参考:
微信公众号:架构师之路
一分钟了解负载均衡的一切
什么是负载均衡
负载均衡(Load Balance)是分布式系统架构设计中必须考虑的因素之一,它通常是指,将请求/数据【均匀】分摊到多个操作单元上执行,负载均衡的关键在于【均匀】。
常见的负载均衡方案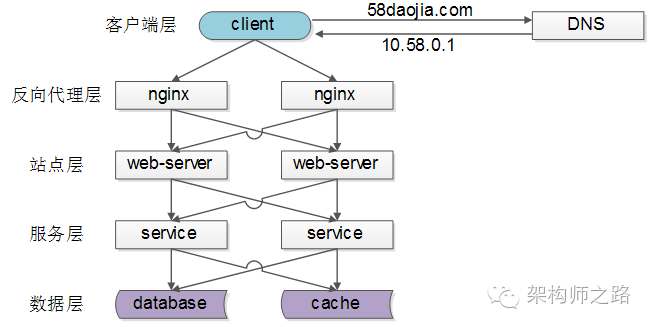
常见互联网分布式架构如上,分为客户端层、反向代理nginx层、站点层、服务层、数据层。可以看到,每一个下游都有多个上游调用,只需要做到,每一个上游都均匀访问每一个下游,就能实现“将请求/数据【均匀】分摊到多个操作单元上执行”。
【客户端层->反向代理层】的负载均衡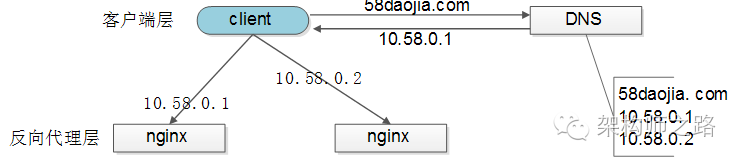
【客户端层】到【反向代理层】的负载均衡,是通过“DNS轮询”实现的:DNS-server对于一个域名配置了多个解析ip,每次DNS解析请求来访问DNS-server,会轮询返回这些ip,保证每个ip的解析概率是相同的。这些ip就是nginx的外网ip,以做到每台nginx的请求分配也是均衡的。
【反向代理层->站点层】的负载均衡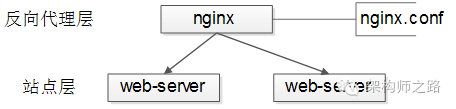
【反向代理层】到【站点层】的负载均衡,是通过“nginx”实现的。通过修改nginx.conf,可以实现多种负载均衡策略:
1)请求轮询:和DNS轮询类似,请求依次路由到各个web-server
2)最少连接路由:哪个web-server的连接少,路由到哪个web-server
3)ip哈希:按照访问用户的ip哈希值来路由web-server,只要用户的ip分布是均匀的,请求理论上也是均匀的,ip哈希均衡方法可以做到,同一个用户的请求固定落到同一台web-server上,此策略适合有状态服务,例如session(58沈剑备注:可以这么做,但强烈不建议这么做,站点层无状态是分布式架构设计的基本原则之一,session最好放到数据层存储)
4)…
【站点层->服务层】的负载均衡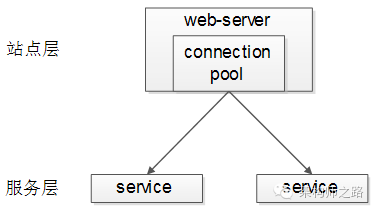
【站点层】到【服务层】的负载均衡,是通过“服务连接池”实现的。
上游连接池会建立与下游服务多个连接,每次请求会“随机”选取连接来访问下游服务。
上一篇文章《RPC-client实现细节》中有详细的负载均衡、故障转移、超时处理的细节描述,欢迎点击link查阅,此处不再展开。
【数据层】的负载均衡
在数据量很大的情况下,由于数据层(db,cache)涉及数据的水平切分,所以数据层的负载均衡更为复杂一些,它分为“数据的均衡”,与“请求的均衡”。
数据的均衡是指:水平切分后的每个服务(db,cache),数据量是差不多的。
请求的均衡是指:水平切分后的每个服务(db,cache),请求量是差不多的。
业内常见的水平切分方式有这么几种:
一、按照range水平切分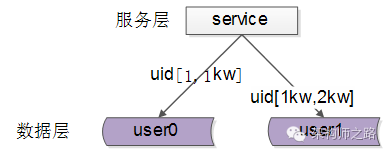
