- Markov Decision Processes (MDP)
- Q-Learning
- Deep Q Learning
- Applications
Supervised Learning
监督学习算法试图让它们的输出模仿训练集中给出的标签y。
那顺序决策问题呢?
•很难定义让它骑自行车的正确行为是什么
•难以对试图模仿的学习算法进行明确监督。(如监督学习)
->“Reinforcement Learning”
Reinforcement Learning
强化学习是一种从交互中学习的计算方法。
构造reward function当learning agent做的好或者不好
-奖励𝑹𝒕是一个标量反馈信号
-表示代理在步骤t处的工作情况
-特工的任务是使累计奖励最大化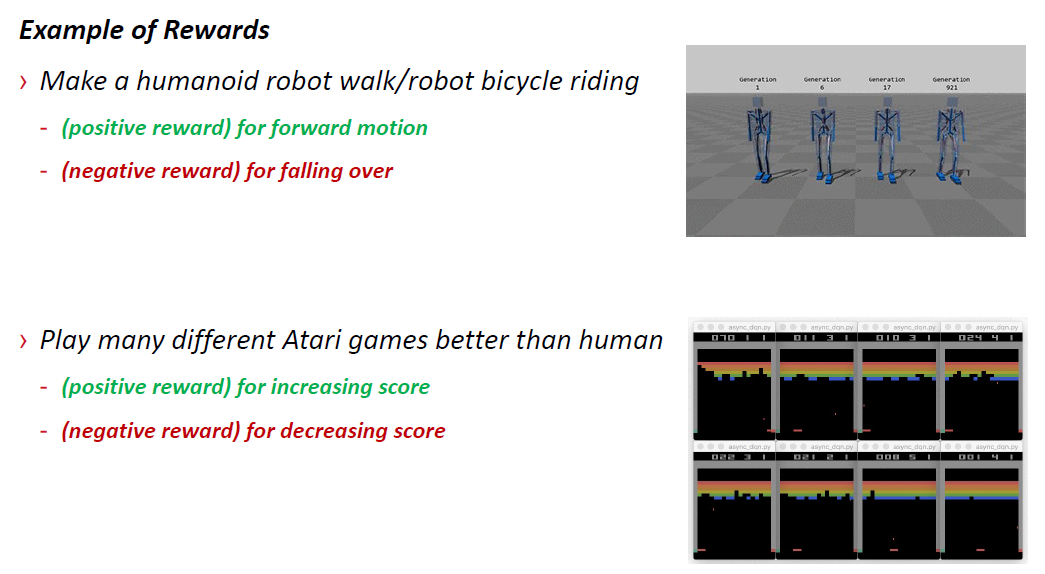
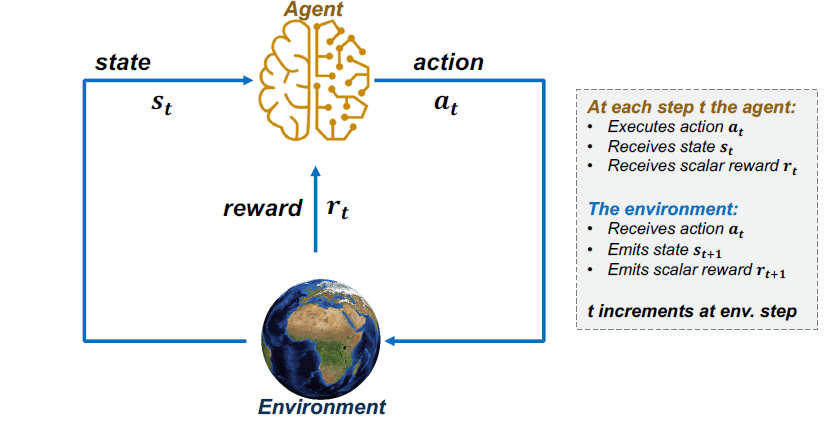


State is using the which two of the last dimension. And action is the perfermance of prediction. Reward could be the increse weight of the dimension with the higher performance.
