
作者 | 思语
阅读时间 | 34分钟
**
webpack 是一个 JS 代码模块化的打包工具,藉由它强大的扩展能力,随着社区的发展,逐渐成为一个功能完善的构建工具,目前webpack已更新第五版本。
webpack的与众不同
webpack 是前端常用的打包工具,可以看作是模块打包机,它的工作主要是分析项目结构,找到JavaScript模块以及一些浏览器无法直接编译的其它拓展语言(比如sass,ts等等),对项目整体进行解析、加工、打包、优化。
Q:WebPack 和 Grunt 以及 Gulp 相比有什么特性?
A:同作为前端打包工具,Webpack和另外两个没有太多的可比性,相对而言,Gulp/Grunt更倾向于专业的流程打包工具,而WebPack提供的是一整套模块化的解决方案,webpack所能做的事情更多更完善,至今为止webpack以及发展到了5.x版本,webpack的优点使得Webpack在很多场景下可以替代Gulp/Grunt类的工具。
Grunt、Gulp的工作方式是:在一个配置文件中,指明对某些文件进行类似编译,组合,压缩等任务的具体步骤,工具之后可以自动替你完成这些任务。
Webpack的工作方式是:把你的项目当做一个整体,通过一个给定的主文件(如:index.js),Webpack将从这个文件开始找到你的项目的所有依赖文件,使用loaders处理它们,最后打包为一个(或多个)浏览器可识别的JavaScript文件。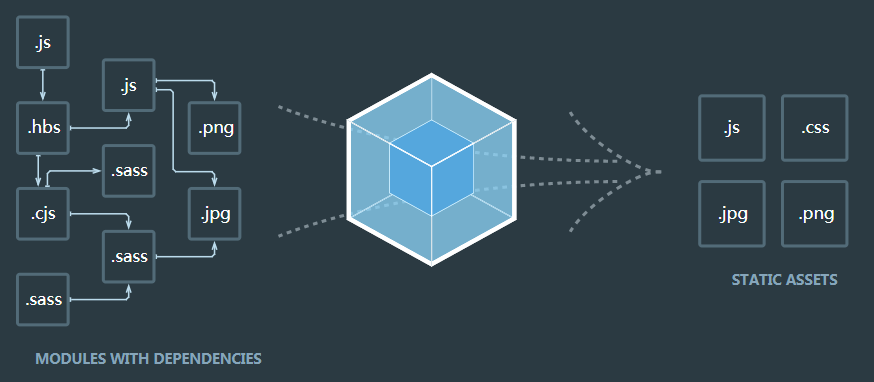
webpack 内部工作机制
以webpack4为例,上篇文章 【工具篇】1 | Webpack的基本使用 已经详细介绍webpack的基本使用方法,下面将探讨 webpack 内部运行机制和其构建优化。
了解 webpack 的内部工作流程,有助于我们解决日常使用 webpack 时遇到的一些问题,也有助于我们更好地理解 webpack loader 和 plugin 的使用。
先暂时抛开复杂的 loader 和 plugin 机制(以后将详细介绍),webpack 本质上就是一个 JS Module Bundler,用于将多个代码模块进行打包,首先通过一个相对简单的 JS Module Bunlder 的基础工作流程是如何运行的,在了解了 bundler 如何工作的基础上,再进一步去整理 webpack 整个流程,将 loader 和 plugin 的机制弄明白。
以下内容将 module bundler 简称为 bundler。
1.bundler 的基础流程
bundler 从构建入口出发,解析代码,分析出代码模块依赖关系,然后将依赖的代码模块组合在一起,在 JavaScript bundler 中,还需要提供一些胶水代码让多个代码模块可以协同工作,相互引用。首先是解析代码、分析依赖关系,对于 ES6 Module 以及 CommonJS Modules 语法定义的模块,例如这样的代码:
// entry.jsimport { bar } from './bar.js'; // 依赖 ./bar.js 模块// bar.jsconst foo = require('./foo.js'); // 依赖 ./foo.js 模块
bundler 需要从这个入口代码(第一段)中解析出依赖 bar.js,然后再读取 bar.js 这个代码文件,解析出依赖 foo.js 代码文件,继续解析其依赖,递归下去,直至没有更多的依赖模块,最终形成一颗模块依赖树。
分析出依赖关系后,bunlder 需要将依赖关系中涉及的所有文件组合到一起,由于依赖代码的执行是有先后顺序以及会引用模块内部不同的内容,不能简单地将代码拼接到一起。webpack 会利用 JavaScript Function 的特性提供一些代码来将各个模块整合到一起,即是将每一个模块包装成一个 JS Function,提供一个引用依赖模块的方法,如下面例子中的 __webpack__require__,这样做,既可以避免变量相互干扰,又能够有效控制执行顺序,简单的代码例子如下:
// 将各个依赖模块的代码用 modules 的方式组织起来打包成一个文件// entry.jsmodules['./entry.js'] = function() {const { bar } = __webpack__require__('./bar.js')}// bar.jsmodules['./bar.js'] = function() {const foo = __webpack__require__('./foo.js')};// foo.jsmodules['./foo.js'] = function() {// ...}// 已经执行的代码模块结果会保存在这里const installedModules = {}function __webpack__require__(id) {// ...// 如果 installedModules 中有就直接获取// 没有的话从 modules 中获取 function 然后执行,将结果缓存在 installedModules 中然后返回结果}
我们在介绍 bundler 的基础流程时,把各个部分的实现细节简化了,这有利于我们从整体的角度去看清楚整个轮廓,至于某一部分的具体实现,例如解析代码依赖,模块依赖关系管理,胶水代码的生成等,深入细节的话会比较复杂,以后再对其专题分析。
2.webpack 的结构
webpack 需要高扩展性,在插件实现方面,webpack 利用了 tapable 库来协助实现对于整个构建流程各个步骤的控制。在基于 tapable 库定义主要构建流程后,并使用 tapable 库添加了各类的钩子方法来拓展 webpack,同时对外提供了相对强大的扩展性,即 plugin 的机制。
下面是 webpack 运行过程中的几个重要概念:
- Compiler
webpack 的支柱引擎,实例化时定义 webpack 构建主要流程,同时创建构建时使用的核心对象 compilation; - Compilation
由 Compiler 实例化,存储构建过程中各流程使用到的数据,用于控制这些数据的变化; - Chunk
即用于表示 chunk 的类,对于构建时需要的 chunk 对象由 Compilation 创建后保存管理; - Module
用于表示代码模块的类,衍生出很多子类用于处理不同的情况,关于代码模块的所有信息都会存在 Module 实例中,例如dependencies记录代码模块的依赖等; - Parser
基于 acorn 来分析 AST 语法树,解析出代码模块的依赖; - Dependency
解析时用于保存代码模块对应的依赖使用的对象; - Template
生成最终代码要使用到的代码模板;官方对于 Compiler 和 Compilation 的定义是: compiler 对象代表了完整的 webpack 环境配置。这个对象在启动 webpack 时被一次性建立,并配置好所有可操作的设置,包括 options,loader 和 plugin。当在 webpack 环境中应用一个插件时,插件将收到此 compiler 对象的引用。可以使用它来访问 webpack 的主环境。 compilation 对象代表了一次资源版本构建。当运行 webpack 开发环境中间件时,每当检测到一个文件变化,就会创建一个新的 compilation,从而生成一组新的编译资源。一个 compilation 对象表现了当前的模块资源、编译生成资源、变化的文件、以及被跟踪依赖的状态信息。compilation 对象也提供了很多关键步骤的回调,以供插件做自定义处理时选择使用。
下面是 webpack 内部工作流程中比较重要的几个部分:
1.创建 Compiler ->2.调用 compiler.run 开始构建 ->3.创建 Compilation ->4.基于配置开始创建 Chunk ->5.使用 Parser 从 Chunk 开始解析依赖 ->6.使用 Module 和 Dependency 管理代码模块相互关系 ->7.使用 Template 基于 Compilation 的数据生成结果代码
