因为 String 实现了 Serializable 接口,所以支持序列化和反序列化支持。Java 的序列化机制是通过在运行时判断类的 serialVersionUID 来验证版本一致性的。在进行反序列化时,JVM 会把传来的字节流中的 serialVersionUID 与本地相应实体(类)的 serialVersionUID 进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常 (InvalidCastException)。
构造方法
空的构造器
public String(){this.value = "".value;}
该构造方法会创建空的字符序列,注意这个构造方法的使用,因为创造不必要的字符串对象是不可变的。因此不建议采取下面的创建 String 对象:
String str = new String()str = "sample";
这样的结果显而易见,会产生了不必要的对象。
使用字符串类型的对象来初始化
public String(String original){this.value = original.value;this.hash = original.hash;}
这里将直接将源 String 中的 value 和 hash 两个属性直接赋值给目标 String。因为 String 一旦定义之后是不可以改变的,所以也就不用担心改变源 String 的值会影响到目标 String 的值。
使用字符数组来构造
public String(char value[]){this.value = Arrays.copyOf(value, value.length);}
public String(char value[], int offset, int count){if(offset<0){throw new StringIndexOutOfBoundsException(offset);}if(count<=0){if(count<0){throw new String IndexOutOfBoundsException(count);}if(offset <= value.length){this.value = "".value;return;}}//Note:offset or count might be near-1>>>1.if(offset > value.length - count){throw new StringIndexOutOfBoundsException(offset+count);}this.value=Arrays.copyOfRange(value,offset,offset+count);}
这里值得注意的是:当我们使用字符数组创建 String 的时候,会用到 Arrays.copyOf 方法或 Arrays.copyOfRange 方法。这两个方法是将原有的字符数组中的内容逐一的复制到 String 中的字符数组中。会创建一个新的字符串对象,随后修改的字符数组不影响新创建的字符串。
使用字节数组来构建 String
在 Java 中,String 实例中保存有一个 char[] 字符数组,char[] 字符数组是以 unicode 码来存储的,String 和 char 为内存形式。
byte 是网络传输或存储的序列化形式,所以在很多传输和存储的过程中需要将 byte[] 数组和 String 进行相互转化。所以 String 提供了一系列重载的构造方法来将一个字符数组转化成 String,提到 byte[] 和 String 之间的相互转换就不得不关注编码问题。
String(byte[] bytes, Charset charset)
该构造方法是指通过 charset 来解码指定的 byte 数组,将其解码成 unicode 的 char[] 数组,构造成新的 String。
这里的 bytes 字节流是使用 charset 进行编码的,想要将他转换成 unicode 的 char[] 数组,而又保证不出现乱码,那就要指定其解码方式
同样的,使用字节数组来构造 String 也有很多种形式,按照是否指定解码方式分的话可以分为两种:
public String(byte bytes[]){this(bytes, 0, bytes.length);}
public String(byte bytes[], int offset, int length){checkBounds(bytes, offset, length);this.value = StringCoding.decode(bytes, offset, length);}
如果我们在使用 byte[] 构造 String 的时候,使用的是下面这四种构造方法(带有 charsetName 或者 charset 参数)的一种的话,那么就会使用 StringCoding.decode 方法进行解码,使用的解码的字符集就是我们指定的 charsetName 或者 charset。
String(byte bytes[])String(byte bytes[], int offset, int length)String(byte bytes[], Charset charset)String(byte bytes[], String charsetName)String(byte bytes[], int offset, int length, Charset charset)String(byte bytes[], int offset, int length, String charsetName)
我们在使用 byte[] 构造 String 的时候,如果没有指明解码使用的字符集的话,那么 StringCoding 的 decode 方法首先调用系统的默认编码格式,如果没有指定编码格式则默认使用 ISO-8859-1 编码格式进行编码操作。主要体现代码如下:
static char[] decode(byte[] ba, int off, int len){String csn = Charset.defaultCharset().name();try{ //use char set name decode() variant which provide scaching.return decode(csn, ba, off, len);} catch(UnsupportedEncodingException x){warnUnsupportedCharset(csn);}try{return decode("ISO-8859-1", ba, off, len); }catch(UnsupportedEncodingException x){//If this code is hit during VM initiali zation, MessageUtils is the only way we will be able to get any kind of error message.MessageUtils.err("ISO-8859-1 char set not available: " + x.toString());// If we can not find ISO-8859-1 (are quired encoding) then things are seriously wrong with the installation.System.exit(1);return null;}}
使用 StringBuffer 和 StringBuilder 构造一个 String
作为 String 的两个“兄弟”,StringBuffer 和 StringBuilder 也可以被当做构造 String 的参数。
public String(StringBuffer buffer) {synchronized(buffer) {this.value = Arrays.copyOf(buffer.getValue(), buffer.length());}}public String(StringBuilder builder) {this.value = Arrays.copyOf(builder.getValue(), builder.length());}
当然,这两个构造方法是很少用到的,因为当我们有了 StringBuffer 或者 StringBuilfer 对象之后可以直接使用他们的 toString 方法来得到 String。
关于效率问题,Java 的官方文档有提到说使用StringBuilder 的 toString 方法会更快一些,原因是 StringBuffer 的 toString 方法是 synchronized 的,在牺牲了效率的情况下保证了线程安全。
StringBuilder 的 toString() 方法:
@Overridepublic String toString(){//Create a copy, don't share the arrayreturn new String(value,0,count);}
StringBuffer 的 toString() 方法:
@Overridepublic synchronized String toString(){if (toStringCache == null){toStringCache = Arrays.copyOfRange(value, 0, count);}return new String(toStringCache, true);}
一个特殊的保护类型的构造方法
String 除了提供了很多公有的供程序员使用的构造方法以外,还提供了一个保护类型的构造方法(Java 7),我们看一下他是怎么样的:
String(char[] value, boolean share) {// assert share : "unshared not supported";this.value = value;}
从代码中我们可以看出,该方法和 String(char[] value) 有两点区别:
- 第一个区别:该方法多了一个参数:boolean share,其实这个参数在方法体中根本没被使用。注释说目前不支持 false,只使用 true。那可以断定,加入这个 share 的只是为了区分于 String(char[] value) 方法,不加这个参数就没办法定义这个函数,只有参数是不同才能进行重载。
- 第二个区别:具体的方法实现不同。我们前面提到过 String(char[] value) 方法在创建 String 的时候会用到 Arrays 的 copyOf 方法将 value 中的内容逐一复制到 String 当中,而这个 String(char[] value, boolean share) 方法则是直接将 value 的引用赋值给 String 的 value。那么也就是说,这个方法构造出来的 String 和参数传过来的 char[] value 共享同一个数组。
为什么 Java 会提供这样一个方法呢?
- 性能好:这个很简单,一个是直接给数组赋值(相当于直接将 String 的 value 的指针指向char[]数组),一个是逐一拷贝,当然是直接赋值快了。
- 节约内存:该方法之所以设置为 protected,是因为一旦该方法设置为公有,在外面可以访问的话,如果构造方法没有对 arr 进行拷贝,那么其他人就可以在字符串外部修改该数组,由于它们引用的是同一个数组,因此对 arr 的修改就相当于修改了字符串,那就破坏了字符串的不可变性。
- 安全的:对于调用他的方法来说,由于无论是原字符串还是新字符串,其 value 数组本身都是 String 对象的私有属性,从外部是无法访问的,因此对两个字符串来说都很安全。
Java 7 加入的新特性
在 Java 7 之前有很多 String 里面的方法都使用上面说的那种“性能好的、节约内存的、安全”的构造函数。
比如:substringreplaceconcatvalueOf等方法实际上它们使用的是 public String(char[], ture) 方法来实现。
但是在 Java 7 中,substring 已经不再使用这种“优秀”的方法了
public String substring(int beginIndex, int endIndex){if(beginIndex < 0){throw new StringIndexOutOfBoundsException(beginIndex);}if(endIndex > value.length){throw new StringIndexOutOfBoundsException(endIndex);}intsubLen = endIndex-beginIndex;if(subLen < 0){throw new StringIndexOutOfBoundsException(subLen);}return ((beginIndex == 0) && (endIndex == value.length)) ? this : newString(value, beginIndex, subLen);}
为什么呢?
虽然这种方法有很多优点,但是他有一个致命的缺点,对于 sun 公司的程序员来说是一个零容忍的 bug,那就是他很有可能造成内存泄露。
看一个例子,假设一个方法从某个地方(文件、数据库或网络)取得了一个很长的字符串,然后对其进行解析并提取其中的一小段内容,这种情况经常发生在网页抓取或进行日志分析的时候。
下面是示例代码:
String aLongString = "...averylongstring...";String aPart = data.substring(20, 40);return aPart;
在这里 aLongString 只是临时的,真正有用的是 aPart,其长度只有 20 个字符,但是它的内部数组却是从 aLongString 那里共享的,因此虽然 aLongString 本身可以被回收,但它的内部数组却不能释放。这就导致了内存泄漏。如果一个程序中这种情况经常发生有可能会导致严重的后果,如内存溢出,或性能下降。
新的实现虽然损失了性能,而且浪费了一些存储空间,但却保证了字符串的内部数组可以和字符串对象一起被回收,从而防止发生内存泄漏,因此新的 substring 比原来的更健壮。
其他方法
length() 返回字符串长度
public int length(){return value.length;}
isEmpty() 返回字符串是否为空
public boolean isEmpty(){return value.length == 0;}
charAt(int index) 返回字符串中第(index+1)个字符(数组索引)
public char charAt(int index){if((index < 0) || (index >= value.length)){throw new StringIndexOutOfBoundsException(index);}return value[index];}
char[] toCharArray() 转化成字符数组trim()去掉两端空格toUpperCase()转化为大写toLowerCase()转化为小写
需要注意String concat(String str) 拼接字符串String replace(char oldChar, char newChar) 将字符串中的
oldChar 字符换成 newChar 字符
以上两个方法都使用了
String(char[] value, boolean share)concat 方法和 replace 方法,他们不会导致元数组中有大量空间不被使用,因为他们一个是拼接字符串,一个是替换字符串内容,不会将字符数组的长度变得很短,所以使用了共享的 char[] 字符数组来优化。
boolean matches(String regex) 判断字符串是否匹配给定的regex正则表达式boolean contains(CharSequence s) 判断字符串是否包含字符序列 sString[] split(String regex, int limit) 按照字符 regex将字符串分成 limit 份String[] split(String regex) 按照字符 regex 将字符串分段
getBytes
在创建 String 的时候,可以使用 byte[] 数组,将一个字节数组转换成字符串,同样,我们可以将一个字符串转换成字节数组,那么 String 提供了很多重载的 getBytes 方法。
public byte[] getBytes(){return StringCoding.encode(value, 0, value.length);}
但是,值得注意的是,在使用这些方法的时候一定要注意编码问题。比如:String s = "你好,世界!"; byte[] bytes = s.getBytes();
这段代码在不同的平台上运行得到结果是不一样的。由于没有指定编码方式,所以在该方法对字符串进行编码的时候就会使用系统的默认编码方式。
在中文操作系统中可能会使用 GBK 或者 GB2312 进行编码,在英文操作系统中有可能使用 iso-8859-1 进行编码。这样写出来的代码就和机器环境有很强的关联性了,为了避免不必要的麻烦,要指定编码方式。
public byte[] getBytes(String charsetName) throws UnsupportedEncodingException{if (charsetName == null) throw new NullPointerException();return StringCoding.encode(charsetName, value, 0, value.length);}
比较方法
