1、同步执行 dispatch_sync
voiddispatch_sync(dispatch_queue_t dq, dispatch_block_t work){uintptr_t dc_flags = DC_FLAG_BLOCK;if (unlikely(_dispatch_block_has_private_data(work))) {return _dispatch_sync_block_with_privdata(dq, work, dc_flags);}_dispatch_sync_f(dq, work, _dispatch_Block_invoke(work), dc_flags);}// 进一步查看 _dispatch_sync_fstatic void_dispatch_sync_f(dispatch_queue_t dq, void *ctxt, dispatch_function_t func,uintptr_t dc_flags){_dispatch_sync_f_inline(dq, ctxt, func, dc_flags);}// 查看 _dispatch_sync_f_inlinestatic inline void_dispatch_sync_f_inline(dispatch_queue_t dq, void *ctxt,dispatch_function_t func, uintptr_t dc_flags){if (likely(dq->dq_width == 1)) {return _dispatch_barrier_sync_f(dq, ctxt, func, dc_flags);}if (unlikely(dx_metatype(dq) != _DISPATCH_LANE_TYPE)) {DISPATCH_CLIENT_CRASH(0, "Queue type doesn't support dispatch_sync");}dispatch_lane_t dl = upcast(dq)._dl;// Global concurrent queues and queues bound to non-dispatch threads// always fall into the slow case, see DISPATCH_ROOT_QUEUE_STATE_INIT_VALUEif (unlikely(!_dispatch_queue_try_reserve_sync_width(dl))) {return _dispatch_sync_f_slow(dl, ctxt, func, 0, dl, dc_flags);}if (unlikely(dq->do_targetq->do_targetq)) {return _dispatch_sync_recurse(dl, ctxt, func, dc_flags);}_dispatch_introspection_sync_begin(dl);_dispatch_sync_invoke_and_complete(dl, ctxt, func DISPATCH_TRACE_ARG(_dispatch_trace_item_sync_push_pop(dq, ctxt, func, dc_flags)));}
可以看到首先通过 width 判定是串行队列还是并发队列,如果是并发队列则调用 _dispatch_sync_invoke_and_complete,如果是串行队列则调用 _dispatch_barrier_sync_f。我们先展开看一下串行队列的同步执行源代码:
static void_dispatch_barrier_sync_f(dispatch_queue_t dq, void *ctxt,dispatch_function_t func, uintptr_t dc_flags){_dispatch_barrier_sync_f_inline(dq, ctxt, func, dc_flags);}// 查看 _dispatch_barrier_sync_f_inlinestatic inline void_dispatch_barrier_sync_f_inline(dispatch_queue_t dq, void *ctxt,dispatch_function_t func, uintptr_t dc_flags){dispatch_tid tid = _dispatch_tid_self();if (unlikely(dx_metatype(dq) != _DISPATCH_LANE_TYPE)) {DISPATCH_CLIENT_CRASH(0, "Queue type doesn't support dispatch_sync");}dispatch_lane_t dl = upcast(dq)._dl;// The more correct thing to do would be to merge the qos of the thread// that just acquired the barrier lock into the queue state.//// However this is too expensive for the fast path, so skip doing it.// The chosen tradeoff is that if an enqueue on a lower priority thread// contends with this fast path, this thread may receive a useless override.//// Global concurrent queues and queues bound to non-dispatch threads// always fall into the slow case, see DISPATCH_ROOT_QUEUE_STATE_INIT_VALUEif (unlikely(!_dispatch_queue_try_acquire_barrier_sync(dl, tid))) {return _dispatch_sync_f_slow(dl, ctxt, func, DC_FLAG_BARRIER, dl,DC_FLAG_BARRIER | dc_flags);}if (unlikely(dl->do_targetq->do_targetq)) {return _dispatch_sync_recurse(dl, ctxt, func,DC_FLAG_BARRIER | dc_flags);}_dispatch_introspection_sync_begin(dl);_dispatch_lane_barrier_sync_invoke_and_complete(dl, ctxt, funcDISPATCH_TRACE_ARG(_dispatch_trace_item_sync_push_pop(dq, ctxt, func, dc_flags | DC_FLAG_BARRIER)));}
可以看到上面的代码逻辑时首先获取线程 tid,然后处理死锁的情况,因此我们先看一下死锁的情况:
static void_dispatch_sync_f_slow(dispatch_queue_class_t top_dqu, void *ctxt,dispatch_function_t func, uintptr_t top_dc_flags,dispatch_queue_class_t dqu, uintptr_t dc_flags){dispatch_queue_t top_dq = top_dqu._dq;dispatch_queue_t dq = dqu._dq;if (unlikely(!dq->do_targetq)) {return _dispatch_sync_function_invoke(dq, ctxt, func);}pthread_priority_t pp = _dispatch_get_priority();struct dispatch_sync_context_s dsc = {.dc_flags = DC_FLAG_SYNC_WAITER | dc_flags,.dc_func = _dispatch_async_and_wait_invoke,.dc_ctxt = &dsc,.dc_other = top_dq,.dc_priority = pp | _PTHREAD_PRIORITY_ENFORCE_FLAG,.dc_voucher = _voucher_get(),.dsc_func = func,.dsc_ctxt = ctxt,.dsc_waiter = _dispatch_tid_self(),};_dispatch_trace_item_push(top_dq, &dsc);__DISPATCH_WAIT_FOR_QUEUE__(&dsc, dq);if (dsc.dsc_func == NULL) {// dsc_func being cleared means that the block ran on another thread ie.// case (2) as listed in _dispatch_async_and_wait_f_slow.dispatch_queue_t stop_dq = dsc.dc_other;return _dispatch_sync_complete_recurse(top_dq, stop_dq, top_dc_flags);}_dispatch_introspection_sync_begin(top_dq);_dispatch_trace_item_pop(top_dq, &dsc);_dispatch_sync_invoke_and_complete_recurse(top_dq, ctxt, func,top_dc_flagsDISPATCH_TRACE_ARG(&dsc));}// 查看 __DISPATCH_WAIT_FOR_QUEUE__static void__DISPATCH_WAIT_FOR_QUEUE__(dispatch_sync_context_t dsc, dispatch_queue_t dq){uint64_t dq_state = _dispatch_wait_prepare(dq);if (unlikely(_dq_state_drain_locked_by(dq_state, dsc->dsc_waiter))) {DISPATCH_CLIENT_CRASH((uintptr_t)dq_state,"dispatch_sync called on queue ""already owned by current thread");}// Blocks submitted to the main thread MUST run on the main thread, and// dispatch_async_and_wait also executes on the remote context rather than// the current thread.//// For both these cases we need to save the frame linkage for the sake of// _dispatch_async_and_wait_invoke_dispatch_thread_frame_save_state(&dsc->dsc_dtf);if (_dq_state_is_suspended(dq_state) ||_dq_state_is_base_anon(dq_state)) {dsc->dc_data = DISPATCH_WLH_ANON;} else if (_dq_state_is_base_wlh(dq_state)) {dsc->dc_data = (dispatch_wlh_t)dq;} else {_dispatch_wait_compute_wlh(upcast(dq)._dl, dsc);}if (dsc->dc_data == DISPATCH_WLH_ANON) {dsc->dsc_override_qos_floor = dsc->dsc_override_qos =(uint8_t)_dispatch_get_basepri_override_qos_floor();_dispatch_thread_event_init(&dsc->dsc_event);}dx_push(dq, dsc, _dispatch_qos_from_pp(dsc->dc_priority));_dispatch_trace_runtime_event(sync_wait, dq, 0);if (dsc->dc_data == DISPATCH_WLH_ANON) {_dispatch_thread_event_wait(&dsc->dsc_event); // acquire} else {_dispatch_event_loop_wait_for_ownership(dsc);}if (dsc->dc_data == DISPATCH_WLH_ANON) {_dispatch_thread_event_destroy(&dsc->dsc_event);// If _dispatch_sync_waiter_wake() gave this thread an override,// ensure that the root queue sees it.if (dsc->dsc_override_qos > dsc->dsc_override_qos_floor) {_dispatch_set_basepri_override_qos(dsc->dsc_override_qos);}}}// 展开 _dq_state_drain_locked_bystatic inline bool_dq_state_drain_locked_by(uint64_t dq_state, dispatch_tid tid){return _dispatch_lock_is_locked_by((dispatch_lock)dq_state, tid);}// 然后看一下 _dispatch_lock_is_locked_bystatic inline bool_dispatch_lock_is_locked_by(dispatch_lock lock_value, dispatch_tid tid){// equivalent to _dispatch_lock_owner(lock_value) == tidreturn ((lock_value ^ tid) & DLOCK_OWNER_MASK) == 0;}
可以看到队列 push 以后就是用 _dispatch_lock_is_locked_by 判断将要调度的和当前等待的队列是不是同一个,如果相同则返回 YES,产生死锁DISPATCH_CLIENT_CRASH;如果没有产生死锁,则执行 _dispatch_trace_item_pop()出队列执行。如何执行调度呢,我们可以看一下_dispatch_sync_invoke_and_complete_recurse