每一个数据服务,存储一定范围的数据,上图为例:
user0服务,存储uid范围1-1kw
user1服务,存储uid范围1kw-2kw
这个方案的好处是:
(1)规则简单,service只需判断一下uid范围就能路由到对应的存储服务
(2)数据均衡性较好
(3)比较容易扩展,可以随时加一个uid[2kw,3kw]的数据服务
不足是:
(1)请求的负载不一定均衡,一般来说,新注册的用户会比老用户更活跃,大range的服务请求压力会更大
二、按照id哈希水平切分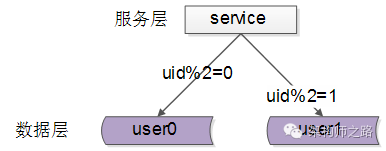
每一个数据服务,存储某个key值hash后的部分数据,上图为例:
user0服务,存储偶数uid数据
user1服务,存储奇数uid数据
这个方案的好处是:
(1)规则简单,service只需对uid进行hash能路由到对应的存储服务
(2)数据均衡性较好
(3)请求均匀性较好
不足是:
(1)不容易扩展,扩展一个数据服务,hash方法改变时候,可能需要进行数据迁移
总结
负载均衡(Load Balance)是分布式系统架构设计中必须考虑的因素之一,它通常是指,将请求/数据【均匀】分摊到多个操作单元上执行,负载均衡的关键在于【均匀】。
(1)【客户端层】到【反向代理层】的负载均衡,是通过“DNS轮询”实现的
(2)【反向代理层】到【站点层】的负载均衡,是通过“nginx”实现的
(3)【站点层】到【服务层】的负载均衡,是通过“服务连接池”实现的
(4)【数据层】的负载均衡,要考虑“数据的均衡”与“请求的均衡”两个点,常见的方式有“按照范围水平切分”与“hash水平切分”
lvs为何不能完全替代DNS轮询
上一篇文章“一分钟了解负载均衡的一切”引起了不少同学的关注,评论中大家争论的比较多的一个技术点是接入层负载均衡技术,部分同学持这样的观点:
1)nginx前端加入lvs和keepalived可以替代“DNS轮询”
2)F5能搞定接入层高可用、扩展性、负载均衡,可以替代“DNS轮询”
“DNS轮询”究竟是不是过时的技术,是不是可以被其他方案替代,接入层架构技术演进,是本文将要细致讨论的内容。
一、问题域
nginx、lvs、keepalived、f5、DNS轮询,每每提到这些技术,往往讨论的是接入层的这样几个问题:
1)可用性:任何一台机器挂了,服务受不受影响
2)扩展性:能否通过增加机器,扩充系统的性能
3)反向代理+负载均衡:请求是否均匀分摊到后端的操作单元执行
二、上面那些名词都是干嘛的
由于每个技术人的背景和知识域不同,上面那些名词缩写(运维的同学再熟悉不过了),还是花1分钟简单说明一下(详细请自行“百度”):
1)nginx:一个高性能的web-server和实施反向代理的软件
2)lvs:Linux Virtual Server,使用集群技术,实现在linux操作系统层面的一个高性能、高可用、负载均衡服务器
3)keepalived:一款用来检测服务状态存活性的软件,常用来做高可用
4)f5:一个高性能、高可用、负载均衡的硬件设备(听上去和lvs功能差不多?)
