在前面的文章中,我们探索了 iOS 类的底层原理,其中比较重要的四个属性,我们已经分析了其中的三个,现在我们开始分析第三个属性 cache_t,对于这个属性,我们可以学习到苹果对于缓存的设计与理解,同时也会接触到消息发送相关的知识。
我们在探索 iOS 底层的时候,尽量不要站在上帝视角去审视相应的技术点,我们应该尽量给自己多问出几个问题,然后尝试去解决每个问题,通过这样的探索,对提高我们阅读源码的能力是十分重要的。
1、 cache_t 基本结构
首先,我们还是再回过头来看看 OC 中类的结构
struct objc_class {Class isa;Class superclass;cache_t cache; // 方法缓存class_data_bits_t bits; // 具体的类信息class_rw_t *data() {return bits.data();}// 省略代码.....}
接着我们查看一下源码中 cache_t 的定义
struct cache_t {#if CACHE_MASK_STORAGE == CACHE_MASK_STORAGE_OUTLINEDexplicit_atomic<struct bucket_t *> _buckets;explicit_atomic<mask_t> _mask;#elif CACHE_MASK_STORAGE == CACHE_MASK_STORAGE_HIGH_16explicit_atomic<uintptr_t> _maskAndBuckets;mask_t _mask_unused;#if __LP64__uint16_t _flags;#endifuint16_t _occupied;// 省略代码.....}
struct bucket_t {// IMP-first is better for arm64e ptrauth and no worse for arm64.// SEL-first is better for armv7* and i386 and x86_64.#if __arm64__explicit_atomic<uintptr_t> _imp;explicit_atomic<SEL> _sel;#elseexplicit_atomic<SEL> _sel;explicit_atomic<uintptr_t> _imp;#endif// 省略代码.....}
所以从上面源代码的定义处,我们可以看出,bucket_t 其实缓存的是方法的实现 IMP。上面的苹果注释有一个有意思的地方,就是 IMP-first 和 SEL-first。
IMP-first is better for arm64e ptrauth and no worse for arm64.
IMP-first对arm64e的效果更好,对arm64不会有坏的影响。
