- Two kinds of task:
- Supervised task: classification and regression
- Classification: predicted variable is categorical
- Regression: predicted variable is numerical
- Unsupervised task: clustering
- Supervised task: classification and regression
- Others:
- Associate rule mining
- reinforcement learning
- outlier detection
- Outliers are noise and should be removed before data analysis
- Outliers are the goal of our DManalysis – to detect unusual behavior, e.g. credit card fraud detection or intrusion detection
- DM process:
- Business understanding
- Data understanding
- Data preparation
- Modelling
- Evaluation
- Deployment
- Nominal and numeric attributes
Data cleaning
- Noise
- distortion of values
- addition of spurious examples
- inconsistent and duplicate data
- Solutions for type i and ii
- Using signal and image processing and outlier detection techniques before DM
- Using ML algorithms that are more robust to noise – give acceptable results in presence of noise
- Missing values
- Noise
Data preprocessing
- Data aggregation
- Feature extraction
- Feature subset selection
- Converting features from one type to another
- Normalization of feature values
- Similarity measures
- Euclidean, Manhattan, Minkowski
- Hamming, SMC, Jaccard coefficient
- Cosine similarity
- Correlation

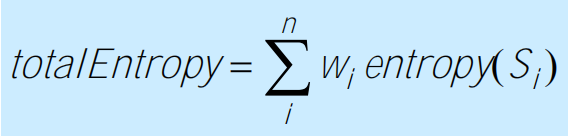
the one with minimum total entropy
Normaliztion and Standardization(归一化和标准化)
Used to avoid the dominance of attributes with large values over
attributes with small values.
Measuring similarity
- Distance
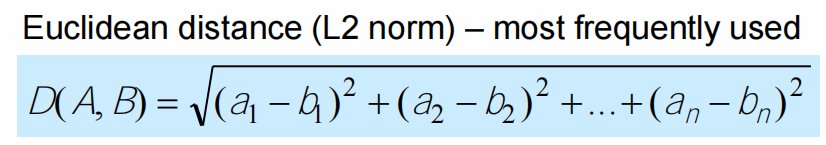
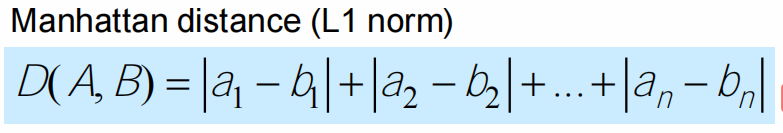
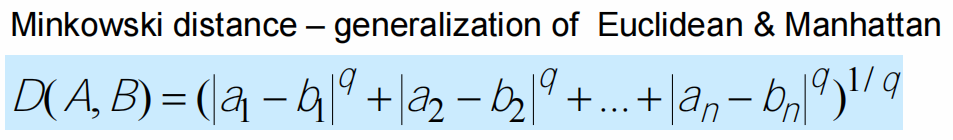
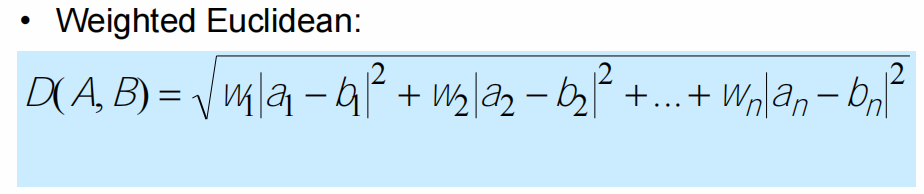
- Hamming distance: One-hot matrix using Manhattan distance
- Similarity coefficients
- Simple Matching Coefficient (SMC) - matching 1-1 and 0-0 / num.
- Jaccard Coefficient = SMC exclude FNs (TP、 FN)
- Correlation
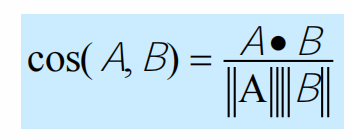

Measuring similarity

若有收获,就点个赞吧
0 人点赞