5)DNS轮询:通过在DNS-server上对一个域名设置多个ip解析,来扩充web-server性能及实施负载均衡的技术
三、接入层技术演进
【裸奔时代(0)单机架构】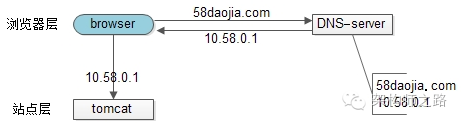
裸奔时代的架构图如上:
1)浏览器通过DNS-server,域名解析到ip
2)浏览器通过ip访问web-server
缺点:
1)非高可用,web-server挂了整个系统就挂了
2)扩展性差,当吞吐量达到web-server上限时,无法扩容
注:单机不涉及负载均衡的问题
【简易扩容方案(1)DNS轮询】
假设tomcat的吞吐量是1000次每秒,当系统总吞吐量达到3000时,如何扩容是首先要解决的问题,DNS轮询是一个很容易想到的方案: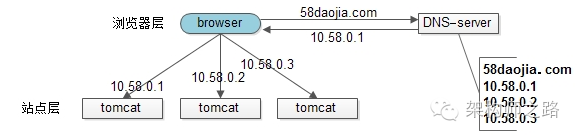
此时的架构图如上:
1)多部署几份web-server,1个tomcat抗1000,部署3个tomcat就能抗3000
2)在DNS-server层面,域名每次解析到不同的ip
优点:
1)零成本:在DNS-server上多配几个ip即可,功能也不收费
2)部署简单:多部署几个web-server即可,原系统架构不需要做任何改造
3)负载均衡:变成了多机,但负载基本是均衡的
缺点:
1)非高可用:DNS-server只负责域名解析ip,这个ip对应的服务是否可用,DNS-server是不保证的,假设有一个web-server挂了,部分服务会受到影响
2)扩容非实时:DNS解析有一个生效周期
3)暴露了太多的外网ip
【简易扩容方案(2)nginx】
tomcat的性能较差,但nginx作为反向代理的性能就强多了,假设线上跑到1w,就比tomcat高了10倍,可以利用这个特性来做扩容: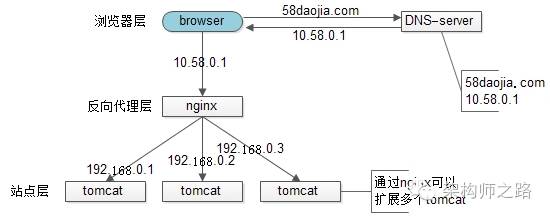
此时的架构图如上:
1)站点层与浏览器层之间加入了一个反向代理层,利用高性能的nginx来做反向代理
2)nginx将http请求分发给后端多个web-server
优点:
1)DNS-server不需要动
2)负载均衡:通过nginx来保证
3)只暴露一个外网ip,nginx->tomcat之间使用内网访问
4)扩容实时:nginx内部可控,随时增加web-server随时实时扩容
5)能够保证站点层的可用性:任何一台tomcat挂了,nginx可以将流量迁移到其他tomcat
缺点:
1)时延增加+架构更复杂了:中间多加了一个反向代理层
2)反向代理层成了单点,非高可用:tomcat挂了不影响服务,nginx挂了怎么办?
