- Deep Neural Networks
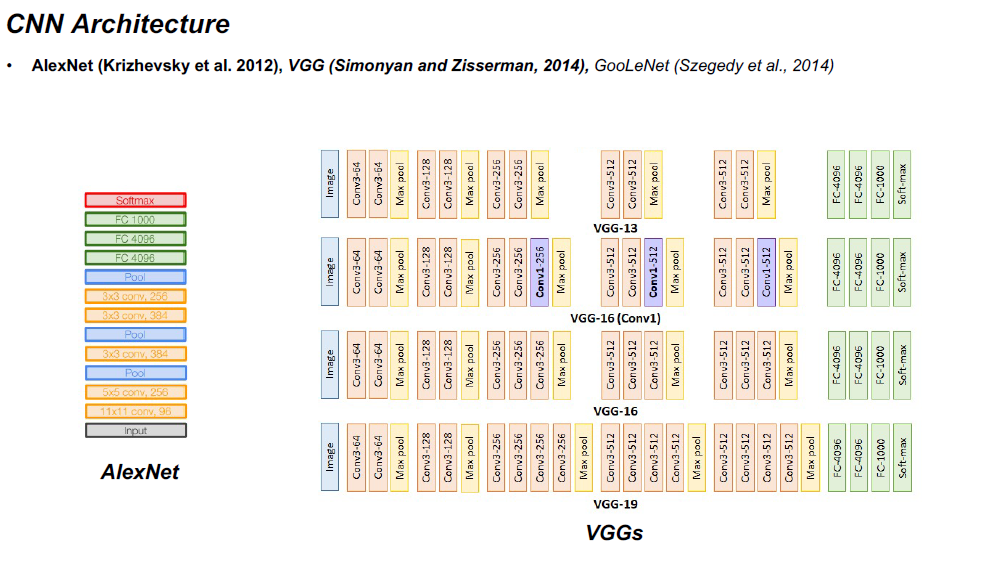
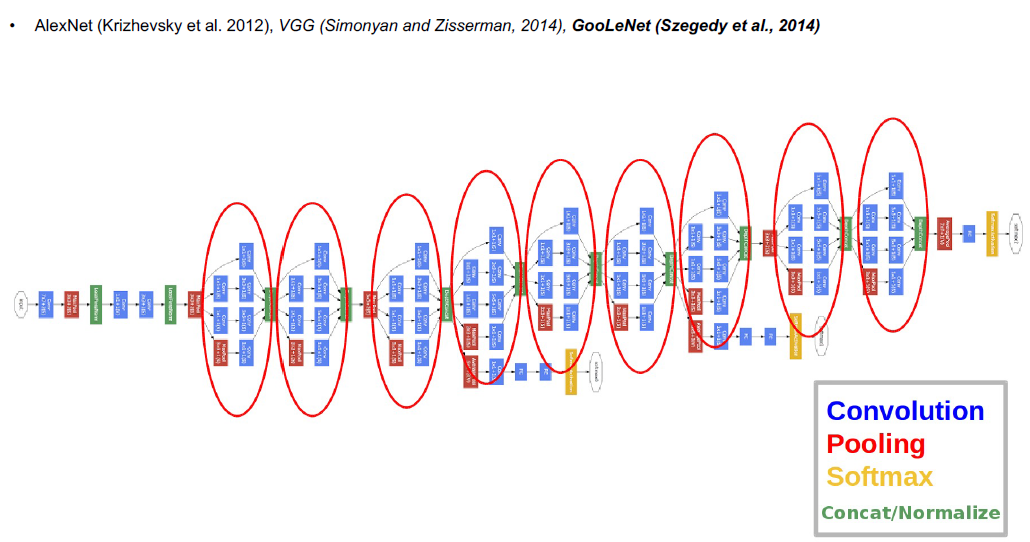
- Convolutional Neural Networks (CNN)
- Recurrent Neural Networks (RNN)
- Weight Initialisation
一般设置小的随机数。神经网络权值的初始化是一个完整的研究领域,因为仔细初始化网络可以加快学习过程。现代的深度学习库,如Keras,提供了一系列的网络初始化方法,所有这些都是用小随机数初始化权值的变化。
- Epoch, Batches, and Iteration
Epoch represents one iteration over the entire dataset
