Peceptron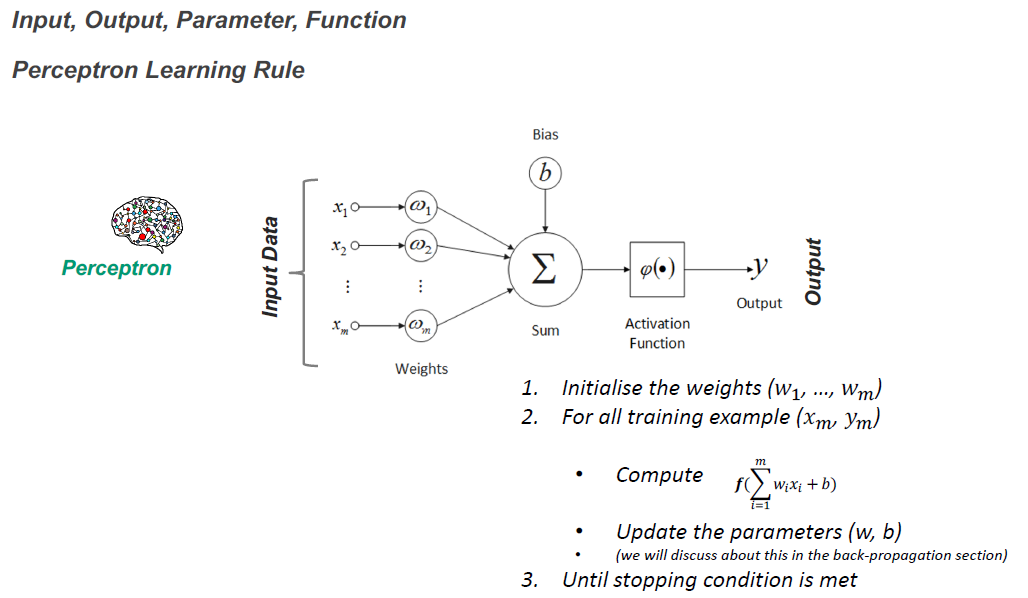
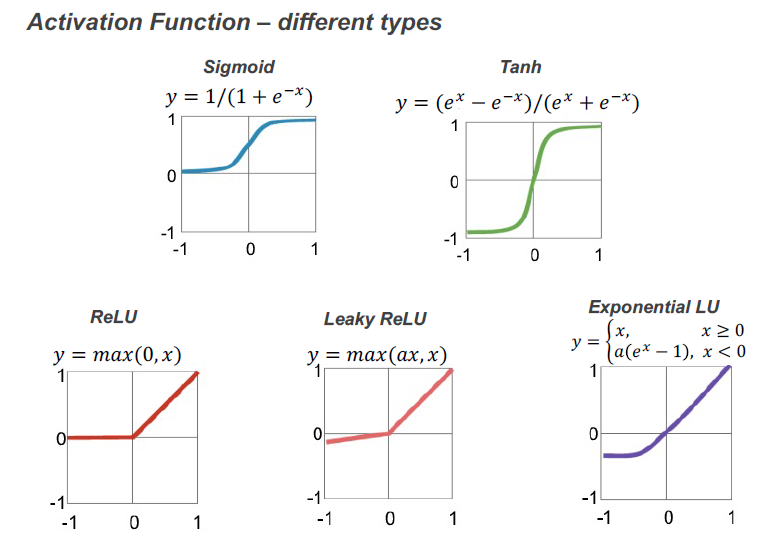
激活函数的目的是为函数添加非线性属性(神经网络)
Reduction can be apply by mutiply the input data with a weights matrix. 