回调入门指南 中提到过Dash的核心原则之一 : Dash Callbacks 绝不能修改其范围之外的变量。修改任何 global 变量都是不安全的。本章解释这样操作为什么不安全,并提出在回调函数间共享状态的替代方式。
1.概述
1.1为什么要共享状态?
- 某些应用可能会有SQL查询、运行模拟或下载数据等扩展性数据处理任务,所以会使用多个回调函数。
- 与其让每个回调函数都运行同一个大规模运算任务,不如让其中一个回调函数执行任务,然后将结果共享给其它回调函数,而不是让每个回调函数运行相同的昂贵任务。
- 由于可以为一次回调设置多个输出,实现昂贵的任务一次完成,即可用于所有的输出。但在某些情况下,这仍然不太理想,例如,如果有简单的后续任务可以修改结果,例如单位转换。我们不需要重复大型数据库查询,只是为了将结果从华氏温度更改为摄氏温度。
1.2为什么全局变量会破坏应用?
Dash应用旨在在多用户环境中工作,多个人可以同时查看应用程序,并具有独立会话。
如果用户可以修改应用的全局变量,即使用修改后的 global 变量,会影响下一位用户会话的值。
Dash的设计思路还包括运行多个Python workers,实现多个回调函数,并行执行。通常,使用gunicorn语法完成:
$ gunicorn --workers 4 app:server
- app:命名的文件
app.py - server:命名的文件的变量
server:server = app.server
当Dash应用跨多个工作程序(worker)运行时,不会共享内存。这意味着,如果某个回调函数修改了全局变量,则该修改将不会应用于其它的工作程序。
1.3在回调函数之间共享数据
为了在多个python进程之间安全地共享数据,则需要将数据存储在每个进程可访问的位置。推荐在如下3个位置存储数据:
- 在用户的浏览器会话中
- 在磁盘上,例如:文件或新数据库
- 与Redis一样,存在共享内存空间
1.4示例
```python df = pd.DataFrame({ ‘a’: [1, 2, 3], ‘b’: [4, 1, 4], ‘c’: [‘x’, ‘y’, ‘z’], })
app.layout = html.Div([ dcc.Dropdown( id=’dropdown’, options=[{‘label’: i, ‘value’: i} for i in df[‘c’].unique()], value=’a’ ), html.Div(id=’output’), ])
@app.callback(Output(‘output’, ‘children’), Input(‘dropdown’, ‘value’)) def update_output_1(value): global df = df[df[‘c’] == value] # 不要这样做,不安全 return len(df)
修改一下```pythondf = pd.DataFrame({'a': [1, 2, 3],'b': [4, 1, 4],'c': ['x', 'y', 'z'],})app.layout = html.Div([dcc.Dropdown(id='dropdown',options=[{'label': i, 'value': i} for i in df['c'].unique()],value='a'),html.Div(id='output'),])@app.callback(Output('output', 'children'),Input('dropdown', 'value'))def update_output_1(value):# 安全地将过滤器重新分配给一个新变量filtered_df = df[df['c'] == value]return len(filtered_df)
2.在回调之间共享数据
为了在多个python进程之间安全地共享数据,我们需要将数据存储在每个进程都可以访问的地方。
有三个主要的地方来存储这些数据:
1 -在用户的浏览器会话
2 -在磁盘上(例如在一个文件上或在一个新的数据库上)
3 -在共享内存空间,像Redis
下面三个例子说明了这些方法。
例1 -在浏览器中使用隐藏的Div存储数据
- 通过将数据保存为Dash前端存储的一部分来实现【连接】
- 为了存储和传输数据,必须将数据转换为
JSON之类的字符串 以这种方式缓存的数据将只在用户的当前会话中可用
- 如果你打开一个新的浏览器,应用程序的回调将总是计算数据。数据只在会话内的回调之间缓存和传输。
- 因此,与缓存不同,这个方法不会增加应用程序的内存占用。
- 网络传输可能会有成本。如果在回调之间共享10MB的数据,那么这些数据将在每个回调之间通过网络传输。
- 如果网络成本太高,那么就提前计算聚合并传输它们。你的应用可能不会显示10MB的数据,它将只是显示它的子集或聚合。
这个示例概述了如何在一个回调中执行昂贵的数据处理步骤,将输出序列化为JSON,并将其作为输入提供给其他回调。这个例子使用了标准的Dash回调,并将json化的数据存储在应用程序的隐藏div中。
