感知机
引入
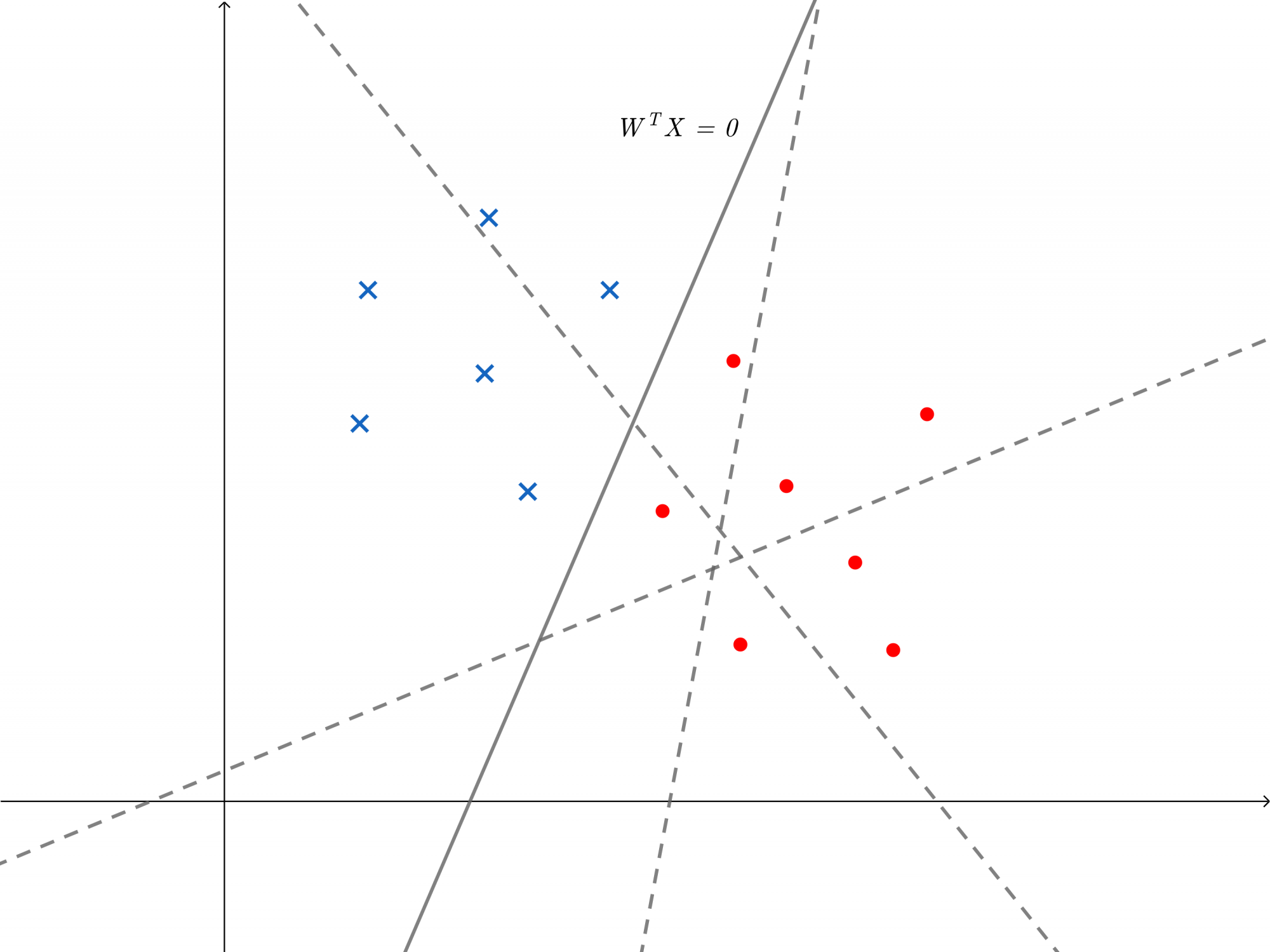
给定样本%5C%7D%7Bi%3D1%7D%5EN%2CX_i%5Cin%5Cmathbb%7BR%7D%5Ep#card=math&code=Data%3D%5C%7B%28X_i%2Cy_i%29%5C%7D%7Bi%3D1%7D%5EN%2CX_i%5Cin%5Cmathbb%7BR%7D%5Ep&height=23&width=220),假设这个样本分为两类并可以被一个超平面分开,这种情况称为线性可分。二维情况下如图,红点和蓝点分别表示两类
如果我们把两个类别分别用+1和-1来表示,于是可建立如下模型
%3Dsign(W%5ETX)%2CX%5Cin%5Cmathbb%7BR%7D%5Ep%2CW%5Cin%5Cmathbb%7BR%7D%5Ep%5C%5C%0Asign(x)%3D%0A%5Cbegin%7Bcases%7D%0A%2B1%2C%26x%5Cge0%5C%5C%0A-1%2C%26x%5Clt0%0A%5Cend%7Bcases%7D%0A%5Cend%7Bgathered%7D%0A#card=math&code=%5Cbegin%7Bgathered%7D%0Af%28X%29%3Dsign%28W%5ETX%29%2CX%5Cin%5Cmathbb%7BR%7D%5Ep%2CW%5Cin%5Cmathbb%7BR%7D%5Ep%5C%5C%0Asign%28x%29%3D%0A%5Cbegin%7Bcases%7D%0A%2B1%2C%26x%5Cge0%5C%5C%0A-1%2C%26x%5Clt0%0A%5Cend%7Bcases%7D%0A%5Cend%7Bgathered%7D%0A&height=69&width=280)
我们的目的就是找到空间中一个超平面可将样本切分为两类。如图可看出,有些超平面并不能完全切分样本,会有样本分类错误,于是我们自然想到建立一个loss function为分类错误的样本数量
- 先来看对样本
分类错误怎么表示
于是loss function可以写为
%3D%5Csum%7Bi%3D1%7D%5ENI(-y_iW%5ETX_i)%5C%5C%0AI(x)%3D%0A%5Cbegin%7Bcases%7D%0A1%2C%26x%5Cge0%5C%5C%0A0%2C%26x%5Clt0%0A%5Cend%7Bcases%7D%0A%5Cend%7Bgathered%7D%0A#card=math&code=%5Cbegin%7Bgathered%7D%0AL%28W%29%3D%5Csum%7Bi%3D1%7D%5ENI%28-y_iW%5ETX_i%29%5C%5C%0AI%28x%29%3D%0A%5Cbegin%7Bcases%7D%0A1%2C%26x%5Cge0%5C%5C%0A0%2C%26x%5Clt0%0A%5Cend%7Bcases%7D%0A%5Cend%7Bgathered%7D%0A&height=98&width=193)
