/ 写在前面 – 我热爱技术、热爱开源。我也相信开源能使技术变得更好、共享能使知识传播得更远。但是开源并不意味着某些商业机构/个人可以为了自身的利益而一味地索取,甚至直接剽窃大家曾为之辛勤付出的知识成果,所以本文未经允许,不得转载,谢谢。/
基本定义
产生式、终结符和非终结符的定义:
in which the arrow may be read as “can have the form.” Such a rule is called a production. In a production, lexical elements like the keyword
and the parentheses are called terminals. Variables like
and
represent sequences of terminals and are called nonterminals.
终结符代表了一种终结状态,即不可再被替换。
上下文无关文法的定义:
A “context-free grammar” (or “grammar“ for short) has four components:
- A set of terminal symbols, sometimes referred to as “tokens.” The terminals are the elementary symbols of the language de ned by the grammar.
- A set of nonterminals, sometimes called “syntactic variables.” Each nonterminal represents a set of strings of terminals, in a manner we shall describe.
- A set of productions, where each production consists of a nonterminal, called the head or left side of the production, an arrow, and a sequence of terminals and/or nonterminals, called the body or right side of the production. The intuitive intent of a production is to specify one of the written forms of a construct; if the head nonterminal represents a construct, then the body represents a written form of the construct.
- A designation of one of the nonterminals as the start symbol.
A parse tree pictorially shows how the start symbol of a grammar derives a string in the language. If nonterminal A has a production
, then a parse tree may have an interior node labeled A with three children labeled X, Y, and Z, from left to right:
Formally, given a context-free grammar, a parse tree according to the grammar is a tree with the following properties:
- The root is labeled by the start symbol.
- Each leaf is labeled by a terminal or by ε.
- Each interior node is labeled by a nonterminal.
- If A is the nonterminal labeling some interior node and
are the labels of the children of that node from left to right, then there must be a production
. Here,
is a production, then a node labeled A may have a single child labeled
.
文法的作用是什么?或者说文法如何起作用?
答:文法描述了语言的句子集合,比如 int i = 0; 就是一个句子。
文法到句子:
- 从产生式的初始符号 S 开始;
- 根据产生式替换 S 右边所有的非终结符;
- 重复第 2 步,直到右边所有的串没有非终结符为止。
关于终结符(Terminal):
- 终结符表示不能再被替换
- 一旦产生就固定
- 终结符应该是词法分析的Tokens
定义:推导(Derivation)是一系列产生式。
推导过程可以用语法树(Parse Tree)表示,初始符号是语法树的根节点。
最左(右)推导:每一步推导先替换最左(右)边的非终结符。
推导小结:
- 关于语法树
- 叶子节点为终结符
- 非终结符对应树上的非叶子节点
- 按序In order遍历树上的节点就是输入的句子
- 语法树表现了结合顺序
Context-Free Grammars
Context-Free Grammars Versus Regular Expressions
给定一个rexp,我们可以得到它的NFA,然后按照以下步骤得到它的CFGs:
- For each state
of the NFA, create a nonterminal
.
- If state
on input
, add the production
. If state
.
- If
.
