多线程开发是日常开发任务中不可缺少的一部分,在iOS开发中常用到的多线程开发技术有GCD、NSOperation、NSThread,本文主要讲解多线系列文章中关于GCD的相关知识和使用详解。
1、GCD 简介
GCD 对于 iOS 开发者来说并不陌生,在实际开发中我们会经常用到 GCD 进行多线程的处理,那么 GCD 是什么呢?
Grand Central Dispatch(GCD) 是 Apple 开发的一个多核编程的较新的解决方法。它主要用于优化应用程序以支持多核处理器以及其他对称多处理系统。它是一个在线程池模式的基础上执行的并发任务。在 Mac OS X 10.6 雪豹中首次推出,也可在 iOS 4 及以上版本使用。
GCD有着很明显的优势,正是这些优势才使得GCD在处理多线程问题有着举足轻重的地位。
- GCD是apple为多核的并行运算提出的解决方案。
- GCD能较好的利用CPU内核资源。
- GCD不需要开发者去管理线程的生命周期。
- 使用简便,开发者只需要告诉GCD执行什么任务,并不需要编写任何线程管理代码。
2、GCD任务和队列
相信很多初级开发者会对 GCD 任务和队列之间的关系理解含糊不清,实际上队列只是提供了保存任务的容器。为了更好的理解 GCD,很有必要先了解 任务 和 队列 的概念。
2.1 GCD 任务
任务 就是需要执行的操作,是 GCD 中放在 block 中在线程中执行的那段代码。任务的执行的方式有 同步执行 和 异步执行 两中执行方式。两者的主要区别是 是否等待队列的任务执行结束,以及 是否具备开启新线程的能力。
- 同步执行(sync):同步添加任务到队列中,在队列之前的任务执行结束之前会一直等待;同步执行的任务只能在当前线程中执行,不具备开启新线程的能力。
- 异步执行(async):异步添加任务到队列中,并需要理会队列中其他的任务,添加即执行;异步执行可以在新的线程中执行,具备开启新的线程的能力。
2.2 GCD 队列
队列:队列是一种特殊的线性表,队列中允许插入操作的一端称为队尾,允许删除操作的一端称为队头,是一种先进先出的结构。

在 GCD 里面队列是指执行任务的等待队列,是用来存放任务的。按照队列的结构特性,新任务总是插入在队列的末尾,而任务的执行总是从队列的对头输出,每读取一个任务,则从队列中释放一个任务。
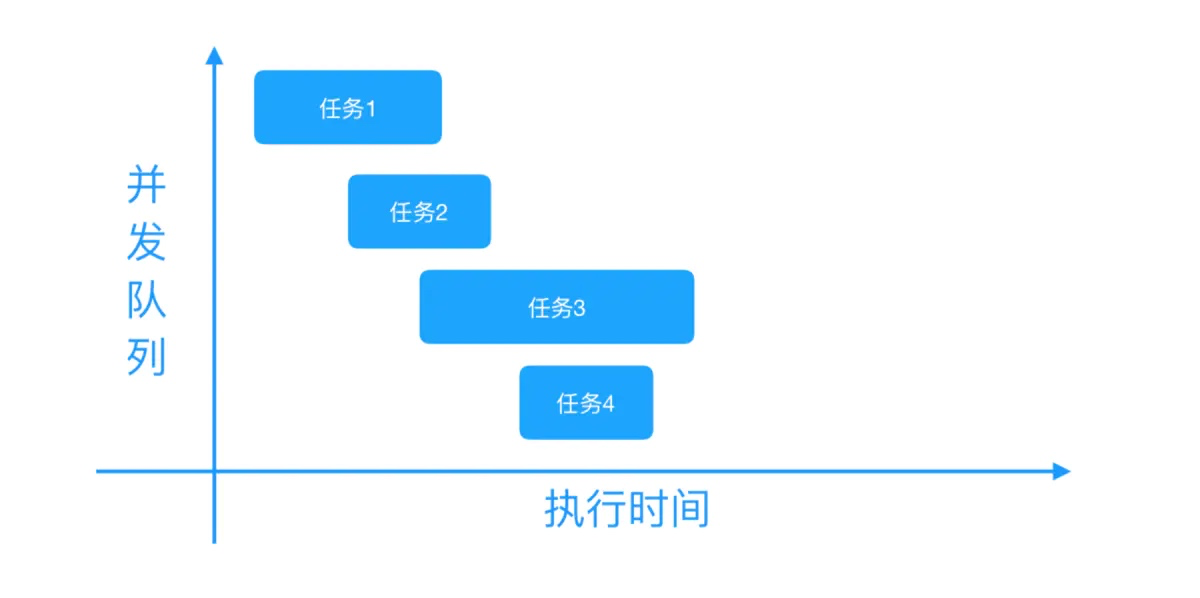
GCD的队列分为 串行队列 和 并发队列 两种,两者都符合 FIFO(先进先出) 的原则。两者的主要区别是:执行顺序不同,以及开启线程数不同。
- 串行队列:只开启一个线程,每次只能有一个任务执行,等待执行完毕后才会执行下一个任务。
- 并发队列:可以让对个任务同时执行,也就是开启多个线程,让多个任务同时执行。
两者之间区别如下图所示:

3、GCD 基本使用
GCD的使用很简单,首先创建一个队列,然后向队列中追加任务,系统会根据任务的类型执行任务。
3.1 队列的创建
- 队列的创建很简单,只需要调用
dispatch_queue_create方法传入相对应的参数便可。这个方法有两个参数:- 第一个参数表示队列的唯一标识,可以传空。
- 第二个参数用来识别是串行队列还是并发队列。
DISPATCH_QUEUE_SERIAL表示串行队列,DISPATCH_QUEUE_CONCURRENT表示并发队列。
// 创建串行队列dispatch_queue_t queue = dispatch_queue_create("com.thread.demo", DISPATCH_QUEUE_SERIAL);// 创建并发队列dispatch_queue_t queue = dispatch_queue_create("com.thread.demo", DISPATCH_QUEUE_CONCURRENT);
- GCD 默认提供一种 全局并发队列,调用
dispatch_get_global_queue方法来获取全局并发队列。这个方法需要传入两个参数。- 第一个参数是一个长整型类型的参数,表示队列优先级,有
DISPATCH_QUEUE_PRIORITY_HIGH、DISPATCH_QUEUE_PRIORITY_LOW、DISPATCH_QUEUE_PRIORITY_BACKGROUND、DISPATCH_QUEUE_PRIORITY_DEFAULT四个选项,一般用DISPATCH_QUEUE_PRIORITY_DEFAULT。 - 第二个参数暂时没用,用 0 即可。
- 第一个参数是一个长整型类型的参数,表示队列优先级,有
// 获取全局并发队列dispatch_queue_t globalQueue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
- GCD 默认提供了 主队列,调用
dispatch_get_main_queue方法获取,所有放在主队列中的任务都会在主线程中执行。主队列是一种串行队列。
// 主队列dispatch_queue_t mainQueue = dispatch_get_main_queue();
注意:主队列实质上就是一个普通的串行队列,只是因为默认情况下,当前代码是放在主队列中的,然后主队列中的代码,有都会放到主线程中去执行,所以才造成了主队列特殊的现象。
3.2 创建任务
GCD 调用 dispatch_sync 创建同步任务,调用 dispatch_async 创建异步任务。任务的内容都是在block代码块中。
//异步任务dispatch_async(queue, ^{//异步执行的代码});//同步任务dispatch_sync(queue, ^{//同步执行的代码});
创建的任务需要放在队列中去执行,同时考虑到主队列的特殊性,那么在不考虑嵌套任务的情况下就会存在同步任务+串行队列、同步任务+并发队列、异步任务+串行队列、异步任务+并发队列、主队列+同步任务、主队列+异步任务六种组合,下面我们来分析下这几种组合。
1. 同步任务+串行队列:同步任务不会开启新的线程,任务串行执行。 2. 同步任务+并发队列:同步任务不会开启新的线程,虽然任务在并发队列中,但是系统只默认开启了一个主线程,没有开启子线程,所以任务串行执行。 3. 异步任务+串行队列:异步任务有开启新的线程,任务串行执行。 4. 异步任务+并发队列:异步任务有开启新的线程,任务并发执行。 5. 主队列+同步任务:主队列是一种串行队列,任务在主线程中串行执行,将同步任务添加到主队列中会造成追加的同步任务和主线程中的任务相互等待阻塞主线程,导致死锁。 6. 主队列+异步任务:主队列是一种串行队列,任务在主线程中串行执行,即使是追加的异步任务也不会开启新的线程,任务串行执行。
除了上边提到的主队列中调用 主队列+同步任务 会导致死锁问题。实际在使用串行队列的时候,也可能出现阻塞串行队列所在线程的情况发生,从而造成死锁问题。这种情况多见于同一个串行队列的嵌套使用。
比如下面代码这样:在异步任务+串行队列的任务中,又嵌套了当前的串行队列,然后进行同步执行。
dispatch_queue_t queue = dispatch_queue_create("com.thread.demo", DISPATCH_QUEUE_SERIAL);dispatch_async(queue, ^{ // 异步任务 + 串行队列dispatch_sync(queue, ^{ // 同步任务 + 串行队列sleep(1); // 模拟耗时操作NSLog(@"1");});});
