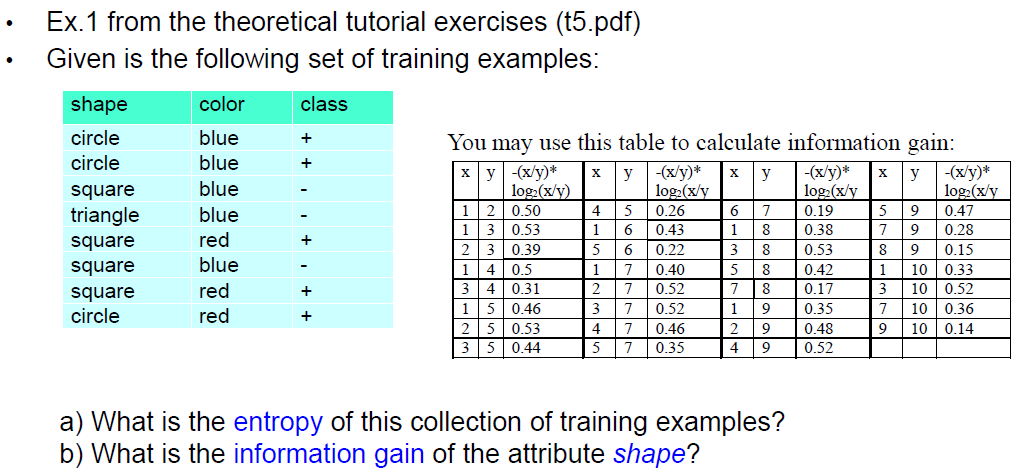
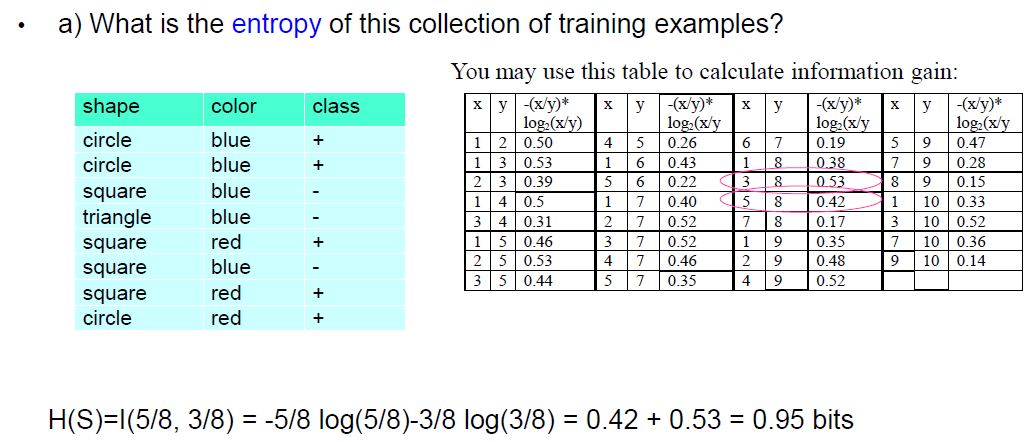
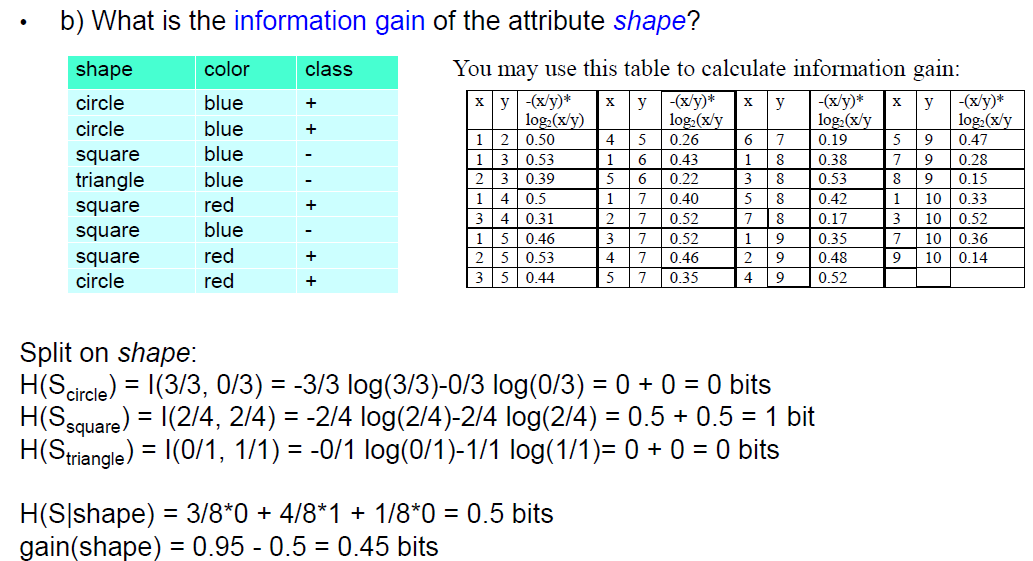
• Constructing decision tree
• Entropy and information gain
• Pruning decision trees
• Dealing with numeric attributes
• Dealing with highly branching attributes – gain ratio
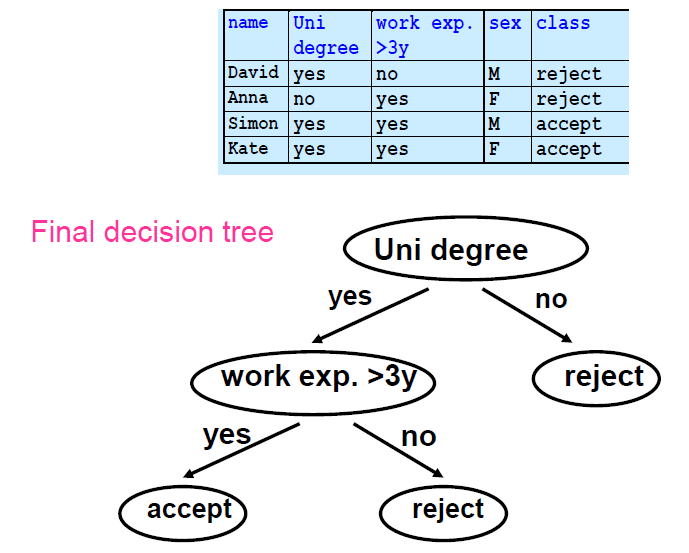
Decision Tree
- 每一个非叶子节点都对应着对一个属性值的测试。
- 每个分支对应于一个属性值
- 每个叶子节点都指定了一个类别
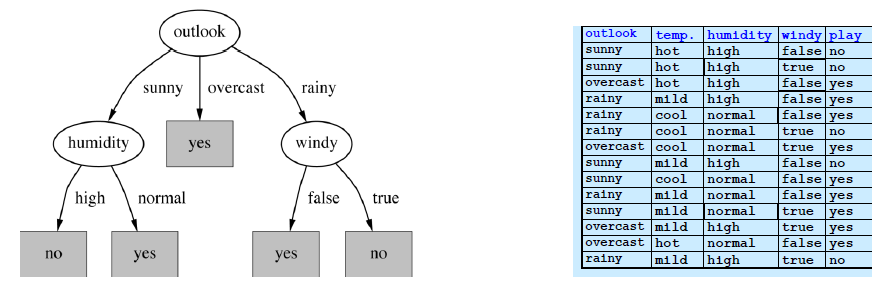
- 策略:自上而下的学习,使用递归的分而治之(recursive divide-and-conquer)过程。
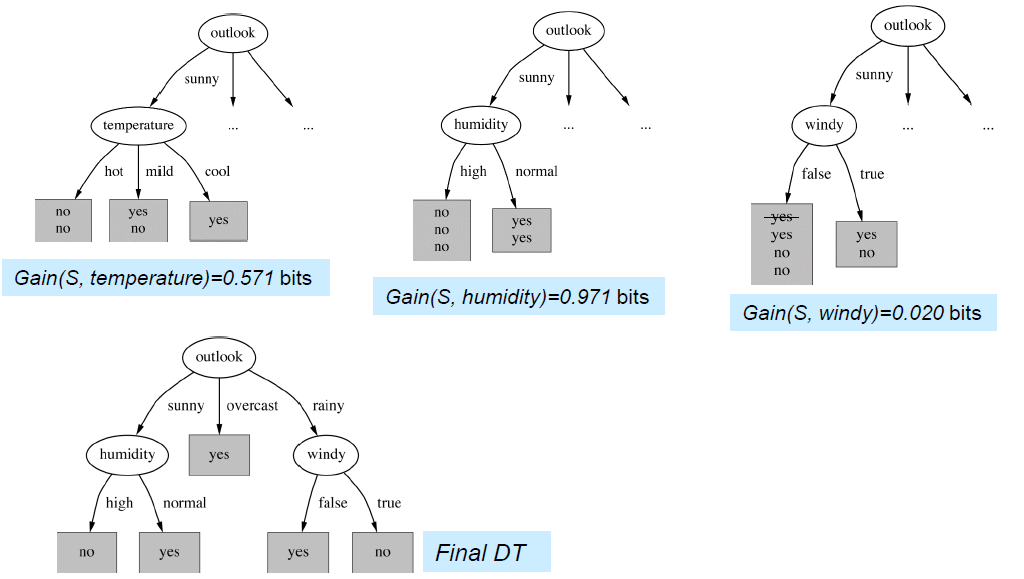
- 首先:为根节点选择最佳属性,并为每个可能的属性值创建分支。
- 然后。将例子分割成子集,每个分支都有一个从根节点延伸出来的子集。
- 最后。对每个分支进行递归重复,只使用到达分支的例子。
- 如果所有的例子都有相同的类别就停止
- 为这个类做一个叶子结点