SEL-first is better for armv7* and i386 and x86_64.
SEL-first适用于armv7*、i386和x86_64。
如果对于 SEL 和 IMP 不是很熟悉的同学可以去 objc4-781 源码中查看关于 method_t 的定义:
struct method_t {SEL name; // 方法选择器const char *types; // 方法类型字符串MethodListIMP imp; // 方法实现// 省略代码.....};
通过上面的源码,我们大致了解了 bucket_t 类型的结构,那么现在问题来了,类中的 cache 是在什么时候以什么样的方式来进行缓存的呢?
2、 LLDB 大法好
了解到 cache_t 和 bucket_t 的基本结构后,我们可以通过 LLDB 来打印验证一下:
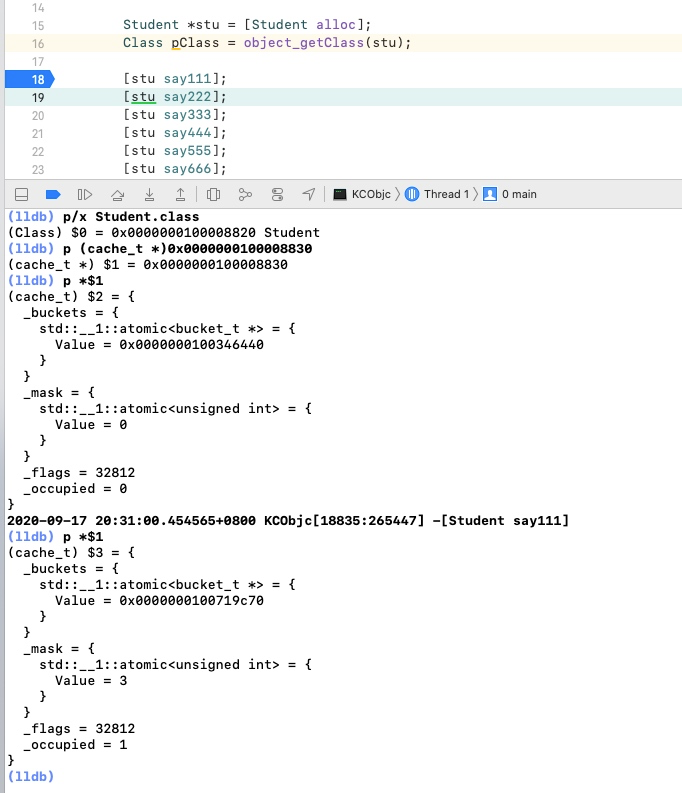
我们发现,断点在18行的时候,_occupied 和 _mask 的值还为0,但当我们走到19行的时候,_occupied 和 _mask 的值已经分别为1和3了,现在我们打印一下 _buckets 里面的内容看看

我们可以看到,打印到 buckets 的第一个元素的时候,我们的 say111 方法被缓存了,也就是说 _occupied 可能表示的是当前被缓存方法的个数。这里可能会有同学会疑惑,为什么 alloc 方法为什么没有被缓存呢?其实这是因为 alloc 是类方法,根据我们前面探索类底层原理的时候,类方法是存储在元类里面的,所以这里的类对象的缓存里面只会存储对象方法,我们接着下一步执行到20行
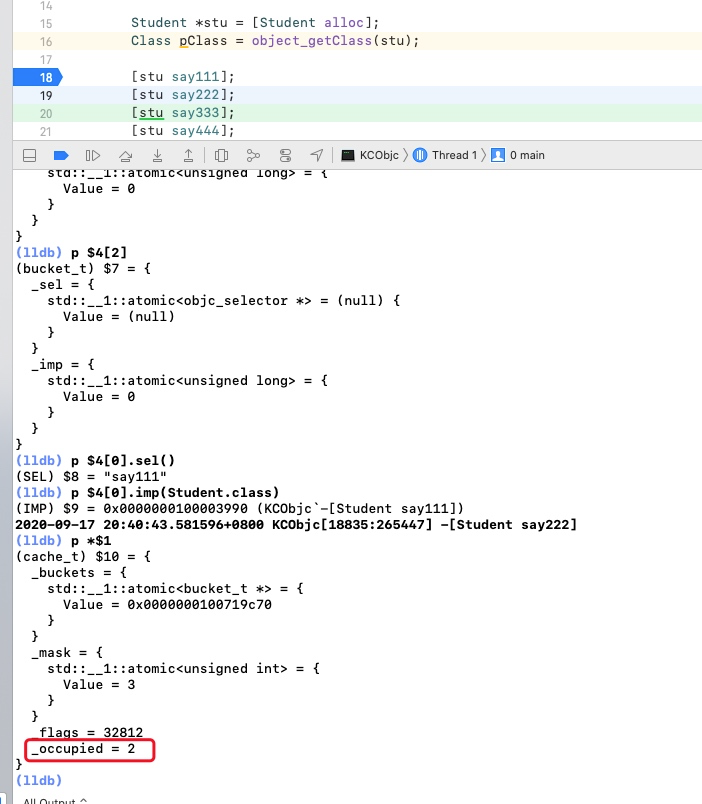
_occupied 的值又发送变化了,我们前面的猜想又得到进一步的验证,我们再往下执行一行
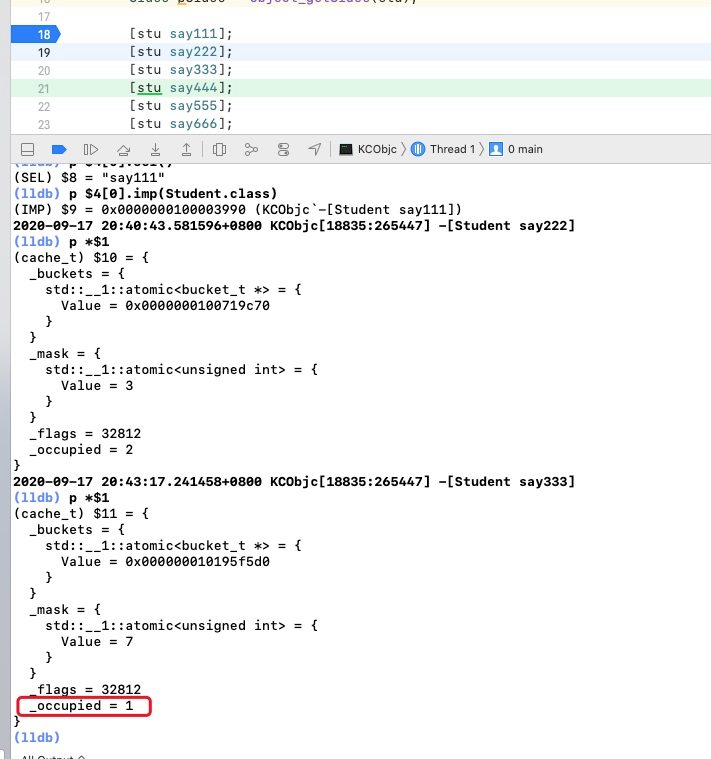
这时候,_occupied 的值居然变成1了,但是我们往上看一下,的值已经从3变成到7。我们往前回顾一下当前缓存里面缓存的方法
_occupied 的值 |
_mask 的值 |
缓存的方法 |
|---|---|---|
| 1 | 3 | Student 的 - say111 方法 |
| 2 | 3 | Student 的 - say222 方法 |
可以看到,当我们缓存第三个方法的时候缓存发送了变化,如果大家对散列表这种数据结构比较熟悉的话,相信已经看出端倪了。是的,这里其实是用到了 开放寻址法 来解决散列冲突的(哈希冲突)。
关于哈希冲突,可以借助鸽笼理论,即把 11 只鸽子放进 10 个抽屉里面,肯定会有一个抽屉里面有 2 只鸽子。是不是理解起来很简单? 如果还有不了解散列表原理的,推荐可以看一下这篇文章,这里就不详细展开分析了 什么是散列表?