【高可用方案(3)keepalived】
为了解决高可用的问题,keepalived出场了(之前的文章“使用shadow-master保证系统可用性”详细介绍过):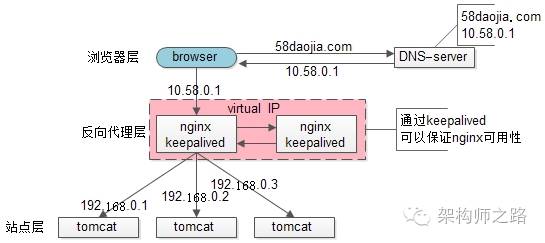
此时:
1)做两台nginx组成一个集群,分别部署上keepalived,设置成相同的虚IP,保证nginx的高可用
2)当一台nginx挂了,keepalived能够探测到,并将流量自动迁移到另一台nginx上,整个过程对调用方透明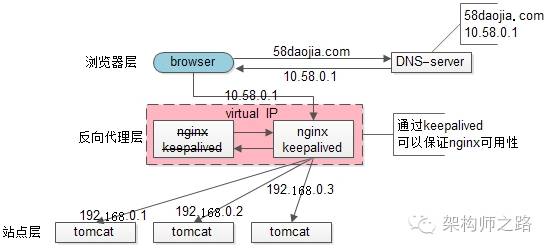
优点:
1)解决了高可用的问题
缺点:
1)资源利用率只有50%
2)nginx仍然是接入单点,如果接入吞吐量超过的nginx的性能上限怎么办,例如qps达到了50000咧?
【scale up扩容方案(4)lvs/f5】
nginx毕竟是软件,性能比tomcat好,但总有个上限,超出了上限,还是扛不住。
lvs就不一样了,它实施在操作系统层面;f5的性能又更好了,它实施在硬件层面;它们性能比nginx好很多,例如每秒可以抗10w,这样可以利用他们来扩容,常见的架构图如下: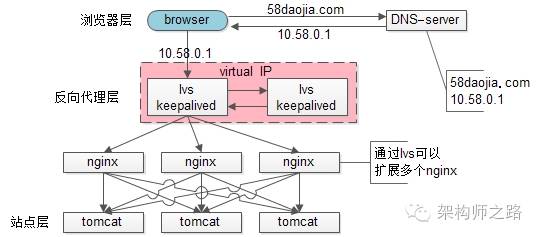
此时:
1)如果通过nginx可以扩展多个tomcat一样,可以通过lvs来扩展多个nginx
2)通过keepalived+VIP的方案可以保证可用性
99.9999%的公司到这一步基本就能解决接入层高可用、扩展性、负载均衡的问题。
这就完美了嘛?还有潜在问题么?
好吧,不管是使用lvs还是f5,这些都是scale up的方案,根本上,lvs/f5还是会有性能上限,假设每秒能处理10w的请求,一天也只能处理80亿的请求(10w秒吞吐量8w秒),那万一*系统的日PV超过80亿怎么办呢?(好吧,没几个公司要考虑这个问题)
【scale out扩容方案(5)DNS轮询】
如之前文章所述,水平扩展,才是解决性能问题的根本方案,能够通过加机器扩充性能的方案才具备最好的扩展性。
facebook,google,baidu的PV是不是超过80亿呢,它们的域名只对应一个ip么,终点又是起点,还是得通过DNS轮询来进行扩容: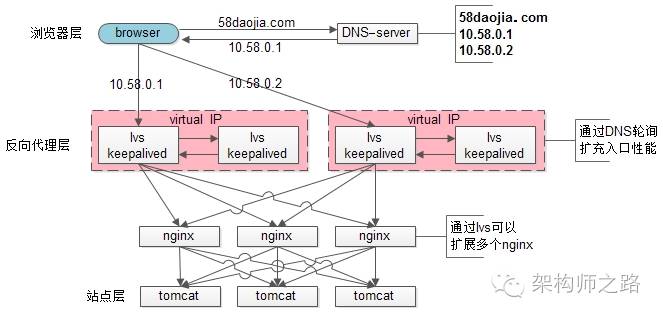
此时:
1)通过DNS轮询来线性扩展入口lvs层的性能
2)通过keepalived来保证高可用
3)通过lvs来扩展多个nginx
4)通过nginx来做负载均衡,业务七层路由
四、结论
聊了这么多,稍微做一个简要的总结:
1)接入层架构要考虑的问题域为:高可用、扩展性、反向代理+扩展均衡
2)nginx、keepalived、lvs、f5可以很好的解决高可用、扩展性、反向代理+扩展均衡的问题
3)水平扩展scale out是解决扩展性问题的根本方案,DNS轮询是不能完全被nginx/lvs/f5所替代的
末了,上一篇文章有同学留言问58到家采用什么方案,58到家目前部署在阿里云上,前端购买了SLB服务(可以先粗暴的认为是一个lvs+keepalived的高可用负载均衡服务),后端是nginx+tomcat。
五、挖坑
接入层讲了这么多,下一章,准备讲讲服务层“异构服务的负载均”(牛逼的机器应该分配更多的流量,如何做到?)。
如何实施异构服务器的负载均衡及过载保护?
