所有教程来自于DataWhale。感谢大佬们的辛勤付出原地址【传送门】
2.2.1 收集数据集并选择合适的特征
在数据集上我们使用我们比较熟悉的IRIS鸢尾花数据集。
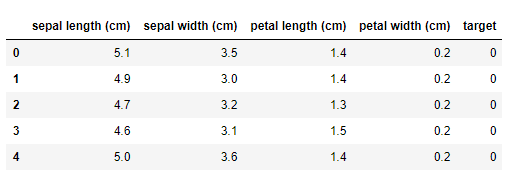
from sklearn import datasetsiris = datasets.load_iris()X = iris.datay = iris.targetfeature = iris.feature_namesdata = pd.DataFrame(X,columns=feature)data['target'] = ydata.head()
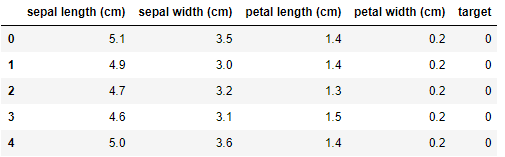
各个特征的相关解释:
- sepal length (cm):花萼长度(厘米)
- sepal width (cm):花萼宽度(厘米)
- petal length (cm):花瓣长度(厘米)
- petal width (cm):花瓣宽度(厘米)
2.2.2 选择度量模型性能的指标
度量分类模型的指标和回归的指标有很大的差异,首先是因为分类问题本身的因变量是离散变量,因此像定义回归的指标那样,单单衡量预测值和因变量的相似度可能行不通。其次,在分类任务中,我们对于每个类别犯错的代价不尽相同,例如:我们将癌症患者错误预测为无癌症和无癌症患者错误预测为癌症患者,在医院和个人的代价都是不同的,前者会使得患者无法得到及时的救治而耽搁了最佳治疗时间甚至付出生命的代价,而后者只需要在后续的治疗过程中继续取证就好了,因此我们很不希望出现前者,当我们发生了前者这样的错误的时候会认为建立的模型是很差的。为了解决这些问题,我们必须将各种情况分开讨论,然后给出评价指标。
- 真阳性TP:预测值和真实值都为正例;
- 真阴性TN:预测值与真实值都为正例;
- 假阳性FP:预测值为正,实际值为负;
- 假阴性FN:预测值为负,实际值为正;
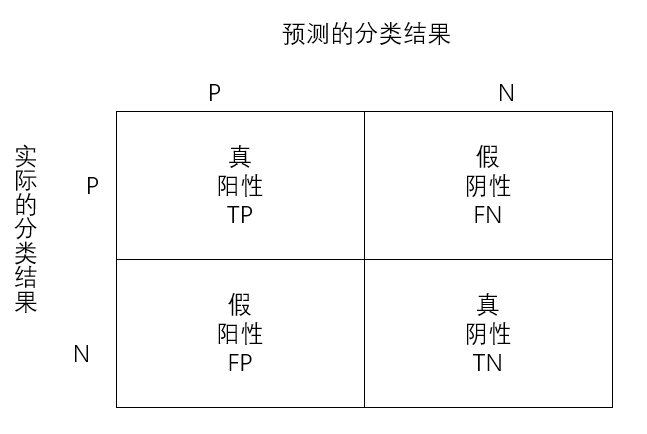
- 分类模型的指标:
- 准确率:分类正确的样本数占总样本的比例,即:

- 精度:预测为正且分类正确的样本占预测值为正的比例,即:
 预测为对的P量/实际P量
预测为对的P量/实际P量 - 召回率:预测为正且分类正确的样本占类别为正的比例,即:
 预测为对的P量/预测的P量
预测为对的P量/预测的P量 - F1值:综合衡量精度和召回率,即:

- ROC曲线:以假阳率为横轴,真阳率为纵轴画出来的曲线,曲线下方面积越大越好。
分类指标【传送门】
在本次小案例中,我们使用ROC曲线作为最终评价指标。
2.2.3 选择具体的模型并进行训练
2.2.3.1 逻辑回归logistic regression
在分类问题中,我们往往是通过已知X的信息预测Y的类别,往往是一个离散集合中的某个元素。如:是否患癌症,图片是猫还是狗等。
一个很自然的想法是能否用线性回归去处理分类问题,答案是可以但不好!先来看看线性回归处理分类问题会出现什么弊端,我们仔细来看这个线性回归的例子, ,只要输入Balance 和 Income 以及default的数据就能用最小二乘法估计出
,只要输入Balance 和 Income 以及default的数据就能用最小二乘法估计出 ,设定预测的default>0.5就是违约反之不违约,感觉很完美的样子,但事实真的是这样吗?假设我们需要用某个人的债务(Balance)和收入(Income)去预测是否会信用卡违约(default):
,设定预测的default>0.5就是违约反之不违约,感觉很完美的样子,但事实真的是这样吗?假设我们需要用某个人的债务(Balance)和收入(Income)去预测是否会信用卡违约(default):
- 我们假设有一个穷人Lisa,他的Balance和Income都很小,那么有可能会导致default的值为负数,那么这个负数代表什么意义呢?显然是没有任何意义的。
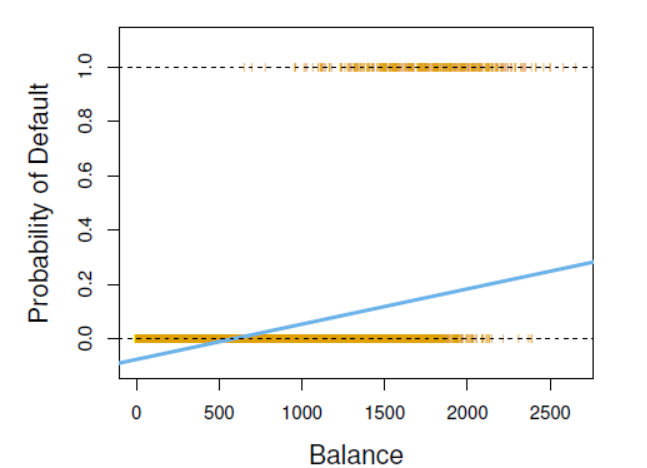
- 当我们的分类变量是多类的时候,以0.5为界限划分分类就不可用了,那么我们应该怎么找到一个界限衡量多分类呢?