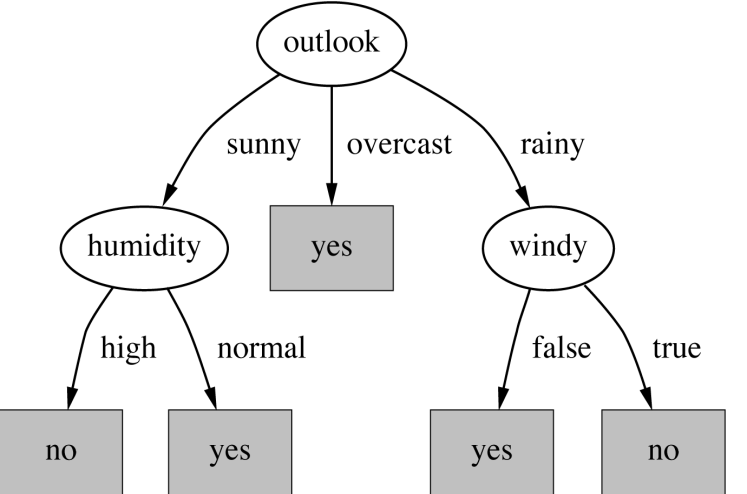
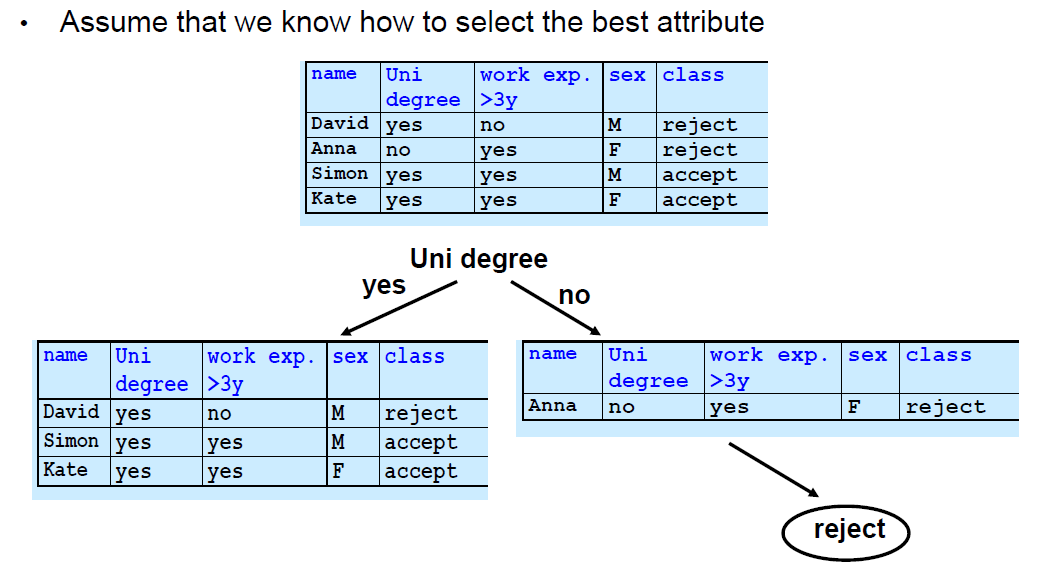
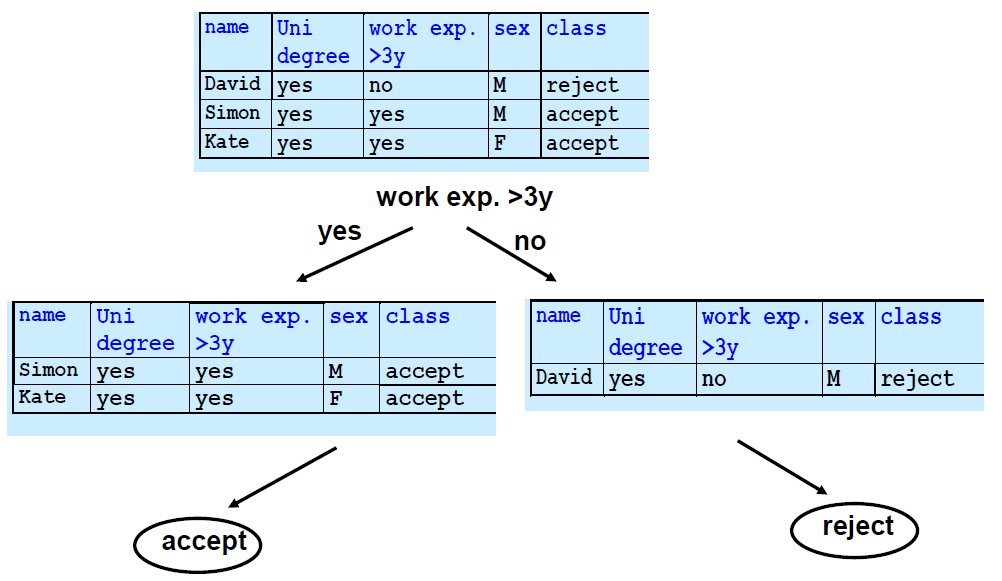
- 一个只有一个类(是或不是)的叶子节点将不必再被分割,并且 递归过程将终止
- 我们希望这种情况尽快发生,因为我们寻求小树。
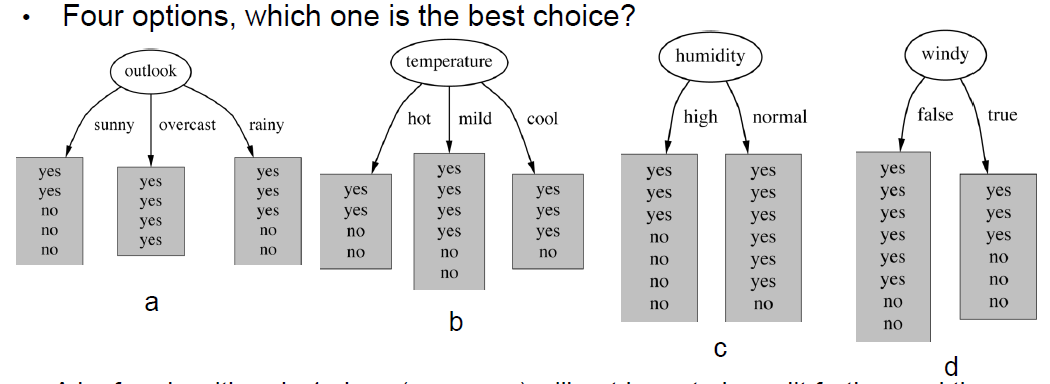
- 如果我们对每个节点的纯度有一个衡量标准,我们就可以选择能产生最纯净分区的属性。
- 我们将使用的衡量纯度的方法称为信息增益 (information gain)
- 它是基于另一种叫做熵的测量方法(entropy)
- 给定一组例子和它们的类别,熵衡量这组例子相对于类别的同质性homogeneity (purity)
- 熵越小,数据集的纯度就越高。
- 熵也被用于信号压缩、信息理论和物理学中。


- 信息增益衡量的是使用一个属性来划分训练实例集所造成的熵的减少。
- 最好的属性是具有最高信息增益的属性(即具有最大的熵减)。
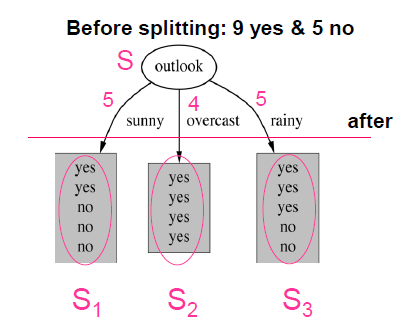
- 它是两个熵的差值。增益 = T1 -T2
- T1是分割前与父节点相关的例子集S的熵
- T2是在S被属性分割后S中剩余的熵(例如:外观)
- 差别越大,信息增益就越高
- 最佳属性是具有最高信息增益
- 它使父节点的熵减少最多
