划分(例如K-means)被设计用来寻找球形的簇。它很难找到任意形状的簇,如S形和椭圆簇。
Density-based聚类
基于密度(一种局部聚类准则)的聚类,如密度连接点。
基于密度的聚类的特征和特征
•发现任意形状的簇
•处理噪音
•一次扫描(只检查局部区域以确定密度)
•需要密度参数作为终止条件
基于密度的聚类是指由低密度区域分隔的高密度区域。<br />**DBSCAN**<br />DBSCAN是一种简单而有效的基于密度的聚类算法,它演示了许多重要的概念,这些概念对于任何基于密度的聚类方法都很重要。<br />•聚类定义为密度连通点的最大集合<br /> •密度=指定半径内点的数量(Eps)<br />两个参数:<br /> •Epsilon (Eps - Ɛ):邻域的最大半径,例如,点a的Eps半径内的点数是7,包括点a本身。<br /> •最小点数(MinPts):一个点的eps -邻域内的最小点数<br />如果半径足够大,那么所有点的密度为m,即数据集中点的数量。同样,如果半径太小,那么所有点的密度都是1。<br />基于中心的密度方法允许我们把一个点分类为:<br /> •如果Eps内至少有指定数量的点(MinPts),则为核心点<br /> •这些是集群内部的点<br /> •本身算到MinPts中<br /> •边界点不是核心点,而是在核心点附近<br /> •噪声点/离群点是指任何不是核心点或边界点的点<br />任何两个足够接近的中心点——彼此之间的距离为Eps——都被放在同一个簇中。任何足够接近核心点的边界点都被放在与核心点相同的簇中。(如果边界点靠近来自不同集群的核心点,则需要解决关系问题。)<br /> 噪声点被丢弃。<br />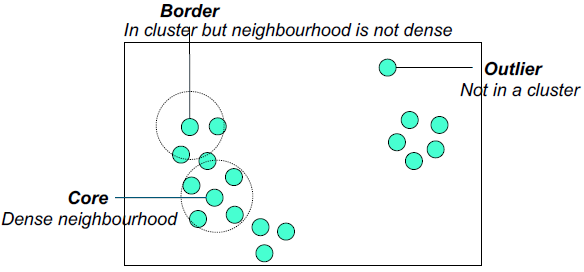<br /><br />**算法:**<br />
•任意选择点p
•通过Eps (ε), MinPts从p中检索所有密度可达点
如果p是一个核心点,则形成一个簇
如果p是边界点,没有点是密度可达的,DBSCAN访问数据库的下一个点