执行上面的代码会导致 串行队列中追加的任务 和 串行队列中原有的任务 两者之间相互等待,阻塞了串行队列,最终造成了串行队列所在的线程(子线程)死锁问题。主队列造成死锁也是基于这个原因,所以,这也进一步说明了主队列其实并不特殊。
3.3 GCD 的基础使用
3.3.1 同步任务+串行队列
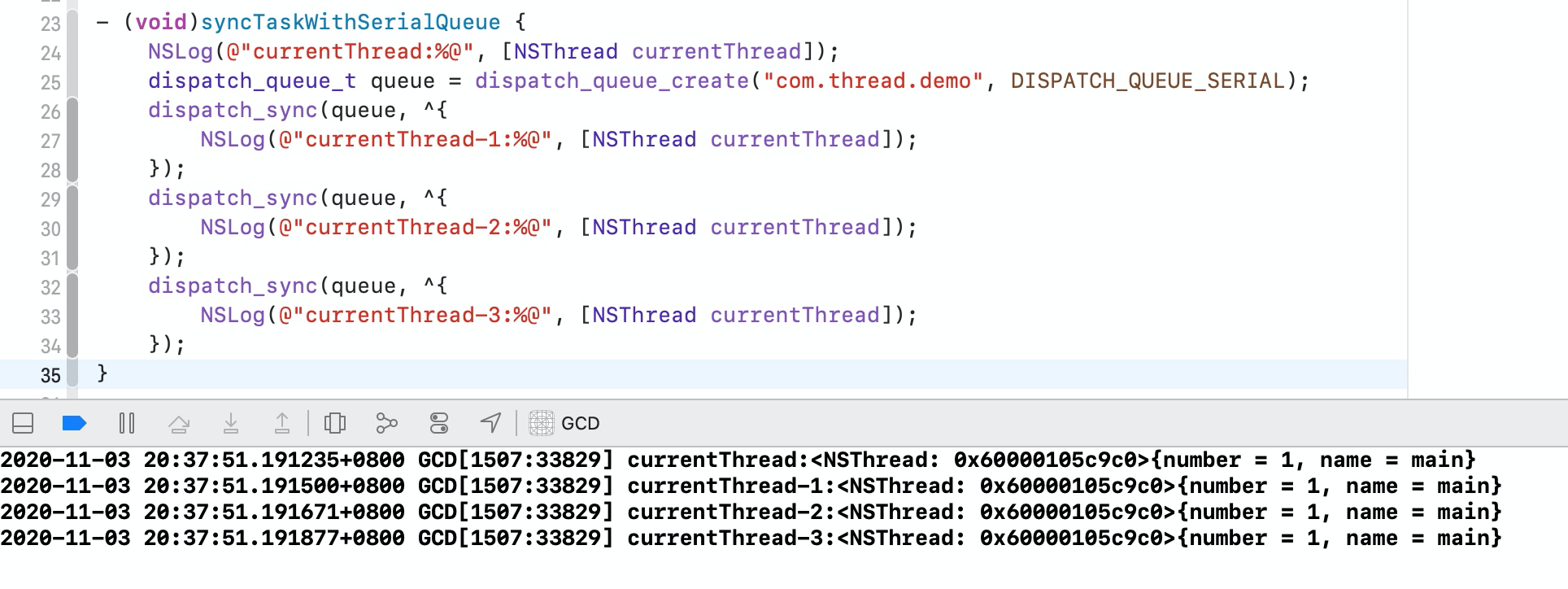
从上面代码运行的结果可以看出,并没有开启新的线程,任务是按顺序执行的。
3.3.2 同步任务+并发队列
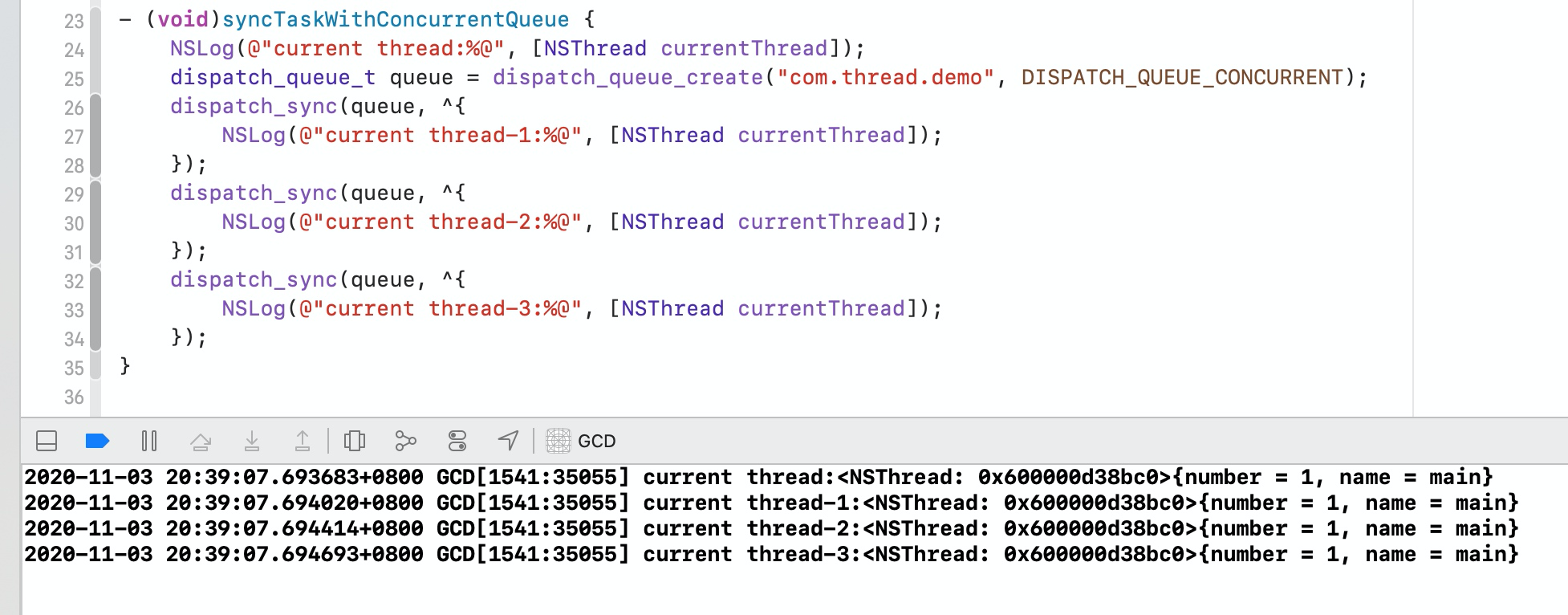
从上面代码运行的结果可以看出,同步任务不会开启新的线程,虽然任务在并发队列中,但是系统只默认开启了一个主线程,没有开启子线程,所以任务串行执行。
3.3.3 异步任务+串行队列
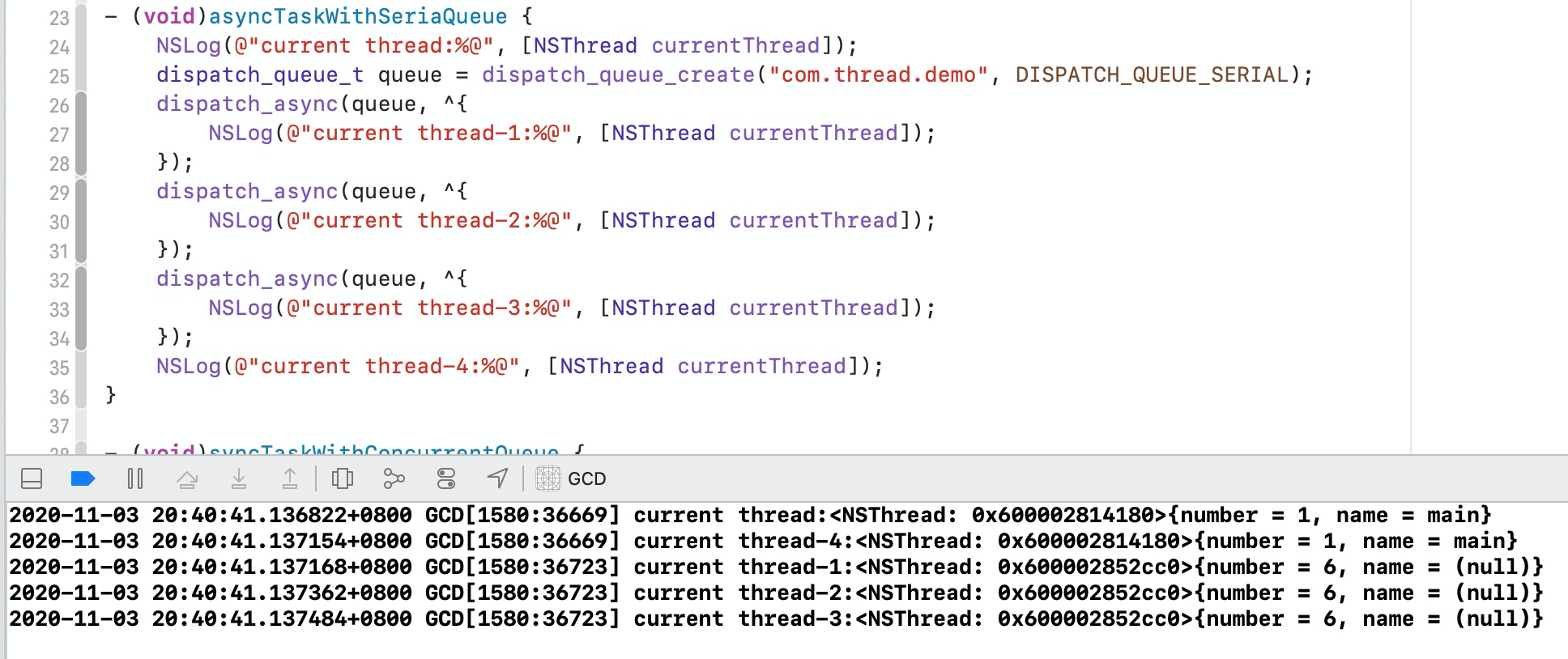
从上面代码运行的结果可以看出,开启了一个新的线程,说明异步任务具备开启新的线程的能力,但是由于任务是在串行队列中执行的,所以任务是顺序执行的。
3.3.4 异步任务+并发队列
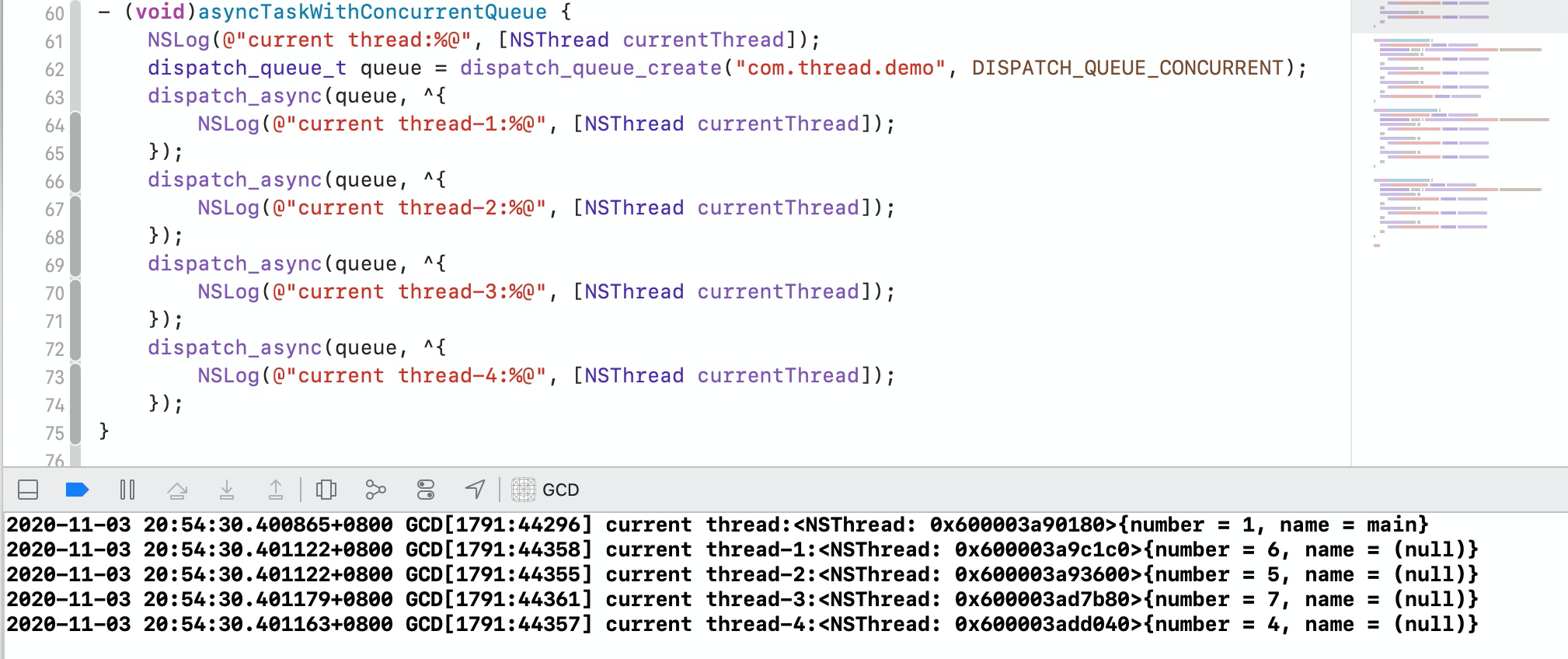
从上面代码的运行结果可以看出,生成了多个线程,并且任务是随机执行(并发执行)的。
3.3.5 主队列+同步任务
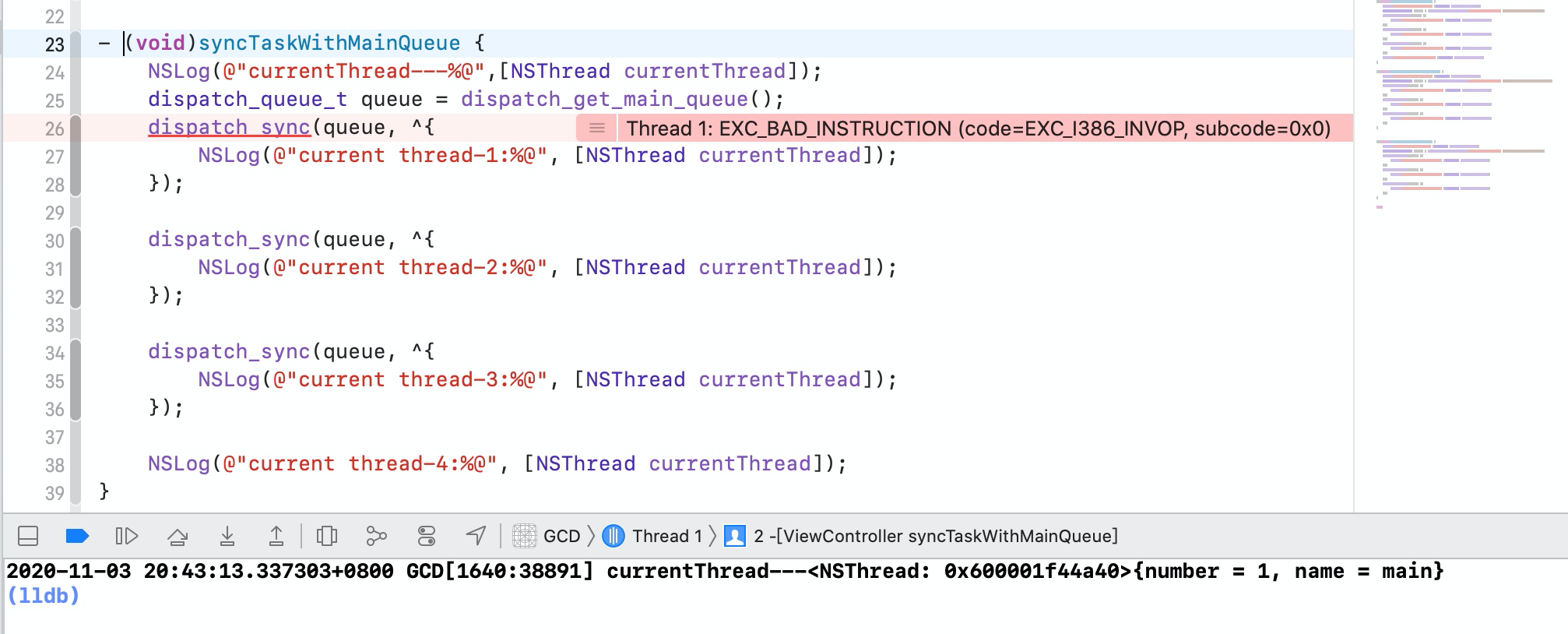
很明显上面这段代码运行崩溃了,这是因为我们在主线程中执行 syncTaskWithMainQueue 方法,相当于把 syncTaskWithMainQueue 任务放到了主线程的队列中。而 同步执行 会等待当前队列中的任务执行完毕,才会接着执行。那么当我们把 任务1 追加到主队列中,任务1 就在等待主线程处理完 syncTaskWithMainQueue 任务。而 syncMain 任务需要等待 任务1 执行完毕,这样就形成了相互等待的情况,产生了死锁。
3.3.6 主队列+异步任务

从上面代码的运行结果可以看出,虽然是异步任务,但是并没有开启新的线程,任然是在主线程中执行,并且任务是顺序执行的。
4、GCD源码分析
4.1 队列是如何产生的?
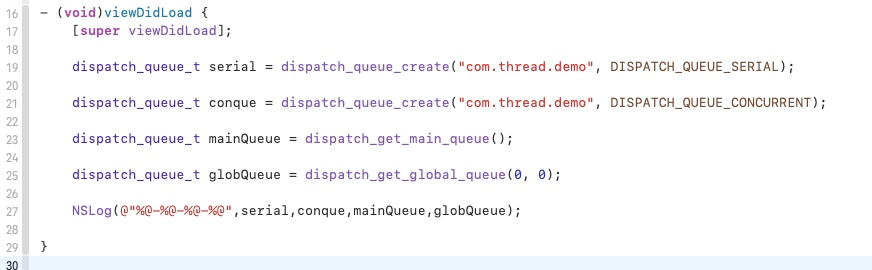
我们给 dispatch_queue_create 下个符号断点,看它是属于哪个系统库的
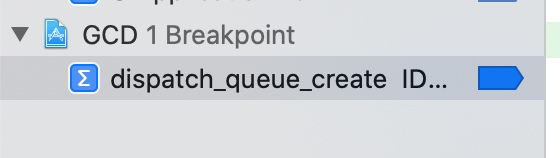
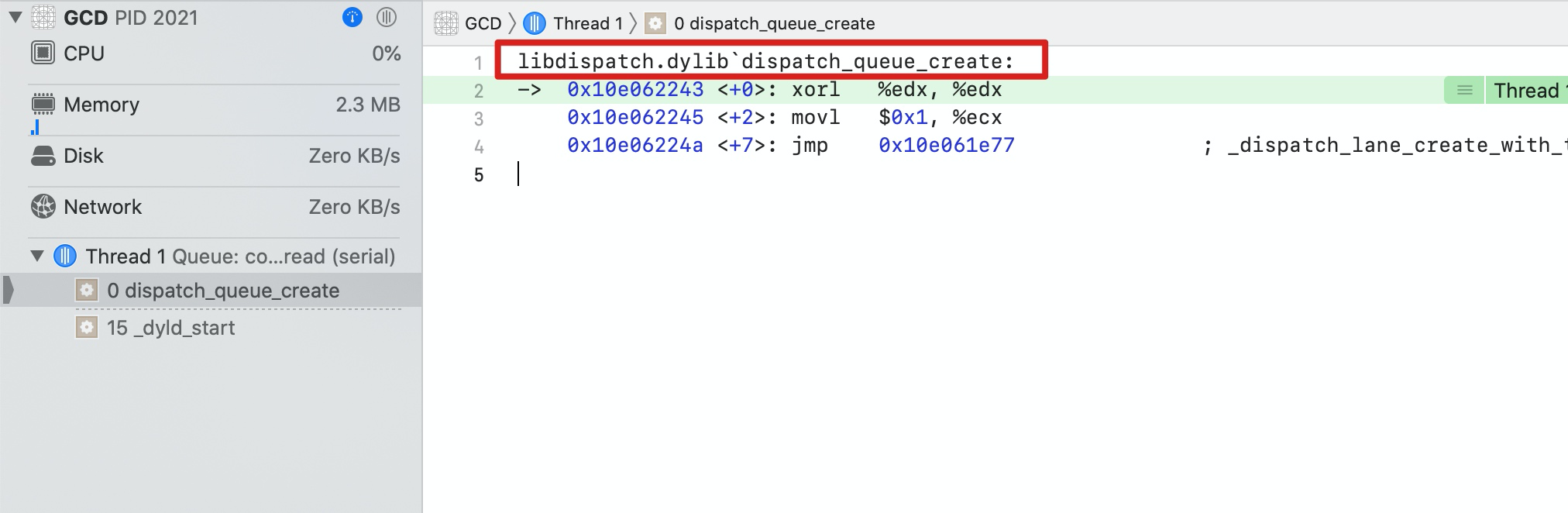
可以看到是 libdispatch.dylib,我们从苹果官网上下载最新源码 libdispatch 1173.40.5
4.1.1 串行与并发队列
现在我们一步步跟着源码的流程来进行分析
dispatch_queue_create分析
// 如何在创建的时候区分串行还是并发// 通过结构体位域设置dqai的属性dispatch_queue_tdispatch_queue_create(const char *label, dispatch_queue_attr_t attr){return _dispatch_lane_create_with_target(label, attr,DISPATCH_TARGET_QUEUE_DEFAULT, true);}
_dispatch_lane_create_with_target分析
DISPATCH_NOINLINEstatic dispatch_queue_t_dispatch_lane_create_with_target(const char *label, dispatch_queue_attr_t dqa,dispatch_queue_t tq, bool legacy){// dqai 创建 - 如果是串行队列会返回 { } 空dispatch_queue_attr_info_t dqai = _dispatch_queue_attr_to_info(dqa);//// Step 1: Normalize arguments (qos, overcommit, tq)//dispatch_qos_t qos = dqai.dqai_qos;#if !HAVE_PTHREAD_WORKQUEUE_QOSif (qos == DISPATCH_QOS_USER_INTERACTIVE) {dqai.dqai_qos = qos = DISPATCH_QOS_USER_INITIATED;}if (qos == DISPATCH_QOS_MAINTENANCE) {dqai.dqai_qos = qos = DISPATCH_QOS_BACKGROUND;}#endif // !HAVE_PTHREAD_WORKQUEUE_QOS_dispatch_queue_attr_overcommit_t overcommit = dqai.dqai_overcommit;if (overcommit != _dispatch_queue_attr_overcommit_unspecified && tq) {if (tq->do_targetq) {DISPATCH_CLIENT_CRASH(tq, "Cannot specify both overcommit and ""a non-global target queue");}}if (tq && dx_type(tq) == DISPATCH_QUEUE_GLOBAL_ROOT_TYPE) {// Handle discrepancies between attr and target queue, attributes winif (overcommit == _dispatch_queue_attr_overcommit_unspecified) {if (tq->dq_priority & DISPATCH_PRIORITY_FLAG_OVERCOMMIT) {overcommit = _dispatch_queue_attr_overcommit_enabled;} else {overcommit = _dispatch_queue_attr_overcommit_disabled;}}if (qos == DISPATCH_QOS_UNSPECIFIED) {qos = _dispatch_priority_qos(tq->dq_priority);}tq = NULL;} else if (tq && !tq->do_targetq) {// target is a pthread or runloop root queue, setting QoS or overcommit// is disallowedif (overcommit != _dispatch_queue_attr_overcommit_unspecified) {DISPATCH_CLIENT_CRASH(tq, "Cannot specify an overcommit attribute ""and use this kind of target queue");}} else {if (overcommit == _dispatch_queue_attr_overcommit_unspecified) {// Serial queues default to overcommit!overcommit = dqai.dqai_concurrent ?