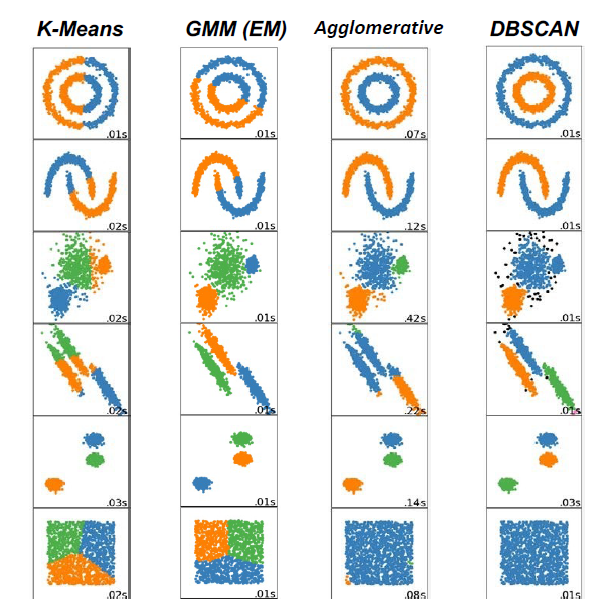
Clustering: Definition and Motivation
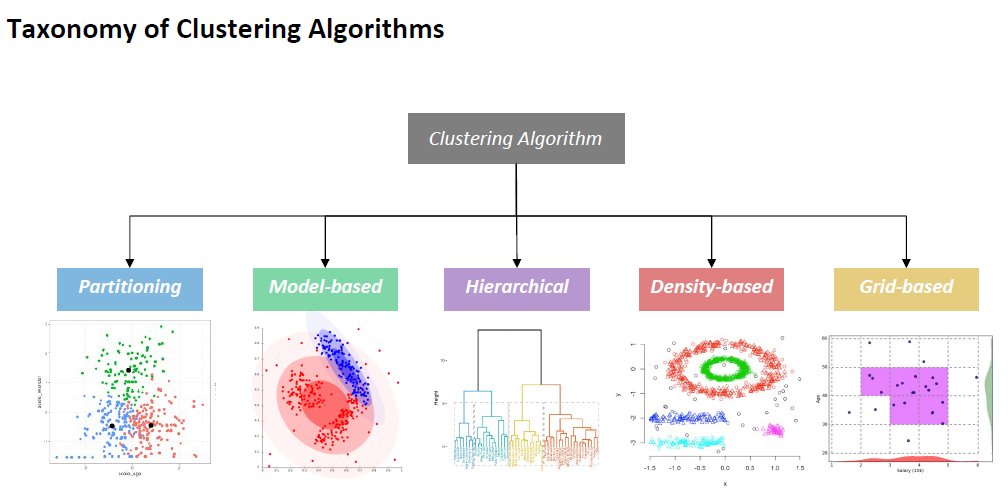
Clustering Approaches
• Partitioning Clustering: K-means Clustering
• Model-based Clustering: GMM with Expectation-Maximization (EM)
• Hierarchical Clustering: Agglomerative and Divisive Clustering
• Density-based Clustering: DBSCAN (Lecture 10)
• Grid-based Clustering: CLIQUE (Lecture 10)
Evaluation of Clustering Results (Lecture 10)
聚类(又称无监督学习)
将数据分组成集群的过程,以便数据对象(示例):
•在同一个集群中彼此相似
•不同于其他集群中的对象
聚类是无监督分类:没有预定义的类
•给定:一组未标记的示例(输入)
•任务:将集群(组)示例分成k个集群
聚类应用:图像离散化
•重新分配颜色值到k个不同的颜色
•使用颜色差异聚类像素,而不是空间数据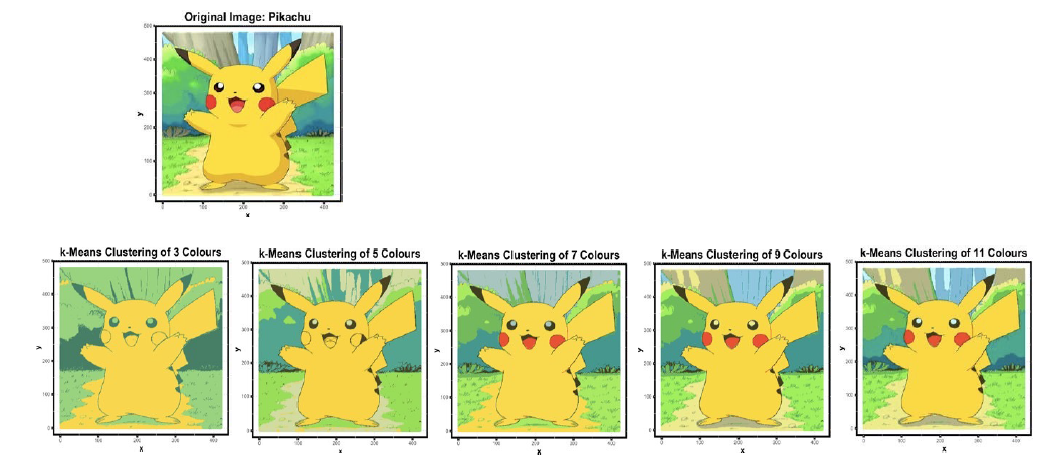
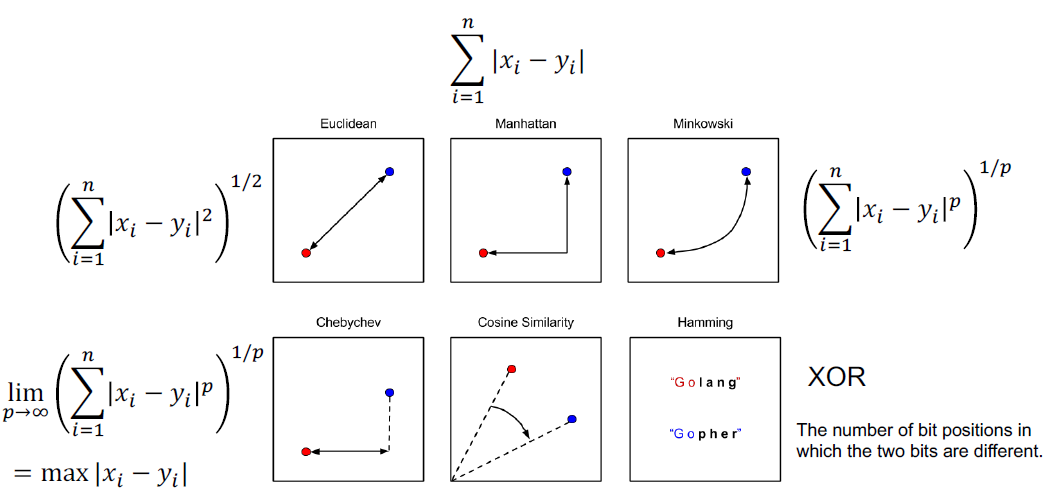
