前言
前面已经介绍了主键索引的加锁范围和非主键唯一索引的加锁范围。
主键索引:
- 加锁时,会先给表添加意向锁,IX 或 IS;
- 加锁是如果是多个范围,是分开加了多个锁,每个范围都有锁;(这个可以实践下 id < 20 的情况)
- 主键等值查询,数据存在时,会对该主键索引的值加行锁
X,REC_NOT_GAP; - 主键等值查询,数据不存在时,会对查询条件主键值所在的间隙添加间隙锁
X,GAP; - 主键等值查询,范围查询时情况则比较复杂:
- 8.0.17 版本是前开后闭,而 8.0.18 版本及以后,修改为了
前开后开区间; - 临界
<=查询时,8.0.17 会锁住下一个 next-key 的前开后闭区间,而 8.0.18 及以后版本,修复了这个 bug。
- 8.0.17 版本是前开后闭,而 8.0.18 版本及以后,修改为了
非主键唯一索引:
- 非主键唯一索引等值查询,数据存在,for update 是会在主键加锁的,而 for share 只有在走覆盖索引的情况下,会仅在自己索引上加锁;
- 非主键索引等值查询,数据不存在,无论是否索引覆盖,相当于一个范围查询,仅仅会在非主键索引上加锁,加的还是间隙锁,前开后开区间;
- 在非主键唯一索引范围查询时,不是覆盖索引的时候,会对相应的范围加前开后闭区间,并且如果存在数据,会对对应的主键加行锁;
- 在非主键唯一索引范围查询时,如果是覆盖索引时,会对所有的后闭区间对应的主键,加行锁;
- 在非主键唯一索引加锁时,还是存在 next-key 锁住下一个区间的 bug。
数据库表数据
CREATE TABLE `t` (`id` int NOT NULL COMMENT '主键',`a` int DEFAULT NULL COMMENT '唯一索引',`c` int DEFAULT NULL COMMENT '普通索引',`d` int DEFAULT NULL,PRIMARY KEY (`id`),UNIQUE KEY `uniq_a` (`a`),KEY `idx_c` (`c`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
数据库数据如下: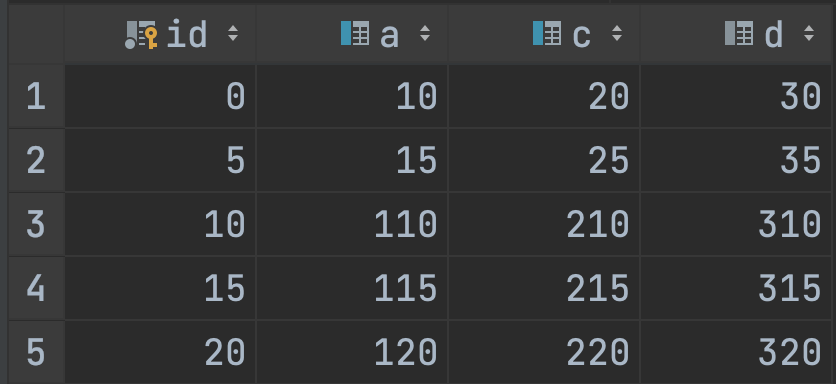
思路和非主键唯一索引相同,只不过唯一的区别是这里看的是 c 和 d 字段。
因为前面小伙伴对 data_locks 应该有了一定的了解,这里就直接分析 data_locks 的数据信息。
普通索引
普通索引等值查询 —— 数据存在
mysql> begin; select * from t where c = 210 for update;

直接分析 data_locks
- 表意向锁;
- 索引 idx_c 上添加了 210 区间的前开后闭锁;
- 索引 idx_c 上添加了 215 区间的间隙锁,LOCK_MODE 为
X,GAP; - 主键上添加了 15 的行锁 ,LOCK_MODE 为
X,REC_NOT_GAP。

主要是因为普通索引不能唯一锁定一条记录,所以要锁定该字段的前后范围。
普通索引等值查询 —— 数据不存在
mysql> begin; select * from t where c = 211 for update;

直接分析 data_locks
- 表意向锁;
- 索引 idx_c 上添加了 215 区间的间隙锁。

分析是因为数据不存在,只需要锁住 215 间隙就可以了,因为 215 和 210 肯定不属于这个范围。
普通索引范围查询
mysql> begin; select * from t where c > 210 and c <= 215 for update;

对于锁住 idx_c 索引的 215 的前开后闭区间是可以理解的,但是锁住了 220 就不太理解了,应该也是那个 bug 没有完全修复。
普通字段
普通字段就更好理解了。
对普通字段而言,无论是哪个查询,都需要扫描全部记录,所以这个锁直接加在了主键上,并且是锁住全部的区间。
总结
本文在基于第一篇和第二篇的基础上,直接通过分析 data_locks 的信息,进行判断加锁范围。
select * from performance_schema.data_locks;
| LOCK_MODE | LOCK_DATA | 锁范围 |
|---|---|---|
| X,REC_NOT_GAP | 15 | 15 那条数据的行锁 |
| X,GAP | 15 | 15 那条数据之前的间隙,不包含 15 |
| X | 15 | 15 那条数据的间隙,包含 15 |
LOCK_MODE = X是前开后闭区间;X,GAP是前开后开区间(间隙锁);X,REC_NOT_GAP行锁。
普通索引

若有收获,就点个赞吧
0 人点赞