基于以上问题,现在大家是否还觉得线性回归模型作为一个分类模型是否足够优秀呢?其实,为了解决以上的问题(1)我们来想想能不能将线性回归的结果 default转化为区间[0:1]上,让default转变成一个违约的概率呢?下面我们来解决这个问题吧。
在推导逻辑回归之前,我们先来认识下一组函数,这组函数具有神奇的作用,可以将是实数轴上的数转换为[0:1]区间上的概率。 首先,我们假设我们的线性回归模型为 那么这个函数是如何将线性回归的结果转化为概率呢?这个函数就是logistic 函数,具体的形式为
那么这个函数是如何将线性回归的结果转化为概率呢?这个函数就是logistic 函数,具体的形式为
他的函数图像如下图:(左边是线性回归,右边是逻辑函数)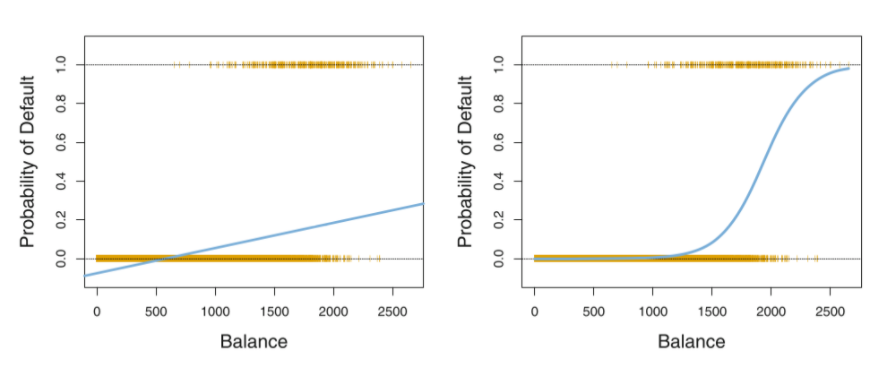
逻辑回归在实际中不太用于多分类问题,因为实际效果不是很好,所以我们可以借助其他模型来解决这个问题,那让我们来解决这个遗留下来的问题吧。
2.2.3.2基于概率的分类模型
(a) 线性判别分析:
基于贝叶斯公式对线性判别分析的理解:
**
贝叶斯定理: 推广可得
推广可得
降维分类的思想理解线性判别分析:
【段落教程来源:知乎链接】
线性分类模型是指采用直线(或超平面)将样本直接划开的模型,其形式可以表示成  的形式,划分平面可以表示成
的形式,划分平面可以表示成  。这里可以看出,线性分类模型对于样本的拟合并不一定是线性的,例如逻辑回归(外面套了一层sigmod函数)和感知机(外面套了一层激活函数)。
。这里可以看出,线性分类模型对于样本的拟合并不一定是线性的,例如逻辑回归(外面套了一层sigmod函数)和感知机(外面套了一层激活函数)。
线性判别分析的基本思想是把所有样本投影到一条直线上,使样本在这条直线上最容易分类。
**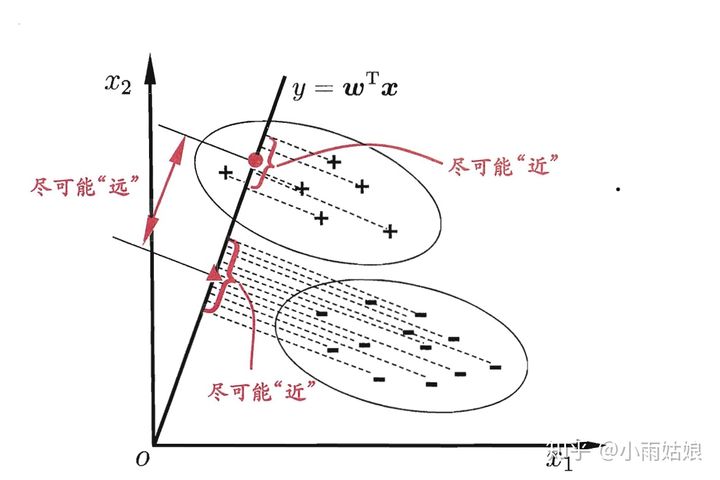
设直线的方向向量为  ,则样本
,则样本  在直线上的投影为
在直线上的投影为  ,如图:
,如图:
我们的目标是使两类样本的中心点在线上的投影距离大(两类样本区分度高);
同时使每一类样本在线上投影的离散程度尽可能小(类内样本区分度低)。
令  ,
, ,
,  分别代表每一类的样本,每一类样本的均值向量,每一类样本的协方差矩阵。
分别代表每一类的样本,每一类样本的均值向量,每一类样本的协方差矩阵。
若将所有样本都投影到直线上,则两类样本的中心点可分别表示为  ,
,  。
。
若将所有样本都投影到直线上,则两类样本的协方差可表示为  ,
,  。
。
协方差是什么?协方差表示的是两个变量总体误差的期望。如果两个变量的变化趋势一致,则Cov为正值;若相反则为负值;变化趋势无关时为0,此时两个变量独立。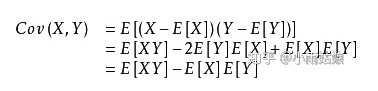
因此我们如果要让两类样本在投影后离散程度尽可能小,我们就应该让他们之间的方差尽可能小。计算每一类元素投影后的方差在做向量化时,中间就是协方差矩阵。
特征 ,因变量
,因变量 ,类别c1的特征
,类别c1的特征 ,同理,类别c2的特征
,同理,类别c2的特征 ,属于c1类别的数据个数为
,属于c1类别的数据个数为 ,属于类别c2的数据个数为
,属于类别c2的数据个数为 ,其中
,其中

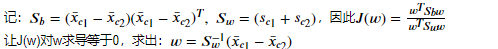
(b) 朴素贝叶斯:
在线性判别分析中,我们假设每种分类类别下的特征遵循同一个协方差矩阵,每两个特征之间是存在协方差的,因此在线性判别分析中各种特征是不是独立的。但是,朴素贝叶斯算法对线性判别分析作进一步的模型简化,它将线性判别分析中的协方差矩阵中的协方差全部变成0,只保留各自特征的方差,也就是朴素贝叶斯假设各个特征之间是不相关的。在之前所看到的偏差-方差理论中,我们知道模型的简化可以带来方差的减少但是增加偏差,因此朴素贝叶斯也不例外,它比线性判别分析模型的方差小,偏差大。虽然简化了模型,实际中使用朴素贝叶斯的案例非常多,甚至多于线性判别分析,例如鼎鼎大名的新闻分类,垃圾邮件分类等。