如何测量距离?
•欧氏距离
•曼哈顿距离
•余弦距离 cos值越接近1相似度越高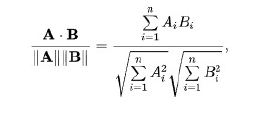
•还有许多其他…… 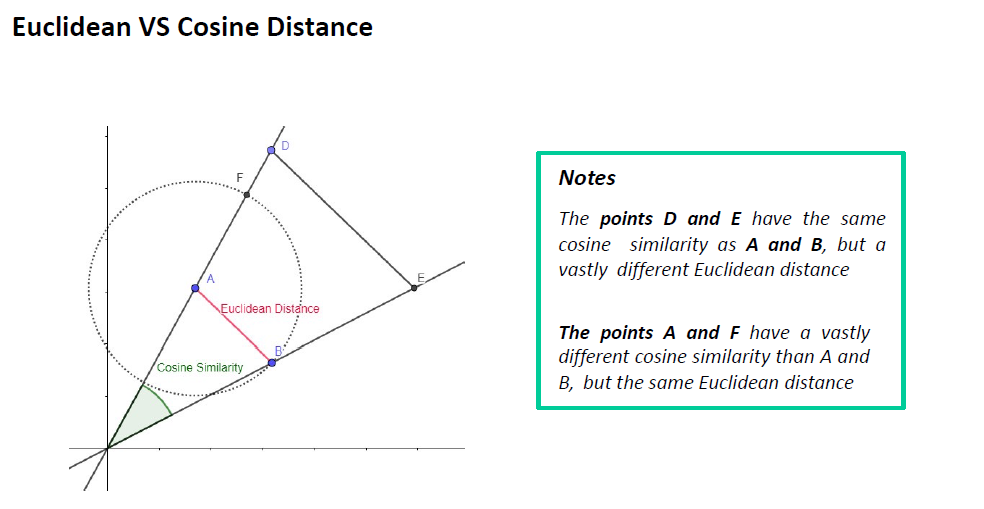
分区集群是一种集群方法,它要求分析人员指定要生成的集群数量。
k - means聚类
•必须指定集群数量K
•每个簇都有一个质心(中心点)
•每个点都被分配到具有最近质心的簇中
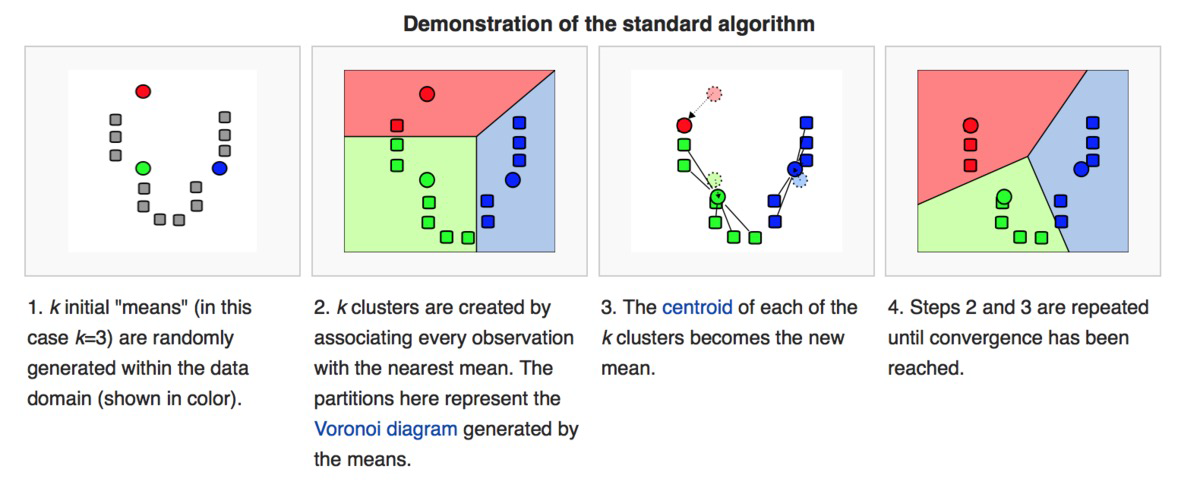
Kmeans procedures:
选择一些组来使用并随机初始化它们各自的中心点。
中心点是与每个数据点向量长度相同的向量,是图形中的“X”。
通过计算每个数据点与每个组中心之间的距离对每个数据点进行分类,然后将其分类为离其中心最近的组内点。
在这些分类点的基础上,通过取组内所有向量的平均值重新计算组中心。
对一组迭代重复这些步骤或随机初始化组中心,然后选择看起来提供了最佳结果的运行
细节:
•初始质心通常是随机选择的。
每次运行产生的集群各不相同。
•质心是聚类中点的平均值。
•“接近度”是通过欧氏距离、余弦相似度、相关性等来衡量的。
•K-means将收敛上述常见相似度量。
•大多数收敛发生在最初的几次迭代中。
通常停止条件更改为“直到相对较少的点改变簇”
•复杂度是O(n K I d)
•n =点的数量,K =簇的数量,
I =迭代次数,d =次数o
k -均值收敛(停止)准则
•没有(或最少)重新分配数据点到不同的集群,或