_dispatch_queue_attr_overcommit_disabled :_dispatch_queue_attr_overcommit_enabled;}}if (!tq) {tq = _dispatch_get_root_queue(qos == DISPATCH_QOS_UNSPECIFIED ? DISPATCH_QOS_DEFAULT : qos,overcommit == _dispatch_queue_attr_overcommit_enabled)->_as_dq;if (unlikely(!tq)) {DISPATCH_CLIENT_CRASH(qos, "Invalid queue attribute");}}//// Step 2: Initialize the queue//if (legacy) {// if any of these attributes is specified, use non legacy classesif (dqai.dqai_inactive || dqai.dqai_autorelease_frequency) {legacy = false;}}const void *vtable;dispatch_queue_flags_t dqf = legacy ? DQF_MUTABLE : 0;// 通过dqai.dqai_concurrent区分串行和并发// 然后通过 DISPATCH_VTABLE 生成对应的对象// OS_dispatch_##name##_class -> OS_dispatch_queue_concurrent_classif (dqai.dqai_concurrent) {// OS_dispatch_queue_concurrentvtable = DISPATCH_VTABLE(queue_concurrent);} else {vtable = DISPATCH_VTABLE(queue_serial);}switch (dqai.dqai_autorelease_frequency) {case DISPATCH_AUTORELEASE_FREQUENCY_NEVER:dqf |= DQF_AUTORELEASE_NEVER;break;case DISPATCH_AUTORELEASE_FREQUENCY_WORK_ITEM:dqf |= DQF_AUTORELEASE_ALWAYS;break;}// label 赋值if (label) {const char *tmp = _dispatch_strdup_if_mutable(label);if (tmp != label) {dqf |= DQF_LABEL_NEEDS_FREE;label = tmp;}}// 开辟内存,生成相应的对象:dq -- 队列对象 → dispatch_queue_create方法创建出对象dispatch_lane_t dq = _dispatch_object_alloc(vtable,sizeof(struct dispatch_lane_s));// 其中有 dispatch_object_t 最大的对象,其他对象都是此对象衍生的// 构造方法 --- 如果是并发,给个最大宽度 0xffe 4094,如果是串行,宽度给个1_dispatch_queue_init(dq, dqf, dqai.dqai_concurrent ?DISPATCH_QUEUE_WIDTH_MAX : 1, DISPATCH_QUEUE_ROLE_INNER |(dqai.dqai_inactive ? DISPATCH_QUEUE_INACTIVE : 0)); // init// label 赋值dq->dq_label = label;// 优先级 赋值dq->dq_priority = _dispatch_priority_make((dispatch_qos_t)dqai.dqai_qos,dqai.dqai_relpri);if (overcommit == _dispatch_queue_attr_overcommit_enabled) {dq->dq_priority |= DISPATCH_PRIORITY_FLAG_OVERCOMMIT;}if (!dqai.dqai_inactive) {_dispatch_queue_priority_inherit_from_target(dq, tq);_dispatch_lane_inherit_wlh_from_target(dq, tq);}_dispatch_retain(tq);dq->do_targetq = tq;_dispatch_object_debug(dq, "%s", __func__);return _dispatch_trace_queue_create(dq)._dq;}
_dispatch_queue_attr_to_info分析
dispatch_queue_attr_info_t_dispatch_queue_attr_to_info(dispatch_queue_attr_t dqa){dispatch_queue_attr_info_t dqai = { };if (!dqa) return dqai;#if DISPATCH_VARIANT_STATIC// 如果是并发队列这里就返回了,走到下面都是串行队列if (dqa == &_dispatch_queue_attr_concurrent) {dqai.dqai_concurrent = true;return dqai;}#endifif (dqa < _dispatch_queue_attrs ||dqa >= &_dispatch_queue_attrs[DISPATCH_QUEUE_ATTR_COUNT]) {DISPATCH_CLIENT_CRASH(dqa->do_vtable, "Invalid queue attribute");}// 苹果自己定的算法size_t idx = (size_t)(dqa - _dispatch_queue_attrs);// 位域写法:某几位代表某个意思-为了节省空间// 例如 isa 指针里面的某些位代表 nonpointer、has_assoc 等dqai.dqai_inactive = (idx % DISPATCH_QUEUE_ATTR_INACTIVE_COUNT);idx /= DISPATCH_QUEUE_ATTR_INACTIVE_COUNT;dqai.dqai_concurrent = !(idx % DISPATCH_QUEUE_ATTR_CONCURRENCY_COUNT);idx /= DISPATCH_QUEUE_ATTR_CONCURRENCY_COUNT;dqai.dqai_relpri = -(int)(idx % DISPATCH_QUEUE_ATTR_PRIO_COUNT);idx /= DISPATCH_QUEUE_ATTR_PRIO_COUNT;dqai.dqai_qos = idx % DISPATCH_QUEUE_ATTR_QOS_COUNT;idx /= DISPATCH_QUEUE_ATTR_QOS_COUNT;dqai.dqai_autorelease_frequency =idx % DISPATCH_QUEUE_ATTR_AUTORELEASE_FREQUENCY_COUNT;idx /= DISPATCH_QUEUE_ATTR_AUTORELEASE_FREQUENCY_COUNT;dqai.dqai_overcommit = idx % DISPATCH_QUEUE_ATTR_OVERCOMMIT_COUNT;idx /= DISPATCH_QUEUE_ATTR_OVERCOMMIT_COUNT;return dqai;}