•继续这个过程,直到所有的点都被处理完毕
计算复杂度
•如果使用空间索引(如kd-trees),则DBSCAN的计算复杂度为O(nlogn),其中n为数据库对象的数量
•否则,复杂度为O(𝑛%)
选择DBSCAN参数的方法
•决定在一个密集区域中需要多少点:MinPts。
(假设我们希望核心点至少有k个ε邻居)
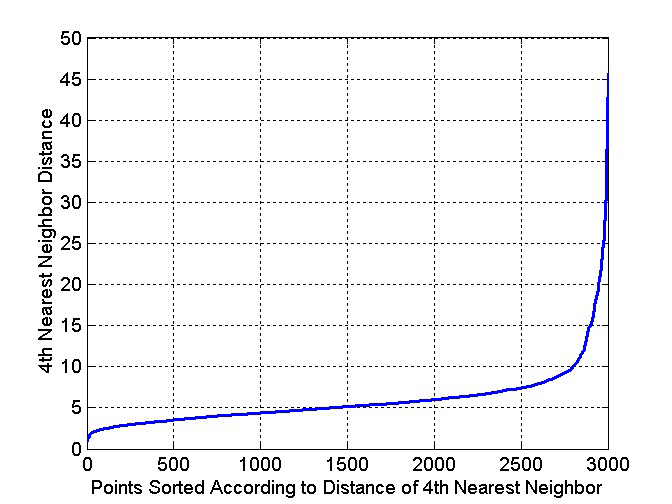
•确定每个点到它的第k个最近邻的距离,称为kdist
•对于属于某个簇的点,kdist的值会很小
[如果k不大于簇大小]
•对于不在一个簇中的点,比如噪声点,kdist会比较大
•如果我们计算某个k的所有数据点的kdist,将它们按递增顺序排序,然后绘制排序后的值,我们期望看到kdis值对应于ε的一个合适值的急剧变化。
•如果我们选择这个分割距离作为ε参数,并取k的值作为MinPts参数,那么kdist小于ε的点将被标记为核心点,而其他点将被标记为噪声点或边界点。
当DBSCAN工作良好时
•耐噪音
•可以处理不同形状和大小的集群
如果簇的密度变化很大,DBSCAN在密度方面会有问题。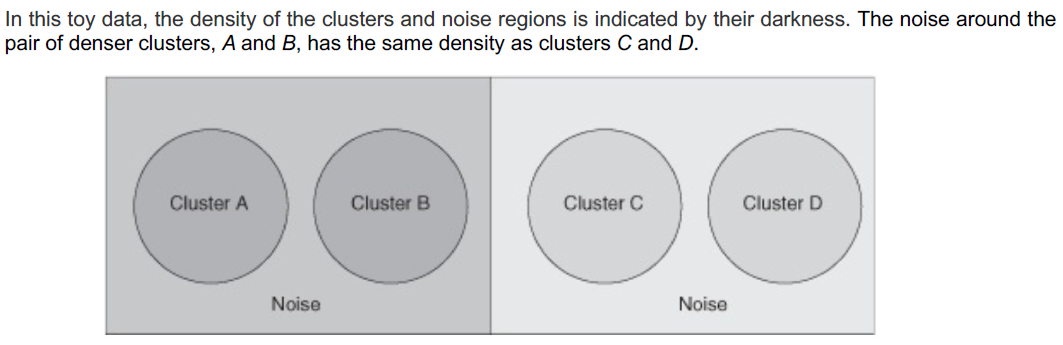
对于一个固定的MinPts,如果Eps阈值的选择使DBSCAN发现C和D是不同的簇,它们周围的点是噪声,那么a和B以及它们周围的点将成为一个单一簇。
如果设置Eps阈值,DBSCAN发现A和B作为单独的簇,它们周围的点被标记为噪声,那么C、D以及它们周围的点也将被标记为噪声。
Grid-based Clustering Method
网格是组织一组数据的一种有效方式,至少在低维的情况下是这样。
探讨聚类中的多分辨率网格数据结构
•将数据空间划分为有限数量的单元格,形成网格结构
•从网格结构的单元格中找到簇(密集区域)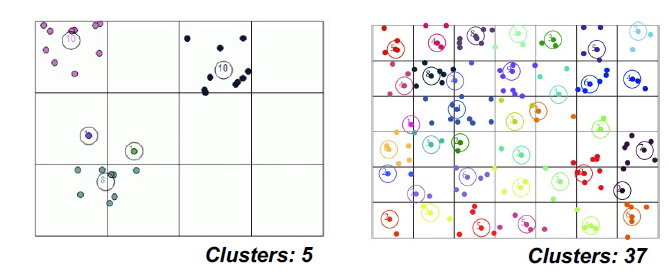
STING (STatistical INformation Grid approach) Wang等人(1997)
•探索网格单元中存储的统计信息