•没有(或最少)改变质心,或
•最小的平方误差减少(SSE)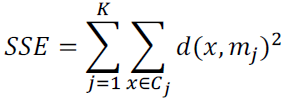

当使用质心的随机初始化时,不同的K-means运行通常产生不同的总平方误差。
选择初始质心
一种通常用于解决选择初始质心问题的技术是执行多次运行,每次运行使用随机选择的不同初始质心集,然后选择SSE最小的集群集。
开发了一种新的初始化K-means的方法,称为k -means++。
k -means聚类-空簇问题
K-means可以产生空集群(有质心无成员)
假设我们有数字(灰色)和质心(绿色、蓝色、红色)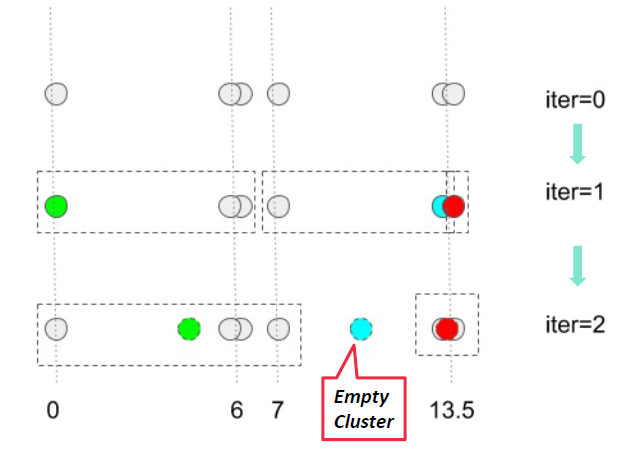
几个策略
•选择离当前任何质心最远的点。如果没有其他的,这消除了目前对总平方误差贡献最大的点。
也可以使用k -means++方法。
•从具有最高SSE的集群中随机选择替换质心。*
•这通常会拆分集群,减少集群的整体SSE。如果有几个空集群,以上步骤可以重复几次。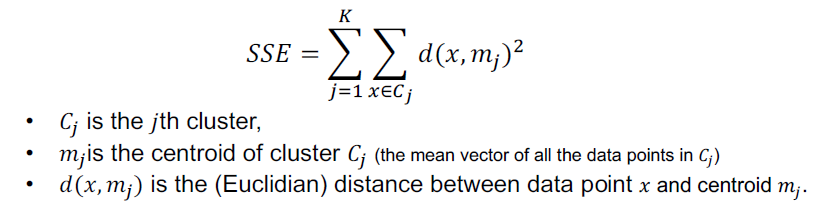
Outliers
当使用平方误差准则时,异常值会对所发现的聚类产生不良影响。特别是,当异常值存在时,产生的聚类质心
(原型)通常不像它们那样具有代表性,因此,SSE将会更高。
如果我们在聚类之前使用去除异常值的方法,我们就可以避免聚类不好的点。或者,也可以在后处理步骤中确定异常值。
Updating Centroids Incrementally