DISPATCH_VTABLE分析
下面的宏定义也可以看出来 队列其实也是一个对象,我们把 ##name 替换替换了,得到
OS_dispatch_queue_serial 和 OS_dispatch_queue_concurrent
其实就是串行队列和并发队列
#define DISPATCH_VTABLE(name) DISPATCH_OBJC_CLASS(name)->#define DISPATCH_OBJC_CLASS(name) (&DISPATCH_CLASS_SYMBOL(name))->#define DISPATCH_CLASS_SYMBOL(name) OS_dispatch_##name##_class->#define DISPATCH_CLASS(name) OS_dispatch_##name
4.1.2 mainQueue 和 globalQueue
_dispatch_get_root_queue分析
DISPATCH_ALWAYS_INLINE DISPATCH_CONSTstatic inline dispatch_queue_global_t_dispatch_get_root_queue(dispatch_qos_t qos, bool overcommit) // (4,YES/NO){if (unlikely(qos < DISPATCH_QOS_MIN || qos > DISPATCH_QOS_MAX)) {DISPATCH_CLIENT_CRASH(qos, "Corrupted priority");}// 取数组下标 6 或 7// 下面进入_dispatch_root_queues[]--静态数组,装了很多信息:target_queuereturn &_dispatch_root_queues[2 * (qos - 1) + overcommit];}
struct dispatch_queue_global_s _dispatch_root_queues[] = {#define _DISPATCH_ROOT_QUEUE_IDX(n, flags) \((flags & DISPATCH_PRIORITY_FLAG_OVERCOMMIT) ? \DISPATCH_ROOT_QUEUE_IDX_##n##_QOS_OVERCOMMIT : \DISPATCH_ROOT_QUEUE_IDX_##n##_QOS)#define _DISPATCH_ROOT_QUEUE_ENTRY(n, flags, ...) \[_DISPATCH_ROOT_QUEUE_IDX(n, flags)] = { \DISPATCH_GLOBAL_OBJECT_HEADER(queue_global), \.dq_state = DISPATCH_ROOT_QUEUE_STATE_INIT_VALUE, \.do_ctxt = _dispatch_root_queue_ctxt(_DISPATCH_ROOT_QUEUE_IDX(n, flags)), \.dq_atomic_flags = DQF_WIDTH(DISPATCH_QUEUE_WIDTH_POOL), \.dq_priority = flags | ((flags & DISPATCH_PRIORITY_FLAG_FALLBACK) ? \_dispatch_priority_make_fallback(DISPATCH_QOS_##n) : \_dispatch_priority_make(DISPATCH_QOS_##n, 0)), \__VA_ARGS__ \}_DISPATCH_ROOT_QUEUE_ENTRY(MAINTENANCE, 0,.dq_label = "com.apple.root.maintenance-qos",.dq_serialnum = 4,),_DISPATCH_ROOT_QUEUE_ENTRY(MAINTENANCE, DISPATCH_PRIORITY_FLAG_OVERCOMMIT,.dq_label = "com.apple.root.maintenance-qos.overcommit",.dq_serialnum = 5,),_DISPATCH_ROOT_QUEUE_ENTRY(BACKGROUND, 0,.dq_label = "com.apple.root.background-qos",.dq_serialnum = 6,),_DISPATCH_ROOT_QUEUE_ENTRY(BACKGROUND, DISPATCH_PRIORITY_FLAG_OVERCOMMIT,.dq_label = "com.apple.root.background-qos.overcommit",.dq_serialnum = 7,),_DISPATCH_ROOT_QUEUE_ENTRY(UTILITY, 0,.dq_label = "com.apple.root.utility-qos",.dq_serialnum = 8,),_DISPATCH_ROOT_QUEUE_ENTRY(UTILITY, DISPATCH_PRIORITY_FLAG_OVERCOMMIT,.dq_label = "com.apple.root.utility-qos.overcommit",.dq_serialnum = 9,),_DISPATCH_ROOT_QUEUE_ENTRY(DEFAULT, DISPATCH_PRIORITY_FLAG_FALLBACK,.dq_label = "com.apple.root.default-qos",.dq_serialnum = 10,),_DISPATCH_ROOT_QUEUE_ENTRY(DEFAULT,DISPATCH_PRIORITY_FLAG_FALLBACK | DISPATCH_PRIORITY_FLAG_OVERCOMMIT,.dq_label = "com.apple.root.default-qos.overcommit",.dq_serialnum = 11,),_DISPATCH_ROOT_QUEUE_ENTRY(USER_INITIATED, 0,.dq_label = "com.apple.root.user-initiated-qos",.dq_serialnum = 12,),_DISPATCH_ROOT_QUEUE_ENTRY(USER_INITIATED, DISPATCH_PRIORITY_FLAG_OVERCOMMIT,.dq_label = "com.apple.root.user-initiated-qos.overcommit",.dq_serialnum = 13,),_DISPATCH_ROOT_QUEUE_ENTRY(USER_INTERACTIVE, 0,.dq_label = "com.apple.root.user-interactive-qos",.dq_serialnum = 14,),_DISPATCH_ROOT_QUEUE_ENTRY(USER_INTERACTIVE, DISPATCH_PRIORITY_FLAG_OVERCOMMIT,.dq_label = "com.apple.root.user-interactive-qos.overcommit",.dq_serialnum = 15,),};
