在工作中基本上都会使用定时任务,常用的有 Spring 定时框架、Quartz、elastic-job、xxl-job 等。这里说不上框架的好坏,只有适合自己的才是最好的,本文仅从个人角度上谈一谈对定时任务的看法。
单机定时
单机定时我这里分为纯单机版、 固定 IP 版、分布式锁版、单机调度版,下面从这四个角度来谈一谈他们的实现方式以及当时所在的背景。
纯单机版
顾名思义,就是应用都是单体应用,不存在集群,写一个定时任务就可以了,可以是线程定时调度、也可以是 Spring 定时框架用 @Scheduled注解实现。这种方式在单体应用的极为合适,主要是简单方便。
当然也存在他的弊端,那就是如果我的应用是多机部署的,那就会导致并发冲突。出现问题,解决问题,所以下面三种方式应运而生。
固定 IP 版
就是如果事先知道了机器的 IP 地址,并且基本上 IP 地址也不会变化,只需要在代码中写一个判断逻辑,这样 IP 地址不是当前机器的应用,并不会执行定时任务。
大概逻辑如下:
@Componentpublic class ScheduledTask {@Scheduled(cron="0 0 * * * ? *")public void execute() {// 获取当前机器的 IP 地址// 比较配置的 IP 地址和当前机器的 IP 地址是否相同// 不相同直接返回// 相同则继续执行定时任务}}
这种方式可以很完美的避免多台机器同时执行定时任务,也可以稍微进阶一下,就是将指定的 IP 地址用 @Value 注解,然后可以在配置中心比如 Apollo 进行动态修改。
分布式锁版
这种和上面的方式区别不大,只是在中间尝试获取分布式锁,不过需要对分布式锁的时间把握好,一般问题不大,如果一天一次的定时任务,在 Redis 锁它个一天都可以,总不能定时任务也执行一天。当然几分钟一次的也一个意思,合理安排锁的时间就行。在数据库写个标识也可以,都是大同小异。
@Componentpublic class ScheduledTask {@Scheduled(cron="0 0 0 * * ? *")public void execute() {// 尝试获取分布式锁// 获取锁失败,说明别的机器在执行定时任务,直接返回// 获取锁成功,在本机执行定时任务}}
单机调度版
这种方式也很容易理解,定时执行的任务,也是一个接口,我定时去调度一下这个接口就行了。
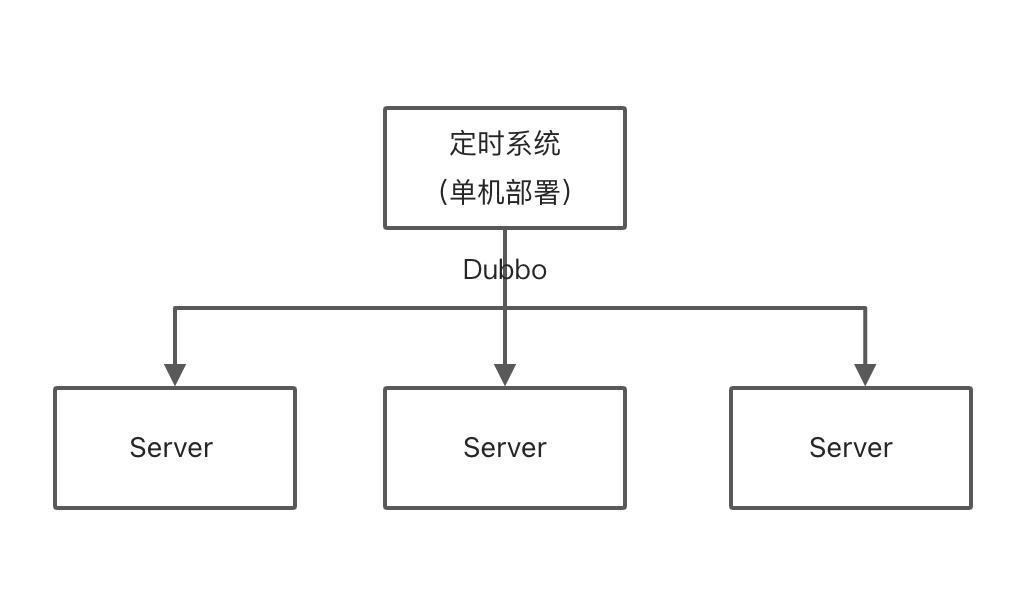
这种方式是完全可以的,定时系统用 Spring 定时框架定时执行,定时系统是单机的,不存在并发,调度到业务系统,可以使用 Dubbo,这里只会有一台机器被调度到。
至于说重复调度了这种极端情况那就另说,不过像查单、补单这种基本不会有啥问题,做个幂等就行。
这种情况也存在弊端,就是定时系统是单机的,如果他挂了怎么办?不用怕,技术还可以继续演进!