不需要在所有点分配给集群后更新集群的质心,而可以在每个点分配给集群后递增更新质心。
• Each assignment updates zero or two centroids• More expensive (-)
• Introduces an order dependency (-)
• Never get an empty cluster
• Can use “weights” to change the impact
*Bisecting K-means
这是基本K-means算法的一个直接扩展,它基于一个简单的想法:获得K个簇,将所有点的集合分割成两个簇,选择其中一个进行分割,以此类推,直到产生K个簇。
- choose the largest cluster at each step
- choose the one with the largest SSE,
- use a criterion based on both size and SSE.
平分K-means不太容易受到初始化问题的影响。
K-means及其变体在寻找不同类型的集群方面有许多限制。特别是,K-means很难检测“自然”簇,指的是簇具有非球形形状或大小或密度相差很大的簇。K-means目标函数与我们试图寻找的聚类类型不匹配。
Strengths and Weaknesses
K-means很简单,可以用于各种数据类型。
它也相当高效,即使经常执行多次运行。有些变体,包括平分K-means,效率更高,而且不太容易受到初始化问题的影响。
然而,K-means并不适用于所有类型的数据。它不能处理non-globular 簇或不同大小和密度的簇,但如果指定了足够多的簇,它通常可以找到纯子簇。
K-means在聚类包含异常值的数据时也有问题。在这种情况下,异常值的检测和去除会有很大的帮助。
Gaussian Mixture Models (EM Clustering)
假设数据生成过程是多元正态分布的混合物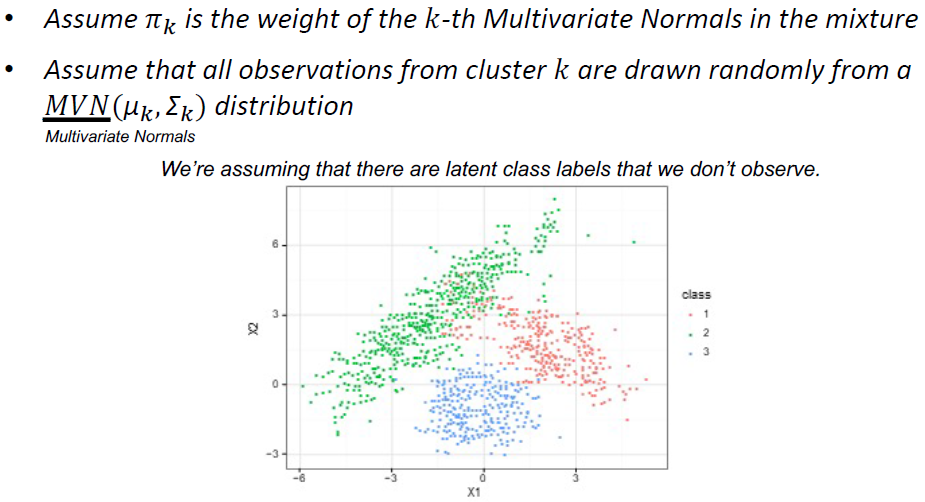
•我们不知道混合物的成分是什么样子
•我们将使用类似于𝑘-means的迭代算法
•首先将𝑘固定在某个值上
•计算每个点属于每个分布的概率
•使用这些概率来计算参数的一个新的估计
期望步骤对应于将每个对象分配给一个簇的K- means步骤。相反,每个对象都以一定的概率分配给每个集群(分布)
最大化步骤对应于计算簇的质心。相反,选择所有分布的参数,以及权重参数,以使可能性最大化。
•这是通过加权平均完成的,其中权重是点属于分布的概率
高斯混合建模(EM)与k均值
对参数进行初始猜测:μk,;Σk,:πk
•在这个例子中,GMM做得更好,因为当把点分配给质心时,它们基本上允许数据自适应的距离概念
•即,在原始数据中,我们有2个小方差的簇,和一个大方差的簇
•K-means不能捕获这些附加信息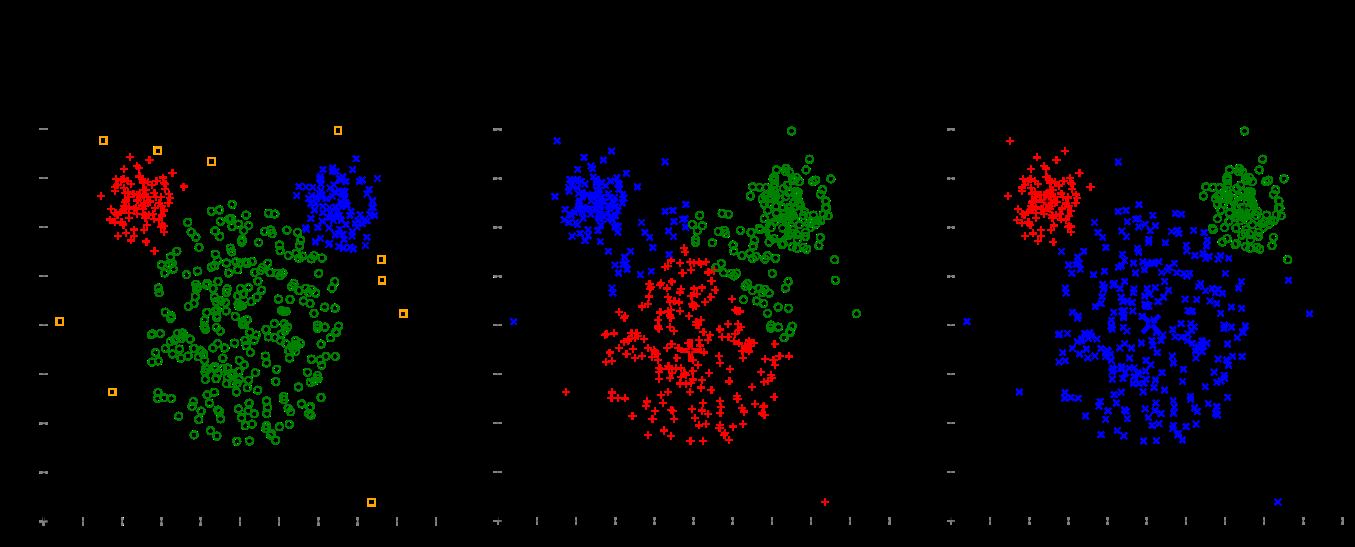
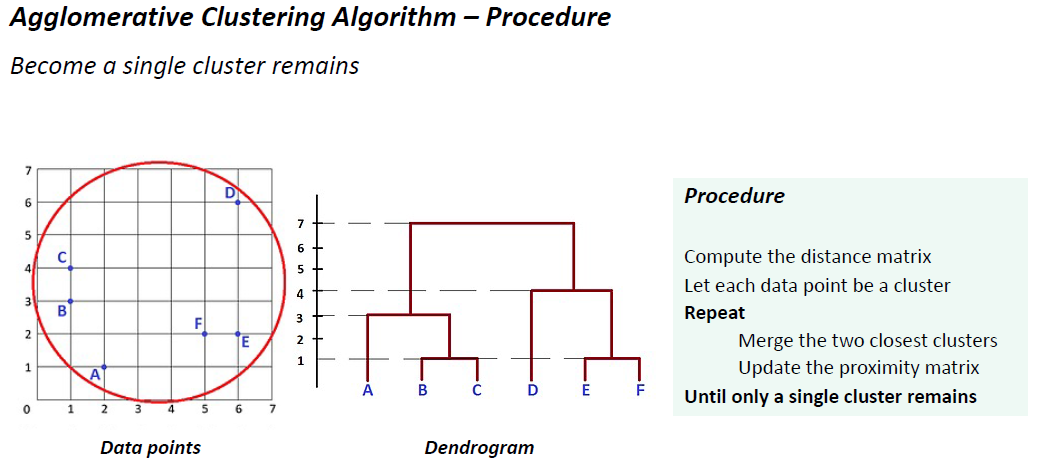
分层聚类
•生成一组组织成层次树的嵌套集群
•可以可视化为树状图
•一个类似树的图表,记录合并或拆分的序列
为什么要使用分层聚类?