# 逻辑回归'''penalty {‘l1’, ‘l2’, ‘elasticnet’, ‘none’}, default=’l2’正则化方式dual bool, default=False 是否使用对偶形式,当n_samples> n_features时,默认dual = False。C float, default=1.0solver {‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’}, default=’lbfgs’l1_ratio float, default=None'''from sklearn.linear_model import LogisticRegressionlog_iris = LogisticRegression()log_iris.fit(X,y)log_iris.score(X,y)# 0.9733333333333334
# 线性判别分析'''参数:solver:{'svd','lsqr','eigen'},默认='svd'solver的使用,可能的值:'svd':奇异值分解(默认)。不计算协方差矩阵,因此建议将此求解器用于具有大量特征的数据。'lsqr':最小二乘解,可以与收缩结合使用。'eigen':特征值分解,可以与收缩结合使用。'''from sklearn.discriminant_analysis import LinearDiscriminantAnalysislda_iris = LinearDiscriminantAnalysis()lda_iris.fit(X,y)lda_iris.score(X,y)# 0.98
# 朴素贝叶斯from sklearn.naive_bayes import GaussianNBNB_iris = GaussianNB()NB_iris.fit(X, y)NB_iris.score(X,y)# 0.96
(c) 决策树
与前面内容所讲的决策树回归大致是一样的,只是在回归问题中,选择分割点的标准是均方误差,但是在分类问题中,由于因变量是类别变量而不是连续变量,因此用均方误差显然不合适。那问题是用什么作为选择分割点的标准呢?我们先来分析具体的问题:
在回归树中,对一个给定的观测值,因变量的预测值取它所属的终端结点内训练集的平均因变量。与之相对应,对于分类树来说,给定一个观测值,因变量的预测值为它所属的终端结点内训练集的最常出现的类。分类树的构造过程与回归树也很类似,与回归树一样,分类树也是采用递归二叉分裂。但是在分类树中,均方误差无法作为确定分裂节点的准则,一个很自然的替代指标是分类错误率。分类错误率就是:此区域内的训练集中非常见类所占的类别,即:
上式中的 代表第m个区域的训练集中第k类所占的比例。但是在大量的事实证明:分类错误率在构建决策树时不够敏感,一般在实际中用如下两个指标代替:
代表第m个区域的训练集中第k类所占的比例。但是在大量的事实证明:分类错误率在构建决策树时不够敏感,一般在实际中用如下两个指标代替:
基尼系数:
在基尼系数的定义中,我们发现这个指标衡量的是K个类别的总方差。不难发现,如果所有的的取值都接近0或者1,基尼系数会很小。因此基尼系数被视为衡量结点纯度的指标——如果他的取值小,那就意味着某个节点包含的观测值几乎来自同一个类别。
由基尼系数作为指标得到的分类树叫做:CART。
交叉熵:
可以替代基尼系数的指标是交叉熵,定义如下:
显然,如果所有的都接近于0或者1,那么交叉熵就会接近0。因此,和基尼系数一样,如果第m个结点的纯度越高,则交叉熵越小。事实证明,基尼系数和交叉熵在数值上时很接近的。 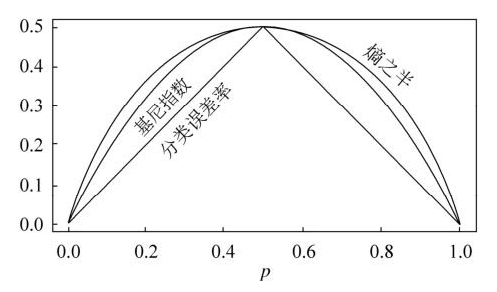
决策树分类算法的完整步骤:
a. 选择最优切分特征j以及该特征上的最优点s:
遍历特征j以及固定j后遍历切分点s,选择使得基尼系数或者交叉熵最小的(j,s)
b. 按照(j,s)分裂特征空间,每个区域内的类别为该区域内样本比例最多的类别。
c. 继续调用步骤1,2直到满足停止条件,就是每个区域的样本数小于等于5。
d. 将特征空间划分为J个不同的区域,生成分类树。
