轻量化是已经是 BIM 业界人所共知的一个概念,虽然至今没有任何严谨的学术或者理论定义,但是这个概念已经几乎成为了行业的标准。它的大意是说,一个适用用于浏览器端渲染的模型数据,包括几何数据和行业数据,必然可以做的很小,如果和原建模软件的原始模型文件比较的话,如果做到 1/4 那是及格标准,做到 1/10,乃至 1/20 之一是优秀。今天我们将讨论下这个概念下具体的技术实现方案和背后的计算机图形学理论,并且希望得出一个对整个行业有参考价值的结论。
纵观现在国内几十种 BIM 的产品,以及结合我们对近 30 年计算机图形理论的资料挖掘,我们认为轻量化并不是一个准确的定义,绝对的轻量化在无论产品的数据流上还是在理论基础上都没有太多可实现性。我们同时认为,轻量化这个概念应该更正为文件压缩,并且于现在的通用文件压缩连接起来,毕竟在实质上,它们是完全相同的。
本文会先对从技术理论出发,介绍可以支撑实现 “轻量化” 的四个图形学技术方向,并且在实际应用过程中产生的工程问题,最后会给出一个综合的轻量化实现框架,以及给出理论上上轻量化可以做到最小压缩比。
定义
在讨论轻量化的可行技术方案之前,我们需要对轻量化进行一个定义和概念厘清。本文所探讨的轻量化,指对三维建筑模型模型,例如 Revit,IFC 等文件中三维几何数据部分的数据压缩。本文针对的轻量化不涉及任何其他非三维几何数据,包括纹理图片、材质信息、建筑 BIM 信息、二维图形信息以及软件特有的附加信息。很多平台产品将自己的纯三维几何数据大小和带有众多信息的原模型大小相对比,得出自己轻量化程度高的结论是非常不科学的。
我们需要对三维几何信息进行进一步定义。这里的三维信息特指三维三角形网格 (triangular mesh) 或者三维线网格(polyline mesh)。每一个 mesh 由一个顶点数组和一个索引数组组成。顶点数组中每一个顶点一定包含 position,即三个 32bit IEEE754 floating number,分别对应顶点的 x, y, z 坐标,可能包含 normal,即三个 32bit IEEE754 floating number,可能包含纹理坐标 UV,即两个 32bit IEEE754 floating number,可能包含顶点颜色,即四个 8bit byte,分别对应 RGBA 四个通道。针对三角形网格,因为考虑渲染效率,一定采用顶点法线(vertex normal),而不是面法线(face normal)。索引数组为一个 unsigned int 16 的数组,元素个数为 3 三角形数量或者 2 线段数量。
除了定义 mesh,我们进一步定义轻量化的应用场景。轻量化仅指进轻量化程序处理后用于保存和网络传输的数据量可以压缩到比原始三维网格的数据量小。在进行渲染前,轻量化的数据可能会解压缩以便是适配于 GPU 渲染 API 的需要,解压缩的数据量可能会增大,甚至比原先的三维网格数量量更大,这是为了渲染效率优化的考虑。本文所讨论的轻量化仅针对优化存储优化和传输优化,并不针对渲染的优化。同时,我们认为因为渲染的 API 的接口规范已给定,渲染时实现 100% 还原度的无损数据压缩是不存在的,虽然本文最后对这类应用情况也提出了一种可行性方案。
技术方向
轻量化的技术方向大致可以分为 Instancing,Compression,LOD 和 Parameterization。下文对四个技术方向以及其落地分别进行探讨。
- Instancing
