Changing Landscape
之前才讲过说,我们能不能够直接改error surface 的 landscape,我们觉得说 error surface 如果很崎嶇的时候,它比较难 train,那我们能不能够直接把山剷平,让它变得比较好 train 呢?Batch Normalization 就是其中一个,把山剷平的想法
我们一开始就跟大家讲说,不要小看 optimization 这个问题,有时候就算你的 error surface 是 convex的,它就是一个碗的形状,都不见得很好 train.假设你的两个参数啊,它们对 Loss 的斜率差别非常大,在 w1这个方向上面,你的斜率变化很小,在w2这个方向上面斜率变化很大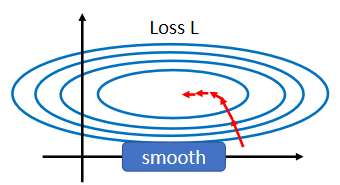
如果是固定的 learning rate,你可能很难得到好的结果,所以我们才说你需要adaptive 的 learning rate、 Adam 等等比较进阶的 optimization 的方法,才能够得到好的结果。现在我们要从另外一个方向想,直接把难做的 error surface 把它改掉,看能不能够改得好做一点。在做这件事之前,也许我们第一个要问的问题就是,有这一种状况, w1跟w2它们的斜率差很多的这种状况,到底是从什麼地方来的。假设我现在有一个非常非常非常简单的 model,它的输入是x1跟x2,它对应的参数就是 w1跟w2,它是一个 linear 的 model,没有 activation function。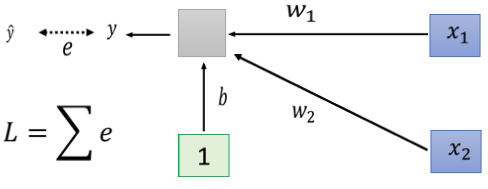
w1乘x1, w2乘x2加上 b 以后就得到 y,然后会计算 y 跟 之间的差距当做 e,把所有 training data e 加起来就是你的 Loss,然后去 minimize 你的 Loss.那什麼样的状况我们会產生像上面这样子,比较不好 train 的 error surface 呢?
之间的差距当做 e,把所有 training data e 加起来就是你的 Loss,然后去 minimize 你的 Loss.那什麼样的状况我们会產生像上面这样子,比较不好 train 的 error surface 呢?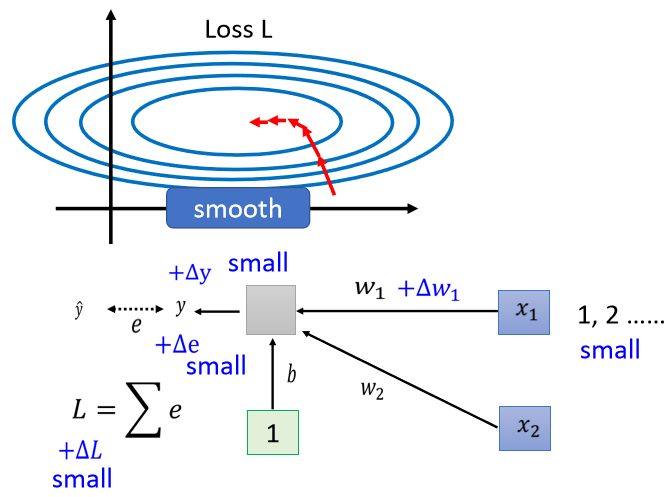