global_df = pd.read_csv('...')app.layout = html.Div([dcc.Graph(id='graph'),html.Table(id='table'),dcc.Dropdown(id='dropdown'),# 应用程序中隐藏的div存储中间值html.Div(id='intermediate-value', style={'display': 'none'})])@app.callback(Output('intermediate-value', 'children'), Input('dropdown', 'value'))def clean_data(value):# 一些昂贵的清洁数据步骤cleaned_df = your_expensive_clean_or_compute_step(value)# more generally, this line would be# json.dumps(cleaned_df)return cleaned_df.to_json(date_format='iso', orient='split')@app.callback(Output('graph', 'figure'), Input('intermediate-value', 'children'))def update_graph(jsonified_cleaned_data):# more generally, this line would be# json.loads(jsonified_cleaned_data)dff = pd.read_json(jsonified_cleaned_data, orient='split')figure = create_figure(dff)return figure@app.callback(Output('table', 'children'), Input('intermediate-value', 'children'))def update_table(jsonified_cleaned_data):dff = pd.read_json(jsonified_cleaned_data, orient='split')table = create_table(dff)return table
例2 -预先计算聚合
如果数据很大,通过网络发送计算数据的代价可能会很高。在某些情况下,序列化这些数据和JSON的代价也会很高。
在很多情况下,你的应用程序将只显示计算或过滤数据的子集或聚合。在这些情况下,您可以在数据处理回调中预先计算聚合,并将这些聚合传输给其余的回调。
下面是一个简单的示例,说明如何将经过过滤或聚合的数据传输到多个回调。
@app.callback(Output('intermediate-value', 'children'),Input('dropdown', 'value'))def clean_data(value):# 高消耗查询cleaned_df = your_expensive_clean_or_compute_step(value)# 几个数据的过滤步骤# 下面的回调中会用到对应的数据df_1 = cleaned_df[cleaned_df['fruit'] == 'apples']df_2 = cleaned_df[cleaned_df['fruit'] == 'oranges']df_3 = cleaned_df[cleaned_df['fruit'] == 'figs']datasets = {'df_1': df_1.to_json(orient='split', date_format='iso'),'df_2': df_2.to_json(orient='split', date_format='iso'),'df_3': df_3.to_json(orient='split', date_format='iso'),}return json.dumps(datasets) #转化成str,直接to_json也行@app.callback(Output('graph', 'figure'),Input('intermediate-value', 'children'))def update_graph_1(jsonified_cleaned_data):datasets = json.loads(jsonified_cleaned_data)dff = pd.read_json(datasets['df_1'], orient='split')figure = create_figure_1(dff)return figure@app.callback(Output('graph', 'figure'),Input('intermediate-value', 'children'))def update_graph_2(jsonified_cleaned_data):datasets = json.loads(jsonified_cleaned_data)dff = pd.read_json(datasets['df_2'], orient='split')figure = create_figure_2(dff)return figure@app.callback(Output('graph', 'figure'),Input('intermediate-value', 'children'))def update_graph_3(jsonified_cleaned_data):datasets = json.loads(jsonified_cleaned_data)dff = pd.read_json(datasets['df_3'], orient='split')figure = create_figure_3(dff)return figure
