1、什么是内存对齐?
元素是按照定义顺序一个一个放到内存中去的,但并不是紧密排列的。从结构体存储的首地址开始,每个元素放置到内存中时,它都会认为内存是按照自己的大小(通常它为4或8)来划分的,因此元素放置的位置一定会在自己宽度的整数倍上开始,这就是所谓的内存对齐。
编译器为程序中的每个“数据单元”安排在适当的位置上。C语言允许你干预“内存对齐”。如果你想了解更加底层的秘密,“内存对齐”对你就不应该再模糊了。
下图是结构体在32bit和64bit环境下各基本数据类型所占的字节数: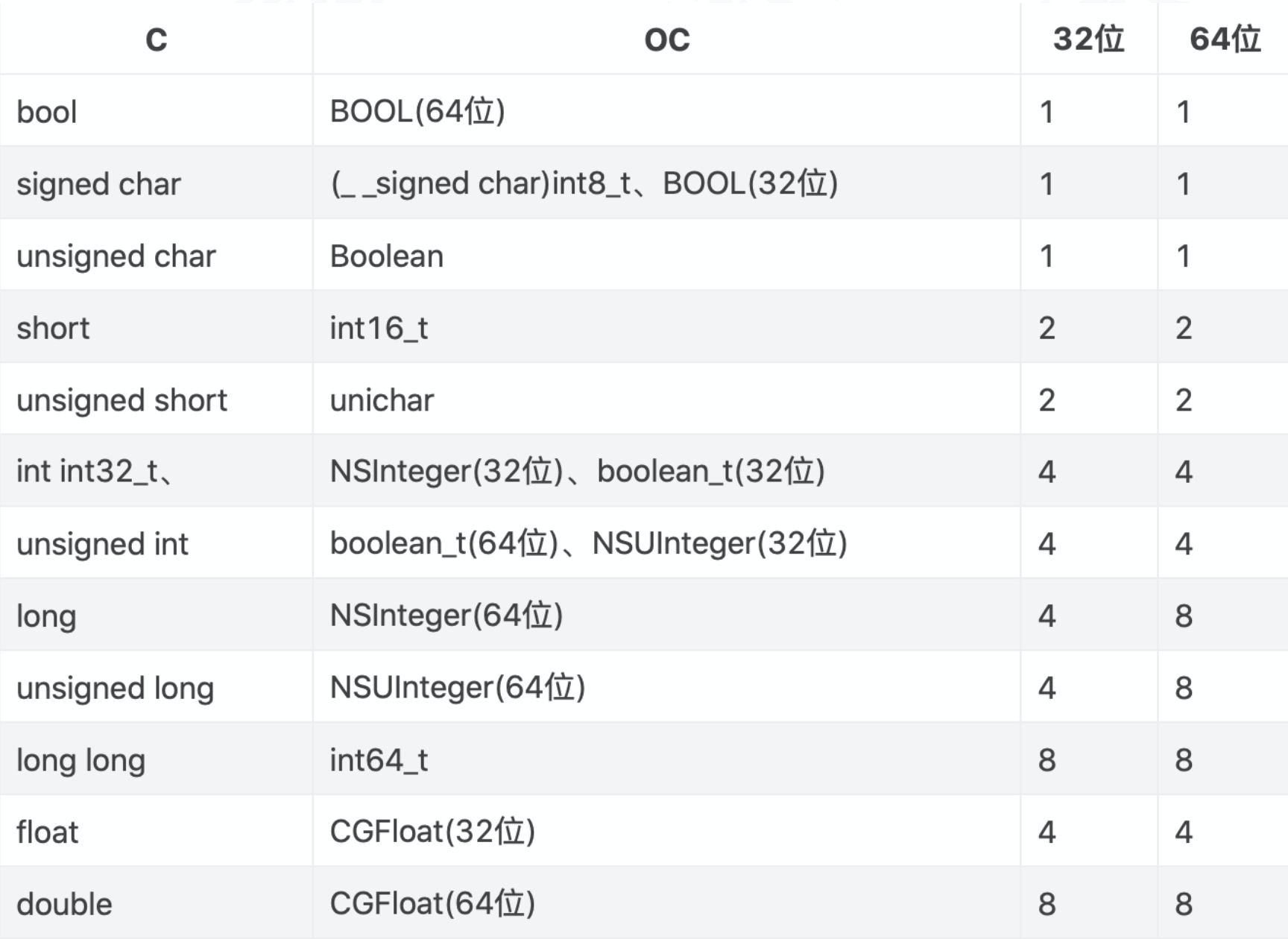
2、以一个例子开始了解
我们先看以下列子,对比上图所给的字节数,大家计算一下以下结构体所占的字节数:
struct ZLStruct1{int x;char y;} struct1;int main(int argc, char * argv[]) {NSString * appDelegateClassName;@autoreleasepool {NSLog(@"%lu",sizeof(struct1));appDelegateClassName = NSStringFromClass([AppDelegate class]);}return UIApplicationMain(argc, argv, nil, appDelegateClassName);}
以上例子的运行结果为 8,为什么呢?如果按照每个成员所占的字节数来计算的话,结果应该为 4 + 1 = 5才对啊。其实这就是内存对齐所导致的。
3、为什么要内存对齐?
- 平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
- 性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
- 假如没有内存对齐机制,数据可以任意存放,现在一个int变量存放在从地址1开始的联系四个字节地址中,该处理器去取数据时,要先从0地址开始读取第一个4字节块,剔除不想要的字节(0地址),然后从地址4开始读取下一个4字节块,同样剔除不要的数据(5,6,7地址),最后留下的两块数据合并放入寄存器。这需要做很多工作。
- 现在有了内存对齐的,int类型数据只能存放在按照对齐规则的内存中,比如说0地址开始的内存。那么现在该处理器在取数据时一次性就能将数据读出来了,而且不需要做额外的操作,提高了效率。
4、内存对齐规则
官方解释如下,简直太长不看,我们直接上案例
- 基本类型的对齐值就是其sizeof值;