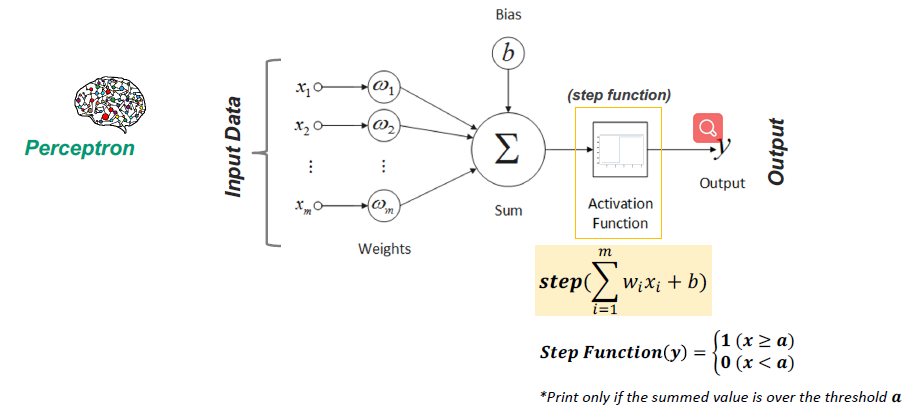
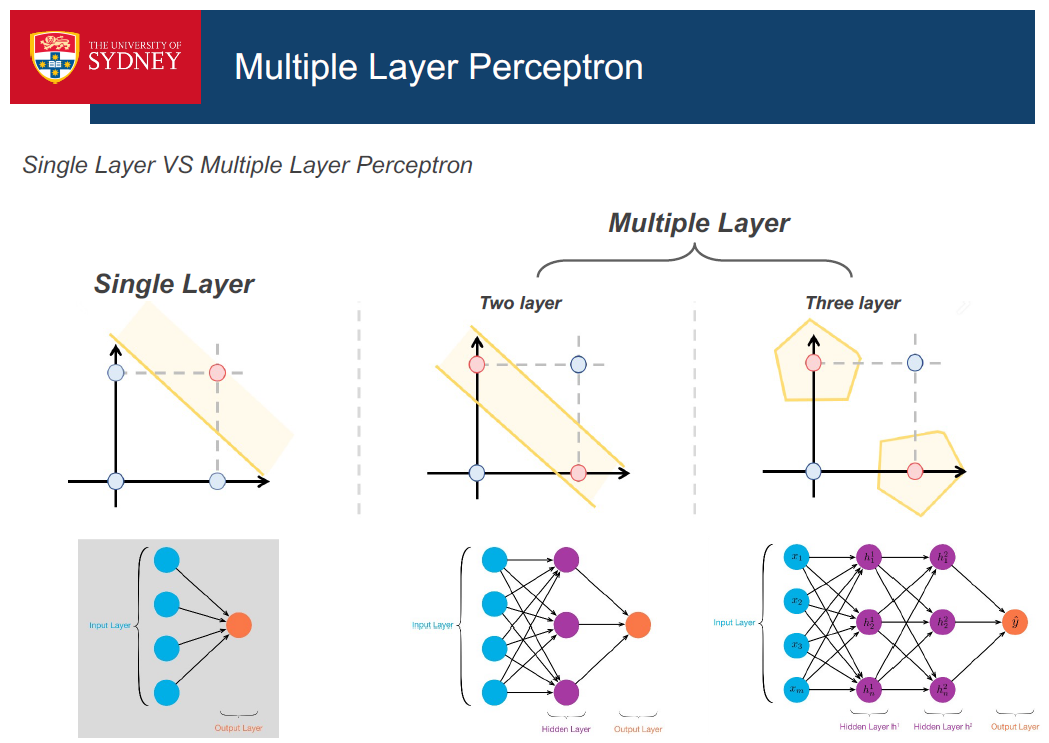
多层感知器(全连接神经网络):每一层的神经元都与下一层的所有神经元相连。
层越多,需要计算最优值的参数(w,b)就越多。s你如何解决这个问题?