例3 -缓存和信令
这个例子:
- 使用
Redis通过Flask-Cache存储“全局变量”。该数据通过函数访问,函数的输出被缓存,并由其输入参数键控。 - 当高消耗计算完成时,使用隐藏的div解决方案向其他回调发送信号。
- 注意,除了
Redis,你也可以把它保存到文件系统。见查看详细信息。 - 这种“信令”很牛逼,因为它允许高消耗计算只占用一个进程。如果没有这种类型的信号,每个回调都可能以并行计算昂贵的计算结束,锁定四个进程而不是一个。
这种方法的优点还在于,将来的会话可以使用预先计算的值。这将适用于具有少量输入的应用程序。
import osimport copyimport timeimport datetimeimport dashimport dash_core_components as dccimport dash_html_components as htmlimport numpy as npimport pandas as pdfrom dash.dependencies import Input, Outputfrom flask_caching import Cacheexternal_stylesheets = [# Dash CSS'https://codepen.io/chriddyp/pen/bWLwgP.css',# Loading screen CSS'https://codepen.io/chriddyp/pen/brPBPO.css']app = dash.Dash(__name__, external_stylesheets=external_stylesheets)CACHE_CONFIG = {# try 'filesystem' if you don't want to setup redis'CACHE_TYPE': 'redis','CACHE_REDIS_URL': os.environ.get('REDIS_URL', 'redis://localhost:6379')}cache = Cache()cache.init_app(app.server, config=CACHE_CONFIG)N = 100df = pd.DataFrame({'category': ((['apples'] * 5 * N) +(['oranges'] * 10 * N) +(['figs'] * 20 * N) +(['pineapples'] * 15 * N))})df['x'] = np.random.randn(len(df['category']))df['y'] = np.random.randn(len(df['category']))app.layout = html.Div([dcc.Dropdown(id='dropdown',options=[{'label': i, 'value': i} for i in df['category'].unique()],value='apples'),html.Div([html.Div(dcc.Graph(id='graph-1'), className="six columns"),html.Div(dcc.Graph(id='graph-2'), className="six columns"),], className="row"),html.Div([html.Div(dcc.Graph(id='graph-3'), className="six columns"),html.Div(dcc.Graph(id='graph-4'), className="six columns"),], className="row"),# hidden signal valuehtml.Div(id='signal', style={'display': 'none'})])# 在这个“全局存储”中执行高消耗的计算# 这些计算被缓存在全局可用的缓存中# redis内存存储是跨进程可用的# 所有的时间@cache.memoize()def global_store(value):# 模拟高消耗的查询print('Computing value with {}'.format(value))time.sleep(5)return df[df['category'] == value]def generate_figure(value, figure):fig = copy.deepcopy(figure)filtered_dataframe = global_store(value)fig['data'][0]['x'] = filtered_dataframe['x']fig['data'][0]['y'] = filtered_dataframe['y']fig['layout'] = {'margin': {'l': 20, 'r': 10, 'b': 20, 't': 10}}return fig@app.callback(Output('signal', 'children'), Input('dropdown', 'value'))def compute_value(value):# compute value and send a signal when doneglobal_store(value)return value@app.callback(Output('graph-1', 'figure'), Input('signal', 'children'))def update_graph_1(value):# generate_figure gets data from `global_store`.# the data in `global_store` has already been computed# by the `compute_value` callback and the result is stored# in the global redis cachedreturn generate_figure(value, {'data': [{'type': 'scatter','mode': 'markers','marker': {'opacity': 0.5,'size': 14,'line': {'border': 'thin darkgrey solid'}}}]})@app.callback(Output('graph-2', 'figure'), Input('signal', 'children'))def update_graph_2(value):return generate_figure(value, {'data': [{'type': 'scatter','mode': 'lines','line': {'shape': 'spline', 'width': 0.5},}]})@app.callback(Output('graph-3', 'figure'), Input('signal', 'children'))def update_graph_3(value):return generate_figure(value, {'data': [{'type': 'histogram2d',}]})@app.callback(Output('graph-4', 'figure'), Input('signal', 'children'))def update_graph_4(value):return generate_figure(value, {'data': [{'type': 'histogram2dcontour',}]})if __name__ == '__main__':app.run_server(debug=True, processes=True)

例4 -服务器上基于用户的会话数据
在某些情况下,你希望将数据与用户会话隔离:一个用户的派生数据不应该更新下一个用户的派生数据。一种方法是将数据保存在一个隐藏的Div中,如第一个示例所示。
另一种方法是将数据保存在带有会话ID的文件系统缓存中,然后使用该会话ID引用数据。由于数据保存在服务器上,而不是通过网络传输,因此这种方法通常比“hidden div”方法更快。
这个例子中:
- 使用
flask_caching文件系统缓存缓存数据。你也可以保存到内存数据库,如Redis。 - 将数据序列化为
JSON。 - 将会话数据保存到预期的并发用户数量。这可以防止缓存被数据填满。
- 创建唯一的会话
id,通过嵌入一个隐藏的随机字符串到应用程序的布局和服务在每个页面加载独特的布局。 ```python import dash from dash.dependencies import Input, Output import dash_core_components as dcc import dash_html_components as html import datetime from flask_caching import Cache import os import pandas as pd import time import uuid
external_stylesheets = [
# Dash CSS'https://codepen.io/chriddyp/pen/bWLwgP.css',# Loading screen CSS'https://codepen.io/chriddyp/pen/brPBPO.css']
app = dash.Dash(name, external_stylesheets=external_stylesheets) cache = Cache(app.server, config={ ‘CACHE_TYPE’: ‘redis’,
