投票法原理及案例分析
投票法的思路
投票法是集成学习中常用的技巧,可以帮助我们提高模型的适应能力,减少模型的错误率。
举个例子,在航空航天领域,每个零件发出的电信号都对航空器的成功发射起到重要作用。如果我们有一个二进制形式的信号:
11101100100111001011011011011
在传输过程中第二位发生了翻转
10101100100111001011011011011
为了避免这个错误,我们可以多次发送这个信号,然后选取最多重复位置的数字,取到原始信号。
一般情况下,错误总是发生在局部,因此融合多个数据是降低误差的一个好方法,这就是投票法的基本思路。
- 对于回归模型来说,投票法最终的预测结果是多个其他回归模型预测结果的平均值。
对于分类模型,硬投票法的预测结果是多个模型预测结果中出现次数最多的类别,软投票对各类预测结果的概率进行求和,最终选取概率之和最大的类标签。
投票法的原理分析
投票法是一种遵循少数服从多数原则的集成学习模型,通过多个模型的集成降低方差,从而提高模型的鲁棒性。在理想情况下,投票法的预测效果应当优于任何一个基模型的预测效果。
投票法在回归模型与分类模型上均可使用:回归投票法:预测结果是所有模型预测结果的平均值。
- 分类投票法:预测结果是所有模型种出现最多的预测结果。
分类投票法又可以被划分为硬投票与软投票:
- 硬投票:预测结果是所有投票结果最多出现的类。
- 软投票:预测结果是所有投票结果中概率加和最大的类。
下面我们使用一个例子说明硬投票:
对于某个样本: 模型 1 的预测结果是 类别 A 模型 2 的预测结果是 类别 B 模型 3 的预测结果是 类别 B
有2/3的模型预测结果是B,因此硬投票法的预测结果是B
同样的例子说明软投票:
对于某个样本: 模型 1 的预测结果是 类别 A 的概率为 99% 模型 2 的预测结果是 类别 A 的概率为 49% 模型 3 的预测结果是 类别 A 的概率为 49%
最终对于类别A的预测概率的平均是 (99 + 49 + 49) / 3 = 65.67%,因此软投票法的预测结果是A。
从这个例子我们可以看出,软投票法与硬投票法可以得出完全不同的结论。相对于硬投票,软投票法考虑到了预测概率这一额外的信息,因此可以得出比硬投票法更加准确的预测结果。
在投票法中,我们还需要考虑到不同的基模型可能产生的影响。理论上,基模型可以是任何已被训练好的模型。但在实际应用上,想要投票法产生较好的结果,需要满足两个条件:
- 基模型之间的效果不能差别过大。当某个基模型相对于其他基模型效果过差时,该模型很可能成为噪声。
- 基模型之间应该有较小的同质性。例如在基模型预测效果近似的情况下,基于树模型与线性模型的投票,往往优于两个树模型或两个线性模型。
当投票合集中使用的模型能预测出清晰的类别标签时,适合使用硬投票。比如这个瓜是好瓜还是坏瓜。
当投票集合中使用的模型能预测类别的概率时,适合使用软投票。比如这个瓜是好瓜的概率。
软投票同样可以用于那些本身并不预测类成员概率的模型,只要他们可以输出类似于概率的预测分数值(例如支持向量机、k-最近邻和决策树)。
投票法的局限性在于,它对所有模型的处理是一样的,这意味着所有模型对预测的贡献是一样的。如果一些模型在某些情况下很好,而在其他情况下很差,这是使用投票法时需要考虑到的一个问题。
投票法的案例分析(基于sklearn,介绍pipe管道的使用以及voting的使用)
Sklearn中提供了 VotingRegressor 与 VotingClassifier 两个投票方法。 这两种模型的操作方式相同,并采用相同的参数。使用模型需要提供一个模型列表,列表中每个模型采用Tuple的结构表示,第一个元素代表名称,第二个元素代表模型,需要保证每个模型必须拥有唯一的名称。
例如这里,我们定义两个模型:
from sklearn.ensemble import VotingClassifierfrom sklearn.linear_model import LogisticRegressionfrom sklearn.svm import SVCmodels = [('lr',LogisticRegression()),('svm',SVC())]ensemble = VotingClassifier(estimators=models)
有时某些模型需要一些预处理操作,我们可以为他们定义Pipeline完成模型预处理工作:
from sklearn.pipeline import make_pipelinefrom sklearn.preprocessing import StandardScalermodels = [('lr',LogisticRegression()),('svm',make_pipeline(StandardScaler(),SVC()))]ensemble = VotingClassifier(estimators=models)
模型还提供了voting参数让我们选择软投票或者硬投票:
models = [('lr',LogisticRegression()),('svm',SVC())]ensemble = VotingClassifier(estimators=models, voting='soft')
下面我们使用一个完整的例子演示投票法的使用:
首先我们创建一个1000个样本,20个特征的随机数据集:
from sklearn.datasets import make_classificationX, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=2)print(X.shape, y.shape)# (1000, 20) (1000,)
我们使用多个KNN模型作为基模型演示投票法,其中每个模型采用不同的邻居值K参数:
from sklearn.neighbors import KNeighborsClassifier# get a voting ensemble of modelsdef get_voting():# define the base modelsmodels = list()models.append(('knn1', KNeighborsClassifier(n_neighbors=1)))models.append(('knn3', KNeighborsClassifier(n_neighbors=3)))models.append(('knn5', KNeighborsClassifier(n_neighbors=5)))models.append(('knn7', KNeighborsClassifier(n_neighbors=7)))models.append(('knn9', KNeighborsClassifier(n_neighbors=9)))# define the voting ensembleensemble = VotingClassifier(estimators=models, voting='hard')return ensemble
然后,我们可以创建一个模型列表来评估投票带来的提升,包括KNN模型配置的每个独立版本和硬投票模型。下面的get_models()函数可以为我们创建模型列表进行评估。