boolean equals(Object anObject); 比较对象boolean contentEquals(String Buffersb); 与字符串比较内容boolean contentEquals(Char Sequencecs); 与字符比较内容boolean equalsIgnoreCase(String anotherString);忽略大小写比较字符串对象int compareTo(String anotherString); 比较字符串int compareToIgnoreCase(String str); 忽略大小写比较字符串boolean regionMatches(int toffset, String other, int ooffset, int len)局部匹配boolean regionMatches(boolean ignoreCase, int toffset, String other, int ooffset, int len) 可忽略大小写局部匹配
字符串有一系列方法用于比较两个字符串的关系。 前四个返回 boolean 的方法很容易理解,前三个比较就是比较 String 和要比较的目标对象的字符数组的内容,一样就返回 true, 不一样就返回false,核心代码如下:
int n = value.length;while (n-- ! = 0) {if (v1[i] != v2[i])return false;i++;}
v1 v2 分别代表 String 的字符数组和目标对象的字符数组。 第四个和前三个唯一的区别就是他会将两个字符数组的内容都使用 toUpperCase 方法转换成大写再进行比较,以此来忽略大小写进行比较。相同则返回 true,不想同则返回 false
equals方法:
public boolean equals(Object anObject) {if (this == anObject) {return true;}if (anObject instanceof String) {String anotherString = (String) anObject;int n = value.length;if (n == anotherString.value.length) {char v1[] = value;char v2[] = anotherString.value;int i = 0;while (n-- != 0) {if (v1[i] != v2[i])return false;i++;}return true;}}return false;}
该方法首先判断 this == anObject ?,也就是说判断要比较的对象和当前对象是不是同一个对象,如果是直接返回 true,如不是再继续比较,然后在判断 anObject 是不是 String 类型的,如果不是,直接返回 false,如果是再继续比较,到了能终于比较字符数组的时候,他还是先比较了两个数组的长度,不一样直接返回 false,一样再逐一比较值。 虽然代码写的内容比较多,但是可以很大程度上提高比较的效率。值得学习!!!
StringBuffer 需要考虑线程安全问题,加锁之后再调用
contentEquals 有两个重载:
- contentEquals((CharSequence) sb) 方法
contentEquals((CharSequence) sb) 分两种情况,一种是cs instanceof AbstractStringBuilder,另外一种是参数是 String 类型。具体比较方式几乎和 equals 方法类似,先做“宏观”比较,在做“微观”比较。
下面这个是 equalsIgnoreCase 代码的实现:
public boolean equalsIgnoreCase(String anotherString) {return (this == anotherString) ? true : (anotherString != null) && (anotherString.value.length == value.length) && regionMatches(true, 0, anotherString, 0, value.length);}
看到这段代码,眼前为之一亮。使用一个三目运算符和 && 操作代替了多个 if 语句。
hashCode
public int hashCode(){int h = hash;if(h == 0 && value.length > 0){char val[] = value;for(int i = 0; i < value.length; i++){h = 31 * h + val[i];}hash = h;}return h;}
hashCode 的实现其实就是使用数学公式:s[0] 31^(n-1) + s[1] 31^(n-2) + … + s[n-1]
所谓“冲突”,就是在存储数据计算 hash 地址的时候,我们希望尽量减少有同样的 hash 地址。如果使用相同 hash 地址的数据过多,那么这些数据所组成的 hash 链就更长,从而降低了查询效率。
所以在选择系数的时候要选择尽量长的系数并且让乘法尽量不要溢出的系数,因为如果计算出来的 hash 地址越大,所谓的“冲突”就越少,查找起来效率也会提高。
现在很多虚拟机里面都有做相关优化,使用 31 的原因可能是为了更好的分配 hash 地址,并且 31 只占用 5 bits。
在 Java 中,整型数是 32 位的,也就是说最多有 2^32 = 4294967296 个整数,将任意一个字符串,经过 hashCode 计算之后,得到的整数应该在这 4294967296 数之中。那么,最多有 4294967297 个不同的字符串作 hashCode 之后,肯定有两个结果是一样的。
hashCode 可以保证相同的字符串的 hash 值肯定相同,但是 hash 值相同并不一定是 value 值就相同。
substring
前面我们介绍过,java 7 中的 substring 方法使用
String(value, beginIndex, subLen) 方法创建一个新的 String 并返回,这个方法会将原来的 char[] 中的值逐一复制到新的 String 中,两个数组并不是共享的,虽然这样做损失一些性能,但是有效地避免了内存泄露。
replaceFirst、replaceAll、replace区别String replaceFirst(String regex, String replacement)String replaceAll(String regex, String replacement)String replace(Char Sequencetarget, Char Sequencereplacement)
public String replace(char oldChar, char newChar){if(oldChar != newChar){int len = value.length;int i = -1;char[] val = value; /*avoid get field opcode*/while (++i < len){if (val[i] == oldChar){break;}}if( i < len ){char buf[] = new char[len];for (intj=0; j<i; j++){buf[j] = val[j];}while (i < len){char c = val[i];buf[i] = (c == oldChar) ? newChar : c;i++;}return new String(buf,true);}}return this;}
- replace 的参数是 char 和 CharSequence,即可以支持字符的替换, 也支持字符串的替换
- replaceAll 和 replaceFirst 的参数是 regex,即基于规则表达式的替换
比如可以通过 replaceAll (“\d”, “*”)把一个字符串所有的数字字符都换成星号;
相同点是都是全部替换,即把源字符串中的某一字符或字符串全部换成指定的字符或字符串,如果只想替换第一次出现的,可以使用 replaceFirst(),这个方法也是基于规则表达式的替换。另外,如果replaceAll() 和r eplaceFirst() 所用的参数据不是基于规则表达式的,则与replace()替换字符串的效果是一样的,即这两者也支持字符串的操作。
copyValueOf 和 valueOf
String 的底层是由 char[] 实现的,早期的 String 构造器的实现呢,不会拷贝数组的,直接将参数的 char[] 数组作为 String 的 value 属性。字符数组将导致字符串的变化。
为了避免这个问题,提供了 copyValueOf 方法,每次都拷贝成新的字符数组来构造新的 String 对象。
现在的 String 对象,在构造器中就通过拷贝新数组实现了,所以这两个方面在本质上已经没区别了。
valueOf()有很多种形式的重载,包括:
public static String valueOf(boolean b) {return b ? "true" : "false";}public static String valueOf(char c) {char data[] = {c};return new String(data, true);}public static String valueOf(int i) {return Integer.toString(i);}public static String valueOf(long l) {return Long.toString(l);}public static String valueOf(float f) {return Float.toString(f);}public static String valueOf(double d) {return Double.toString(d);}
可以看到这些方法可以将六种基本数据类型的变量转换成 String 类型。
intern()方法public native String intern(); 该方法返回一个字符串对象的内部化引用。
String 类维护一个初始为空的字符串的对象池,当 intern 方法被调用时,如果对象池中已经包含这一个相等的字符串对象则返回对象池中的实例,否则添加字符串到对象池并返回该字符串的引用。
String 对 “+” 的重载
我们知道,Java 是不支持重载运算符,String 的 “+” 是 java 中唯一的一个重载运算符,那么 java 使如何实现这个加号的呢?我们先看一段代码:
public static void main(String[] args) {String string = "hello";String string2 = string + "world";}
然后我们将这段代码的实际执行情况贴出来看看:
public static void main(String args[]){String string = "hollo";String string2 = (new StringBuilder(String.valueOf(string))).append("world").toString();}
看了反编译之后的代码我们发现,其实 String 对 “+” 的支持其实就是使用了 StringBuilder 以及他的 append、toString 两个方法。
String.valueOf和Integer.toString的区别
接下来我们看以下这段代码,我们有三种方式将一个 int 类型的变量变成呢过String类型,那么他们有什么区别?
int i = 5;String i1 = "" + i;String i2 = String.valueOf(i);String i3 = Integer.toString(i);
第三行和第四行没有任何区别,因为 String.valueOf(i) 也是调用
Integer.toString(i) 来实现的。
第二行代码其实是 String i1 = (new StringBuilder()).append(i).toString();
首先创建了一个 StringBuilder 对象,然后再调用 append 方法,再调用 toString 方法。
switch 对字符串支持的实现
还是先上代码:
public class switchDemoString {public static void main(String[] args) {String str = "world";switch (str) {case "hello":System.out.println("hello");break;case "world":System.out.println("world");break;default: break;}}}
对编译后的代码进行反编译:
public static void main(String args[]) {String str = "world";String s;switch((s = str).hashCode()) {case 99162322:if(s.equals("hello"))System.out.println("hello");break;case 113318802:if(s.equals("world"))System.out.println("world");break;default: break;}}
看到这个代码,你知道原来字符串的 switch 是通过 equals() 和 hashCode() 方法来实现的。记住,switch 中只能使用整型,比如 byte,short,char(ackii码是整型) 以及 int。还好 hashCode() 方法返回的是 int 而不是 long。
通过这个很容易记住 hashCode 返回的是 int 这个事实。仔细看下可以发现,进行 switch 的实际是哈希值,然后通过使用 equals 方法比较进行安全检查,这个检查是必要的,因为哈希可能会发生碰撞。
因此性能是不如使用枚举进行 switch 或者使用纯整数常量,但这也不是很差。因为 Java 编译器只增加了一个 equals 方法,如果你比较的是字符串字面量的话会非常快,比如 ”abc” ==”abc” 。如果你把 hashCode() 方法的调用也考虑进来了,那么还会再多一次的调用开销,因为字符串一旦创建了,它就会把哈希值缓存起来。
因此如果这个 siwtch 语句是用在一个循环里的,比如逐项处理某个值,或者游戏引擎循环地渲染屏幕,这里 hashCode() 方法的调用开销其实不会很大。
其实 swich 只支持一种数据类型,那就是整型,其他数据类型都是转换成整型之后在使用 switch 的。
总结
一旦 String 对象在内存(堆)中被创建出来,就无法被修改。
特别要注意的是,String 类的所有方法都没有改变字符串本身的值,都是返回了一个新的对象。
如果你需要一个可修改的字符串,应该使用 StringBuffer 或者
StringBuilder。否则会有大量时间浪费在垃圾回收上,因为每次试图修改都有新的String 对象被创建出来。
如果你只需要创建一个字符串,你可以使用双引号的方式,如果你需要在堆中创建一个新的对象,你可以选择构造函数的方式。
作者:石先
链接:https://www.jianshu.com/p/799c4459b808
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1. 面向对象和面向过程的区别
- 面向过程 :面向过程性能比面向对象高。 因为类调用时需要实例化,开销比较大,比较消耗资源,所以当性能是最重要的考量因素的时候,比如单片机、嵌入式开发、Linux/Unix等一般采用面向过程开发。但是,面向过程没有面向对象易维护、易复用、易扩展。
- 面向对象 :面向对象易维护、易复用、易扩展。 因为面向对象有封装、继承、多态性的特性,所以可以设计出低耦合的系统,使系统更加灵活、更加易于维护。但是,面向对象性能比面向过程低。
参见 issue : 面向过程 :面向过程性能比面向对象高??
这个并不是根本原因,面向过程也需要分配内存,计算内存偏移量,Java性能差的主要原因并不是因为它是面向对象语言,而是Java是半编译语言,最终的执行代码并不是可以直接被CPU执行的二进制机械码。 而面向过程语言大多都是直接编译成机械码在电脑上执行,并且其它一些面向过程的脚本语言性能也并不一定比Java好。
2. Java 语言有哪些特点?
- 简单易学;
- 面向对象(封装,继承,多态);
- 平台无关性( Java 虚拟机实现平台无关性);
- 可靠性;
- 安全性;
- 支持多线程( C++ 语言没有内置的多线程机制,因此必须调用操作系统的多线程功能来进行多线程程序设计,而 Java 语言却提供了多线程支持);
- 支持网络编程并且很方便( Java 语言诞生本身就是为简化网络编程设计的,因此 Java 语言不仅支持网络编程而且很方便);
- 编译与解释并存;
修正(参见: issue#544):C11开始(2011年的时候),C就引入了多线程库,在windows、linux、macos都可以使用
std::thread和std::async来创建线程。参考链接:http://www.cplusplus.com/reference/thread/thread/?kw=thread
3. 关于 JVM JDK 和 JRE 最详细通俗的解答
JVM
Java虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。
什么是字节码?采用字节码的好处是什么?
在 Java 中,JVM可以理解的代码就叫做
字节码(即扩展名为.class的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不针对一种特定的机器,因此,Java程序无须重新编译便可在多种不同操作系统的计算机上运行。
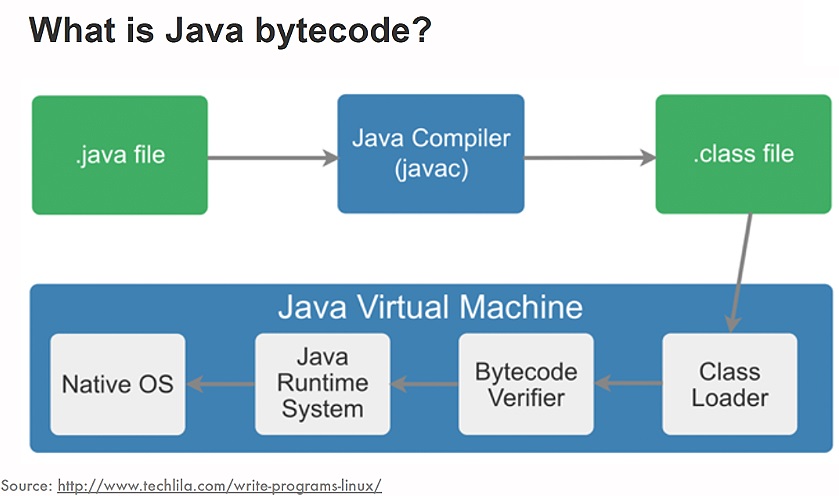
Java 程序从源代码到运行一般有下面3步:

我们需要格外注意的是 .class->机器码 这一步。在这一步 JVM 类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会相对比较慢。而且,有些方法和代码块是经常需要被调用的(也就是所谓的热点代码),所以后面引进了 JIT 编译器,而JIT 属于运行时编译。当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。这也解释了我们为什么经常会说 Java 是编译与解释共存的语言。
HotSpot采用了惰性评估(Lazy Evaluation)的做法,根据二八定律,消耗大部分系统资源的只有那一小部分的代码(热点代码),而这也就是JIT所需要编译的部分。JVM会根据代码每次被执行的情况收集信息并相应地做出一些优化,因此执行的次数越多,它的速度就越快。JDK 9引入了一种新的编译模式AOT(Ahead of Time Compilation),它是直接将字节码编译成机器码,这样就避免了JIT预热等各方面的开销。JDK支持分层编译和AOT协作使用。但是 ,AOT 编译器的编译质量是肯定比不上 JIT 编译器的。
总结:
Java虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。字节码和不同系统的 JVM 实现是 Java 语言“一次编译,随处可以运行”的关键所在。
JDK 和 JRE
JDK是Java Development Kit,它是功能齐全的Java SDK。它拥有JRE所拥有的一切,还有编译器(javac)和工具(如javadoc和jdb)。它能够创建和编译程序。
JRE 是 Java运行时环境。它是运行已编译 Java 程序所需的所有内容的集合,包括 Java虚拟机(JVM),Java类库,java命令和其他的一些基础构件。但是,它不能用于创建新程序。
如果你只是为了运行一下 Java 程序的话,那么你只需要安装 JRE 就可以了。如果你需要进行一些 Java 编程方面的工作,那么你就需要安装JDK了。但是,这不是绝对的。有时,即使您不打算在计算机上进行任何Java开发,仍然需要安装JDK。例如,如果要使用JSP部署Web应用程序,那么从技术上讲,您只是在应用程序服务器中运行Java程序。那你为什么需要JDK呢?因为应用程序服务器会将 JSP 转换为 Java servlet,并且需要使用 JDK 来编译 servlet。
4. Oracle JDK 和 OpenJDK 的对比
可能在看这个问题之前很多人和我一样并没有接触和使用过 OpenJDK 。那么Oracle和OpenJDK之间是否存在重大差异?下面我通过收集到的一些资料,为你解答这个被很多人忽视的问题。
对于Java 7,没什么关键的地方。OpenJDK项目主要基于Sun捐赠的HotSpot源代码。此外,OpenJDK被选为Java 7的参考实现,由Oracle工程师维护。关于JVM,JDK,JRE和OpenJDK之间的区别,Oracle博客帖子在2012年有一个更详细的答案:
问:OpenJDK存储库中的源代码与用于构建Oracle JDK的代码之间有什么区别? 答:非常接近 - 我们的Oracle JDK版本构建过程基于OpenJDK 7构建,只添加了几个部分,例如部署代码,其中包括Oracle的Java插件和Java WebStart的实现,以及一些封闭的源代码派对组件,如图形光栅化器,一些开源的第三方组件,如Rhino,以及一些零碎的东西,如附加文档或第三方字体。展望未来,我们的目的是开源Oracle JDK的所有部分,除了我们考虑商业功能的部分。
总结:
- Oracle JDK大概每6个月发一次主要版本,而OpenJDK版本大概每三个月发布一次。但这不是固定的,我觉得了解这个没啥用处。详情参见:https://blogs.oracle.com/java-platform-group/update-and-faq-on-the-java-se-release-cadence。
- OpenJDK 是一个参考模型并且是完全开源的,而Oracle JDK是OpenJDK的一个实现,并不是完全开源的;
- Oracle JDK 比 OpenJDK 更稳定。OpenJDK和Oracle JDK的代码几乎相同,但Oracle JDK有更多的类和一些错误修复。因此,如果您想开发企业/商业软件,我建议您选择Oracle JDK,因为它经过了彻底的测试和稳定。某些情况下,有些人提到在使用OpenJDK 可能会遇到了许多应用程序崩溃的问题,但是,只需切换到Oracle JDK就可以解决问题;
- 在响应性和JVM性能方面,Oracle JDK与OpenJDK相比提供了更好的性能;
- Oracle JDK不会为即将发布的版本提供长期支持,用户每次都必须通过更新到最新版本获得支持来获取最新版本;
- Oracle JDK根据二进制代码许可协议获得许可,而OpenJDK根据GPL v2许可获得许可。
5. Java和C++的区别?
我知道很多人没学过 C++,但是面试官就是没事喜欢拿咱们 Java 和 C++ 比呀!没办法!!!就算没学过C++,也要记下来!
- 都是面向对象的语言,都支持封装、继承和多态
- Java 不提供指针来直接访问内存,程序内存更加安全
- Java 的类是单继承的,C++ 支持多重继承;虽然 Java 的类不可以多继承,但是接口可以多继承。
- Java 有自动内存管理机制,不需要程序员手动释放无用内存
- 在 C 语言中,字符串或字符数组最后都会有一个额外的字符‘\0’来表示结束。但是,Java 语言中没有结束符这一概念。 这是一个值得深度思考的问题,具体原因推荐看这篇文章: https://blog.csdn.net/sszgg2006/article/details/49148189
6. 什么是 Java 程序的主类 应用程序和小程序的主类有何不同?
一个程序中可以有多个类,但只能有一个类是主类。在 Java 应用程序中,这个主类是指包含 main()方法的类。而在 Java 小程序中,这个主类是一个继承自系统类 JApplet 或 Applet 的子类。应用程序的主类不一定要求是 public 类,但小程序的主类要求必须是 public 类。主类是 Java 程序执行的入口点。
7. Java 应用程序与小程序之间有哪些差别?
简单说应用程序是从主线程启动(也就是 main() 方法)。applet 小程序没有 main() 方法,主要是嵌在浏览器页面上运行(调用init()或者run()来启动),嵌入浏览器这点跟 flash 的小游戏类似。
8. 字符型常量和字符串常量的区别?
- 形式上: 字符常量是单引号引起的一个字符; 字符串常量是双引号引起的若干个字符
- 含义上: 字符常量相当于一个整型值( ASCII 值),可以参加表达式运算; 字符串常量代表一个地址值(该字符串在内存中存放位置)
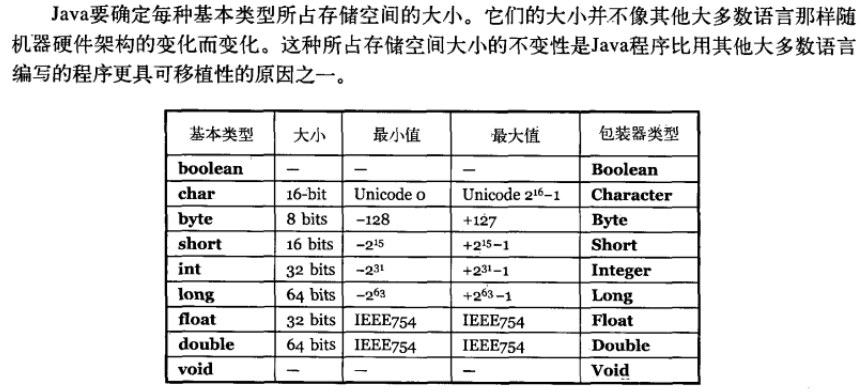
- 占内存大小 字符常量只占2个字节; 字符串常量占若干个字节 (注意: char在Java中占两个字节)
java编程思想第四版:2.2.2节
9. 构造器 Constructor 是否可被 override?
Constructor 不能被 override(重写),但是可以 overload(重载),所以你可以看到一个类中有多个构造函数的情况。
10. 重载和重写的区别
重载
发生在同一个类中,方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同。
下面是《Java核心技术》对重载这个概念的介绍:

重写
重写是子类对父类的允许访问的方法的实现过程进行重新编写,发生在子类中,方法名、参数列表必须相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类。另外,如果父类方法访问修饰符为 private 则子类就不能重写该方法。也就是说方法提供的行为改变,而方法的外貌并没有改变。
11. Java 面向对象编程三大特性: 封装 继承 多态
封装
封装把一个对象的属性私有化,同时提供一些可以被外界访问的属性的方法,如果属性不想被外界访问,我们大可不必提供方法给外界访问。但是如果一个类没有提供给外界访问的方法,那么这个类也没有什么意义了。
继承
继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。通过使用继承我们能够非常方便地复用以前的代码。
关于继承如下 3 点请记住:
- 子类拥有父类对象所有的属性和方法(包括私有属性和私有方法),但是父类中的私有属性和方法子类是无法访问,只是拥有。
- 子类可以拥有自己属性和方法,即子类可以对父类进行扩展。
- 子类可以用自己的方式实现父类的方法。(以后介绍)。
多态
所谓多态就是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量到底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。
在Java中有两种形式可以实现多态:继承(多个子类对同一方法的重写)和接口(实现接口并覆盖接口中同一方法)。
12. String StringBuffer 和 StringBuilder 的区别是什么? String 为什么是不可变的?
可变性
简单的来说:String 类中使用 final 关键字修饰字符数组来保存字符串,private final char value[],所以 String 对象是不可变的。而StringBuilder 与 StringBuffer 都继承自 AbstractStringBuilder 类,在 AbstractStringBuilder 中也是使用字符数组保存字符串char[]value 但是没有用 final 关键字修饰,所以这两种对象都是可变的。
StringBuilder 与 StringBuffer 的构造方法都是调用父类构造方法也就是 AbstractStringBuilder 实现的,大家可以自行查阅源码。
AbstractStringBuilder.java
abstract class AbstractStringBuilder implements Appendable, CharSequence {char[] value;int count;AbstractStringBuilder() {}AbstractStringBuilder(int capacity) {value = new char[capacity];}
线程安全性
String 中的对象是不可变的,也就可以理解为常量,线程安全。AbstractStringBuilder 是 StringBuilder 与 StringBuffer 的公共父类,定义了一些字符串的基本操作,如 expandCapacity、append、insert、indexOf 等公共方法。StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder 并没有对方法进行加同步锁,所以是非线程安全的。
性能
每次对 String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象。StringBuffer 每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 StringBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
对于三者使用的总结:
- 操作少量的数据: 适用String
- 单线程操作字符串缓冲区下操作大量数据: 适用StringBuilder
- 多线程操作字符串缓冲区下操作大量数据: 适用StringBuffer
13. 自动装箱与拆箱
- 装箱:将基本类型用它们对应的引用类型包装起来;
- 拆箱:将包装类型转换为基本数据类型;
14. 在一个静态方法内调用一个非静态成员为什么是非法的?
由于静态方法可以不通过对象进行调用,因此在静态方法里,不能调用其他非静态变量,也不可以访问非静态变量成员。
15. 在 Java 中定义一个不做事且没有参数的构造方法的作用
Java 程序在执行子类的构造方法之前,如果没有用 super()来调用父类特定的构造方法,则会调用父类中“没有参数的构造方法”。因此,如果父类中只定义了有参数的构造方法,而在子类的构造方法中又没有用 super()来调用父类中特定的构造方法,则编译时将发生错误,因为 Java 程序在父类中找不到没有参数的构造方法可供执行。解决办法是在父类里加上一个不做事且没有参数的构造方法。
16. import java和javax有什么区别?
刚开始的时候 JavaAPI 所必需的包是 java 开头的包,javax 当时只是扩展 API 包来使用。然而随着时间的推移,javax 逐渐地扩展成为 Java API 的组成部分。但是,将扩展从 javax 包移动到 java 包确实太麻烦了,最终会破坏一堆现有的代码。因此,最终决定 javax 包将成为标准API的一部分。
所以,实际上java和javax没有区别。这都是一个名字。
17. 接口和抽象类的区别是什么?
- 接口的方法默认是 public,所有方法在接口中不能有实现(Java 8 开始接口方法可以有默认实现),而抽象类可以有非抽象的方法。
- 接口中除了static、final变量,不能有其他变量,而抽象类中则不一定。
- 一个类可以实现多个接口,但只能实现一个抽象类。接口自己本身可以通过extends关键字扩展多个接口。
- 接口方法默认修饰符是public,抽象方法可以有public、protected和default这些修饰符(抽象方法就是为了被重写所以不能使用private关键字修饰!)。
- 从设计层面来说,抽象是对类的抽象,是一种模板设计,而接口是对行为的抽象,是一种行为的规范。
备注:在JDK8中,接口也可以定义静态方法,可以直接用接口名调用。实现类和实现是不可以调用的。如果同时实现两个接口,接口中定义了一样的默认方法,则必须重写,不然会报错。(详见issue:https://github.com/Snailclimb/JavaGuide/issues/146)
18. 成员变量与局部变量的区别有哪些?
- 从语法形式上看:成员变量是属于类的,而局部变量是在方法中定义的变量或是方法的参数;成员变量可以被 public,private,static 等修饰符所修饰,而局部变量不能被访问控制修饰符及 static 所修饰;但是,成员变量和局部变量都能被 final 所修饰。
- 从变量在内存中的存储方式来看:如果成员变量是使用
static修饰的,那么这个成员变量是属于类的,如果没有使用static修饰,这个成员变量是属于实例的。而对象存在于堆内存,局部变量则存在于栈内存。 - 从变量在内存中的生存时间上看:成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动消失。
- 成员变量如果没有被赋初值:则会自动以类型的默认值而赋值(一种情况例外:被 final 修饰的成员变量也必须显式地赋值),而局部变量则不会自动赋值。
19. 创建一个对象用什么运算符?对象实体与对象引用有何不同?
new运算符,new创建对象实例(对象实例在堆内存中),对象引用指向对象实例(对象引用存放在栈内存中)。一个对象引用可以指向0个或1个对象(一根绳子可以不系气球,也可以系一个气球);一个对象可以有n个引用指向它(可以用n条绳子系住一个气球)。
20. 什么是方法的返回值?返回值在类的方法里的作用是什么?
方法的返回值是指我们获取到的某个方法体中的代码执行后产生的结果!(前提是该方法可能产生结果)。返回值的作用:接收出结果,使得它可以用于其他的操作!
21. 一个类的构造方法的作用是什么? 若一个类没有声明构造方法,该程序能正确执行吗? 为什么?
主要作用是完成对类对象的初始化工作。可以执行。因为一个类即使没有声明构造方法也会有默认的不带参数的构造方法。
22. 构造方法有哪些特性?
- 名字与类名相同。
- 没有返回值,但不能用void声明构造函数。
- 生成类的对象时自动执行,无需调用。
23. 静态方法和实例方法有何不同
- 在外部调用静态方法时,可以使用”类名.方法名”的方式,也可以使用”对象名.方法名”的方式。而实例方法只有后面这种方式。也就是说,调用静态方法可以无需创建对象。
- 静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),而不允许访问实例成员变量和实例方法;实例方法则无此限制。
24. 对象的相等与指向他们的引用相等,两者有什么不同?
对象的相等,比的是内存中存放的内容是否相等。而引用相等,比较的是他们指向的内存地址是否相等。
25. 在调用子类构造方法之前会先调用父类没有参数的构造方法,其目的是?
帮助子类做初始化工作。
26. == 与 equals(重要)
== : 它的作用是判断两个对象的地址是不是相等。即,判断两个对象是不是同一个对象(基本数据类型比较的是值,引用数据类型比较的是内存地址)。
equals() : 它的作用也是判断两个对象是否相等。但它一般有两种使用情况:
- 情况1:类没有覆盖 equals() 方法。则通过 equals() 比较该类的两个对象时,等价于通过“==”比较这两个对象。
- 情况2:类覆盖了 equals() 方法。一般,我们都覆盖 equals() 方法来比较两个对象的内容是否相等;若它们的内容相等,则返回 true (即,认为这两个对象相等)。
举个例子:
public class test1 {public static void main(String[] args) {String a = new String("ab"); // a 为一个引用String b = new String("ab"); // b为另一个引用,对象的内容一样String aa = "ab"; // 放在常量池中String bb = "ab"; // 从常量池中查找if (aa == bb) // trueSystem.out.println("aa==bb");if (a == b) // false,非同一对象System.out.println("a==b");if (a.equals(b)) // trueSystem.out.println("aEQb");if (42 == 42.0) { // trueSystem.out.println("true");}}}
说明:
- String 中的 equals 方法是被重写过的,因为 object 的 equals 方法是比较的对象的内存地址,而 String 的 equals 方法比较的是对象的值。
- 当创建 String 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个 String 对象。
27. hashCode 与 equals (重要)
面试官可能会问你:“你重写过 hashcode 和 equals 么,为什么重写equals时必须重写hashCode方法?”
hashCode()介绍
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义在JDK的Object.java中,这就意味着Java中的任何类都包含有hashCode() 函数。
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
为什么要有 hashCode
我们先以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode: 当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的Java启蒙书《Head first java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
通过我们可以看出:hashCode() 的作用就是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode()在散列表中才有用,在其它情况下没用。在散列表中hashCode() 的作用是获取对象的散列码,进而确定该对象在散列表中的位置。
hashCode()与equals()的相关规定
- 如果两个对象相等,则hashcode一定也是相同的
- 两个对象相等,对两个对象分别调用equals方法都返回true
- 两个对象有相同的hashcode值,它们也不一定是相等的
- 因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖
- hashCode() 的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
推荐阅读:Java hashCode() 和 equals()的若干问题解答
28. 为什么Java中只有值传递?
29. 简述线程、程序、进程的基本概念。以及他们之间关系是什么?
线程与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享同一块内存空间和一组系统资源,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
程序是含有指令和数据的文件,被存储在磁盘或其他的数据存储设备中,也就是说程序是静态的代码。
进程是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即是一个进程从创建,运行到消亡的过程。简单来说,一个进程就是一个执行中的程序,它在计算机中一个指令接着一个指令地执行着,同时,每个进程还占有某些系统资源如CPU时间,内存空间,文件,输入输出设备的使用权等等。换句话说,当程序在执行时,将会被操作系统载入内存中。
线程是进程划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。从另一角度来说,进程属于操作系统的范畴,主要是同一段时间内,可以同时执行一个以上的程序,而线程则是在同一程序内几乎同时执行一个以上的程序段。
30. 线程有哪些基本状态?
Java 线程在运行的生命周期中的指定时刻只可能处于下面6种不同状态的其中一个状态(图源《Java 并发编程艺术》4.1.4节)。