这个损失函数虽然很简单很直观,但是它不连续不可导,数学性质较差,不方便我们求解,所以需要寻找其他loss function。
误分类驱动
感知机的目的是找到一个超平面将样本分为两类,如果一个超平面将所有点都分类错误,那么误分类的点到超平面的距离最大,在误分类点减少时,误分类的点到超平面的距离也会减少,找到满足条件的超平面时这个距离为零,因此可以选择将误分类的样本点到超平面的距离总和作为loss function
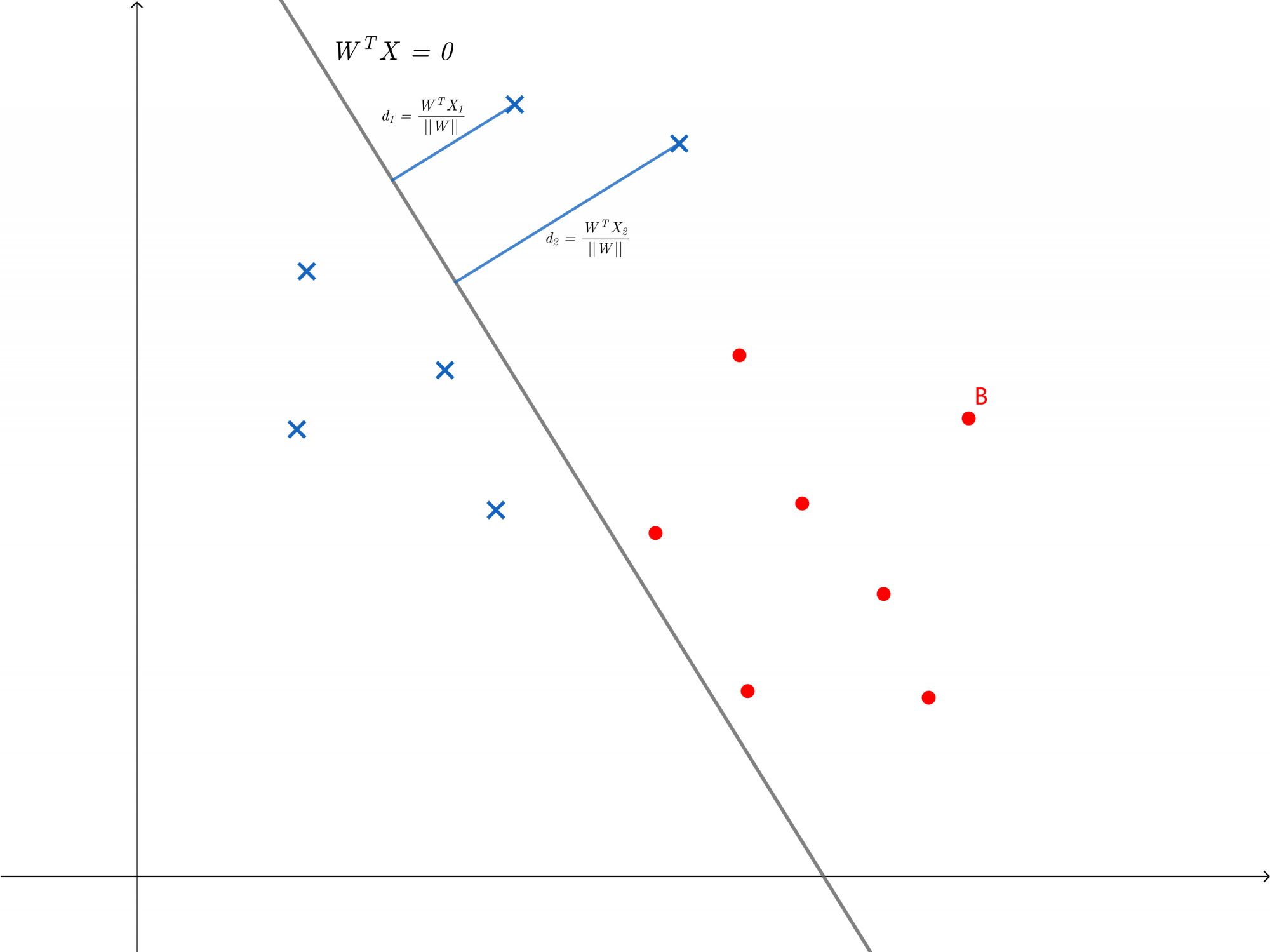
设误分类样本集合为,loss function为
%26%3D%5Csum%7BX_i%5Cin%20D%7D%5Cfrac%7BW%5ETX_i%7D%7B%7C%7CW%7C%7C%7D%5C%5C%0A%26%3D%5Csum%7BXi%5Cin%20D%7D%5Cfrac%7B-y_iW%5ETX_i%7D%7B%7C%7CW%7C%7C%7D%0A%5Cend%7Baligned%7D%0A#card=math&code=%5Cbegin%7Baligned%7D%0AL%28W%29%26%3D%5Csum%7BXi%5Cin%20D%7D%5Cfrac%7BW%5ETX_i%7D%7B%7C%7CW%7C%7C%7D%5C%5C%0A%26%3D%5Csum%7BX_i%5Cin%20D%7D%5Cfrac%7B-y_iW%5ETX_i%7D%7B%7C%7CW%7C%7C%7D%0A%5Cend%7Baligned%7D%0A&height=105&width=185)
这个损失虽然可以使用得到结果,但是对其求导计算十分复杂,我们还可以进一步简化。考虑到我们是为了减少误分类的点,在最终找到超平面没有误分类点时损失函数为零,那么其实分母对我们的目的是没有影响的,因为只取分子的情况下,在误分类点减少时函数值也是一直减小的直到零,因此可以采用如下loss function
%3D%5Csum%7BX_i%5Cin%20D%7D-y_iW%5ETX_i%0A#card=math&code=L%28W%29%3D%5Csum%7BX_i%5Cin%20D%7D-y_iW%5ETX_i%0A&height=42&width=174)
学习算法