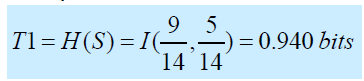
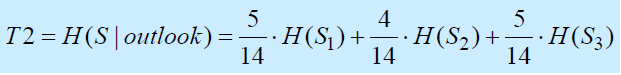

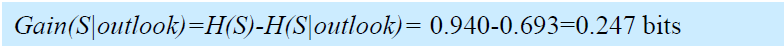

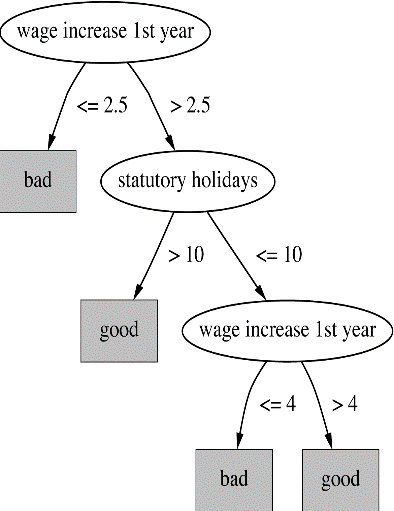
Pruning Decision Trees
- 如果我们将决策树增长到对训练集进行完美分类,那么决策树可能会变得过于具体,并过度拟合数据
- 过度拟合—在训练数据上准确度高,但在新数据上准确度低
- 决策树变得过于具体,主要是记忆数据,而不是提取模式
- 决策树何时发生过拟合?
- 训练数据太小—没有足够的代表性例子来建立
一个可以在新数据上很好地归纳的模型 - 训练数据中存在噪声,例如,错误标记的例子 -> 决策树通过添加新的例子来学习它们。
决策树通过添加新的括号来学习它们,使决策树过于具体
- 训练数据太小—没有足够的代表性例子来建立
使用树的剪枝来避免过度拟合
- 两种主要策略
- 预修剪—在树达到完美分类的点之前,提前停止树的生长
- 后修剪—充分生长树,让它完全覆盖训练数据,然后再进行修剪
- 在实践中,后修剪法是首选
不同的后修剪方法,例如:
子树替换
- 自下而上 - 从树的底部到根部
每个非叶子节点都是修剪的候选者,对于每个节点。
- 删除以其为根的子树
- 用一个叶子来代替它,该叶子的例子类别=多数类,沿着候选节点
- 通过计算新树和旧树在验证集上的准确度来比较新树和旧树