Back-propagation
反向传播是一种基于错误率(即错误率)对神经网络的权值进行微调的实践。(Loss)在前一个纪元(即迭代)中获得的。适当调优权重可以确保这一点较低的错误率,提高了模型的泛化性,使模型更加可靠。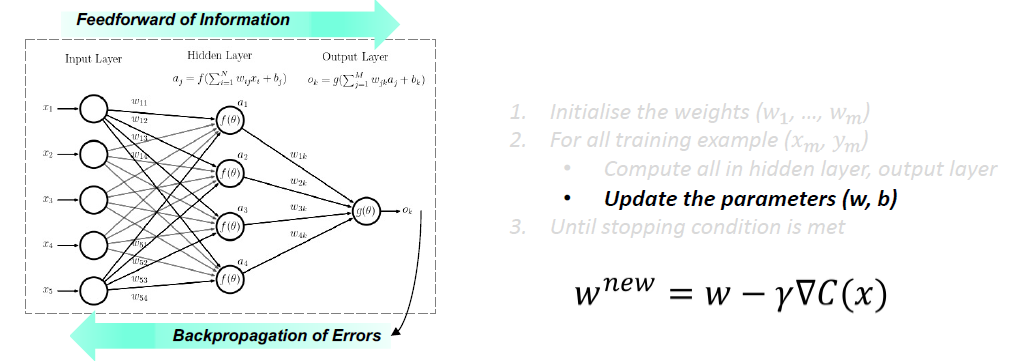

Cost function
均方误差(MSE)是最常用的回归损失函数。MSE是我们的目标变量和预测值之间的平方距离的平均值。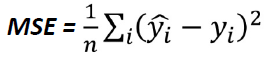
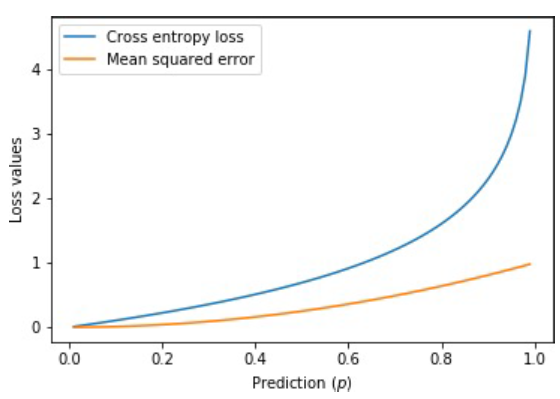
交叉熵损失,或对数损失,衡量的是输出在0到1之间的概率值的分类模型的性能。交叉熵损失随着预测概率偏离实际标签而增加。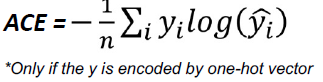
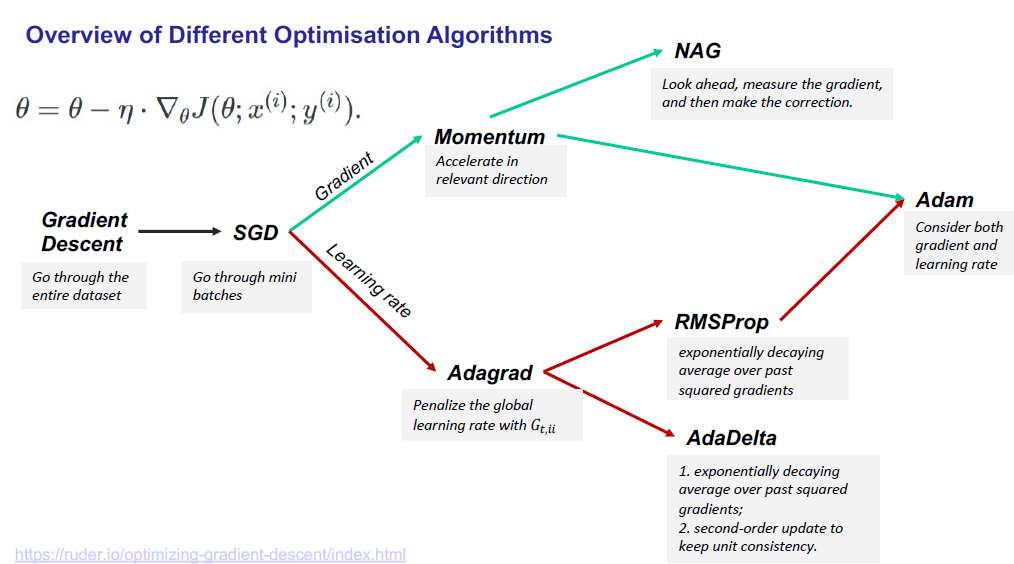
Gradient descent
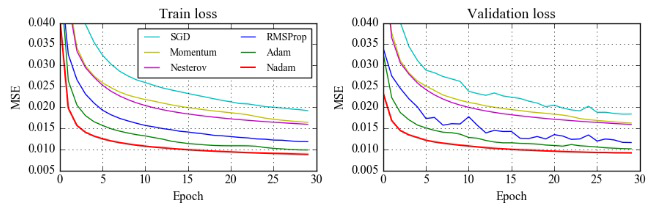
- 有不同类型的梯度下降优化算法: Batch Gradient Descent, Stochastic Gradient Descent, Momentum, Adam, etc.