现在我们将问题简化为了最小化loss function。具体的方法是采用随机梯度下降法,梯度如下计算
%3D-%5Csum%7BX_i%5Cin%20D%7D-y_iX_i%0A#card=math&code=%5Cnabla_WL%28W%29%3D-%5Csum%7BX_i%5Cin%20D%7D-y_iX_i%0A&height=42&width=190)
那么针对某一个错误样本#card=math&code=%28X_i%2Cy_i%29&height=20&width=54),按如下方式对
进行更新
其中为步长,也称为学习率(learning rate)
迭代算法如下
(1)给定任意初始
(2)在训练数据集中选取数据()
(3)如果则根据式(*)更新权值
(4)检查是否还有误分类样本点,若有转至(2),若无算法结束
收敛性
上述算法一定能够成功结束吗,我们会不会进入一个无限循环迭代呢?即是不是在有限迭代次数内一定能够找到一个超平面将样本完全正确的的划分。下面证明算法的收敛性
由于数据集线性可分,则一定可以找到一个将数据集完美划分,不妨设
,对于所有的样本有
那么有如下结论

假设初始的,对于迭代算法中的第
个误分类点,则
%7D(W%5E%7B(t)%7D)%5ETX%5E%7B(t)%7D%5Clt0#card=math&code=y%5E%7B%28t%29%7D%28W%5E%7B%28t%29%7D%29%5ETX%5E%7B%28t%29%7D%5Clt0&height=24&width=140),根据式
#card=math&code=%28%2A%29&height=20&width=21)有
%7D%26%3DW%5E%7B(t-1)%7D%2B%5Ceta%20y%5E%7B(t-1)%7DX%5E%7B(t-1)%7D%5C%5C%0A%26%3DW%5E%7B(t-2)%7D%2B%5Ceta%20y%5E%7B(t-2)%7DX%5E%7B(t-2)%7D%2B%5Ceta%20y%5E%7B(t-1)%7DX%5E%7B(t-1)%7D%5C%5C%0A%26%3DW%5E%7B(0)%7D%2B%5Ceta%20y%5E%7B(0)%7DX%5E%7B(0)%7D%2B%5Ceta%20y%5E%7B(1)%7DX%5E%7B(1)%7D%2B%5Ccdots%2B%5Ceta%20y%5E%7B(t-1)%7DX%5E%7B(t-1)%7D%0A%5Cend%7Baligned%7D%5C%5C%0A%5C%5C%0A%5Cbegin%7Baligned%7D%0A%5CRightarrow%20W%7Bopt%7D%5ETW%5E%7B(t)%7D