static void_dispatch_sync_invoke_and_complete_recurse(dispatch_queue_class_t dq,void *ctxt, dispatch_function_t func, uintptr_t dc_flagsDISPATCH_TRACE_ARG(void *dc)){_dispatch_sync_function_invoke_inline(dq, ctxt, func);_dispatch_trace_item_complete(dc);_dispatch_sync_complete_recurse(dq._dq, NULL, dc_flags);}// 看一下 _dispatch_sync_function_invoke_inlinestatic inline void_dispatch_sync_function_invoke_inline(dispatch_queue_class_t dq, void *ctxt,dispatch_function_t func){dispatch_thread_frame_s dtf;_dispatch_thread_frame_push(&dtf, dq);_dispatch_client_callout(ctxt, func);_dispatch_perfmon_workitem_inc();_dispatch_thread_frame_pop(&dtf);}// 看一下 _dispatch_client_calloutvoid_dispatch_client_callout(void *ctxt, dispatch_function_t f){@try {return f(ctxt);}@catch (...) {objc_terminate();}}可以比较清楚的看到最终执行f函数,这个就是外界传过来的回调block。
2、异步调用 dispatch_async
今天我们重新来分析一遍 dispatch_async 的调用过程
voiddispatch_async(dispatch_queue_t dq, dispatch_block_t work){dispatch_continuation_t dc = _dispatch_continuation_alloc();uintptr_t dc_flags = DC_FLAG_CONSUME;dispatch_qos_t qos;qos = _dispatch_continuation_init(dc, dq, work, 0, dc_flags);_dispatch_continuation_async(dq, dc, qos, dc->dc_flags);}// 查看 _dispatch_continuation_init 代码,主要进行block初始化static inline dispatch_qos_t_dispatch_continuation_init(dispatch_continuation_t dc,dispatch_queue_class_t dqu, dispatch_block_t work,dispatch_block_flags_t flags, uintptr_t dc_flags){void *ctxt = _dispatch_Block_copy(work);dc_flags |= DC_FLAG_BLOCK | DC_FLAG_ALLOCATED;if (unlikely(_dispatch_block_has_private_data(work))) {dc->dc_flags = dc_flags;dc->dc_ctxt = ctxt;// will initialize all fields but requires dc_flags & dc_ctxt to be setreturn _dispatch_continuation_init_slow(dc, dqu, flags);}dispatch_function_t func = _dispatch_Block_invoke(work);if (dc_flags & DC_FLAG_CONSUME) {func = _dispatch_call_block_and_release;}return _dispatch_continuation_init_f(dc, dqu, ctxt, func, flags, dc_flags);}// 另外查看 _dispatch_continuation_asyncstatic inline void_dispatch_continuation_async(dispatch_queue_class_t dqu,dispatch_continuation_t dc, dispatch_qos_t qos, uintptr_t dc_flags){#if DISPATCH_INTROSPECTIONif (!(dc_flags & DC_FLAG_NO_INTROSPECTION)) {_dispatch_trace_item_push(dqu, dc);}#else(void)dc_flags;#endifreturn dx_push(dqu._dq, dc, qos);}// 进一步查看 dx_push#define dx_push(x, y, z) dx_vtable(x)->dq_push(x, y, z)// 本质是调用 dx_vtable 的 dq_push (其实就是调用对象的 do_push ),进一步查看 dq_push,我们假设是 global_queue 进行异步调用可以看到:DISPATCH_VTABLE_SUBCLASS_INSTANCE(queue_global, lane,.do_type = DISPATCH_QUEUE_GLOBAL_ROOT_TYPE,.do_dispose = _dispatch_object_no_dispose,.do_debug = _dispatch_queue_debug,.do_invoke = _dispatch_object_no_invoke,.dq_activate = _dispatch_queue_no_activate,.dq_wakeup = _dispatch_root_queue_wakeup,.dq_push = _dispatch_root_queue_push,);
可以看到 dx_push已经到了 _dispatch_root_queue_push ,这是可以接着查看 _dispatch_root_queue_push:
void_dispatch_root_queue_push(dispatch_queue_global_t rq, dispatch_object_t dou,dispatch_qos_t qos){#if DISPATCH_USE_KEVENT_WORKQUEUEdispatch_deferred_items_t ddi = _dispatch_deferred_items_get();if (unlikely(ddi && ddi->ddi_can_stash)) {dispatch_object_t old_dou = ddi->ddi_stashed_dou;dispatch_priority_t rq_overcommit;rq_overcommit = rq->dq_priority & DISPATCH_PRIORITY_FLAG_OVERCOMMIT;if (likely(!old_dou._do || rq_overcommit)) {dispatch_queue_global_t old_rq = ddi->ddi_stashed_rq;dispatch_qos_t old_qos = ddi->ddi_stashed_qos;ddi->ddi_stashed_rq = rq;ddi->ddi_stashed_dou = dou;ddi->ddi_stashed_qos = qos;_dispatch_debug("deferring item %p, rq %p, qos %d",dou._do, rq, qos);if (rq_overcommit) {ddi->ddi_can_stash = false;}if (likely(!old_dou._do)) {return;}// push the previously stashed itemqos = old_qos;rq = old_rq;dou = old_dou;}}#endif#if HAVE_PTHREAD_WORKQUEUE_QOSif (_dispatch_root_queue_push_needs_override(rq, qos)) {return _dispatch_root_queue_push_override(rq, dou, qos);}#else(void)qos;#endif_dispatch_root_queue_push_inline(rq, dou, dou, 1);}// 多数情况下符合 HAVE_PTHREAD_WORKQUEUE_QOS,会执行 _dispatch_root_queue_push_override(对比的是 qos 与 root 队列的 qos 是否一致,基本上都不一致的。)static void_dispatch_root_queue_push_override(dispatch_queue_global_t orig_rq,dispatch_object_t dou, dispatch_qos_t qos){bool overcommit = orig_rq->dq_priority & DISPATCH_PRIORITY_FLAG_OVERCOMMIT;dispatch_queue_global_t rq = _dispatch_get_root_queue(qos, overcommit);dispatch_continuation_t dc = dou._dc;if (_dispatch_object_is_redirection(dc)) {// no double-wrap is needed, _dispatch_async_redirect_invoke will do// the right thingdc->dc_func = (void *)orig_rq;} else {dc = _dispatch_continuation_alloc();dc->do_vtable = DC_VTABLE(OVERRIDE_OWNING);dc->dc_ctxt = dc;dc->dc_other = orig_rq;dc->dc_data = dou._do;dc->dc_priority = DISPATCH_NO_PRIORITY;dc->dc_voucher = DISPATCH_NO_VOUCHER;}_dispatch_root_queue_push_inline(rq, dc, dc, 1);}/*上面 _dispatch_object_is_redirection 函数其实就是 return _dispatch_object_has_type(dou,DISPATCH_CONTINUATION_TYPE(ASYNC_REDIRECT));所以自定义队列会走这个 if 语句,如果是 dispatch_get_global_queue 不会走 if 语句。展开 _dispatch_root_queue_push_inline。注意_dispatch_root_queue_push_inline中 的 if 把任务装进队列,大多数不走进if语句。但是第一个任务进来之前还是满足这个条件式的,会进入这个条件语句去激活队列来执行里面的任务,后面再加入的任务因为队列被激活了,所以也就不太需要再进入这个队列了,所以相对来说激活队列只要一次。*/static inline void_dispatch_root_queue_push_inline(dispatch_queue_global_t dq,dispatch_object_t _head, dispatch_object_t _tail, int n){struct dispatch_object_s *hd = _head._do, *tl = _tail._do;if (unlikely(os_mpsc_push_list(os_mpsc(dq, dq_items), hd, tl, do_next))) {return _dispatch_root_queue_poke(dq, n, 0);}}// 我们可以看到,我们装入到自定义的任务都被扔到其挂靠的root队列里去了,所以我们我们自己创建的队列只是一个代理人身份,继续查看 _dispatch_root_queue_poke 源码void_dispatch_root_queue_poke(dispatch_queue_global_t dq, int n, int floor){if (!_dispatch_queue_class_probe(dq)) {return;}#if !DISPATCH_USE_INTERNAL_WORKQUEUE#if DISPATCH_USE_PTHREAD_POOLif (likely(dx_type(dq) == DISPATCH_QUEUE_GLOBAL_ROOT_TYPE))#endif{if (unlikely(!os_atomic_cmpxchg2o(dq, dgq_pending, 0, n, relaxed))) {_dispatch_root_queue_debug("worker thread request still pending ""for global queue: %p", dq);return;}}#endif // !DISPATCH_USE_INTERNAL_WORKQUEUEreturn _dispatch_root_queue_poke_slow(dq, n, floor);}// 继续查看 _dispatch_root_queue_poke_slowstatic void_dispatch_root_queue_poke_slow(dispatch_queue_global_t dq, int n, int floor){int remaining = n;int r = ENOSYS;_dispatch_root_queues_init();_dispatch_debug_root_queue(dq, __func__);_dispatch_trace_runtime_event(worker_request, dq, (uint64_t)n);#if !DISPATCH_USE_INTERNAL_WORKQUEUE#if DISPATCH_USE_PTHREAD_ROOT_QUEUESif (dx_type(dq) == DISPATCH_QUEUE_GLOBAL_ROOT_TYPE)#endif{_dispatch_root_queue_debug("requesting new worker thread for global ""queue: %p", dq);r = _pthread_workqueue_addthreads(remaining,_dispatch_priority_to_pp_prefer_fallback(dq->dq_priority));(void)dispatch_assume_zero(r);return;}#endif // !DISPATCH_USE_INTERNAL_WORKQUEUE#if DISPATCH_USE_PTHREAD_POOLdispatch_pthread_root_queue_context_t pqc = dq->do_ctxt;if (likely(pqc->dpq_thread_mediator.do_vtable)) {while (dispatch_semaphore_signal(&pqc->dpq_thread_mediator)) {_dispatch_root_queue_debug("signaled sleeping worker for ""global queue: %p", dq);if (!