# 使用决策树算法对iris分类:'''criterion:{“gini”, “entropy”}, default=”gini”max_depth:树的最大深度。min_samples_split:拆分内部节点所需的最少样本数min_samples_leaf :在叶节点处需要的最小样本数。'''from sklearn.tree import DecisionTreeClassifiertree_iris = DecisionTreeClassifier(min_samples_leaf=5)tree_iris.fit(X,y)tree_iris.score(X,y)# 0.9734
(d) 支持向量机SVM
支持向量机SVM是20世纪90年代在计算机界发展起来的一种分类算法,在许多问题中都被证明有较好的效果,被认为是适应性最广的算法之一。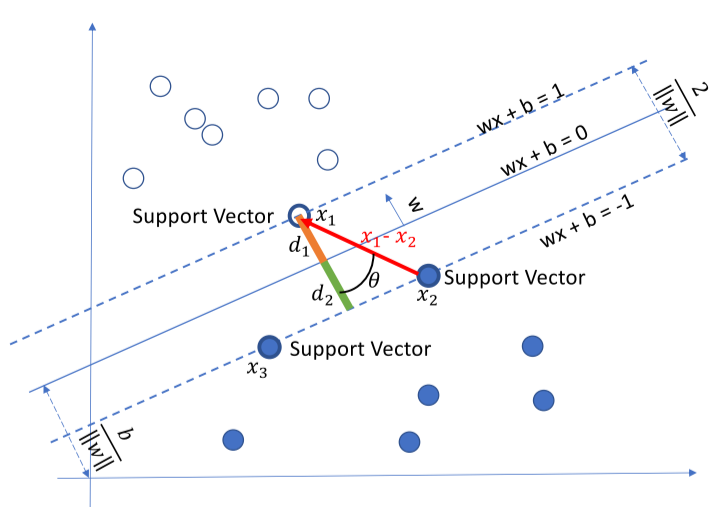
支持向量机的基本原理非常简单,如图所视,白色和蓝色的点各为一类,我们的目标是找到一个分割平面将两个类别分开。通常来说,如果数据本身是线性可分的,那么事实上存在无数个这样的超平面。这是因为给定一个分割平面稍微上移下移或旋转这个超平面,只要不接触这些观测点,仍然可以将数据分开。一个很自然的想法就是找到最大间隔超平面,即找到一个分割平面距离最近的观测点最远。下面我们来严格推导:
我们根据距离超平米那最近的点,只要同时缩放w和b可以得到: 与
与  。因此:
。因此:
由此可知道SVM模型的具体形式:
可以将约束条件写为: 
可以将优化问题拉格朗日化
因此:欲构造 dual 问题, 首先求拉格朗日化的问题中 和
和 的值,对求梯度,令梯度等于0,可求得
的值,对求梯度,令梯度等于0,可求得
将 带入拉格朗日化的原问题可得
带入拉格朗日化的原问题可得
因此:
非线性支持向量机
在刚刚的讨论中,我们都是着重讨论了线性支持向量机是如何工作的,但是在现实生活中,我们很难碰到线性可分的数据集,如: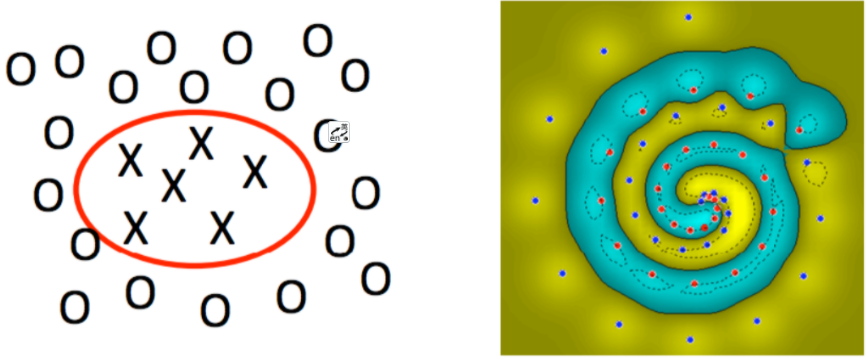
那我们应该如何处理非线性问题呢?答案就是将数据投影至更加高的维度!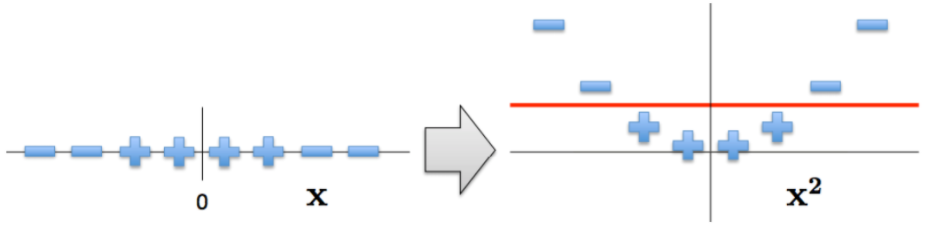
如果我们使用上面公式的形式将低维数据拓展至高维数据,则必须面临一个很大的问题,那就是:维度爆炸导致的计算量太大的问题。假如是一个2维特征的数据,我们可以将其映射到5维来做特征的内积,如果原始空间是三维,可以映射到到19维空间,似乎还可以处理。但是如果我们的低维特征是100个维度,1000个维度呢?那么我们要将其映射到超级高的维度来计算特征的内积。这时候映射成的高维维度是爆炸性增长的,这个计算量实在是太大了,而且如果遇到无穷维的情况,就根本无从计算了。能不能呢个避免这个问题呢?核函数隆重登场:
回顾线性可分SVM的优化目标函数: 
注意到上式低维特征仅仅以内积 的形式出现,如果我们定义一个低维特征空间到高维特征空间的映射
的形式出现,如果我们定义一个低维特征空间到高维特征空间的映射 ,将所有特征映射到一个更高的维度,让数据线性可分,我们就可以继续按前两篇的方法来优化目标函数,求出分离超平面和分类决策函数了。也就是说现在的SVM的优化目标函数变成:
,将所有特征映射到一个更高的维度,让数据线性可分,我们就可以继续按前两篇的方法来优化目标函数,求出分离超平面和分类决策函数了。也就是说现在的SVM的优化目标函数变成:
可以看到,和线性可分SVM的优化目标函数的区别仅仅是将内积替换为 。我们要将其映射到超级高的维度来计算特征的内积。这时候映射成的高维维度是爆炸性增长的,这个计算量实在是太大了,而且如果遇到无穷维的情况,就根本无从计算了。下面引入核函数:
。我们要将其映射到超级高的维度来计算特征的内积。这时候映射成的高维维度是爆炸性增长的,这个计算量实在是太大了,而且如果遇到无穷维的情况,就根本无从计算了。下面引入核函数:
假设是一个从低维的输入空间 (欧式空间的子集或者离散集合)到高维的希尔伯特空间的
(欧式空间的子集或者离散集合)到高维的希尔伯特空间的 映射。那么如果存在函数
映射。那么如果存在函数 ,对于任意
,对于任意 ,都有:
,都有: 。那么我们就称
。那么我们就称 为核函数。
为核函数。
仔细发现的计算是在低维特征空间来计算的,它避免了在刚才我们提到了在高维维度空间计算内积的恐怖计算量。也就是说,我们可以好好享受在高维特征空间线性可分的利益,却避免了高维特征空间恐怖的内积计算量。下面介绍几种常用的核函数:
(1) 多项式核函数:
多项式核函数(Polynomial Kernel)是线性不可分SVM常用的核函数之一,表达式为: 
C用来控制低阶项的强度,C=0,d=1代表无核函数。
(2) 高斯核函数:
高斯核函数(Gaussian Kernel),在SVM中也称为径向基核函数(Radial Basis Function,RBF),它是非线性分类SVM最主流的核函数。libsvm默认的核函数就是它。表达式为: 
使用高斯核函数之前需要将特征标准化,因此这里衡量的是样本之间的相似度。
(3) Sigmoid核函数:
Sigmoid核函数(Sigmoid Kernel)也是线性不可分SVM常用的核函数之一,表达式为: 
此时的SVM相当于没有隐藏层的简单神经网络。
(4) 余弦相似度核:
常用于衡量两段文字的余弦相似度,表达式为:
from sklearn.pipeline import make_pipelinefrom sklearn.preprocessing import StandardScalerfrom sklearn.svm import SVC'''C:正则化参数。正则化的强度与C成反比。必须严格为正。惩罚是平方的l2惩罚。kernel:{'linear','poly','rbf','sigmoid','precomputed'},默认='rbf'degree:多项式和的阶数gamma:“ rbf”,“ poly”和“ Sigmoid”的内核系数。shrinking:是否软间隔分类,默认true'''svc_iris = make_pipeline(StandardScaler(), SVC(gamma='auto'))svc_iris.fit(X, y)svc_iris.score(X,y)# 0.97334
实战
import pandas as pdfrom sklearn import datasetsiris = datasets.load_iris()X = iris.datay = iris.targetfeature = iris.feature_namesdata = pd.DataFrame(X,columns=feature)data['target'] = ydata.head()# 熟悉一下数据
from sklearn.pipeline import make_pipelinefrom sklearn.preprocessing import StandardScalerfrom sklearn.svm import SVC'''C:正则化参数。正则化的强度与C成反比。必须严格为正。惩罚是平方的l2惩罚。kernel:{'linear','poly','rbf','sigmoid','precomputed'},默认='rbf'degree:多项式和的阶数gamma:“ rbf”,“ poly”和“ Sigmoid”的内核系数。shrinking:是否软间隔分类,默认true'''svc_iris = make_pipeline(StandardScaler(), SVC(gamma='auto'))svc_iris.fit(X, y)svc_iris.score(X,y)# 0.9733
# 使用网格搜索进行超参数调优:# 方式1:网格搜索GridSearchCV()from sklearn.model_selection import GridSearchCVfrom sklearn.svm import SVCimport timestart_time = time.time()pipe_svc = make_pipeline(StandardScaler(),SVC(random_state=1))param_range = [0.0001,0.001,0.01,0.1,1.0,10.0,100.0,1000.0]param_grid = [{'svc__C':param_range,'svc__kernel':['linear']},{'svc__C':param_range,'svc__gamma':param_range,'svc__kernel':['rbf']}]gs = GridSearchCV(estimator=pipe_svc,param_grid=param_grid,scoring='accuracy',cv=10,n_jobs=-1)gs = gs.fit(X,y)end_time = time.time()print("网格搜索经历时间:%.3f S" % float(end_time-start_time))print(gs.best_score_)print(gs.best_params_)# 网格搜索经历时间:1.766 S# 0.9800000000000001# {'svc__C': 1.0, 'svc__gamma': 0.1, 'svc__kernel': 'rbf'}
# 方式2:随机网格搜索RandomizedSearchCV()from sklearn.model_selection import RandomizedSearchCVfrom sklearn.svm import SVCimport timestart_time = time.time()pipe_svc = make_pipeline(StandardScaler(),SVC(random_state=1))param_range = [0.0001,0.001,0.01,0.1,1.0,10.0,100.0,1000.0]param_grid = [{'svc__C':param_range,'svc__kernel':['linear']},{'svc__C':param_range,'svc__gamma':param_range,'svc__kernel':['rbf']}]# param_grid = [{'svc__C':param_range,'svc__kernel':['linear','rbf'],'svc__gamma':param_range}]gs = RandomizedSearchCV(estimator=pipe_svc, param_distributions=param_grid,scoring='accuracy',cv=10,n_jobs=-1)gs = gs.fit(X,y)end_time = time.time()print("随机网格搜索经历时间:%.3f S" % float(end_time-start_time))print(gs.best_score_)print(gs.best_params_)# 随机网格搜索经历时间:0.156 S# 0.9733333333333334# {'svc__kernel': 'rbf', 'svc__gamma': 0.0001, 'svc__C': 1000.0}
当类别为两类时,可以绘制混淆矩阵与ROC曲线
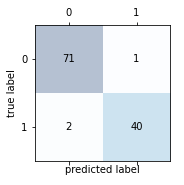
import matplotlib.pyplot as plt# 混淆矩阵:# 加载数据df = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data",header=None)'''乳腺癌数据集:569个恶性和良性肿瘤细胞的样本,M为恶性,B为良性'''# 做基本的数据预处理from sklearn.preprocessing import LabelEncoderX = df.iloc[:,2:].valuesy = df.iloc[:,1].valuesle = LabelEncoder() #将M-B等字符串编码成计算机能识别的0-1y = le.fit_transform(y)le.transform(['M','B'])# 数据切分8:2from sklearn.model_selection import train_test_splitX_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,stratify=y,random_state=1)from sklearn.svm import SVCpipe_svc = make_pipeline(StandardScaler(),SVC(random_state=1))from sklearn.metrics import