Batches split the total data into many segments or batches
Iterations number of batches we need to compile one Epoch
当整个训练数据集通过神经网络向前传播然后向后传播时,就会出现一个epoch。
在第一个epoch之后,我们将有一个下降的权值集,但是通过将我们的训练数据一次又一次地输入到我们的神经网络中,我们进一步改进了权值。这就是为什么我们要为几个迭代/时代进行训练。除非我们有巨大的内存容量,否则我们不能简单地把所有的训练数据传递给我们的神经网络。我们需要将数据分割成段或批。
- Deep Neural network
深度神经网络与普通的单隐藏层神经网络的区别在于其深度;也就是说,在模式识别的多步骤过程中,数据必须通过的节点层数。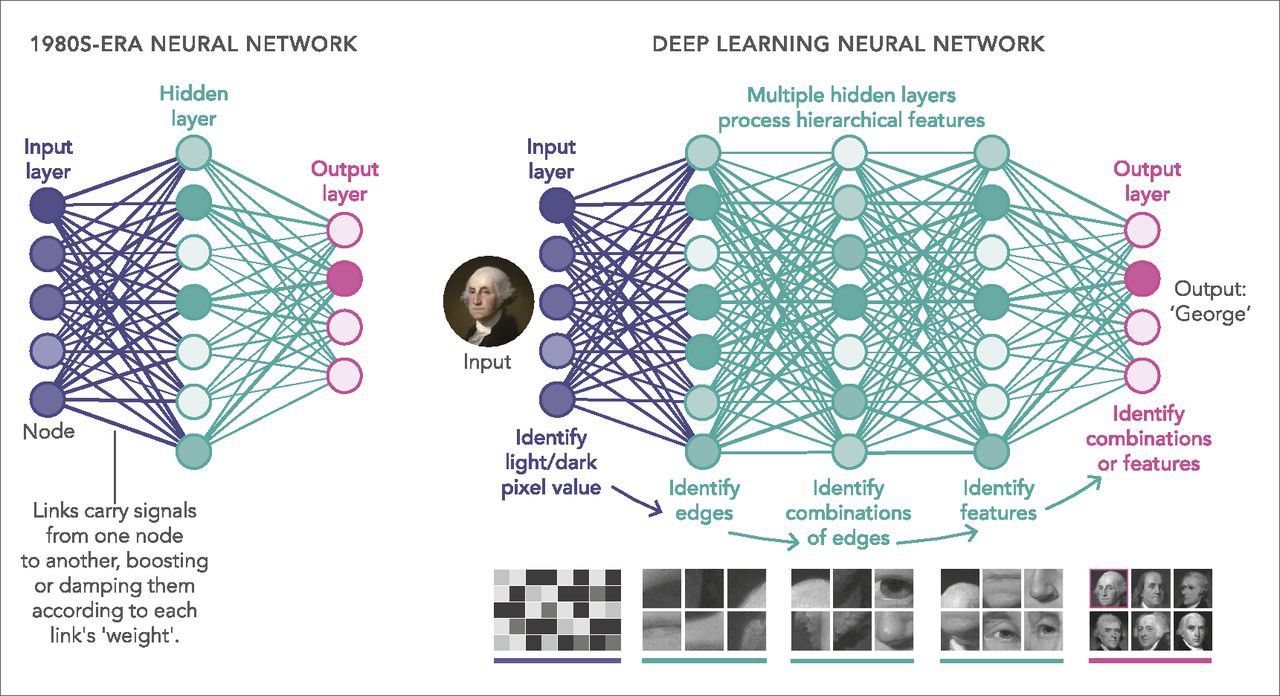