•空间区域被分成不同分辨率的矩形单元格,这些单元格形成树状结构
•在𝑖级别的单元格包含了一些更小的𝑖+1级别的单元格
•每个单元格的统计信息(例如,计数,平均值,标准偏差)预先计算和存储,并用于回答查询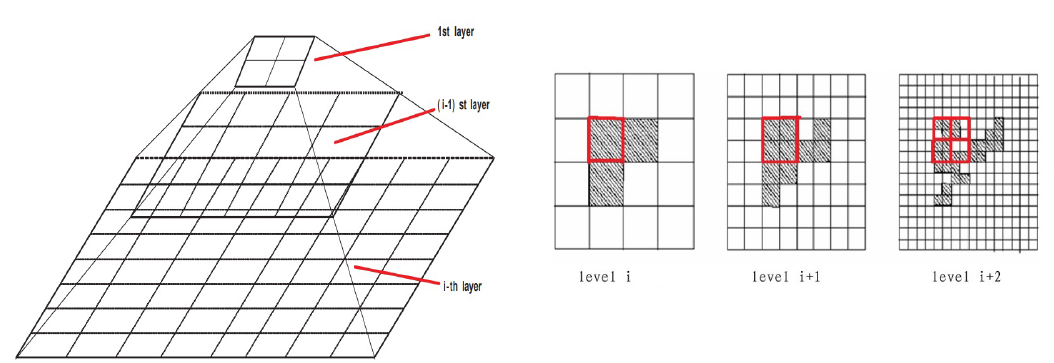
处理区域查询
•从根开始,使用STING索引进入下一个较低的层次
•使用cell的统计信息计算一个cell在某种置信水平上与查询相关的可能性
•递归地探索可能相关细胞的子细胞
•重复这个过程,直到达到最底层
优势
•易于并行化,增量更新
•效率:复杂度是O(K)
•K:最低层网格单元的#,K << N(即数据点的#)
缺点
•它的概率性质可能意味着在查询处理的准确性的损失
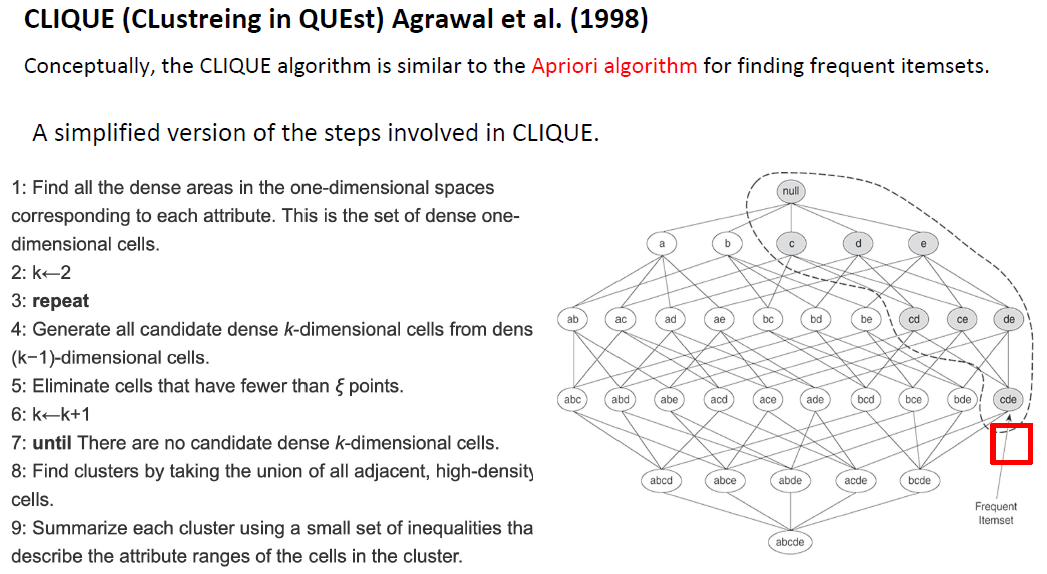
CLIQUE (QUEst中的集群)Agrawal等(1998)
•表示在高维数据空间中基于网格和密度的子空间聚类方法
到目前为止所考虑的聚类技术通过使用所有的属性来发现聚类。然而,如果只考虑特征的子集,即数据的子空间,那么我们发现的聚类可以从一个子空间到另一个子空间非常不同。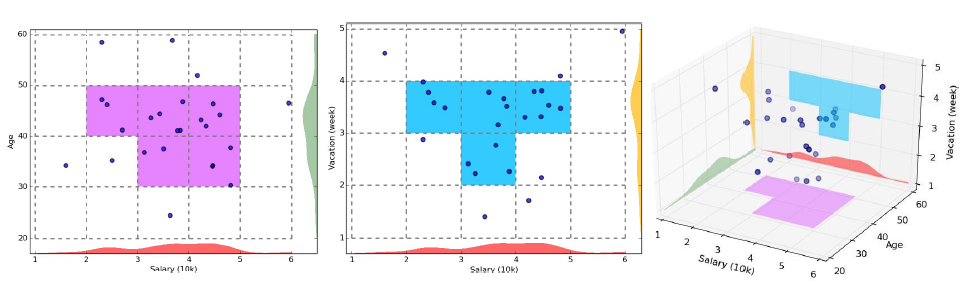
CLIQUE (QUEst中的集群)Agrawal等(1998)
检查每个子空间的集群是不切实际的,因为这样的数量
子空间的维数是指数的。
CLIQUE依赖于以下属性:
如果一组点在k个维度(属性)中形成一个基于密度的聚类,那么同一组点在这些维度的所有可能子集中也是基于密度的聚类的一部分。
考虑一组相邻的k维细胞,它们形成一个簇;也就是说,有一个邻近细胞的集合,其密度超过指定的阈值ξ。
在k−1个维度中,可以通过省略k个维度(属性)中的一个来找到相应的单元格集。低维单元格仍然相邻,每个低维单元格包含相应高维单元格的所有点。
因此,低维单元的密度大于或等于相应的高维单元的密度。因此,低维细胞形成集群;也就是说,这些点与属性的约简集形成一个聚类。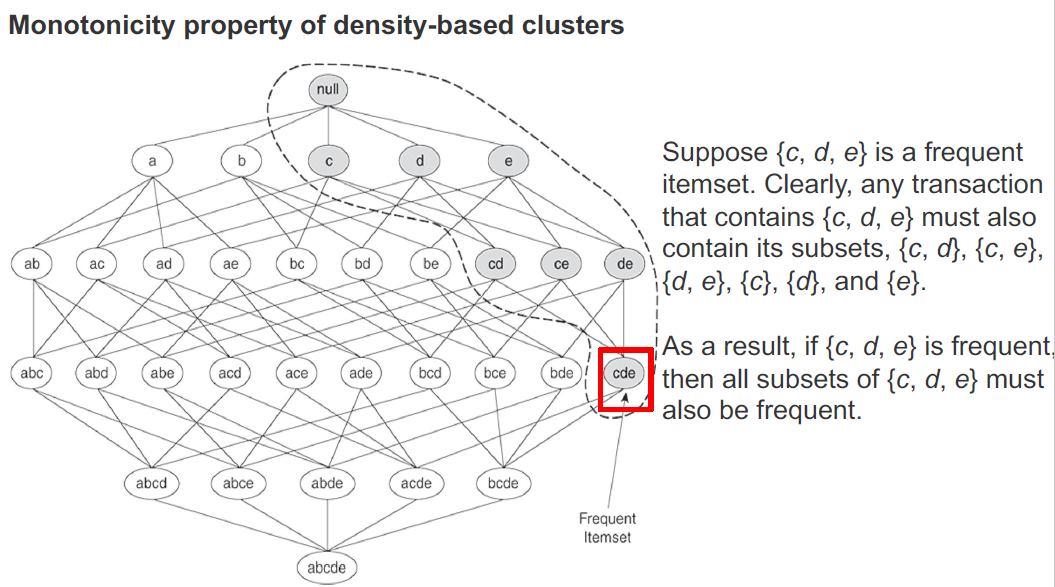
