SegNet: A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labelling
这是和DeconvNet 同期的模型,是Vijay Badrinarayanan在2015年5月27日(仅仅相差10天)发表在arXiv上的。
结构和DeconvNet十分相似,给人一种撞衫的感觉。(可见科研的激烈程度,23333)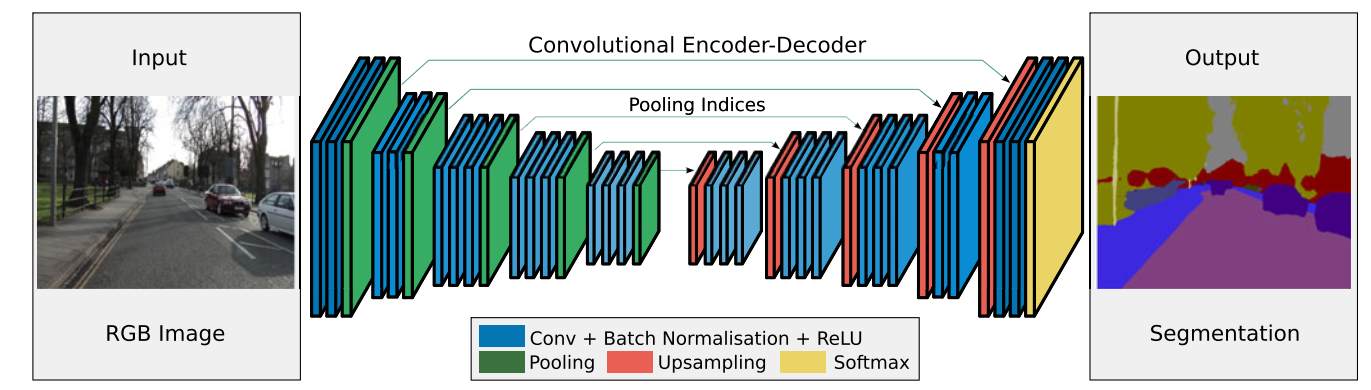
相同的两点:
- 都是经典encoder-decoder结构,encoder部分都是根据VGG-16来的。
- pooling 过程都记录了位置信息,upsampling 的时候使用位置信息。如下图:
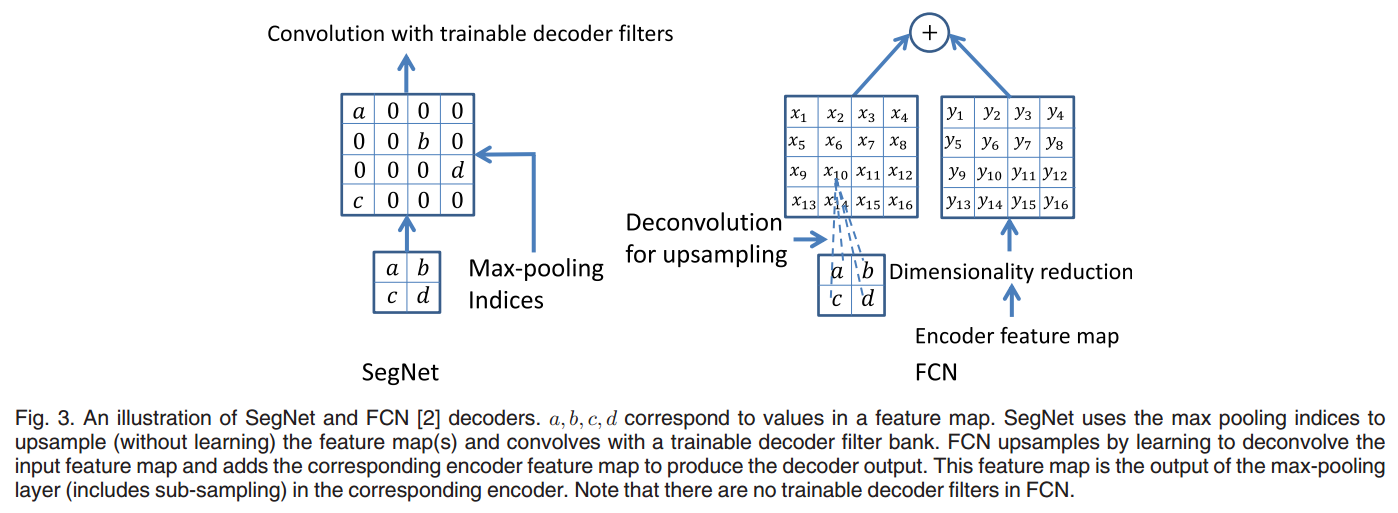
不同点:
- 仔细看,SegNet在encoder-decoder中间没有deconvNet的两个全连接层。
- SegNet 在卷积层上加了BN结构。
知乎上有网友的评价:
segnet去掉了全连接层从而提升了速度,加了batch normalization加快了收敛抑制了过拟合,加了bayesion可以输出图像的不确定性分割数值,加了test batch dropout提升测试时的性能,加了带权重softmax应对分割样本不均衡现象。可以说,segnet是更实用的框架。
Tensorflow 目前还不支持在池化的时候保留索引,这就很尴尬了。所以上面两个都只有caffe的代码。有人重现了Tensorflow版本的SegNet,不是还是和原始的有些不同。有cpu版本的可用,会比较慢。

若有收获,就点个赞吧
0 人点赞