--remaining) {return;}}}bool overcommit = dq->dq_priority & DISPATCH_PRIORITY_FLAG_OVERCOMMIT;if (overcommit) {os_atomic_add2o(dq, dgq_pending, remaining, relaxed);} else {if (!os_atomic_cmpxchg2o(dq, dgq_pending, 0, remaining, relaxed)) {_dispatch_root_queue_debug("worker thread request still pending for ""global queue: %p", dq);return;}}int can_request, t_count;// seq_cst with atomic store to tail <rdar://problem/16932833>t_count = os_atomic_load2o(dq, dgq_thread_pool_size, ordered);do {can_request = t_count < floor ? 0 : t_count - floor;if (remaining > can_request) {_dispatch_root_queue_debug("pthread pool reducing request from %d to %d",remaining, can_request);os_atomic_sub2o(dq, dgq_pending, remaining - can_request, relaxed);remaining = can_request;}if (remaining == 0) {_dispatch_root_queue_debug("pthread pool is full for root queue: ""%p", dq);return;}} while (!os_atomic_cmpxchgvw2o(dq, dgq_thread_pool_size, t_count,t_count - remaining, &t_count, acquire));#if !defined(_WIN32)pthread_attr_t *attr = &pqc->dpq_thread_attr;pthread_t tid, *pthr = &tid;#if DISPATCH_USE_MGR_THREAD && DISPATCH_USE_PTHREAD_ROOT_QUEUESif (unlikely(dq == &_dispatch_mgr_root_queue)) {pthr = _dispatch_mgr_root_queue_init();}#endifdo {_dispatch_retain(dq); // released in _dispatch_worker_threadwhile ((r = pthread_create(pthr, attr, _dispatch_worker_thread, dq))) {if (r != EAGAIN) {(void)dispatch_assume_zero(r);}_dispatch_temporary_resource_shortage();}} while (--remaining);#else // defined(_WIN32)#if DISPATCH_USE_MGR_THREAD && DISPATCH_USE_PTHREAD_ROOT_QUEUESif (unlikely(dq == &_dispatch_mgr_root_queue)) {_dispatch_mgr_root_queue_init();}#endifdo {_dispatch_retain(dq); // released in _dispatch_worker_thread#if DISPATCH_DEBUGunsigned dwStackSize = 0;#elseunsigned dwStackSize = 64 * 1024;#endifuintptr_t hThread = 0;while (!(hThread = _beginthreadex(NULL, dwStackSize, _dispatch_worker_thread_thunk, dq, STACK_SIZE_PARAM_IS_A_RESERVATION, NULL))) {if (errno != EAGAIN) {(void)dispatch_assume(hThread);}_dispatch_temporary_resource_shortage();}if (_dispatch_mgr_sched.prio > _dispatch_mgr_sched.default_prio) {(void)dispatch_assume_zero(SetThreadPriority((HANDLE)hThread, _dispatch_mgr_sched.prio) == TRUE);}CloseHandle((HANDLE)hThread);} while (--remaining);#endif // defined(_WIN32)#else(void)floor;#endif // DISPATCH_USE_PTHREAD_POOL}
到了这里可以清楚的看到对于全局队列使用 _pthread_workqueue_addthreads 开辟线程,对于其他队列使用 pthread_create 开辟新的线程。那么任务执行的代码为什么没看到?其实 _dispatch_root_queues_init 中会首先执行第一个任务:
static inline void_dispatch_root_queues_init(void){dispatch_once_f(&_dispatch_root_queues_pred, NULL,_dispatch_root_queues_init_once);}// 看一下 dispatch_once_f 就不展开了,可以看一下下面 dispatch_once 的分析,这里看一下 _dispatch_root_queues_init_oncestatic void_dispatch_root_queues_init_once(void *context DISPATCH_UNUSED){_dispatch_fork_becomes_unsafe();#if DISPATCH_USE_INTERNAL_WORKQUEUEsize_t i;for (i = 0; i < DISPATCH_ROOT_QUEUE_COUNT; i++) {_dispatch_root_queue_init_pthread_pool(&_dispatch_root_queues[i], 0,_dispatch_root_queues[i].dq_priority);}#elseint wq_supported = _pthread_workqueue_supported();int r = ENOTSUP;if (!(wq_supported & WORKQ_FEATURE_MAINTENANCE)) {DISPATCH_INTERNAL_CRASH(wq_supported,"QoS Maintenance support required");}#if DISPATCH_USE_KEVENT_SETUPstruct pthread_workqueue_config cfg = {.version = PTHREAD_WORKQUEUE_CONFIG_VERSION,.flags = 0,.workq_cb = 0,.kevent_cb = 0,.workloop_cb = 0,.queue_serialno_offs = dispatch_queue_offsets.dqo_serialnum,#if PTHREAD_WORKQUEUE_CONFIG_VERSION >= 2.queue_label_offs = dispatch_queue_offsets.dqo_label,#endif};#endif#pragma clang diagnostic push#pragma clang diagnostic ignored "-Wunreachable-code"if (unlikely(!_dispatch_kevent_workqueue_enabled)) {#if DISPATCH_USE_KEVENT_SETUPcfg.workq_cb = _dispatch_worker_thread2;r = pthread_workqueue_setup(&cfg, sizeof(cfg));#elser = _pthread_workqueue_init(_dispatch_worker_thread2,offsetof(struct dispatch_queue_s, dq_serialnum), 0);#endif // DISPATCH_USE_KEVENT_SETUP#if DISPATCH_USE_KEVENT_WORKLOOP} else if (wq_supported & WORKQ_FEATURE_WORKLOOP) {#if DISPATCH_USE_KEVENT_SETUPcfg.workq_cb = _dispatch_worker_thread2;cfg.kevent_cb = (pthread_workqueue_function_kevent_t) _dispatch_kevent_worker_thread;cfg.workloop_cb = (pthread_workqueue_function_workloop_t) _dispatch_workloop_worker_thread;r = pthread_workqueue_setup(&cfg, sizeof(cfg));#elser = _pthread_workqueue_init_with_workloop(_dispatch_worker_thread2,(pthread_workqueue_function_kevent_t)_dispatch_kevent_worker_thread,(pthread_workqueue_function_workloop_t)_dispatch_workloop_worker_thread,offsetof(struct dispatch_queue_s, dq_serialnum), 0);#endif // DISPATCH_USE_KEVENT_SETUP#endif // DISPATCH_USE_KEVENT_WORKLOOP#if DISPATCH_USE_KEVENT_WORKQUEUE} else if (wq_supported & WORKQ_FEATURE_KEVENT) {#if DISPATCH_USE_KEVENT_SETUPcfg.workq_cb = _dispatch_worker_thread2;cfg.kevent_cb = (pthread_workqueue_function_kevent_t) _dispatch_kevent_worker_thread;r = pthread_workqueue_setup(&cfg, sizeof(cfg));#elser = _pthread_workqueue_init_with_kevent(_dispatch_worker_thread2,(pthread_workqueue_function_kevent_t)_dispatch_kevent_worker_thread,offsetof(struct dispatch_queue_s, dq_serialnum), 0);#endif // DISPATCH_USE_KEVENT_SETUP#endif} else {DISPATCH_INTERNAL_CRASH(wq_supported, "Missing Kevent WORKQ support");}#pragma clang diagnostic popif (r != 0) {DISPATCH_INTERNAL_CRASH((r << 16) | wq_supported,"Root queue initialization failed");}#endif // DISPATCH_USE_INTERNAL_WORKQUEUE}// 继续查看 _dispatch_workloop_worker_threadstatic void_dispatch_workloop_worker_thread(uint64_t *workloop_id,dispatch_kevent_t *events, int *nevents){if (!dispatch_assume(workloop_id && events && nevents)) {return;}if (!dispatch_assume(*workloop_id != 0)) {return _dispatch_kevent_worker_thread(events, nevents);}if (*nevents == 0 || *events == NULL) {// events for worker thread request have already been delivered earlier// or got cancelled before point of no return concurrentlyreturn;}dispatch_wlh_t wlh = (dispatch_wlh_t)*workloop_id;_dispatch_adopt_wlh(wlh);_dispatch_wlh_worker_thread(wlh, *events, nevents);_dispatch_preserve_wlh_storage_reference(wlh);}// 查看 _dispatch_worker_thread2static void_dispatch_worker_thread2(pthread_priority_t pp){bool overcommit = pp & _PTHREAD_PRIORITY_OVERCOMMIT_FLAG;dispatch_queue_global_t dq;pp &= _PTHREAD_PRIORITY_OVERCOMMIT_FLAG | ~_PTHREAD_PRIORITY_FLAGS_MASK;_dispatch_thread_setspecific(dispatch_priority_key, (void *)(uintptr_t)pp);dq = _dispatch_get_root_queue(_dispatch_qos_from_pp(pp), overcommit);_dispatch_introspection_thread_add();_dispatch_trace_runtime_event(worker_unpark, dq, 