首先我们要知道Kafka本质上使用Java NIO的ByteBuffer来保存消息。
好处:ByteBuffer是紧凑的二进制字节结构,不浪费空间。
1.消息版本变迁
1.1V0版本
Kafka在0.10.0版本之前都是采用V0版本的消息格式
如下表格所示为V0版本的一条Record的组成及其含义:
| Record | -字段- | -含义- |
|---|---|---|
| Record head | CRC校验码 | 4个字节CRC校验码,校验范围为magic到value之间,用于确保消息再传输过程中不会被恶意篡改 |
| Record head | magic字段 | 单字节的版本号,V0 magic = 0 ,V1 magic =1 ,v2 magic =2 |
| Record head | attribute | 单个字节属性字段,目前仅仅使用后三位来表示消息传输的压缩类型。 0x00: 未启用压缩 ,0x01: GZIP ,0x02: Snappy ,0x03: LZ4 |
| Record head | key长度字段 | 4字节的消息key长度信息。若为指定key,默认值为-1 |
| Record body | key值 | 消息key,长度由key长度字段确定,如果为-1,则没有该消息字段 |
| Record head | value长度字段 | 4字节的消息长度,未指定 默认值为-1 |
| Record body | value字段 | 消息value 长度由value长度字段确定 -1,消息没有该字段 |
可以计算出V0版本的一条Record最少需要14B的存储空间
1.2 V1版本消息格式
V0版本消息格式弊端:
- 消息不存储时间的话,kafka定期删除消息日志的时候,只能依靠日志段文件的“最近修改时间”,但是这种方式事不安全的,一旦我们通过系统的命令操作了文件,并且更新了该日志文件的最近修改时间,kakfa就不能对其做成正确的判断了。
- 很多流处理框架都需要消息的保存时间以便对消息执行时间窗口等聚合操作。
因此V1版本的消息格式比V0版本的消息格式多了一个timestamp字段。
timestamp:8个字节,记录了消息的时间戳。时间戳有两种创建类型,由attribute的第四个bit位决定的。
- CreateTime (由Producer指定)
- LogAppendTime(由Broker指定)
MessageSet(V0,V1 未开启压缩)
V0版本和V1版本Kafka处理消息都是以MesssageSet为基础的,分为压缩和未压缩两种格式
未开启消息压缩的传输格式:V0版本和V1版本都是一样的只是差了一个时间戳的字段。
如图所示为未开启压缩 的消息在Messag Set 中的一条Log都是以 Log OVERHEAD + Record为基础的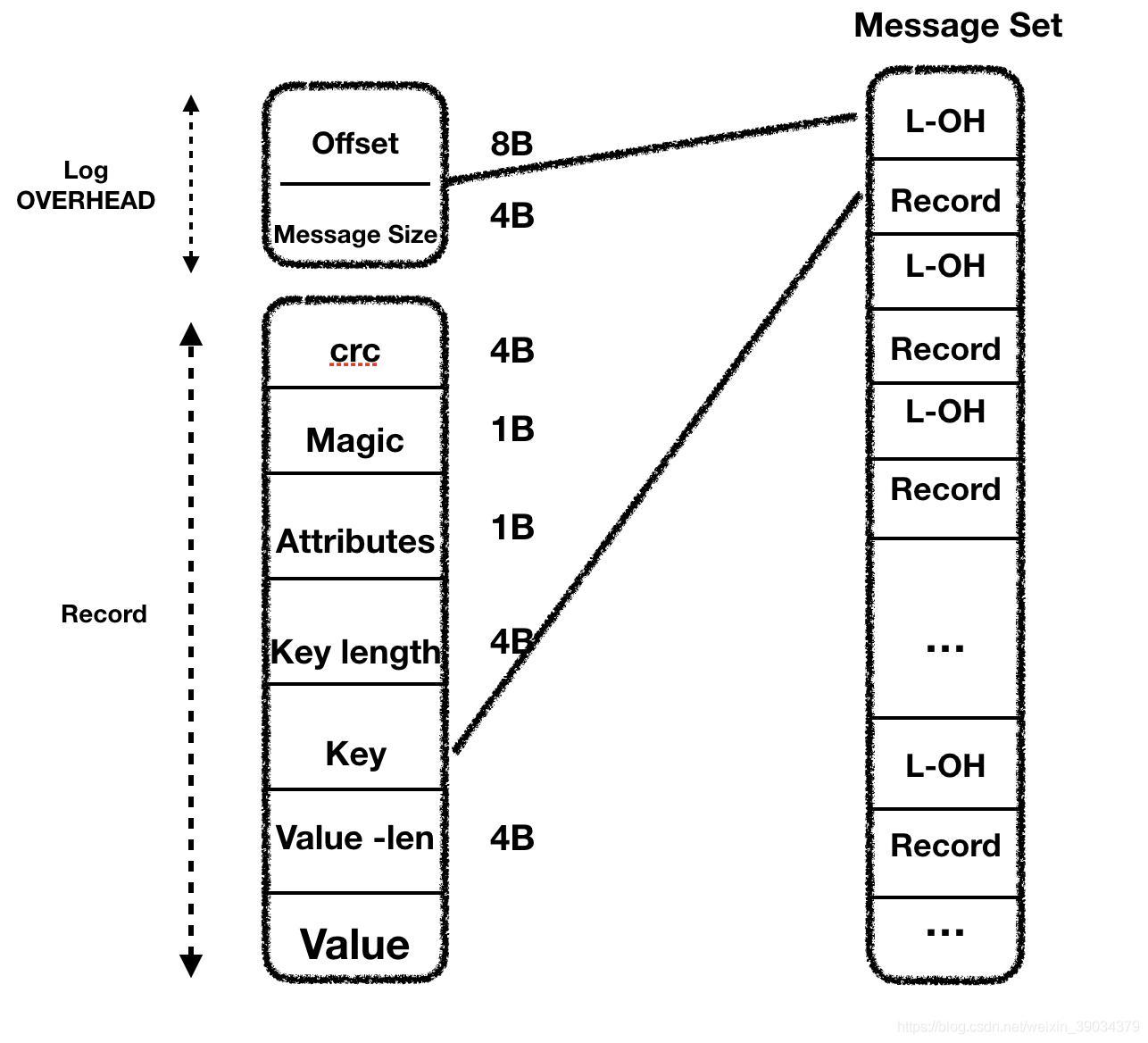
1.3 Message Set V0,V1 开启压缩
首先我们要知道 压缩是一Message Set 为单位进行压缩的。
压缩后的消息分为 Wrapper Message 和Inner Message ,Inner Message 作为Wrapper Message 的value字段存储,Inner Message 就是压缩后的Message Set。因为压缩后的key为null,所以就不做体现。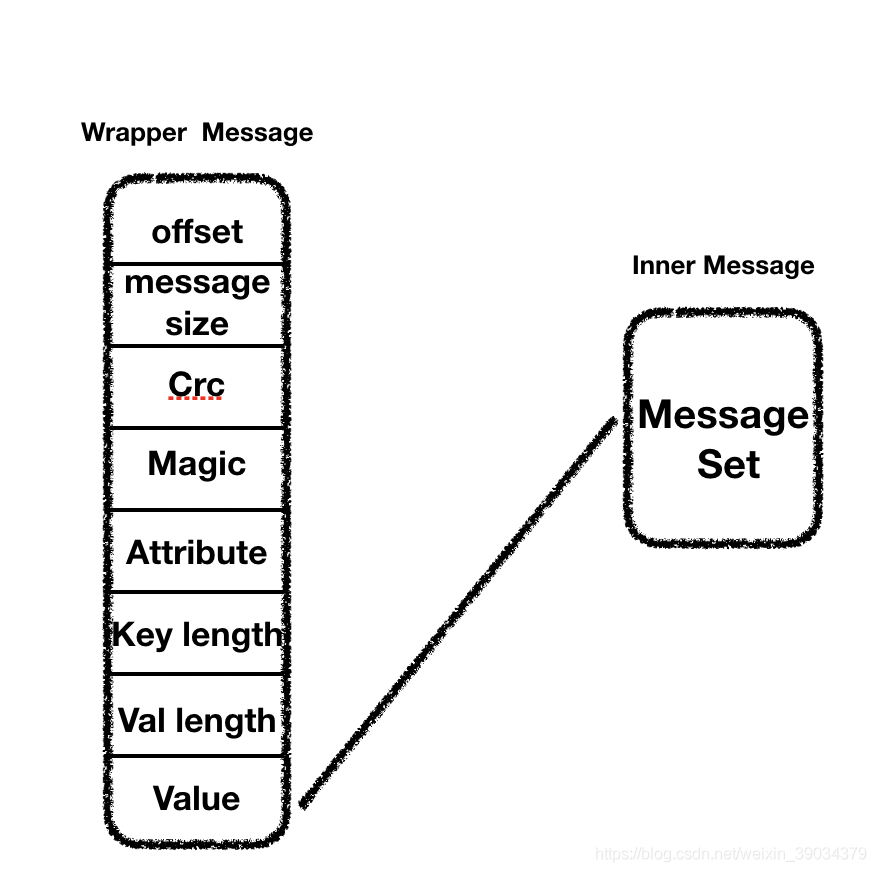