当我们对w1有一个小小的改变,比如说加上 delta w1的时候,那这个 L 也会有一个改变,那这个w1呢,是透过w1改变的时候,你就改变了 y,y 改变的时候你就改变了 e,然后接下来就改变了 L。那什麼时候w1的改变会对 L 的影响很小呢,也就是它在 error surface 上的斜率会很小呢?一个可能性是当你的 input 很小的时候,假设x1的值在不同的 training example 裡面,它的值都很小,那因為x1是直接乘上w1,如果x1的值都很小, w1有一个变化的时候,它得到的,它对 y 的影响也是小的,对 e 的影响也是小的,它对 L 的影响就会是小的。
反之呢,如果今天是x2的话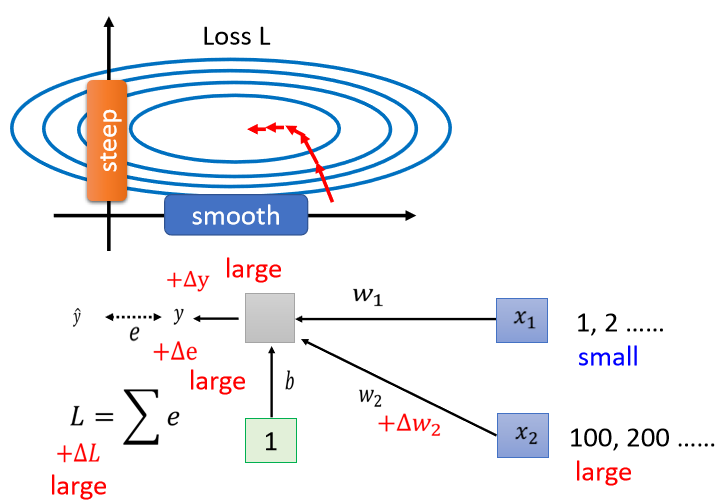
那假设x2的值都很大,当你的w2有一个小小的变化的时候,虽然w2这个变化可能很小,但是因為它乘上了x2 , x2的值很大,那 y 的变化就很大,那 e 的变化就很大,那 L 的变化就会很大,就会导致我们在 w 这个方向上,做变化的时候,我们把 w 改变一点点,那我们的 error surface 就会有很大的变化
所以你发现说,既然在这个 linear 的 model 裡面,当我们 input 的 feature,每一个 dimension 的值,它的 scale 差距很大的时候,我们就可能產生像这样子的 error surface,就可能產生不同方向,斜率非常不同,坡度非常不同的 error surface
所以怎麼办呢,我们有没有可能给feature 裡面不同的 dimension,让它有同样的数值的范围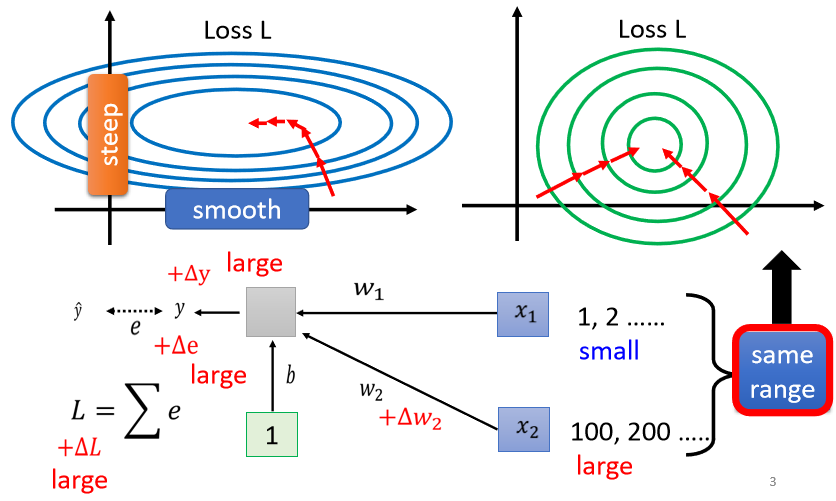
如果我们可以给不同的 dimension,同样的数值范围的话,那我们可能就可以製造比较好的 error surface,让 training 变得比较容易一点。其实有很多不同的方法,这些不同的方法,往往就合起来统称為Feature Normalization。
Feature Normalization
以下所讲的方法只是Feature Normalization 的一种可能性,它并不是 Feature Normalization 的全部,假设x1到xR,是我们所有的训练资料的 feature vector.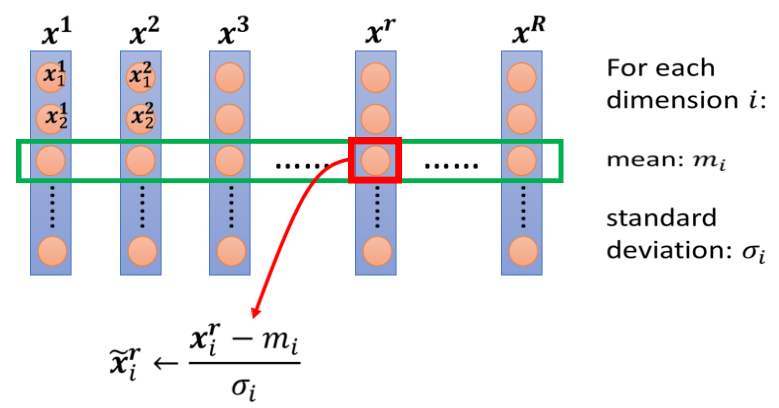

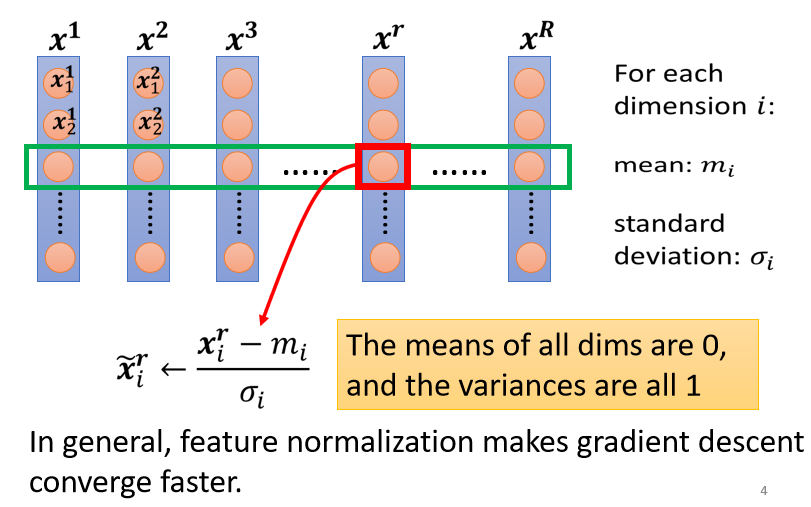
- 做完 normalize 以后啊,这个 dimension 上面的数值就会平均是 0,然后它的 variance就会是 1,所以这一排数值的分布就都会在 0 上下
- 对每一个 dimension都做一样的 normalization,就会发现所有 feature 不同 dimension 的数值都在 0 上下,那你可能就可以製造一个,比较好的 error surface。
