FCN是深度学习用于语义分割的鼻祖了。
FullyConvolutional Networks forSemantic Segmentation 是 UC Berkeley提出来的,也是 2015 年CVPR的best paper 。2014年11月发表在arXiv上。
FCN的主要思想如下图所说:
将原本的分类模型(AlexNet)的最后的全连接层,转化成全卷积,不在输出分类特征,而是一个热图(heatmap)。
下面FCN更详细的信息:
- FCN-32s在模型最后conv 7的特征图上,进行步长为32的,上采样,还原到原始图片大小。
- FCN-16s在pool 4 层后,加上一个1x1的卷积层,产生一个支路输出特征图A。对conv 7的输出进行步长为 2的上采样,得到特征图B。这时候A和B大小一样,进行特征融合,然后进行步长为16的上采样,还原到原始图片大小。
- FCN-8s在pool 3 层后,加上一个1x1的卷积层,产生一个支路输出特征图A。在pool 4 层后,加上一个1x1的卷积层,输出进行步长为 2的上采样,产生一个支路输出特征图B。对conv 7 的输出进行步长为 4 的上采样,得到特征图C。这时候A、B、C大小一样,进行特征融合,然后进行步长为8的上采样,还原到原始图片大小。
关于上面所说的上采样:
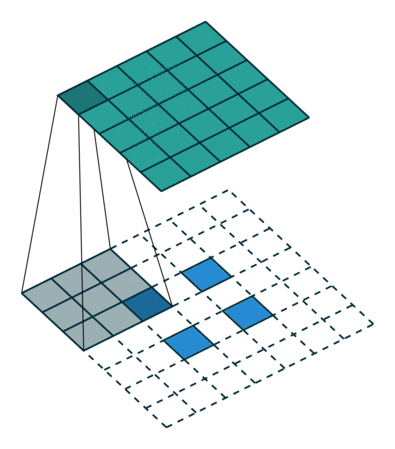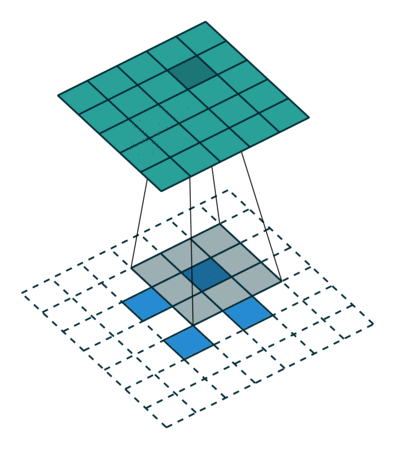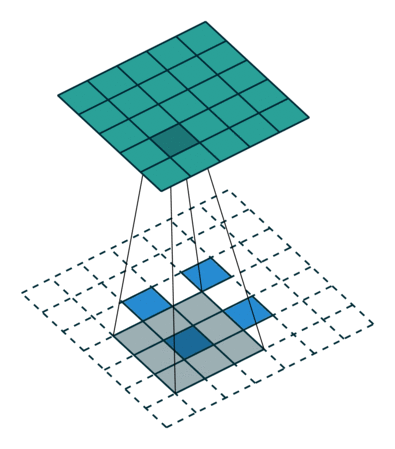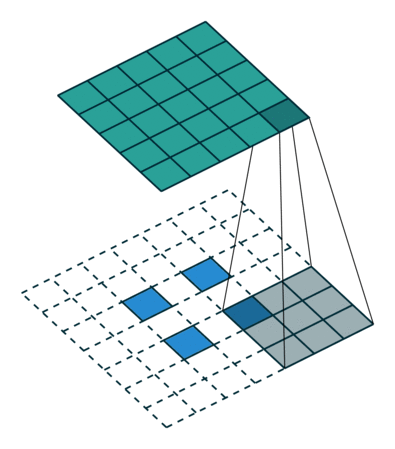
上采样本质是插值。FCN中上采样的方法是反卷积(Deconvolution)。Caffe和Kera里叫Deconvolution,而tensorflow 里叫 conv_transpose。论文中,作者说反卷积的卷积核是可以学习的,但是代码中并没有学习,lr_mult: 0。和网络前面卷积层不同,deconvolution 中卷积核个数不是随机的,而是根据放大的尺寸生成了与类别相同数量的矩阵。
论文中采用的上采样是双线性内插,通过卷积操作完成的。先上池化,然后卷积。如下图:(蓝色是输入,蓝绿色是输出)
https://img2018.cnblogs.com/blog/1366400/201903/1366400-20190306122823641-1153150233.gif
DeconvNet
是韩国的Hyeonwoo Noh 在 ICCV 2015 的文章。2015年5月17日发表在arXiv上的文章。Learning Deconvolution Network for Semantic Segmentation是对FCN的改进。
DeconvNet 的结构是经典encoder-decoder结构。相比于FCN有点混乱的结构,这种对称的结构就显得很优雅。如下图: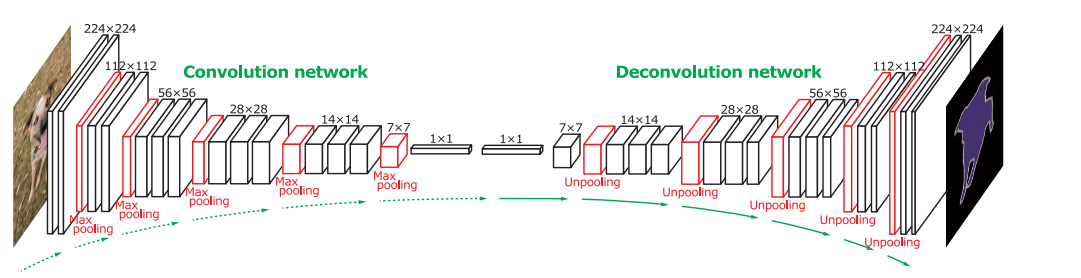
前面的encoder部分是VGG-16去掉分类部分的前13个卷积层,末尾是2个全连接层。Decoder部分是对称的反卷积层。
有两点比较独特:
- 在 pooling 处理的过程中会记录最大值位置,unpooling 的时候会把相应的值放回到原来位置。
- 作者强调他们的反卷积网络权重是学习的。

若有收获,就点个赞吧
0 人点赞

{kind=link}