- 如果新树的准确度比旧树的准确度好或相同,则保留新树(即修剪候选节点)
更多信息见Witten第6.1章。

子树提升
- 将树转换为规则,然后进行修剪
- 要修剪多少?使用一个验证集来决定
- => 可用的数据被分成3组:训练组、验证组和测试组
- 训练集—用于建立树
- 验证集—评估修剪的影响并决定何时停止
- 测试数据—评估树有多好
- => 可用的数据被分成3组:训练组、验证组和测试组
- 两种主要策略
Numerical Attributes
Discretizing numeric attributes
- 数值属性需要被离散化,即转换为名义属性
- 标准方法:二进制拆分,例如temp<45
- 与名义属性不同,每个数字属性都有许多可能的拆分。
- 离散化程序。
- 根据数字属性的值对例子进行分类
- 分割点—每当类别发生变化时,就进行一半的分割
- 对每个可能的分割点评估信息增益或其他衡量标准,并选择最好的一个
- 最佳分割点的信息增益=该属性的信息增益
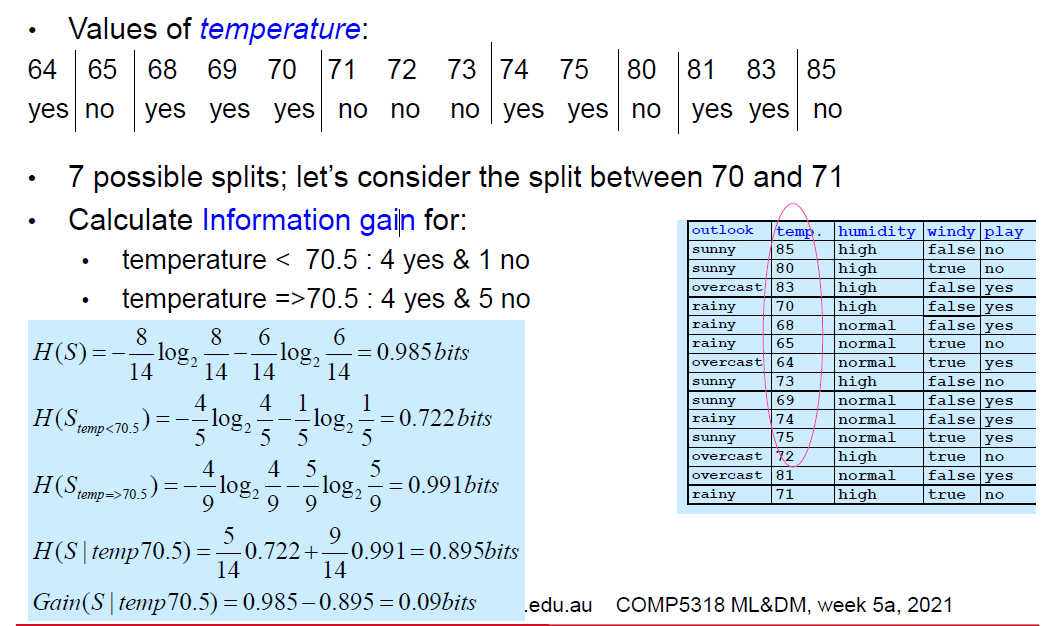
Alternatives to information gain
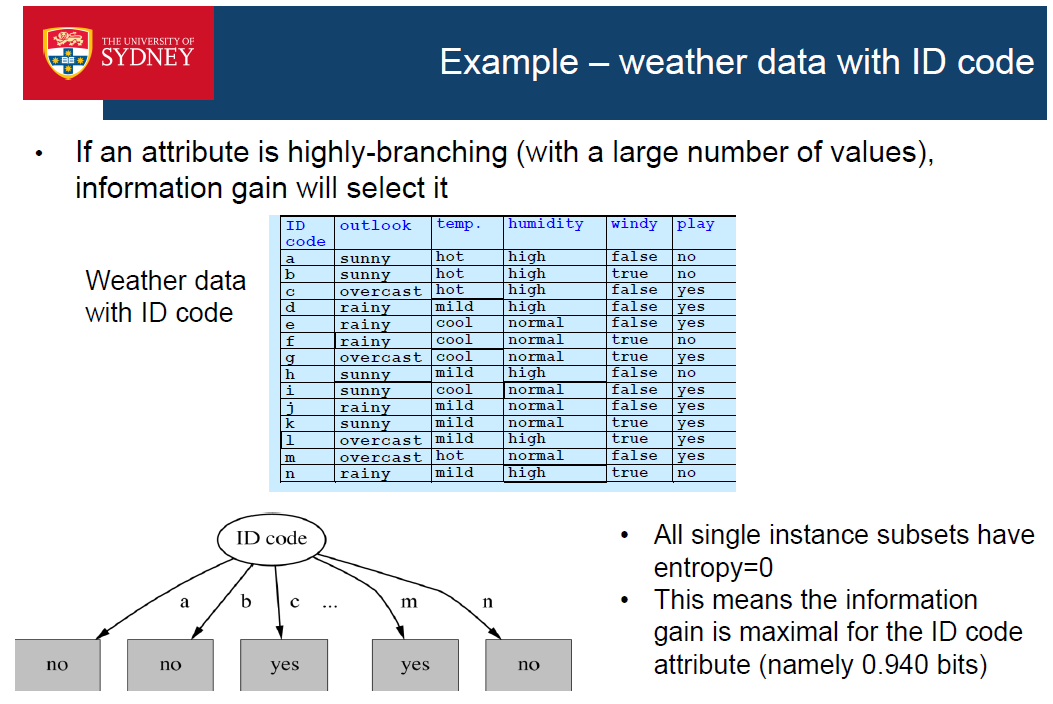
- 如果一个属性是高度分支的(有大量的值)。信息增益会选择它!
- 原因是:高度分支的属性更有可能创造出纯粹的子集
- => 纯子集具有低熵->高信息增益
- 例子:想象一下,使用ID码作为其中一个属性;它将把训练数据分成1个实例子集,它的信息增益会很高。并且它将被选为最佳属性