所以像这样子 Feature Normalization 的方式,往往对你的 training 有帮助,它可以让你在做 gradient descent 的时候,这个 gradient descent,它的 Loss 收敛更快一点,可以让你的 gradient descent,它的训练更顺利一点,这个是 Feature Normalization
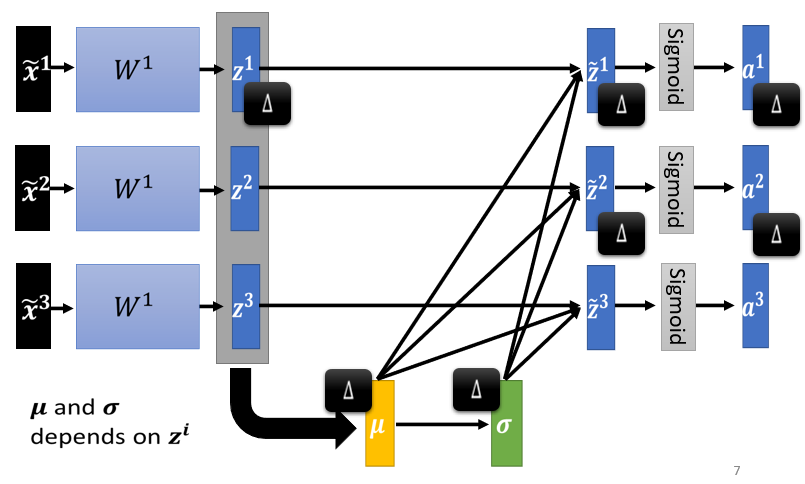
Considering Deep Learning
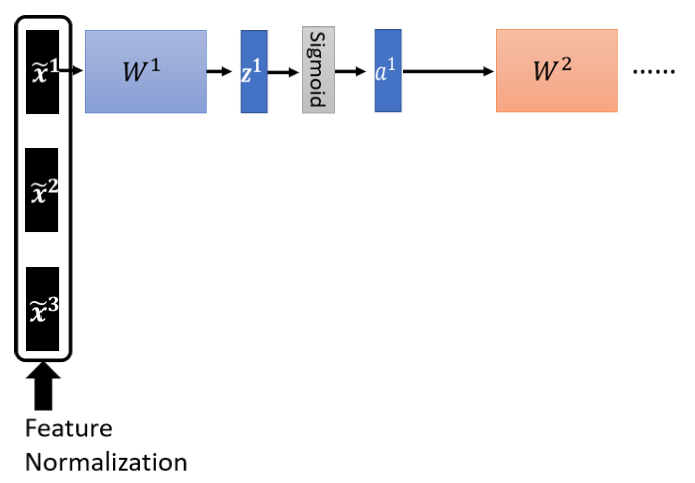
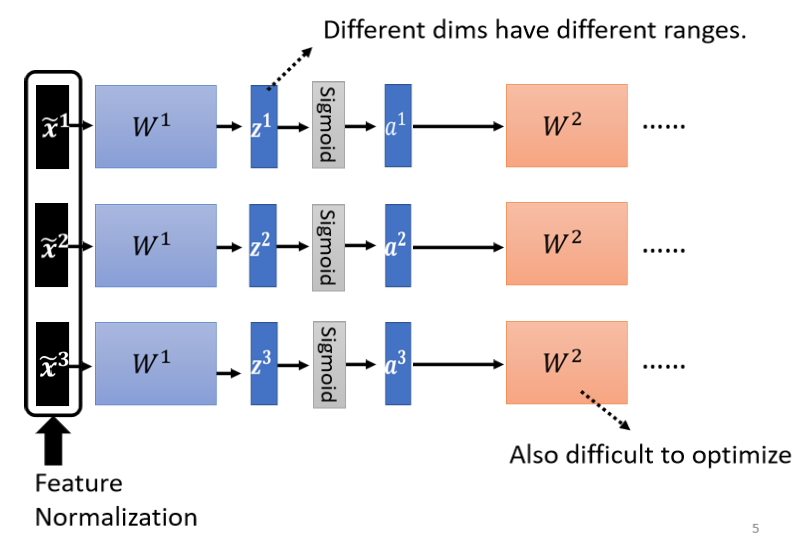

对w2来说,这边的 a 或这边的 z 其实也是一种 feature,我们应该要对这些 feature 也做 normalization.那如果你选择的是 Sigmoid,那可能比较推荐对 z 做 Feature Normalization,因為Sigmoid 是一个 s 的形状,那它在 0 附近斜率比较大,所以如果你对 z 做 Feature Normalization,把所有的值都挪到 0 附近,那你到时候算 gradient 的时候,算出来的值会比较大
那不过因為你不见得是用 sigmoid ,所以你也不一定要把 Feature Normalization放在 z 这个地方,如果是选别的,也许你选a也会有好的结果,也说不定,Ingeneral 而言,这个 normalization,要放在 activation function 之前,或之后都是可以的,在实作上,可能没有太大的差别,好 那我们这边呢,就是对 z 呢,做一下 Feature Normalization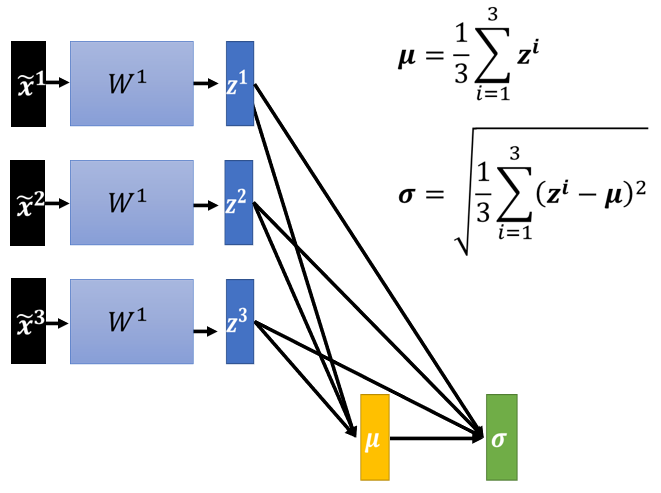
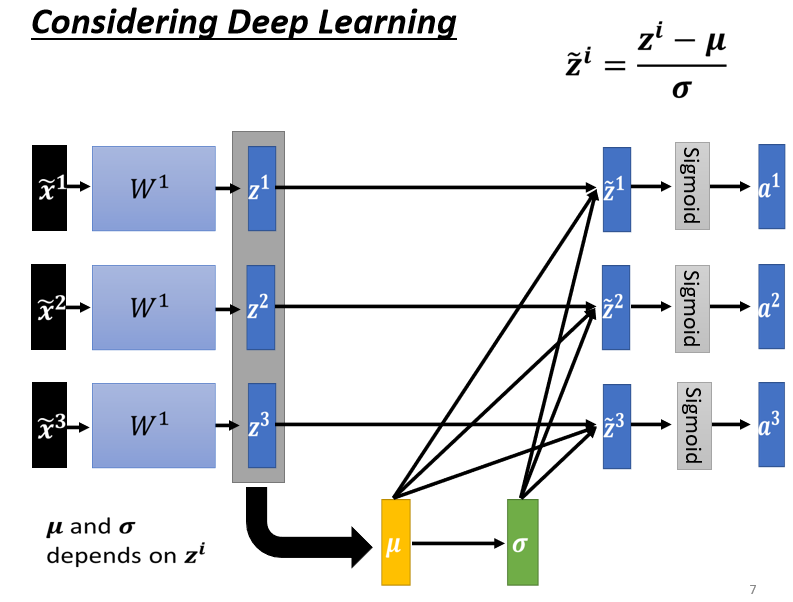
有时候文字真的是苍白的,一图胜千言。
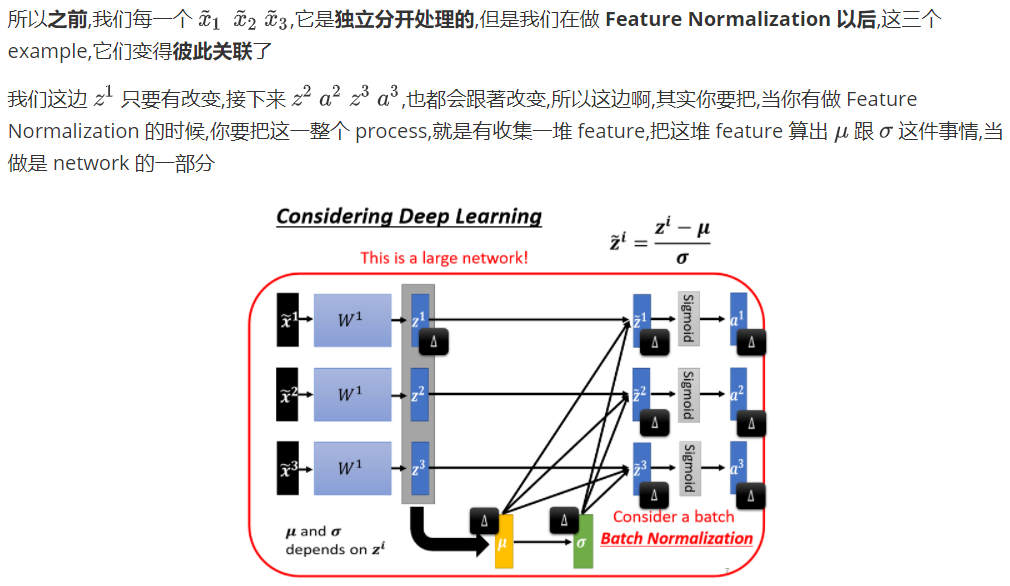
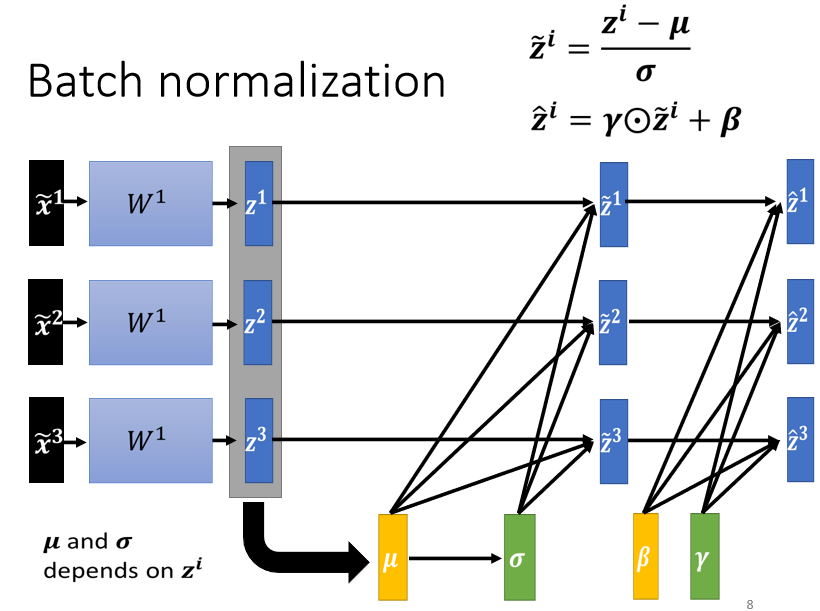
方法,思想都挺好。但是理论归理论,不能脱离实际。 假设说我们现在的有上百万data,GPU的memory根本就没有办法把所有的数据都load进去。在实作的时候,你不会让这一个 network 考虑整个 training data 裡面的所有 example,你只会考虑一个 batch 裡面的 example,举例来说,你 batch设64,那你这个巨大的 network,就是把 64 笔 data 读进去,算这 64 笔 data 的 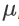 ,算这 64 笔 data 的