0);int pending = os_atomic_dec2o(dq, dgq_pending, relaxed);dispatch_assert(pending >= 0);_dispatch_root_queue_drain(dq, dq->dq_priority,DISPATCH_INVOKE_WORKER_DRAIN | DISPATCH_INVOKE_REDIRECTING_DRAIN);_dispatch_voucher_debug("root queue clear", NULL);_dispatch_reset_voucher(NULL, DISPATCH_THREAD_PARK);_dispatch_trace_runtime_event(worker_park, NULL, 0);}// 查看 _dispatch_root_queue_drainstatic void_dispatch_root_queue_drain(dispatch_queue_global_t dq,dispatch_priority_t pri, dispatch_invoke_flags_t flags){#if DISPATCH_DEBUGdispatch_queue_t cq;if (unlikely(cq = _dispatch_queue_get_current())) {DISPATCH_INTERNAL_CRASH(cq, "Premature thread recycling");}#endif_dispatch_queue_set_current(dq);_dispatch_init_basepri(pri);_dispatch_adopt_wlh_anon();struct dispatch_object_s *item;bool reset = false;dispatch_invoke_context_s dic = { };#if DISPATCH_COCOA_COMPAT_dispatch_last_resort_autorelease_pool_push(&dic);#endif // DISPATCH_COCOA_COMPAT_dispatch_queue_drain_init_narrowing_check_deadline(&dic, pri);_dispatch_perfmon_start();while (likely(item = _dispatch_root_queue_drain_one(dq))) {if (reset) _dispatch_wqthread_override_reset();_dispatch_continuation_pop_inline(item, &dic, flags, dq);reset = _dispatch_reset_basepri_override();if (unlikely(_dispatch_queue_drain_should_narrow(&dic))) {break;}}// overcommit or not. worker threadif (pri & DISPATCH_PRIORITY_FLAG_OVERCOMMIT) {_dispatch_perfmon_end(perfmon_thread_worker_oc);} else {_dispatch_perfmon_end(perfmon_thread_worker_non_oc);}#if DISPATCH_COCOA_COMPAT_dispatch_last_resort_autorelease_pool_pop(&dic);#endif // DISPATCH_COCOA_COMPAT_dispatch_reset_wlh();_dispatch_clear_basepri();_dispatch_queue_set_current(NULL);}// 查看 _dispatch_continuation_pop_inline 这个是出队列操作,这里注意一下首先看了有没有 vtable(_dispatch_object_has_vtable),这里解释了为什么 dispatch_barrier_async 尽管主要流程和 dispatch_async 一模一样但是无法应用到全局队列的原因,因为全局队列没有 v_table 结构会直接像dispatch_async 一样执行static inline void_dispatch_continuation_pop_inline(dispatch_object_t dou,dispatch_invoke_context_t dic, dispatch_invoke_flags_t flags,dispatch_queue_class_t dqu){dispatch_pthread_root_queue_observer_hooks_t observer_hooks =_dispatch_get_pthread_root_queue_observer_hooks();if (observer_hooks) observer_hooks->queue_will_execute(dqu._dq);flags &= _DISPATCH_INVOKE_PROPAGATE_MASK;if (_dispatch_object_has_vtable(dou)) {dx_invoke(dou._dq, dic, flags);} else {_dispatch_continuation_invoke_inline(dou, flags, dqu);}if (observer_hooks) observer_hooks->queue_did_execute(dqu._dq);}// 查看 _dispatch_continuation_invoke_inline,这里_dispatch_client_callout 就是真正的执行 block 操作 ,当然还有一种情况这里还不会走就是 _dispatch_continuation_with_group_invoke,这个后面的 dispatch_group 会用到static inline void_dispatch_continuation_invoke_inline(dispatch_object_t dou,dispatch_invoke_flags_t flags, dispatch_queue_class_t dqu){dispatch_continuation_t dc = dou._dc, dc1;dispatch_invoke_with_autoreleasepool(flags, {uintptr_t dc_flags = dc->dc_flags;// Add the item back to the cache before calling the function. This// allows the 'hot' continuation to be used for a quick callback.//// The ccache version is per-thread.// Therefore, the object has not been reused yet.// This generates better assembly._dispatch_continuation_voucher_adopt(dc, dc_flags);if (!(dc_flags & DC_FLAG_NO_INTROSPECTION)) {_dispatch_trace_item_pop(dqu, dou);}if (dc_flags & DC_FLAG_CONSUME) {dc1 = _dispatch_continuation_free_cacheonly(dc);} else {dc1 = NULL;}if (unlikely(dc_flags & DC_FLAG_GROUP_ASYNC)) {_dispatch_continuation_with_group_invoke(dc);} else {_dispatch_client_callout(dc->dc_ctxt, dc->dc_func);_dispatch_trace_item_complete(dc);}if (unlikely(dc1)) {_dispatch_continuation_free_to_cache_limit(dc1);}});_dispatch_perfmon_workitem_inc();}
另外对于 _dispatch_continuation_init 的代码中的并没有对其进行展开,其实 _dispatch_continuation_init 中的 func 就是 _dispatch_call_block_and_release(源码如下),它在 dx_push 调用时包装进了 qos。
void_dispatch_call_block_and_release(void *block){void (^b)(void) = block;b();Block_release(b);}
dispatch_async 代码实现看起来比较复杂,因为其中的数据结构较多,分支流程控制比较复杂。不过思路其实很简单,用链表保存所有提交的 block(先进先出,在队列本身维护了一个链表新加入 block 放到链表尾部),然后在底层线程池中,依次取出 block 并执行。
类似的可以看到 dispatch_barrier_async 源码和 dispatch_async 几乎一致,仅仅多了一个标记位 DC_FLAG_BARRIER,这个标记位用于在取出任务时进行判断,正常的异步调用会依次取出,而如果遇到了 DC_FLAG_BARRIER 则会返回,所以可以等待所有任务执行结束执行 dx_push(不过提醒一下dispatch_barrier_async 必须在自定义队列才有用,原因是 global 队列没有 v_table 结构,同时不要试图在主队列调用,否则会 crash):
voiddispatch_barrier_async(dispatch_queue_t dq, dispatch_block_t work){dispatch_continuation_t dc = _dispatch_continuation_alloc();uintptr_t dc_flags = DC_FLAG_CONSUME | DC_FLAG_BARRIER;dispatch_qos_t qos;qos = _dispatch_continuation_init(dc, dq, work, 0, dc_flags);_dispatch_continuation_async(dq, dc, qos, dc_flags);}
3、单次执行 dispatch_once
下面的代码在objc开发中应该很常见,这种方式可以保证instance只会创建一次:
+ (instancetype)sharedInstance {static MyClass *instance;static dispatch_once_t onceToken;dispatch_once(&onceToken, ^{instance = [[MyClass alloc] init];});return instance;}
我们不妨分析一下 dispatch_once 的源码:
voiddispatch_once(dispatch_once_t *val, dispatch_block_t block){dispatch_once_f(val, block, _dispatch_Block_invoke(block));}// 展开 dispatch_once_fvoiddispatch_once_f(dispatch_once_t *val, void *ctxt, dispatch_function_t func){dispatch_once_gate_t l = (dispatch_once_gate_t)val;#if !DISPATCH_ONCE_INLINE_FASTPATH || DISPATCH_ONCE_USE_QUIESCENT_COUNTERuintptr_t v = os_atomic_load(&l->dgo_once, acquire);if (likely(v == DLOCK_ONCE_DONE)) {return;}#if DISPATCH_ONCE_USE_QUIESCENT_COUNTERif (likely(DISPATCH_ONCE_IS_GEN(v))) {return _dispatch_once_mark_done_if_quiesced(l, v);}#endif#endifif (_dispatch_once_gate_tryenter(l)) {return _dispatch_once_callout(l, ctxt, func);}return _dispatch_once_wait(l);}// 如果 os_atomic_load 为 DLOCK_ONCE_DONE 则直接返回,否则进入_dispatch_once_gate_tryenter,在这里首先判断对象是否存储过,如果存储过则则标记为 unlockstatic inline bool_dispatch_once_gate_tryenter(dispatch_once_gate_t l){return os_atomic_cmpxchg(&l->dgo_once, DLOCK_ONCE_UNLOCKED,(uintptr_t)_dispatch_lock_value_for_self(), relaxed);}// 如果没有存储过则执行 _dispatch_once_callout,主要是执行 blockstatic void_dispatch_once_callout(dispatch_once_gate_t l, void *ctxt,dispatch_function_t func){_dispatch_client_callout(ctxt, func);_dispatch_once_gate_broadcast(l);}// 执行过 block 则调用 _dispatch_once_gate_broadcaststatic inline void_dispatch_once_gate_broadcast(dispatch_once_gate_t l){dispatch_lock value_self = _dispatch_lock_value_for_self();uintptr_t v;#if DISPATCH_ONCE_USE_QUIESCENT_COUNTERv = _dispatch_once_mark_quiescing(l);#elsev = _dispatch_once_mark_done(l);#endifif (likely((dispatch_lock)v == value_self)) return;_dispatch_gate_broadcast_slow(&l->dgo_gate, (dispatch_lock)v);}// 在 _dispatch_once_gate_broadcast 中由于执行完毕,使用_dispatch_once_mark_done 标记为 donestatic inline uintptr_t_dispatch_once_mark_done(dispatch_once_gate_t dgo){return os_atomic_xchg(&dgo->dgo_once, DLOCK_ONCE_DONE, release);}