- 这可能会导致过度拟合
- 增益率(Gain ratio)是对信息增益的一种修正,它减少了信息增益对高分支属性的偏爱。
- 它在选择一个属性时考虑到了分支的数量,并惩罚高度分支的属性。
Summary
- 非常流行的ML技术
- 使用递归分而治之过程进行自上而下的学习
- 易于实现
- 可解释
- 产生的树易于可视化,非专家也能理解和客户
- 可解释性增加了人们对机器学习的信任模型的信任。
- 使用剪枝来防止过度拟合
- 数字属性被转换为名义属性(二元分割)
- 选择最佳属性—信息增益、增益比、其他
- 变化:纯度可以用不同的方式来衡量,例如,CART使用了基尼指数而不是熵
• Motivation for creating ensembles
• Ensemble methods
• Bagging
• Boosting – AdaBoost and Gradient Boosting
• Random Forest
Ensemble method
- 一个集合体结合了多个分类器的预测结果
- 被组合的分类器被称为基础分类器,它们是用训练数据创建的。
- 对新的例子进行预测的方法有很多,例如,通过采取基础分类器的多数票、加权投票等。
- 集合体的效果往往比它们组合的基础分类器更好
- 集合的例子。
- 在训练数据上训练3个基础分类器,例如k个最近的邻居,逻辑回归和决策树
- 为了对一个新的例子进行分类,通过投票将各个预测结合起来
Motivation for ensembles
- 集合方法何时起作用?