分布式调度中间件
单机执行版
分布式调度中间件,相对熟悉一些的就是 xxl-job。图和上面定时系统调度版本区别不大,一般常用的就是将调度任务发到一台机器来执行。基本上使用的都是这种方式,能解决大部分的场景,但是依然存在问题,毕竟咱们的主题是多层分发。
@Component@JobHandler("demoJob")@Slf4jpublic class DemoJob extends IJobHandler {@Overridepublic ReturnT<String> execute(String param) throws Exception {log.info("XXJob 收到调度 ...");try {} catch (Exception e) {log.info("XXJob 调度异常:", e);return FAIL;}return SUCCESS;}}
如果是定时查单,并且 TPS 不是很高的情况下,问题不大,毕竟每分钟改的单量,定时还是可以查的过来的。但是如果换成基金发息或者账务对账那就大不一样了。
因为单机执行定时调度,会花费很久,像基金需要知道昨日金额等等,账务需要对用户交易计算。结果就是可能一个定时任务执行四五个小时,当然一天也有可能。四五个小时还好,毕竟今天能出结果,如果执行一天才出结果,今天的还没算完,明天的交易又来了,并且这个时效性也太差了。
所以就用到了 xxl-job 的分片广播 & 动态分片功能。
分片广播
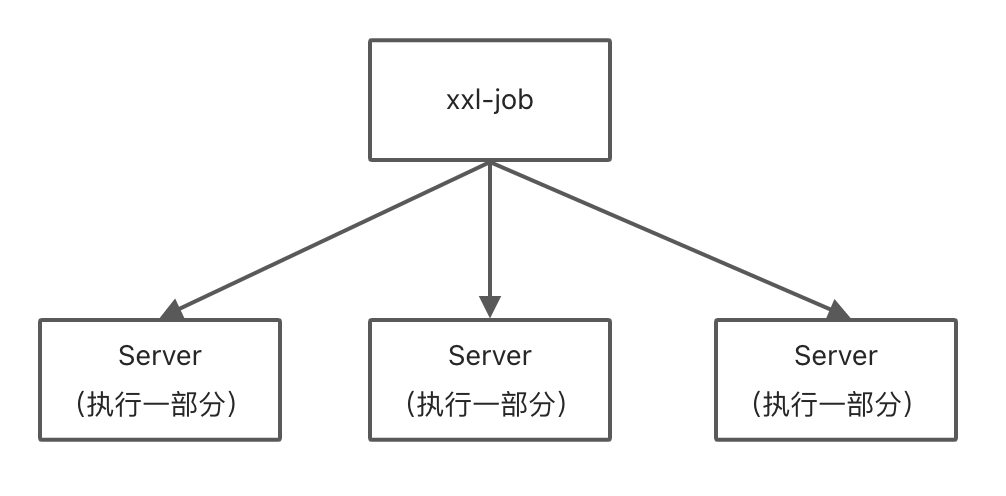
在分片广播场景下,xxl-job 会对当前定时中所有注册的应用发起调度。
按照文档可以使用下面的方式获取当前机器的 shardIndex 和 shardTotal。
👉🏻 文档地址
// 可参考Sample示例执行器中的示例任务"ShardingJobHandler"了解试用int shardIndex = XxlJobHelper.getShardIndex();int shardTotal = XxlJobHelper.getShardTotal();
有人问这种有什么用呢?可以想一下,本来是由单机执行的定时任务,现在变成集群每台机器来执行一部分,这不是充分利用了集群的特征了么?
具体一点可以是:
- 按照 user_id 取模,然后每台机器只执行某些特定用户的定时统计
- 分库分表场景下,一台机器执行一个库的数据统计
多层分发
就像面试题肯定会层层剖析,这时候肯定会问如果发生数据倾斜了怎么办?