4.1.2.1 dispatch_get_global_queue 全局并发队列
dispatch_queue_global_tdispatch_get_global_queue(long priority, unsigned long flags){dispatch_assert(countof(_dispatch_root_queues) ==DISPATCH_ROOT_QUEUE_COUNT);if (flags & ~(unsigned long)DISPATCH_QUEUE_OVERCOMMIT) {return DISPATCH_BAD_INPUT;}dispatch_qos_t qos = _dispatch_qos_from_queue_priority(priority);#if !HAVE_PTHREAD_WORKQUEUE_QOSif (qos == QOS_CLASS_MAINTENANCE) {qos = DISPATCH_QOS_BACKGROUND;} else if (qos == QOS_CLASS_USER_INTERACTIVE) {qos = DISPATCH_QOS_USER_INITIATED;}#endifif (qos == DISPATCH_QOS_UNSPECIFIED) {return DISPATCH_BAD_INPUT;}// 前面的 _dispatch_root_queues[] --静态数组return _dispatch_get_root_queue(qos, flags & DISPATCH_QUEUE_OVERCOMMIT);}
4.2.1.2 dispatch_get_main_queue 主队列/串行队列
苹果暴露给我们的代码
dispatch_queue_main_tdispatch_get_main_queue(void){// 进入 dispatch_queue_main_treturn DISPATCH_GLOBAL_OBJECT(dispatch_queue_main_t, _dispatch_main_q);}
DISPATCH_DECL_SUBCLASS(dispatch_queue_main, dispatch_queue_serial);
// name -> 标准类 base -> 基类#define DISPATCH_DECL_SUBCLASS(name, base) OS_OBJECT_DECL_SUBCLASS(name, base)
libdispatch 源码
// 意思是:name(标准类) 是 base(基类) 的重写// 即:dispatch_queue_main_t 是 _dispatch_main_q 的重写 --- 函数重写#define OS_OBJECT_DECL_SUBCLASS(name, super) \OS_OBJECT_DECL_IMPL(name, <OS_OBJECT_CLASS(super)>)
struct dispatch_queue_static_s _dispatch_main_q = {DISPATCH_GLOBAL_OBJECT_HEADER(queue_main),#if !DISPATCH_USE_RESOLVERS.do_targetq = _dispatch_get_default_queue(true),#endif.dq_state = DISPATCH_QUEUE_STATE_INIT_VALUE(1) |DISPATCH_QUEUE_ROLE_BASE_ANON,.dq_label = "com.apple.main-thread",.dq_atomic_flags = DQF_THREAD_BOUND | DQF_WIDTH(1),.dq_serialnum = 1,};
dispatch_queue_main_tdispatch_get_main_queue(void){return DISPATCH_GLOBAL_OBJECT(dispatch_queue_main_t, _dispatch_main_q);}
#define DISPATCH_GLOBAL_OBJECT(type, object) ((OS_OBJECT_BRIDGE type)&(object))
4.2 异步函数源码分析
4.2.1 如何创建线程
voiddispatch_async(dispatch_queue_t dq, dispatch_block_t work){dispatch_continuation_t dc = _dispatch_continuation_alloc();uintptr_t dc_flags = DC_FLAG_CONSUME;dispatch_qos_t qos;// 任务包装器 - 接受 - 保存 - 函数式// 保存 blockqos = _dispatch_continuation_init(dc, dq, work, 0, dc_flags);// 创建线程_dispatch_continuation_async(dq, dc, qos, dc->dc_flags);}
_dispatch_continuation_init
static inline dispatch_qos_t_dispatch_continuation_init(dispatch_continuation_t dc,dispatch_queue_class_t dqu, dispatch_block_t work,dispatch_block_flags_t flags, uintptr_t dc_flags){void *ctxt = _dispatch_Block_copy(work);dc_flags |= DC_FLAG_BLOCK | DC_FLAG_ALLOCATED;if (unlikely(_dispatch_block_has_private_data(work))) {dc->dc_flags = dc_flags;dc->dc_ctxt = ctxt;// will initialize all fields but requires dc_flags & dc_ctxt to be setreturn _dispatch_continuation_init_slow(dc, dqu, flags);}// 调用dispatch_function_t func = _dispatch_Block_invoke(work);if (dc_flags & DC_FLAG_CONSUME) {func = _dispatch_call_block_and_release;/*注意:_dispatch_call_block_and_release(void *block){void (^b)(void) = block;b();Block_release(b);}*/}return _dispatch_continuation_init_f(dc, dqu, ctxt, func, flags, dc_flags);}
_dispatch_continuation_init_f