%26%3DW%7Bopt%7D%5ETW%5E%7B(0)%7D%2B%5Ceta%20y%5E%7B(0)%7DW%7Bopt%7D%5ETX%5E%7B(0)%7D%2B%5Ceta%20y%5E%7B(1)%7DW%7Bopt%7D%5ETX%5E%7B(1)%7D%2B%5Ccdots%2B%5Ceta%20y%5E%7B(t-1)%7DW%7Bopt%7D%5ETX%5E%7B(t-1)%7D%5C%5C%0A%26%5Cge%5Ceta%5Cgamma%2B%5Cge%5Ceta%5Cgamma%2B%5Ccdots%2B%5Ceta%5Cgamma%5C%5C%0A%26%3Dt%5Ceta%5Cgamma%0A%5Cend%7Baligned%7D%0A%5Cend%7Bgathered%7D%0A#card=math&code=%5Cbegin%7Bgathered%7D%0A%5Cbegin%7Baligned%7D%0AW%5E%7B%28t%29%7D%26%3DW%5E%7B%28t-1%29%7D%2B%5Ceta%20y%5E%7B%28t-1%29%7DX%5E%7B%28t-1%29%7D%5C%5C%0A%26%3DW%5E%7B%28t-2%29%7D%2B%5Ceta%20y%5E%7B%28t-2%29%7DX%5E%7B%28t-2%29%7D%2B%5Ceta%20y%5E%7B%28t-1%29%7DX%5E%7B%28t-1%29%7D%5C%5C%0A%26%3DW%5E%7B%280%29%7D%2B%5Ceta%20y%5E%7B%280%29%7DX%5E%7B%280%29%7D%2B%5Ceta%20y%5E%7B%281%29%7DX%5E%7B%281%29%7D%2B%5Ccdots%2B%5Ceta%20y%5E%7B%28t-1%29%7DX%5E%7B%28t-1%29%7D%0A%5Cend%7Baligned%7D%5C%5C%0A%5C%5C%0A%5Cbegin%7Baligned%7D%0A%5CRightarrow%20W%7Bopt%7D%5ETW%5E%7B%28t%29%7D%26%3DW%7Bopt%7D%5ETW%5E%7B%280%29%7D%2B%5Ceta%20y%5E%7B%280%29%7DW%7Bopt%7D%5ETX%5E%7B%280%29%7D%2B%5Ceta%20y%5E%7B%281%29%7DW%7Bopt%7D%5ETX%5E%7B%281%29%7D%2B%5Ccdots%2B%5Ceta%20y%5E%7B%28t-1%29%7DW%7Bopt%7D%