具体现象就是如果按照用户来分配机器,取模等于 0 的用户在 shardIndex0 上执行定时,但是这些用户的总交易量占据了 90% 以上,那就会导致另几台的定时咔咔咔一会执行完了,这台机器还在吭哧吭哧的干。那不就没啥用了么?
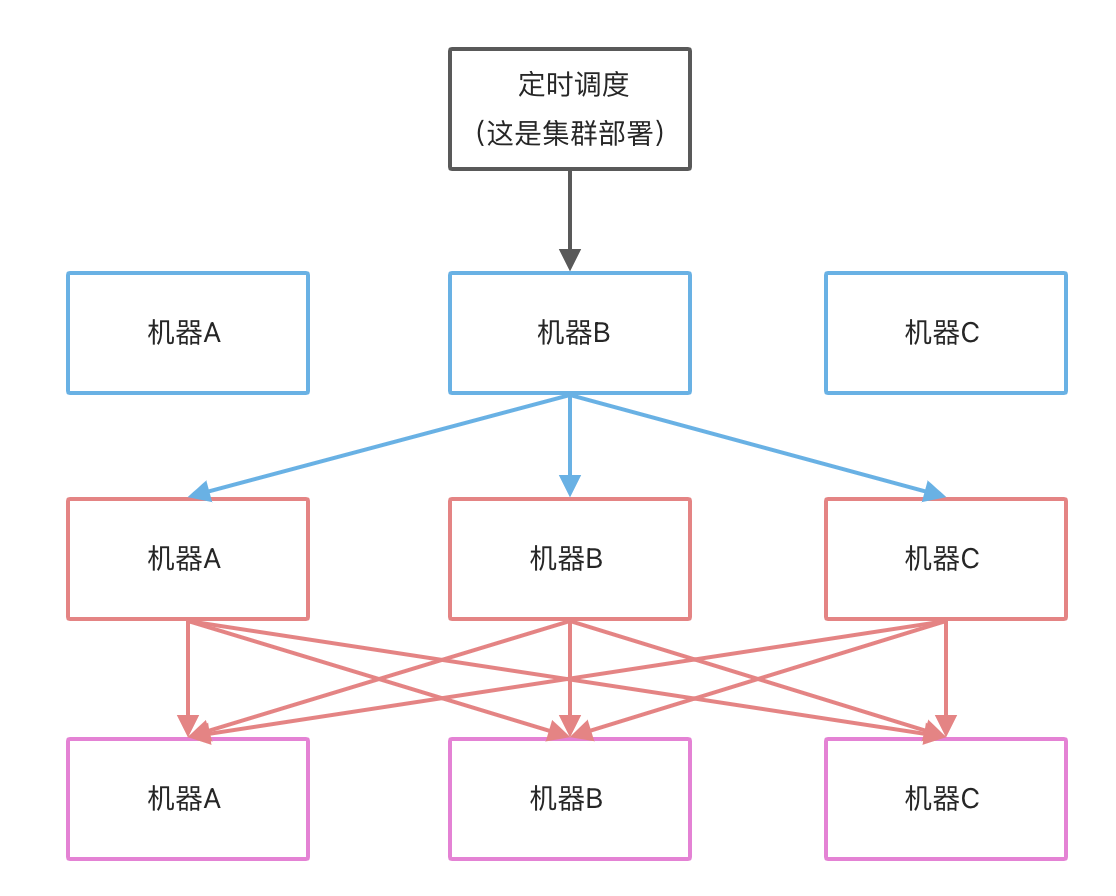
上图只是分发了三层:
- 第一层仅有一台机器收到调度,然后获取所有任务,可以是多少个库,也可以是有多少数据,然后发起 RPC 调用本集群的接口,说你们每次执行这些
- 第二层收到调度,再按照其他维度再分割一次,比如第一次按照用户来分的,第二次则查出来订单,按照订单再分,然后再发送 RPC 调用集群执行接口
- 第三层收到被执行的订单,开始执行具体的任务
理论上是可以多层分发的,最终结果就是让每台机器均匀的执行定时任务,这样可以充分利用每台机器的能力。
总结
其实这个问题是我曾经遇到的面试题,当时还和群友讨论了很久。在实际工作中,这几种也并没有好坏之差,只要适合自己,就够了。

若有收获,就点个赞吧
0 人点赞