上述只是大概流程,实际流程细节相对复杂,一方面是技术实现的细节有一定复杂度,另一方面是实现的功能逻辑上也有一定复杂度,深入介绍的话,篇幅会很长,并且可能效果不理想,当我们还没到了要去实现具体功能的时候,无须关注那么具体的实现细节,只需要站在更高的层面去分析整体的流程。更细节的部分将在 Node篇 进一步探讨。
从源码中探索 webpack
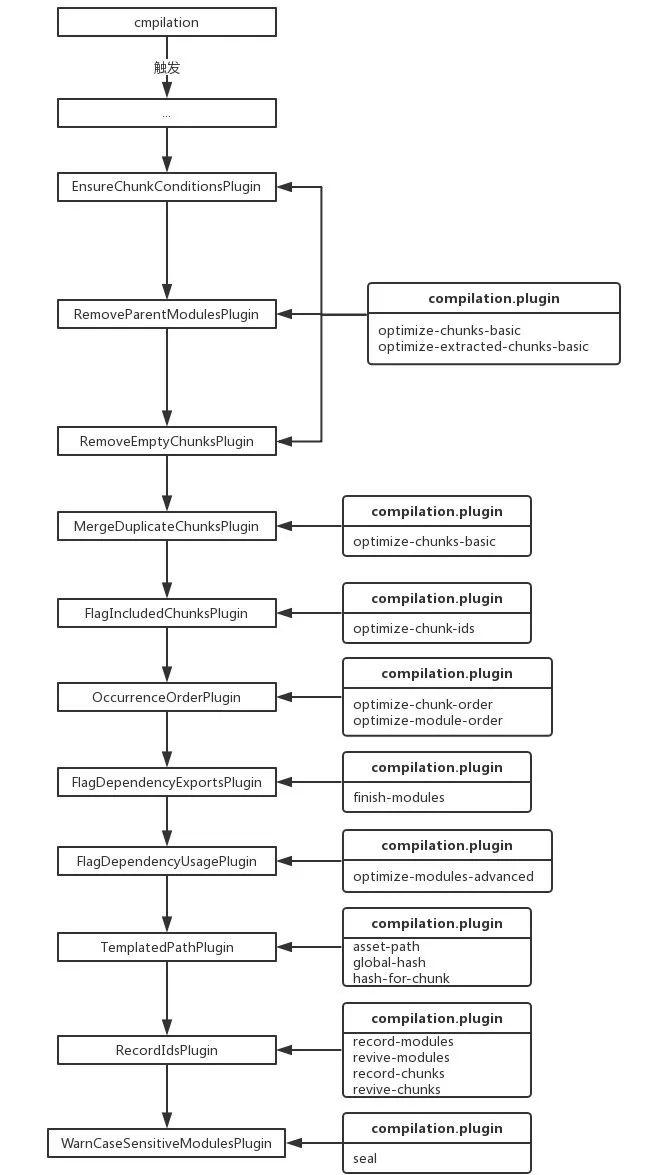
webpack 主要的构建处理方法都在 Compilation 中,按照官网的说法,Compilation 模块会被 Compiler 用来创建新的编译(或新的构建)。compilation 实例能够访问所有的模块和它们的依赖(大部分是循环依赖)。它会对应用程序的依赖图中所有模块进行字面上的编译(literal compilation)。在编译阶段,模块会被加载(loaded)、封存(sealed)、优化(optimized)、分块(chunked)、哈希(hashed)和重新创建(restored),下面仅对下面几个个关键部分来探讨一下。
1.Tapable
webpack4重写了Tapable, 是webpack的插件组织的核心。它提供给各个插件钩子,在事件触发时执行这些挂载的方法。webapck的插件里必须有apply()方法,当其被调用的时候webpack将钩子上的方法挂载到各个事件下面有点像nodejs里EventEmitter的$on
class Car {constructor() {this.hooks = {accelerate: new SyncHook(["newSpeed"]),brake: new SyncHook(),calculateRoutes: new AsyncParallelHook(["source", "target", "routesList"])};},setSpeed(newSpeed) {this.hooks.accelerate.call(newSpeed);}}
如上代码所示先是在实例化的过程中注册了三个钩子函数,在实例上调用方法时触发钩子函数。
2.Compiler
最高层的实例,初始化配置,提供全局性的钩子比如done, compilation。其他的Tapable实例需要通过其访问,如
compiler.hooks.compilation.tap("myFirstWebpackPlugin",(compilation, params) => {compilation.hooks.seal.tap()});
3.addEntry 和 _addModuleChain
addEntry 这个方法顾名思义,用于把配置的入口加入到构建的任务中去,当解析好 webpack 配置,准备好开始构建时,便会执行 addEntry 方法,而 addEntry 会调用 _addModuleChain 来为入口文件(入口文件这个时候等同于第一个依赖)创建一个对应的 Module 实例。_addModuleChain 方法会根据入口文件这第一个依赖的类型创建一个 moduleFactory,然后再使用这个 moduleFactory 给入口文件创建一个 Module 实例,这个 Module 实例用来管理后续这个入口构建的相关数据信息,关于 Module 类的具体实现可以参考这个源码:lib/Module.js,这个是个基础类,大部分我们构建时使用的代码模块的 Module 实例是 lib/NormalModule.js 这个类创建的。
我们介绍 addEntry 主要是为了寻找整个构建的起点,让这一切有迹可循,后续的深入可以从这个点出发。
4.buildModule
当一个 Module 实例被创建后,比较重要的一步是执行 compilation.buildModule 这个方法,这个方法主要会调用 Module 实例的 build 方法,这个方法主要就是创建 Module 实例需要的一些东西,对我们梳理流程来说,这里边最重要的部分就是调用自身的 runLoaders 方法。runLoaders 这个方法是 webpack 依赖的这个类库实现的:loader-runner,这个方法也比较容易理解,就是执行对应的 loaders,将代码源码内容一一交由配置中指定的 loader 处理后,再把处理的结果保存起来。