4、信号量 dispatch_semaphore
信号量是线程同步操作中很常用的一个操作,常用的几个类型:
- dispatch_semaphore_t:信号量类型
- dispatch_semaphore_create:创建一个信号量
- dispatch_semaphore_wait:发送一个等待信号,信号量-1,当信号量为0阻塞线程,大于0则开始执行后面的逻辑(也就是说执行
dispatch_semaphore_wait前如果信号量 <=0 则阻塞,否则正常执行后面的逻辑) - dispatch_semaphore_signal:发送唤醒信号,信号量会+1
比如我们有个操作 run() 在异步线程已经开始执行,同时可能用户会手动再次触发动作 watch(),但是 watch 依赖 run 完成则可以使用信号量:
- (void)run {dispatch_semaphore_t semaphore = dispatch_semaphore_create(0);dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{// 这里执行其他任务。。。// TODO:// 执行完发送信号dispatch_semaphore_signal(semaphore);});self->semaphore = semaphore;}- (void)watch {// 等待上面的操作完成,如果60s还没有完成则超时继续执行下面的逻辑dispatch_semaphore_wait(self.semaphore, dispatch_time(DISPATCH_TIME_NOW, 60*NSEC_PER_SEC));// 这里执行其他任务。。。但是依赖上面的操作完成// TODO:}
那么信号量是如何实现的呢,不妨看一下它的源码:
// 首先看一下 dispatch_semaphore_t,没错和上面一样本质就是 dispatch_semaphore_s,dsema_value 代表当前信号量,dsema_orig 表示初始信号量DISPATCH_CLASS_DECL(semaphore, OBJECT);struct dispatch_semaphore_s {DISPATCH_OBJECT_HEADER(semaphore);long volatile dsema_value;long dsema_orig;_dispatch_sema4_t dsema_sema;};// 查看 dispatch_semaphore_create 源码,其实并不复杂创建分配 DISPATCH_VTABLE 结构的空间,设置初始信号量,但是可以清楚的看到同样指定了目标队列,这是一个优先级为 DISPATCH_QUEUE_PRIORITY_DEFAULT 的非过载队列dispatch_semaphore_tdispatch_semaphore_create(long value){dispatch_semaphore_t dsema;// If the internal value is negative, then the absolute of the value is// equal to the number of waiting threads. Therefore it is bogus to// initialize the semaphore with a negative value.if (value < 0) {return DISPATCH_BAD_INPUT;}dsema = _dispatch_object_alloc(DISPATCH_VTABLE(semaphore),sizeof(struct dispatch_semaphore_s));dsema->do_next = DISPATCH_OBJECT_LISTLESS;dsema->do_targetq = _dispatch_get_default_queue(false);dsema->dsema_value = value;_dispatch_sema4_init(&dsema->dsema_sema, _DSEMA4_POLICY_FIFO);dsema->dsema_orig = value;return dsema;}// 下面看一下 dispatch_semaphore_wait,首先 os_atomic_dec2o 信号量减一,当然递减之后信号量大于等于0它其实什么也不做继续执行就好了,但是如果不满足执行 _dispatch_semaphore_wait_slow 等待信号量唤醒或者 timeout 超时longdispatch_semaphore_wait(dispatch_semaphore_t dsema, dispatch_time_t timeout){long value = os_atomic_dec2o(dsema, dsema_value, acquire);if (likely(value >= 0)) {return 0;}return _dispatch_semaphore_wait_slow(dsema, timeout);}// 看一下 _dispatch_semaphore_wait_slow 源码,这里首先对于两种极端情况:如果是 DISPATCH_TIME_NOW 则执行信号量 +1 并返回超时信号,DISPATCH_TIME_FOREVER 则一直等待,默认则调用 _dispatch_sema4_timedwaitstatic long_dispatch_semaphore_wait_slow(dispatch_semaphore_t dsema,dispatch_time_t timeout){long orig;_dispatch_sema4_create(&dsema->dsema_sema, _DSEMA4_POLICY_FIFO);switch (timeout) {default:if (!_dispatch_sema4_timedwait(&dsema->dsema_sema, timeout)) {break;}// Fall through and try to undo what the fast path did to// dsema->dsema_valuecase DISPATCH_TIME_NOW:orig = dsema->dsema_value;while (orig < 0) {if (os_atomic_cmpxchgvw2o(dsema, dsema_value, orig, orig + 1,&orig, relaxed)) {return _DSEMA4_TIMEOUT();}}// Another thread called semaphore_signal().// Fall through and drain the wakeup.case DISPATCH_TIME_FOREVER:_dispatch_sema4_wait(&dsema->dsema_sema);break;}return 0;}// 查看 _dispatch_sema4_timedwait 调用 mach 的内核函数semaphore_timedwait 等待收到信号直至超时bool_dispatch_sema4_timedwait(_dispatch_sema4_t *sema, dispatch_time_t timeout){mach_timespec_t _timeout;kern_return_t kr;do {uint64_t nsec = _dispatch_timeout(timeout);_timeout.tv_sec = (__typeof__(_timeout.tv_sec))(nsec / NSEC_PER_SEC);_timeout.tv_nsec = (__typeof__(_timeout.tv_nsec))(nsec % NSEC_PER_SEC);kr = semaphore_timedwait(*sema, _timeout);} while (unlikely(kr == KERN_ABORTED));if (kr == KERN_OPERATION_TIMED_OUT) {return true;}DISPATCH_SEMAPHORE_VERIFY_KR(kr);return false;}// 最后看一下 dispatch_semaphore_signal,首先信号量 +1,如果信号量大于 0 就什么也不做(通常到了这里 dispatch_semaphore_wait 还没调用),否则执行 _dispatch_semaphore_signal_slowlongdispatch_semaphore_signal(dispatch_semaphore_t dsema){long value = os_atomic_inc2o(dsema, dsema_value, release);if (likely(value > 0)) {return 0;}if (unlikely(value == LONG_MIN)) {DISPATCH_CLIENT_CRASH(value,"Unbalanced call to dispatch_semaphore_signal()");}return _dispatch_semaphore_signal_slow(dsema);}// 查看 _dispatch_semaphore_signal_slow,调用内核 semaphore_signal 唤醒线程,如 Apple Api 描述 “如果唤醒线程则返回非0,否则返回0”。long_dispatch_semaphore_signal_slow(dispatch_semaphore_t dsema){_dispatch_sema4_create(&dsema->dsema_sema, _DSEMA4_POLICY_FIFO);_dispatch_sema4_signal(&dsema->dsema_sema, 1);return 1;}// 查看 _dispatch_sema4_signal 源码void_dispatch_sema4_signal(_dispatch_sema4_t *sema, long count){do {int ret = sem_post(sema);DISPATCH_SEMAPHORE_VERIFY_RET(ret);} while (--count);}
信号量是一个比较重要的内容,合理使用可以让你的程序更加的优雅,比如说一个常见的情况:大家知道
PHImageManager.requestImage是一个释放消耗内存的方法,有时我们需要批量获取到图片执行一些操作的话可能就没办法直接for循环,不然内存会很快爆掉,因为每个requestImage操作都需要占用大量内存,即使外部嵌套autoreleasepool也不一定可以及时释放(想想 for 执行的速度,释放肯定来不及),那么requestImage又是一个异步操作,如此只能让一个操作执行完再执行另一个循环操作才能解决。也就是说这个问题就变成 for 循环内部的异步操作串行执行的问题。要解决这个问题有几种思路: 1.使用requestImage的同步请求照片 2.使用递归操作一个操作执行完再执行另外一个操作移除 for 操作 3.使用信号量解决。 当然第一个方法并非普适,有些异步操作并不能轻易改成同步操作,第二个方法相对普适,但是递归调用本身因为要改变原来的代码结构看起来不是那么优雅,自然当前讨论的信号量是更好的方式。我们假设requestImage是一个watch(callback:((_ image)-> Void))操作,整个请求是一个run(callback:((_ images)->Void))那么它的实现方式如下:
- (void)run:(CallbackWithImages)callback {dispatch_queue_t globalQueue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);dispatch_semaphore_t semaphore = dispatch_semaphore_create(0);dispatch_async(globalQueue, ^{NSMutableArray *array = [[NSMutableArray alloc] init];for (int i=0; i<100; ++i) {[self watch:^(UIImage *image){[array addObject:image];dispatch_semaphore_signal(semaphore);}];dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER);}dispatch_async(dispatch_get_main_queue(), ^{callback([array copy]);});});}- (void)watch:(CallbackWithImage)callback {dispatch_queue_t globalQueue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);dispatch_async(globalQueue, ^{callback([UIImage new]);});}
5、调度组 dispatch_group
dispatch_group 常常用来同步多个任务(注意和 dispatch_barrier_sync 不同的是它可以是多个队列的同步),所以其实上面先分析 dispatch_semaphore 也是这个原因,它本身是依靠信号量来完成的同步管理。典型的用法如下:
dispatch_queue_t globalQueue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);dispatch_group_t group = dispatch_group_create();dispatch_group_async(group, globalQueue, ^{sleep(10);NSLog(@"任务1完成");});dispatch_group_async(group, globalQueue, ^{NSLog(@"任务2完成");});dispatch_group_notify(group, globalQueue, ^{NSLog(@"两个任务全部完成");});dispatch_async(globalQueue, ^{// 等待5s超时后继续执行,此时dispatch_group中的任务未必全部完成,注意:dispatch_group_wait是同步操作必须放到异步队列否则阻塞当前线程dispatch_group_wait(group, dispatch_time(DISPATCH_TIME_NOW, 5*NSEC_PER_SEC));NSLog(@"等待到了上限,开始执行。。。");});
下面看一下 dispatch_group 相关的源码:
// 和其他对象一样,dispatch_group_t 的本质就是 dispatch_group_s 指针,这里重点关注一下 dg_state 和 dg_bits 是一个计数器struct dispatch_group_s {DISPATCH_OBJECT_HEADER(group);DISPATCH_UNION_LE(uint64_t volatile dg_state,uint32_t dg_bits,uint32_t dg_gen) DISPATCH_ATOMIC64_ALIGN;struct dispatch_continuation_s *volatile dg_notify_head;struct dispatch_continuation_s *volatile dg_notify_tail;};// 查看 dispatch_group_createdispatch_group_tdispatch_group_create(void){return _dispatch_group_create_with_count(0);}// 展开 _dispatch_group_create_with_count,其实就是一个dispatch_group_s 对象,指定了 do_targetq 是默认队列并且不支持过载static inline dispatch_group_t_dispatch_group_create_with_count(uint32_t n){dispatch_group_t dg = _dispatch_object_alloc(DISPATCH_VTABLE(group),sizeof(struct dispatch_group_s));dg->do_next = DISPATCH_OBJECT_LISTLESS;dg->do_targetq = _dispatch_get_default_queue(false);if (n) {os_atomic_store2o(dg, dg_bits,(uint32_t)-n * DISPATCH_GROUP_VALUE_INTERVAL, relaxed);os_atomic_store2o(dg, do_ref_cnt, 1, relaxed); // <rdar://22318411>}return dg;}// 首先看一下 dispatch_group_enter,它的核心就是 os_atomic_sub_orig2o 对 dg_bits 进行 -1 操作voiddispatch_group_enter(dispatch_group_t dg){// The value is decremented on a 32bits wide atomic so that the carry// for the 0 -> -1 transition is not propagated to the upper 32bits.uint32_t old_bits = os_atomic_sub_orig2o(dg, dg_bits,DISPATCH_GROUP_VALUE_INTERVAL, acquire);uint32_t old_value = old_bits & DISPATCH_GROUP_VALUE_MASK;if (unlikely(old_value == 0)) {_dispatch_retain(dg); // <rdar://problem/22318411>}if (unlikely(old_value == DISPATCH_GROUP_VALUE_MAX)) {DISPATCH_CLIENT_CRASH(old_bits,"Too many nested calls to dispatch_group_enter()");}}// 然后看一下 dispatch_group_leave,核心就是 os_atomic_add_orig2o 执行 dg_state+1 操作,如果 +1 之后还等于 0 那么说明之前没有调用dispatch_group_enter,就里会 crash,当然这里核心在 _dispatch_group_wakevoiddispatch_group_leave(dispatch_group_t dg){// The value is incremented on a 64bits wide atomic so that the carry for// the -1 -> 0 transition increments the generation atomically.uint64_t new_state, old_state = os_atomic_add_orig2o(dg, dg_state,DISPATCH_GROUP_VALUE_INTERVAL, release);uint32_t old_value = (uint32_t)(old_state & DISPATCH_GROUP_VALUE_MASK);if (unlikely(old_value == DISPATCH_GROUP_VALUE_1)) {old_state += DISPATCH_GROUP_VALUE_INTERVAL;do {new_state = old_state;if ((old_state & DISPATCH_GROUP_VALUE_MASK) == 0) {new_state &= ~DISPATCH_GROUP_HAS_WAITERS;new_state &= ~DISPATCH_GROUP_HAS_NOTIFS;} else {// If the group was entered again since the atomic_add above,// we can't clear the waiters bit anymore as we don't know for// which generation the waiters are fornew_state &= ~DISPATCH_GROUP_HAS_NOTIFS;}if (old_state == new_state) break;} while (unlikely(!os_atomic_cmpxchgv2o(dg, dg_state,old_state, new_state, &old_state, relaxed)));return _dispatch_group_wake(dg, old_state, true);}if (unlikely(old_value == 0)) {DISPATCH_CLIENT_CRASH((uintptr_t)old_value,"Unbalanced call to dispatch_group_leave()");}}// 查看 _dispatch_group_wake 源码,到了这里通常就是出了调度组,如果有 notify 等待则执行 notify 遍历并且在对应队列中执行,如果有 wait 任务则唤醒其执行任务(注意这里比较牛叉的 _dispatch_wake_by_address 可以根据地址进行函数调用,本身是调用的 WakeByAddressAll 这个系统调用)static void_dispatch_group_wake(dispatch_group_t dg, uint64_t dg_state, bool needs_release){uint16_t refs = needs_release ? 1 : 0; // <rdar://problem/22318411>if (dg_state & DISPATCH_GROUP_HAS_NOTIFS) {dispatch_continuation_t dc, next_dc, tail;// Snapshot before anything is notified/woken <rdar://problem/8554546>dc = os_mpsc_capture_snapshot(os_mpsc(dg, dg_notify), &tail);do {dispatch_queue_t dsn_queue = (dispatch_queue_t)dc->dc_data;next_dc = os_mpsc_pop_snapshot_head(dc, tail, do_next);_dispatch_continuation_async(dsn_queue, dc,_dispatch_qos_from_pp(dc->dc_priority), dc->dc_flags);_dispatch_release(dsn_queue);} while ((dc = next_dc));refs++;}if (dg_state & DISPATCH_GROUP_HAS_WAITERS) {_dispatch_wake_by_address(&dg->dg_gen);}if (refs) _dispatch_release_n(dg, refs);}// 查看 dispatch_group_async 源码,dispatch_continuation_t 仅仅是封装任务,核心是 _dispatch_continuation_group_asyncvoiddispatch_group_async(dispatch_group_t dg, dispatch_queue_t dq,dispatch_block_t db){dispatch_continuation_t dc = _dispatch_continuation_alloc();uintptr_t dc_flags = DC_FLAG_CONSUME | DC_FLAG_GROUP_ASYNC;dispatch_qos_t qos;qos = _dispatch_continuation_init(dc, dq, db, 0, dc_flags);_dispatch_continuation_group_async(dg, dq, dc, qos);}// 展开 _dispatch_continuation_group_async,这里重点记住 dispatch_group_enter() 方法,至于 _dispatch_continuation_async 前面已经介绍过static inline void_dispatch_continuation_group_async(dispatch_group_t dg, dispatch_queue_t dq,dispatch_continuation_t dc, dispatch_qos_t qos){dispatch_group_enter(dg);dc->dc_data = dg;_dispatch_continuation_async(dq, dc, qos, dc->dc_flags);}// 继续查看 dispatch_group_notify,注意这里将 dispatch_block_t 存储到了共享数据 dispatch_continuation_t 中voiddispatch_group_notify(dispatch_group_t dg, dispatch_queue_t dq,dispatch_block_t db){dispatch_continuation_t dsn = _dispatch_continuation_alloc();_dispatch_continuation_init(dsn, dq, db, 0, DC_FLAG_CONSUME);_dispatch_group_notify(dg, dq, dsn);}// 展开 _dispatch_group_notify,其实最主要的方法就是 _dispatch_group_wakestatic inline void_dispatch_group_notify(dispatch_group_t dg, dispatch_queue_t dq,dispatch_continuation_t dsn){uint64_t old_state, new_state;dispatch_continuation_t prev;dsn->dc_data = dq;_dispatch_retain(dq);prev = os_mpsc_push_update_tail(os_mpsc(dg, dg_notify), dsn, do_next);if (os_mpsc_push_was_empty(prev)) _dispatch_retain(dg);os_mpsc_push_update_prev(os_mpsc(dg, dg_notify), prev, dsn, do_next);if (os_mpsc_push_was_empty(prev)) {os_atomic_rmw_loop2o(dg, dg_state, old_state, new_state, release, {new_state = old_state | DISPATCH_GROUP_HAS_NOTIFS;if ((uint32_t)old_state == 0) {os_atomic_rmw_loop_give_up({return _dispatch_group_wake(dg, new_state, false);});}});}}
简单的说就是 dispatch_group_async 和 dispatch_group_notify 本身就是和 dispatch_group_enter、dispatch_group_leave 没有本质区别,后者相对更加灵活。当然这里还有一个重要的操作就是dispatch_group_wait,还没有看:
// os_atomic_rmw_loop2o 不断遍历,如果 (old_state & DISPATCH_GROUP_VALUE_MASK) == 0 表示执行完,直接返回 0,如果当前如果超时立即返回,其他情况调用 _dispatch_group_wait_slowlongdispatch_group_wait(dispatch_group_t dg, dispatch_time_t timeout){uint64_t old_state, new_state;os_atomic_rmw_loop2o(dg, dg_state, old_state, new_state, relaxed, {if ((old_state & DISPATCH_GROUP_VALUE_MASK) == 0) {os_atomic_rmw_loop_give_up_with_fence(acquire, return 0);}if (unlikely(timeout == 0)) {os_atomic_rmw_loop_give_up(return _DSEMA4_TIMEOUT());}new_state = old_state | DISPATCH_GROUP_HAS_WAITERS;if (unlikely(old_state & DISPATCH_GROUP_HAS_WAITERS)) {os_atomic_rmw_loop_give_up(break);}});return _dispatch_group_wait_slow(dg, _dg_state_gen(new_state), timeout);}// 查看 _dispatch_group_wait_slow,最终调用_dispatch_wait_on_address 直至 __ulock_waitstatic long_dispatch_group_wait_slow(dispatch_group_t dg, uint32_t gen,dispatch_time_t timeout){for (;;) {int rc = _dispatch_wait_on_address(&dg->dg_gen, gen, timeout, 0);if (likely(gen != os_atomic_load2o(dg, dg_gen, acquire))) {return 0;}if (rc == ETIMEDOUT) {return _DSEMA4_TIMEOUT();}}}