深度神经网络变体,卷积神经网络(多用于计算机视觉),循环神经网络(多用于自然语言处理)
基本的神经网络容易受到图像位置、大小、角度的变化的影响。
- CNN
CNN架构明确假设输入是图像,这允许我们将某些属性编码到体系结构中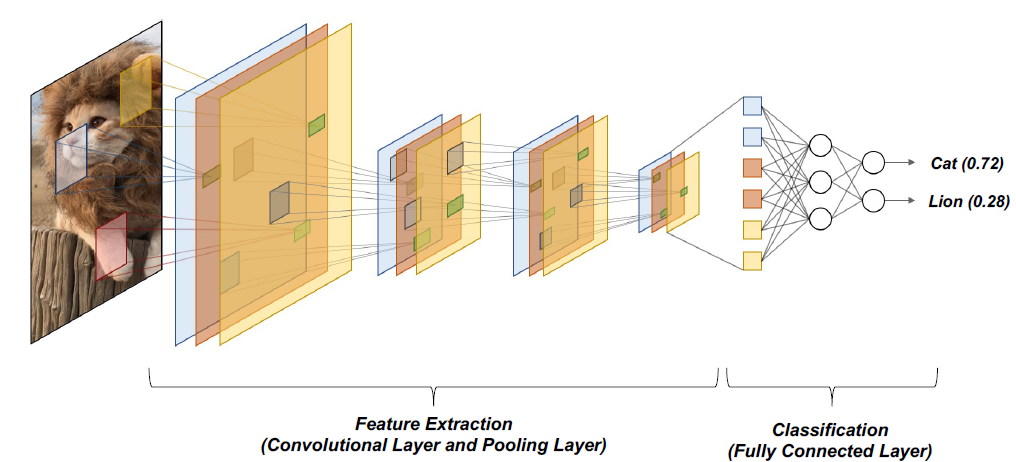
cnn非常类似于全连接神经网络:
•由具有可学习的权重和偏差的神经元组成。
•每个神经元接收一些输入,执行点积(可选的非线性)
•表示一个单一的可微分分数函数(从原始图像像素在一端到班级分数在另一端)
因此,所有学习全连接神经网络的技巧仍然适用。

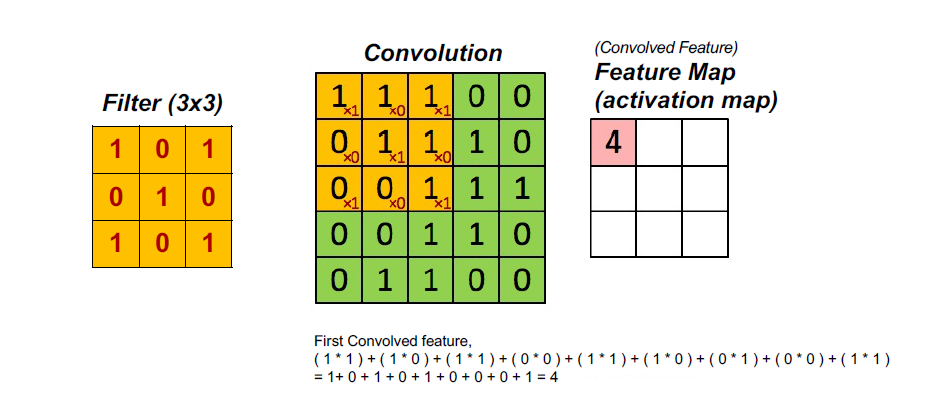
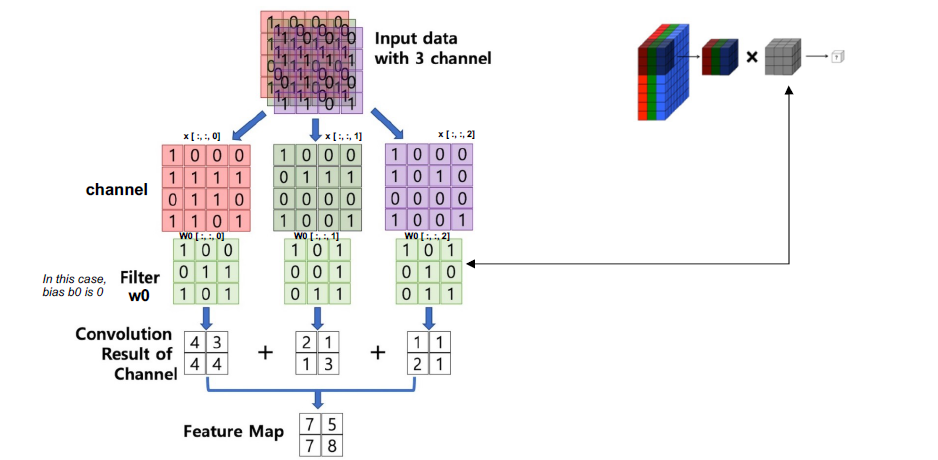
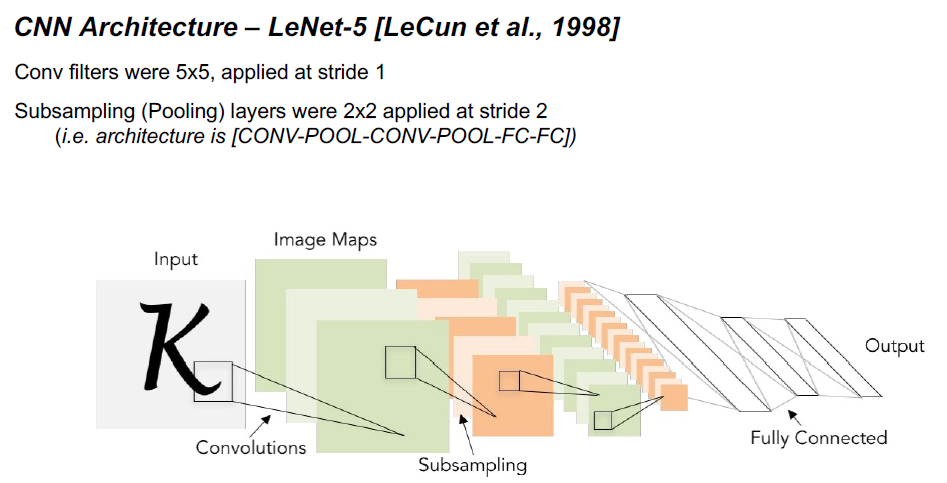
CONV(卷积)层
