/ 写在前面 – 我热爱技术、热爱开源。我也相信开源能使技术变得更好、共享能使知识传播得更远。但是开源并不意味着某些商业机构/个人可以为了自身的利益而一味地索取,甚至直接剽窃大家曾为之辛勤付出的知识成果,所以本文未经允许,不得转载,谢谢。/
如何设计词法分析器:
- 定义Token
- 识别Token
定义Token
Token、Pattern、Lexeme的定义和区别:What is the difference between a token and a lexeme? - Stack OverflowUsing “Compilers Principles, Techniques, & Tools, 2nd Ed.“ (WorldCat) by Aho, Lam, Sethi and Ullman, AKA the Purple Dragon Book,
Lexeme p. 111 A lexeme is a sequence of characters in the source program that matches the pattern for a token and is identified by the lexical analyzer as an instance of that token.
Token p. 111 A token is a pair consisting of a token name and an optional attribute value. The token name is an abstract symbol representing a kind of lexical unit, e.g., a particular keyword, or sequence of input characters denoting an identifier. The token names are the input symbols that the parser processes.
Pattern p. 111 A pattern is a description of the form that the lexemes of a token may take. In the case of a keyword as a token, the pattern is just the sequence of characters that form the keyword. For identifiers and some other tokens, the pattern is more complex structure that is matched by many strings.
Figure 3.2: Examples of tokens p.112
[Token] [Informal Description] [Sample Lexemes]if characters i, f ifelse characters e, l, s, e elsecomparison < or > or <= or >= or == or != <=, !=id letter followed by letters and digits pi, score, D2number any numeric constant 3.14159, 0, 6.02e23literal anything but ", surrounded by "'s "core dumped"
此外,还可参考COMPILER DESIGN: Tokens, patterns and lexemes。
lecture2.pdf - p. 1 什么是词法记号Token?
- 句子最小的单元
- 自然语言:名词、动词、形容词……
- 程序语言:标识符、关键字、空格、整数……
龙书 - p. 43 Tokens Versus Terminals A token consists of two components, a token name and an attribute value. Often, we shall call these token names terminals, since they appear as terminal symbols in the grammar for a programming language.
- S表示符号集合
- S = {a, ^, $, b, 3, 8}
- L(语言)就是定义在S上符号串的集合
- L = {ab3, 883, ^aaaa, …}
正则表达式定义
正则表达式就是定义在字母表上的一系列表达式集合。
原子正则表达式:
- 单个字符
- ‘c’ = {“c”}
- epsilon
- ε = {“”}
复合的正则表达式:
- 联合 - union
- 联合 - concatenation
- 重复 - iteration(闭包)
- 零个或任意多个A组成的串,例:

- 零个或任意多个A组成的串,例:


一些常用的等价记号
- Union:

- Option:

- Range:

- Iteration:

识别Token
有限状态自动机(Finite Automation,FA)包括5元式(5个要素):
- An input alphabet -

- A set of states -

- A start state -

- A set of accepting states -

- A set of transitions -

FA的状态转移:
- 状态
 读入字符
读入字符 后转移到
后转移到 ;
; - 如果输入的结尾到达接受状态
 ,则识别出一个词。
,则识别出一个词。
FA的各类图:
- A state:

- The start state:

- An accepting state:

- A transition:
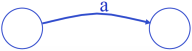
注意一种特殊情况——空转移( -moves):在未读入任何字符的情况下从状态A到状态B,
-moves):在未读入任何字符的情况下从状态A到状态B,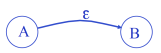 。
。
注意:在接受状态上加一个星号*不表示闭包,其含义为虽然“我”在这里接受了,但是我识别的东西是需要回退一格的。
DFA和NFA
确定的自动机(Deterministic Finite Automata,DFA):(下列2个条件需都满足,&&)
- 状态给定一个输入只会确定到一个状态
- 没有空转移
非确定自动机(Nondeterministic Finite Automata,NFA):(下列2个条件满足任意一个,||)
- 状态给定一个输入可能会跳转到多个状态
- 有空转移
NFA与DFA的异同:
- NFA与DFA识别相同的语言(正规语言);
- NFA的初始状态不唯一,而DFA的初始状态唯一;
- DFA比NFA识别的效率高(没有路径需要选择,每一步的状态都是确定的);
- 给定语言,设计NFA比DFA简单,
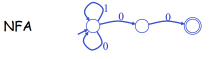 vs.
vs. 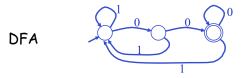 ;
; - DFA的状态可能比NFA大(空间换时间)。
故,人偏好NFA,而计算机偏好DFA。
词法识别流程:
- Lexical Specification
- Regular Expressions
- NFA
- DFA
- Table-driven Impletation of DFA
从正则表达式(rexp)到NFA
对每一类rexp(M),定义一个对应的NFA:
- For :
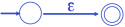
- For input :
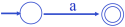
- For
 :
:
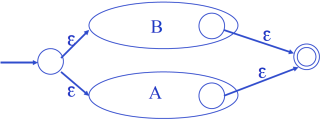
- For
 :
:
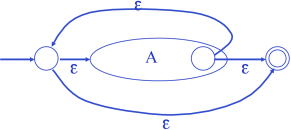
- For
 :
:
从NFA到DFA
NFA转换为DFA的算法为子集构造法(解决弧和转换关系),其算法流程如下:
其中:
 :能够从NFA的状态
:能够从NFA的状态 开始只通过转换到达的NFA状态集合;
开始只通过转换到达的NFA状态集合; :能够从
:能够从 中某个NFA状态开始只通过转换到达的NFA状态集合,即
中某个NFA状态开始只通过转换到达的NFA状态集合,即 ;
; 能够从中某个状态出发通过标号为的转换到达的NFA状态的集合;
能够从中某个状态出发通过标号为的转换到达的NFA状态的集合; :DFA状态集;
:DFA状态集; :表示转移表;
:表示转移表;// 初始,ε-closure(s0)是Dstates仅有的状态,并且尚未标记while (Dstates有尚未标记的状态T){标记T;for (每个输入符号a){U = ε-closure(move(T, a));if (U不在Dstates中)把U作为尚未标记的状态加入Dstates;Dtran[T, a] = U}}
Compiler - Priciples, Techniques and Tools, p. 145.
Note that a path can have zero edges, so state 0 is reachable from itself by an ε-labeled path.
DFA最小化
DFA的化简(最小化)主要取决于:
- 第一次划分 - 区分终态(F)和非终态(S - F),即区分一个状态是否是接受状态。
- 第二次划分 - 区分非一致行动的状态,即:
- 把S的状态集划分为一些不相交的子集,使得任何两个不同子集的状态是可区别的,而同一子集的任何两个状态是等价的;
- 最后,让每个子集选出一个代表,同时消去其他状态。

若有收获,就点个赞吧
0 人点赞