5ETX%5E%7B%28t-1%29%7D%5C%5C%0A%26%5Cge%5Ceta%5Cgamma%2B%5Cge%5Ceta%5Cgamma%2B%5Ccdots%2B%5Ceta%5Cgamma%5C%5C%0A%26%3Dt%5Ceta%5Cgamma%0A%5Cend%7Baligned%7D%0A%5Cend%7Bgathered%7D%0A&height=165&width=616)
令,则有
%7D%7C%7C%5E2%26%3D%7C%7CW%5E%7B(t-1)%7D%7C%7C%5E2%2B2%5Ceta%20y%5E%7B(t-1)%7DW%5E%7B(t-1)%7D%5Ccdot%20X%5E%7B(t-1)%7D%2B%5Ceta%5E2(y%5E%7B(t-1)%7D)%5E2%7C%7CX%5E%7B(t-1)%7D%7C%7C%5E2%5C%5C%0A%26%3D%7C%7CW%5E%7B(t-1)%7D%7C%7C%5E2%2B2%5Ceta%20y%5E%7B(t-1)%7D(W%5E%7B(t-1)%7D)%5ETX%5E%7B(t-1)%7D%2B%5Ceta%5E2%7C%7CX%5E%7B(t-1)%7D%7C%7C%5E2%5C%5C%0A%26%5Clt%7C%7CW%5E%7B(t-1)%7D%7C%7C%5E2%2B%5Ceta%5E2%7C%7CX%5E%7B(t-1)%7D%7C%7C%5E2%5C%5C%0A%26%5Clt%7C%7CW%5E%7B(t-1)%7D%7C%7C%5E2%2B%5Ceta%5E2R%5E2%5C%5C%0A%26%5Clt%7C%7CW%5E%7B(0)%7D%7C%7C%5E2%2B%5Ceta%5E2R%5E2%2B%5Ccdots%2B%5Ceta%5E2R%5E2%5C%5C%0A%26%3Dt%5Ceta%5E2R%5E2%0A%5Cend%7Baligned%7D%0A#card=math&code=%5Cbegin%7Baligned%7D%0A%7C%7CW%5E%7B%28t%29%7D%7C%7C%5E2%26%3D%7C%7CW%5E%7B%28t-1%29%7D%7C%7C%5E2%2B2%5Ceta%20y%5E%7B%28t-1%29%7DW%5E%7B%28t-1%29%7D%5Ccdot%20X%5E%7B%28t-1%29%7D%2B%5Ceta%5E2%28y%5E%7B%28t-1%29%7D%29%5E2%7C%7CX%5E%7B%28t-1%29%7D%7C%7C%5E2%5C%5C%0A%26%3D%7C%7CW%5E%7B%28t-1%29