# get a list of models to evaluatedef get_models():models = dict()models['knn1'] = KNeighborsClassifier(n_neighbors=1)models['knn3'] = KNeighborsClassifier(n_neighbors=3)models['knn5'] = KNeighborsClassifier(n_neighbors=5)models['knn7'] = KNeighborsClassifier(n_neighbors=7)models['knn9'] = KNeighborsClassifier(n_neighbors=9)models['hard_voting'] = get_voting()return models
下面的evaluate_model()函数接收一个模型实例,并以分层10倍交叉验证三次重复的分数列表的形式返回。
from sklearn.model_selection import RepeatedStratifiedKFoldfrom sklearn.model_selection import cross_val_score# evaluate a give model using cross-validationdef evaluate_model(model, X, y):cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')return scores
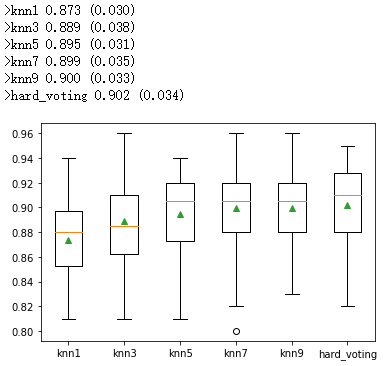
然后,我们可以报告每个算法的平均性能,还可以创建一个箱形图和须状图来比较每个算法的精度分数分布。
import numpy as npfrom matplotlib import pyplot# get the models to evaluatemodels = get_models()# evaluate the models and store resultsresults, names = list(), list()for name, model in models.items():scores = evaluate_model(model, X, y)results.append(scores)names.append(name)print('>%s %.3f (%.3f)' % (name, np.mean(scores), np.std(scores)))# plot model performance for comparisonpyplot.boxplot(results, labels=names, showmeans=True)pyplot.show()
bagging的思路
与投票法不同的是,bagging会施加一定的策略来影响基模型训练,保证基模型可以服从一定的假设。以加大各个模型之间的差异性。
投票法是同一个数据集训练N次,然后对N次进行平均值或取最大值。bagging是对一个数据集进行反复采样,每次采样进行一次模型训练,最后进行集和。
bagging的原理分析
Bagging的核心在于自助采样(bootstrap)这一概念,即有放回的从数据集中进行采样,也就是说,同样的一个样本可能被多次进行采样。一个自助采样的小例子是我们希望估计全国所有人口年龄的平均值,那么我们可以在全国所有人口中随机抽取不同的集合(这些集合可能存在交集),计算每个集合的平均值,然后将所有平均值的均值作为估计值。
首先我们随机取出一个样本放入采样集合中,再把这个样本放回初始数据集,重复K次采样,最终我们可以获得一个大小为K的样本集合。同样的方法, 我们可以采样出T个含K个样本的采样集合,然后基于每个采样集合训练出一个基学习器,再将这些基学习器进行结合,这就是Bagging的基本流程。
对回归问题的预测是通过预测取平均值来进行的。对于分类问题的预测是通过对预测取多数票预测来进行的。Bagging方法之所以有效,是因为每个模型都是在略微不同的训练数据集上拟合完成的,这又使得每个基模型之间存在略微的差异,使每个基模型拥有略微不同的训练能力。
Bagging同样是一种降低方差的技术,因此它在不剪枝决策树、神经网络等易受样本扰动的学习器上效果更加明显。在实际的使用中,加入列采样的Bagging技术对高维小样本往往有神奇的效果。
bagging的案例分析(基于sklearn,介绍随机森林的相关理论以及实例)
Sklearn为我们提供了 BaggingRegressor 与 BaggingClassifier 两种Bagging方法的API,我们在这里通过一个完整的例子演示Bagging在分类问题上的具体应用。这里两种方法的默认基模型是树模型。
我们创建一个含有1000个样本20维特征的随机分类数据集:
# test classification datasetfrom sklearn.datasets import make_classification# define datasetX, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=5)# summarize the datasetprint(X.shape, y.shape) # (1000, 20) (1000,)
我们将使用重复的分层k-fold交叉验证来评估该模型,一共重复3次,每次有10个fold。我们将评估该模型在所有重复交叉验证中性能的平均值和标准差。
# evaluate bagging algorithm for classificationfrom numpy import meanfrom numpy import stdfrom sklearn.datasets import make_classificationfrom sklearn.model_selection import cross_val_scorefrom sklearn.model_selection import RepeatedStratifiedKFoldfrom sklearn.ensemble import BaggingClassifier# define datasetX, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=5)# define the modelmodel = BaggingClassifier()# evaluate the modelcv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')# report performanceprint('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))# Accuracy: 0.864 (0.038)
最终模型的效果是Accuracy: 0.856 标准差0.037

若有收获,就点个赞吧
0 人点赞