- 数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员的对齐按照#pragma pack指定的数值和这个数据成员自身长度中,比较小的那个进行;
- 结构(或联合)的整体对齐规则:在数据成员完成各自对齐之后,结构(或联合)本身也要进行对齐,对齐将按照#pragma pack指定的数值和结构(或联合)最大数据成员长度中,比较小的那个进行;
struct ZLStruct1 {int i;char c1;char c2;} struct1;struct ZLStruct2 {char c1;int i;char c2;} struct2;struct ZLStruct3 {char c1;char c2;int i;} struct3;int main(int argc, char * argv[]) {NSString * appDelegateClassName;@autoreleasepool {NSLog(@"%lu",sizeof(struct1)); // 8NSLog(@"%lu",sizeof(struct2)); // 12NSLog(@"%lu",sizeof(struct3)); // 8appDelegateClassName = NSStringFromClass([AppDelegate class]);}return UIApplicationMain(argc, argv, nil, appDelegateClassName);}
看以上结构体,我们可以看到结构体中最长的数据类型为4个字节,所以有效对齐单位为4字节,下面根据上面所说的规则以第二个结构体来分析其内存布局: 首先使用规则1,对成员变量进行对齐:
- sizeof(c1) = 1 <= 4(有效对齐位),按照1字节对齐,占用第0单元;
- sizeof(i) = 4 <= 4(有效对齐位),相对于结构体首地址的偏移要为4的倍数,占用第4,5,6,7单元;
- sizeof(c2) = 1 <= 4(有效对齐位),相对于结构体首地址的偏移要为1的倍数,占用第8单元;
然后使用规则2,对结构体整体进行对齐:
第二个结构体中变量i占用内存最大占4字节,而有效对齐单位也为4字节,两者较小值就是4字节。因此整体也是按照4字节对齐。由规则1得到struct2占9个字节,此处再按照规则2进行整体的4字节对齐,所以整个结构体占用12个字节。
根据上面的分析,不难得出上面例子三个结构体的内存布局如下: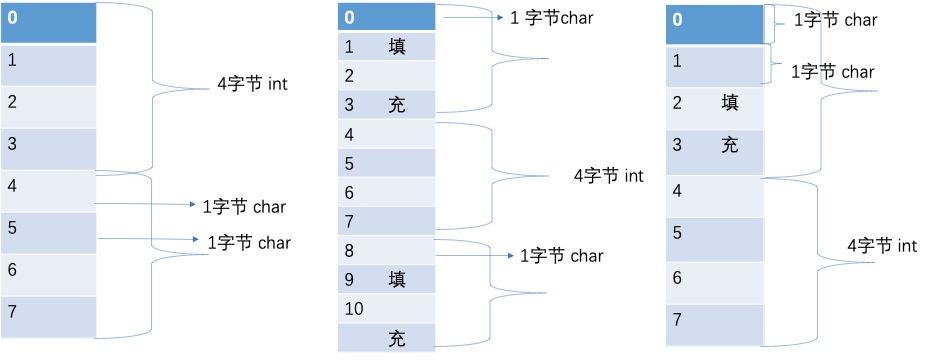