- 在神经网络中,获得最优权值的关键技术是梯度下降法算法。这个算法依赖于一个叫做学习率的超参数, 用来调节重量变化的速率,使成本函数最小化。
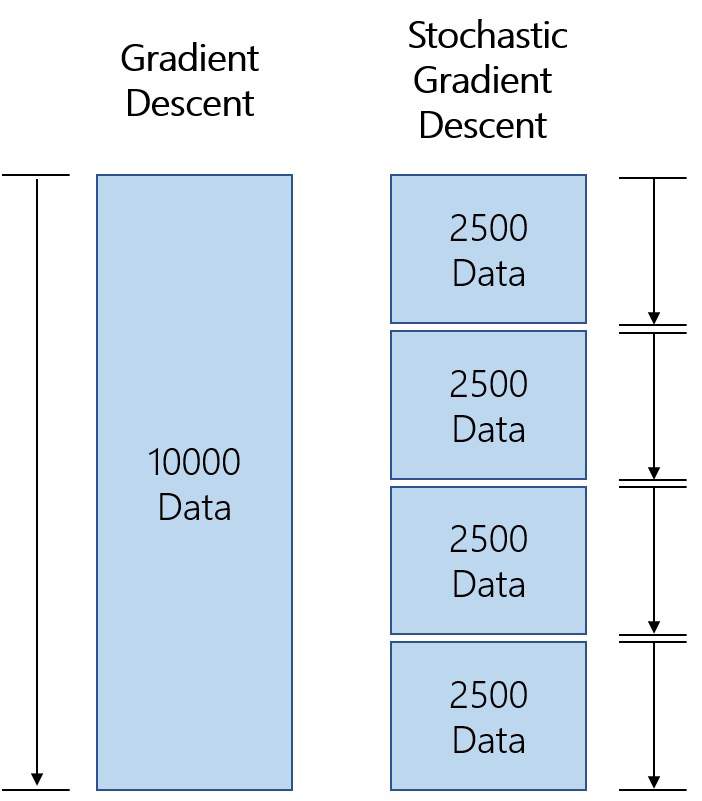
- Vanilla Gradient Descent(VGD:Vanilla梯度下降,又称批量梯度下降,计算成本函数的梯度w r t到参数θ的整个训练数据集。
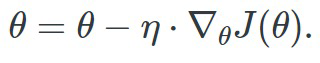 然而,它是非常缓慢的计算所有数据集在每个epoch。
