前言 JUC 下面的相关源码继续往下阅读,这就看到了非阻塞的无界线程安全队列 —— ConcurrentLinkedQueue,来一起看看吧。
介绍
基于链接节点的无界线程安全队列,对元素FIFO(先进先出)进行排序。 队列的头部是队列中最长时间的元素,队列的尾部是队列中最短时间的元素。 在队列的尾部插入新元素,队列检索操作获取队列头部的元素。
当许多线程共享对公共集合的访问 ConcurrentLinkedQueue 是一个合适的选择。 与大多数其他并发集合实现一样,此类不允许使用null元素。
基本使用
public class ConcurrentLinkedQueueTest {public static void main(String[] args) {ConcurrentLinkedQueue<String> queue = new ConcurrentLinkedQueue<String>();// 将指定元素插入此队列的尾部。queue.add("liuzhihang");// 将指定元素插入此队列的尾部。queue.offer("liuzhihang");// 获取但不移除此队列的头,队列为空返回 null。queue.peek();// 获取并移除此队列的头,此队列为空返回 null。queue.poll();}}
源码分析
基本结构

参数介绍
private static class Node<E> {// 节点中的元素volatile E item;// 下一个节点volatile Node<E> next;Node(E item) {UNSAFE.putObject(this, itemOffset, item);}// CAS 的方式设置节点元素boolean casItem(E cmp, E val) {return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);}// 设置下一个节点void lazySetNext(Node<E> val) {UNSAFE.putOrderedObject(this, nextOffset, val);}// CAS 的方式设置下一个节点boolean casNext(Node<E> cmp, Node<E> val) {return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);}// 省略 ……}
在 ConcurrentLinkedQueue 内部含有一个内部类 Node,如上所示,这个内部类用来标识链表中的一个节点,通过代码可以看出,在 ConcurrentLinkedQueue 中的链表为单向链表。
public class ConcurrentLinkedQueue<E> extends AbstractQueue<E>implements Queue<E>, java.io.Serializable {// 其他省略// 头结点private transient volatile Node<E> head;// 尾节点private transient volatile Node<E> tail;}
构造函数
public ConcurrentLinkedQueue() {head = tail = new Node<E>(null);}

添加元素
public boolean add(E e) {return offer(e);}public boolean offer(E e) {// 验证是否为空checkNotNull(e);// 创建节点final Node<E> newNode = new Node<E>(e);// 循环入队列// t 是当前尾节点,p 初始为 tfor (Node<E> t = tail, p = t;;) {// q 为尾节点的下一个节点Node<E> q = p.next;if (q == null) {// 为空,说明后面没有节点,则 CAS 设置尾节点if (p.casNext(null, newNode)) {// 此时 p.next 是 newNode// 如果 p != t 说明有并发if (p != t)// 其他线程已经更新了 tail// q = p.next 所以 q == null 不正确了// q 取到了 t.next// 此时将 tail 更新为 新节点casTail(t, newNode); // Failure is OK.return true;}// Lost CAS race to another thread; re-read next}// 多线程情况下, poll ,操作移除元素,可能会导致 p == q// 此时要重新查找else if (p == q)//p = (t != (t = tail)) ? t : head;else// 检查 tail 并更新p = (p != t && t != (t = tail)) ? t : q;}}
画图说明:
- 单线程情况下:
- 当执行到
Node<E> q = p.next;时,当前情况如图所示:

- 判断
q == null,满足条件,此时便会执行p.casNext(null, newNode)使用 CAS 设置 p.next。 - 设置成功之后,
p == t没有变动,所以程序退出。
- 多线程情况下:
- 当执行到
Node<E> q = p.next;时,当前情况如图所示:
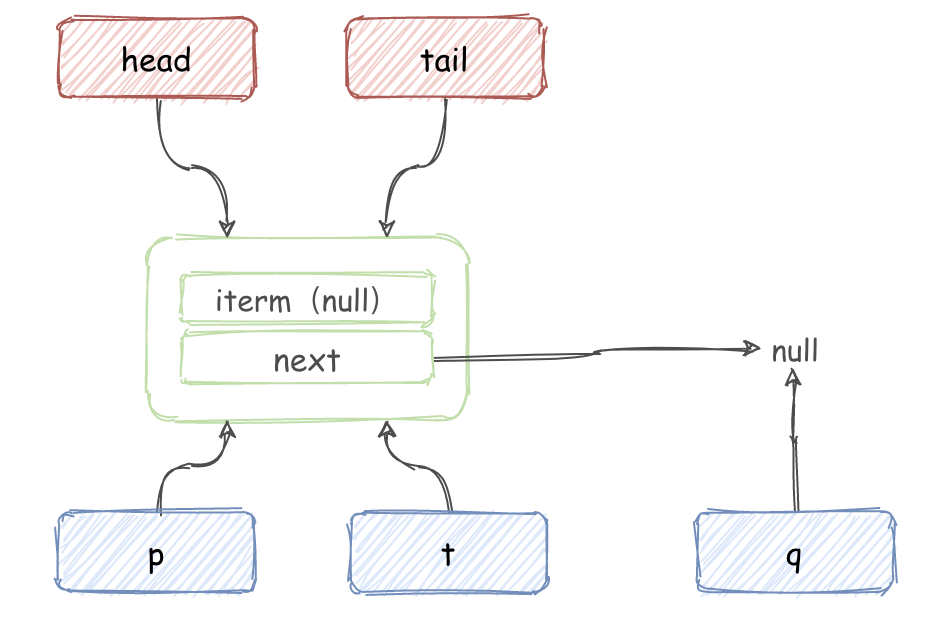
- 多个线程执行
p.casNext(null, newNode)使用 CAS 设置 p.next。 - A 线程 CAS 设置成功:

- B 线程 CAS 执行失败, 重新循环,会执行到
p = (p != t && t != (t = tail)) ? t : q。

-
获取元素
public E poll() {restartFromHead:// 无限循环for (;;) {for (Node<E> h = head, p = h, q;;) {// 头结点的 itermE item = p.item;// 当前节点如果不为 null CAS 设置为 nullif (item != null && p.casItem(item, null)) {// CAS 成功 则标记移除if (p != h) // hop two nodes at a timeupdateHead(h, ((q = p.next) != null) ? q : p);return item;}// 当前队列未空 返回 nullelse if ((q = p.next) == null) {updateHead(h, p);return null;}// 自引用了, 重新进行循环else if (p == q)continue restartFromHead;elsep = q;}}}
画图过程如下:
在执行内层循环时,如果队列为空:
E item = p.item;此时,iterm 为 null,会updateHead(h, p)并返回 null。- 假设同时有并发插入操作,添加了一个元素,此时如图所示:

这时会执行最后的 else 将 p = q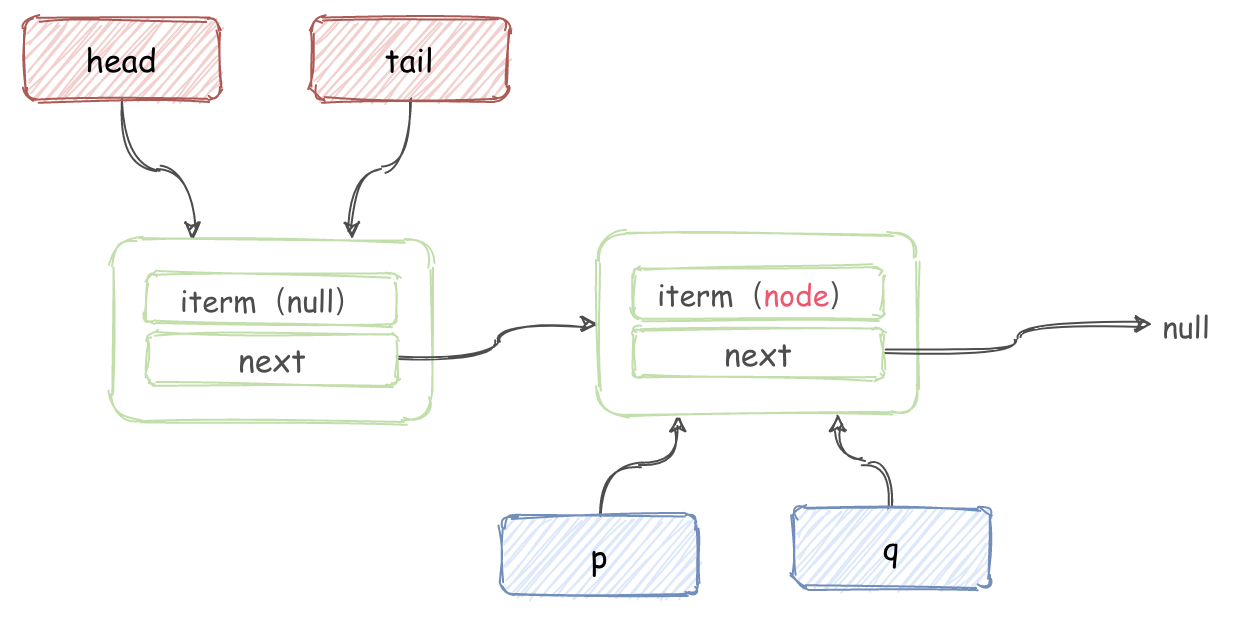
- 继续循环获取 item,并执行
p.casItem(item, null), 然后判断p != h,更新 head 并返回 item。

这里的情况比较复杂,这里只是列举一种,如果需要可以自己多列举几种。
而查看元素的代码和获取元素代码类似就不多介绍了。
size 操作
public int size() {int count = 0;for (Node<E> p = first(); p != null; p = succ(p))if (p.item != null)// Collection.size() spec says to max outif (++count == Integer.MAX_VALUE)break;return count;}
CAS 没有加锁,所以 size 是不准确的。并且 size 会遍历一遍列表,比较耗费性能。
总结
ConcurrentLinkedQueue 在工作中使用的相对较少,所以阅读相关源码的时候也只是大概看了一下,了解常用 API,以及底层原理。
简单总结就是使用单向链表来保存队列元素,内部使用非阻塞的 CAS 算法,没有加锁。所以计算 size 时可能不准确,同样 size 会遍历链表,所以并不建议使用。

若有收获,就点个赞吧
0 人点赞
