Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
原文地址:DeepLabv3+
本文是在DeepLabv3的基础上将多个技术融合到一起,达到新的state-of-the-art。
论文在提出了DeepLabv3+架构。主要以DeepLabv3做encoder架构,decoder采用一个简单却有效的模块。并探索了了改进的Xception和深度分离卷积在模型中的应用,进一步提升模型在语义分割任务上的性能。
Abstract
空间金字塔模块在输入feature上应用多采样率扩张卷积(膨胀卷积)、多接收野卷积或池化,探索多尺度上下文信息。 Encoder-Decoder结构通过逐渐恢复空间信息来捕捉清晰的目标边界。
DeepLabv3+结合了这两者的优点,具体来说,以DeepLabv3为encoder架构,在此基础上添加了简单却有效的decoder模块用于细化分割结果。此外论文进一步探究了以Xception结构为模型主干,并探讨了Depthwise separable convolution在ASPP和decoder模块上的应用,最终得到了更快更强大的encoder-decoder网络。
论文在PASCAL VOC 2012上验证了模型的有效性,在没有添加任何后端处理的情况下达到了89%mIoU.
Introduction
在DeepLabv3+中,使用了两种类型的神经网络,使用空间金字塔模块和encoder-decoder结构做语义分割。
空间金字塔:通过在不同分辨率上以池化操作捕获丰富的上下文信息
encoder-decoder架构:逐渐的获得清晰的物体边界
DeepLabv3+结合这两者的优点,在DeepLabv3的基础上拓展了一个简单有效的模块用于恢复边界信息。如下图所示: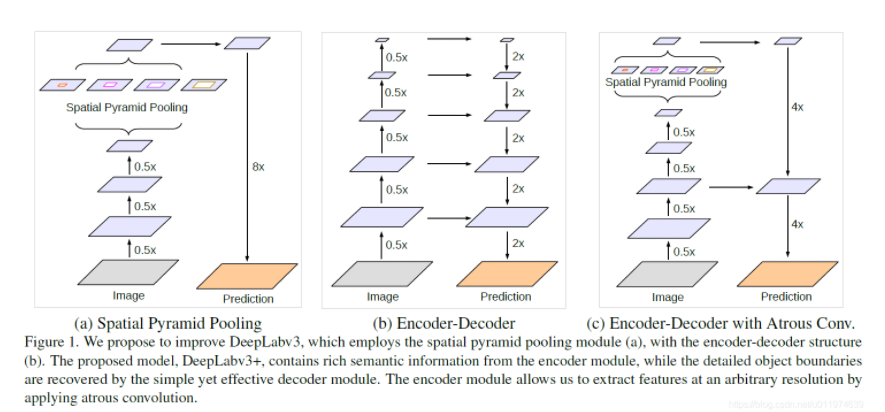
(a): 即DeepLabv3的结构,使用ASPP模块获取多尺度上下文信息,直接上采样得到预测结果
(b): encoder-decoder结构,高层特征提供语义,decoder逐步恢复边界信息
(c):DeepLabv3+结构,以DeepLabv3为encoder,decoder结构简单
DeepLabv3的top layer输出的feature中有丰富的语义信息,可通过扩张卷积依据计算资源限制控制计算密度,配合一个decoder模块用于逐渐恢复边界信息。
在上述的encoder-decoder架构上,论文受到Xception等工作启发,将深度分离卷积应用到ASPP和decoder模块,用于快速计算并保持模型的强大学习能力。最终得到的模型在没有添加后端处理的情况下,达到了新的state-of-the-art.