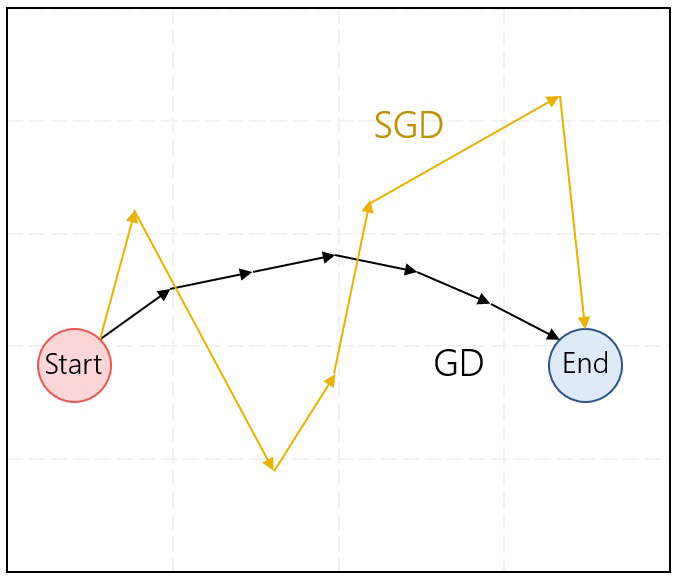
然而,它是非常缓慢的计算所有数据集在每个epoch。 - 相反,随机梯度下降(SGD)对每个训练示例𝑥(i)和执行参数更新标签𝑦(i)。SGD通过每次执行一个更新来消除这种冗余。因此通常比GD快多了。SGD执行频繁的更新,其方差很大,导致目标函数波动很大。
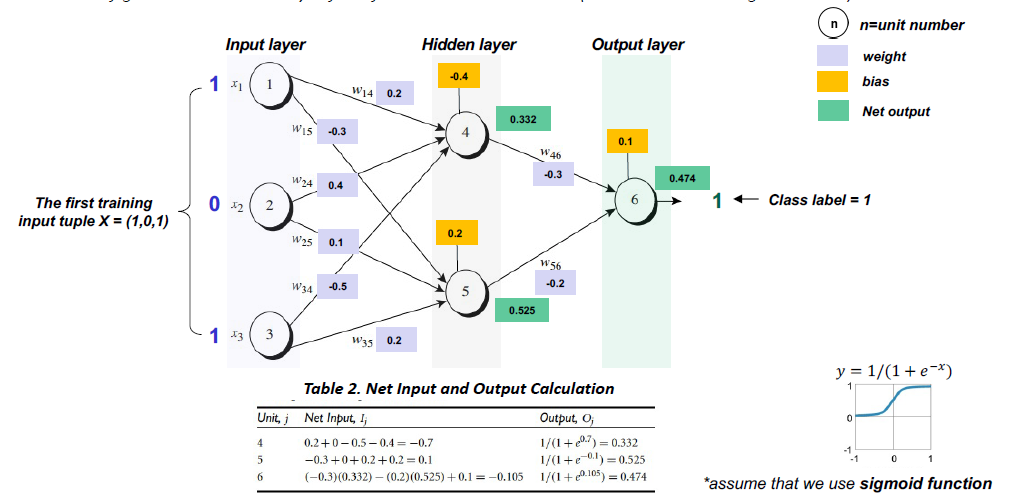
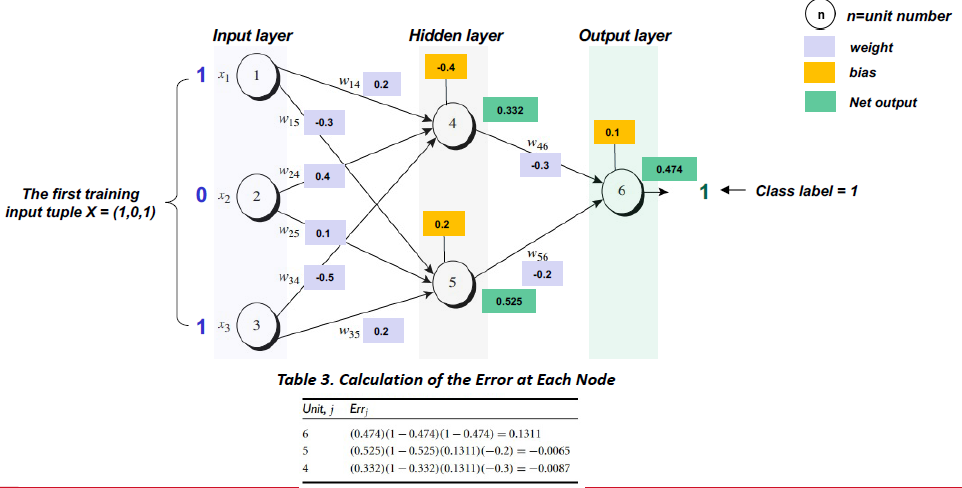
