参考链接:
https://www.cnblogs.com/shengguorui/p/10695646.html
https://baijiahao.baidu.com/s?id=1645429373049393021&wfr=spider&for=pc
https://www.cnblogs.com/moodlxs/p/10345989.html
https://www.jianshu.com/p/50b1e3f847b5
前言
B+树索引是B+树在数据库中的一种实现,是最常见也是数据库中使用最为频繁的一种索引。B+树中的B代表平衡(balance),而不是二叉(binary),因为B+树是从最早的平衡二叉树演化而来的。在讲B+树之前必须先了解二叉查找树、平衡二叉树(AVLTree)和平衡多路查找树(B-Tree),B+树即由这些树逐步优化而来。
二叉查找树
【性质】:左子树的键值小于根的键值,右子树的键值大于根的键值。
比如: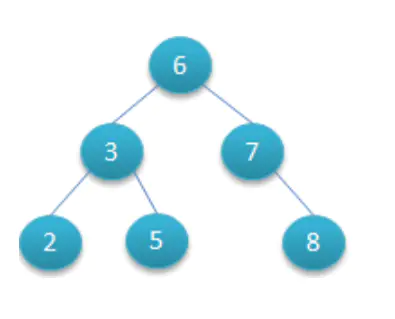
二叉查找树
这样的设计是为了提高查找效率,但是在某些构造条件下,二叉查找树会退化成近似链表的结构,从而丧失了其优势。
比如,同样是2,3,5,6,7,8这六个数字,也可以按照下图的方式来构造: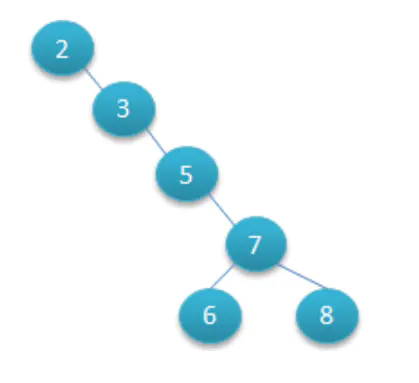
退化的二叉查找树
为了解决二叉查找树退化近似链表的不足,又引入了平衡二叉树的概念。