优势:
•自动发现最高维的子空间,只要高密度集群存在于这些子空间
•对输入中记录的顺序不敏感,不假设一些规范的数据分布
•随输入的大小线性扩展,并且随着数据维度的增加具有良好的可伸缩性
缺点:
•与所有基于网格的聚类方法一样,结果的质量关键取决于分区和网格单元的数量和宽度的适当选择
一个好的聚类方法将产生高质量的簇
•类内相似性高:集群内的内聚性
•类间相似性低:集群之间具有独特性
质量功能
•通常是一个单独的“质量”函数,用来衡量集群的“好坏”
•难以定义“足够相似”或“足够好”
相似性度量是聚类分析的关键
•你会使用什么样的相似性度量?
质量
•能够处理不同类型的属性
(数字、分类、文本、多媒体、网络和多种类型的混合)
•发现任意形状的簇
•处理嘈杂数据的能力
可伸缩性
•聚类所有数据,而不仅仅是样本
•高维度
•增量或流聚类,对输入顺序不敏感
基于聚类
•用户给定的偏好或约束;领域知识;用户查询
可解释性和可用性
•最终生成的集群在语义上应该是有意义的和有用的
聚类评价
聚类评价:评价聚类结果的好坏
•实践中没有公认的最佳合适措施
categorization of measures: External, internal, and relative
- External: Supervised, employ criteria not inherent to the dataset
Compare a clustering against prior or expert-specified knowledge
(i.e., the ground truth) using certain clustering quality measure- 集群同质性(Cluster homogeneity)
•越纯越好 - 集群的完整性(Cluster completeness)
•将ground truth中属于同一类别的对象分配到同一簇中 - Rag bag better than alien