论文的主要贡献在于:
- 论文提出了一个全新的encoder-decoder架构,使用DeepLabv3作为encoder模块,并添加了一个简单却有效的decoder模块
- 在我们提出的encoder-decoder架构中,可通过扩张卷积直接控制提取encoder特征的分辨率,用于平衡精度和运行时间
- 论文将Xception结构应用于分割任务中,在ASPP和decoder模块中加入深度分离卷积,获得到强大又快速的模型
- 模型达到了新的state-of-the-art,同时我们给出了模型设计分析细节和模型变体
Related Work
近几年基于全卷积神经网络的模型在语义分割任务上表现成功。有几种变体模型提出利用上下文信息包括多尺度输入在内的做分割,也有采用概率图模型细化分割结果。本文主要讨论使用空间金字塔池化和encoder-decoder结构、并讨论了基于Xception为主体的强大特征提取层,和基于深度分离卷积快速计算。
空间金字塔池化:如PSPNet使用多个不同gird的池化,DeepLab的ASPP模块平行的使用不同扩张率的扩张卷积,执行空间金字塔合并获取多尺度信息。在多个benchmark获得不错的结果。
Encoder-Decoder: encoder-decoder结构在多个计算机视觉任务上获得成功,例如人类姿态估计、目标检测和语义分割。通常,encoder-decoder网络包含:
encoder模块逐步减少feature map分辨率,捕获高级语义信息
decoder模块逐渐恢复空间信息
在这领域上基础上,我们使用DeepLabv3作为encoder模块,并增加一个简单又有效的的decoder模块获取空间信息。
深度分离卷积: 深度分离卷积和组卷积能够减少计算消耗和参数量的同时维持相似的表现。深度分离卷积已应用在多个神经网络中,特别的,我们探索了Xception架构,在语义分割任务上展现了精度和速度上的双重提升。
Methods
本节简单回顾DeepLabv3架构,提出改进后的Xception模型,介绍扩张卷积和深度分离卷积。
Encoder-Decoder with Atrous Convolution
DeepLabv3 as encoder:
DeepLabv3中也使用扩张卷积提取特征,我们将输入和输出的分辨率比值称为output_stride, 对于语义分割任务,使用扩张卷积替换下采样,使得输出的feature的output_stride=16。
DeepLabv3的ASPP模块使用了多个平行的扩张卷积,配合了图像级特征(即全局平均池化)。我们将DeepLabv3的logit前的输出特征作为encoder-decoder模型的encoder输出。此时输出的feature通道为256,可依据计算资源限制合理使用扩张卷积。