平衡查找树
【性质】
(1)从任何一个节点出发,左右子树深度之差的绝对值不超过1。
(2)左右子树仍然为平衡二叉树。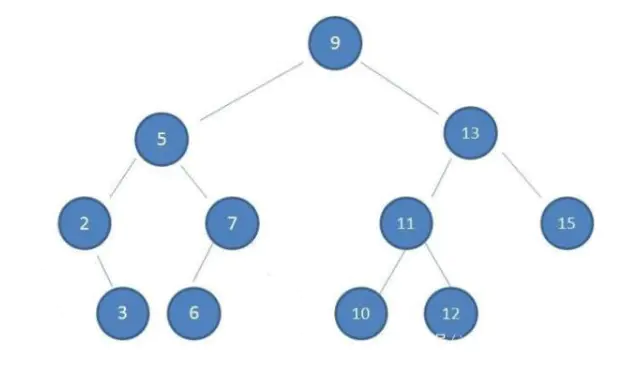
平衡查找树
为了维持平衡查找树的特性,插入数据后往往需要自我调整。
如果在那种插入、删除很频繁的场景中,平衡树需要频繁着进行调整,这会使平衡树的性能大打折扣,为了解决这个问题,于是有了红黑树。
红黑树
【性质】
(1)每个节点只有两种颜色:红色和黑色。
(2)根节点是黑色的。
(3)每个叶子节点(NIL)都是黑色的空节点。(叶子节点不存数据)
(4)从根节点到叶子节点,不会出现两个连续的红色节点。(红色节点被黑色节点隔开)
(5)从任何一个节点出发,到叶子节点,这条路径上都有相同数目的黑色节点。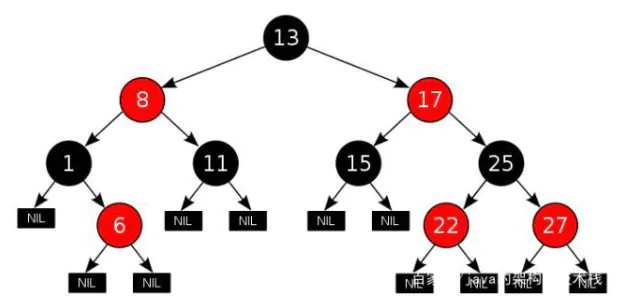
红黑树
【红黑树与平衡二叉树的区别】
1、红黑树放弃了追求完全平衡,追求大致平衡,在与平衡二叉树的时间复杂度相差不大的情况下,保证每次插入最多只需要三次旋转就能达到平衡,实现起来也更为简单。
2、平衡二叉树追求绝对平衡,条件比较苛刻,实现起来比较麻烦,每次插入新节点之后需要旋转的次数不能预知。
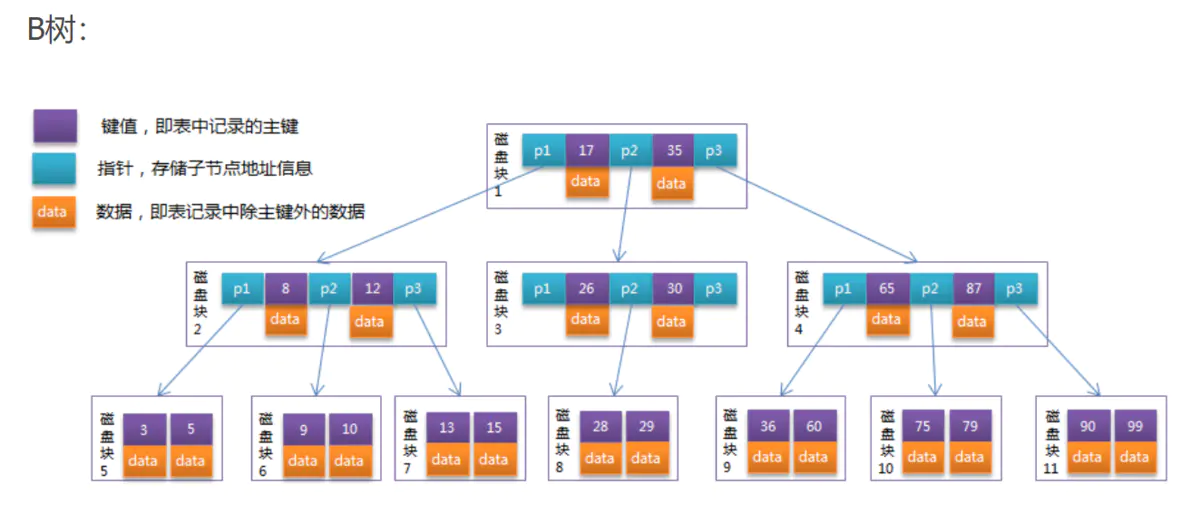
B-Tree