confusion_matrixpipe_svc.fit(X_train,y_train)y_pred = pipe_svc.predict(X_test)confmat = confusion_matrix(y_true=y_test,y_pred=y_pred)fig,ax = plt.subplots(figsize=(2.5,2.5))ax.matshow(confmat, cmap=plt.cm.Blues,alpha=0.3)for i in range(confmat.shape[0]):for j in range(confmat.shape[1]):ax.text(x=j,y=i,s=confmat[i,j],va='center',ha='center')plt.xlabel('predicted label')plt.ylabel('true label')plt.show()
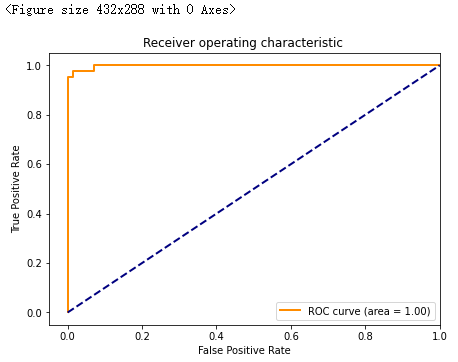
# 绘制ROC曲线:from sklearn.metrics import roc_curve,aucfrom sklearn.metrics import make_scorer,f1_scorescorer = make_scorer(f1_score,pos_label=0)gs = GridSearchCV(estimator=pipe_svc,param_grid=param_grid,scoring=scorer,cv=10)y_pred = gs.fit(X_train,y_train).decision_function(X_test)#y_pred = gs.predict(X_test)fpr,tpr,threshold = roc_curve(y_test, y_pred) ###计算真阳率和假阳率roc_auc = auc(fpr,tpr) ###计算auc的值plt.figure()lw = 2plt.figure(figsize=(7,5))plt.plot(fpr, tpr, color='darkorange',lw=lw, label='ROC curve (area = %0.2f)' % roc_auc) ###假阳率为横坐标,真阳率为纵坐标做曲线plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')plt.xlim([-0.05, 1.0])plt.ylim([-0.05, 1.05])plt.xlabel('False Positive Rate')plt.ylabel('True Positive Rate')plt.title('Receiver operating characteristic ')plt.legend(loc="lower right")plt.show()
作业
结合sklearn的fetch_lfw_people数据集,进行一次实战。
案例参照:https://scikit-learn.org/stable/modules/generated/sklearn.datasets.fetch_lfw_people.html
from sklearn.datasets import fetch_lfw_peoplefaces = fetch_lfw_people(min_faces_per_person=60)print(faces.target_names)print(faces.images.shape)# ['Ariel Sharon' 'Colin Powell' 'Donald Rumsfeld' 'George W Bush'# 'Gerhard Schroeder' 'Hugo Chavez' 'Junichiro Koizumi' 'Tony Blair']# (1348, 62, 47)
import matplotlib.pyplot as pltimport seaborn as sns;sns.set()fig, ax = plt.subplots(3,5)fig.subplots_adjust(left=0.0625, right=1.2, wspace=1)for i, axi in enumerate(ax.flat):axi.imshow(faces.images[i], cmap='bone')axi.set(xticks=[], yticks=[], xlabel=faces.target_names[faces.target[i]])