%7D%7C%7C%5E2%2B2%5Ceta%20y%5E%7B%28t-1%29%7D%28W%5E%7B%28t-1%29%7D%29%5ETX%5E%7B%28t-1%29%7D%2B%5Ceta%5E2%7C%7CX%5E%7B%28t-1%29%7D%7C%7C%5E2%5C%5C%0A%26%5Clt%7C%7CW%5E%7B%28t-1%29%7D%7C%7C%5E2%2B%5Ceta%5E2%7C%7CX%5E%7B%28t-1%29%7D%7C%7C%5E2%5C%5C%0A%26%5Clt%7C%7CW%5E%7B%28t-1%29%7D%7C%7C%5E2%2B%5Ceta%5E2R%5E2%5C%5C%0A%26%5Clt%7C%7CW%5E%7B%280%29%7D%7C%7C%5E2%2B%5Ceta%5E2R%5E2%2B%5Ccdots%2B%5Ceta%5E2R%5E2%5C%5C%0A%26%3Dt%5Ceta%5E2R%5E2%0A%5Cend%7Baligned%7D%0A&height=148&width=512)
由以上推导最终可得
%7D%5Cle%7C%7CW%7Bopt%7D%7C%7C%5Ccdot%7C%7CW%5E%7B(t)%7D%7C%7C%3D%7C%7CW%5E%7B(t)%7D%7C%7C%5Clt%5Csqrt%7Bt%7D%5Ceta%20R%5C%5C%0A%5CRightarrow%20t%5Clt%5Cleft(%7BR%5Cover%5Cgamma%7D%5Cright)%5E2%0A%5Cend%7Bgathered%7D%0A#card=math&code=%5Cbegin%7Bgathered%7D%0At%5Ceta%5Cgamma%5Cle%20W%7Bopt%7D%5ETW%5E%7B%28t%29%7D%5Cle%7C%7CW_%7Bopt%7D%7C%7C%5Ccdot%7C%7CW%5E%7B%28t%29%7D%7C%7C%3D%7C%7CW%5E%7B%28t%29%7D%7C%7C%5Clt%5Csqrt%7Bt%7D%5Ceta%20R%5C%5C%0A%5CRightarrow%20t%5Clt%5Cleft%28%7BR%5Cover%5Cgamma%7D%5Cright%29%5E2%0A%5Cend%7Bgathered%7D%0A&height=76&width=395)
因为在给定样本集后均为常数,则迭代次数
是有上界的,即数据集线性可分的情况下,在有限迭代次数内一定能够找到一个超平面将样本完全正确的的划分,感知机学习算法是收敛的。但当数据集不是线性可分时,感知机算法不收敛,迭代结果会发生震荡