计算连接到输入局部区域的神经元的输出,每个神经元计算它们的权值(来自可学习滤波器)和它们在输入体积中连接的小区域之间的点积。
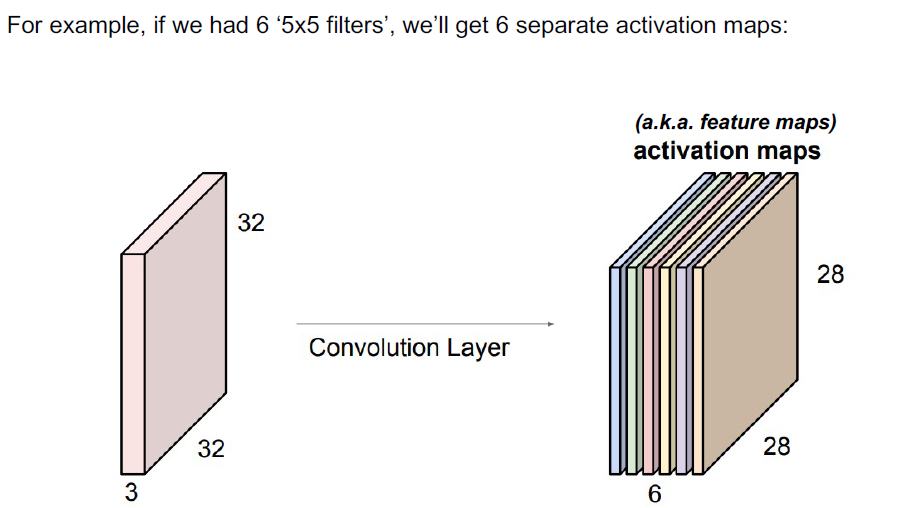
如果我们决定使用12个过滤器,这可能会导致像[32 x 32 x 12]这样的容量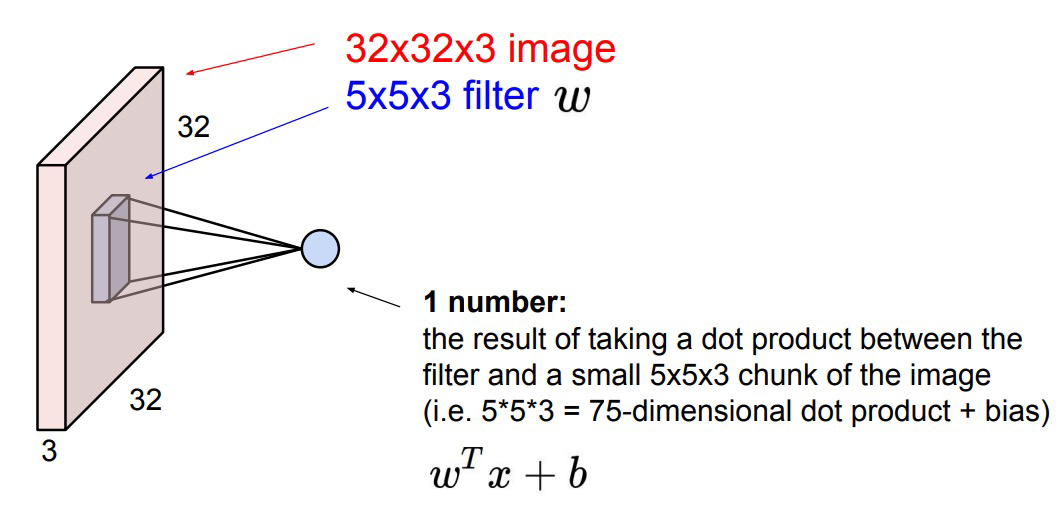
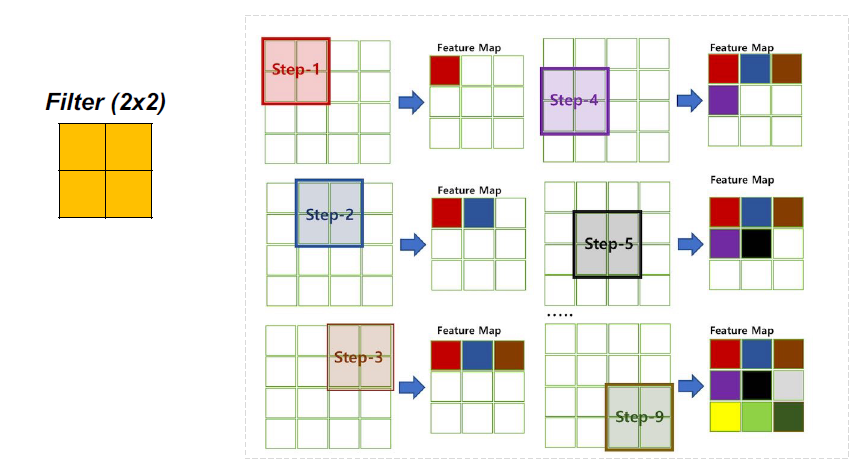
在输入量的边框上填充零将会很方便。这个加零的大小是一个超参数。零填充的优点是它允许我们控制输出卷的空间大小。
Stride控制滤波器如何围绕输入量进行卷积。
•当stride为1时,我们每次移动滤镜一个像素。当步幅是2(或不常见的3或更多,尽管这在实践中是罕见的),然后过滤器跳2像素在我们左右滑动。这将在空间上产生更小的产量。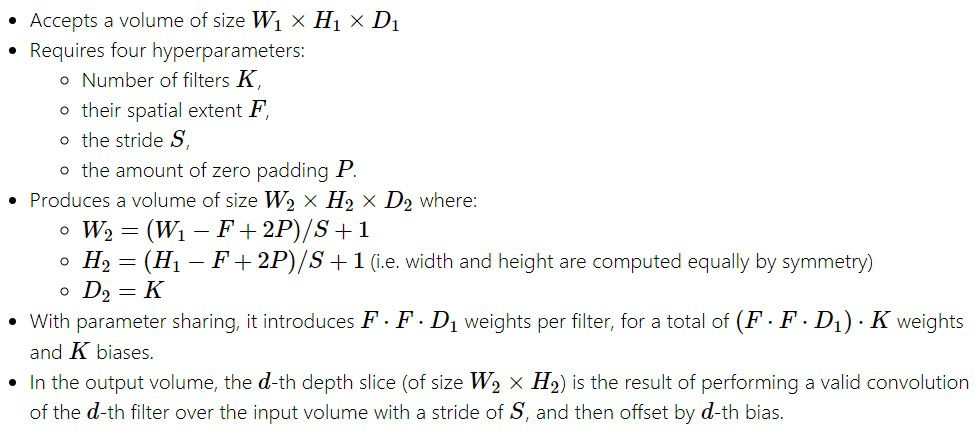