static inline dispatch_qos_t_dispatch_continuation_init_f(dispatch_continuation_t dc,dispatch_queue_class_t dqu, void *ctxt, dispatch_function_t f,dispatch_block_flags_t flags, uintptr_t dc_flags){pthread_priority_t pp = 0;dc->dc_flags = dc_flags | DC_FLAG_ALLOCATED;dc->dc_func = f; // 保存任务dc->dc_ctxt = ctxt;// in this context DISPATCH_BLOCK_HAS_PRIORITY means that the priority// should not be propagated, only taken from the handler if it has oneif (!(flags & DISPATCH_BLOCK_HAS_PRIORITY)) {pp = _dispatch_priority_propagate();}_dispatch_continuation_voucher_set(dc, flags);return _dispatch_continuation_priority_set(dc, dqu, pp, flags);}
_dispatch_continuation_async
static inline void_dispatch_continuation_async(dispatch_queue_class_t dqu,dispatch_continuation_t dc, dispatch_qos_t qos, uintptr_t dc_flags){#if DISPATCH_INTROSPECTIONif (!(dc_flags & DC_FLAG_NO_INTROSPECTION)) {_dispatch_trace_item_push(dqu, dc);}#else(void)dc_flags;#endif// dx_push 宏 -> dx_vtable -> dq_push// 并发 .dq_push = _dispatch_root_queue_pushreturn dx_push(dqu._dq, dc, qos);}
_dispatch_root_queue_push
void_dispatch_root_queue_push(dispatch_queue_global_t rq, dispatch_object_t dou,dispatch_qos_t qos){#if DISPATCH_USE_KEVENT_WORKQUEUEdispatch_deferred_items_t ddi = _dispatch_deferred_items_get();if (unlikely(ddi && ddi->ddi_can_stash)) {dispatch_object_t old_dou = ddi->ddi_stashed_dou;dispatch_priority_t rq_overcommit;rq_overcommit = rq->dq_priority & DISPATCH_PRIORITY_FLAG_OVERCOMMIT;if (likely(!old_dou._do || rq_overcommit)) {dispatch_queue_global_t old_rq = ddi->ddi_stashed_rq;dispatch_qos_t old_qos = ddi->ddi_stashed_qos;ddi->ddi_stashed_rq = rq;ddi->ddi_stashed_dou = dou;ddi->ddi_stashed_qos = qos;_dispatch_debug("deferring item %p, rq %p, qos %d",dou._do, rq, qos);if (rq_overcommit) {ddi->ddi_can_stash = false;}if (likely(!old_dou._do)) {return;}// push the previously stashed itemqos = old_qos;rq = old_rq;dou = old_dou;}}#endif#if HAVE_PTHREAD_WORKQUEUE_QOSif (_dispatch_root_queue_push_needs_override(rq, qos)) {return _dispatch_root_queue_push_override(rq, dou, qos);}#else(void)qos;#endif_dispatch_root_queue_push_inline(rq, dou, dou, 1);}
- 进入
_dispatch_root_queue_push_inline
static inline void_dispatch_root_queue_push_inline(dispatch_queue_global_t dq,dispatch_object_t _head, dispatch_object_t _tail, int n){struct dispatch_object_s *hd = _head._do, *tl = _tail._do;if (unlikely(os_mpsc_push_list(os_mpsc(dq, dq_items), hd, tl, do_next))) {return _dispatch_root_queue_poke(dq, n, 0);}}
- 进入
_dispatch_root_queue_poke
void_dispatch_root_queue_poke(dispatch_queue_global_t dq, int n, int floor){if (!_dispatch_queue_class_probe(dq)) {return;}#if !DISPATCH_USE_INTERNAL_WORKQUEUE#if DISPATCH_USE_PTHREAD_POOLif (likely(dx_type(dq) == DISPATCH_QUEUE_GLOBAL_ROOT_TYPE))#endif{if (unlikely(!os_atomic_cmpxchg2o(dq, dgq_pending, 0, n, relaxed))) {_dispatch_root_queue_debug("worker thread request still pending ""for global queue: %p", dq);return;}}#endif // !DISPATCH_USE_INTERNAL_WORKQUEUEreturn _dispatch_root_queue_poke_slow(dq, n, floor);}
- 进入
_dispatch_root_queue_poke_slow