5、分析结构体嵌套结构体
接下来我们挑战升级,在一个结构体中嵌套另外一个结构体,分析它所占用的字节数:
struct ZLStruct1 {int i;char c1;char c2;} struct1;struct ZLStruct2 {char c1;int i;char c2;struct ZLStruct1 struct1;} struct2;int main(int argc, char * argv[]) {NSString * appDelegateClassName;@autoreleasepool {NSLog(@"%lu",sizeof(struct1)); // 8NSLog(@"%lu",sizeof(struct2)); //appDelegateClassName = NSStringFromClass([AppDelegate class]);}return UIApplicationMain(argc, argv, nil, appDelegateClassName);}
根据我们上面所说的内存对齐规则,可以看到struct1的长度为8字节,但struct1中最长的数据类型为sizeof(i) = 4,
- sizeof(c1) = 1 <= 4(有效对齐位),按照1字节对齐,占用第0单元;
- sizeof(i) = 4 <= 4(有效对齐位),相对于结构体首地址的偏移要为4的倍数,占用第4,5,6,7单元;
- sizeof(c2) = 1 <= 4(有效对齐位),相对于结构体首地址的偏移要为1的倍数,占用第8单元;
- sizeof(struct1) = 8 <= 4(有效对齐位),相对于结构体首地址的偏移要为4的倍数,占用第12,13,14,15,16,17,18,19单元;
因此对齐后,可以得出所占字节数为20的内存分布图: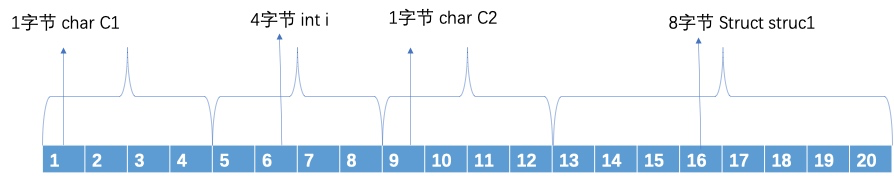
6、总结
结构体作为一种复合数据类型,其构成元素既可以是基本数据类型的变量,也可以是一些复合型类型数据。对此,编译器会自动进行成员变量的对齐以提高运算效率。默认情况下,按自然对齐条件分配空间。各个成员按照它们被声明的顺序在内存中顺序存储,第一个成员的地址和整个结构的地址相同,向结构体成员中size最大的成员对齐。
许多实际的计算机系统对基本类型数据在内存中存放的位置有限制,它们会要求这些数据的首地址的值是某个数k(通常它为4或8)的倍数,而这个k则被称为该数据类型的对齐模数。

若有收获,就点个赞吧
0 人点赞