每个节点都存储key和data,所有节点组成这棵树,并且叶子节点指针为null。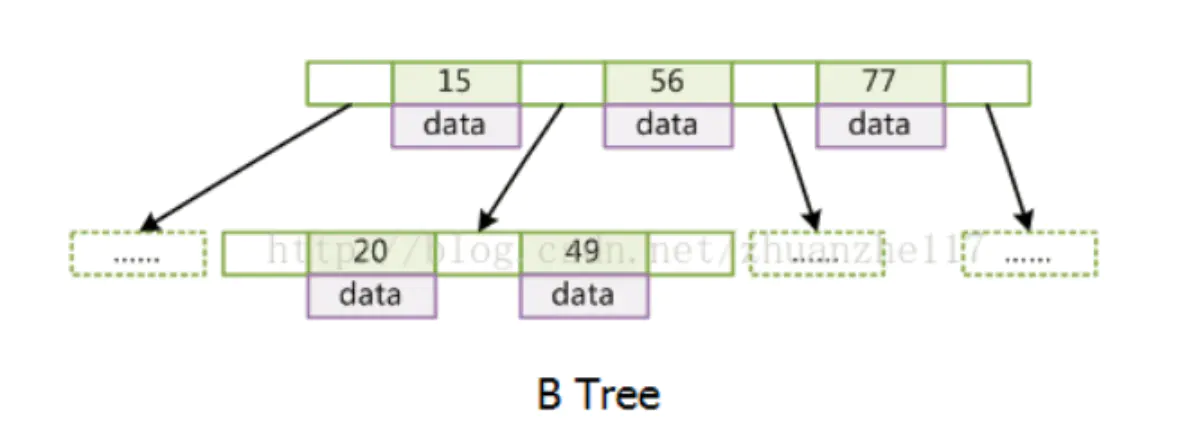
B+Tree
只有叶子节点存储data,叶子节点包含了这棵树的所有键值,叶子节点不存储指针。
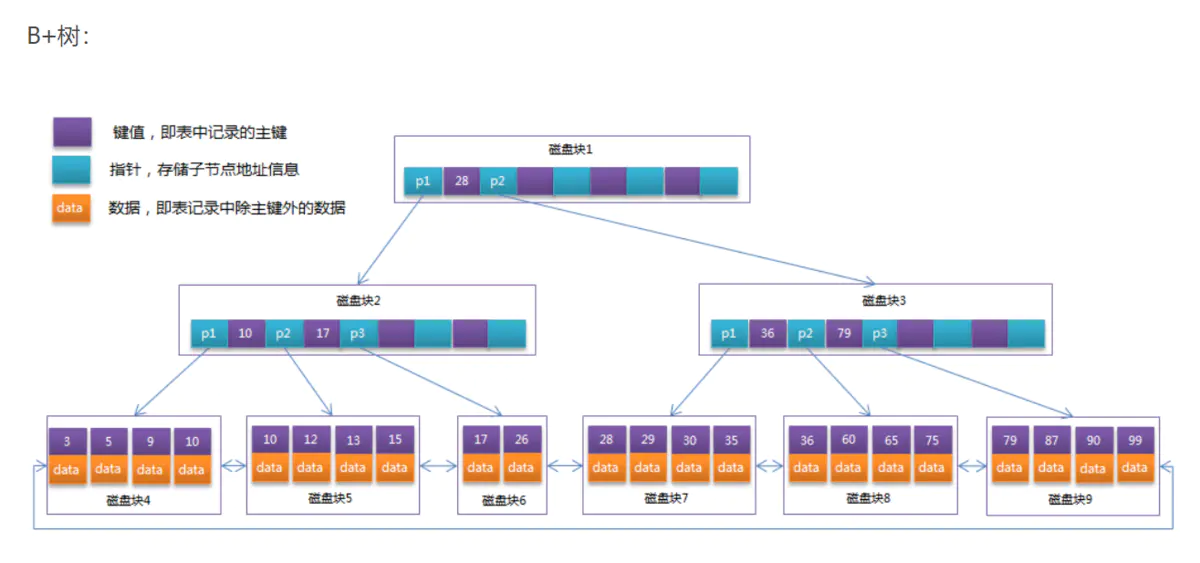
后来,在B+树上增加了顺序访问指针,也就是每个叶子节点增加一个指向相邻叶子节点的指针,这样一棵树成了数据库系统实现索引的首选数据结构。
原因有很多,最主要的是这棵树矮胖,呵呵。一般来说,索引很大,往往以索引文件的形式存储的磁盘上,索引查找时产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的时间复杂度。树高度越小,I/O次数越少。
那为什么是B+树而不是B树呢,因为它内节点不存储data,这样一个节点就可以存储更多的key。
MyISAM
data存的是数据地址。索引是索引,数据是数据。索引放在XX.MYI文件中,数据放在XX.MYD文件中,所以也叫非聚集索引。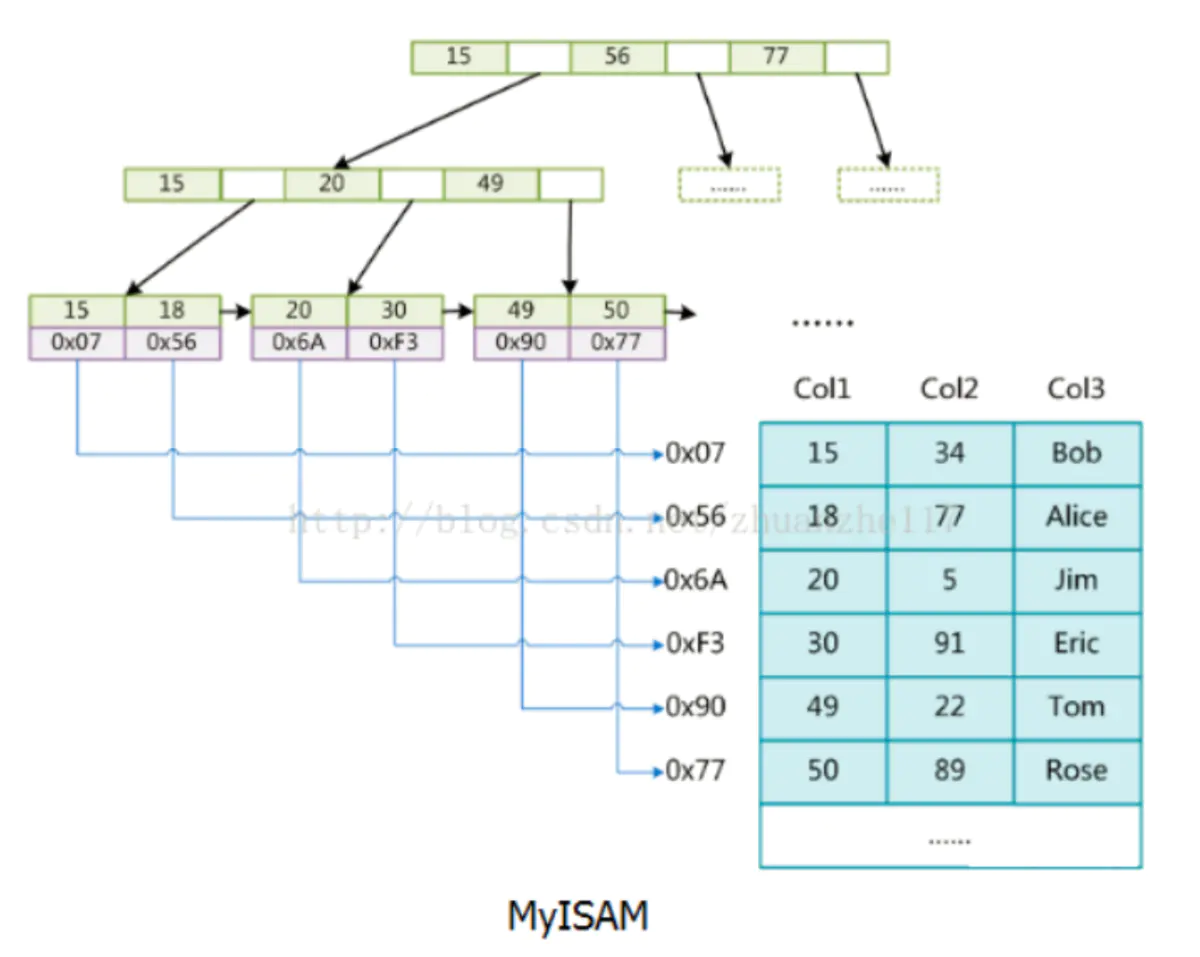
InnoDB
data存的是数据本身。索引也是数据。数据和索引存在一个XX.IDB文件中,所以也叫聚集索引。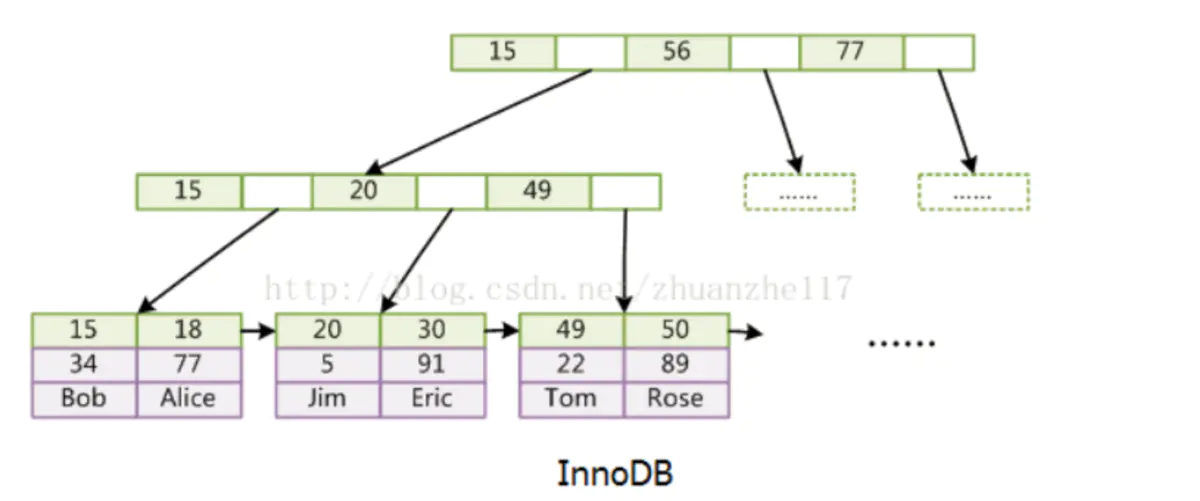
了解了数据结构再看索引,一切都不费解了,只是顺着逻辑推而已。另加两种存储引擎的区别:
1、MyISAM是非事务安全的,而InnoDB是事务安全的
2、MyISAM锁的粒度是表级的,而InnoDB支持行级锁
3、MyISAM支持全文类型索引,而InnoDB不支持全文索引
4、MyISAM相对简单,效率上要优于InnoDB,小型应用可以考虑使用MyISAM
5、MyISAM表保存成文件形式,跨平台使用更加方便
6、MyISAM管理非事务表,提供高速存储和检索以及全文搜索能力,如果在应用中执行大量select操作可选择
7、InnoDB用于事务处理,具有ACID事务支持等特性,如果在应用中执行大量insert和update操作,可选择。
补充1
为什么mysql的索引使用B+树而不是B树呢??
(1)B+树更适合外部存储(一般指磁盘存储),由于内节点(非叶子节点)不存储data,所以一个节点可以存储更多的内节点,每个节点能索引的范围更大更精确。也就是说使用B+树单次磁盘IO的信息量相比较B树更大,IO效率更高。(提高IO效率)
(2)mysql是关系型数据库,经常会按照区间来访问某个索引列,B+树的叶子节点间按顺序建立了链指针,加强了区间访问性,所以B+树对索引列上的区间范围查询很友好。而B树每个节点的key和data在一起,无法进行区间查找。(范围查找更友好)
作者:舒小贱
链接:https://www.jianshu.com/p/0371c9569736
来源:简书

若有收获,就点个赞吧
0 人点赞