# Note that filesystem cache doesn't work on systems with ephemeral# filesystems like Heroku.'CACHE_TYPE': 'filesystem','CACHE_DIR': 'cache-directory',# should be equal to maximum number of users on the app at a single time# higher numbers will store more data in the filesystem / redis cache'CACHE_THRESHOLD': 200
})
def get_dataframe(session_id): @cache.memoize() def query_and_serialize_data(session_id):
# expensive or user/session-unique data processing step goes here# simulate a user/session-unique data processing step by generating# data that is dependent on timenow = datetime.datetime.now()# simulate an expensive data processing task by sleepingtime.sleep(5)df = pd.DataFrame({'time': [str(now - datetime.timedelta(seconds=15)),str(now - datetime.timedelta(seconds=10)),str(now - datetime.timedelta(seconds=5)),str(now)],'values': ['a', 'b', 'a', 'c']})return df.to_json()return pd.read_json(query_and_serialize_data(session_id))
def serve_layout(): session_id = str(uuid.uuid4())
return html.Div([html.Div(session_id, id='session-id', style={'display': 'none'}),html.Button('Get data', id='get-data-button'),html.Div(id='output-1'),html.Div(id='output-2')])
app.layout = serve_layout
@app.callback(Output(‘output-1’, ‘children’), Input(‘get-data-button’, ‘n_clicks’), Input(‘session-id’, ‘children’)) def display_value_1(value, session_id): df = get_dataframe(session_id) return html.Div([ ‘Output 1 - Button has been clicked {} times’.format(value), html.Pre(df.to_csv()) ])
@app.callback(Output(‘output-2’, ‘children’), Input(‘get-data-button’, ‘n_clicks’), Input(‘session-id’, ‘children’)) def display_value_2(value, session_id): df = get_dataframe(session_id) return html.Div([ ‘Output 2 - Button has been clicked {} times’.format(value), html.Pre(df.to_csv()) ])
if name == ‘main‘:
app.run_server(debug=True)
```
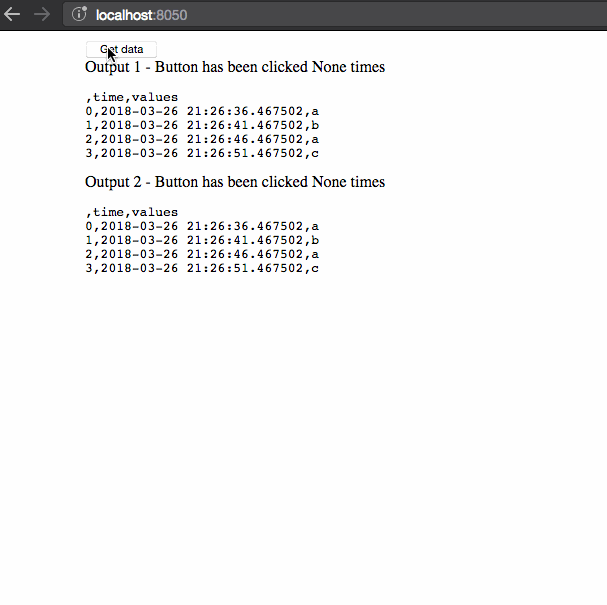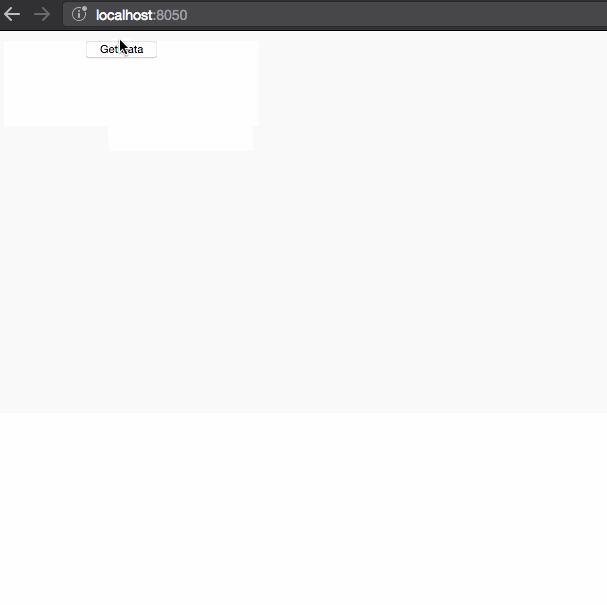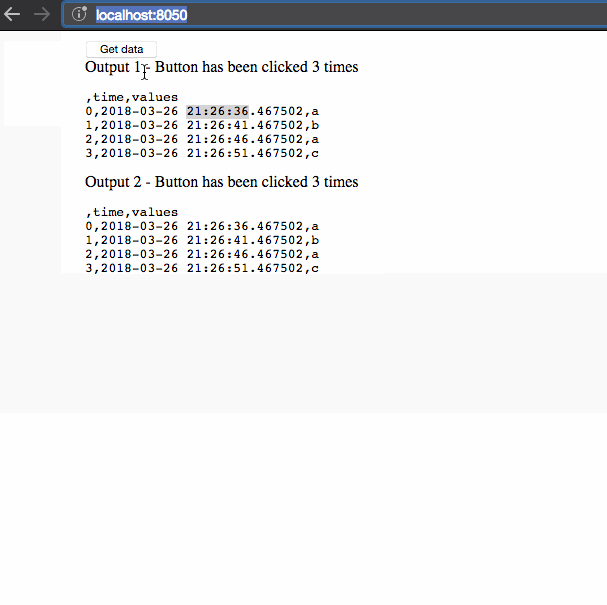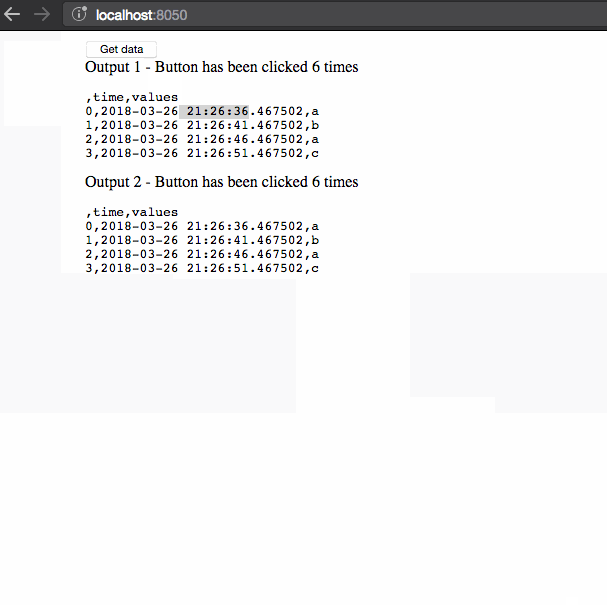
在这个例子中有三件事需要注意:
- 当我们检索数据时,数据帧的时间戳不会更新。该数据作为用户会话的一部分缓存。
- 检索数据最初需要5秒,但后续查询是即时的,因为数据已被缓存。
- 第二个会话显示的数据与第一个会话不同:回调之间共享的数据与单独的用户会话隔离。

若有收获,就点个赞吧
0 人点赞