- 让我们考虑一个例子,它说明了集合方法如何能够提高单一分类器的性能。
- 一个由25个二元分类器组成的集合体。每个基础分类器在测试集上的错误率在测试集上的错误率为0.35(即准确率为0.65)。为了预测一个新例子的类别,基础分类器的预测被多数票合并。
- 案例1:基础分类器是相同的,也就是说,犯同样的错误。合并后的测试集的错误率将是多少?
- 0.35
- 情况2:基础分类器是独立的,也就是说,它们的错误没有相关的。集合体在测试集上的错误率将是多少?
- 一个新的例子什么时候会被错误分类?只有当一半以上的基准分类器的预测是错误的。
- 可以证明,合集的错误率将是
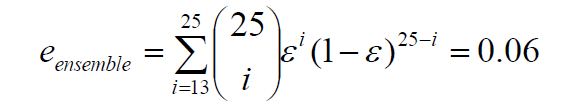
- 0.06<0.35,即合集的错误率远远低于基础分类器的错误率。
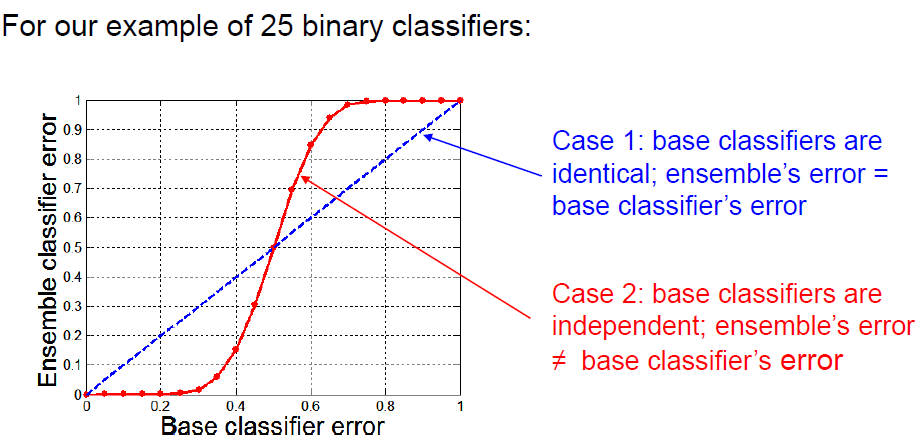

- 集合体要比单一分类器表现好的条件。
- 基础分类器应该足够好,也就是说,要比随机猜测好(对于二元分类器来说,<0.5)
- 基础分类器是相互独立的
- 独立性—在实践中。
- 不可能确保基础分类器之间完全独立。
- 当基础分类器之间有轻微关联时,合集方法已经取得了良好的效果。
Methods for constructing ensembles
- 有效的合集由基础分类器组成,这些分类器是合理正确的,同时也是不同的(即独立的)基础分类器。
- 创建合集的方法主要是在基础分类器之间产生分歧
- 操纵训练数据—通过以下方式创建多个训练集根据一些抽样分布对原始数据进行重新抽样并为每个训练集构建一个分类器(例如:Bagging和boosting)。
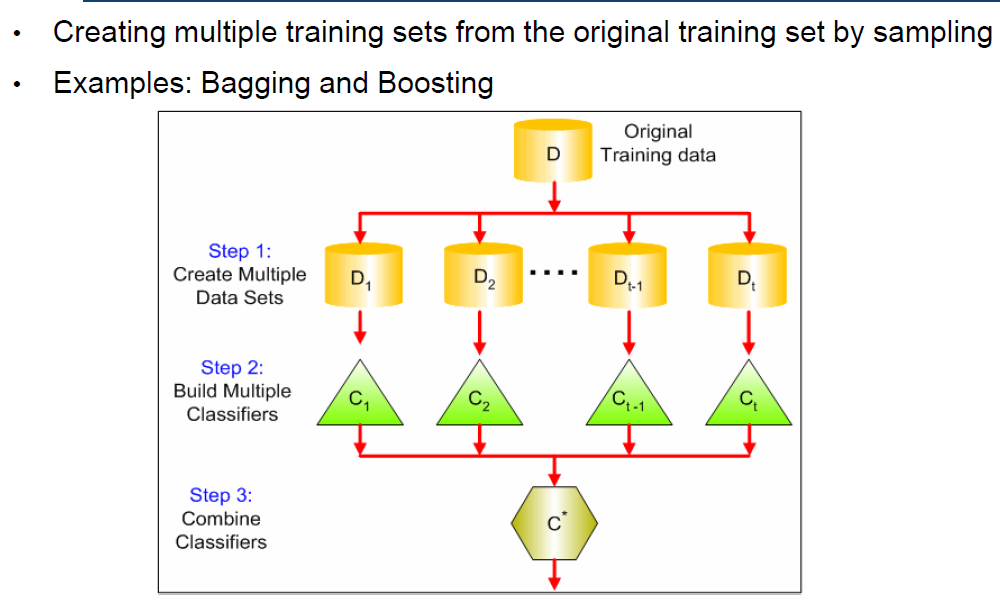
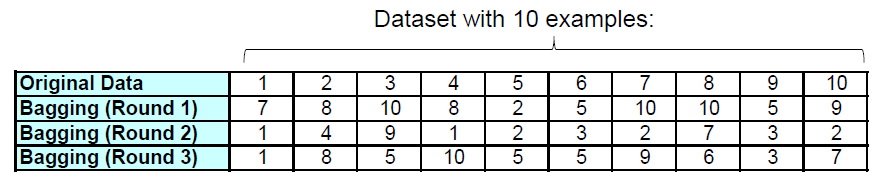
- Bagging- Bagging is also called bootstrap aggregation- 自举样本--定义- 给定:一个有n个例子的数据集D(原始数据集)。- 来自D的引导样本D':也包含n个例子,随机地从D中随机选取(即D中的一些例子会在D'中出现不止一次,有些则完全不出现)- 平均来说,D中63%的例子也会出现在D'中,因为它可以证明,选择一个例子的概率是(1-1/n)n
- 创建M个引导样本
- 使用每个样本来建立一个分类器
- 对一个新的例子进行分类:得到每个分类器的预测结果,并将它们与多数票结合起来。
- 也就是说,各个分类器得到的权重相同
- 模型的生成
- 设n为训练数据中的例子数
- 对于每一次的M次迭代。
- 从训练数据中抽取n个例子,并进行替换
- 对样本应用学习算法
- 存储生成的模型
- 分类
- 对于每一个M个模型。
- 使用模型预测测试样本的类别