offset的对应关系如下下图所示,Wrapper Message offset 是消息集合的消息的绝对位移(absolute offset)AO,相对于Topc的整个分区而言的。内部消息的offset为消息的相对位移(Relative Offset)RO。
如何计算一条相对位移为(CURRENT_RO)的消息的绝对位移(AO_CURRENT):
RO_DIFF = CURRENT_RO - Last_INNER_Message_OFFSET
AO_CURRENT = AO_OF_WRAPPER_MESSAGE_OFFSET + RO_DIFF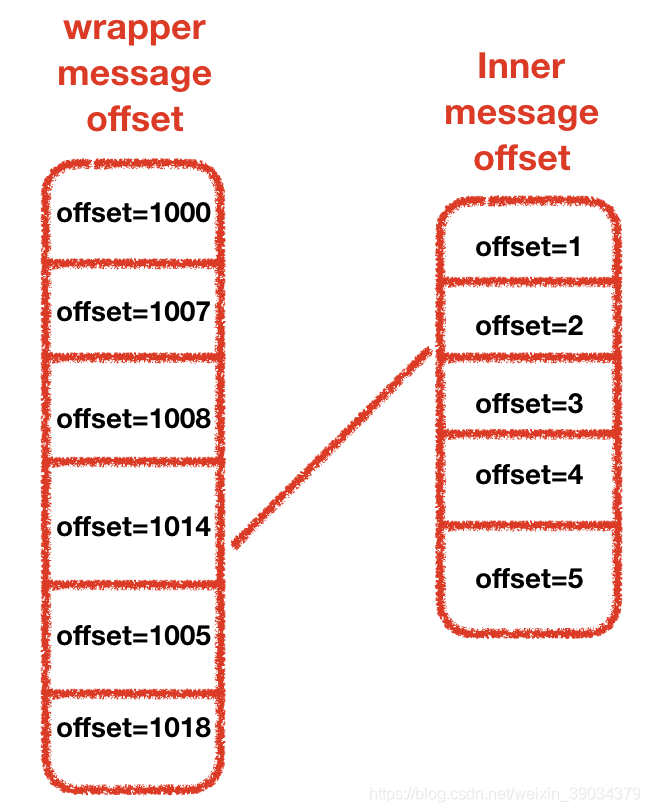
时间的车轮总是滚滚向前,随着时间的推移,旧版消息(V1)的弊端也一一体现出来,总体如下:
- 空间利用率不高
- key-lengh 和value-size 字段总是4byte,显得有些浪费,因为大部分场景来说,key和value的字段只用一个字节来存储都足矣,每条消息都浪费3个字节,试想每天发送十几亿条消息的kafka会浪费多少数据。
- 只保存最新的消息的位移
- 若启用压缩,offset字段就只会保存,最新的消息唯一,我们需要获得第一条消息的位移,就必须先解压缩,然后从后向前遍历获取offset的值
- 冗余的消息级CRC校验
- 每条消息都进行CRC校验显的有些多余
- 为保存消息的长度
- 需要用到消息长度的时候,都需要重新计算,而且每次计算为了防止对原始数据的破坏,都会使用的大量的副本,解序列化的效率很低。
因此Kafka在0.11.0.0对消息的格式进行了重构,诞生出了V2版本消息。
1.4 V2版本消息
V2版本对消息集合不再称为MessageSet 而改为了RecordBatch.