RELU层应用elementwise激活函数,如max(0,x)阈值为0。这使得卷的大小保持不变([32x32x12])
POOL (Pooling)层沿空间维度(宽度、高度)执行降采样操作,产生体积如[16x16x12]。在连续的Conv层之间定期插入一个Pooling层是很常见的。逐步减少表示的空间大小,以减少网络中的参数和计算量,从而也控制过拟合
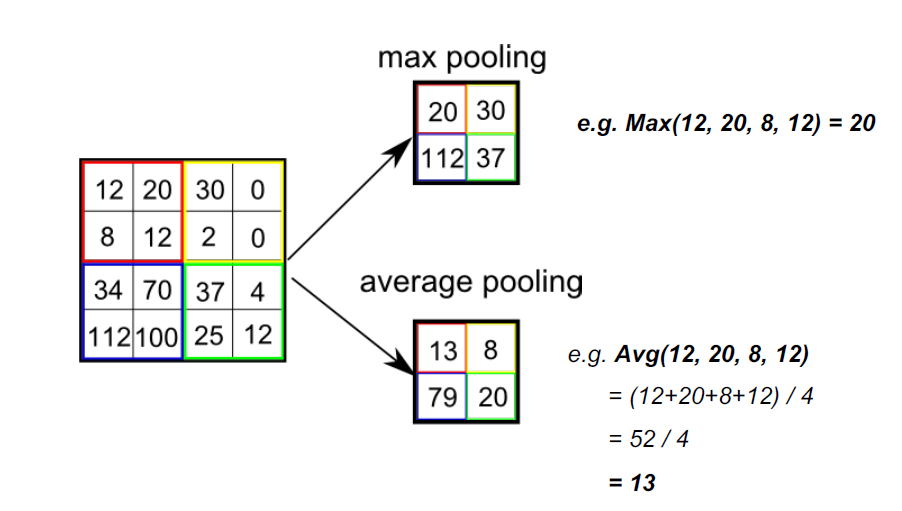
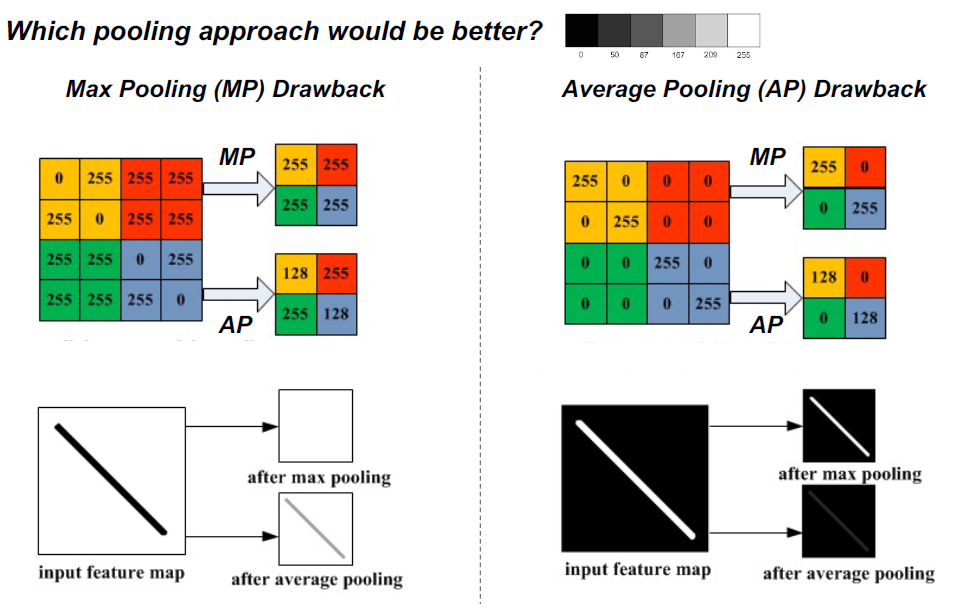
平层
在卷积层和完全连接层之间,有一个“Flatten”层。扁平化是将多维特征矩阵转化为一个向量,该向量可以被输入到一个全连接神经网络分类器。
FC(全连接)层计算类分数,这两个类别中的每个类别对应于一个类分数,例如我们数据集的两个类别中。就像普通的神经网络一样,顾名思义,这一层的每个神经元将与前一卷中的所有数字相连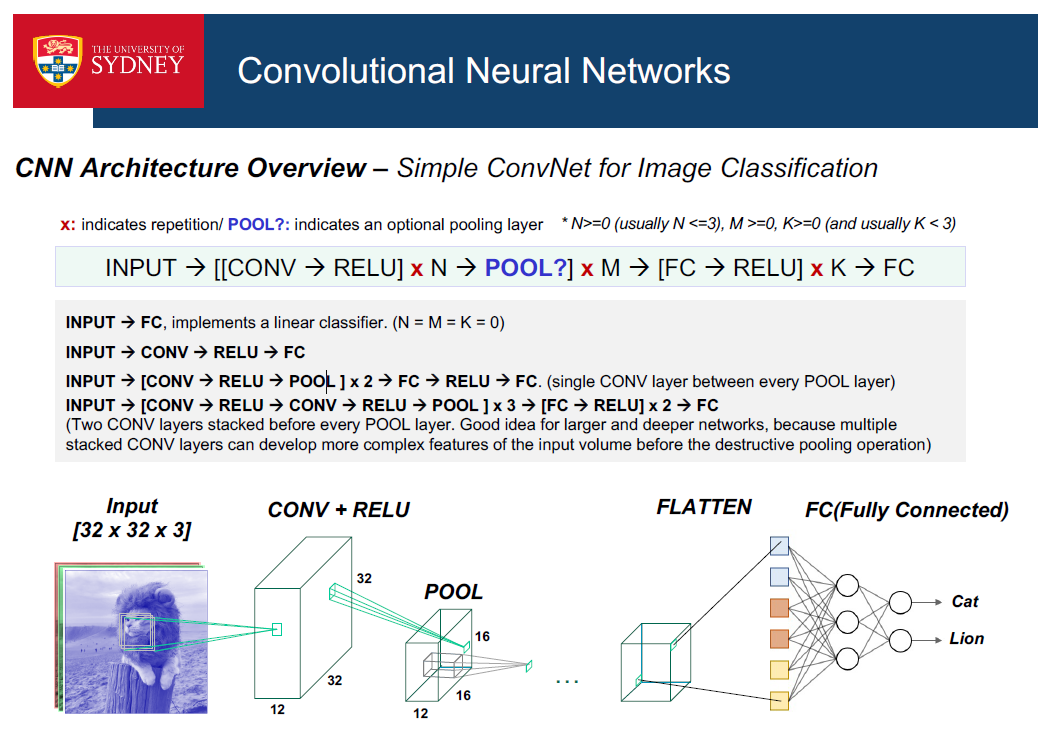