- 返回被预测次数最多的类别(多数票)。
- 通常情况下,性能明显优于单一分类器,并且从来没有明显差过。
- 对不稳定的分类器特别有效
- 不稳定的分类器:训练集的微小变化会导致预测的巨大变化。例如,决策树、神经网络被认为是不稳定的分类器。
- 在回归任务中应用bagging法--单个预测被平均的
-
Boosting
- 最广泛使用的组合方法
- 思路。使分类器相互补充
- 如何做?下一个分类器应该使用对前一个分类器来说很困难的例子来创建。
- 已经提出了许多提升算法,最流行的是AdaBoost和梯度提升算法
- AdaBoost
- 使用加权的训练集
- 每个训练实例都有一个相关的权重(>=0 )
- 权重越高,该例子就越难被以前的分类器分类。
- 具有较高权重的例子将有更大的机会被选入下一个分类器的训练集中。
- AdaBoost是由Freud和Shapire在1996年提出的。
- 最初,所有训练实例的权重相等,例如,1/m,m是指 训练例子的数量
- 从这个集合中,产生第一个分类器(假设)h1
- 它对一些训练实例进行了正确的分类,对一些实例进行了错误的分类。
- 我们希望下一个分类器能够学会对错误分类的例子进行分类,因此我们增加错误分类的例子的权重,减少正确分类的例子的权重。
- 有一种机制用于选择下一个分类器的训练集的例子;权重高的例子更有可能被选中。
- 从这个新的加权集中,我们生成分类器h2
- 继续下去,直到生成M个分类器
- 最后的合集:根据分类器在训练集上的表现,用加权投票的方式将M个分类器合在一起。
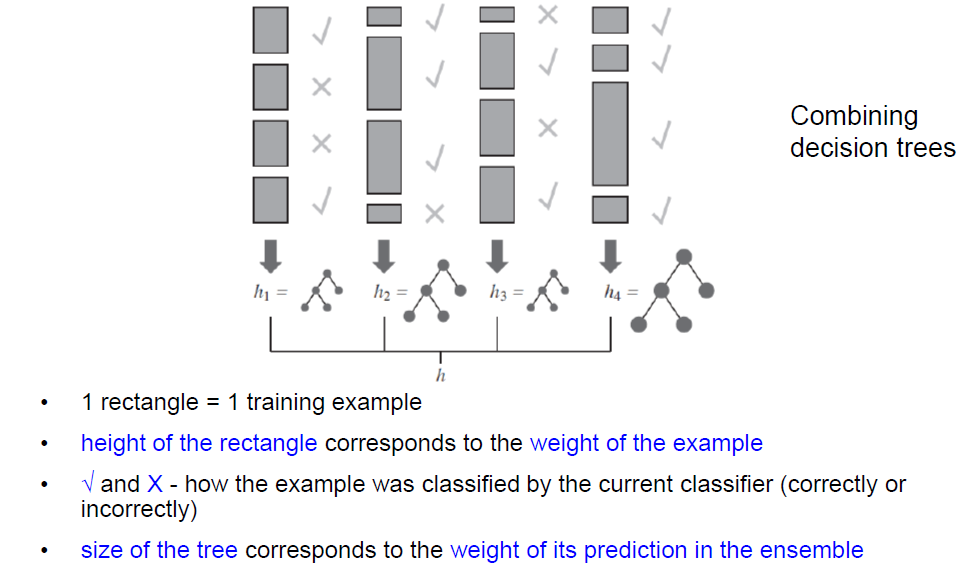


- 如果基础学习者是弱学习者,那么AdaBoost将返回一个 训练数据进行完美分类的合集,并且有足够大的 迭代次数(学习者组合)M
- 弱学习者是一个分类器,其分类性能比随机猜测略好(例如,二元分类的50%)。
- 因此,AdaBoost将一组弱学习器提升为一个强学习器
- Boosting允许从非常简单的分类器中建立一个强大的组合分类器。Boosting可以从非常简单的分类器中建立强大的组合分类器,例如1级决策树。
- 更多的理论结果—Boosting的效果很好。
- 如果基础分类器不是太复杂
- 随着迭代次数的增加,它们的误差不会很快变得太大
- Shapire等人(1997)对 “too”的含义进行了定义。
Gradient Boosting
- 使用决策树作为基础学习器,通常是浅层(弱)树。
- 与AdaBoost一样,它的工作方式是依次将基础学习器添加到集合中,每一个基础学习器都专注于前一个基础学习器难以分类的例子。
- 然而,AdaBoost在每次迭代时都会更新例子的权重。迭代,而梯度提升则是增加一个新的模型,使前一个模型的误差最小化的新模型
- 回归任务的例子,见Géron教科书第203页