如下图所示为V2版本的消息集,和消息的构成,可以看到,V2版本的消息,提取了大量的公共元素到,提高了服用性,而且还是用了大量的可变长字段。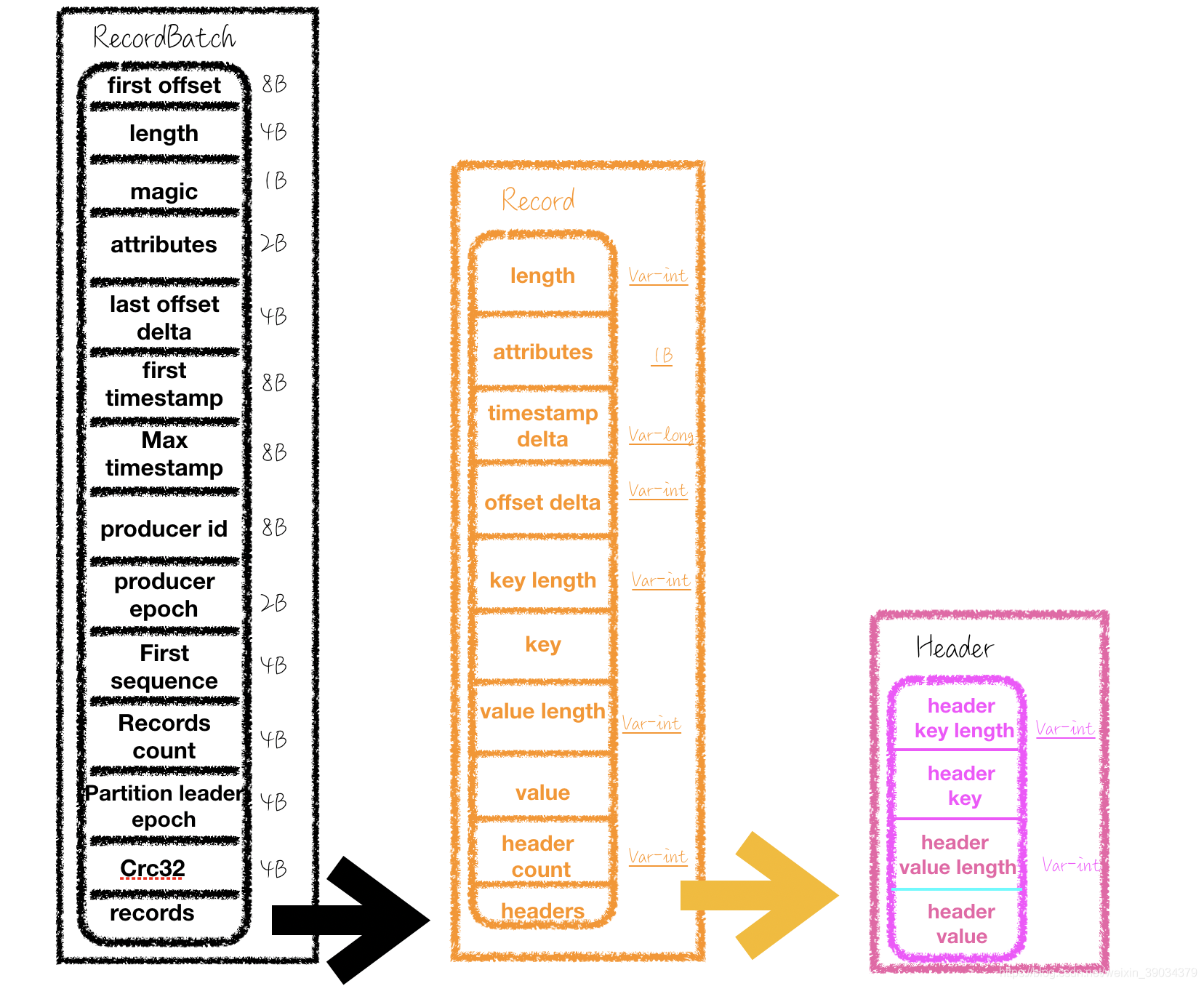
先分析一下Record的消息格式
| -名称- | -含义- | -字节数- |
|---|---|---|
| length | 消息总长度(每条) | 可变长字段 |
| attributes | 弃用(保留未来的格式扩展使用) | 1B |
| timestamp delta | 时间戳增量。通常一个时间戳会占据8个字节,这里保存的是由RecordBatch的起始时间戳的差值,明显占据更少的空间 | 可变长字段 |
| offset delta | 位移增量。保存与RecordBacth的起始位移的差值,同样可以节省占用字节数。 | 可变长字段 |
| headers | 为了做应用级别的扩展使用 |
RecordBatch格式:
| -名称- | -含义- | -字节数- |
|---|---|---|
| first offset | RecordBacth的起始位移,也就是第一条消息的位移 | 8B |
| length | 计算从magic字段开始到末尾的总长度 | 4B |
| partition leader epoch | leader的版本号,为了副本同步使用 | 4B |
| magic | 消息的版本号 | 1B |
| Attributes | 第三位压缩格式,第四位时间戳类型,第五位表示是否处于事务当中,0,非事务,1事务 第六位表示是否控制消息 | 2B |
| last offset delta | Record Batch 中最后一个 消息的位移与第一个位移的差值,主要用来Broker来保证RecordBacth中Record组装的准确性。 | 4B |
| first timestamp | RecordBatch中第一条消息的时间戳 | 8B |
| max timestamp | 最大时间戳,一般是最后一条消息的时间戳 | 8B |
| record count | 消息的个数 | 4B |
RecodBatch的其他属性都是用来支持事务和幂等性的这里不做具体的讲解。
可以计算出如果仅仅发送一条消息其实RecordBatch的大小反而增大了,但是10条100条呢?