Instance,多实例是已经非常普遍的渲染技术[2]。它的原理是针对同样的几何物体,只保存一份几何数据,通过在渲染管线中分别绘制若干次,且每次应用不同的几何变化和材质信息得到在同一帧多个类似几何物体的渲染效果,见图 1。用实际的例子说,如果要绘制很多相同的桌子,我们只需要使用一份桌子的几何数据,然后绘制多编,每一遍把桌子放在不同的位置即可。目前的渲染管线已经完全将 instancing 放在了硬件管线中执行,大大节约了 GPU 内存的开销和 CPU 的计算开销(主要指发起一个 drawcall 的驱动使用 CPU 资源)[1, 3]。WebGL 1.0 中可以通过使用 ANGLE_instance_arrays[3]就扩展实现这个功能,在 WebGL 2.0 中已经有原生 API 支持,即 gl.drawElementsInstanced。

图 1 Instacing 示例
对应轻量化的 Instancing 表达,已经有一定的研究[4,5]。研究的主要解决问题,如何在一个场景中,对几何体进行一一对比,如果两个几何体是同一个几何体,那么只需要实际保存一份几何数据,将另外一个几何体压缩为一个空间变化和材质信息。判断两个几何体是否相同往往从附加在几何体上的语义出发,例如两个几何体是不是都标记为一张桌子,或者直接从 mesh 相似度出发。纯几何的算法是非常具有挑战性的,因为单纯的内存比较显然在大多数情况下不适用,只要索引数组略有变化或者一个简单的平移变换,这种比较就失效了。现在业界应用比较多的是 Hausdorff 距离[6],即计算两个 mesh 之间的最小欧式距离。这个距离算法一样对简单的旋转无能无力。
另一方面在建筑建模中,我们发现大多数的建模软件已经内置了 Instancing 的功能。一个物体如果在场景中重复出现多次,在模型文件中它的几何数据只保留了一份,每一个实例压缩为了一个 4x4 空间变换矩阵。这样的发现告诉我们,在 BIM 的数据流中想通过 instancing 来减少几何数据的大小已经不太现实,源文件已经在这个方面做到了最好。
综上所述,在实际的生产环境中,利用 Instancing 来减少原始文件的尺寸,效果不会太好。
- 压缩
压缩的概念就很好理解,就是和普通的文件压缩类似。有两种方向,第一种是几何无关的,例如直接用将模型数据进行 gzip 压缩后保存,因为浏览器原生支持 gzip 解压[7],在传输过程还是 gzip 压缩数据,而在应用层已经为解压后的模型数据,根据我们经验,针对上文中提及的几何数据,gzip 的压缩率在 2:1,即能压缩到原始数据一半的大小。第二种方向是几何相关的,比如 Google 的 Draco 库[8],Khronos 的Open3DGC[9]。Draco 的公开资料中并没有提及它的具体算法,但是它的压缩率是惊人的,见图 2。对于 Open3DGC,它在一定程度上利用了 quantization 的方法,是一种有损压缩。虽然他们加入了针对几何信息更好的压缩,但是本质上还是一种压缩算法,需要在载入到 GPU 前将数据解压缩。
https://www.cnx-software.com/wp-content/uploads/2017/01/Draco-Compression-Ratio-Performance.jpg
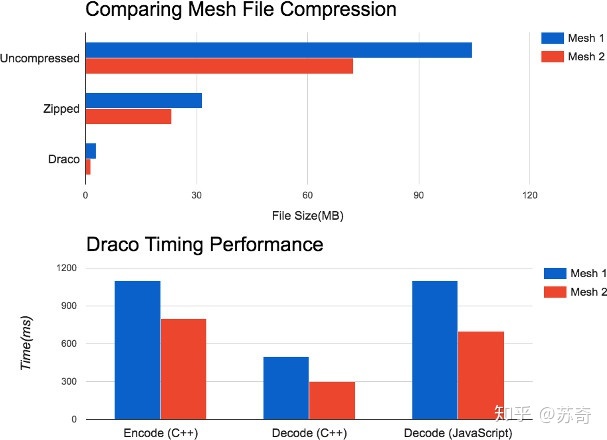
图 2 Draco 的压缩率和压缩表现
https://www.cnx-software.com/wp-content/uploads/2017/01/Draco-Compression-Ratio-Performance.jpg
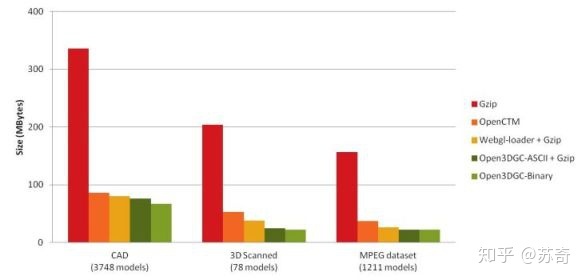
图 3 Open3DGC 的压缩率
压缩是目前在轻量化中实用价值最高的方法,原因是它完全对于渲染透明,且在服务器端保存的几何数据量大幅度减少,所需要的无非是一些计算性能的开销,例如 Draco 解压一个 100MB 左右的文件需要 1 秒左右的 CPU 时间。
- LOD