Major Components of an RL Agent
An RL agent may include one or more of these components:
› Policy: agent’s behaviour function
› Value Function: how good is each state and/or action
› Model: agent’s representation of the environment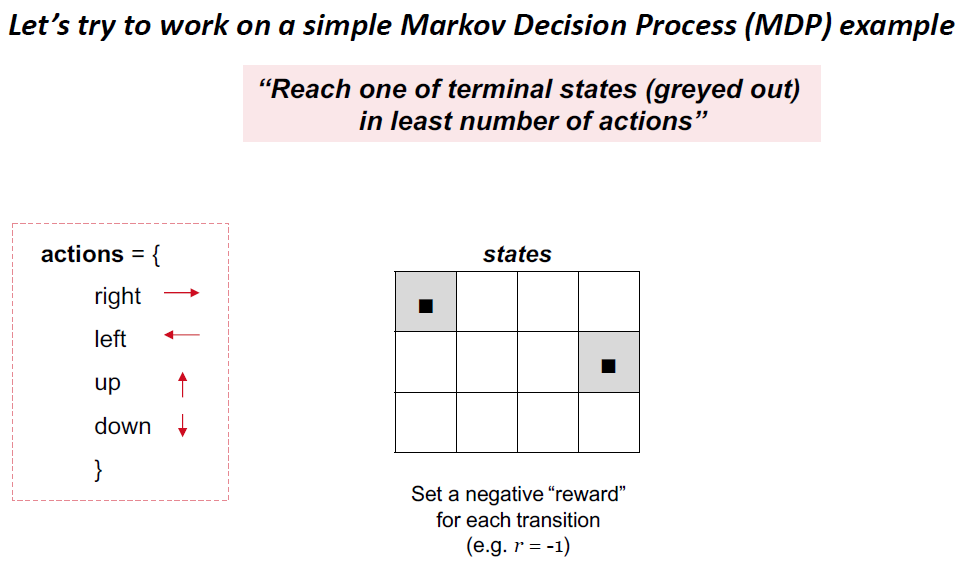