通过上面的探索,我们已经了解到方法缓存使用的是哈希表存储,并且为了解决无法避免的哈希冲突使用的是开放寻址法,而开放寻址法必然要在合适的时机进行扩容,这个时机肯定不是会在数据已经装满的时候,我们可以进源码探索一下,我们先定位到 cache_t 的源码处
我们怎么去寻找 cache_t 的扩容算法呢,其实我们应该猜到,我们每次缓存方法的时候,_occupied 的值都会变化,所以我们从这方面入手,通过查找源码我们发现了下面这段函数
void cache_t::incrementOccupied(){_occupied++;}
然后我们 全局搜索 incrementOccupied() 函数调用的地方
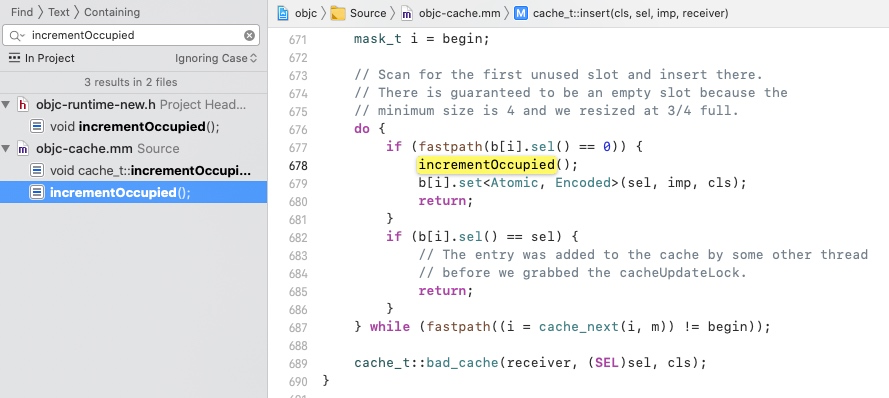
只找到了这一处的调用,我们查看一下这个是什么函数,通过函数名和里面的代码函数,我们可以基本确定,这就是我们想要查找的核心部分

然后我们来看看它里面的判断逻辑是怎样的,为了方便阅读,我们删减一部分无关紧要的代码和注释
void cache_t::insert(Class cls, SEL sel, IMP imp, id receiver){// 插入新的方法缓存,并且数量+1mask_t newOccupied = occupied() + 1;unsigned oldCapacity = capacity(), capacity = oldCapacity;// 如果还没有缓存过方法if (slowpath(isConstantEmptyCache())) {// 最初分配的容量4if (!capacity) capacity = INIT_CACHE_SIZE;// 创建和分配内存reallocate(oldCapacity, capacity, /* freeOld */false);}else if (fastpath(newOccupied + CACHE_END_MARKER <= capacity / 4 * 3)) {// 保证缓存表存的方法数量小于等于容量的3/4}else {// 如果超过容量的3/4,进入扩容,容量进行翻倍处理capacity = capacity ? capacity * 2 : INIT_CACHE_SIZE;// 不能超过最大值,最大值为 1 << 16if (capacity > MAX_CACHE_SIZE) {capacity = MAX_CACHE_SIZE;}// 超过容量之后,将之前缓存的方法全部清空reallocate(oldCapacity, capacity, true);}bucket_t *b = buckets();mask_t m = capacity - 1;mask_t begin = cache_hash(sel, m);// 通过 sel & mask 计算出 sel 该存放的位置 imask_t i = begin;// 如果计算出来的值没有缓存方法,则直接插入保存,否则如果已经有方法插入了,i--,即是如果被占用,往上走一格,还被占用继续往上走,因为规则限定了3/4,所以肯定能找到没有保存方法的位置。