Proposed decoder:
在原先的DeepLabv3中,取预测的feature 直接双线性上采样16倍到期望尺寸,这样的简易的decoder模块不能成功的恢复分割细节(这个问题在Understand Convolution for Semantic Segmentation重点讨论过~)
DeepLabv3+的整体的架构如下图所示: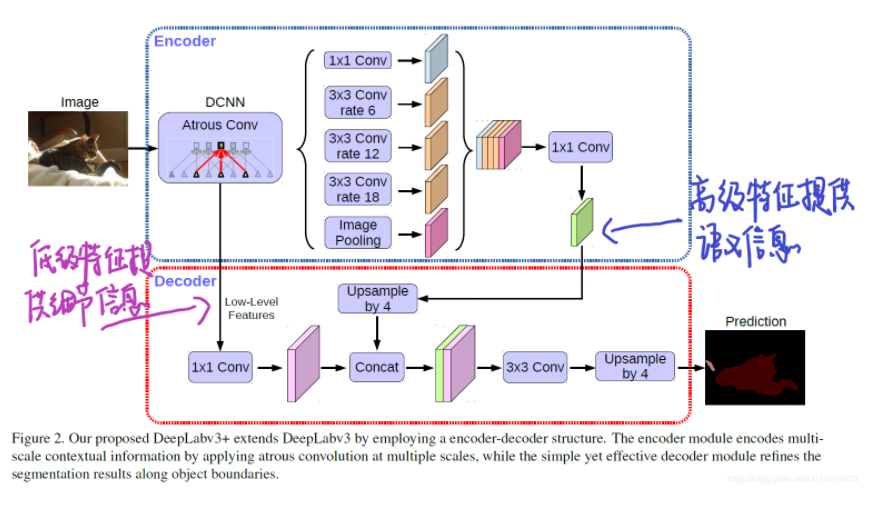

使用分离卷积改进Xcetpion
扩张分离卷积
Atrous Convolution:
DeepLab系列,Understand Convolution for Semantic Segmentation, Dilated Residual Networks 
Depthwise separable convolution:
深度分离卷积在MobileNet里面重点讲过,这里简单说一下:
深度可分离卷积干的活是:把标准卷积分解成深度卷积(depthwise convolution)和逐点卷积(pointwise convolution)。深度卷积对每个通道独立使用空间卷积,逐点卷积用于结合深度卷积的输出。深度分离卷积可以大幅度降低参数量和计算量。
我们将扩张卷积核深度分离卷积结合到一起,即扩张分离卷积。扩张分离卷积能够显著的减少模型的计算复杂度并维持相似的表现。
Modified Aligned Xcetpion
论文受到近期MSRA组在Xception上改进工作可变形卷积(Deformable-ConvNets)启发,Deformable-ConvNets对Xception做了改进,能够进一步提升模型学习能力,新的结构如下: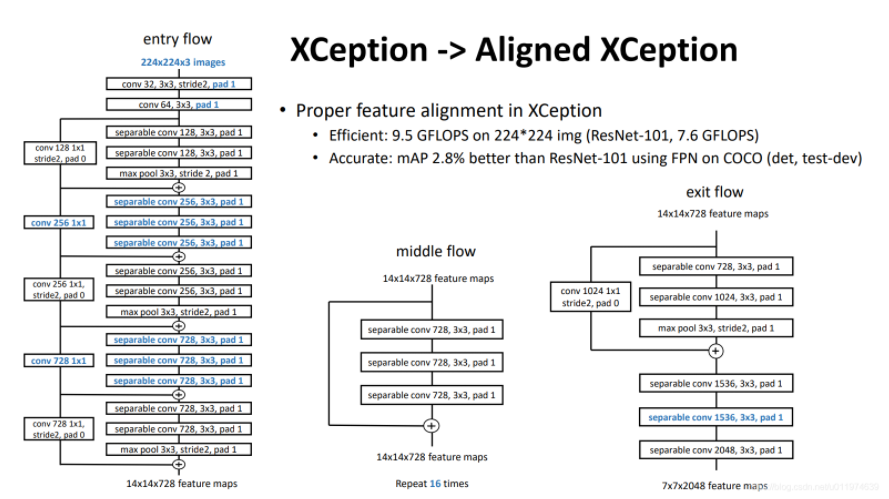
摘自MSRA COCO Detection & Segmentation Challenge 2017 Entry。
论文进一步改进了MSRA的工作以适应语义分割任务,具体如下:
- 更深的Xception结构,不同的地方在于不修改entry flow network的结构,为了快速计算和有效的使用内存
- 所有的最大池化操作替换成带下采样的深度分离卷积,这能够应用扩张分离卷积扩展feature的分辨率
- 在每个3 × 3的深度卷积后增加BN层和ReLU
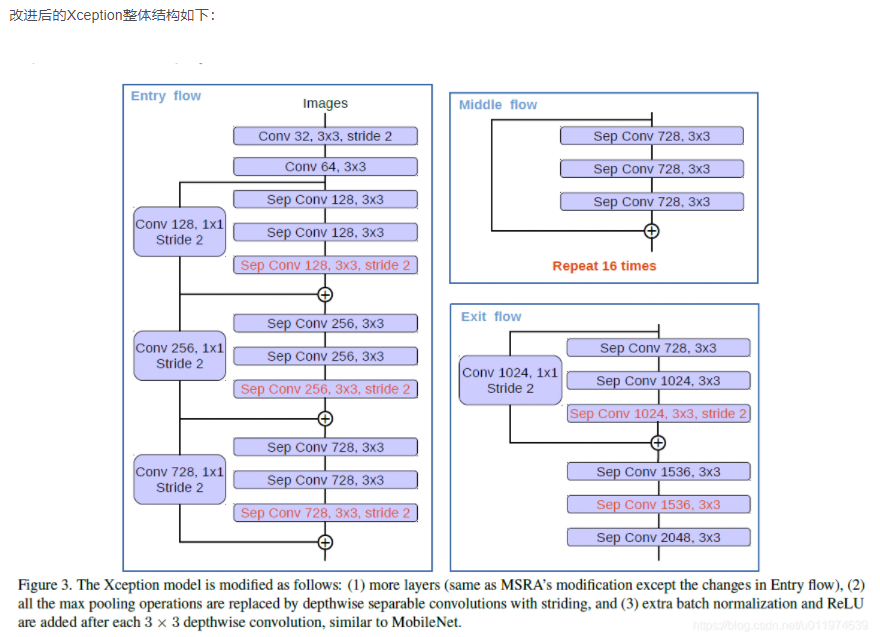
改进后的Xception为encodet网络主体,替换原本DeepLabv3的ResNet101.