上面提到的 Module 实例的 build 方法在执行完对应的 loader,处理完模块代码自身的转换后,还有相当重要的一步是调用 Parser 的实例来解析自身依赖的模块,解析后的结果存放在 module.dependencies 中,首先保存的是依赖的路径,后续会经由 compilation.processModuleDependencies 方法,再来处理各个依赖模块,递归地去建立整个依赖关系树。
5.Compilation 的钩子
由Compiler创建,整个构建就在这里完成,进行依赖图构建,优化资源,渲染出runtime时的代码等。下面的4个实例都是发生在这个阶段。webpack 会使用 tapable 库给整个流程的各个步骤拓展钩子方法,便于特定的环节执行时触发相应的事件,注册的事件函数便可以调整构建时的上下文数据,或者做额外的处理工作,这就是 webpack 的 plugin 机制。在 webpack 执行入口处 lib/webpack.js 有这么一段代码:
if (options.plugins && Array.isArray(options.plugins)) {for (const plugin of options.plugins) {plugin.apply(compiler); // 调用每一个 plugin 的 apply 方法,把 compiler 实例传递过去}}
plugin 的 apply 方法就是用来给 compiler 实例注册事件钩子函数的,而 compiler 的一些事件钩子中可以获得 compilation 实例的引用,通过引用又可以给 compilation 实例注册事件函数,以此类推,便可以将 plugin 的能力覆盖到整个 webpack 构建过程。
6.Resolver
当你请求一个模块的时候,你将模块名或者相对地址发给模块解析器,它会去解析出绝对地址去寻找那个模块,看是否存在,如果存在则返回相应的模块信息,包括上下文等。这里的请求可以类似网络请求一样携带上查询参数之类的,Resolver将会返回额外信息。webpack4里将Resolver这个实例抽出来单独发了一个包enhanced-resolve, 抽象出来可以便于用户实现自己的Resolver。
7.ModuleFactory
模块工厂就是负责构造模块的实例,介绍两种NormalModuleFactory和ContextModuleFactory。两者不同的地方在于后者用于解析动态import(),模块工厂主要是用于将Resolver解析成功的请求里的源码从文件中拿出,在内存中创建一个模块对象(NormalModule)。
8.Parser
Parser主要用于将代码解析成AST抽象语法树.可以在ast查看代码转换成AST后的样子。webpack默认采用acorn解析器,babel是babylon。Parser将ModuleFactory返回的对象里的代码字符串转换成AST后进行解析,发现import或者require或者define类似模块引用时会将这些引用信息也就是依赖添加到当前模块的对象里,这样每个模块对象里不但有自己模块的信息还包含它的依赖信息。webpack会在不仅仅会在模块声明处触发事件,它甚至会在解析到变量时也触发事件。如下在webpack/lib/Parser.js里可以看到如下三个钩子函数:
varDeclaration: new HookMap(() => new SyncBailHook(["declaration"])),varDeclarationLet: new HookMap(() => new SyncBailHook(["declaration"])),varDeclarationConst: new HookMap(() => new SyncBailHook(["declaration"])),
Template负责生成运行时的代码