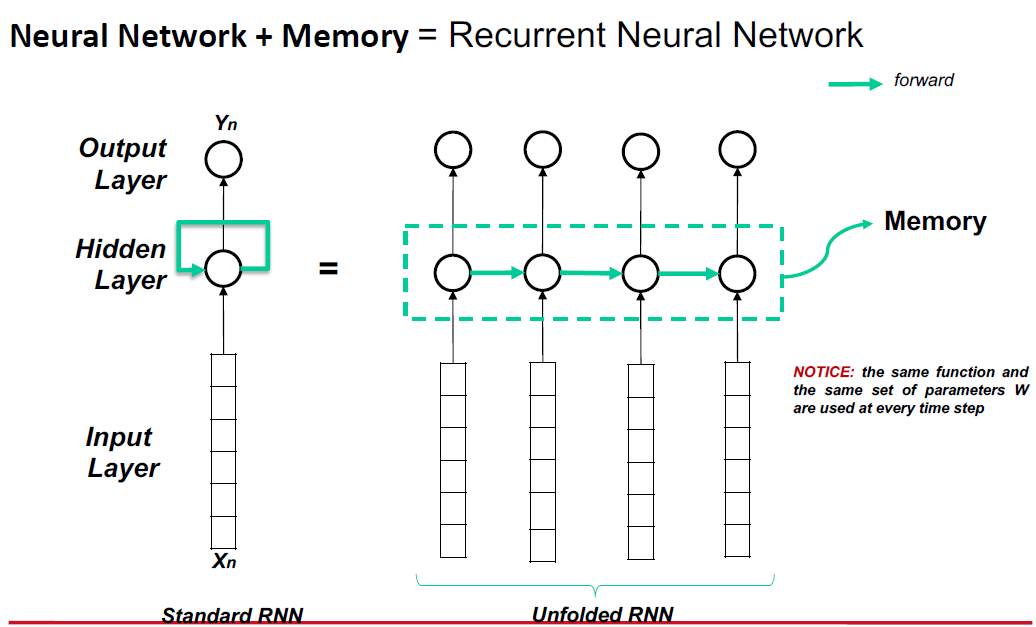
- Recurrent Neural Networks (RNN)
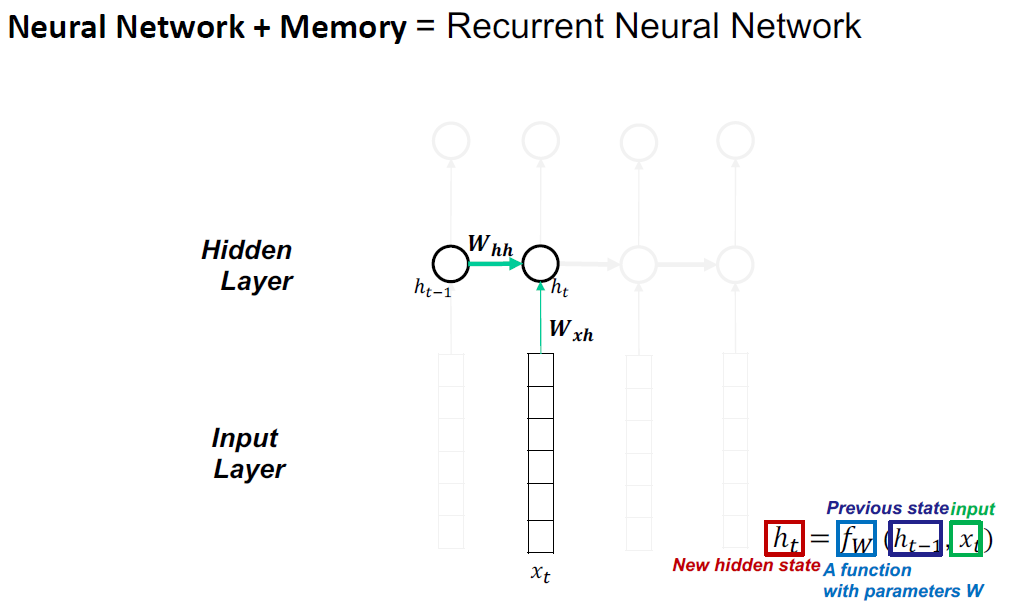
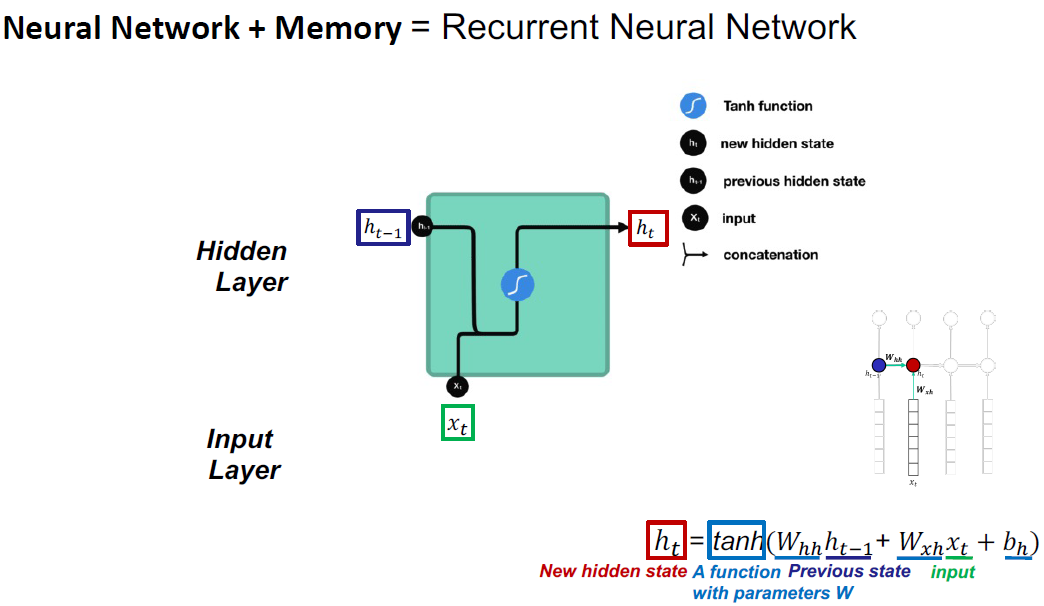
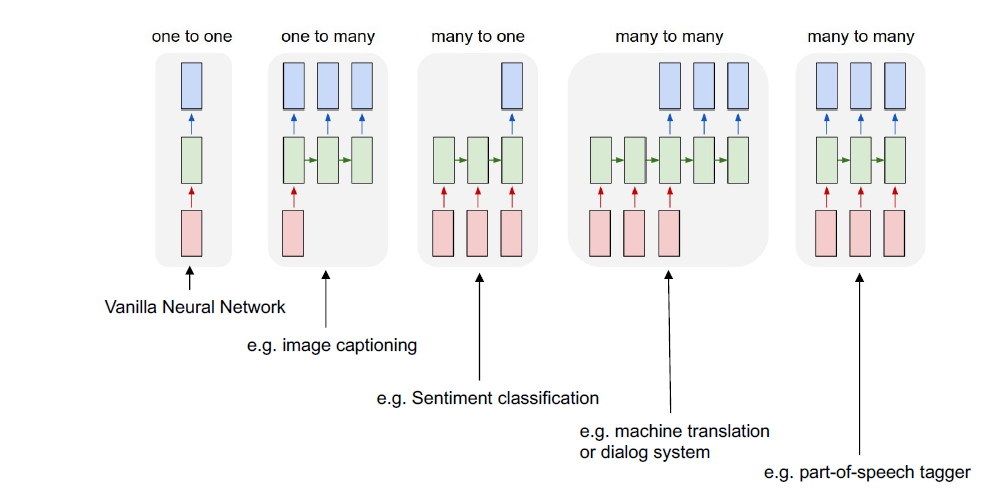
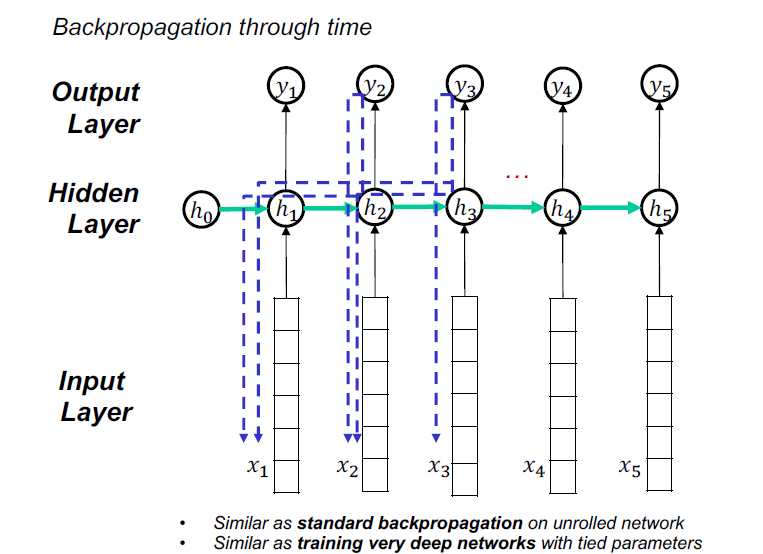
Vanilla RNN不能有效地处理长序列,因为消失和爆炸梯度问题。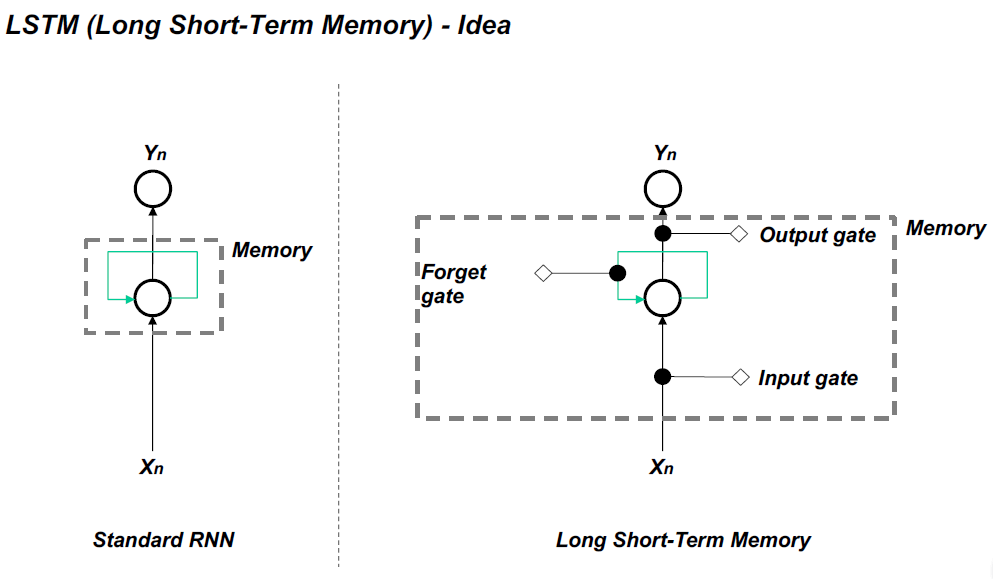
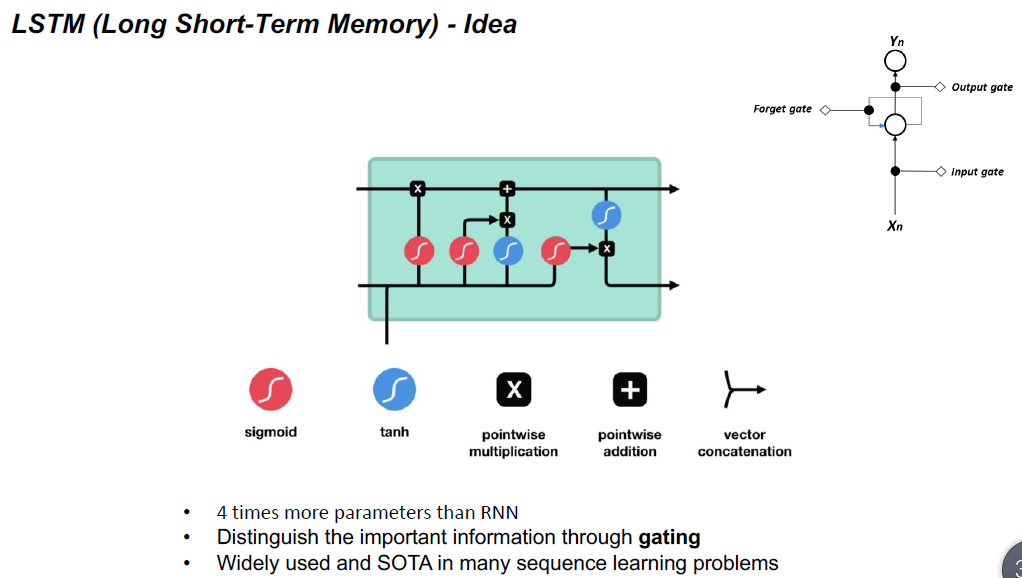
