手写数字数据集
中科院CASIA数据集
1、CASIA-HWDB1.0-1.2
表 1. 离线孤立字符数据集统计
| Dataset | #writers | #character samples | ||
|---|---|---|---|---|
| total | Symbol | Chinese/#class | ||
| HWDB1.0 | 420 | 1,680,258 | 71,122 | 1,609,136/3,866 |
| HWDB1.1 | 300 | 1,172,907 | 51,158 | 1,121,749/3,755 |
| HWDB1.2 | 300 | 1,041,970 | 50,981 | 990,989/3,319 |
| Total | 1,020 | 3,895,135 | 173,261 | 3,721,874/7,185 |
HWDB1.0包括3866个汉字和171个字母数字和符号。在3866个汉字中,GB2312-80一级集中有3740个汉字(共3755个汉字)。
HWDB1.1包括3755个GB2312-80一级汉字和171个字母数字和符号。
HWDB1.2包括3319个汉字和171个字母数字和符号。HWDB1.2(3319个类)中的汉字集是HWDB1.0的不相交集。
HWDB1.0和HWDB1.2共包含7185个汉字(7,185=3,866+3,319),其中包括GB2312中的全部6763个汉字。
2、CASIA-HWDB2.0-2.2。
表 3 离线手写文本数据集统计
| Dataset | #writers | #pages | #lines | #character/#class | #out-of-class sample |
|---|---|---|---|---|---|
| HWDB2.0 | 419 | 2,092 | 20,495 | 538,868/1,222 | 1,106 |
| HWDB2.1 | 300 | 1,500 | 17,292 | 429,553/2,310 | 172 |
| HWDB2.2 | 300 | 1,499 | 14,443 | 380,993/1,331 | 581 |
| 全部的 | 1,019 | 5,091 | 52,230 | 1,349,414/2,703 | 1,859 |
数据来源:http://www.nlpr.ia.ac.cn/databases/handwriting/Download.html