// 源码// index.jsvar multiply = require('./multiply')var sum = (a,b)=>{return a+b;}module.exports = sum;// multiply.jsmodule.exports = (a, b) => a*b// 生成的runtime[/* 0 *//***/ (function(module, exports, __webpack_require__) {var multiply = __webpack_require__(1)var sum = (a,b)=>{return a+b;}module.exports = sum;/***/ }),/* 1 *//***/ (function(module, exports) {module.exports = (a, b) => a*b/***/ })];
如上面代码所示,里面包含三个模板,分别负责chunk、module、dependency。chunk是包含多个模块的数组,就是外面数组的形式;module就是里面用立即执行函数包围的部分;dependency就是将原先import,require等引用模块部分转换成 webpack_require。
优化webpack构建速度
刚刚前面我们了解到了 webpack 大致工作流程,在实际工作业务里,我们的前端项目会随着时间推移和业务发展,经过不断的迭代重构,页面可能会越来越多,或者功能和业务代码会越来越多,又或者依赖的外部类库会多而复杂,这个时候原本不足为道的 webpack 构建时间消耗就会慢慢地进入我们的视野。
构建消耗的时间变长了,如果是使用 CI 服务来做构建,大部分情况下我们无须等待,其实影响不大。但是本地的 webpack 开发环境服务启动时的速度和我们日常开发工作息息相关,在一些性能不是特别突出的设备上(例如便携式笔记本等等),启动时的长时间等待可能会让你越来越受不了。
试想一下,如果你使用 webpack build 的时长可以达到十多分钟左右,这种场景下,就算用 CI 服务,在遇见需要紧急发布修复问题时,也会让人很抓狂。所以不仅要会使用 webpack,还需要掌握如何优化 webpack 的构建性能。
1.让 webpack 少干点活
提升 webpack 构建速度本质上就是想办法让 webpack 少干点活,活少了速度自然快了,尽量避免 webpack 去做一些不必要的事情。
2.减少 resolve 的解析
在前边第三小节我们详细介绍了 webpack 的 resolve 配置,如果我们可以精简 resolve 配置,让 webpack 在查询模块路径时尽可能快速地定位到需要的模块,不做额外的查询工作,那么 webpack 的构建速度也会快一些,下面举个例子,介绍如何在 resolve 这一块做优化:
resolve: {modules: [path.resolve(__dirname, 'node_modules'), // 使用绝对路径指定 node_modules,不做过多查询],// 删除不必要的后缀自动补全,少了文件后缀的自动匹配,即减少了文件路径查询的工作// 其他文件可以在编码时指定后缀,如 import('./index.scss')extensions: [".js"],// 避免新增默认文件,编码时使用详细的文件路径,代码会更容易解读,也有益于提高构建速度mainFiles: ['index'],},
上述是可以从配置 resolve 下手提升 webpack 构建速度的配置例子。
我们在编码时,如果是使用我们自己本地的代码模块,尽可能编写完整的路径,避免使用目录名,如:import './lib/slider/index.js',这样的代码既清晰易懂,webpack 也不用去多次查询来确定使用哪个文件,一步到位。
3.把 loader 应用的文件范围缩小
我们在使用 loader 的时候,尽可能把 loader 应用的文件范围缩小,只在最少数必须的代码模块中去使用必要的 loader,例如 node_modules 目录下的其他依赖类库文件,基本就是直接编译好可用的代码,无须再经过 loader 处理了:
rules: [{test: /.jsx?/,include: [path.resolve(__dirname, 'src'),// 限定只在 src 目录下的 js/jsx 文件需要经 babel-loader 处理// 通常我们需要 loader 处理的文件都是存放在 src 目录],use: 'babel-loader',},// ...],
如上边这个例子,如果没有配置 include,所有的外部依赖模块都经过 Babel 处理的话,构建速度也是会收很大影响的。
4.减少 plugin 的消耗
webpack 的 plugin 会在构建的过程中加入其它的工作步骤,如果可以的话,适当地移除掉一些没有必要的 plugin。
这里再提一下 webpack 4.x 的 mode,区分 mode 会让 webpack 的构建更加有针对性,更加高效。例如当 mode 为 development 时,webpack 会避免使用一些提高应用代码加载性能的配置项,如 UglifyJsPlugin,ExtractTextPlugin 等,这样可以更快地启动开发环境的服务,而当 mode 为 production 时,webpack 会避免使用一些便于 debug 的配置,来提升构建时的速度,例如极其消耗性能的 Source Maps 支持。
5.换种方式处理图片
我们在前边的小节提到图片可以使用 webpack 的 image-webpack-loader 来压缩图片,在对 webpack 构建性能要求不高的时候,这样是一种很简便的处理方式,但是要考虑提高 webpack 构建速度时,这一块的处理就得重新考虑一下了,思考一下是否有必要在 webpack 每次构建时都处理一次图片压缩。
这里介绍一种解决思路,我们可以直接使用 imagemin 来做图片压缩,编写简单的命令即可。然后使用 pre-commit 这个类库来配置对应的命令,使其在 git commit 的时候触发,并且将要提交的文件替换为压缩后的文件。
这样提交到代码仓库的图片就已经是压缩好的了,以后在项目中再次使用到的这些图片就无需再进行压缩处理了,image-webpack-loader 也就没有必要了。
6.使用 DLLPlugin
DLLPlugin 是 webpack 官方提供的一个插件,也是用来分离代码的,和 optimization.splitChunks(3.x 版本的是 CommonsChunkPlugin)有异曲同工之妙,之所以把 DLLPlugin 放到 webpack 构建性能优化这一部分,是因为它的配置相对繁琐,如果项目不涉及性能优化这一块,基本上使用 optimization.splitChunks 即可。
我们来看一下 DLLPlugin 如何使用,使用这个插件时需要额外的一个构建配置,用来打包公共的那一部分代码,举个例子,假设这个额外配置是 webpack.dll.config.js:
module.exports = {name: 'vendor',entry: ['lodash'], // 这个例子我们打包 lodash 作为公共类库output: {path: path.resolve(__dirname, "dist"),filename: "vendor.js",library: "vendor_[hash]" // 打包后对外暴露的类库名称},plugins: [new webpack.DllPlugin({name: 'vendor_[hash]',path: path.resolve(__dirname, "dist/manifest.json"), // 使用 DLLPlugin 在打包的时候生成一个 manifest 文件})],}
然后就是我们正常的应用构建配置,在那个的基础上添加两个一个新的 webpack.DllReferencePlugin 配置:
module.exports = {plugins: [new webpack.DllReferencePlugin({manifest: path.resolve(__dirname, 'dist/manifest.json'),// 指定需要用到的 manifest 文件,// webpack 会根据这个 manifest 文件的信息,分析出哪些模块无需打包,直接从另外的文件暴露出来的内容中获取}),],}