Forget Gate决定哪些信息应该丢弃或保留。来自前一个隐藏状态的信息和来自当前输入的信息通过sigmoid函数传递。值的取值范围是0到1。接近0表示忘记,接近1表示保留。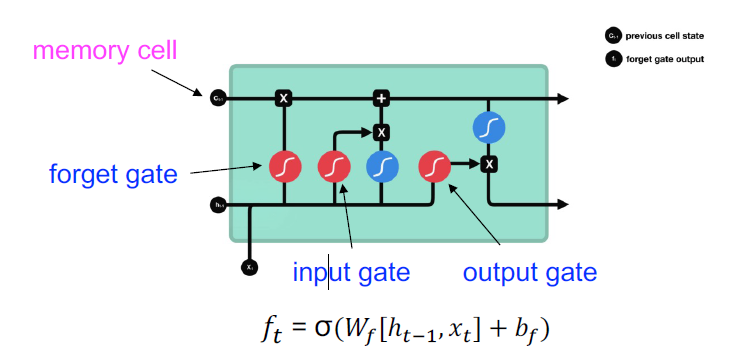
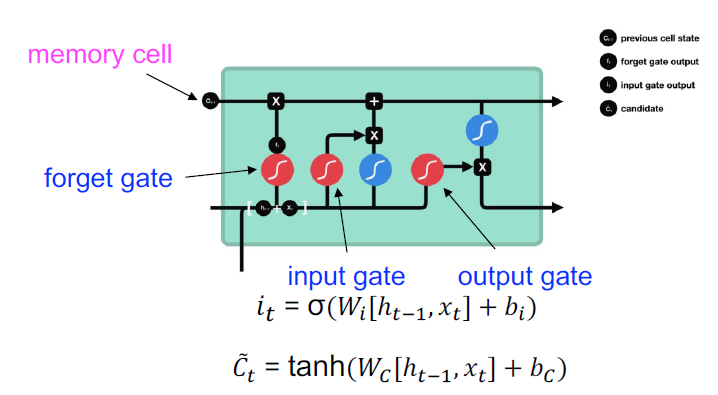
Input Gate:
- 将之前的隐藏状态和当前输入传递给一个sigmoid函数
- 将隐藏状态和当前输入传递给tanh函数,以压缩-1和1之间的值帮助规范网络
- 将tanh输出与sigmoid输出相乘
- *sigmoid输出将决定在tanh输出中保留哪些重要信息
Cell States
•单元格状态逐点乘以遗忘向量
•从输入门获取输出,并逐点加法,将细胞状态更新为神经网络发现的新值
•这给了我们新的细胞状态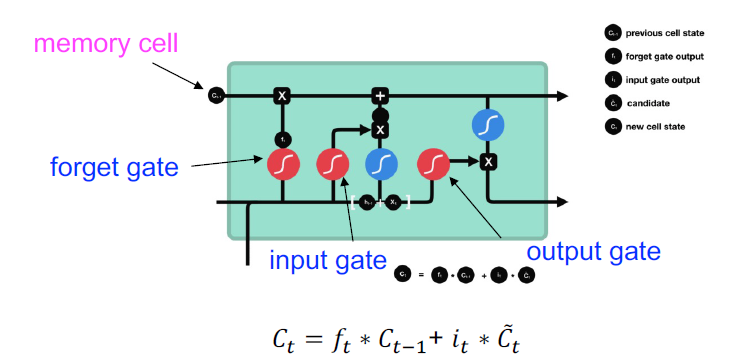
Output Gate