6、延迟执行 dispatch_after
dispatch_after 也是一个常用的延迟执行的方法,比如常见的使用方法是:
dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(1.0 * NSEC_PER_SEC)), dispatch_get_main_queue(), ^{NSLog(@"...");});
在查看 dispatch_after 源码之前先看一下另一个内容事件源 dispatch_source_t,其实 dispatch_source_t 是一个很少让开发者和 GCD 联想到一起的一个类型,它本身也有对应的创建方法 dispatch_source_create(事实上它的使用甚至可以追踪到 Runloop)。多数开发者认识 dispatch_source_t 都是通过定时器,很多文章会教你如何创建一个比较准确的定时器,比如下面的代码:
dispatch_source_t timerSource = dispatch_source_create(DISPATCH_SOURCE_TYPE_TIMER, 0, 0, dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0));dispatch_source_set_timer(timerSource, dispatch_time(DISPATCH_TIME_NOW, 0), 3*NSEC_PER_SEC, 0);dispatch_source_set_event_handler(timerSource, ^{NSLog(@"dispatch_source_t...");});dispatch_resume(timerSource);self.source = timerSource;
如果你知道上面一个定时器如何执行的那么下面看一下 dispatch_after 应该就比较容易明白了:
voiddispatch_after(dispatch_time_t when, dispatch_queue_t queue,dispatch_block_t work){_dispatch_after(when, queue, NULL, work, true);}// 查看 _dispatch_afterstatic inline void_dispatch_after(dispatch_time_t when, dispatch_queue_t dq,void *ctxt, void *handler, bool block){dispatch_timer_source_refs_t dt;dispatch_source_t ds;uint64_t leeway, delta;if (when == DISPATCH_TIME_FOREVER) {#if DISPATCH_DEBUGDISPATCH_CLIENT_CRASH(0, "dispatch_after called with 'when' == infinity");#endifreturn;}delta = _dispatch_timeout(when);if (delta == 0) {if (block) {return dispatch_async(dq, handler);}return dispatch_async_f(dq, ctxt, handler);}leeway = delta / 10; // <rdar://problem/13447496>if (leeway < NSEC_PER_MSEC) leeway = NSEC_PER_MSEC;if (leeway > 60 * NSEC_PER_SEC) leeway = 60 * NSEC_PER_SEC;// this function can and should be optimized to not use a dispatch sourceds = dispatch_source_create(&_dispatch_source_type_after, 0, 0, dq);dt = ds->ds_timer_refs;dispatch_continuation_t dc = _dispatch_continuation_alloc();if (block) {_dispatch_continuation_init(dc, dq, handler, 0, 0);} else {_dispatch_continuation_init_f(dc, dq, ctxt, handler, 0, 0);}// reference `ds` so that it doesn't show up as a leakdc->dc_data = ds;_dispatch_trace_item_push(dq, dc);os_atomic_store2o(dt, ds_handler[DS_EVENT_HANDLER], dc, relaxed);dispatch_clock_t clock;uint64_t target;_dispatch_time_to_clock_and_value(when, &clock, &target);if (clock != DISPATCH_CLOCK_WALL) {leeway = _dispatch_time_nano2mach(leeway);}dt->du_timer_flags |= _dispatch_timer_flags_from_clock(clock);dt->dt_timer.target = target;dt->dt_timer.interval = UINT64_MAX;dt->dt_timer.deadline = target + leeway;dispatch_activate(ds);}
代码并不是太复杂,无时间差则直接调用 dispatch_async,否则先创建一个dispatch_source_t,不同的是这里的类型并不是 DISPATCH_SOURCE_TYPE_TIMER 而是 _dispatch_source_type_after,查看源码不难发现它只是 dispatch_source_type_s 类型的一个常量和 _dispatch_source_type_timer 并没有明显区别:
const dispatch_source_type_s _dispatch_source_type_after = {.dst_kind = "timer (after)",.dst_filter = DISPATCH_EVFILT_TIMER_WITH_CLOCK,.dst_flags = EV_DISPATCH,.dst_mask = 0,.dst_timer_flags = DISPATCH_TIMER_AFTER,.dst_action = DISPATCH_UNOTE_ACTION_SOURCE_TIMER,.dst_size = sizeof(struct dispatch_timer_source_refs_s),.dst_create = _dispatch_source_timer_create,.dst_merge_evt = _dispatch_source_merge_evt,};
而 dispatch_activate() 其实和 dispatch_resume() 是一样的开启定时器。那么为什么看不到 dispatch_source_set_event_handler 来给 timer 设置 handler 呢?不妨看一下 dispatch_source_set_event_handler 的源代码:
voiddispatch_source_set_event_handler(dispatch_source_t ds,dispatch_block_t handler){_dispatch_source_set_handler(ds, handler, DS_EVENT_HANDLER, true);}// 查看 _dispatch_source_set_handlerstatic void_dispatch_source_set_handler(dispatch_source_t ds, void *func,uintptr_t kind, bool is_block){dispatch_continuation_t dc;dc = _dispatch_source_handler_alloc(ds, func, kind, is_block);if (_dispatch_lane_try_inactive_suspend(ds)) {_dispatch_source_handler_replace(ds, kind, dc);return _dispatch_lane_resume(ds, DISPATCH_RESUME);}dispatch_queue_flags_t dqf = _dispatch_queue_atomic_flags(ds);if (unlikely(dqf & DSF_STRICT)) {DISPATCH_CLIENT_CRASH(kind, "Cannot change a handler of this source ""after it has been activated");}// Ignore handlers mutations past cancelation, it's harmlessif ((dqf & DSF_CANCELED) == 0) {_dispatch_ktrace1(DISPATCH_PERF_post_activate_mutation, ds);if (kind == DS_REGISTN_HANDLER) {_dispatch_bug_deprecated("Setting registration handler after ""the source has been activated");} else if (func == NULL) {_dispatch_bug_deprecated("Clearing handler after ""the source has been activated");}}dc->dc_data = (void *)kind;_dispatch_barrier_trysync_or_async_f(ds, dc,_dispatch_source_set_handler_slow, 0);}
可以看到最终还是封装成一个 dispatch_continuation_t 进行同步或者异步调用,而上面 _dispatch_after 直接构建了 dispatch_continuation_t 进行执行。
取消延迟执行的任务
使用 dispatch_after 还有一个问题就是取消问题,当然通常遇到了这种问题大部分答案就是使用下面的方式:
[self performSelector:@selector(myDelayedMethod) withObject: self afterDelay: desiredDelay];[NSObject cancelPreviousPerformRequestsWithTarget: self selector:@selector(myDelayedMethod) object: self];
不过如果你使用的是 iOS 8 及其以上的版本,那么其实是可以取消的(如下),当然如果你还在支持 iOS 8以下 的版本不妨试试这个自定义的dispatch_cancelable_block_t类:
dispatch_block_t block = dispatch_block_create(DISPATCH_BLOCK_INHERIT_QOS_CLASS, ^{NSLog(@"dispatch_after...");});dispatch_after(dispatch_time(DISPATCH_TIME_NOW, 3*NSEC_PER_SEC), dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), block);// 取消dispatch_block_cancel(block);
7、dispatch_apply
dispatch_apply 设计的主要目的是提高并行能力,所以一般我们用来并行执行多个结构类似的任务,比如:
voiddispatch_apply(size_t iterations, dispatch_queue_t dq, void (^work)(size_t)){dispatch_apply_f(iterations, dq, work,(dispatch_apply_function_t)_dispatch_Block_invoke(work));}// 查看 dispatch_apply_f,对于 width=1 或者单核心数cpu其实这个是一个同步调用,核心方法就是 _dispatch_apply_fvoiddispatch_apply_f(size_t iterations, dispatch_queue_t _dq, void *ctxt,void (*func)(void *, size_t)){if (unlikely(iterations == 0)) {return;}dispatch_thread_context_t dtctxt =_dispatch_thread_context_find(_dispatch_apply_key);size_t nested = dtctxt ? dtctxt->dtc_apply_nesting : 0;dispatch_queue_t old_dq = _dispatch_queue_get_current();dispatch_queue_t dq;if (likely(_dq == DISPATCH_APPLY_AUTO)) {dq = _dispatch_apply_root_queue(old_dq)->_as_dq;} else {dq = _dq; // silence clang Nullability complaints}dispatch_qos_t qos = _dispatch_priority_qos(dq->dq_priority) ?:_dispatch_priority_fallback_qos(dq->dq_priority);if (unlikely(dq->do_targetq)) {// if the queue passed-in is not a root queue, use the current QoS// since the caller participates in the work anywayqos = _dispatch_qos_from_pp(_dispatch_get_priority());}int32_t thr_cnt = (int32_t)_dispatch_qos_max_parallelism(qos,DISPATCH_MAX_PARALLELISM_ACTIVE);if (likely(!nested)) {nested = iterations;} else {thr_cnt = nested < (size_t)thr_cnt ? thr_cnt / (int32_t)nested : 1;nested = nested < DISPATCH_APPLY_MAX && iterations < DISPATCH_APPLY_MAX? nested * iterations : DISPATCH_APPLY_MAX;}if (iterations < (size_t)thr_cnt) {thr_cnt = (int32_t)iterations;}struct dispatch_continuation_s dc = {.dc_func = (void*)func,.dc_ctxt = ctxt,.dc_data = dq,};dispatch_apply_t da = (__typeof__(da))_dispatch_continuation_alloc();da->da_index = 0;da->da_todo = iterations;da->da_iterations = iterations;da->da_nested = nested;da->da_thr_cnt = thr_cnt;#if DISPATCH_INTROSPECTIONda->da_dc = _dispatch_continuation_alloc();*da->da_dc = dc;da->da_dc->dc_flags = DC_FLAG_ALLOCATED;#elseda->da_dc = &dc;#endifda->da_flags = 0;if (unlikely(dq->dq_width == 1 || thr_cnt <= 1)) {return dispatch_sync_f(dq, da, _dispatch_apply_serial);}if (unlikely(dq->do_targetq)) {if (unlikely(dq == old_dq)) {return dispatch_sync_f(dq, da, _dispatch_apply_serial);} else {return dispatch_sync_f(dq, da, _dispatch_apply_redirect);}}dispatch_thread_frame_s dtf;_dispatch_thread_frame_push(&dtf, dq);_dispatch_apply_f(upcast(dq)._dgq, da, _dispatch_apply_invoke);_dispatch_thread_frame_pop(&dtf);}// 查看 _dispatch_apply_fstatic inline void_dispatch_apply_f(dispatch_queue_global_t dq, dispatch_apply_t da,dispatch_function_t func){int32_t i = 0;dispatch_continuation_t head = NULL, tail = NULL;pthread_priority_t pp = _dispatch_get_priority();// The current thread does not need a continuationint32_t continuation_cnt = da->da_thr_cnt - 1;dispatch_assert(continuation_cnt);for (i = 0; i < continuation_cnt; i++) {dispatch_continuation_t next = _dispatch_continuation_alloc();uintptr_t dc_flags = DC_FLAG_CONSUME;_dispatch_continuation_init_f(next, dq, da, func,DISPATCH_BLOCK_HAS_PRIORITY, dc_flags);next->dc_priority = pp | _PTHREAD_PRIORITY_ENFORCE_FLAG;next->do_next = head;head = next;if (!tail) {tail = next;}}_dispatch_thread_event_init(&da->da_event);// FIXME: dq may not be the right queue for the priority of `head`_dispatch_trace_item_push_list(dq, head, tail);_dispatch_root_queue_push_inline(dq, head, tail, continuation_cnt);// Call the first element directly_dispatch_apply_invoke_and_wait(da);}// 展开 _dispatch_apply_invoke_and_waitstatic void_dispatch_apply_invoke_and_wait(void *ctxt){_dispatch_apply_invoke2(ctxt, DISPATCH_APPLY_INVOKE_WAIT);_dispatch_perfmon_workitem_inc();}// 查看 _dispatch_apply_invoke2,主要是循环使用 _dispatch_perfmon_workitem_inc 调用任务,同时在最后一个任务调用完恢复线程 _dispatch_thread_event_signalstatic inline void_dispatch_apply_invoke2(dispatch_apply_t da, long invoke_flags){size_t const iter = da->da_iterations;size_t idx, done = 0;idx = os_atomic_inc_orig2o(da, da_index, acquire);if (unlikely(idx >= iter)) goto out;// da_dc is only safe to access once the 'index lock' has been acquireddispatch_apply_function_t const func = (void *)da->da_dc->dc_func;void *const da_ctxt = da->da_dc->dc_ctxt;_dispatch_perfmon_workitem_dec(); // this unit executes many items// Handle nested dispatch_apply rdar://problem/9294578dispatch_thread_context_s apply_ctxt = {.dtc_key = _dispatch_apply_key,.dtc_apply_nesting = da->da_nested,};_dispatch_thread_context_push(&apply_ctxt);dispatch_thread_frame_s dtf;dispatch_priority_t old_dbp = 0;if (invoke_flags & DISPATCH_APPLY_INVOKE_REDIRECT) {dispatch_queue_t dq = da->da_dc->dc_data;_dispatch_thread_frame_push(&dtf, dq);old_dbp = _dispatch_set_basepri(dq->dq_priority);}dispatch_invoke_flags_t flags = da->da_flags;// Striding is the responsibility of the caller.do {dispatch_invoke_with_autoreleasepool(flags, {_dispatch_client_callout2(da_ctxt, idx, func);_dispatch_perfmon_workitem_inc();done++;idx = os_atomic_inc_orig2o(da, da_index, relaxed);});} while (likely(idx < iter));if (invoke_flags & DISPATCH_APPLY_INVOKE_REDIRECT) {_dispatch_reset_basepri(old_dbp);_dispatch_thread_frame_pop(&dtf);}_dispatch_thread_context_pop(&apply_ctxt);// The thread that finished the last workitem wakes up the possibly waiting// thread that called dispatch_apply. They could be one and the same.if (!os_atomic_sub2o(da, da_todo, done, release)) {_dispatch_thread_event_signal(&da->da_event);}out:if (invoke_flags & DISPATCH_APPLY_INVOKE_WAIT) {_dispatch_thread_event_wait(&da->da_event);_dispatch_thread_event_destroy(&da->da_event);}if (os_atomic_dec2o(da, da_thr_cnt, release) == 0) {#if DISPATCH_INTROSPECTION_dispatch_continuation_free(da->da_dc);#endif_dispatch_continuation_free((dispatch_continuation_t)da);}}
8、补充
8.1 线程和锁
在GCD中其实总共有两个线程池进行线程管理,一个是主线程池,另一个是除了主线程池之外的线程池。主线程池由序列为1的主队列管理,使用 objc.io 上的一幅图表示如下:
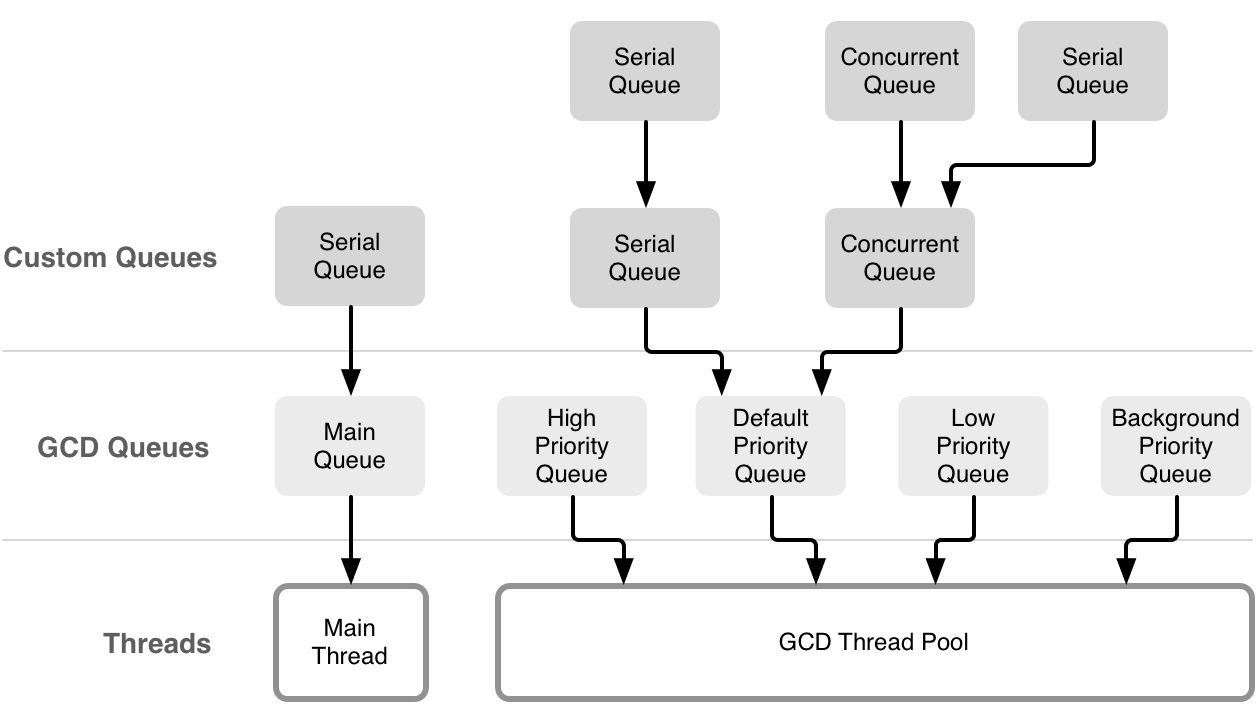
大家都知道使用 dispatch_sync 很有可能会发生死锁那么这是为什么呢?
不妨回顾一下 dispatch_sync 的过程:
dispatch_sync_dispatch_sync_f:区分并发还是串行队列,如果是串行队列_dispatch_barrier_sync_f:是不是同一个队列,如果是_dispatch_sync_f_slow
重点在 _dq_state_drain_locked_by(dq_state, dsc->dsc_waiter) 这个条件,成立则会发生死锁,那么它成立的条件就是 ((lock_value ^ tid) & DLOCK_OWNER_MASK) == 0 首先 lock_value 和 tid 进行异或操作,相同为 0 不同为 1,然后和 DLOCK_OWNER_MASK(0xfffffffc) 进行按位与操作,一个为0则是0,所以如果 lock_value 和 tid 相同则会发生死锁。
8.2 likely 和 unlikely
#define likely(x) __builtin_expect(!!(x), 1)#define unlikely(x) __builtin_expect(!!(x), 0)
看了 likely 和 unlikely 可以了解,likely 表示更大可能成立,unlikely 表示更大可能不成立。likely 就是 if(likely(x == 0)) 就是 if (x==0)。
8.3 __builtin_expect
__builtin_expect 是一个针对编译器优化的内置函数,让编译更加优化。比如说我们会写这种代码:
if a {print(a)} else {print(b)}
如果我们更加倾向于使用 a 那么可将其设为默认值,极特殊情况下才会使用 b 条件。CPU读取指定是多条一起加载的,可能先加载进来的是 a,那么如果遇到执行 b 的情况则再加载 b,那么对于条件 a 的情况就造成了性能浪费。long builtin_expect (long EXP, long C) 第一个参数是要预测变量,第二个参数是预测值,这样 builtin_expect(a,false) 说明多数情况 a 应该是false,极少数情况可能是 true,这样不至于造成性能浪费。其实对于编译器在汇编时会优化成 if !a 的形式:
if !a {print(b)} else {print(a)}
8.4 os_atomic_cmpxchg
第二个参数与第一个参数值比较,如果相等,第三个参数的值替换第一个参数的值。如果不相等,把第一个参数的值赋值到第二个参数上。
#define os_atomic_cmpxchg(p, e, v, m) \({ _os_atomic_basetypeof(p) _r = (e); \atomic_compare_exchange_strong_explicit(_os_atomic_c11_atomic(p), \&_r, v, memory_order_##m, memory_order_relaxed); })
8.5 os_atomic_store2o
将第二个参数保存到第一个参数中
#define os_atomic_store2o(p, f, v, m) \os_atomic_store(&(p)->f, (v), m)#define os_atomic_store(p, v, m) \atomic_store_explicit(_os_atomic_c11_atomic(p), v, memory_order_##m)
8.6 os_atomic_inc_orig
第一个参数赋值为1
#define os_atomic_inc_orig(p, m) \os_atomic_add_orig((p), 1, m)#define os_atomic_add_orig(p, v, m) \_os_atomic_c11_op_orig((p), (v), m, add, +)#define _os_atomic_c11_op_orig(p, v, m, o, op) \atomic_fetch_##o##_explicit(_os_atomic_c11_atomic(p), v, \memory_order_##m)
8.7 os_atomic_inc_orig2o
第二个参数加1并返回
#define os_atomic_inc_orig2o(p, f, m) \os_atomic_add_orig2o(p, f, 1, m)#define os_atomic_add_orig2o(p, f, v, m) \os_atomic_add_orig(&(p)->f, (v), m)
8.8 os_atomic_dec2o
第二个参数-1并返回
#define os_atomic_dec2o(p, f, m) \os_atomic_sub2o(p, f, 1, m)#define os_atomic_sub2o(p, f, v, m) \os_atomic_sub(&(p)->f, (v), m)

若有收获,就点个赞吧
0 人点赞