在构建的时候,我们需要优先使用 webpack.dll.config.js 来打包,如 webpack -c webpack.dll.config.js --mode production,构建后生成公共代码模块的文件 vendor.js 和 manifest.json,然后再进行应用代码的构建。
你会发现构建结果的应用代码中不包含 lodash 的代码内容,这一部分代码内容会放在 vendor.js 这个文件中,而你的应用要正常使用的话,需要在 HTML 文件中按顺序引用这两个代码文件,如:
<script src="vendor.js"></script><script src="main.js"></script>
其实作用和 optimization.splitChunks 很相似,但是有个区别,DLLPlugin 构建出来的内容无需每次都重新构建,后续应用代码部分变更时,你不用再执行配置为 webpack.dll.config.js 这一部分的构建,沿用原本的构建结果即可,所以相比 optimization.splitChunks,使用 DLLPlugin 时,构建速度是会有显著提高的。
但是很显然,DLLPlugin 的配置要麻烦得多,并且需要关心你公共部分代码的变化,当你升级 lodash(即你的公共部分代码的内容变更)时,要重新去执行 webpack.dll.config.js 这一部分的构建,不然沿用的依旧是旧的构建结果,使用上并不如 optimization.splitChunks 来得方便。这是一种取舍,根据项目的实际情况采用合适的做法。
还有一点需要注意的是,html-webpack-plugin 并不会自动处理 DLLPlugin 分离出来的那个公共代码文件,我们需要自己处理这一部分的内容,可以考虑使用 add-asset-html-webpack-plugin,关于这一个的使用就不讲解了,详细参考官方的说明文档:使用 add-asset-html-webpack-plugin。
webpack 4.x 的构建性能
从官方发布的 webpack 4.0 更新日志来看,webpack 4.0 版本做了很多关于提升构建性能的工作,我觉得比较重要的改进有这么几个:
- AST 可以直接从 loader 直接传递给 webpack,避免额外的解析,对这一个优化细节有兴趣的可以查看这个 PR。
- 使用速度更快的 md4 作为默认的 hash 方法,对于大型项目来说,文件一多,需要 hash 处理的内容就多,webpack 的 hash 处理优化对整体的构建速度提升应该还是有一定的效果的。
- Node 语言层面的优化,如用
for of替换forEach,用Map和Set替换普通的对象字面量等等,这一部分就不展开讲了,有兴趣的同学可以去 webpack 的 PRs 寻找更多的内容。 - 默认开启 uglifyjs-webpack-plugin 的
cache和parallel,即缓存和并行处理,这样能大大提高 production mode 下压缩代码的速度。
除此之外,还有比较琐碎的一些内容,可以查阅:webpack release 4.0,留意 performance 关键词。
很显然,webpack 的开发者们越来越关心 webpack 构建性能的问题,有一个关于 webpack 4.x 和 3.x 构建性能的简单对比:
6 entries, dev mode, source maps off, using a bunch of loaders and plugins. dat speed ⚡️
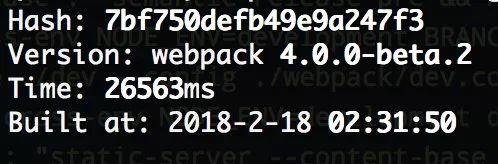 speed webpack of 4.x
speed webpack of 4.x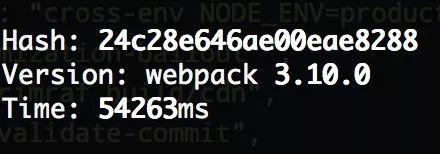 speed webpack of 3.x
speed webpack of 3.x