几何解释
还有另外一种理解感知机的方式:对于空间中的超平面,其法向量为
,那么对于一个样本点
有
,显然决定
符号的关键就是向量
与向量
的夹角
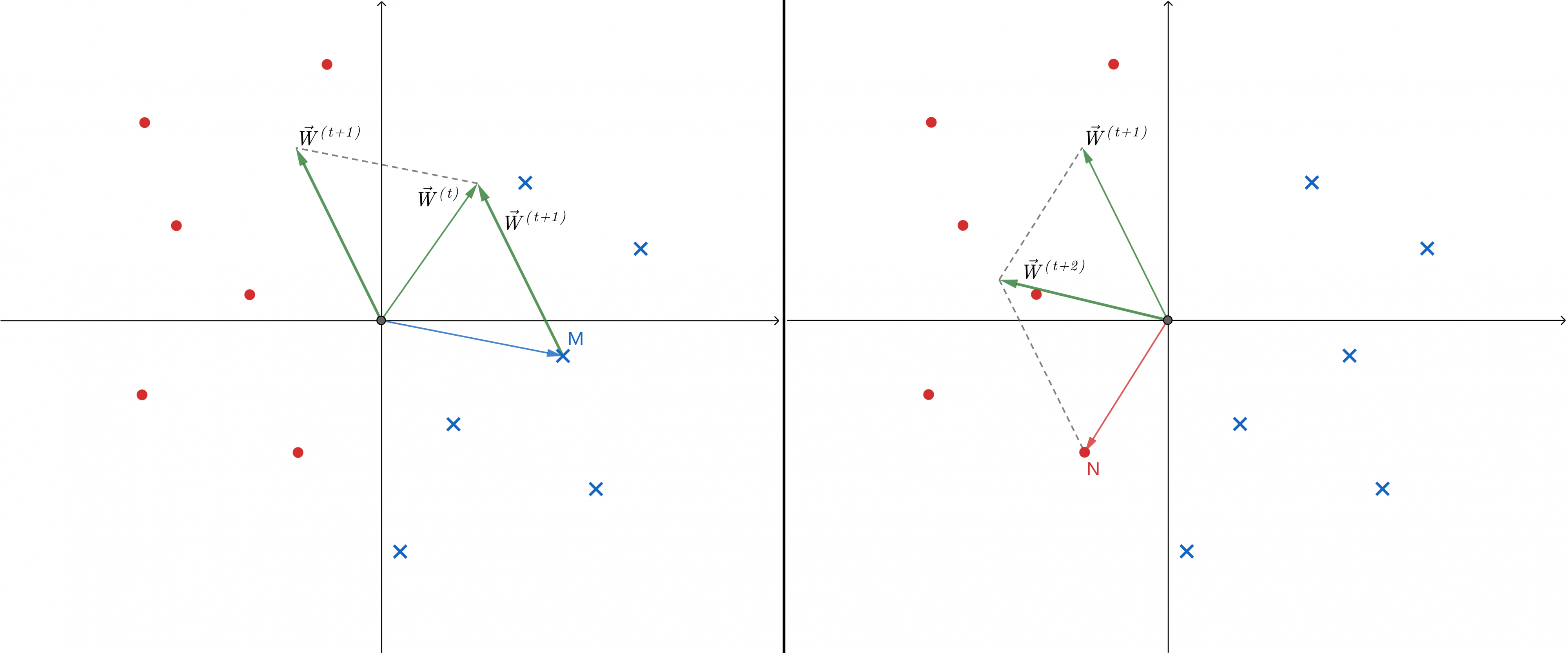
如图左边所示,假设红点为正类蓝点为负类。在%7D#card=math&code=W%5E%7B%28t%29%7D&height=20&width=33)时,我们随机找到一个误分类点如负类点M,从图中容易看到M本应该分类为-1,即
%7D)%5ETX_m%3D%5Cvec%7BW%7D%5E%7B(t)%7D%5Ccdot%20%5Cvec%7BX%7D_m%5Clt0#card=math&code=%28W%5E%7B%28t%29%7D%29%5ETX_m%3D%5Cvec%7BW%7D%5E%7B%28t%29%7D%5Ccdot%20%5Cvec%7BX%7D_m%5Clt0&height=28&width=207),那么
%7D#card=math&code=%5Cvec%7BW%7D%5E%7B%28t%29%7D&height=25&width=32)与
夹角应该大于90度,于是我们要想办法让
%7D#card=math&code=%5Cvec%7BW%7D%5E%7B%28t%2B1%29%7D&height=25&width=48)远离
,增大夹角。于是我们令
%7D%3D%5Cvec%7BW%7D%5E%7B(t)%7D-%5Cvec%7BX%7D_m#card=math&code=%5Cvec%7BW%7D%5E%7B%28t%2B1%29%7D%3D%5Cvec%7BW%7D%5E%7B%28t%29%7D-%5Cvec%7BX%7D_m&height=28&width=150)即可达到目的,又
则
%7D%26%3D%5Cvec%7BW%7D%5E%7B(t)%7D-%5Cvec%7BX%7D_m%5C%5C%0A%26%3DW%5E%7B(t)%7D%2By_mX_m%0A%5Cend%7Baligned%7D%0A#card=math&code=%5Cbegin%7Baligned%7D%0A%5Cvec%7BW%7D%5E%7B%28t%2B1%29%7D%26%3D%5Cvec%7BW%7D%5E%7B%28t%29%7D-%5Cvec%7BX%7D_m%5C%5C%0A%26%3DW%5E%7B%28t%29%7D%2By_mX_m%0A%5Cend%7Baligned%7D%0A&height=52&width=176)