线程在生命周期中并不是固定处于某一个状态而是随着代码的执行在不同状态之间切换。Java 线程状态变迁如下图所示(图源《Java 并发编程艺术》4.1.4节):
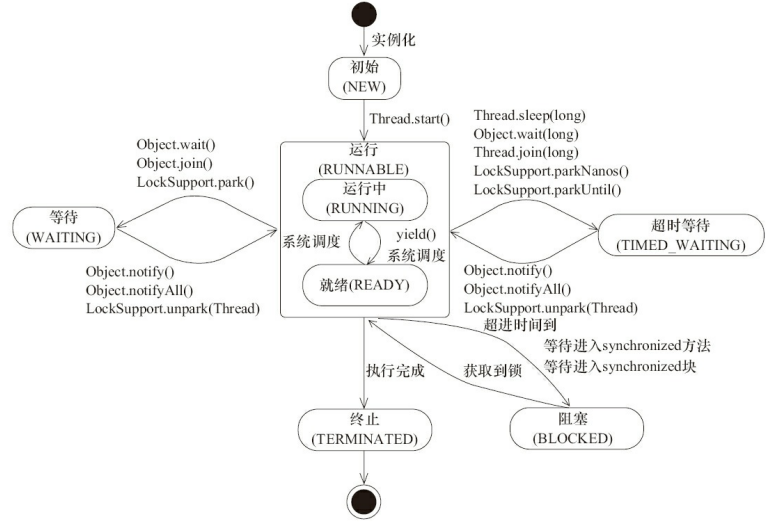
由上图可以看出:
线程创建之后它将处于 NEW(新建) 状态,调用 start() 方法后开始运行,线程这时候处于 READY(可运行) 状态。可运行状态的线程获得了 cpu 时间片(timeslice)后就处于 RUNNING(运行) 状态。
操作系统隐藏 Java虚拟机(JVM)中的 READY 和 RUNNING 状态,它只能看到 RUNNABLE 状态(图源:HowToDoInJava:Java Thread Life Cycle and Thread States),所以 Java 系统一般将这两个状态统称为 RUNNABLE(运行中) 状态 。

当线程执行 wait()方法之后,线程进入 WAITING(等待)状态。进入等待状态的线程需要依靠其他线程的通知才能够返回到运行状态,而 TIME_WAITING(超时等待) 状态相当于在等待状态的基础上增加了超时限制,比如通过 sleep(long millis)方法或 wait(long millis)方法可以将 Java 线程置于 TIMED WAITING 状态。当超时时间到达后 Java 线程将会返回到 RUNNABLE 状态。当线程调用同步方法时,在没有获取到锁的情况下,线程将会进入到 BLOCKED(阻塞) 状态。线程在执行 Runnable 的run()方法之后将会进入到 TERMINATED(终止) 状态。
31 关于 final 关键字的一些总结
final关键字主要用在三个地方:变量、方法、类。
- 对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。
- 当用final修饰一个类时,表明这个类不能被继承。final类中的所有成员方法都会被隐式地指定为final方法。
- 使用final方法的原因有两个。第一个原因是把方法锁定,以防任何继承类修改它的含义;第二个原因是效率。在早期的Java实现版本中,会将final方法转为内嵌调用。但是如果方法过于庞大,可能看不到内嵌调用带来的任何性能提升(现在的Java版本已经不需要使用final方法进行这些优化了)。类中所有的private方法都隐式地指定为final。
32 Java 中的异常处理
Java异常类层次结构图
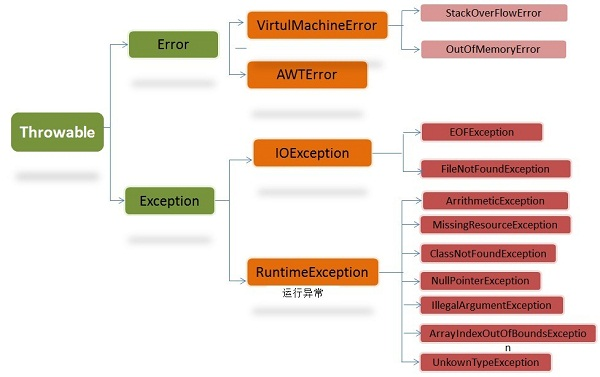
在 Java 中,所有的异常都有一个共同的祖先java.lang包中的 Throwable类。Throwable: 有两个重要的子类:Exception(异常) 和 Error(错误) ,二者都是 Java 异常处理的重要子类,各自都包含大量子类。
Error(错误):是程序无法处理的错误,表示运行应用程序中较严重问题。大多数错误与代码编写者执行的操作无关,而表示代码运行时 JVM(Java 虚拟机)出现的问题。例如,Java虚拟机运行错误(Virtual MachineError),当 JVM 不再有继续执行操作所需的内存资源时,将出现 OutOfMemoryError。这些异常发生时,Java虚拟机(JVM)一般会选择线程终止。
这些错误表示故障发生于虚拟机自身、或者发生在虚拟机试图执行应用时,如Java虚拟机运行错误(Virtual MachineError)、类定义错误(NoClassDefFoundError)等。这些错误是不可查的,因为它们在应用程序的控制和处理能力之 外,而且绝大多数是程序运行时不允许出现的状况。对于设计合理的应用程序来说,即使确实发生了错误,本质上也不应该试图去处理它所引起的异常状况。在 Java中,错误通过Error的子类描述。
Exception(异常):是程序本身可以处理的异常。Exception 类有一个重要的子类 RuntimeException。RuntimeException 异常由Java虚拟机抛出。NullPointerException(要访问的变量没有引用任何对象时,抛出该异常)、ArithmeticException(算术运算异常,一个整数除以0时,抛出该异常)和 ArrayIndexOutOfBoundsException (下标越界异常)。
注意:异常和错误的区别:异常能被程序本身处理,错误是无法处理。
Throwable类常用方法
- public string getMessage():返回异常发生时的简要描述
- public string toString():返回异常发生时的详细信息
- public string getLocalizedMessage():返回异常对象的本地化信息。使用Throwable的子类覆盖这个方法,可以生成本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与getMessage()返回的结果相同
- public void printStackTrace():在控制台上打印Throwable对象封装的异常信息
异常处理总结
- try 块: 用于捕获异常。其后可接零个或多个catch块,如果没有catch块,则必须跟一个finally块。
- catch 块: 用于处理try捕获到的异常。
- finally 块: 无论是否捕获或处理异常,finally块里的语句都会被执行。当在try块或catch块中遇到return
语句时,finally语句块将在方法返回之前被执行。
在以下4种特殊情况下,finally块不会被执行:
- 在finally语句块第一行发生了异常。 因为在其他行,finally块还是会得到执行
- 在前面的代码中用了System.exit(int)已退出程序。 exit是带参函数 ;若该语句在异常语句之后,finally会执行
- 程序所在的线程死亡。
- 关闭CPU。
下面这部分内容来自issue:https://github.com/Snailclimb/JavaGuide/issues/190。
注意: 当try语句和finally语句中都有return语句时,在方法返回之前,finally语句的内容将被执行,并且finally语句的返回值将会覆盖原始的返回值。如下:
public static int f(int value) {try {return value * value;} finally {if (value == 2) {return 0;}}}
如果调用 f(2),返回值将是0,因为finally语句的返回值覆盖了try语句块的返回值。
33 Java序列化中如果有些字段不想进行序列化,怎么办?
对于不想进行序列化的变量,使用transient关键字修饰。
transient关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被transient修饰的变量值不会被持久化和恢复。transient只能修饰变量,不能修饰类和方法。
34 获取用键盘输入常用的两种方法
方法1:通过 Scanner
Scanner input = new Scanner(System.in);String s = input.nextLine();input.close();
方法2:通过 BufferedReader
BufferedReader input = new BufferedReader(new InputStreamReader(System.in));String s = input.readLine();
35 Java 中 IO 流
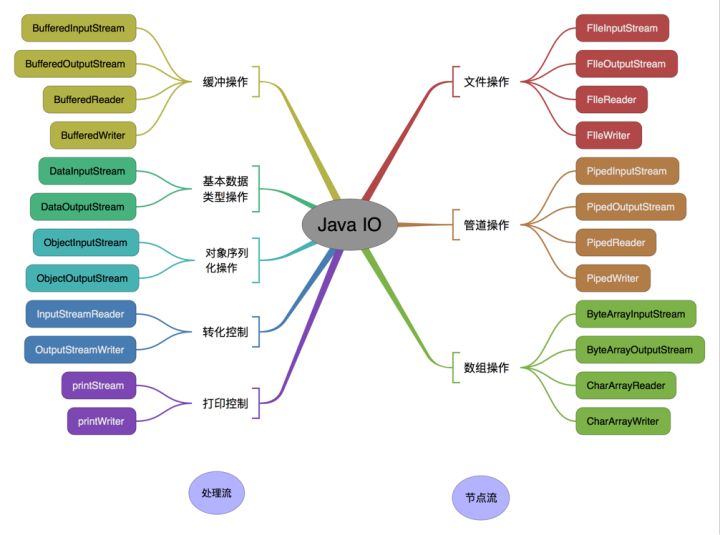
Java 中 IO 流分为几种?
- 按照流的流向分,可以分为输入流和输出流;
- 按照操作单元划分,可以划分为字节流和字符流;
- 按照流的角色划分为节点流和处理流。
Java Io流共涉及40多个类,这些类看上去很杂乱,但实际上很有规则,而且彼此之间存在非常紧密的联系, Java I0流的40多个类都是从如下4个抽象类基类中派生出来的。
- InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。
- OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
按操作方式分类结构图:
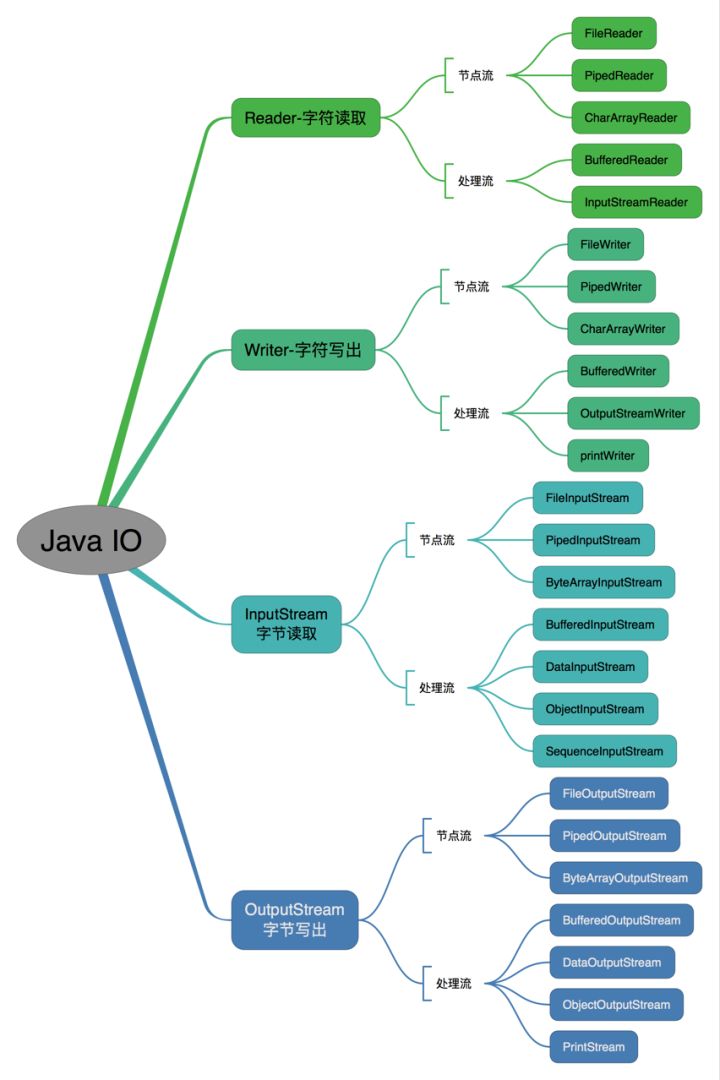
按操作对象分类结构图:
既然有了字节流,为什么还要有字符流?
问题本质想问:不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?
回答:字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还算是非常耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。
BIO,NIO,AIO 有什么区别?
- BIO (Blocking I/O): 同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
- NIO (New I/O): NIO是一种同步非阻塞的I/O模型,在Java 1.4 中引入了NIO框架,对应 java.nio 包,提供了 Channel , Selector,Buffer等抽象。NIO中的N可以理解为Non-blocking,不单纯是New。它支持面向缓冲的,基于通道的I/O操作方法。 NIO提供了与传统BIO模型中的
Socket和ServerSocket相对应的SocketChannel和ServerSocketChannel两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞I/O来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发 - AIO (Asynchronous I/O): AIO 也就是 NIO 2。在 Java 7 中引入了 NIO 的改进版 NIO 2,它是异步非阻塞的IO模型。异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。AIO 是异步IO的缩写,虽然 NIO 在网络操作中,提供了非阻塞的方法,但是 NIO 的 IO 行为还是同步的。对于 NIO 来说,我们的业务线程是在 IO 操作准备好时,得到通知,接着就由这个线程自行进行 IO 操作,IO操作本身是同步的。查阅网上相关资料,我发现就目前来说 AIO 的应用还不是很广泛,Netty 之前也尝试使用过 AIO,不过又放弃了。
36. 常见关键字总结:static,final,this,super
详见笔主的这篇文章: https://gitee.com/SnailClimb/JavaGuide/blob/master/docs/java/Basis/final、static、this、super.md
37. Collections 工具类和 Arrays 工具类常见方法总结
38. 深拷贝 vs 浅拷贝
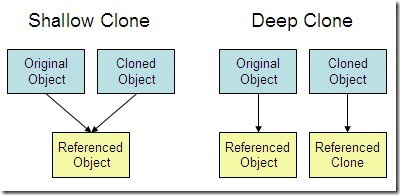
- 浅拷贝:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。
- 深拷贝:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。
参考
- https://stackoverflow.com/questions/1906445/what-is-the-difference-between-jdk-and-jre
- https://www.educba.com/oracle-vs-openjdk/
- https://stackoverflow.com/questions/22358071/differences-between-oracle-jdk-and-openjdk?answertab=active#tab-top
公众号
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
《Java面试突击》: 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本公众号后台回复 “Java面试突击” 即可免费领取!
Java工程师必备学习资源: 一些Java工程师常用学习资源公众号后台回复关键字 “1” 即可免费无套路获取。

