数据复制指的是通过互联网在多台机器上保存副本,目的是:
- 使数据在地理位置上更接近用户,降低延迟访问。
- 当部分组件故障时,仍然可用,提高系统可用性。
- 提供更多的数据读服务,提高吞吐量。
复制的三种方案
几乎所有的数据复制,都绕不开这三种方案:
- 主从复制
- 多主节点复制
- 无主节点复制
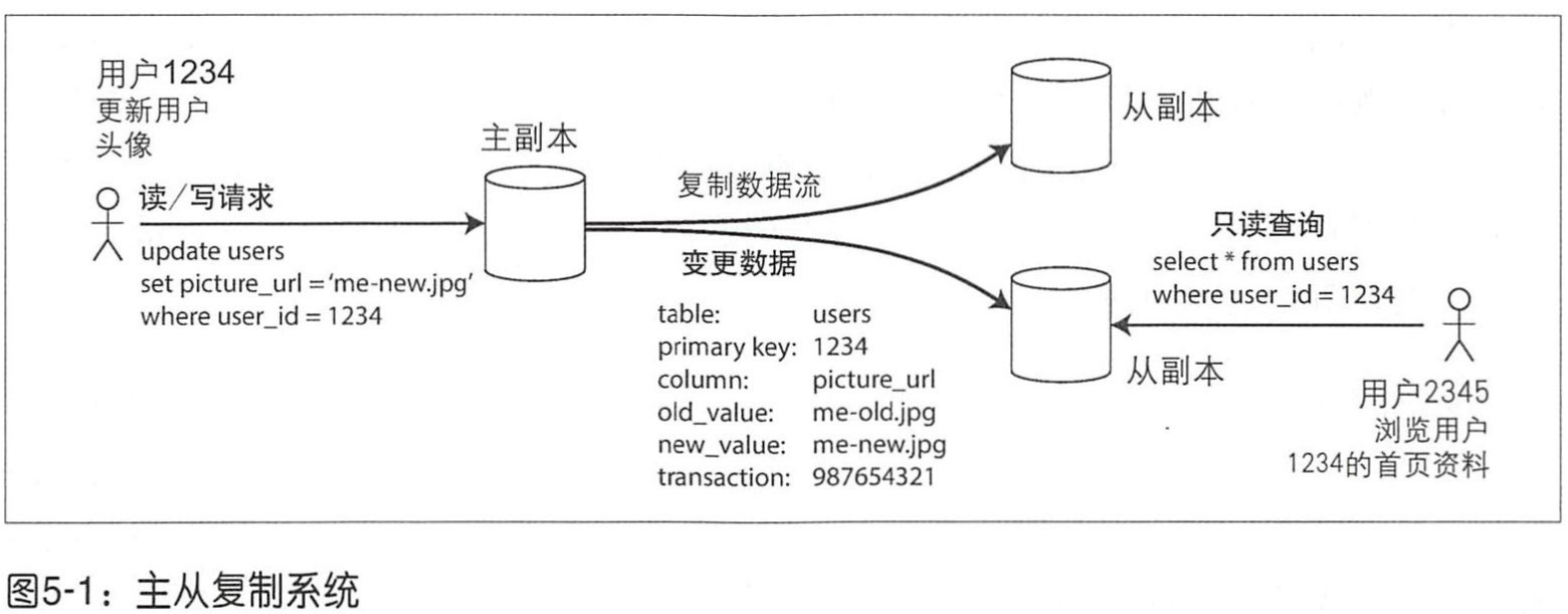
主节点与从节点
主从复制的三个步骤:
- 主节点接受写请求,先把数据写到主节点中
- 然后主节点把数据复制给其它从节点,且写入顺序和主节点保持一致
- 只要主节点才可以支持写请求,从节点只能提供读服务
同步复制与异步复制
同步复制的优点:一旦确认,可以保证和主节点的数据是一致的。缺点是,只要从节点无法完成确认,那么会阻塞其它的从节点。
异步复制的优点:任何一个节点都可以响应请求,吞吐量好。缺点是,你不能保证数据被持久化,即使发起了同步请求。
新加入的节点如何保持数据一致性
简单的复制一份数据是不够的,因为数据还在不断的写入。
一种做法是,先从主节点拷贝一份数据,然后设置这份数据的末位置索引,后面再这个索引中开始继续追加。
复制日志的实现
基于语句的复制
也就是从节点或执行主节点的 insert,update 等 SQL 语句。
基于预写日志的复制
基于行的逻辑日志复制
这种复制日志称为逻辑日志,逻辑日志通用性好。MySQL 建议设置使用这种模式。
无主节点复制
这种也成为去中心化,没有主节点,也就是任何一个节点都可以进行读请求。客户端会像多个节点发起写请求,有些可能成功,有些可能失败。成功的大于失败的,则认为此次写成功,再读取数据时,根据数据的版本号来判断当前数据是不是过期数据。然后将新的数据更新到过期的节点中。

若有收获,就点个赞吧
0 人点赞