Experiment
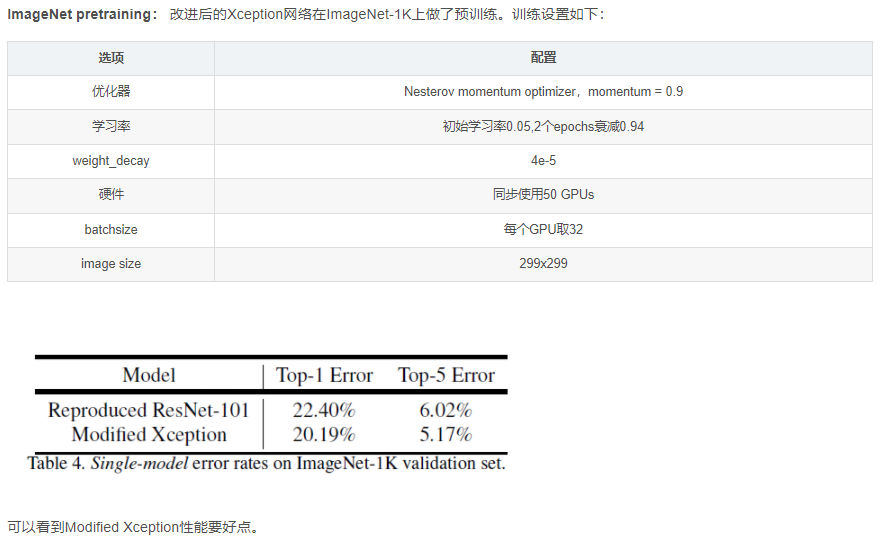
论文使用modified aligned Xception改进后的ResNet-101,在ImageNet-1K上做预训练,通过扩张卷积做密集的特征提取。采用DeepLabv3的训练方式(poly学习策略,crop513 × 513 513×513513×513).注意在decoder模块同样包含BN层。
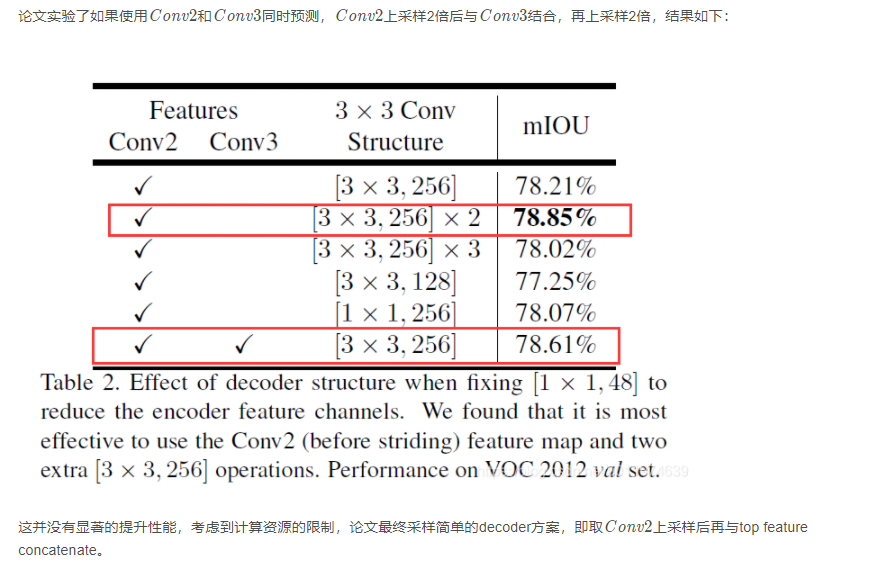