反射中,Class.forName和ClassLoader区别
在java中Class.forName()和ClassLoader都可以对类进行加载。
区别:
(1)Class.forName除了将类的.class文件加载到jvm中之外,还会对类进行解释,执行类中的static块。
(2)而classloader只干一件事情,就是将.class文件加载到jvm中,不会执行static中的内容,只有在newInstance才会去执行static块。
#Class.forName(name,initialize,loader)带参数也可控制是否加载static块。并且只有调用了newInstance()方法采用调用构造函数,创建类的对象。
ClassLoader就是遵循双亲委派模型最终调用启动类加载器的类加载器,实现的功能是“通过一个类的全限定名来获取描述此类的二进制字节流”,获取到二进制流后放到JVM中。Class.forName()方法实际上也是调用的CLassLoader来实现的。
Java类装载过程
装载:通过类的全限定名(com.codetop.*.User)获取二进制字节流,将二进制字节流转换成方法区中的运行时数据结构,在内存中生成Java.lang.class对象;
链接:执行下面的校验、准备和解析步骤,其中解析步骤是可以选择的;
校验:检查导入类或接口的二进制数据的正确性;(文件格式验证,元数据验证,字节码验证,符号引用验证)
准备:给类的静态变量分配并初始化存储空间;
解析:将常量池中的符号引用转成直接引用;
初始化:激活类的静态变量的初始化Java代码和静态Java代码块,并初始化程序员设置的变量值。
Class.forName(className)方法,内部实际调用的方法是 Class.forName(className,true,classloader);
第2个boolean参数表示类是否需要初始化, Class.forName(className)默认是需要初始化。
一旦初始化,就会触发目标对象的 static块代码执行,static参数也也会被再次初始化。
ClassLoader.loadClass(className)方法,内部实际调用的方法是 ClassLoader.loadClass(className,false);
第2个 boolean参数,表示目标对象是否进行链接,false表示不进行链接,由上面介绍可以,
不进行链接意味着不进行包括初始化等一些列步骤,那么静态块和静态对象就不会得到执行
JDBC Driver源码如下,因此使用Class.forName(classname)才能在反射回去类的时候执行static块
static {
try {
java.sql.DriverManager.registerDriver(new Driver());
} catch (SQLException E) {
throw new RuntimeException(“Can’t register driver!”);
}
}
JVM 的一些知识
在说明finalize()的用法之前要树立有关于java垃圾回收器几个观点:
- 对象可以不被垃圾回收
java的垃圾回收遵循一个特点, 就是能不回收就不会回收.只要程序的内存没有达到即将用完的地步, 对象占用的空间就不会被释放。
因为如果程序正常结束了,而且垃圾回收器没有释放申请的内存, 那么随着程序的正常退出, 申请的内存会自动交还给操作系统;
而且垃圾回收本身就需要付出代价, 是有一定开销的, 如果不使用,就不会存在这一部分的开销。
- 垃圾回收只能回收内存
而且只能回收内存中由java创建对象方式(堆)创建的对象所占用的那一部分内存, 无法回收其他资源, 比如文件操作的句柄, 数据库的连接等等。
- 垃圾回收不是C++中的析构
两者不是对应关系, 因为第一点就指出了垃圾回收的发生是不确定的, 而C++中析构函数是由程序员控制(delete) 或者离开器作用域时自动调用发生, 是在确定的时间对对象进行销毁并释放其所占用的内存。
-
finalize的作用
finalize()是Object的protected方法,子类可以覆盖该方法以实现资源清理工作,GC在回收对象之前调用该方法。
finalize()与C++中的析构函数不是对应的。
C++中的析构函数调用的时机是确定的(对象离开作用域或delete掉),但Java中的finalize的调用具有不确定性。
finalize() 的功能: 一旦垃圾回收器准备释放对象所占的内存空间, 如果对象覆盖了finalize()并且函数体内不能是空的, 就会首先调用对象的finalize(), 然后在下一次垃圾回收动作发生的时候真正收回对象所占的空间。
finalize() 有一个特点就是: JVM始终只调用一次. 无论这个对象被垃圾回收器标记为什么状态, finalize()始终只调用一次. 但是程序员在代码中主动调用的不记录在这之内。finalize函数的调用机制
java虚拟机规范并没有硬性规定垃圾回收该不该搞,以及该如何搞。所以这里提到的调用机制不能保证适合所有jvm。
何时被调用?
finalize啥时候才会被调用捏?
一般来说,要等到JVM开始进行垃圾回收的时候,它才有可能被调用。
而JVM进行垃圾回收的时间点是非常不确定的,依赖于各种运行时的环境因素。
正是由于finalize函数调用时间点的不确定,导致了后面提到的某些缺点。谁来调用?
常见的JVM会通过GC的垃圾回收线程来进行finalize函数的调用。
由于垃圾回收线程比较重要(人家好歹也是JVM的一个组成部分嘛),为了防止finalize函数抛出的异常影响到垃圾回收线程的运作,垃圾回收线程会在调用每一个finalize函数时进行try catch,如果捕获到异常,就直接丢弃,然后接着处理下一个失效对象的finalize函数。使用场景
不建议使用的原因
一些问题
一些与finalize相关的方法,由于一些致命的缺陷,已经被废弃了,如System.runFinalizersOnExit()方法、Runtime.runFinalizersOnExit()方法
System.gc()与System.runFinalization()方法增加了finalize方法执行的机会,但不可盲目依赖它们
Java语言规范并不保证finalize方法会被及时地执行、而且根本不会保证它们会被执行
finalize方法可能会带来性能问题。因为JVM通常在单独的低优先级线程中完成finalize的执行
对象再生问题:finalize方法中,可将待回收对象赋值给GC Roots可达的对象引用,从而达到对象再生的目的
finalize方法至多由GC执行一次(用户当然可以手动调用对象的finalize方法,但并不影响GC对finalize的行为)适合的场景
finalize()主要使用的方面:
根据垃圾回收器的第2点可知, java垃圾回收器只能回收创建在堆中的java对象, 而对于不是这种方式创建的对象则没有方法处理, 这就需要使用finalize()对这部分对象所占的资源进行释放. 使用到这一点的就是JNI本地对象, 通过JNI来调用本地方法创建的对象只能通过finalize()保证使用之后进行销毁,释放内存
充当保证使用之后释放资源的最后一道屏障, 比如使用数据库连接之后未断开,并且由于程序员的个人原因忘记了释放连接, 这时就只能依靠finalize()函数来释放资源.
《thinking in java》中所讲到的“终结条件”验证, 通过finalize()方法来试图找出程序的漏洞
尽管finalize()可以主动调用, 但是最好不要主动调用, 因为在代码中主动调用之后, 如果JVM再次调用, 由于之前的调用已经释放过资源了,所以二次释放资源就有可能出现导致出现空指针等异常, 而恰好这些异常是没有被捕获的, 那么就造成对象处于被破坏的状态, 导致该对象所占用的某一部分资源无法被回收而浪费.尽量避免使用finalize():
finalize()不一定会被调用, 因为java的垃圾回收器的特性就决定了它不一定会被调用
就算finalize()函数被调用, 它被调用的时间充满了不确定性, 因为程序中其他线程的优先级远远高于执行 finalize() 函数线程的优先级。
也许等到finalize()被调用, 数据库的连接池或者文件句柄早就耗尽了。
如果一种未被捕获的异常在使用finalize方法时被抛出,这个异常不会被捕获,finalize方法的终结过程也会终止,造成对象出于破坏的状态。被破坏的对象又很可能导致部分资源无法被回收, 造成浪费。
finalize()和垃圾回收器的运行本身就要耗费资源, 也许会导致程序的暂时停止。禁止使用的原因
1.调用时间不确定—有资源浪费的风险
前面已经介绍了调用机制。
同学们应该认清“finalize的调用时机是很不确定的”这样一个事实。
所以,假如你把某些稀缺资源放到finalize()中释放,可能会导致该稀缺资源等上很久很久很久以后才被释放。
这可是资源的浪费啊!另外,某些类对象所携带的资源(比如某些JDBC的类)可能本身就很耗费内存,这些资源的延迟释放会造成很大的性能问题。2. 可能不被调用—-有资源泄露的风险
很多同学以为finalize()总是会被调用,其实不然。
在某些情况下,finalize()压根儿不被调用。
比如在JVM退出的当口,内存中那些对象的finalize函数可能就不会被调用了。
估计有同学在打“runFinalizersOnExit”的主意,来确保所有的finalize在JVM退出前被调用。
很可惜也很遗憾,该方法从JDK 1.2开始,就已经被废弃了。即使该方法不被废弃,也是有很大的线程安全隐患滴!
从上述可以看出,一旦你依赖finalize()来帮你释放资源,那可是很不妙啊(有资源泄漏的危险)!
很多时候,资源泄露导致的性能问题更加严重,万万不可小看。3. 对象可能在finalize函数调用时复活
本来,只有当某个对象已经失效(没有引用),垃圾回收器才会调用该对象的finalize函数。但是,万一碰上某个变态的程序员,在finalize()函数内部再把对象自身的引用(也就是this)重新保存在某处,也就相当于把自己复活了(因为这个对象重新有了引用,不再处于失效状态)。 为了防止发生这种诡异的事情,垃圾回收器只能在每次调用完finalize()之后再次去检查该对象是否还处于失效状态。这无形中又增加了JVM的开销。随便提一下。由于JDK的文档中规定了,JVM对于每一个类对象实例最多只会调用一次finalize()。所以,对于那些诈尸的实例,当它们真正死亡时,finalize()反而不会被调用了。这看起来是不是很奇怪?
4. 要记得自己做异常捕获
刚才在介绍finalize()调用机制时提到,一旦有异常抛出到finalize函数外面,会被垃圾回收线程捕获并丢弃。
也就是说,异常被忽略掉了(异常被忽略的危害,“这里”有提到)。
为了防止这种事儿,凡是finalize()中有可能抛出异常的代码,你都得写上try catch语句,自己进行捕获。5. 小心线程安全
由于调用finalize()的是垃圾回收线程,和你自己代码的线程不是同一个线程;
甚至不同对象的finalize()可能会被不同的垃圾回收线程调用(比如使用“并行收集器”的时候)。
所以,当你在finalize()里面访问某些数据的时候,还得时刻留心线程安全的问题。finalize 的执行过程(生命周期)
大致流程
首先,大致描述一下finalize流程:当对象变成(GC Roots)不可达时,GC会判断该对象是否覆盖了finalize方法,若未覆盖,则直接将其回收。
否则,若对象未执行过finalize方法,将其放入F-Queue队列,由一低优先级线程执行该队列中对象的finalize方法。
执行finalize方法完毕后,GC会再次判断该对象是否可达,若不可达,则进行回收,否则,对象“复活”。具体的finalize流程:
对象可由两种状态,涉及到两类状态空间。
一是终结状态空间F = {unfinalized, finalizable, finalized};
二是可达状态空间R = {reachable, finalizer-reachable, unreachable}。
各状态含义如下:
unfinalized: 新建对象会先进入此状态,GC并未准备执行其finalize方法,因为该对象是可达的
finalizable: 表示GC可对该对象执行finalize方法,GC已检测到该对象不可达。
正如前面所述,GC通过F-Queue队列和一专用线程完成finalize的执行
finalized: 表示GC已经对该对象执行过finalize方法
reachable: 表示GC Roots引用可达
finalizer-reachable(f-reachable):表示不是reachable,但可通过某个finalizable对象可达
unreachable:对象不可通过上面两种途径可达 状态变迁图
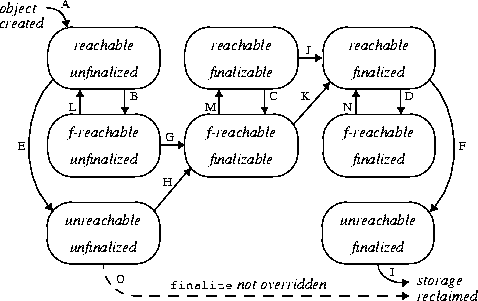
变迁说明
新建对象首先处于[reachable, unfinalized]状态(A)
随着程序的运行,一些引用关系会消失,导致状态变迁,从reachable状态变迁到f-reachable(B, C, D)或unreachable(E, F)状态
若JVM检测到处于unfinalized状态的对象变成f-reachable或unreachable,JVM会将其标记为finalizable状态(G,H)。若对象原处于[unreachable, unfinalized]状态,则同时将其标记为f-reachable(H)。
在某个时刻,JVM取出某个finalizable对象,将其标记为finalized并在某个线程中执行其finalize方法。由于是在活动线程中引用了该对象,该对象将变迁到(reachable, finalized)状态(K或J)。该动作将影响某些其他对象从f-reachable状态重新回到reachable状态(L, M, N)
处于finalizable状态的对象不能同时是unreahable的,由第4点可知,将对象finalizable对象标记为finalized时会由某个线程执行该对象的finalize方法,致使其变成reachable。这也是图中只有八个状态点的原因
程序员手动调用finalize方法并不会影响到上述内部标记的变化,因此JVM只会至多调用finalize一次,即使该对象“复活”也是如此。
程序员手动调用多少次不影响JVM的行为
若JVM检测到finalized状态的对象变成unreachable,回收其内存(I)
若对象并未覆盖finalize方法,JVM会进行优化,直接回收对象(O)
注:System.runFinalizersOnExit()等方法可以使对象即使处于reachable状态,JVM仍对其执行finalize方法
测试代码
对象复活
public class GC {public static GC SAVE_HOOK = null;public static void main(String[] args) throws InterruptedException {SAVE_HOOK = new GC();SAVE_HOOK = null;System.gc();Thread.sleep(500);if (null != SAVE_HOOK) { //此时对象应该处于(reachable, finalized)状态System.out.println("Yes , I am still alive");} else {System.out.println("No , I am dead");}SAVE_HOOK = null;System.gc();Thread.sleep(500);if (null != SAVE_HOOK) {System.out.println("Yes , I am still alive");} else {System.out.println("No , I am dead");}}@Overrideprotected void finalize() throws Throwable {super.finalize();System.out.println("execute method finalize()");SAVE_HOOK = this;}}
测试案例2
class C {static A a;}class A {B b;public A(B b) {this.b = b;}@Overridepublic void finalize() {System.out.println("A finalize");C.a = this;}}class B {String name;int age;public B(String name, int age) {this.name = name;this.age = age;}@Overridepublic void finalize() {System.out.println("B finalize");}@Overridepublic String toString() {return name + " is " + age;}}public class Main {public static void main(String[] args) throws Exception {A a = new A(new B("allen", 20));a = null;System.gc();Thread.sleep(5000);System.out.println(C.a.b);}}
我的理解:为方便起见, 把a,b两个变量所指的内存空间就叫做a和b
A a = new A(new B("allen" , 20)); //此时a和b都是reachable, unfinalized状态a = null;
这之后, a和b的状态会在某一个时刻变成unreachable, unfinalized(但是b变成了unreachable还是f-reachable我不是很确定, 如果大家知道,欢迎补充^_^) 或者a和b直接变成f-reachable, unfianlized。
然后在某个时刻,GC检测到a和b处于unfinalized状态, 就将他们添加到F-queue,并将状态改为f-reachable finalizable.
之后分两种情况: 第一: GC从F-queue中首先取出a, 并被某个线程执行了finalize(), 也就相当于被某个活动的线程持有, a状态变成了reachable, finalized. 此时由于a被c对象所引用,所以之后不会变成unreachable finalized而被销毁(重生) 与此同时, b由于一直被a所引用, 所以b的状态变成了reachable, finalizable. 然后在某个时刻被从F-queue取出, 变成reachable, finalized状态
第二: GC从F-queue中首先取出b,并被某个线程执行了finalize(), 状态变成reachable finalized. 然后a也类似, 变成reachable finalized状态, 并被c引用, 重生
对象重生的代码2
public class GC{public static GC SAVE_HOOK = null;public static void main(String[] args) throws InterruptedException, Throwable{SAVE_HOOK = new GC();SAVE_HOOK = null;System.gc();Thread.sleep(500);if (null != SAVE_HOOK) //此时对象应该处于(reachable, finalized)状态{System.out.println("Yes , I am still alive");}else{System.out.println("No , I am dead");}SAVE_HOOK = null;System.gc();Thread.sleep(500);if (null != SAVE_HOOK){System.out.println("Yes , I am still alive");}else{System.out.println("No , I am dead");}}@Overrideprotected void finalize() throws Throwable{super.finalize();System.out.println("execute method finalize()");SAVE_HOOK = this;}}
拓展阅读
个人收获
以前一直觉得 finalize() 类似于析构函数,甚至没有和 GC 联系起来。
自己读过《Thinking in Java》也没有什么印象,经典基础的知识是值得反复学习的。
参考资料
《Thinking in Java》
when-is-the-finalize-method-called-in-java
java finalize方法总结、GC执行finalize的过程
Java禁止使用finalize方法
更多实时资讯,前沿技术,生活趣事。尽在【老马啸西风】
Object有哪些方法?
1- 反射相关
getClass