,算这 64 笔 data 的 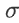 ,对这 64 笔 data 都去做 normalization因為我们在实作的时候,我们只对一个 batch 裡面的 data,做 normalization,所以这招叫做 Batch Normalization。
,对这 64 笔 data 都去做 normalization因為我们在实作的时候,我们只对一个 batch 裡面的 data,做 normalization,所以这招叫做 Batch Normalization。
那这个 Batch Normalization,显然有一个问题 就是,你一定要有一个够大的 batch,你才算得出 跟 ,假设你今天,你 batch size 设 1,那你就没有什麼或可以算,所以这个 Batch Normalization,是适用於 batch size 比较大的时候,因為 batch size 如果比较大,也许这个 batch size 裡面的 data,就足以表示,整个 corpus 的分布,那这个时候你就可以,把这个本来要对整个 corpus,做 Feature Normalization 这件事情,改成只在一个 batch,做 Feature Normalization,作為 approximation,

Testing
以上说的都是 training 的部分,testing ,有时候又叫 inference ,所以有人在文件上看到有人说,做个 inference,inference 指的就是 testing
这个 Batch Normalization 在 inference,或是 testing 的时候,会有什麼样的问题呢,在 testing 的时候,如果 当然如果今天你是在做作业,我们一次会把所有的 testing 的资料给你,所以你确实也可以在 testing 的资料上面,製造一个一个 batch.但是假设你真的有系统上线,你是一个真正的线上的 application,你可以说,我今天一定要等 30,比如说你的 batch size 设 64,我一定要等 64 笔资料都进来,我才一次做运算吗,这显然是不行的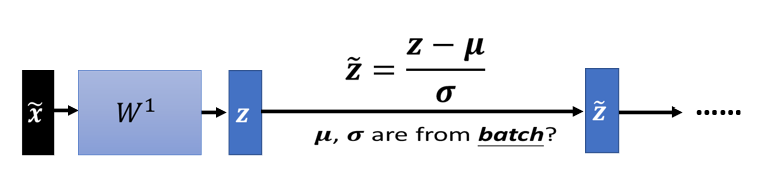