•不需要假设任何特定数量的集群
•通过在适当的水平上“切割”树状图,可以获得任何想要的簇数
•它们可能对应有意义的分类法
•生物科学中的例子(例如,动物王国,系统发育重建,…)
- 凝聚聚类(自下而上)
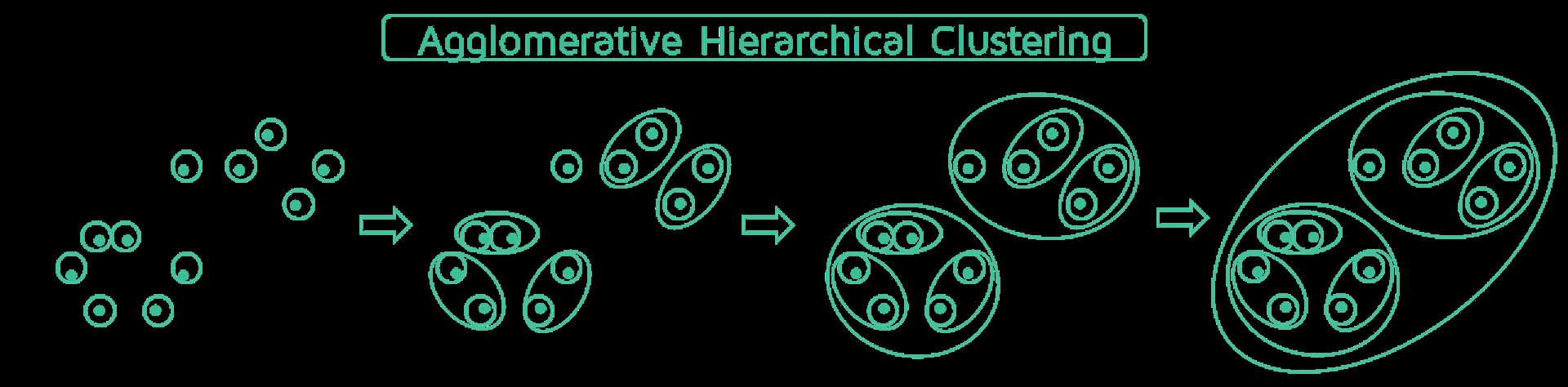
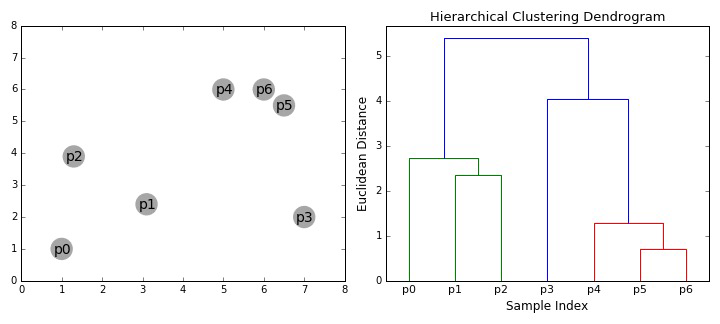
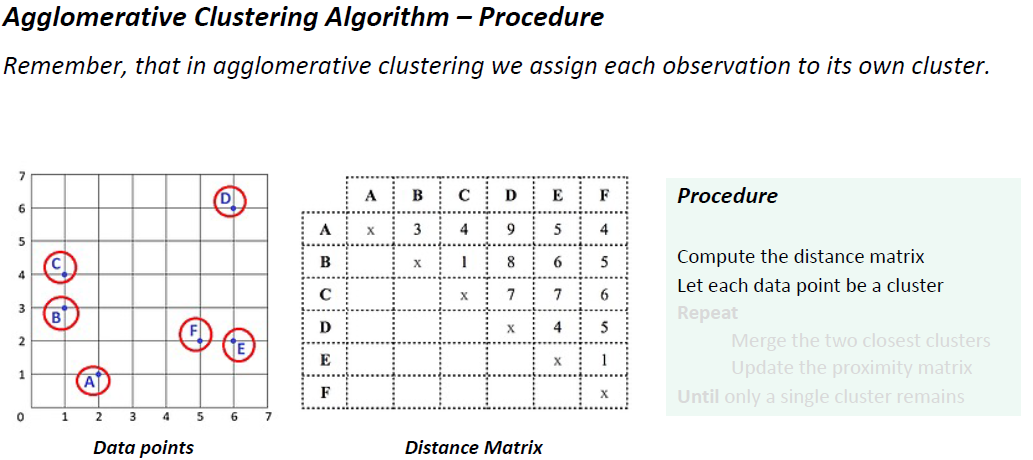
过程:
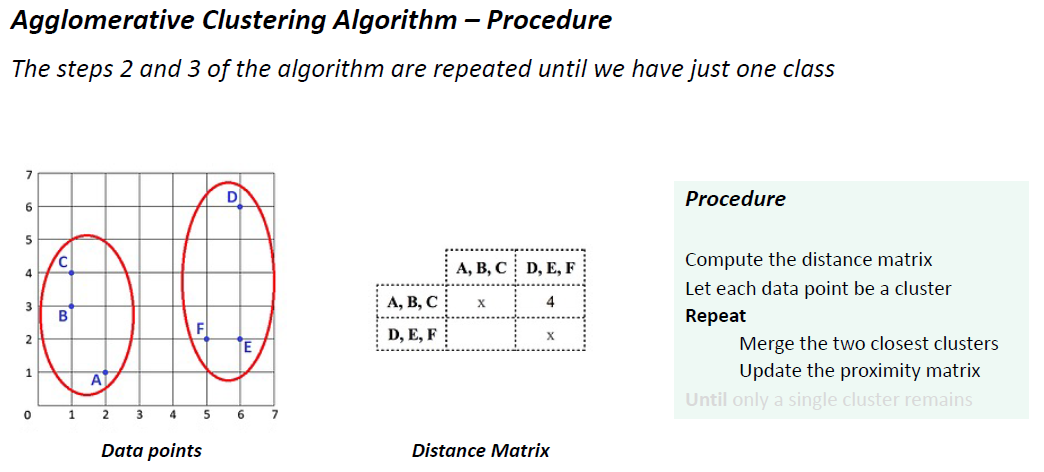
计算距离矩阵
每个数据点都是一个簇
重复
合并两个最接近的集群
更新接近矩阵
直到只剩下一个集群
*关键操作是计算两个簇的距离:定义簇间距离的不同方法区分了不同的算法
Single link:两个簇之间的距离是一个簇中的元素与另一个簇中的元素之间的最小距离