2.Varints and ZigZag编码
Kafka参考了Protocol Buffer 而引入了变长整型(Varints)和ZigZag编码。
2.1 Varints
Varints 是用一个或多个字节来序列化一个整数的一种方法,数值越小,其占用的字节数就越少。
可变长字段又叫Base128 ,通常而言一个字节8位可以表示256位,就叫做Base256,而可变长字段只能表示128位,为什么呢,因为每个字节的最高位可变长字段又叫做msb(most significant bit),除最后一个字节外其余的最高位都是1,最后一个的最高位位0,用来判别后边的字节是否和当前字节一起来表示同一个整数。
拿300来举例子为300如何转变为一个可变长字段的。如下图所示:
如果是V0版本和V1版本的消息格式就是无脑的使用四个字节来表示300.而可变长度最终只需要两个字节可以。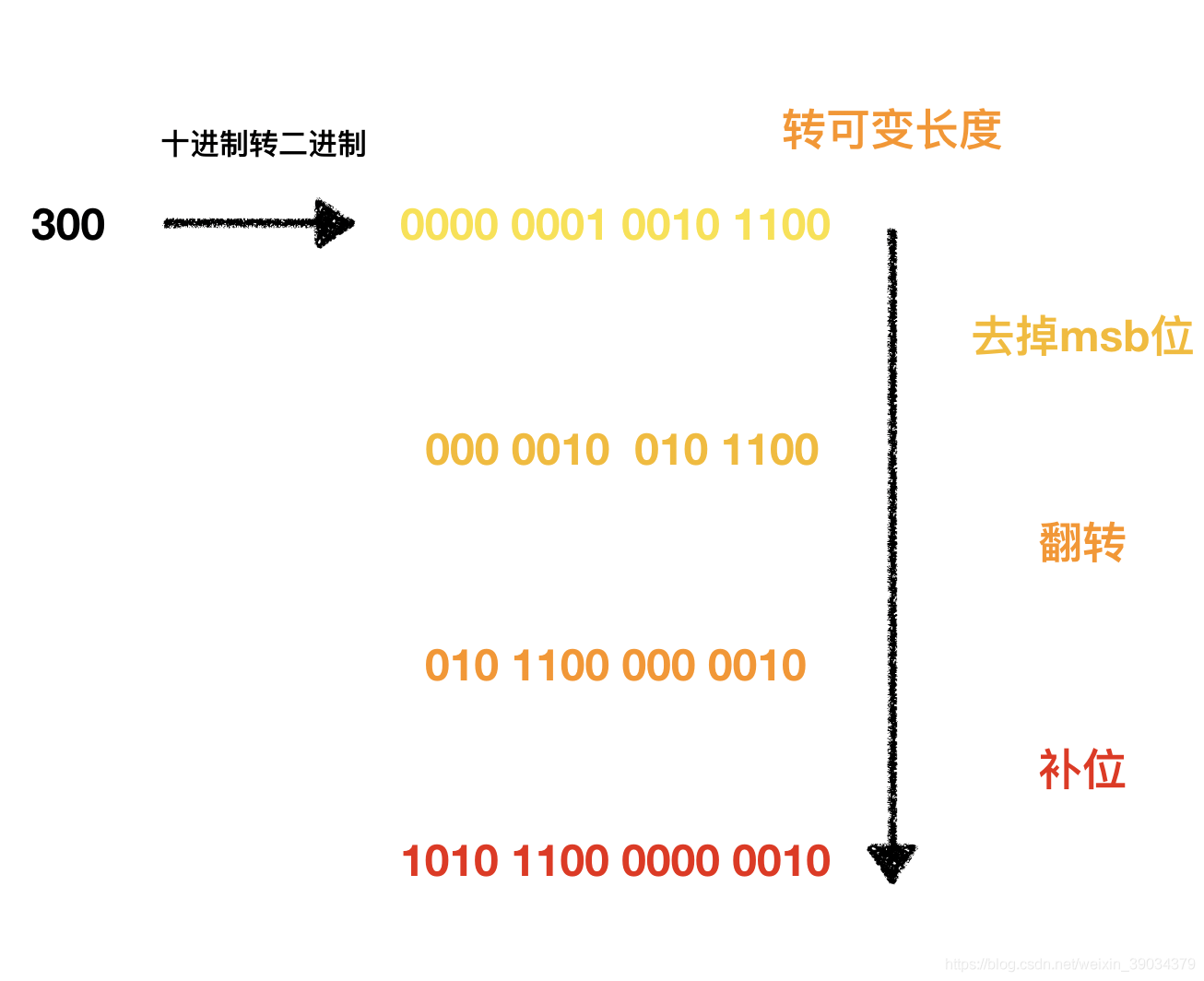
因为可变长字段在表示负数的时候字段长度会非常的长,拿int64来举例只要是负数都会统一使用十个字节来表示。针对于这个缺陷,Kafka又使用了ZigZag编码的方式来处理正负数的缺陷。
2.2 ZigZag编码
ZigZag是一种锯齿形(zig-zags)的方式来回穿梭正负整数。如下为ZigZag的编码方式:
| -编码前- | -编码后- |
|---|---|
| 0 | 0 |
| -1 | 1 |
| 1 | 2 |
| -2 | 2 |
| 2 | 4 |
int32公式:
(n << 1) ^ (n >> 31)
int64公式:
(n << 1) ^ (n >> 63)
异或总结:
AnyNum ^ 0 = AnyNum偶数 ^ 1 = 偶数 + 1奇数 ^ 1 = 奇数 - 1AnyNum ^ (-1) = -(AnyNum+1)
3.服务端存储方式
如图为消息存储在磁盘上的存储格式,其中/user/Kafka为你配置的文件路径
然后消息的存储是按照分区来区分的,假设当前Broker存储了TopciName位”Hello”分区位0的消息的内容。
topic-partitionCount 就是 “Hello-0” 就是一个文件夹的名称,然后LogSegment位消息存储的逻辑概念,真正存储的文件就是 .log日志文件(就是我们的RecordBacth组成的).index日志索引文件,.timeindex时间戳索引文件,和其他的文件等等。可以知道相同的topci不同的分区是在不同的文件夹下的,不同的topic和相同的分区数同样是在不同的文件夹下的。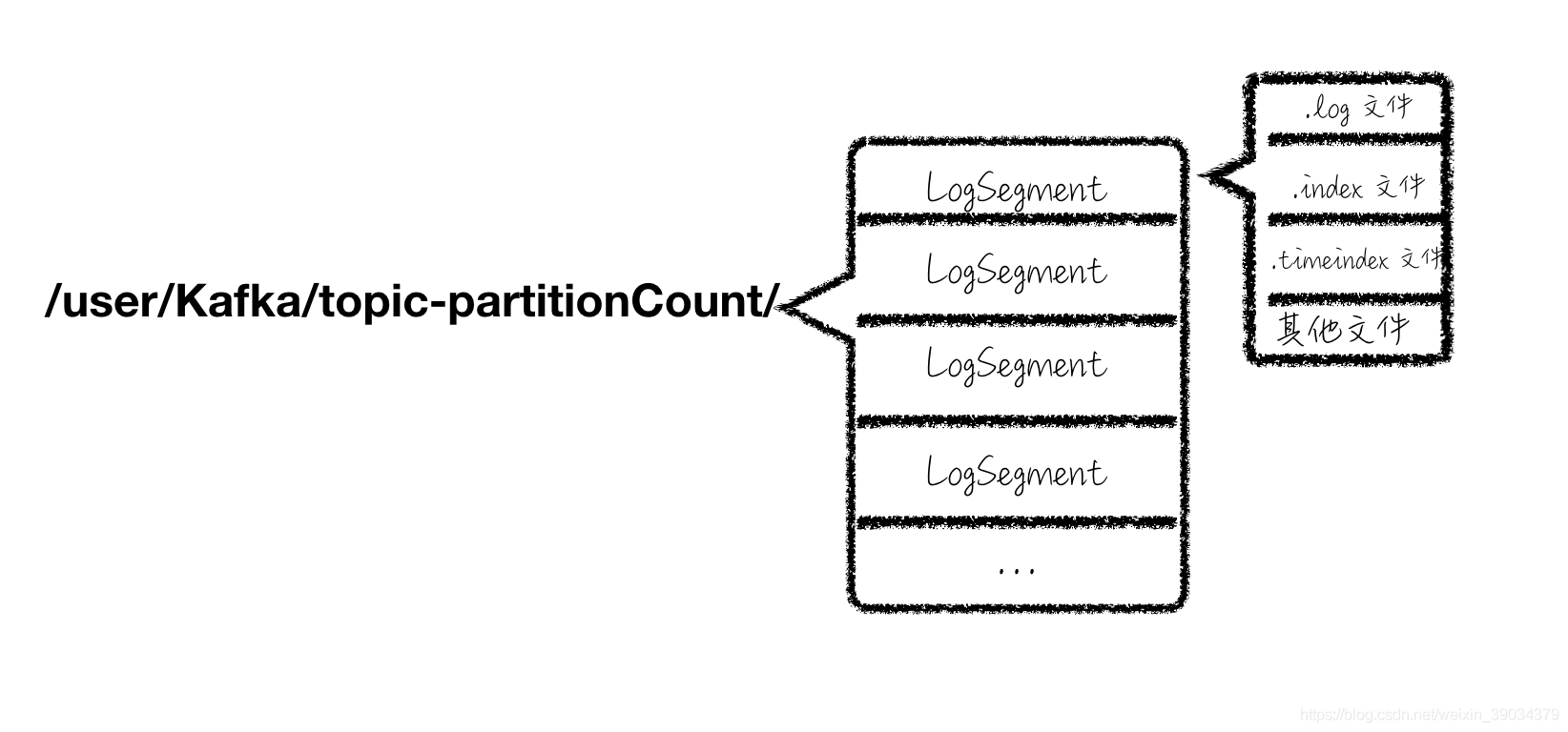
如下图所示位具体的数据存储格式:
3.1日志文件、偏移量索引、时间戳索引详解
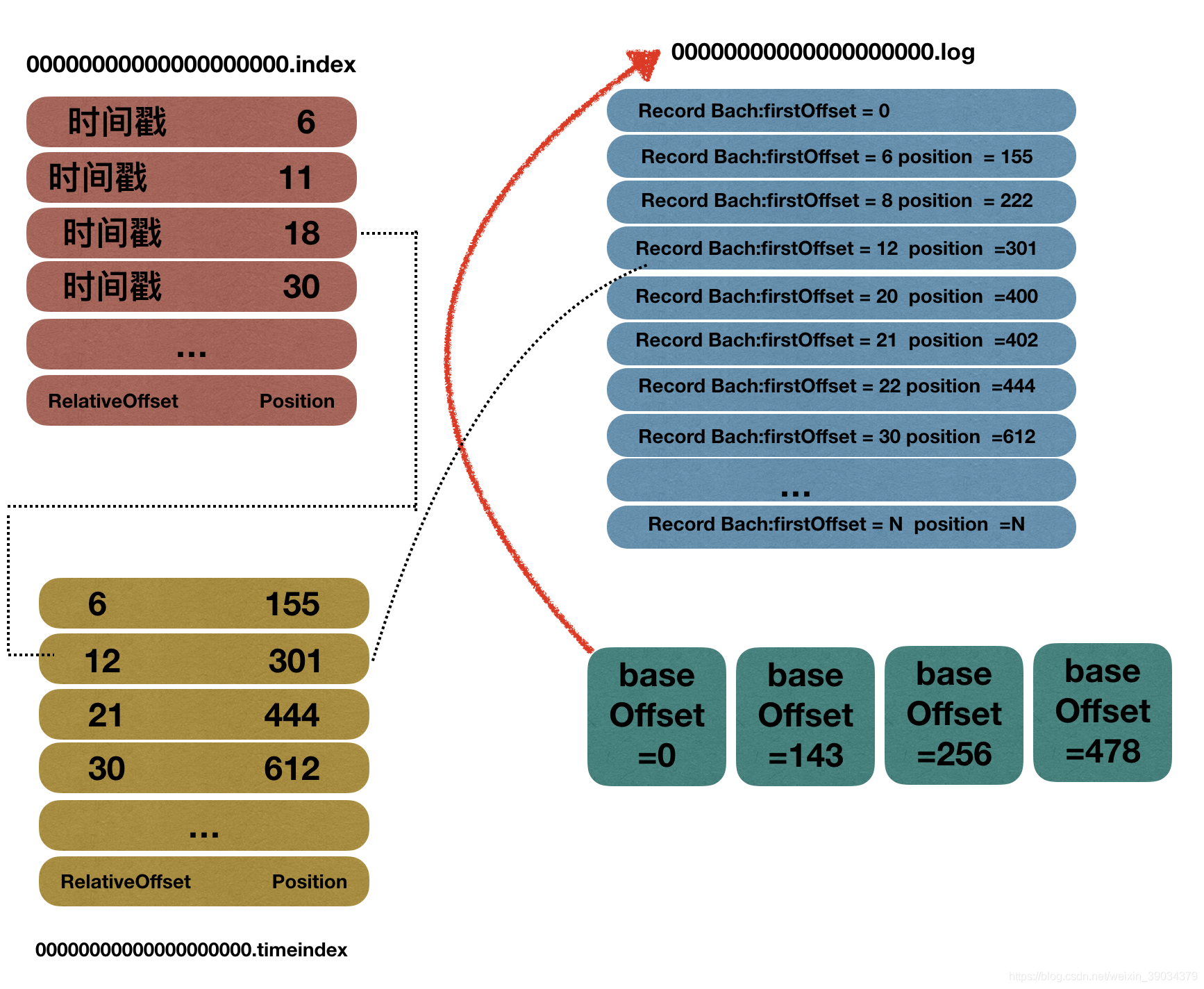
如下图所示,为一个baseOffset为0的log文件的详细存储格式。需要清楚一下几点:
- 文件的名称就是整个日志段的baseOffset其他的位用0补齐。