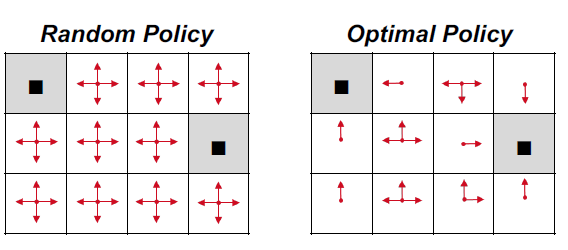



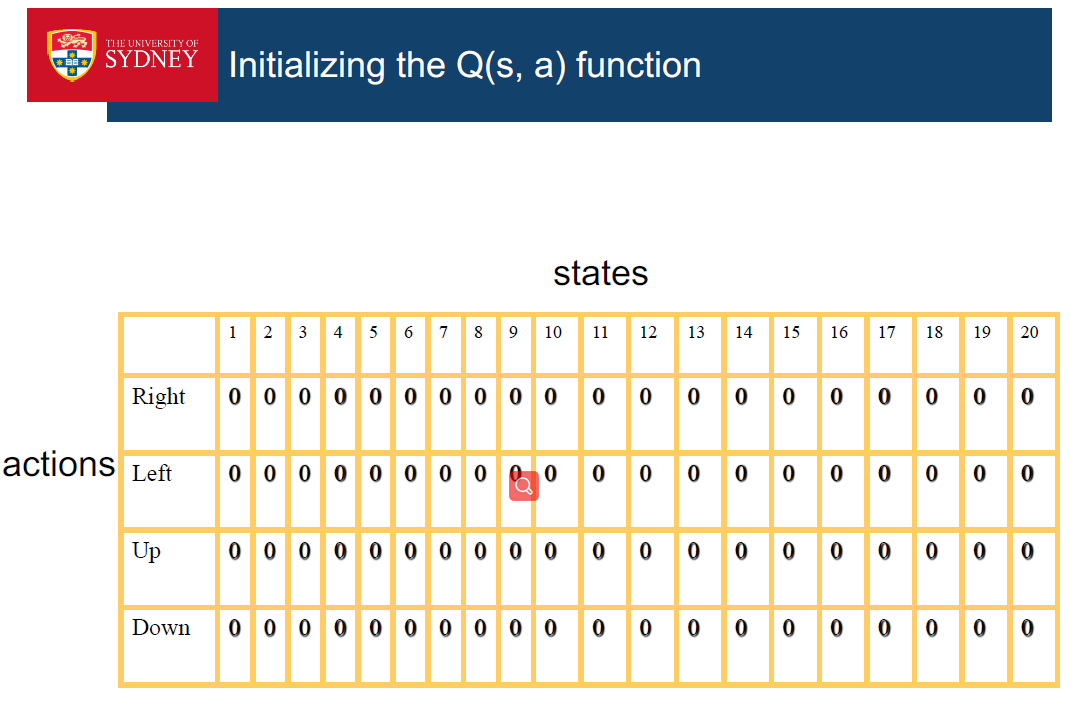

Q-learning的主要优势就是使用了时间差分法(融合了蒙特卡洛和动态规划)能够进行off-policy的学习,使用贝尔曼方程可以对马尔科夫过程求解最优策略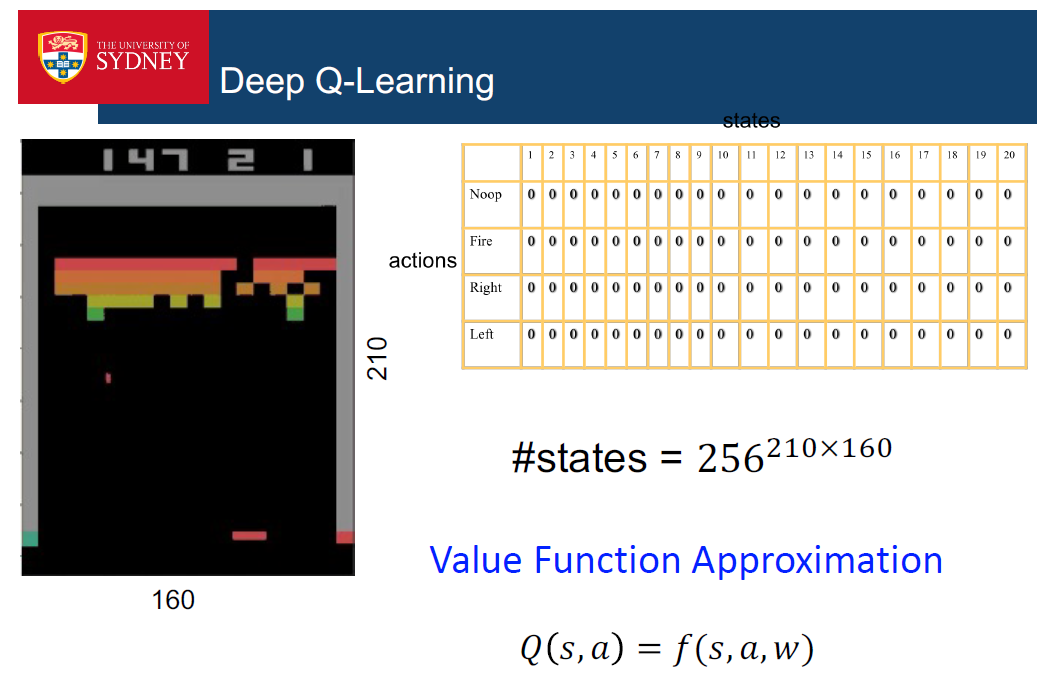
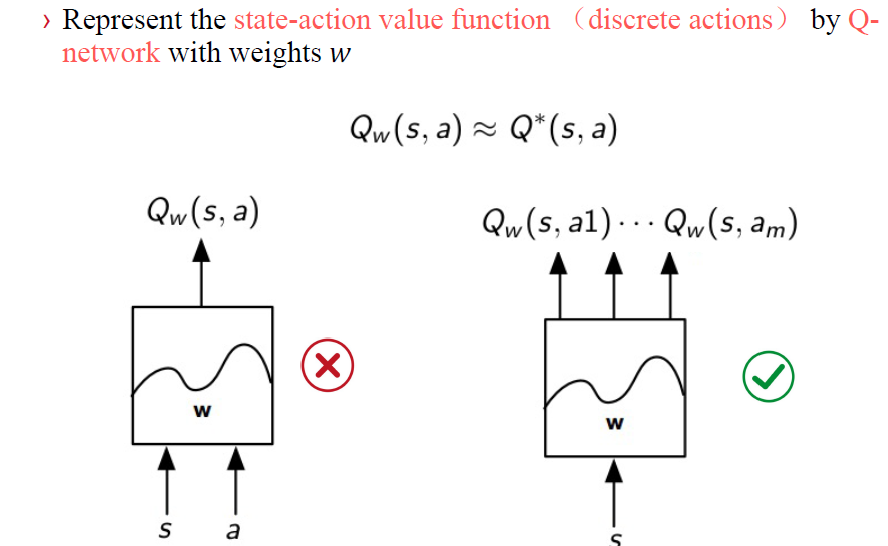
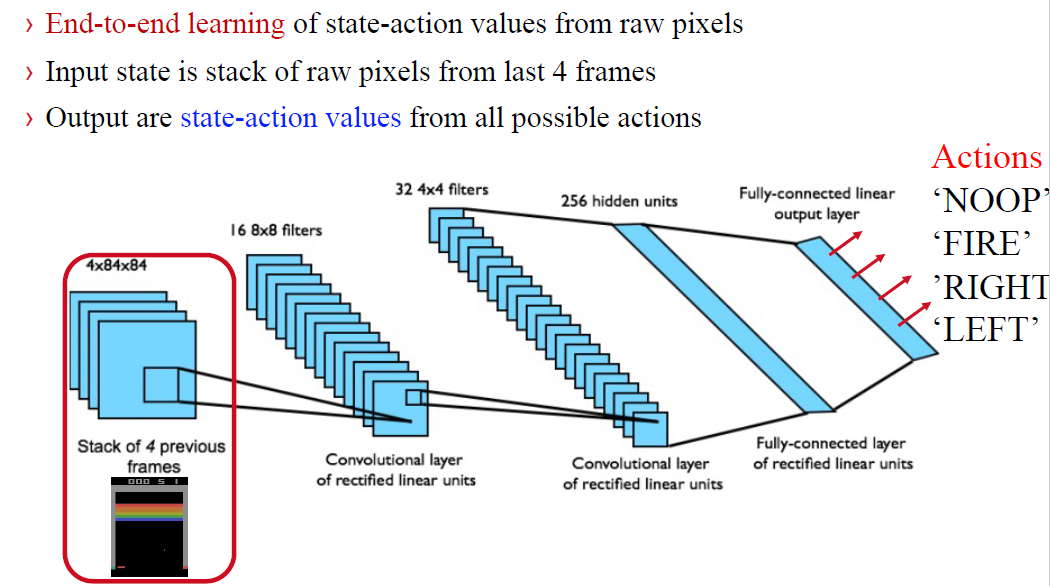