- If
能用文法描述的语言不一定能用rexp描述!实际上,每个rexp都是一个上下文无关文法。
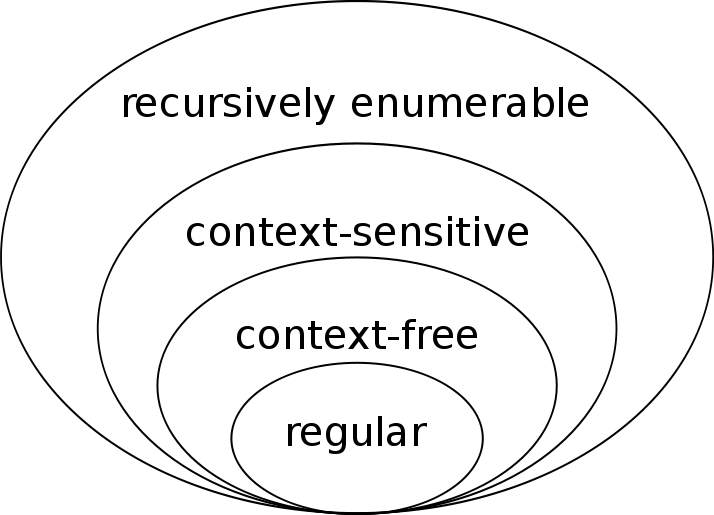
形式语言分类
- 0型文法也叫短语文法。一个非常重要的理论结果是,0型文法的能力相当于图灵机。
- 1型文法也叫上下文有关文法。
- 2型文法就是上下文无关文法。
- 3型文法等价于正则表达式,因而也叫正则文法。
小结
设计文法描述给定的语言难;而给定一个句子,判断这个句子是否属于由文法确定的语言易。
Prerequisites
输入:Token流
输出:语法树
成功构造语法树意味着句子合法。但是,困难在于如何在每一步确定选择哪一个产生式。
Leftmost BFS 存在指数级规模问题。
Leftmost DFS 存在左递归问题。
语法推导就是成功构造语法树。
- Top-down Parsing: 从文法开始符号开始,能否推导出句子。
- Bottom-up Parsing: 从句子开始,能否规约(reduce)出文法初始符号。
消除左递归
对于一般的左递归,即不涉及2步或2步以上的左递归,比如下面这种文法:
这种文法就存在2步左递归: 。
。
我们有一个小技巧来消除一般的左递归,见下面这种左递归文法:
其中没有一个 以
以 开头,我们进行如下替换即可消除这种左递归:
开头,我们进行如下替换即可消除这种左递归:
📕 举个例子,下面这个产生式就是带有左递归的:
我们按照上面的方法进行变换,得到它的非左递归变体:
具体参见Compiler - Priciples, Techniques and Tools, p. 193 and section 4.3.3。
消除左公因子(Eliminating Left-Factoring)
消除左公因子的技巧其实和消除左递归差不多。
对形如:
的一对产生式( 是左公因子),可用如下三个产生式替换:
是左公因子),可用如下三个产生式替换:
其中 为新增加的未出现过的非终结符。
为新增加的未出现过的非终结符。
📕 举个例子,看下面这个产生式:
我们按照上面的方法进行变换,得到:
具体参见Compiler - Priciples, Techniques and Tools, section 4.3.4。
计算FIRST集
- If
 is a terminal, then
is a terminal, then  .
. - If
 and
and  cannot produce ε,FIRST() contains FIRST().
cannot produce ε,FIRST() contains FIRST(). - If and can produce ε, FIRST() contains all non-ε symbols of FIRST() and all non-ε symbols of FIRST(
 ), respectively.
), respectively. - If and all can produce ε, FIRST() contains all non-ε symbols of FIRST() and ε.
- If is a production, then add ε to FIRST().
❗ 注意,第3点和第4点,如果不是所有串的FIRST集都包含ε,那就不需要在 中添加ε。
中添加ε。
计算FOLLOW集
- Place
$in , where
, where  is the start symbol, and
is the start symbol, and $is the input right endmarker. - If there is a production
 , then everything in
, then everything in  except ε is in
except ε is in  .
. - If there is a production
 , or a production , where contains ε, then everything in
, or a production , where contains ε, then everything in  is in .
is in .
总结一下,ε可以出现在FIRST集中而不能出现在FOLLOW集中, $ 可以出现在FOLLOW集中而不能出现在FIRST集中。
Top-Down Parsing
LL(1)
自顶向下,预测分析:
- L: Left-to-right scan of the tokens
- L: Leftmost derivation
- (1): One token of lookahead
对一系列Token流,构造最左推导;当遇到非终结符时,通过超前搜索1个字符来确定使用哪个产生式。
LL(1)文法判断
一个文法G是LL(1)的,当且仅当G的任意两个不同产生式 满足以下条件:
满足以下条件:
 ,即不存在终结符号
,即不存在终结符号 都能够推导出以
都能够推导出以 ,那么
,那么 (即
(即 和
和
若有收获,就点个赞吧
0 人点赞