- 偏移量索引、时间戳索引都是稀疏索引,存储的是消息的相对位移,也就是相对于baseOffset的位移指,并不是每个RecordBatch都在索引文件中有存储,每当写入一定量的消息才会添加一条日志索引和时间戳索引。
- 时间戳索引不是和偏移量索引文件一一对应的。
3.2如何新增数据
源代码如下,做了详细的注释。
def append(largestOffset: Long, //新增消息的最大offsetlargestTimestamp: Long, //新增消息的额最大时间戳shallowOffsetOfMaxTimestamp: Long, //最大时间戳消息对应的位移 就是时间戳索引文件的offsetrecords: MemoryRecords): Unit = {//判断 是否存在写入的消息if (records.sizeInBytes > 0) {//int 类型val physicalPosition = log.sizeInBytes()//判断日志断是否为空if (physicalPosition == 0)//更新用于日志段切分的时间戳rollingBasedTimestamp = Some(largestTimestamp)//确定写入消息的索引是否在合理访问以内ensureOffsetInRange(largestOffset)// append the messages write records to the OS pageCacheval appendedBytes = log.append(records)// Update the in memory max timestamp and corresponding offset.if (largestTimestamp > maxTimestampSoFar) {maxTimestampSoFar = largestTimestampoffsetOfMaxTimestamp = shallowOffsetOfMaxTimestamp}// append an entry to the index【.index/.timeindex】 (if needed)if (bytesSinceLastIndexEntry > indexIntervalBytes) {offsetIndex.append(largestOffset, physicalPosition)timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestamp)bytesSinceLastIndexEntry = 0}bytesSinceLastIndexEntry += records.sizeInBytes}}
Kafka对日志有两种清除机制,有两种第一种就是条件清除包括a.基于时间的 b.基于BaseOffset的。第二种叫做Compact类似于java虚拟机的整理清楚算法。Kafka给我们提供了非常灵活的配置方案我们可以仅仅配置一种,也可以两种都配置,还可以基于Topic单独进行配置。非常灵活,这里对原理就不做详细的讲解了。

若有收获,就点个赞吧
0 人点赞