但是在做 Batch Normalization 的时候,一个 ,一个 normalization 过的 feature 进来,然后你有一个 z,你的 z 呢,要减掉
,一个 normalization 过的 feature 进来,然后你有一个 z,你的 z 呢,要减掉 跟除
跟除 ,那这个跟
,那这个跟 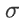 ,是用一个 batch 的资料算出来的。但如果今天在 testing 的时候,根本就没有 batch,那我们要怎麼算这个,跟怎麼算这个 呢?
,是用一个 batch 的资料算出来的。但如果今天在 testing 的时候,根本就没有 batch,那我们要怎麼算这个,跟怎麼算这个 呢?
所以真正的,这个实作上的解法是这个样子的,如果你看那个 PyTorch 的话呢,Batch Normalization 在 testing 的时候,你并不需要做什麼特别的处理,PyTorch 帮你处理好了。在 training 的时候,如果你有在做 Batch Normalization 的话,在 training 的时候,你每一个 batch 计算出来的跟 ,他都会拿出来算 moving average。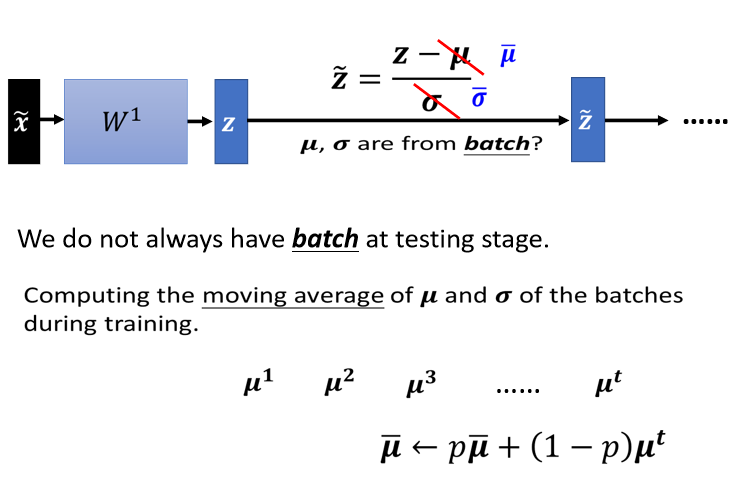

Comparison
那这个是从 Batch Normalization,原始的文件上面截出来的一个实验结果,那在原始的文件上还讲了很多其他的东西,举例来说,我们今天还没有讲的是,Batch Normalization 用在 CNN 上,要怎麼用呢,那你自己去读一下原始的文献,裡面会告诉你说,Batch Normalization 如果用在 CNN 上,应该要长什麼样子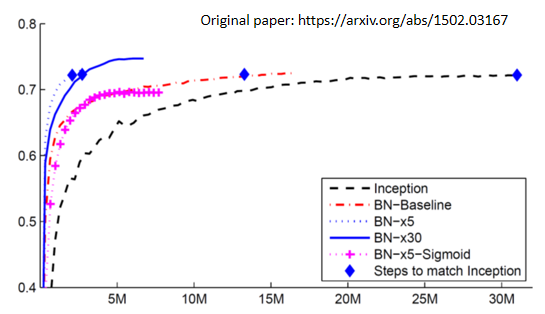
这个是原始文献上面截出来的一个数据
- 横轴呢,代表的是训练的过程,纵轴代表的是 validation set 上面的 accuracy
- 那这个黑色的虚线是没有做 Batch Normalization 的结果,它用的是 inception 的 network,就是某一种 network 架构啦,也是以 CNN 為基础的 network 架构
- 然后如果有做 Batch Normalization,你会得到红色的这一条虚线,那你会发现说,红色这一条虚线,它训练的速度,显然比黑色的虚线还要快很多,虽然最后收敛的结果啊,就你只要给它足够的训练的时间,可能都跑到差不多的 accuracy,但是红色这一条虚线,可以在比较短的时间内,就跑到一样的 accuracy,那这边这个蓝色的菱形,代表说这几个点的那个 accuracy 是一样的