Decoder Design Choise

使用1×1卷积减少来自低级feature的通道数
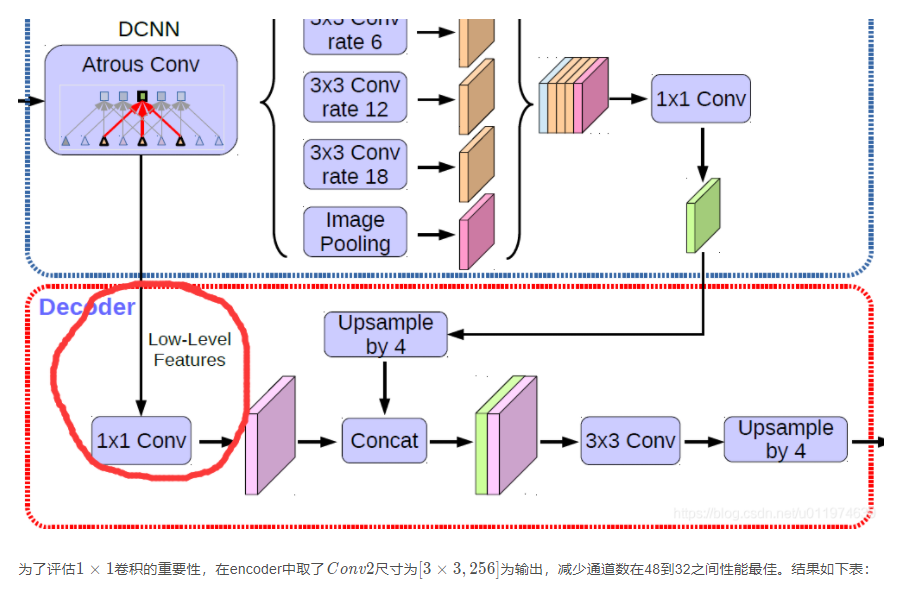

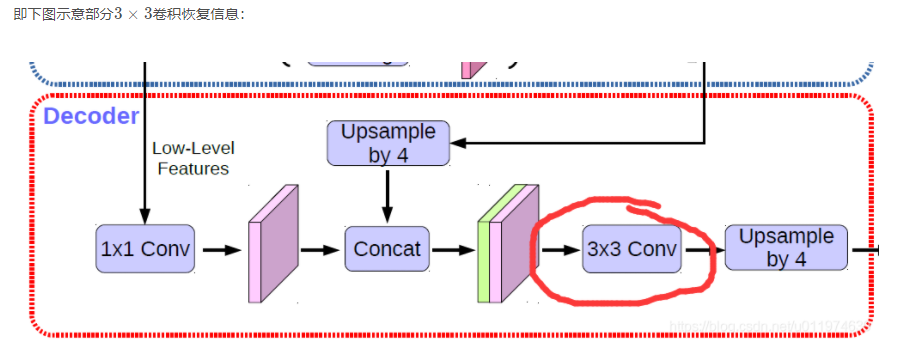
是否需要3 × 3 3×33×3卷积逐步获取分割结果
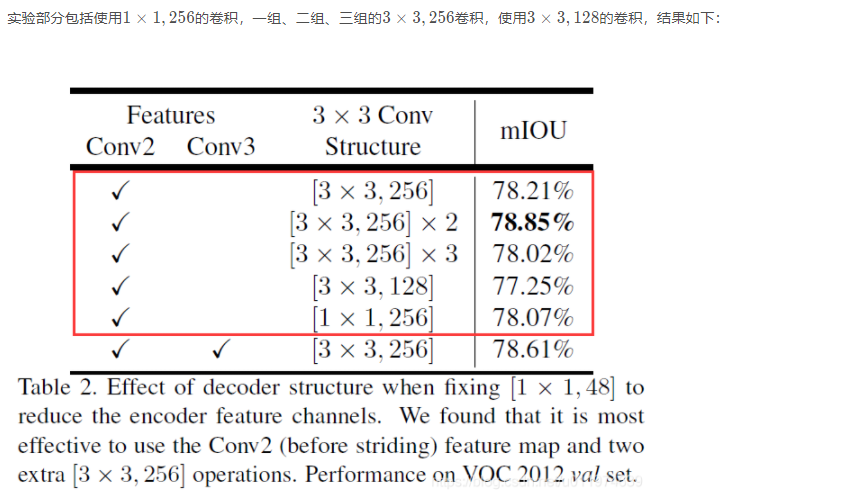
结果显示使用两组3 × 3 , 256 3×3,2563×3,256卷积性能最佳。
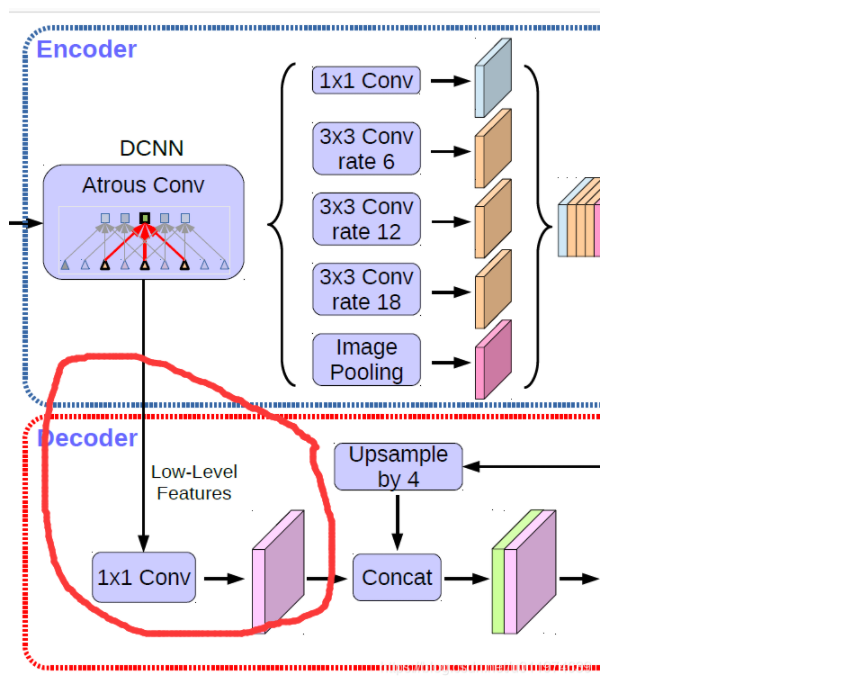