static void_dispatch_root_queue_poke_slow(dispatch_queue_global_t dq, int n, int floor){int remaining = n;int r = ENOSYS;_dispatch_root_queues_init();_dispatch_debug_root_queue(dq, __func__);_dispatch_trace_runtime_event(worker_request, dq, (uint64_t)n);#if !DISPATCH_USE_INTERNAL_WORKQUEUE#if DISPATCH_USE_PTHREAD_ROOT_QUEUESif (dx_type(dq) == DISPATCH_QUEUE_GLOBAL_ROOT_TYPE)#endif{_dispatch_root_queue_debug("requesting new worker thread for global ""queue: %p", dq);r = _pthread_workqueue_addthreads(remaining,_dispatch_priority_to_pp_prefer_fallback(dq->dq_priority));// 此处直接往工作队列中添加线程。进不去,看不到更进一步的源码(void)dispatch_assume_zero(r);return;}#endif // !DISPATCH_USE_INTERNAL_WORKQUEUE#if DISPATCH_USE_PTHREAD_POOLdispatch_pthread_root_queue_context_t pqc = dq->do_ctxt;if (likely(pqc->dpq_thread_mediator.do_vtable)) {while (dispatch_semaphore_signal(&pqc->dpq_thread_mediator)) {_dispatch_root_queue_debug("signaled sleeping worker for ""global queue: %p", dq);if (!--remaining) {return;}}}bool overcommit = dq->dq_priority & DISPATCH_PRIORITY_FLAG_OVERCOMMIT;if (overcommit) {os_atomic_add2o(dq, dgq_pending, remaining, relaxed);} else {if (!os_atomic_cmpxchg2o(dq, dgq_pending, 0, remaining, relaxed)) {_dispatch_root_queue_debug("worker thread request still pending for ""global queue: %p", dq);return;}}int can_request, t_count;// seq_cst with atomic store to tail <rdar://problem/16932833>// 获取缓存池的大小t_count = os_atomic_load2o(dq, dgq_thread_pool_size, ordered);do {// 可以产生的线程数can_request = t_count < floor ? 0 : t_count - floor;// 想要产生的线程数 > 能够产生的线程数if (remaining > can_request) {_dispatch_root_queue_debug("pthread pool reducing request from %d to %d",remaining, can_request);os_atomic_sub2o(dq, dgq_pending, remaining - can_request, relaxed);remaining = can_request;}if (remaining == 0) {_dispatch_root_queue_debug("pthread pool is full for root queue: ""%p", dq);return;}} while (!os_atomic_cmpxchgvw2o(dq, dgq_thread_pool_size, t_count,t_count - remaining, &t_count, acquire)); // 判断缓存池的大小#if !defined(_WIN32)pthread_attr_t *attr = &pqc->dpq_thread_attr;pthread_t tid, *pthr = &tid;#if DISPATCH_USE_MGR_THREAD && DISPATCH_USE_PTHREAD_ROOT_QUEUESif (unlikely(dq == &_dispatch_mgr_root_queue)) {pthr = _dispatch_mgr_root_queue_init();}#endif// remaining > 0 且通过以上判断说明没有问题则开始开辟线程do {_dispatch_retain(dq); // released in _dispatch_worker_threadwhile ((r = pthread_create(pthr, attr, _dispatch_worker_thread, dq))) {if (r != EAGAIN) {(void)dispatch_assume_zero(r);}_dispatch_temporary_resource_shortage();}} while (--remaining); // 当 remaining == 0 时说明开辟完毕#else(void)floor;#endif // DISPATCH_USE_PTHREAD_POOL}
4.2.2 如何执行任务
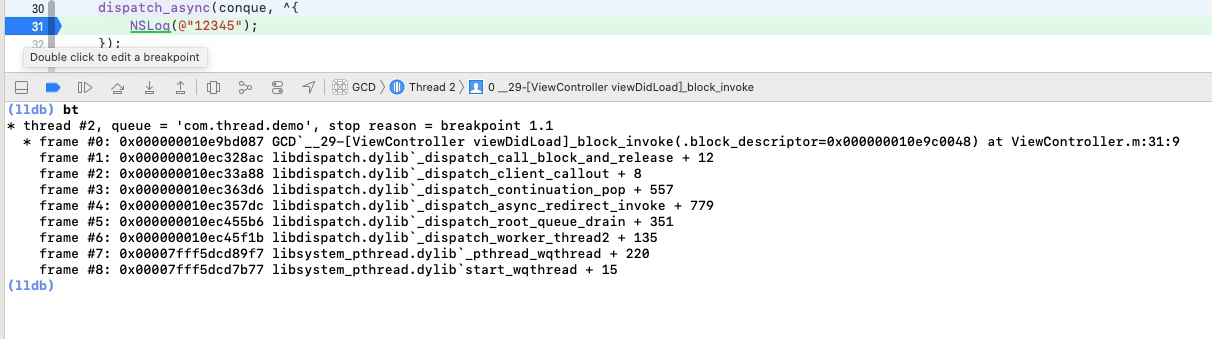
从上面打印的堆栈中,我们从 _dispatch_worker_thread2 开始分析
static void_dispatch_worker_thread2(pthread_priority_t pp){bool overcommit = pp & _PTHREAD_PRIORITY_OVERCOMMIT_FLAG;dispatch_queue_global_t dq;pp &= _PTHREAD_PRIORITY_OVERCOMMIT_FLAG | ~_PTHREAD_PRIORITY_FLAGS_MASK;_dispatch_thread_setspecific(dispatch_priority_key, (void *)(uintptr_t)pp);dq = _dispatch_get_root_queue(_dispatch_qos_from_pp(pp), overcommit);_dispatch_introspection_thread_add();_dispatch_trace_runtime_event(worker_unpark, dq, 0);int pending = os_atomic_dec2o(dq, dgq_pending, relaxed);dispatch_assert(pending >= 0);_dispatch_root_queue_drain(dq, dq->dq_priority,DISPATCH_INVOKE_WORKER_DRAIN | DISPATCH_INVOKE_REDIRECTING_DRAIN);_dispatch_voucher_debug("root queue clear", NULL);_dispatch_reset_voucher(NULL, DISPATCH_THREAD_PARK);_dispatch_trace_runtime_event(worker_park, NULL, 0);}
进入 _dispatch_root_queue_drain