2- 线程间通信
notify()

notifyAll

wait(long timeout)

wait(long timeout, int nanos)

wait()

- 注意wait()和wait(0)一样,是一直等待,直到被中断或通知
- 当wait方法发生超时或者被通知,都是要继续去竞争监视器锁成功后才能从wait方法返回,并执行后续的代码。参考:https://hacpai.com/article/1488015279637
3- 垃圾清理


4- 其他
hashCode() 和 equals(Object obj)

两者之间的关系:
- 当用于Hash结构的集合中时,如HsahMap,HashSet等,hashCode()相等的两个对象equals()不一定相等(发生hash冲突时),当equals相等时则hashCode()一定相等。
- 当不用于Hash结构的集合时,则一般不会重写hashCode方法,这两者也没有任何联系。hashCode默认为对象的内存地址。
clone() 和 toString()


作者:zhanglbjames
链接:https://www.jianshu.com/p/4daa6547eac0
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Cloneable 接口
浅拷贝(shallow clone)和深拷贝(deep clone)
浅拷贝是指拷贝对象时仅仅拷贝对象本身和对象中的基本变量,以及它所包含的所有对象的引用地址,而不拷贝对象包含的引用指向的对象(这是 java 中的浅拷贝,其他语言的浅拷贝貌似是直接拷贝引用,即新引用和旧引用指向同一对象)
深拷贝不仅拷贝对象本身和对象中的基本变量,而且拷贝对象包含的引用指向的所有对象
注意:对于常量池方式创建的 String 类型,会针对原值克隆,不存在引用地址一说,对于其他不可变类,如 LocalDate,也是一样
Cloneable 接口的使用
Cloneable 没有定义任何的方法签名,clone 方法定义在 Object 类中:
protected native Object clone() throws CloneNotSupportedException;
从 JVM 的角度看,Cloneable 就是一个标记接口而已。到 clone() 的基本实现中,JVM 会去检测要 clone 的对象的类有没有被打上这个标记,有就让 clone,没有就抛异常。
Object 类的 clone() 一个 native 方法,native 方法的效率一般来说都远高于非 native 方法。这也解释了为什么要用 Object 中 clone() 方法而不是先 new 一个类,然后把原始对象中的信息赋到新对象中。
- 如果类没有实现 Cloneable 接口,直接调用从 Object 继承下来的 clone 方法,会抛出 CloneNotSupportedException
public class Test {public static void main(String[] args) throws CloneNotSupportedException {Test test = new Test();Object cloned = test.clone(); // 结果是抛出 Clone NotSupportedException 异常}}
- 所有数组类型都有一个 public 的 clone 方法,而不是 protected。可以用这个方法建立一个新数组,包含原数组所有元素的副本。(数组类型由 JVM 独立实现)
int[] numbers = { 1, 2, 3, 4 };int[] cloned = numbers.clone();cloned[0] = 11; // 不会改变 numbers
- Object 提供的 clone 方法是浅复制,如果要深克隆,需要重写(override)Object 类的 clone() 方法,并且在方法内部调用持有对象的 clone() 方法
public class Employee implements Cloneable {private String name;private double salary;private Date hireDay;public Employee clone() throws CloneNotSupportedException {// call Object.clone()Employee cloned = (Employee) super.clone();// clone mutable fieldscloned.hireDay = (Date) hireDay.clone();return cloned;}}
- 继承链上的祖先必须要有一个类声明实现 Cloneable 接口
public class Person {}public class Male extends Person implements Cloneable {protected Object clone() throws CloneNotSupportedException {return super.clone();}}public class ChineseMale extends Male {}public class Test {public static void main(String[] args) throws CloneNotSupportedException {Person person = new Person();Male male = new male();ChineseMale chineseMale = new ChineseMale();person.clone(); // 报错male.clone();chineseMale.clone();}}
为什么 clone() 是 protected 方法
clone() 方法是 protected 方法,为了让其它类能调用这个类的 clone() 方法,重载之后要把 clone() 方法的属性设置为 public 。
之所以把 Object 类中的 clone 方法定义为 protected,是因为若把 clone 方法定义为 public 时,就失去了安全机制。这样的 clone 方法会被子类继承,而不管它对于子类有没有意义。比如,我们已经为 Employee 类定义了 clone 方法,而其他人可能会去克隆它的子类 Manager 对象。Employee 克隆方法能完成这件事吗?这取决于 Manager 类中的字段类型。如果 Manager 的实例字段是基本类型,不会发生什么问题。但通常情况下,需要检查你所扩展的任何类的 clone 方法。
如果,只是进行浅度克隆,那就没有没有必要把它设写成 protected,public 就可以了。
总之,把 Object 类中的 clone 方法定义为 protected,就是确保深度克隆时派生类中的 clone 方法会被检查。
protected 利与弊
一般不会使用 protected 域,因为会破坏类的封装性
但是 protected 方法对于指示那些不提供一般用途而应在子类中重新定义的方法很有用
鸡肋
事实上,若想实现对象的克隆,就不重写 Object 的 clone() 方法,还得实现 Cloneable 接口,有点麻烦。
而且如果某字段是个 final 的可变类,就不能将该引用指向原型对象新的克隆体了。
有更好的做法:
- 深克隆(deep clone/copy): SerializationUtils
- 浅克隆(shallow clone/copy):BeanUtils
简单的克隆,也可以通过编写拷贝构造方法实现
这是Java的一个设计缺陷。是个很糟糕的设计。如果Java在今天被重新设计一次的话,多半就不会设计成这样了。
当时的一些设计需求 / 限制是:
- Java对象要支持clone功能。但不是所有Java对象都应该可以clone,而是要让用户自己标记出哪些类是可以clone的
- clone()是一个特殊的多态操作,最好是有JVM的直接支持
- 早期Java不支持annotation。从Java 5开始支持。
- 早期Java支持接口形式的“声明多继承”
- 早期Java不支持任何“实现多继承”(简称“多继承”)。从Java 8开始可以通过接口的default method实现。
把上述几条结合起来,就得到了Cloneable接口这个糟糕的设计。
怎么说呢?
首先,我们要能标记出哪些类是可以clone的。在Java里,类型层面的元数据可以用几种方法来表示:
- 继承的基类
- 实现的接口
- 直接在Class文件中通过access flags实现的修饰符
- 使用annotation,无论是自定义的还是Java自带的
显然当初设计Java的时候,一个类是否应该支持clone,是一个重要的属性,但却还没重要到值得给它一个关键字修饰符来修饰class声明,于是不能用(3)。
然后Java类是单继承的,如果要出于标记目的而消耗掉“基类”这个资源,显然是有点别扭的(但想想看倒也不是完全不可以…),所以(1)也不太好。
那么就只剩下(2)和(4)了。可是早期Java不支持(4),就只剩下(2)了。
其次,clone()的语义有特殊性,最好是有JVM的直接支持,然后用户代码就算要自定义clone()最好也要调用JVM提供的基础实现然后再添加自己的功能(也就是大家经常简单的在clone()中先调用super.clone()的做法)。
JVM要直接支持,得在API里找地方来暴露出这个支持给Java代码调用才行啊。最直观的做法就是把clone()方法的基本实现放在一个所有可以clone的类都能访问到的基类中,让可clone的类继承这一实现。
但根据上面一点的讨论,我们不希望把clone()的基本实现放在一个特殊基类中,消耗掉Java类唯一的“基类”槽。那还能放哪里呢?干脆就放在java.lang.Object这个所有Java类的共通基类上吧。
诶。
=======================================
所以说一个实现了Cloneable接口的类跟一个没实现该接口的类有啥区别呢?
从JVM的角度看,这就是一个标记接口而已。实现了就是打上cloneable标记,没实现就是没这个标记。
然后到clone()的基本实现中,JVM会去检测要clone的对象的类有没有被打上这个标记,有就让clone,没有就抛异常。就这么简单。
Java里的数组类型是由JVM直接实现的,没有对应的Java源码文件。具体JVM如何实现是它们的自由。
Java语言规范所做的规定仅有这么一节:Chapter 10. Arrays
引用其中的演示用代码:
An array thus has the same public fields and methods as the following class:
class A<T> implements Cloneable, java.io.Serializable {public final int length = X;public T[] clone() {try {return (T[])super.clone();} catch (CloneNotSupportedException e) {throw new InternalError(e.getMessage());}}}
Note that the cast to T[] in the code above would generate an unchecked warning (§5.1.9) if arrays were really implemented this way. 仅此而已。
Java死锁排查和Java CPU 100% 排查的步骤整理
简介
本篇整理两个排查问题的简单技巧,一个是java死锁排查,这个一般在面试的时会问到,如果没有写多线程的话,实际中遇到的机会不多;第二个是java cpu 100%排查,这个实际的开发中,线的应用出现这个问题可能性比较大,所以这里简单总结介绍一下,对自己学习知识的一个整理,提高自己的解决问题能力。
一、Java死锁排查
通过标题我们就要思考三个问题:
- 什么是死锁?
- 为什么会出现死锁?
- 怎么排查代码中出现了死锁?
作为技术人员(工程师),在面对问题的时候,可能需要的能力是怎么去解决这个问题。但是在学习技术知识的时候,那就要多问为什么,一定要锻炼自己这方面的能力,这样才能更好的掌握知识。
解答:
- 什么是死锁?
死锁是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。百度百科:死锁
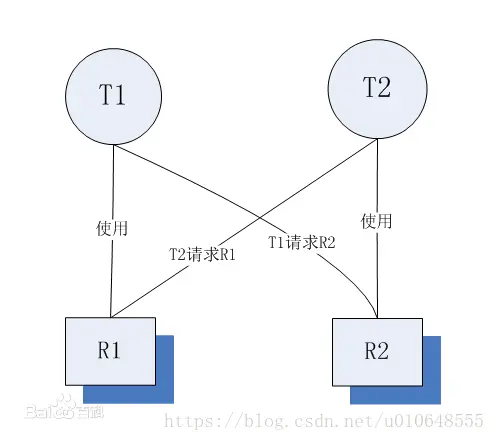
死锁图示
注:进程和线程都可以发生死锁,只要满足死锁的条件!
为什么会出现死锁?
从上面的概念中我们知道 (1)必须是两个或者两个以上进程(线程) (2)必须有竞争资源
怎么排查代码中出现了死锁?【重点来了】
首先写一个死锁的代码,看例子:
/**** 使用jstack 排查死锁* @author dufyun**/public class JStackDemo {public static void main(String[] args) {Thread t1 = new Thread(new DeadLockTest(true));//建立一个线程Thread t2 = new Thread(new DeadLockTest(false));//建立另一个线程t1.setName("thread-dufy-1");t2.setName("thread-dufy-2");t1.start();//启动一个线程t2.start();//启动另一个线程}}class DeadLockTest implements Runnable {public boolean falg;// 控制线程DeadLockTest(boolean falg) {this.falg = falg;}public void run() {/*** 如果falg的值为true则调用t1线程*/if (falg) {while (true) {synchronized (Demo.o1) {System.out.println("o1 " + Thread.currentThread().getName());synchronized (Demo.o2) {System.out.println("o2 " + Thread.currentThread().getName());}}}}/*** 如果falg的值为false则调用t2线程*/else {while (true) {synchronized (Demo.o2) {System.out.println("o2 " + Thread.currentThread().getName());synchronized (Demo.o1) {System.out.println("o1 " + Thread.currentThread().getName());}}}}}}class Demo {static Object o1 = new Object();static Object o2 = new Object();}
使用 jps + jstack
第一:在windons命令窗口,使用 jps -l 【不会使用jps请自行查询资料】
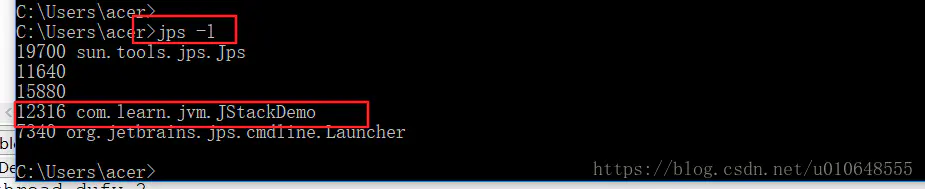
jps -l 命令
第二:使用jstack -l 12316 【不会使用jstack请自行查询资料】
jstack
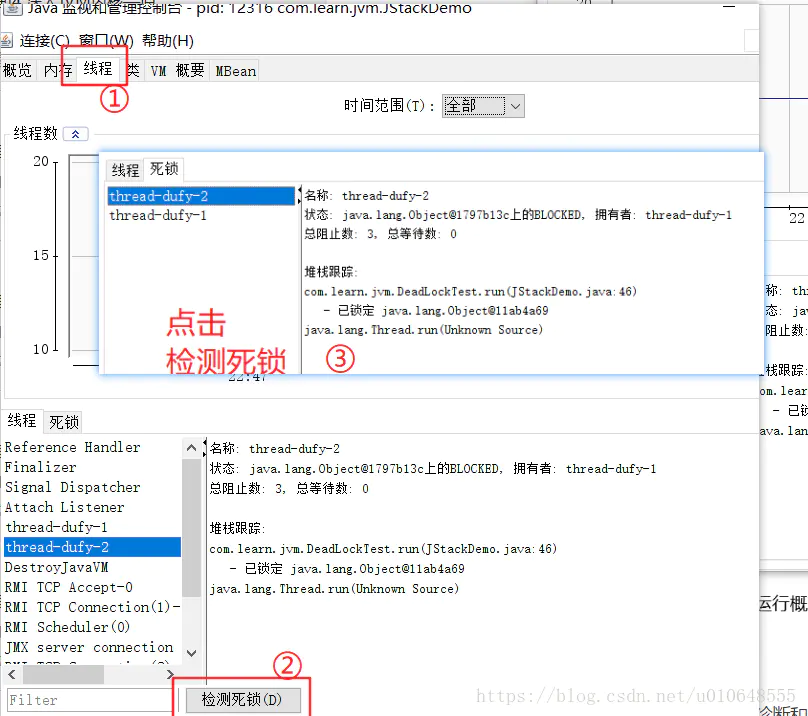
使用jconsole
在window打开 JConsole,JConsole是一个图形化的监控工具!
在windons命令窗口 ,输出 JConsole
这里写图片描述
使用Java Visual VM
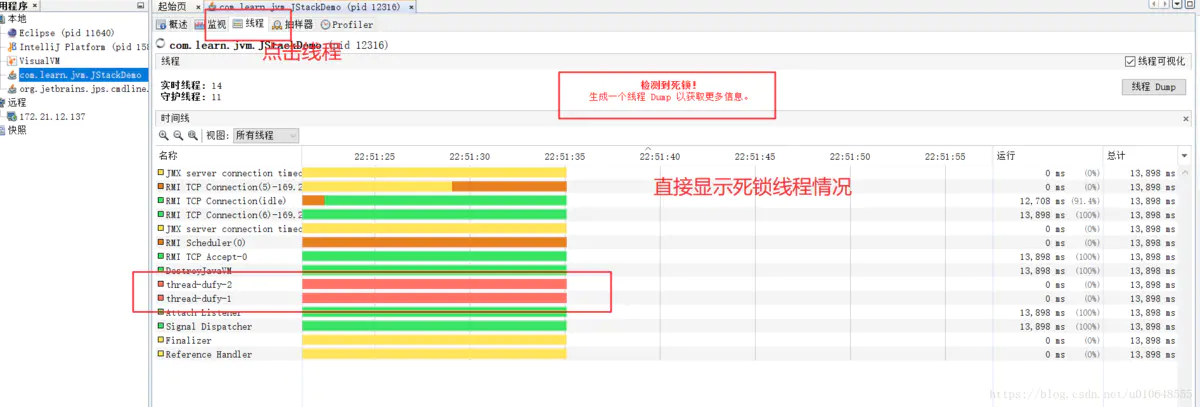
在window打开 jvisualvm,jvisualvm是一个图形化的监控工具!
在windons命令窗口 ,输出 jvisualvm
二、Java CPU 100% 排查
这个如果在实际的应用开发中遇到,要怎么排查呢?
这里没有一步步的图示过程,只有一个简单的操作过程!有空写一个详细的例子。
1 、 使用top命令查看cpu占用资源较高的PID
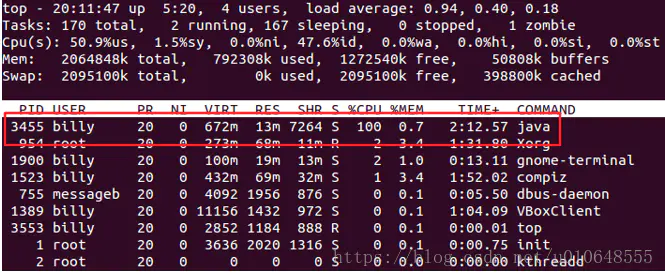
top命令
2、 通过jps 找到当前用户下的java程序PID
执行 jps -l 能够打印出所有的应用的PID,找到有一个PID和这个cpu使用100%一样的ID!!就知道是哪一个服务了。
3、 使用 pidstat -p 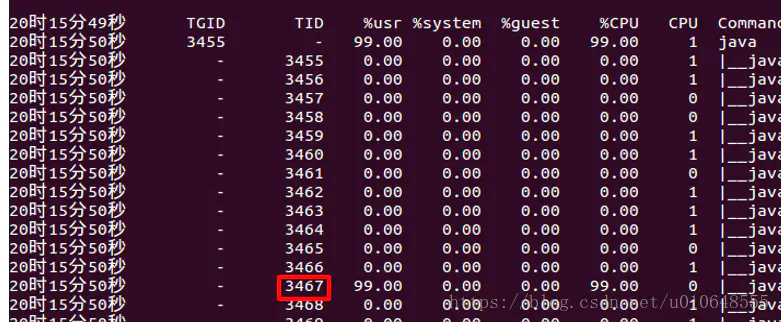
这里写图片描述
4 、 找到cpu占用较高的线程TID
通过上图发现是 3467的TID占用cup较大
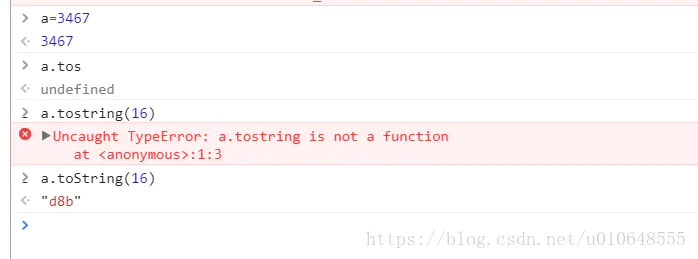
5、 将TID转换为十六进制的表示方式
将3467转为十六进制 d8d,注意是小写!
巧转进制
6、 通过jstack -l
使用jstack 输出当前PID的线程dunp信息
7、 查找 TID对应的线程(输出的线程id为十六进制),找到对应的代码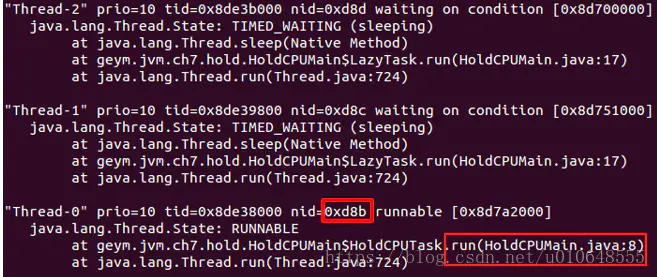
查找
三、压力测试使用jstack找到系统的代码性能问题
1、在进行压力测试的时候,使用jps找到应用的PID
2、然后使用jstack输出出压力测试时候应用的dump信息
3、分析输出的日志文件中那个方法block线程占用最多,这里可能是性能有问题,找到对应的代码分析
参考
1、Java应用CPU占用100%原因分析
2、[Java] CPU 100% 原因查找解决
3、线上应用故障排查系列
4、分析JAVA应用CPU占用过高的问题
欢迎访问我的csdn博客,我们一同成长!
不管做什么,只要坚持下去就会看到不一样!在路上,不卑不亢!
博客首页 : http://blog.csdn.net/u010648555
Java String类为什么是final的?
答:1.为了实现字符串池
2.为了线程安全
3.为了实现String可以创建HashCode不可变性
首先你要理解final的用途,在分析String为什么要用final修饰,final可以修饰类,方法和变量,并且被修饰的类或方法,被final修饰的类不能被继承,即它不能拥有自己的子类,被final修饰的方法不能被重写, final修饰的变量,无论是类属性、对象属性、形参还是局部变量,都需要进行初始化操作。
在了解final的用途后,在看String为什么要被final修饰:主要是为了”安全性“和”效率“的缘故。
查看JDK String的源码
final修饰的String,代表了String的不可继承性,final修饰的char[]代表了被存储的数据不可更改性。但是:虽然final代表了不可变,但仅仅是引用地址不可变,并不代表了数组本身不会变,请看下面图片。