Complete link:一簇中一个元素与另一个簇中元素之间的最大距离
Average link:一簇中每个元素与另一簇中每个元素之间的平均距离
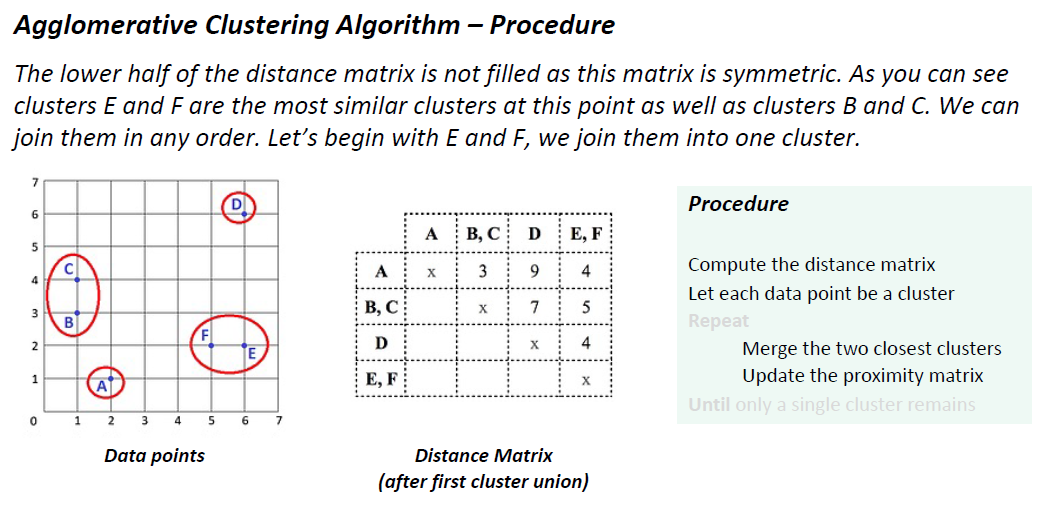 由于这个矩阵是对称的,所以距离矩阵的下半部分没有被填充。正如您所看到的,集群E和F在这一点上是最相似的集群,集群B和集群c也是。我们可以以任何顺序加入它们。让我们从E和F开始,我们把它们加入一个集群。
由于这个矩阵是对称的,所以距离矩阵的下半部分没有被填充。正如您所看到的,集群E和F在这一点上是最相似的集群,集群B和集群c也是。我们可以以任何顺序加入它们。让我们从E和F开始,我们把它们加入一个集群。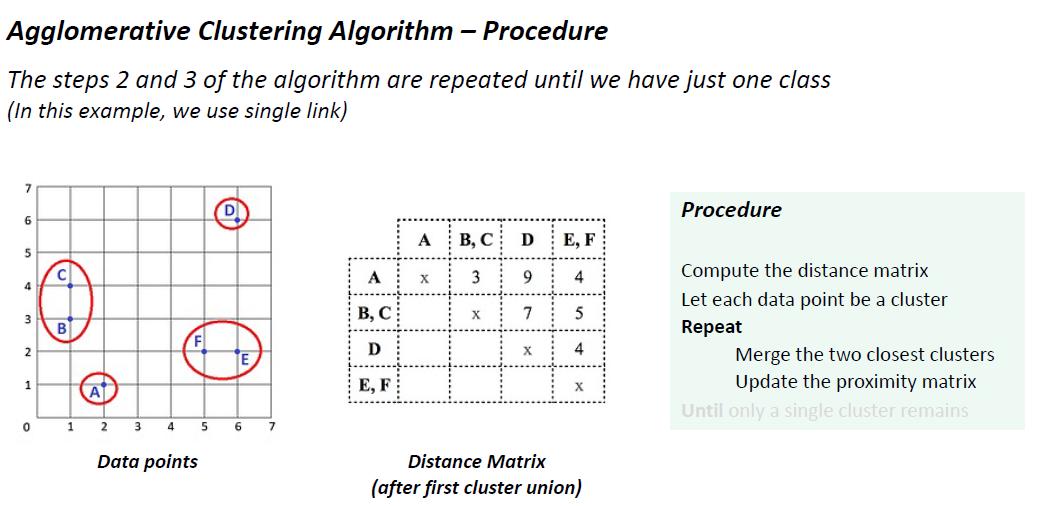

优缺点:
更一般地说,通常使用这种算法是因为底层应用程序(例如创建分类法)需要层次结构。
此外,一些研究表明,这些算法可以产生质量更好的聚类。
然而,凝聚层次聚类算法在计算和存储方面的需求是昂贵的。
所有合并都是最终的,这一事实也可能给嘈杂的高维数据(如文档数据)带来麻烦。
反过来,通过首先使用另一种技术(如K-means)部分聚类数据,可以在一定程度上解决这两个问题。
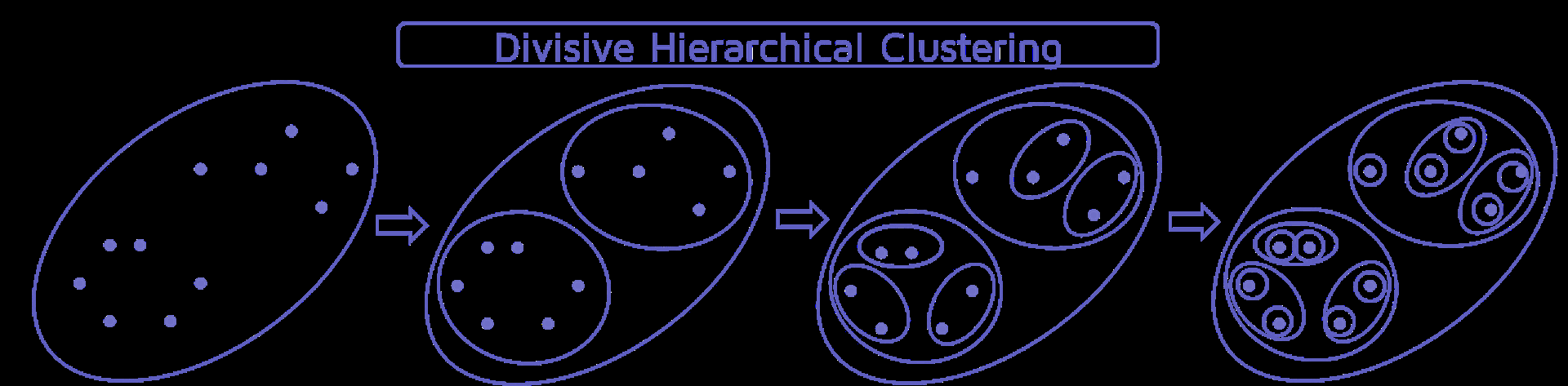
- 分裂性聚类(自上而下)
传统的分层算法使用相似性或距离矩阵(一次合并或拆分一个簇)
 时间序列聚类
时间序列聚类
•这里有一个使用层次集群来集群时间序列的例子。
•你可以通过计算它们之间的相关性来量化两个时间序列之间的相似性。有不同种类的相关性。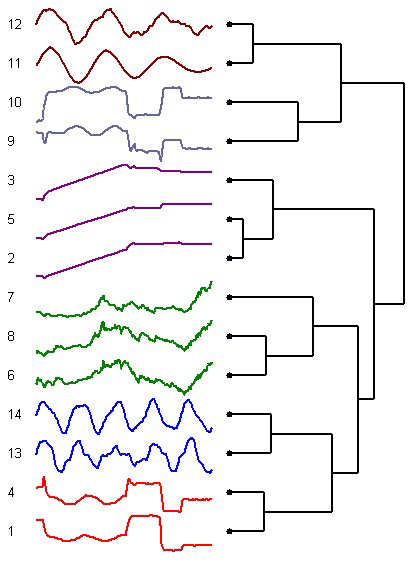

若有收获,就点个赞吧
0 人点赞