DISPATCH_NOT_TAIL_CALLED // prevent tailcall (for Instrument DTrace probe)static void_dispatch_root_queue_drain(dispatch_queue_global_t dq,dispatch_priority_t pri, dispatch_invoke_flags_t flags){#if DISPATCH_DEBUGdispatch_queue_t cq;if (unlikely(cq = _dispatch_queue_get_current())) {DISPATCH_INTERNAL_CRASH(cq, "Premature thread recycling");}#endif_dispatch_queue_set_current(dq);_dispatch_init_basepri(pri);_dispatch_adopt_wlh_anon();struct dispatch_object_s *item;bool reset = false;dispatch_invoke_context_s dic = { };#if DISPATCH_COCOA_COMPAT_dispatch_last_resort_autorelease_pool_push(&dic);#endif // DISPATCH_COCOA_COMPAT_dispatch_queue_drain_init_narrowing_check_deadline(&dic, pri);_dispatch_perfmon_start();while (likely(item = _dispatch_root_queue_drain_one(dq))) {if (reset) _dispatch_wqthread_override_reset();_dispatch_continuation_pop_inline(item, &dic, flags, dq);reset = _dispatch_reset_basepri_override();if (unlikely(_dispatch_queue_drain_should_narrow(&dic))) {break;}}// overcommit or not. worker threadif (pri & DISPATCH_PRIORITY_FLAG_OVERCOMMIT) {_dispatch_perfmon_end(perfmon_thread_worker_oc);} else {_dispatch_perfmon_end(perfmon_thread_worker_non_oc);}#if DISPATCH_COCOA_COMPAT_dispatch_last_resort_autorelease_pool_pop(&dic);#endif // DISPATCH_COCOA_COMPAT_dispatch_reset_wlh();_dispatch_clear_basepri();_dispatch_queue_set_current(NULL);}
发现上面的重点部分是 while 循环里面的 _dispatch_continuation_pop_inline
static inline void_dispatch_continuation_pop_inline(dispatch_object_t dou,dispatch_invoke_context_t dic, dispatch_invoke_flags_t flags,dispatch_queue_class_t dqu){dispatch_pthread_root_queue_observer_hooks_t observer_hooks =_dispatch_get_pthread_root_queue_observer_hooks();if (observer_hooks) observer_hooks->queue_will_execute(dqu._dq);flags &= _DISPATCH_INVOKE_PROPAGATE_MASK;if (_dispatch_object_has_vtable(dou)) {dx_invoke(dou._dq, dic, flags);} else {_dispatch_continuation_invoke_inline(dou, flags, dqu);}if (observer_hooks) observer_hooks->queue_did_execute(dqu._dq);}
进入 _dispatch_continuation_invoke_inline
static inline void_dispatch_continuation_invoke_inline(dispatch_object_t dou,dispatch_invoke_flags_t flags, dispatch_queue_class_t dqu){dispatch_continuation_t dc = dou._dc, dc1;dispatch_invoke_with_autoreleasepool(flags, {uintptr_t dc_flags = dc->dc_flags;// Add the item back to the cache before calling the function. This// allows the 'hot' continuation to be used for a quick callback.//// The ccache version is per-thread.// Therefore, the object has not been reused yet.// This generates better assembly._dispatch_continuation_voucher_adopt(dc, dc_flags);if (!(dc_flags & DC_FLAG_NO_INTROSPECTION)) {_dispatch_trace_item_pop(dqu, dou);}if (dc_flags & DC_FLAG_CONSUME) {dc1 = _dispatch_continuation_free_cacheonly(dc);} else {dc1 = NULL;}if (unlikely(dc_flags & DC_FLAG_GROUP_ASYNC)) {_dispatch_continuation_with_group_invoke(dc);} else {_dispatch_client_callout(dc->dc_ctxt, dc->dc_func);_dispatch_trace_item_complete(dc);}if (unlikely(dc1)) {_dispatch_continuation_free_to_cache_limit(dc1);}});_dispatch_perfmon_workitem_inc();}
重点代码 _dispatch_client_callout
void_dispatch_client_callout(void *ctxt, dispatch_function_t f){@try {// 执行任务函数return f(ctxt);}@catch (...) {objc_terminate();}}
到这里,就能正确理解异步函数的执行过程了。

若有收获,就点个赞吧
0 人点赞