Level-of-Detail(LOD)[11, 12],一个渲染加速技术,对于离相机原的物体采取比离近的物体精度低的多的几何数据,甚至一个 billboard 来表达。这样在一个帧内就能大大减少 vertex 数量,减轻渲染管线的计算量,见图 4。LOD 某种程度上可以会被误认为一种简化 mesh 模型的技术容易把 LOD 混同轻量化来谈,这是一种认识误区,正如前面所述,LOD 是一种渲染加速技术,它不但不能减少文件保存时和传输时的尺寸,还是需要增加文件尺寸的。例如图 4 中,除了原始的最左边的模型,模型处理程序还需要构建出右边三个简化模型,将其传输到客户端用于渲染加速。额外的三个简化模型大大增加了模型的数据尺寸。
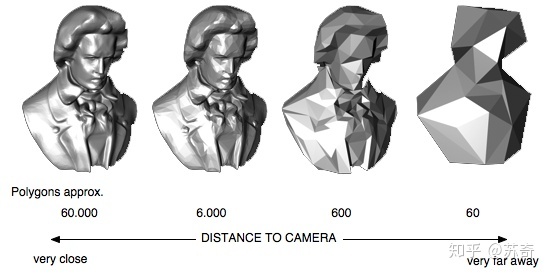
图 4 Level-of-Detail 本质上是根据相机距离选区不同复杂度的集合模型渲染
但是也有通过 quantization 方法,在不增加文件尺寸的基础上提供了 LOD 技术[13](图 5)。它把模型的定点坐标的 floating number 全部转换为 normalized 整形,然后依靠 cutting off 来实现 downsampling。这是一个非常巧妙的办法,唯一的开销是在 vertex shader 中需要将 normalized floating number 展开。
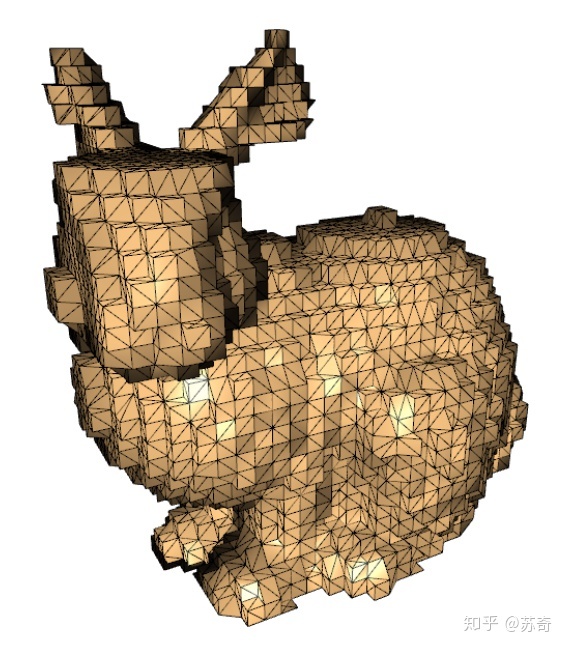
图 5 Pop Buffer 利用 quantization 来做 LOD
LOD 虽然不能直接降低模型的几何数据大小,但是依据 LOD 的层级可以实现模型几何数据的增量传输 (progressive loading),也就是先传输低层级的几何数据且显示,最后再传输那些更加细致的几何数据。如果用户允许一定程度上的几何细节损失,LOD 也可以成为一种轻量化方法。对于模型简化的算法可以参考[14, 15, 16]。另一个非常类似的研究方向是 mesh streaming,更多的应用于大规模地形模型的渲染。
- Parameterization
参数化这个做法就是将 mesh 转成 nurbs 或者其他参数表达方式。这个技术本来是在逆向工程中使用,从激光扫描的点云中恢复参数曲面用来车床加工[20, 21, 22]。对于参数易表达的面,比如球体,这种方式大大减少了数据量。但是对于建筑来说,大多数面片都是平面,并不能减少太多数据量,甚至在有些情况曲面消耗的存储空间比 mesh 更大,比如带很多 trim 的曲面。何况 GPU 并不支持参数曲面的实时绘制。
还有两种类似参数化的方法,分别是 remeshing 即重新 mesh[23],见图 6 和 subdividision 曲面细分[24],见图 7。前者将 mesh 重新采样做成一个新的 mesh,后者将一个曲面细分,生成一个更加复杂的曲面,实质上是生成一个由原先曲面作为控制点的 b-spline surface。理论上,我们只要找到一个和现有 mesh 几何相近但是更简化的表达,就达到了压缩的目的,但是这样做并不容易,原因还是建筑模型中大多数的几何体并不适用于细分曲面。

图 6 Remeshing
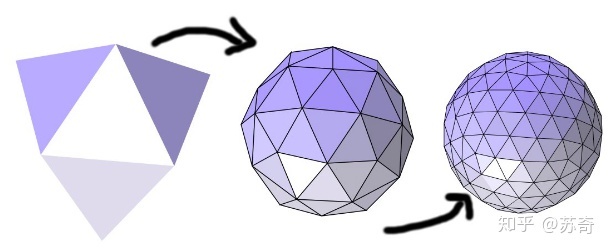
图 7 细分曲面
但是参数化表达并无不可取之处,对于几种特殊的情况,参数化表达可以达到非常好的效果。比如管道等利用 extrusion 操作生成的物体结构,见图 8。这样的扫描体完全可以用一条路径加一个横截面来表达,如果横截面为一个方便公式表达的形状,例如圆形,那么数据压缩的效果会更加明显。为了进一步减轻客户端将这种参数表达的形体展开为 mesh 的工作量,我们可以将 path 中的采样点预先计算出来。
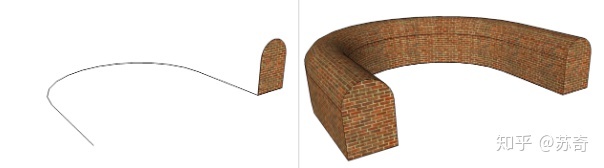
图 8 Extrusion