•将异构对象放入纯簇比将其放入杂类(即“杂项”或“其他”类别)更糟糕。 - 小型簇保护(Small cluster preservation)
•把一个小类别分成几个部分比把一个大类别分成几个部分更有害
- 集群同质性(Cluster homogeneity)
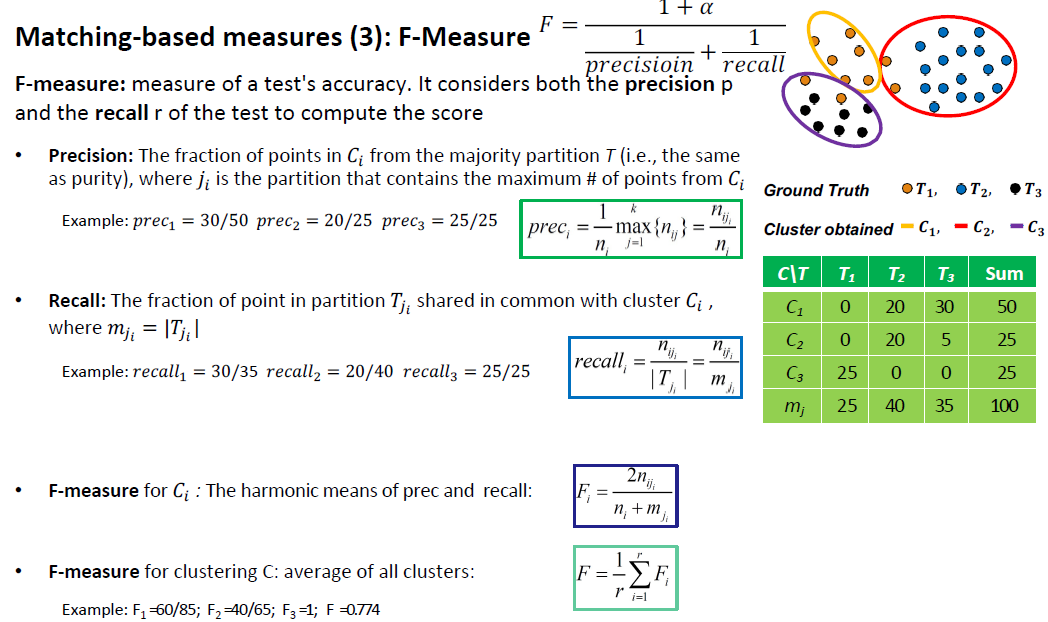
- Matching-based measures
- Purity, maximum matching, F-measure
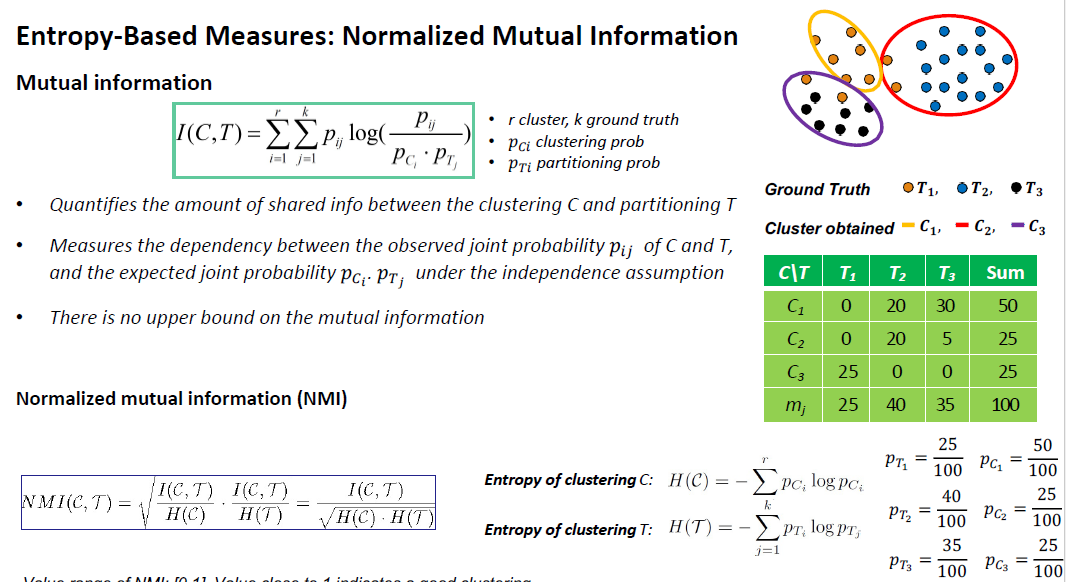
- Entropy-Based Measures
- Conditional entropy
- 标准化互信息(NMI)(Normalized mutual information)
- Pairwise measures
- Four possibilities: True positive (TP), FN, FP, TN
- Jaccard coefficient, Rand statistic, Fowlkes-Mallow measure
- Internal: Unsupervised, criteria derived from data itself
• Evaluate the goodness of a clustering by considering how well the clusters are
separated and how compact the clusters are
• e.g., silhouette coefficient, calinski-harabasz Index, Davies-Bouldin Index - Relative: Directly compare different clusterings, usually those obtained via different
parameter settings for the same algorithm. 同一算法不同参数






若有收获,就点个赞吧
0 人点赞