final也可以将数组本身改变的,这个时候,起作用的还有private,正是因为两者保证了String的不可变性。
那么为什么保证String不可变呢,因为只有当字符串是不可变的,字符串池才有可能实现。字符串池的实现可以在运行时节约很多heap空间,因为不同的字符串变量都指向池中的同一个字符串。但如果字符串是可变的,那么String interning将不能实现,因为这样的话,如果变量改变了它的值,那么其它指向这个值的变量的值也会一起改变。
如果字符串是可变的,那么会引起很严重的安全问题。譬如,数据库的用户名、密码都是以字符串的形式传入来获得数据库的连接,或者在socket编程中,主机名和端口都是以字符串的形式传入。因为字符串是不可变的,所以它的值是不可改变的,否则黑客们可以钻到空子,改变字符串指向的对象的值,造成安全漏洞。
因为字符串是不可变的,所以是多线程安全的,同一个字符串实例可以被多个线程共享。这样便不用因为线程安全问题而使用同步。字符串自己便是线程安全的。
因为字符串是不可变的,所以在它创建的时候HashCode就被缓存了,不需要重新计算。这就使得字符串很适合作为Map中的键,字符串的处理速度要快过其它的键对象。这就是HashMap中的键往往都使用字符串。
字节码增强技术
个人理解,是在Java字节码生成之后,运行期对其进行修改,增强其功能,这种方式相当于对应用程序的二进制文件进行修改。这类增强字节码的技术基本都应用在减少冗余和屏蔽实现细节上,Java的字节代码的增强在很多的Java框架中都可以看到,比如Spring使用cglib对字节码的增强实现面向切面的编程AOP和自动代理类的生成等上。
字节码操作框架
- JDK的动态代理(利用JAVA反射)
- ASM:一个JAVA字节码分析、创建和修改的开源应用框架
- AspectJ:意思是Java的AspectJava的AOP,提供了强大的AOP功能
- CGLIB:功能强大,高性能的代码生成包,使用字节码处理框架ASM(对ASM的封装),来转换字节码并生成新的类
- Javassist:一个开源的分析、编辑和创建Java字节码的类库,在性能上Javassist高于反射,但低于ASM
补充:
CGLIB它为没有实现接口的类提供代理,为JDK的动态代理提供了很好的补充。通常可以使用Java的动态代理创建代理,但当要代理的类没有实现接口或者为了更好的性能,CGLIB是一个好的选择
字节码增强步骤
- 在内存中获取到原始的字节码,然后通用一些开源提供的API来修改它的byte[]数组,得到一个新的byte[]。(ASM,javassist,cglib等技术)
- 将这个新的数组写到PermGen区域,也就是加载它或替换原来的Class字节码(也可以在进程外部调用完成)
实现机制:一种是通过创建原始类的一个子类,也就是动态创建的这个类继承原来的类,现在的SpringAOP正式通过这种方式实现,另一种是非常暴力的,即直接修改原先的Class字节码,在许多类的跟踪过程中会用到这技术(类加载时修改字节码信息,运行时修改)
为什么要动态生成 Java 类?
动态生成 Java 类与 AOP 是密切相关的。AOP 的初衷在于软件设计世界中存在这么一类代码,零散而又耦合:零散是由于一些公有的功能(诸如著名的 log 例子)分散在所有模块之中;同时改变 log 功能又会影响到所有的模块。出现这样的缺陷,很大程度上是由于传统的 面向对象编程注重以继承关系为代表的“纵向”关系,而对于拥有相同功能或者说方面 (Aspect)的模块之间的“横向”关系不能很好地表达。
动态改变 Java 类就是要解决 AOP 的问题,提供一种得到系统支持的可编程的方法,自动化地生成或者增强 Java 代码。这种技术已经广泛应用于最新的 Java 框架内,如 Hibernate,Spring 等
for、foreach、Iterator 比较
for、foreach循环、iterator迭代器都是我们常用的一种遍历方式,你可以用它来遍历任何东西:包括数组、集合等
for 惯用法:
List<String> list = new ArrayList<String>();String[] arr = new String[]{"1,2,3,4"};for(int i = 0;i < arr.length;i++){System.out.println(arr[i]);}for(int i = 0;i < list.size();i++){System.out.println(list.get(i));}
foreach 惯用法:
String[] arr = new String[]{"1,2,3,4"};List<String> list = new ArrayList<String>();list.add("1");list.add("2");for(String str : arr){System.out.println(str);}for (String item : list) {System.out.println(item);}
Iterator 惯用法:
Iterator<String> it = list.iterator();while (it.hasNext()){System.out.println(it.next());}
速度对比
性能是我们选取某一种技术手段的一种考虑方式,且看这三种遍历方式的速度对比
List<Long> list = new ArrayList<Long>();long maxLoop = 2000000;for(long i = 0;i < maxLoop;i++){list.add(i);}// for循环long startTime = System.currentTimeMillis();for(int i = 0;i < list.size();i++){;}long endTime = System.currentTimeMillis();System.out.println(endTime - startTime + "ms");// foreach 循环startTime = System.currentTimeMillis();for(Long lon : list){;}endTime = System.currentTimeMillis();System.out.println(endTime - startTime + "ms");// iterator 循环startTime = System.currentTimeMillis();Iterator<Long> iterator = list.iterator();while (iterator.hasNext()) {iterator.next();}endTime = System.currentTimeMillis();System.out.println(endTime - startTime + "ms");
4ms 16ms 9ms
由以上得知,for()循环是最快的遍历方式,随后是iterator()迭代器,最后是foreach循环
remove操作三种遍历方式的影响
for循环的remove
List<String> list = new ArrayList<String>();list.add("1");list.add("2");for(int i = 0;i < list.size();i++){if("2".equals(list.get(i))){System.out.println(list.get(i));list.remove(list.get(i));}}
foreach 中的remove
List<String> list = new ArrayList<String>();list.add("1");list.add("2");for (String item : list) {if ("2".equals(item)) {System.out.println(item);list.remove(item);}}
你觉得这段代码的正确输出是什么?我们一起来探究一下
当我执行一下这段代码的时候,出现了以下的情况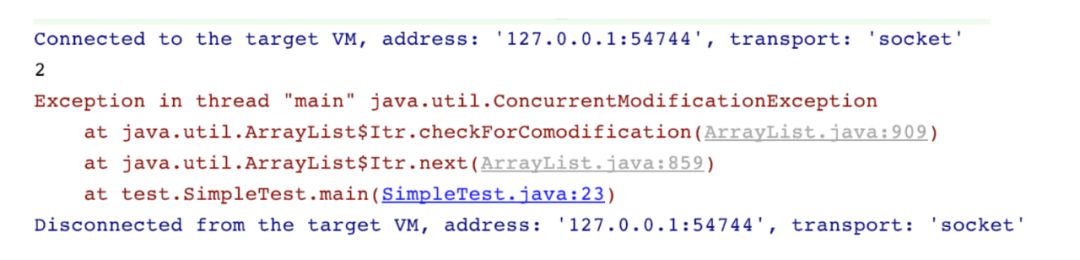
由以上异常情况的堆栈信息得知,程序出现了并发修改的异常,为什么会这样?我们从错误开始入手,
at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:909)
也就是这行代码,找到这行代码的所在地
final void checkForComodification() {if (modCount != expectedModCount)throw new ConcurrentModificationException();}
你会好奇, modCount 和 expectedModCount 是什么变量?在我对 ArrayList 相关用法那篇文章中有比较详细的解释。我大致说明一下:modCount 相当于是程序所能够进行修改 ArrayList 结构化的一个变量,怎么理解?看几个代码片段
你能够从中获取什么共性的特征呢?没错,也就是涉及到其中关于ArrayList的 容量大小 和 元素个数的时候,就会触发modCount 的值的变化
expectedModCount这个变量又是怎么回事?从ArrayList 源码可知,这个变量是一个局部变量,也就是说每个方法内部都有expectedModCount 和 modCount 的判断机制,进一步来讲,这个变量就是 预期的修改次数,
先抛开这个不谈,我们先来谈论一下foreach(增强for循环)本身。
增强for循环是Java给我们提供的一个语法糖,如果将以上代码编译后的class文件进行反编译(使用jad工具)的话,可以得到以下代码:
terator iterator = item.iterator();
也就是说,其实foreach 每次循环都调用了一次iterator的next()方法
因此才会有这个堆栈信息:
at java.util.ArrayList$Itr.next(ArrayList.java:859)
下面我们来尝试分析一下这段代码报错的原因:
1、第一次 以 “1”的值进入循环,”1” != “2”, 执行下一次循环
2、第二次循环以”2”的值进入,判断相等,执行remove()方法(注意这个remove方法并不是 iterator的remove(),而是ArrayList的remove()方法),导致modCount++
3、再次调用next()的时候,modCount != expectedModCount ,所以抛出异常
Iterator迭代器的remove
使用迭代器进行遍历还有很多需要注意的地方:
正确的遍历
List<String> list = new ArrayList<String>();list.add("1");list.add("2");list.add("3");Iterator<String> it = list.iterator();while (it.hasNext()){System.out.println(it.next());it.remove();}
这是一种正确的写法,如果输出语句和 remove()方法互换顺序怎么样呢?
错误的遍历 —— next() 和 remove() 执行顺序的问题
List<String> list = new ArrayList<String>();list.add("1");list.add("2");list.add("3");Iterator<String> it = list.iterator();while (it.hasNext()){it.remove();System.out.println(it.next());}
执行程序输出就会报错:
Exception in thread "main" java.lang.IllegalStateExceptionat java.util.ArrayList$Itr.remove(ArrayList.java:872)at test.SimpleTest.main(SimpleTest.java:46)
这又是为什么?还是直接从错误入手:
定位到错误的位置
at java.util.ArrayList$Itr.remove(ArrayList.java:872)
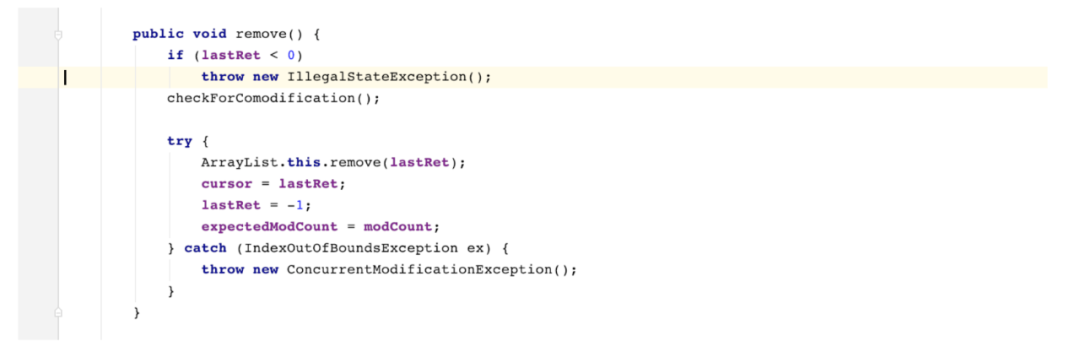
发现如果 lastRet 的值小于 0就会抛出非法状态的异常,这个lastRet是什么?
且看定义: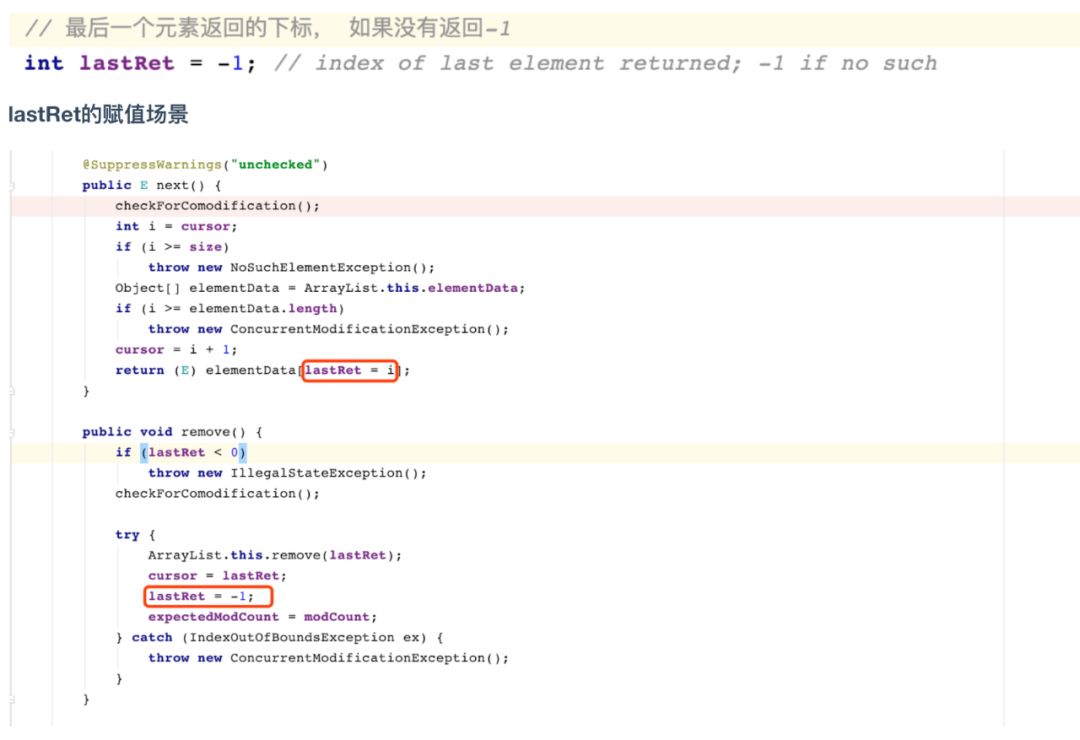
由上面代码可以看出,当你执行next()方法的时候, lastRet 赋值为i,所以这个elementData[]中的下标最小是0,所以这个时候lastRet 最小的值是0, 那么只有当执行remove()方法的时候,lastRet的值赋值为-1,也就是说,你必须先执行一次next方法,再执行一次remove方法,才能够保证程序的正确运行。
错误的遍历 —— 使用Arrays.asList()
List<String> list = Arrays.asList("1","2","3");Iterator<String> it = list.iterator();while (it.hasNext()){System.out.println(it.next());it.remove();}
这段代码执行之后的输出是怎样的呢?
1Exception in thread "main" java.lang.UnsupportedOperationExceptionat java.util.AbstractList.remove(AbstractList.java:161)at java.util.AbstractList$Itr.remove(AbstractList.java:374)at test.SimpleTest.main(SimpleTest.java:50)
很不幸,这段代码也抛出了异常,直接从错误处入手发现,这个remove()方法调用的是AbstractList中的remove方法,跟进入发现有一段代码
remove()方法:
也就是说,只要这段代码执行了,都会报错,抛出异常
后记:
上述文章主要介绍了 for循环、foreach 循环、iterator 迭代器遍历元素的速度大小的比较
还介绍了各自遍历过程中 对 remove 操作的影响。
原文地址:https://www.yuque.com/lobotomy/java/wif5lk

若有收获,就点个赞吧
0 人点赞
