张量tf.Tensor
- tf.Tensor(id, shape=(), dtype, value, graph, name)
常量
- a = tf.constant(2)
- a = tf.constant(2, name= ‘a’)
值
- a.numpy() 输出张量的值
Shape
- a.get_shape() 输出shape值
前面已经赋值了,后面name属性有什么用呢? 答:前面的赋值变量用于输入输出,保存模型时以name为准
张量操作
- tf.add/sub/and/or/matmul
变量tf.Variable
tf.Variable(name, shape, dtype, value)
- s = tf.Variable(2,name=’scalar’)
- m = tf.Variable([[0,1],[2,3]],name = “matrix”)
- W = tf.Variable(tf.zeros([784,10]))
tf.assign()
- a = tf.Variable(1)
- b = (a + 2) 3 等价于 b = (assibn_add(2)) 3

数据类型

变量跟踪

m.variables 会输出所有的变量
tf.data
使用简单的结构构建复杂的数据流。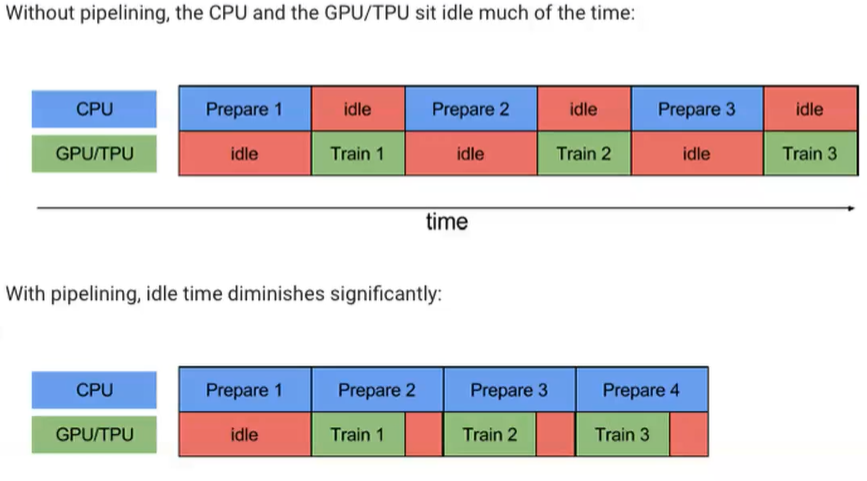
创建数据集,高效pipeline
创建数据集
tf.data.Dataset.from_tensors(tensors) #作为一个tensor输入tf.data.Dataset.from_tensor_slices(tensors) # 作为多个tf.data.Dataset.from_generator(gen,output_types,output_shape)
读取数据集
# 包含多个txt文件的行tf.data.TextLineDataset(filenames)# 来自一个或多个二进制的固定长度记录的数据集tf.data.FixedLengthRecordDataset(filenames)# 包含多个TFRecord文件的记录tf.data.TFRecordDataset(filenames)# 还有多种方法未列举,如csv文件
数据迭代
dataset = tf.data.Dataset.from_tensor_slices([])for e in dataset:print(e.numpy())it = iter(dataset)print(next(it).numpy())
数据集合并
dataset3 = tf.data.Dataset.zip((dataset1,dataset2))
取batch
batched_dataset = dataset.batch(4)
随机打乱
dataset = dataset.shuffle(buffer_size=10) # 参数是随机打乱程度。1不打乱,最大为样本量
常用数据集
tf.keras.datasetstf.keras.datasets.xxxx.load_data()

模型保存
- 保存checkpoints(只保存权重)
- 保存整个模型
存取checkpoints
model.save_weights('checkpoint')# 获得最新的检查点ckpt = tf.train.latest_checkpoint('./tf_ckpts/')# 读取到模型model.restore(ckpt)
保存整个模型
from keras.models import load_modelmodel.save('my_model.h5')model = load_model('my_model.h5')
可视化,1版本
Tensorboardtensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir,histogram_freq=1)# 命令行输入tensorboard --logdir

若有收获,就点个赞吧
0 人点赞