一个可行性数据压缩框架
上文已经总结了可用于压缩的四个基本方向,我们认为并不存在一个适用于普遍场景的 “轻量化” 方案。一个相对可行性方案也是 Modelo 采用的是
- 保存原建模文件中的 instancing 信息
- 如果原建模文件中有 NURBS 曲面 (b-rep),控制它的网格细分力度,取得效果和文件体积平衡。
- 对于 extrusion 物体进行参数化,将其压缩所成 line strip 和一个横截面
- 采用 Google Draco 对其进行压缩
- 采用 gzip 将其压缩
对于一般场景,这个方案最终的压缩率几乎取决于第四步 Draco 的压缩表现,这也是为什么我们认为 “轻量化” 的更应该称之为 “几何数据压缩” 的原因。只有对于极少数的场景,例如可以简化的管道,第三步就可以发挥极大的作用,大大降低文件尺寸,但是这步的工程实现难度也很大,需要考虑很多细节,这里也不一一阐述了。
写在最后,我们总结了现有可以提供 “轻量化” 支持的图形技术,并逐一从工程上分析了它们的可行性,我们坚持认为”轻量化“并不是严谨科学的概念,我们应该称其为网格(几何数据)压缩,类似于纹理压缩一样。在这样的定义下开展研究和开发,才能找对正确的方向。
更多有关于 3D, BIM, AI 的信息,请关注我们的公众号:
http://weixin.qq.com/r/6C97Y_zEfrEBragA93r6 (二维码自动识别)
参考文献
[1] GeForce GTX 980 Whitepaper, http://international.download.nvidia.com/geforce-com/international/pdfs/GeForce_GTX_980_Whitepaper_FINAL.PDF
[2] https://developer.nvidia.com/gpugems/GPUGems2/gpugems2_chapter03.html
[3] OpenGL 4.5 (Core Profile), https://www.khronos.org/registry/OpenGL/specs/gl/glspec45.core.pdf
[4] ANGLE_instanced_arrays WebGL 1.0 extension, https://www.khronos.org/registry/webgl/extensions/ANGLE_instanced_arrays/
[5] 刘小军, 贾金原. “面向手机网页的大规模 WebBIM 场景轻量级实时漫游算法”.《中国科学》(信息版),In Press,2018 年
[6] Solibri IFC Optimizer. http://www.solibri.com/.
[7] Klein R., Liebich G., Strasserw., Mesh reduction with error control. fu Proc. of IEEE Visualization 96 (1996), pp. 3 1 1-3 18.
[8] HTTP compression. https://en.wikipedia.org/wiki/HTTP_compression
[9] Google Draco, https://github.com/google/draco
[10] Khronos Open3DGC, https://github.com/amd/rest3d/tree/master/server/o3dgc
[11] Real-Time Rendering, Fourth Edition, by Tomas Akenine-Möller, Eric Haines, Naty Hoffman, Angelo Pesce, Michał Iwanicki, and Sébastien Hillaire, 1198 pages, from A K Peters/CRC Press, ISBN-13: 978-1138627000, ISBN-10: 1138627003