- 粉红色的线是 sigmoid function,就 sigmoid function 一般的认知,我们虽然还没有讨论这件事啦,但一般都会选择 ReLu,而不是用 sigmoid function,因為 sigmoid function,它的 training 是比较困难的,但是这边想要强调的点是说,就算是 sigmoid 比较难搞的,加 Batch Normalization,还是 train 的起来,那这边没有 sigmoid,没有做 Batch Normalization 的结果,因為在这个实验上,作者有说,sigmoid 不加 Batch Normalization,根本连 train 都 train 不起来
- 蓝色的实线跟这个蓝色的虚线呢,是把 learning rate 设比较大一点,乘 5,就是 learning rate 变原来的 5 倍,然后乘 30,就是 learning rate 变原来的 30 倍,那因為如果你做 Batch Normalization 的话,那你的 error surface 呢,会比较平滑 比较容易训练,所以你可以把你的比较不崎嶇,所以你就可以把你的 learning rate 呢,设大一点,那这边有个不好解释的奇怪的地方,就是不知道為什麼,learning rate 设 30 倍的时候,是比 5 倍差啦,那作者也没有解释啦,你也知道做 deep learning 就是,有时候会產生这种怪怪的,不知道怎麼解释的现象就是了,不过作者就是照实,把他做出来的实验结果,呈现在这个图上面。
Internal Covariate Shift?
Batch Normalization,它為什麼会有帮助呢,在原始的 Batch Normalization,那篇 paper 裡面,他提出来一个概念,叫做 internal covariate shift,covariate shift(训练集和预测集样本分布不一致的问题就叫做“covariate shift”现象) 这个词汇是原来就有的,internal covariate shift,我认為是,Batch Normalization 的作者自己发明的。他认為说今天在 train network 的时候,会有以下这个问题,这个问题是这样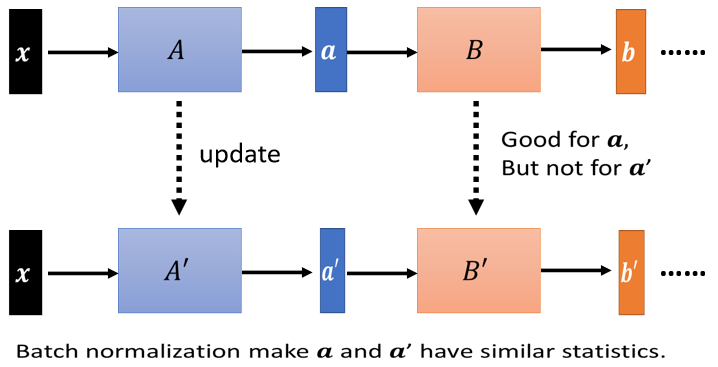
network 有很多层,x 通过第一层以后 得到 a。 a 通过第二层以后 得到 b。计算出 gradient 以后,把 A update 成 A′,把 B 这一层的参数 update 成 B′,但是作者认為说,我们在计算 B,update 到 B′ 的 gradient 的时候,这个时候前一层的参数是 A 啊,或者是前一层的 output 是小 a 啊