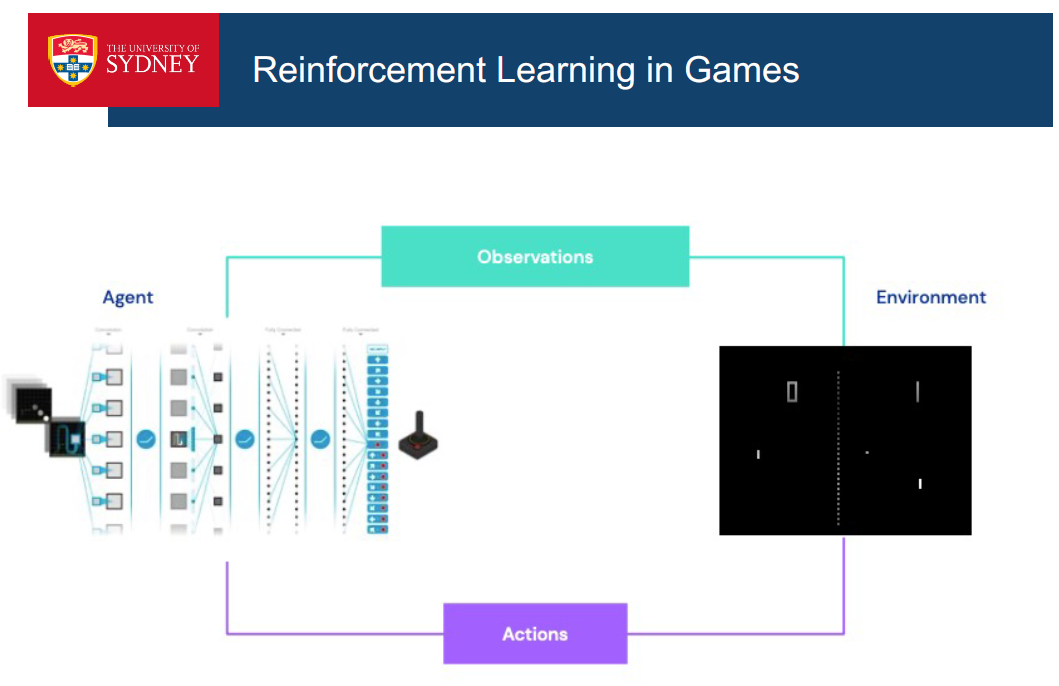
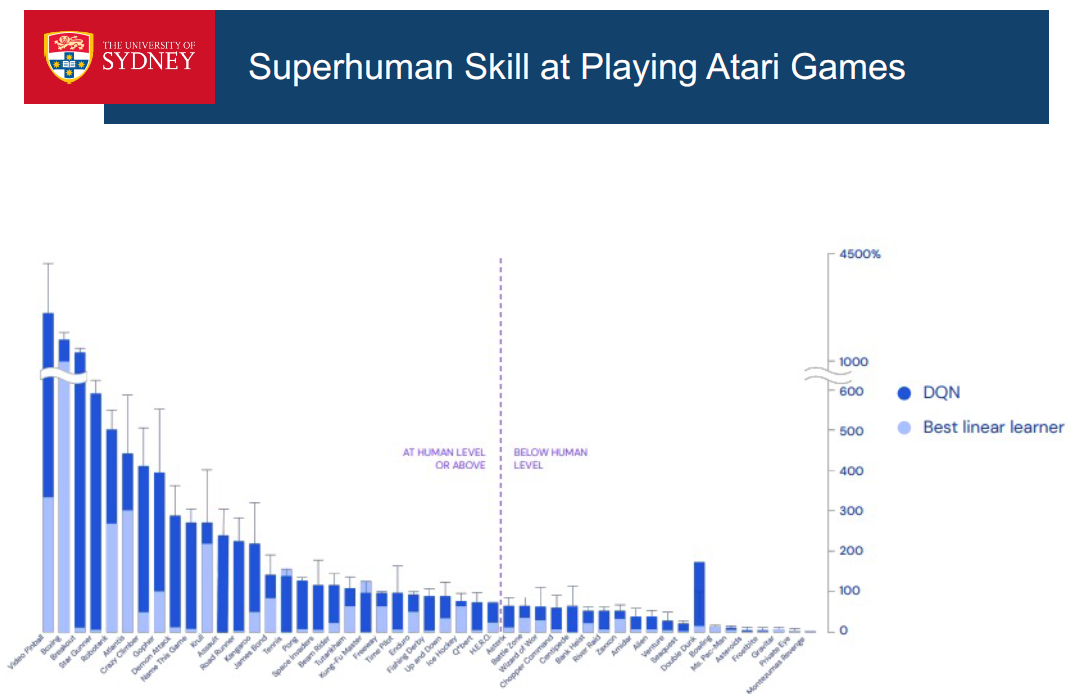

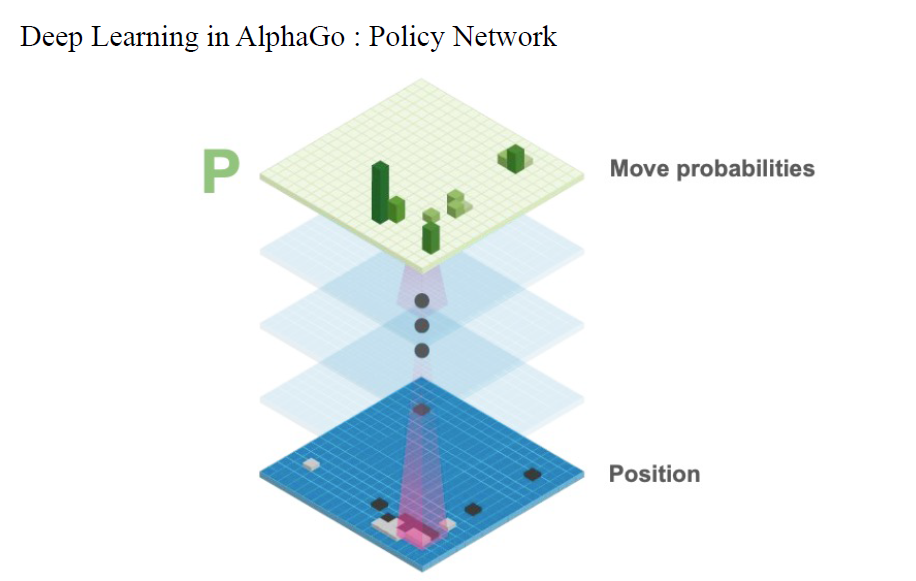
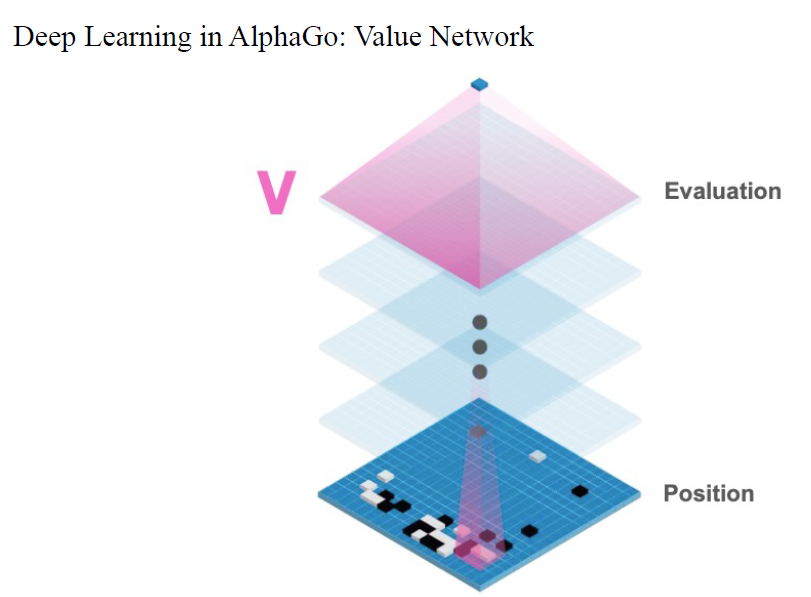
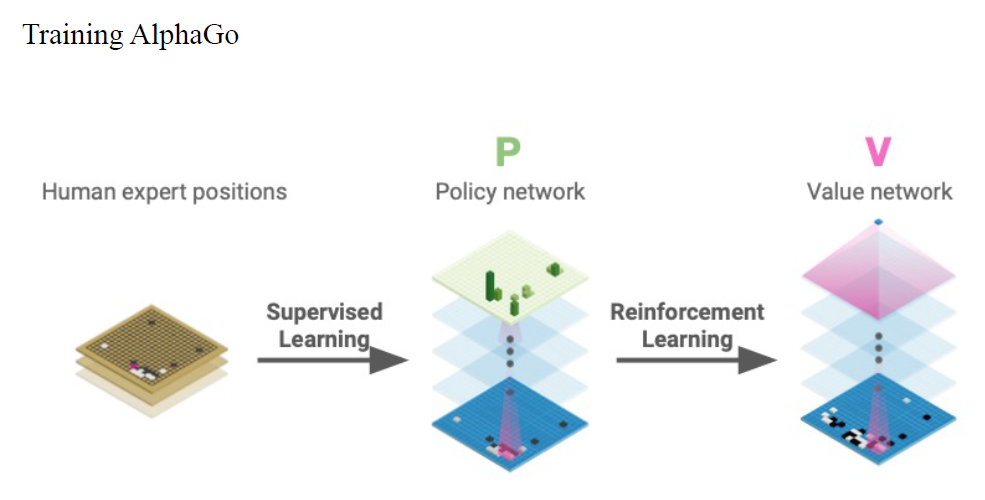
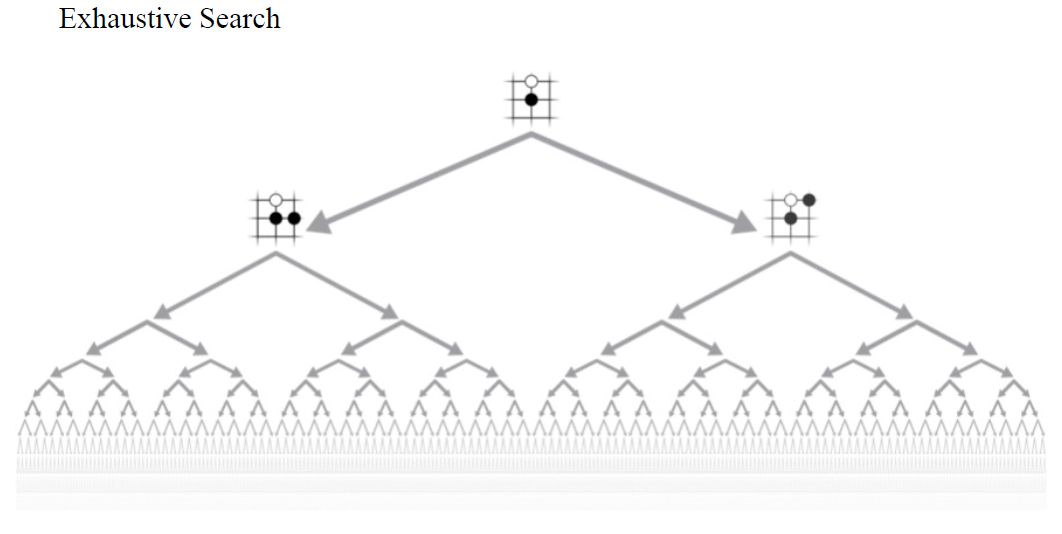
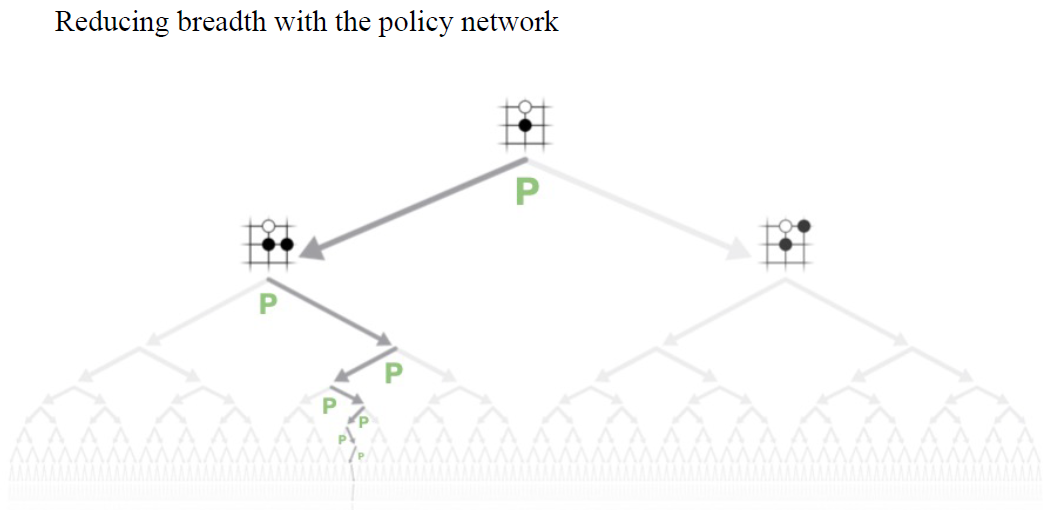