从这个对比的例子上看,4.x 的构建性能对比 3.x 是有很显著的提高,而 webpack 官方后续计划加入多核运算,持久化缓存等特性来进一步提升性能所以,及时更新 webpack 版本,也是提升构建性能的一个有效方式。
webpack5新特性
1.编译器的优化
如果大家读过Webpack的源码一定知道Compiler的重要性,在Webpack中充斥着大量的钩子和触发事件。
在新的版本中,编译器在使用完毕后应该被关闭,因为它们在进入或退出空闲状态时,拥有这些状态的 hook。 插件可以用这些 hook 来执行不太重要的工作(比如:持久性缓存把缓存慢慢地存储到磁盘上)。同时插件的作者应该预见到某些用户可能会忘记关闭编译器,所以 当编译器关闭所有剩下的工作时应尽快完成。 然后回调将会通知已彻底完成。当你升级到 v5 时,请确保在完成工作后使用 Node.js API 调用 Compiler.close。
2.Node.js polyfills 自动被移除
过去,Webpack 4版本附带了大多数 Node.js 核心模块的 polyfills,一旦前端使用了任何核心模块,这些模块就会自动应用,但是其实有些是不必要的。 V5中的尝试是自动停止 polyfilling 这些核心模块,并侧重于前端兼容的模块。当迁移到 v5时,最好尽可能使用前端兼容的模块,并尽可能手动添加核心模块的polyfills。 Webpack鼓励大家多提交自己的意见,因为这个更改可能会也可能不会进入最终的 v5版本。
3.打包大小限制
在V4版本中默认情况下,仅能处理javascript的大小。
module.exports = {optimization: {splitChunks: {cacheGroups: {commons: {chunks: "all",name: "commons",minChunks: 1,minSize: "数值",maxSize: "数值"}}}}}
V5版本之后,更加自由化。
module.exports = {optimization: {splitChunks: {cacheGroups: {commons: {chunks: "all",name: "commons",}},//最小的文件大小 超过之后将不予打包minSize: {javascript: 0,style: 0,},//最大的文件 超过之后继续拆分maxSize: {javascript: 1, //故意写小的效果更明显style: 3000,}}}}
4.按需加载
以前当我们想在index.js内部 import(./async.js”).then(…)的时候,如果我们什么也不加。V4会默认对这些文件生成一堆0.js,1.js,2.js…是多么的整齐.所以我们需要使用
import(/ webpackChunkName: “name” / “module”) 才能化解这份尴尬。今天V5可以在开发模式中启用了一个新命名的块 id 算法,该算法提供块(以及文件名)可读的引用。 模块 ID 由其相对于上下文的路径确定。 块 ID 是由块的内容决定的,所以你不再需要使用Magic Comments。
//src文件夹index.jsimport("./async.js").then((_)=>{console.log(_.data);})console.log("Hello Webpack5")//src文件夹async.jsconst data = "异步数据,测试";export default data;
再次编译之后src_async_js.js 就躺在了dist里。如果这个时候去执行 npm run prod 会在dist里出现一个已数字开头的js文件。
总结
上面我们介绍了 webpack 打包的工资流程,以及优化 webpack 构建速度的一些方法:
- 减少
resolve的解析 - 减少 plugin 的消耗
- 换种方式处理图片
- 使用 DLLPlugin
- 积极更新 webpack 版本
当我们面对因项目过大而导致的构建性能问题时,我们也可以换个角度,思考在 webpack 之上的另外一些解决方案,不要过分依赖于 webpack。

若有收获,就点个赞吧
0 人点赞