那当前一层从 A 变成 A′ 的时候,它的 output 就从小 a 变成小 a′ 啊。但是我们计算这个 gradient 的时候,我们是根据这个 a 算出来的啊,所以这个 update 的方向,也许它适合用在 a 上,但不适合用在 a′ 上面。那如果说 Batch Normalization 的话,我们会让,因為我们每次都有做 normalization,我们就会让 a 跟 a′ 呢,它的分布比较接近,也许这样就会对训练呢,有帮助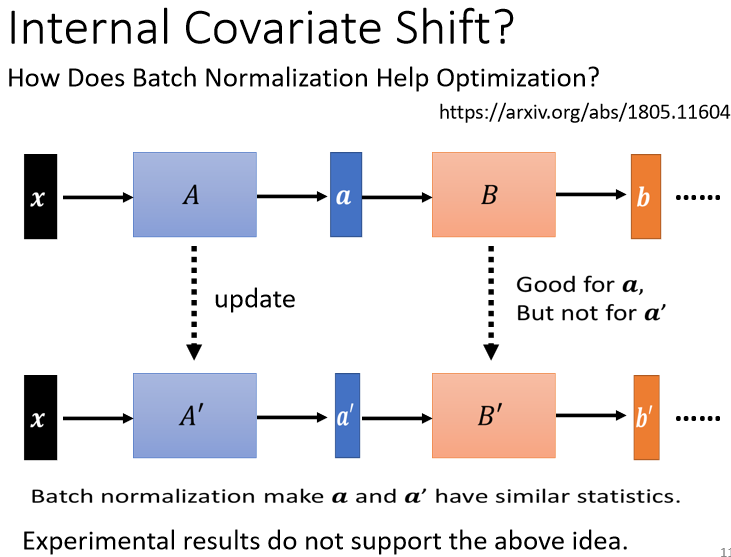
但是有一篇 paper 叫做,How Does Batch Normalization,Help Optimization,然后他就打脸了internal covariate shift 的这一个观点
在这篇 paper 裡面,他从各式各样的面向来告诉你说,internal covariate shift,首先它不一定是 training network 的时候的一个问题,然后 Batch Normalization,它会比较好,可能不见得是因為,它解决了 internal covariate shift。那在这篇 paper 裡面呢,他做了很多很多的实验,比如说他比较了训练的时候,这个 a 的分布的变化 发现,不管有没有做 Batch Normalization,它的变化都不大。然后他又说,就算是变化很大,对 training 也没有太大的伤害,然后他又说,不管你是根据 a 算出来的 gradient,还是根据 a′ 算出来的 gradient,方向居然都差不多。所以他告诉你说,internal covariate shift,可能不是 training network 的时候,最主要的问题,它可能也不是,Batch Normalization 会好的一个的关键,那有关更多的实验,你就自己参见这篇文章。為什麼 Batch Normalization 会比较好呢,那在这篇 How Does Batch Normalization,Help Optimization 这篇论文裡面,他从实验上,也从理论上,至少支持了 Batch Normalization,可以改变 error surface,让 error surface 比较不崎嶇这个观点。