from sklearn.svm import SVCfrom sklearn.decomposition import PCAfrom sklearn.pipeline import make_pipelinepca = PCA(n_components=150, whiten=True, random_state=42)svc = SVC(kernel='rbf', class_weight='balanced')model = make_pipeline(pca, svc)#为了测试分类器的训练效果,将数据集分解成训练集和测试集进行交叉检验from sklearn.model_selection import train_test_splitx_train, x_test, y_train, y_test = train_test_split(faces.data, faces.target, random_state=42)#用网络搜索交叉检验来寻找最优参数组合。通过不断调整C(松弛变量)和参数gamma(控制径向基函数核的大小),确定最优模型from sklearn.model_selection import GridSearchCVparam_grid = {'svc__C': [1,5,10,50], 'svc__gamma':[0.0001, 0.0005, 0.001, 0.005]}grid = GridSearchCV(model, param_grid)grid.fit(x_train, y_train)print(grid.best_params_)# {'svc__C': 10, 'svc__gamma': 0.001}
#有了交叉检验的模型,现在就可以对测试集的数据进行预测了model = grid.best_estimator_y_fit = model.predict(x_test)#比较预测结果和真实结果fig, ax = plt.subplots(4, 6)for i, axi in enumerate(ax.flat):axi.imshow(x_test[i].reshape(62, 47), cmap='bone')axi.set(xticks=[], yticks=[])axi.set_ylabel(faces.target_names[y_fit[i]].split()[-1],color='black' if y_fit[i] == y_test[i] else 'red')fig.suptitle('Predicted Names; Incorect Lables in Red', size=14)

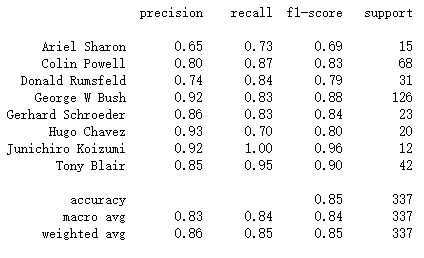
#打印分类效果报告,他会列举每个标签的统计结果,从而对评估器的性能有更全面的认识from sklearn.metrics import classification_reportprint(classification_report(y_test, y_fit, target_names=faces.target_names))
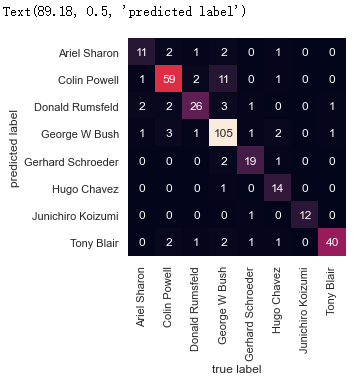
#画出混淆矩阵,它可以帮助我们清晰的判断那些标签容易被分类器误判from sklearn.metrics import confusion_matrixmat = confusion_matrix(y_test, y_fit)sns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False,xticklabels=faces.target_names,yticklabels=faces.target_names)plt.xlabel('true label')plt.ylabel('predicted label')

若有收获,就点个赞吧
0 人点赞