哈工大HIT-OR3C数据集
HIT-OR3C由5个子集组成 (GB1, GB2, Digit, Letter, 和Document),GB1和GB2是汉字标注库GB2312-80内2个子集的简写。GB1, GB2, Digit, 和 Letter子集已采集完成122套,共832,650 个手写汉字。Document子集包括10个从新浪网收集的文档,每个文档采集2套,共收集了20套。文档子集共有77,168个字符, 覆盖2,442个字符,其中2,286个来自GB1,97个来自GB2,49个来自Letter, 10个来自 Digit。
数据来源:http://icrc.hitsz.edu.cn/info/1037/1111.htm
华南理工SCUTCOUCH-2009数据集
SCUT-COUCH2009是一款包括12个子集的完整数据,它们分别是:中文词组、国标一级汉字、国标二级汉字、国标一级汉字对应的繁体字、汉语拼音、英文字母、阿拉伯数字、常用符号、Word8888、Word17366、Word44208和联机文本行数据。每套完整的SCUT-COUCH2009包括6,763个GB2312-80单汉字,5401个Big5繁体字,1384个和GB2312-80一级字库相对应的繁体字,8,888个常用的中文词组,17,366个常用中文词组,摘自《现代汉语大辞典》(第四版)的44,208个词组,2,010个汉语拼音,184个其他符号(包括字母、数字和常用符号)和8,809行联机文本行;现在版本的SCUT-COUCH2009使用PDA或手写屏进行采集,已完成了由190多人书写的完整的数据,字符总数超过3.6百万个。
数据来源:http://www.hcii-lab.net/data/scutcouch/CN/download.html
模型选择
该项目的本质并没有设计到OCR的核心技术-文本检测和文本识别。本质上来说这是一个多分类的项目,基本上所有的分类网络都可以对其进行建模。
经过挑选,选择了EasyOCR,该项目训练简单,效果不错。
CASIA-HWDB1.1数据集上的实验结果100个汉字30W步的情况下能够达到99%。
所有汉字一起训练10w步可以达到90%以上的准确率、
代码
训练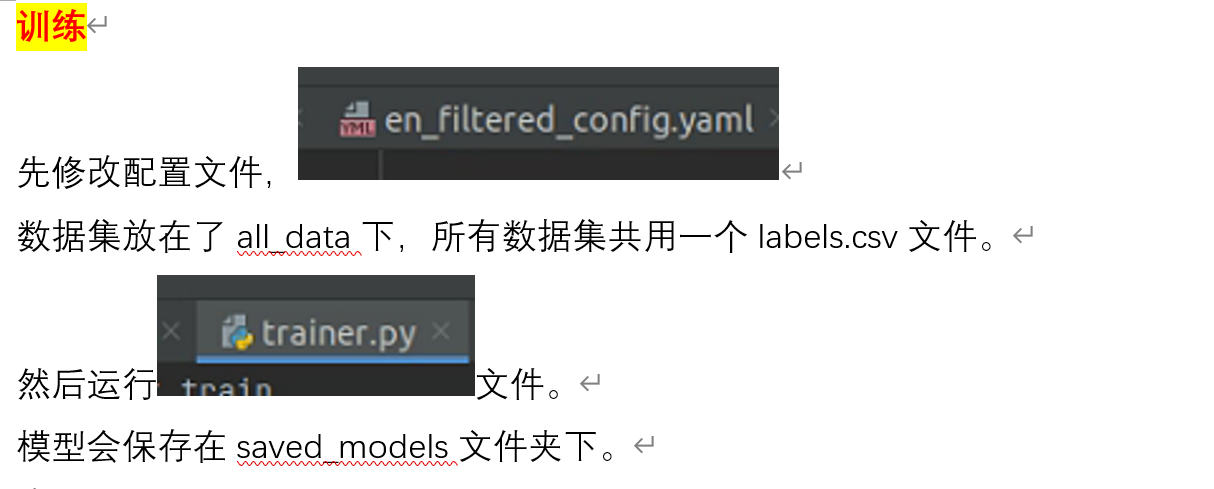
推演,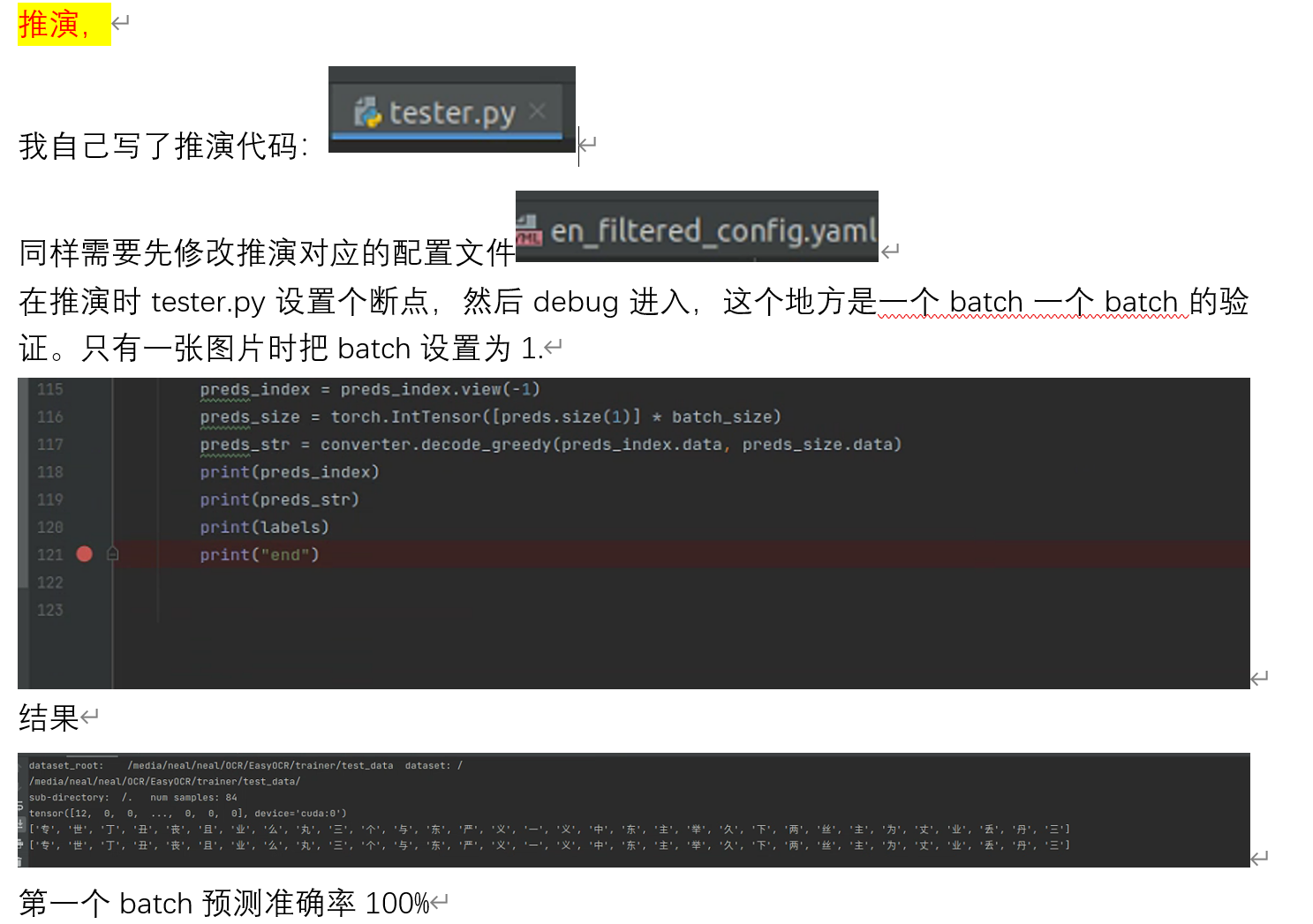
推演代码还有待完善,

若有收获,就点个赞吧
0 人点赞