所以这个观点是有理论的支持,也有实验的佐证的,那在这篇文章裡面呢,作者还讲了一个非常有趣的话,他说他觉得啊,这个 Batch Normalization 的 positive impact。因為他说,如果我们要让 network,这个 error surface 变得比较不崎嶇,其实不见得要做 Batch Normalization,感觉有很多其他的方法,都可以让 error surface 变得不崎嶇,那他就试了一些其他的方法,发现说,跟 Batch Normalization performance 也差不多,甚至还稍微好一点,所以他就讲了下面这句感嘆。他觉得说,这个,positive impact of batchnorm on training,可能是 somewhat,serendipitous,什麼是 serendipitous 呢,这个字眼可能可以翻译成偶然的,但偶然并没有完全表达这个词汇的意思,这个词汇的意思是说,你发现了一个什麼意料之外的东西
举例来说,盘尼西林就是,意料之外的发现,大家知道盘尼西林的由来就是,有一个人叫做弗莱明,然后他本来想要那个,培养一些葡萄球菌,然后但是因為他实验没有做好,他的那个葡萄球菌被感染了,有一些霉菌掉到他的培养皿裡面,然后发现那些培养皿,那些霉菌呢,会杀死葡萄球菌,所以他就发明了,发现了盘尼西林,所以这是一种偶然的发现。那这篇文章的作者也觉得,Batch Normalization 也像是盘尼西林一样,是一种偶然的发现,但无论如何,它是一个有用的方法
To learn more ……
那其实 Batch Normalization,不是唯一的 normalization,normalization 的方法有一把啦,那这边就是列了几个比较知名的,
Batch Renormalizationhttps://arxiv.org/abs/1702.03275
Layer Normalizationhttps://arxiv.org/abs/1607.06450
Instance Normalizationhttps://arxiv.org/abs/1607.08022
Group Normalizationhttps://arxiv.org/abs/1803.08494
Weight Normalizationhttps://arxiv.org/abs/1602.07868
Spectrum Normalizationhttps://arxiv.org/abs/1705.10941
引用:https://unclestrong.github.io/DeepLearning_LHY21_Notes/Notes_html/01_Regression_P1.html(部分做了修改)
本文仅供个人学习,侵删。

若有收获,就点个赞吧
0 人点赞