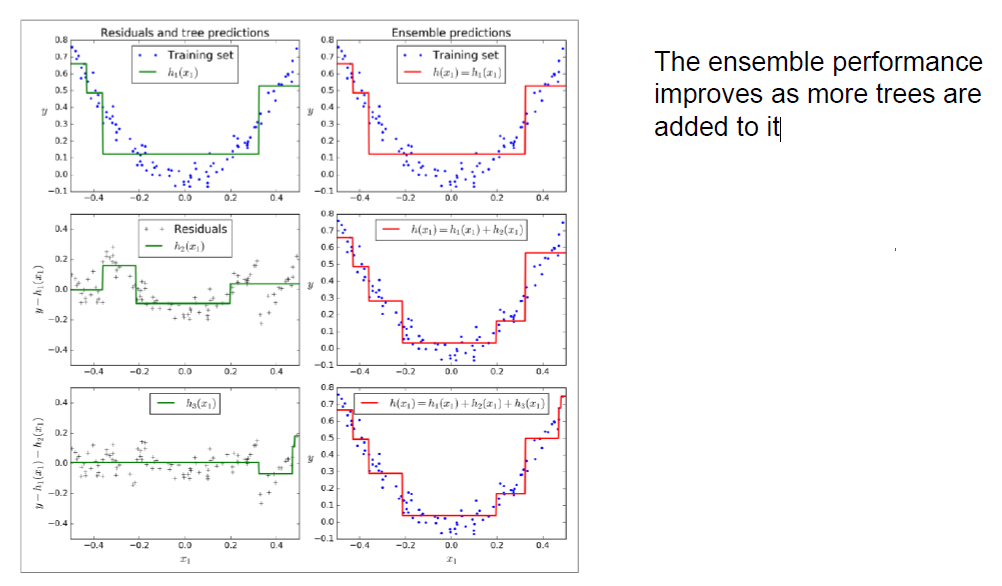
- 创建模型1:对训练数据(X,y)进行DT1拟合,存储模型
- 创建模型2。
- 在训练数据上评估DT1,计算误差:Y2=Y(实际值)-DT1的预测值
- 创建模型2:对(X,y2)进行DT2拟合,存储模型
- 创建模型3。
- 在训练数据上评估DT2,计算误差:y3 = y2 - DT2的预测值
- 创建模型3:对(X,y3)进行DT3拟合,存储模型
- 现在我们有3个决策树。要做一个预测或一个新的例子:将DT1、DT2和DT3的预测值相加。
- 相似性
- 使用投票(用于分类)和平均(用于预测)来结合各个学习者的输出。
- 结合同一类型的分类器,通常是树—如决策树桩或决策树。
- 不同之处
- 创建基础分类器。
- 装袋—单独进行
- 提升—迭代—鼓励新的分类器成为以前的基础学习器所分类错误的例子的专家
(互补的专业知识)
- 组合方法
- 装袋—对所有基础学习者的权重相同
- 提升法—不同的权重—基于训练数据的表现
- 创建基础分类器。
- 操纵属性--使用输入特征的一个子集(例如随机森林和随机子空间)
-
Random Forest
- 每个基础分类器只使用特征的一个子集
- 例如,有K个特征的训练数据,创建一个M个分类器的集合体
- 1)通过从原始特征中随机选择创建特征子集=>创建多个版本的训练数据,每个版本只包含 只包含所选特征
- 2) 为每个版本的训练数据建立一个分类器
- 3) 将预测与多数票结合起来
- 例子。随机森林
- 结合了决策树
- 使用1)装袋+2)特征子集(在建立决策树期间。选择最重要的属性时)

- 性能取决于
- 单个树的准确性(树的强度)。
- 树之间的关联性
- 理想情况下:准确得单个树,但相关性较低
- 装袋和随机特征选择被用来产生多样性 并降低树之间的相关性
- 随着特征数k的增加,强度和相关性都会增加
- 随机森林的性能通常优于单一的决策树
- 对过度拟合有很好的适应性
- 速度快,因为只考虑特征的一个子集
- 操纵类标签--将不包括在内(如纠错的输出编码) - 操纵学习算法--例如,建立一组具有不同参数的分类器具有不同的参数
Ensembles - summary
- 集合体结合了几个分类器的预测结果
- 当单个分类器是准确和多样化的时候,它们就能发挥作用。
- 多样性是通过操作训练数据产生的
- 训练数据(Bagging, Boosting)来产生多样性。
- 属性(随机森林=袋装化+随机选择的 属性)。)
- 学习算法
- 有些合集结合了同一类型的分类器,有些则没有
- 大多数合集使用多数票来对新数据进行预测。其他则使用加权投票
- 集合体表现出优异的性能—在ML竞赛中获胜的解决方案往往是集合体。在ML竞赛中获胜的解决方案是一种集合方法

若有收获,就点个赞吧
0 人点赞