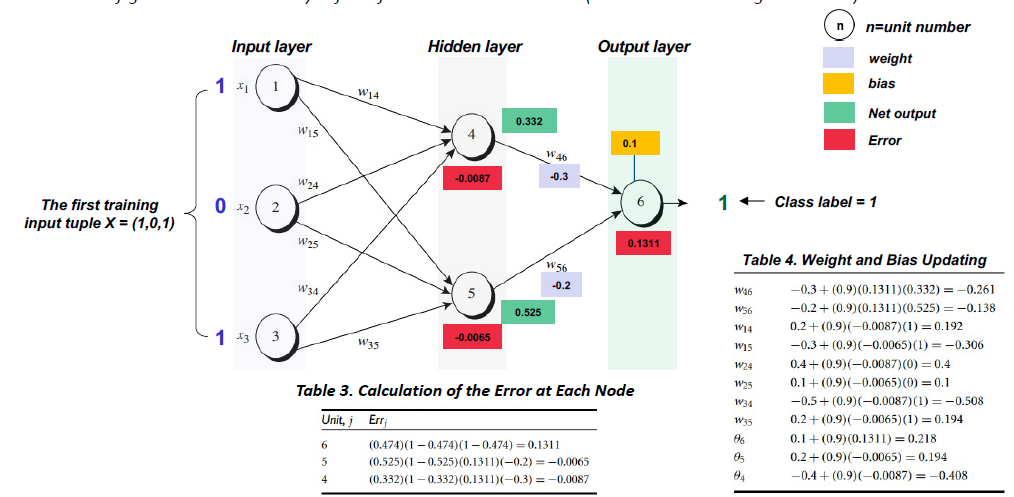
BP calculation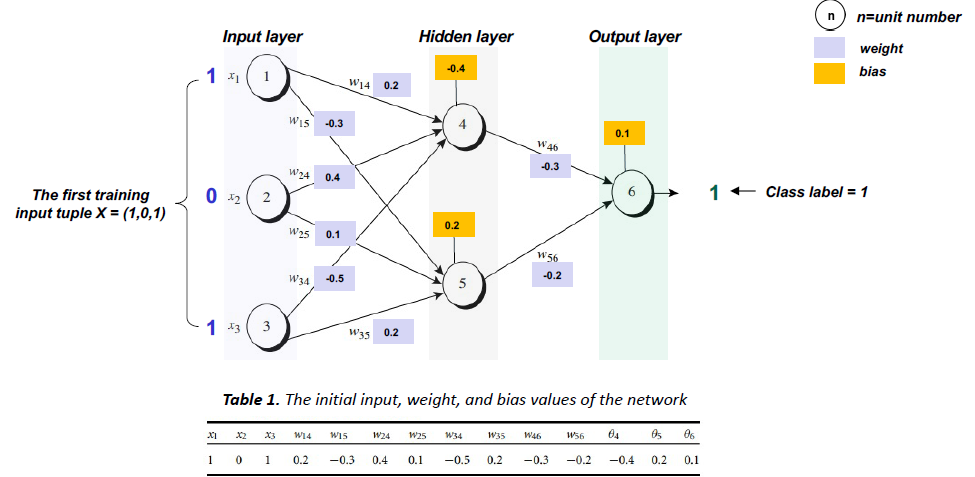
Data Augmentation
Weight Decay
限制网络权值的增长。
在原来的损失函数中增加一个项,惩罚较大的权值: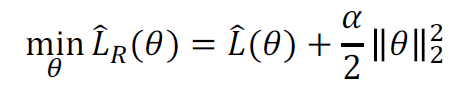 ,正规化目标梯度
,正规化目标梯度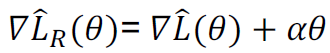 ,梯度下降法更新