do {if (fastpath(b[i].sel() == 0)) {incrementOccupied();b[i].set<Atomic, Encoded>(sel, imp, cls);return;}// 如果是其他线程已经把方法添加到这里了,那就直接退出循环。if (b[i].sel() == sel) {return;}} while (fastpath((i = cache_next(i, m)) != begin)); // i 如果不等于初始位置 i--,继续循环。cache_t::bad_cache(receiver, (SEL)sel, cls);}
总结
- 方法的存储并不是按照数组那样从前到后进行存储,而是通过
sel & mask来存储的,所以难免会存在内存利用率低,但是加快了方法查找的速度,即:空间换时间。- 方法缓存是先于
isa的方法查找的,就是说,缓存中找不到,再到自己的方法列表中查找,找到之后也会缓存到cache_t中,如果是父类的方法,也是会缓存到自己的表当中的。- arm64 之后增加了很多
& mask的操作,获取具体的类信息,也是通过bits & mask来获取,里面存储的信息更多了(文中提到的mask不同的地方,mask的值是不同的)。- 如果
cache_next(i,m)循环到0,还未找到,赋值i == mask,继续循环,直到i == begin,证明没有缓存这个方法,这是最差的情况,相当于遍历了一遍数组。
3、自定义输出 cache_t
如果我们每次都使用上方的 lldb 进行调试,估计会累的够呛,我们可以使用一个自定义的方式去打印一下。自定义代码如下:
typedef unsigned long uintptr_t;typedef uint32_t mask_t;struct custom_bucket_t {SEL _sel;uintptr_t _imp;};struct cache_t {struct custom_bucket_t *_buckets;mask_t _mask;mask_t _occupied;};struct custom_class_data_bits_t {uintptr_t bits;};struct custom_objc_class {Class ISA;Class superclass;struct cache_t cache;struct