使用那部分的低级特征帮助提供细节
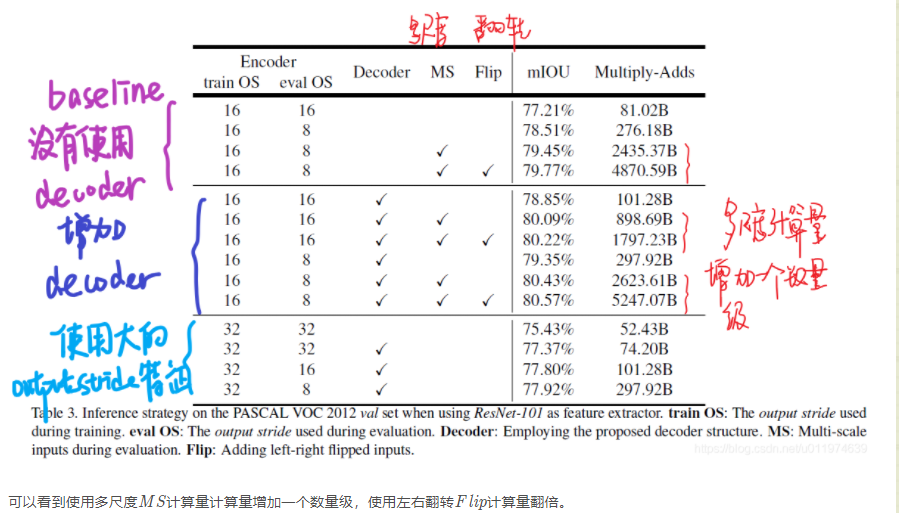
ResNet-101 as Network Backbone

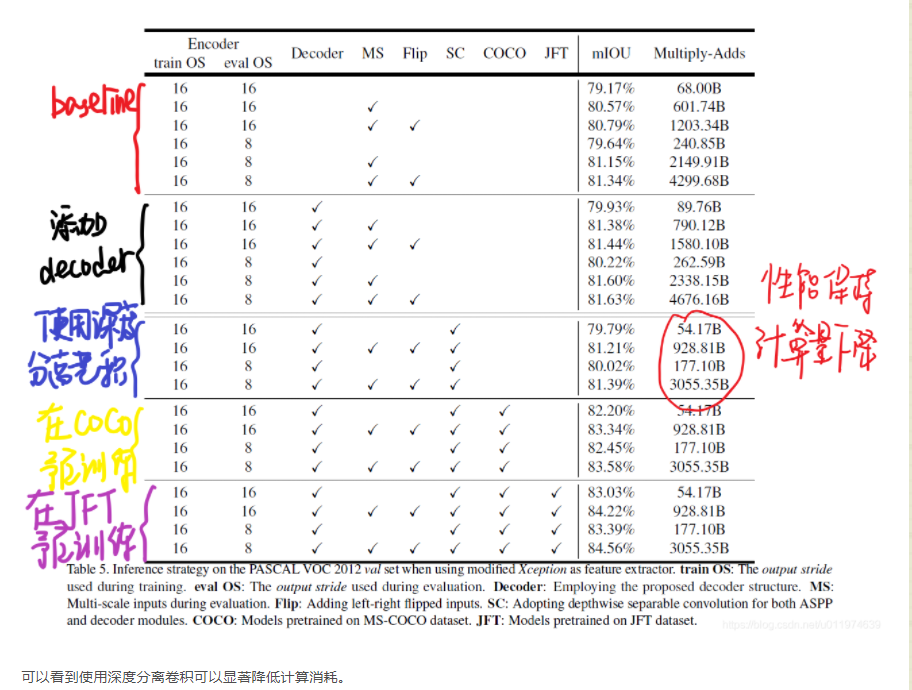
Xception as Network Backbone


在目标边界上的提升
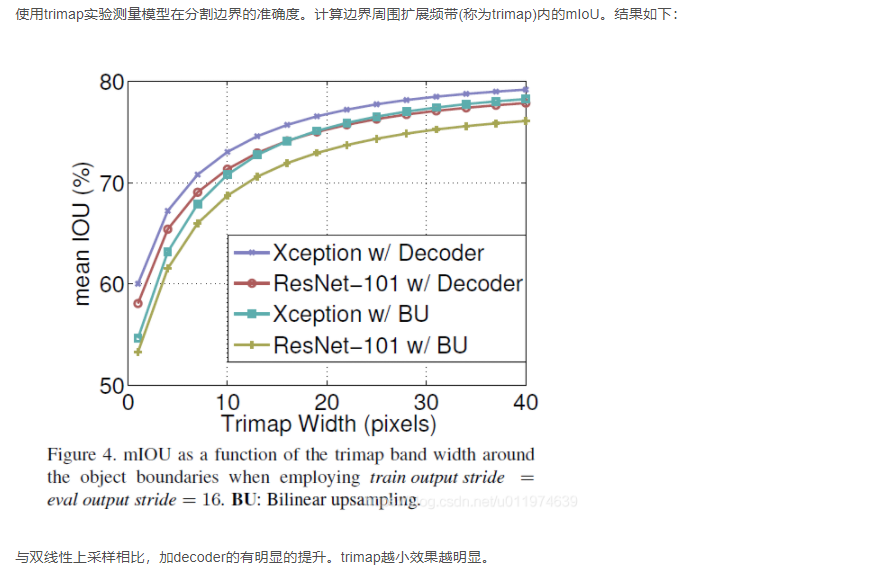

Conclusion
论文提出的DeepLabv3+是encoder-decoder架构,其中encoder架构采用DeepLabv3,decoder采用一个简单却有效的模块用于恢复目标边界细节。并可使用扩张卷积在指定计算资源下控制feature的分辨率。
论文探索了Xception和深度分离卷积在模型上的使用,进一步提高模型的速度和性能。模型在VOC2012上获得了新的state-of-the-art表现。
引用:https://blog.csdn.net/u011974639/article/details/79518175

若有收获,就点个赞吧
0 人点赞