如图右边所示,在%7D#card=math&code=W%5E%7B%28t%2B1%29%7D&height=20&width=48)时仍有误分类点,因此需要继续优化。我们随机找到一个误分类点如正类点N,从图中容易看到N本应该分类为+1,即
%7D)%5ETX_n%3D%5Cvec%7BW%7D%5E%7B(t%2B1)%7D%5Ccdot%20%5Cvec%7BX%7D_n%5Cgt0#card=math&code=%28W%5E%7B%28t%2B1%29%7D%29%5ETX_n%3D%5Cvec%7BW%7D%5E%7B%28t%2B1%29%7D%5Ccdot%20%5Cvec%7BX%7D_n%5Cgt0&height=28&width=230),那么
%7D#card=math&code=%5Cvec%7BW%7D%5E%7B%28t%2B1%29%7D&height=25&width=48)与
夹角应该小于90度,于是我们要想办法让
%7D#card=math&code=%5Cvec%7BW%7D%5E%7B%28t%2B2%29%7D&height=25&width=48)接近
,减小夹角。于是我们令
%7D%3D%5Cvec%7BW%7D%5E%7B(t%2B1)%7D%2B%5Cvec%7BX%7D_n#card=math&code=%5Cvec%7BW%7D%5E%7B%28t%2B2%29%7D%3D%5Cvec%7BW%7D%5E%7B%28t%2B1%29%7D%2B%5Cvec%7BX%7D_n&height=28&width=162)即可达到目的,又
则
%7D%26%3D%5Cvec%7BW%7D%5E%7B(t%2B1)%7D%2B%5Cvec%7BX%7D_n%5C%5C%0A%26%3DW%5E%7B(t%2B1)%7D%2By_nX_n%0A%5Cend%7Baligned%7D%0A#card=math&code=%5Cbegin%7Baligned%7D%0A%5Cvec%7BW%7D%5E%7B%28t%2B2%29%7D%26%3D%5Cvec%7BW%7D%5E%7B%28t%2B1%29%7D%2B%5Cvec%7BX%7D_n%5C%5C%0A%26%3DW%5E%7B%28t%2B1%29%7D%2By_nX_n%0A%5Cend%7Baligned%7D%0A&height=52&width=185)
于是可以对于一个误分类点#card=math&code=%28X_i%2Cy_i%29&height=20&width=54)统一为如下迭代公式
实际在迭代过程中不用每次加上整个向量,可以令
,每次迭代加上向量
,即
这个形式与感知机算法等价

若有收获,就点个赞吧
0 人点赞