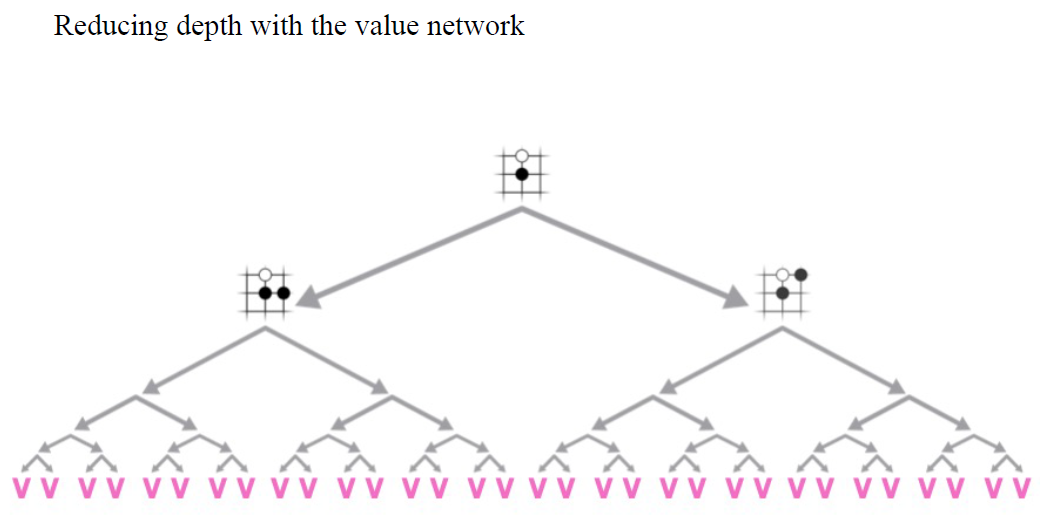

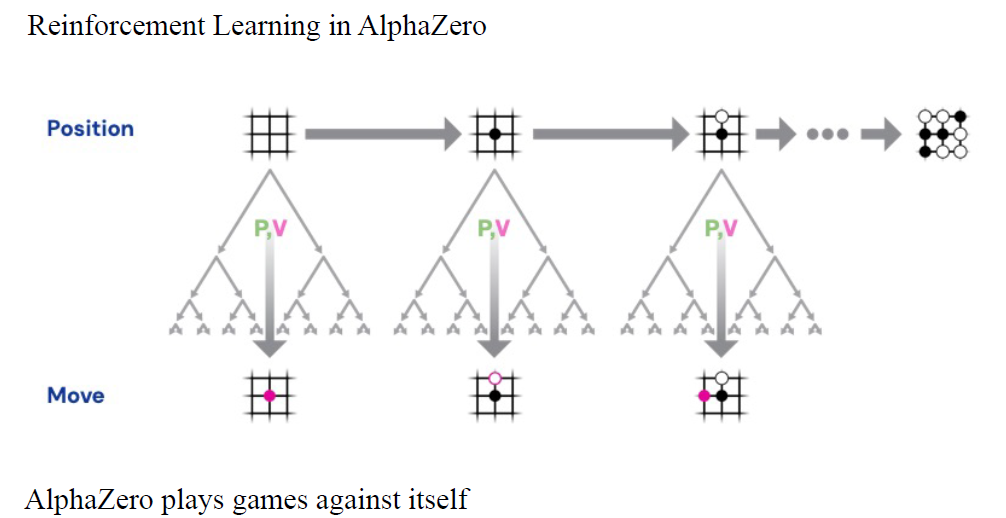
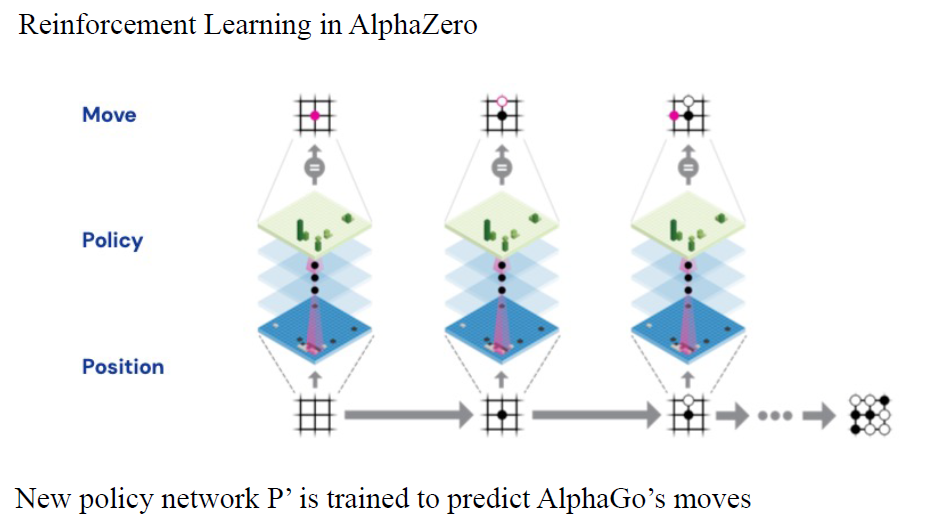
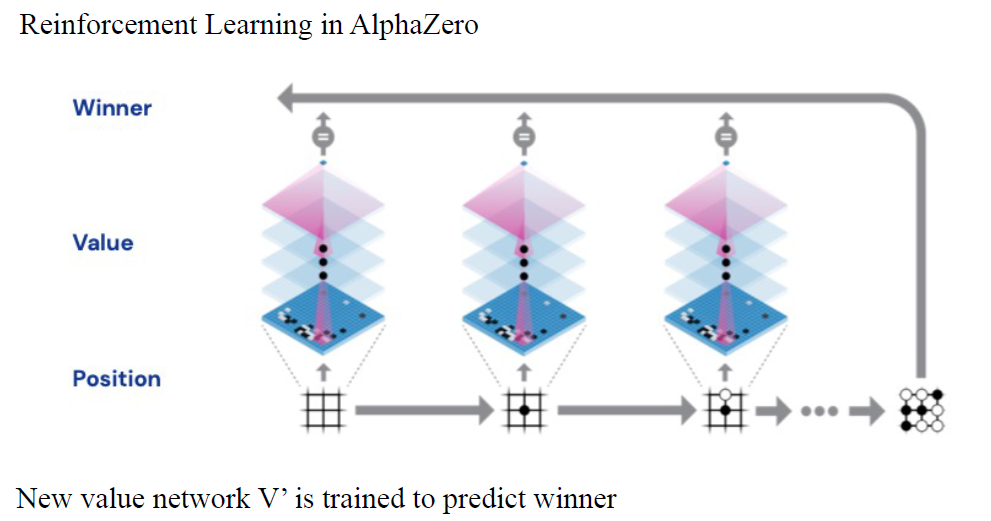
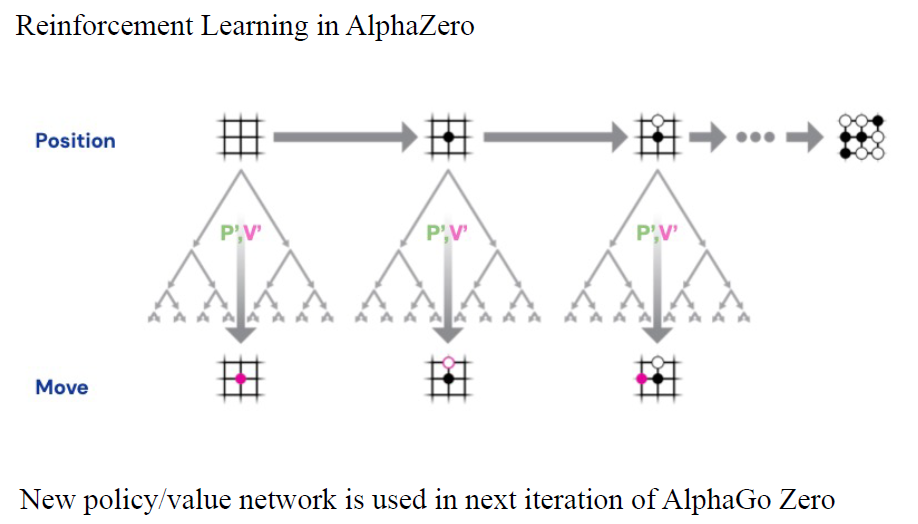

深度学习让我们能够搜索复杂棋类游戏的巨大搜索空间
自玩产生了训练深度神经网络所需的大量数据
自我游戏提供了一个自动课程,从简单的对手到越来越强的对手。
系统发现新知识
新方向:学习游戏规则,超过两名玩家,不完善的信息,更大的行动空间等。
RL是一个通用的决策框架
•RL是指具有行为能力的代理人
•每个动作都会影响代理的未来状态
•成功是通过标量奖励信号来衡量的
•目标:选择行动以最大化未来奖励
【RL is a general-purpose framework for decision-making
• RL is for an agent with the capacity to act
• Each action influences the agent’s future state
• Success is measured by a scalar reward signal
• Goal: select actions to maximise future reward】
DL是表征学习的通用框架
•给出一个目标
•学习实现目标所需的表达方式
•直接从原始输入
•使用最小的领域知识
【DL is a general-purpose framework forrepresentation learning
• Given an objective
• Learn representation that is required to achieve objective
• Directly from raw inputs
• Using minimal domain knowledge
】
我们寻求一个能解决任何人工级任务的单一代理
•RL定义目标
•DL给出了机理
•RL + DL =一般智力
【We seek a single agent which can solve anyhuman-level task
• RL defines the objective
• DL gives the mechanism
• RL + DL = general intelligence
】

若有收获,就点个赞吧
0 人点赞