[12] Level of Detail for 3D Graphics, David Luebke, Martin Reddy, Robert Huebner,2003, ISBN 978-1-55860-838-2, Morgan Kaufmann
[13] The POP Buffer: Rapid Progressive Clustering by Geometry Quantization, https://x3dom.org/pop/files/popbuffer2013.pdf
[14] Progressive meshes.Hugues Hoppe.ACM SIGGRAPH 1996 Proceedings, 99-108
[15] Progressive simplicial complexes.Jovan Popovic, Hugues Hoppe.ACM SIGGRAPH 1997 Proceedings, 217-224.
[16] View-dependent refinement of progressive meshes.Hugues Hoppe. ACM SIGGRAPH 1997 Proceedings, 189-198.
[17] Streaming meshes, http://www.cs.unc.edu/~isenburg/papers/il-sm-05.pdf
[18] Streaming Compression of Triangle Meshes, http://www.cs.unc.edu/~isenburg/research/papers/ils-sctm-05.pdf
[19] Out-of-Core Multigrid Solver for Streaming Meshes, Out-of-Core Multigrid Solver for Streaming Meshes
[20] Fast and accurate NURBS fitting for reverse engineering, Fast and accurate NURBS fitting for reverse engineering
[21] PCL library, http://pointclouds.org/documentation/tutorials/bspline_fitting.php
[22] https://imr.sandia.gov/papers/imr19/Leal2B.2.pdf, https://imr.sandia.gov/papers/imr19/Leal2B.2.pdf
[23] Turk G. Re-tiling polygonal surfaces[J]. international conference on computer graphics and interactive techniques, 1992, 26(2): 55-64.
[24] Catmull, E.; Clark, J. (1978). “Recursively generated B-spline surfaces on arbitrary topological meshes” (PDF). Computer-Aided Design. 10 (6): 350. doi:10.1016/0010-4485(78)90110-0.
https://zhuanlan.zhihu.com/p/47226844

若有收获,就点个赞吧
0 人点赞

{kind=link}