,梯度下降法更新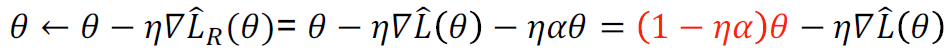
Dopout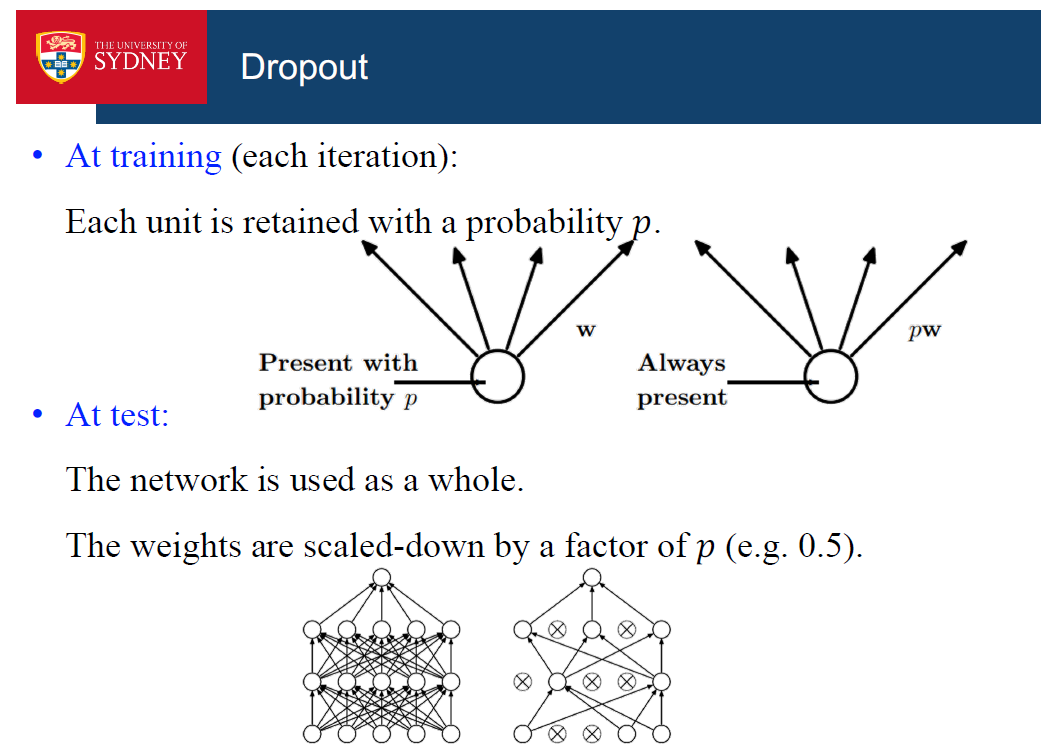
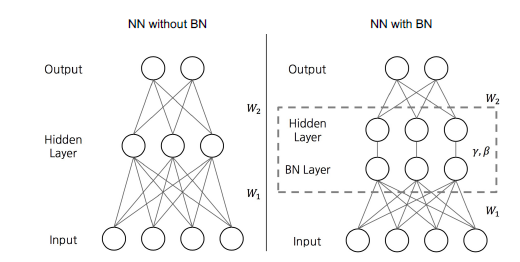
BN
协变量转移是不可取的,因为后面的层必须不断适应对分布类型的改变。
BN减少了爆炸和消失梯度的影响,因为每个梯度都变成大致正态分布。在没有BN的情况下,某一层的活化程度低会导致下一层的活化程度低,甚至下一层的活化程度更低,以此类推。


若有收获,就点个赞吧
0 人点赞