决定下一个隐藏状态应该是什么。
•将之前的隐藏状态和当前输入传递到一个sigmoid函数中将新修改的单元格状态传递给tanh函数
•将tanh输出与sigmoid输出相乘,以决定隐藏状态应该携带什么信息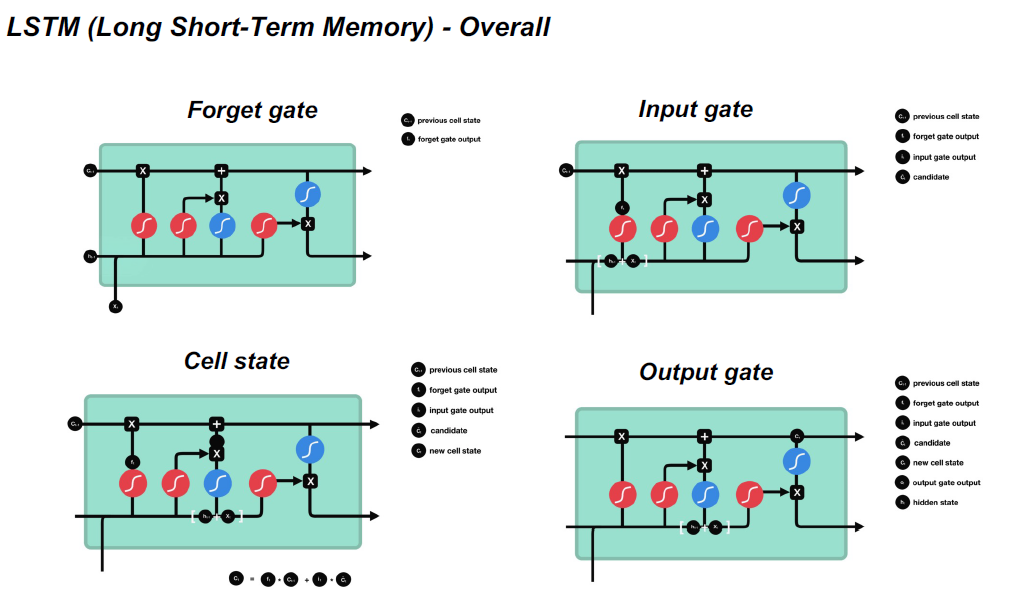
Gated Recurrent Unit
•GRU首先根据当前输入词向量和隐藏状态计算更新门
•以类似的方式计算复位门,但权重不同
•如果reset gate unit为~0,则忽略之前的内存,只存储新单词的信息
•最终内存在时间步结合当前和以前的时间步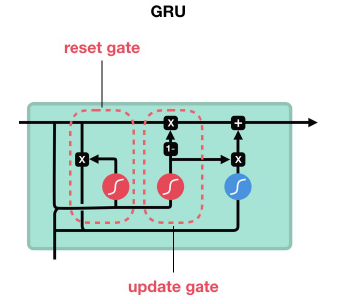
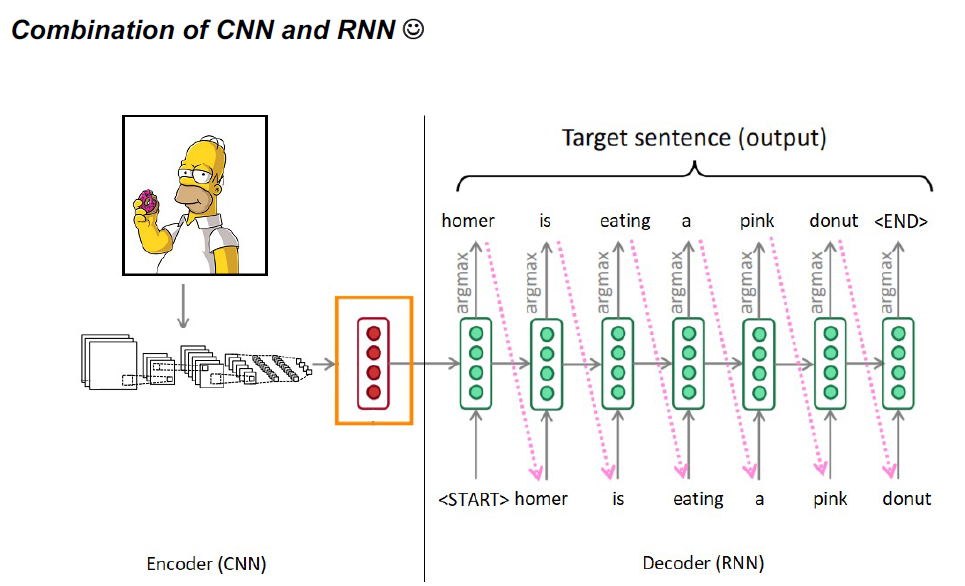
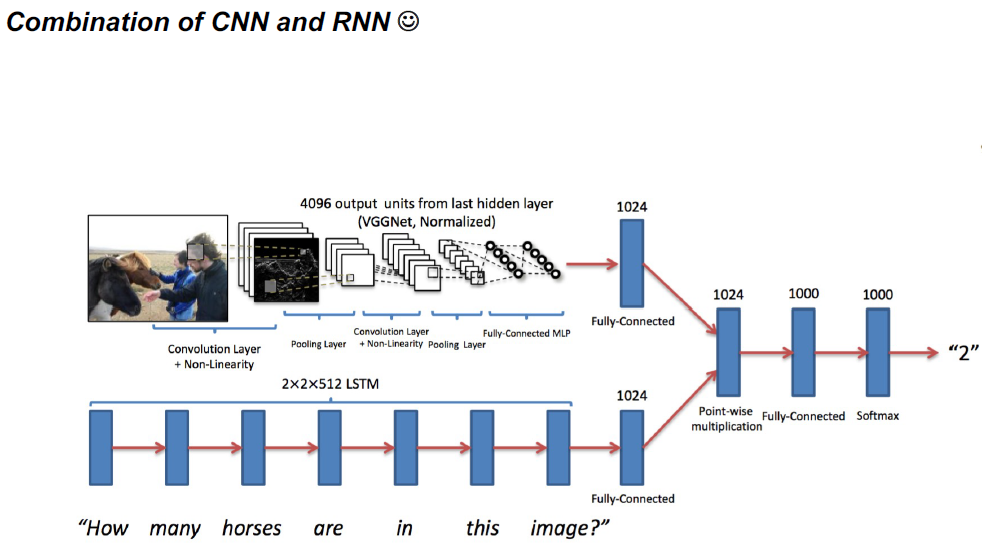

若有收获,就点个赞吧
0 人点赞