custom_class_data_bits_t bits;};int main(int argc, const char * argv[]) {@autoreleasepool {Student *stu = [Student alloc];Class pClass = object_getClass(stu);[stu say111];[stu say222];[stu say333];[stu say444];[stu say555];[stu say666];struct custom_objc_class *zl_pClass = (__bridge struct custom_objc_class *)(pClass);NSLog(@"%u - %u",zl_pClass->cache._occupied,zl_pClass->cache._mask);for (mask_t i = 0; i<zl_pClass->cache._mask; i++) {// 打印获取的 bucketstruct custom_bucket_t bucket = zl_pClass->cache._buckets[i];NSLog(@"%@ - %lu",NSStringFromSelector(bucket._sel),bucket._imp);}NSLog(@"Hello, World!");}return 0;}
打印结果如下:

这样就能很清晰的看到 cache_t 中的缓存方法了。
4、总结
4.1 cache_t 的工作流程
- 当前查找的
IMP没有被缓存,调用reallocate方法进行创建-分配内存,然后使用bucket的set方法进行填充缓存。 - 当前查找的
IMP已经被缓存了,然后判断缓存容量是否已经达到3/4的临界点。- 如果已经到了临界点,则需要进行扩容,扩容大小为原来缓存大小的 2 倍。扩容后处于效率的考虑,会清空之前的内容,然后把当前要查找的
IMP通过bucket的set方法缓存起来。 - 如果没有到临界点,那么直接进行缓存。
- 如果已经到了临界点,则需要进行扩容,扩容大小为原来缓存大小的 2 倍。扩容后处于效率的考虑,会清空之前的内容,然后把当前要查找的
4.2 cache_t 流程图
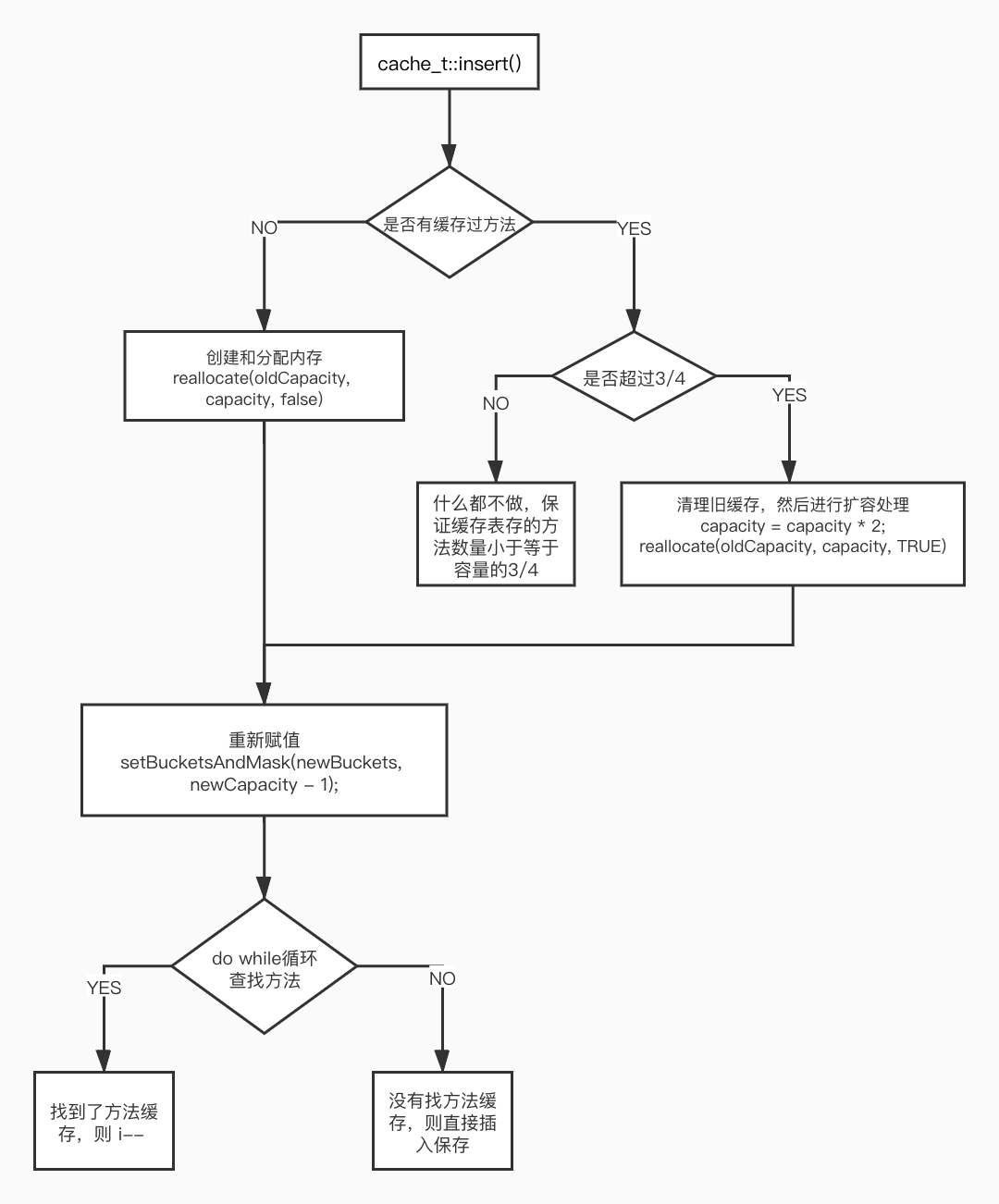
4.3 cache_t 总结
cache_t缓存会提前进行扩容防止溢出。- 方法缓存是为了最大化的提高程序的执行效率。
- 苹果在方法缓存这里用的是 开放寻址法 来解决哈希冲突。
- 通过
cache_t我们可以进一步延伸去探究objc_msgSend,因为查找方法缓存是属于objc_msgSend查找方法实现的快速流程。
下一篇我们将继续探索 iOS 中方法的底层原理。

若有收获,就点个赞吧
0 人点赞