零、需求缘起
第一篇文章“一分钟了解负载均衡”和大家share了互联网架构中反向代理层、站点层、服务层、数据层的常用负载均衡方法。
第二篇文章“lvs为何不能完全代替DNS轮询”和大家share了互联网接入层负载均衡需要解决的问题及架构演进。
在这两篇文章中,都强调了“负载均衡是指,将请求/数据【均匀】分摊到多个操作单元上执行,负载均衡的关键在于【均匀】”。
然而,后端的service有可能部署在硬件条件不同的服务器上:
1)如果对标最低配的服务器“均匀”分摊负载,高配的服务器的利用率不足;
2)如果对标最高配的服务器“均匀”分摊负载,低配的服务器可能会扛不住;
能否根据异构服务器的处理能力来动态、自适应进行负载均衡及过载保护,是本文要讨论的问题。
一、service层的负载均衡通常是怎么做的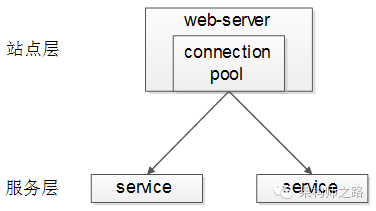
“一分钟了解负载均衡”中提到,service层的负载均衡,一般是通过service连接池来实现的,调用方连接池会建立与下游服务多个连接,每次请求“随机”获取连接,来保证service访问的均衡性。
“RPC-client实现细节”中提到,负载均衡、故障转移、超时处理等细节也都是通过调用方连接池来实现的。
这个调用方连接池能否实现,根据service的处理能力,动态+自适应的进行负载调度呢?
二、通过“静态权重”标识service的处理能力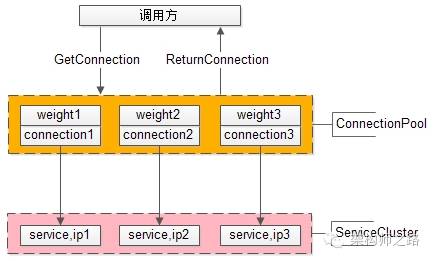
调用方通过连接池组件访问下游service,通常采用“随机”的方式返回连接,以保证下游service访问的均衡性。
要打破这个随机性,最容易想到的方法,只要为每个下游service设置一个“权重”,代表service的处理能力,来调整访问到每个service的概率,例如:
假设service-ip1,service-ip2,service-ip3的处理能力相同,可以设置weight1=1,weight2=1,weight3=1,这样三个service连接被获取到的概率分别就是1/3,1/3,1/3,能够保证均衡访问。
假设service-ip1的处理能力是service-ip2,service-ip3的处理能力的2倍,可以设置weight1=2,weight2=1,weight3=1,这样三个service连接被获取到的概率分别就是2/4,1/4,1/4,能够保证处理能力强的service分别到等比的流量,不至于资源浪费。
使用nginx做反向代理与负载均衡,就有类似的机制。
这个方案的优点是:简单,能够快速的实现异构服务器的负载均衡。
缺点也很明显:这个权重是固定的,无法自适应动态调整,而很多时候,服务器的处理能力是很难用一个固定的数值量化。
三、通过“动态权重”标识service的处理能力
提问:通过什么来标识一个service的处理能力呢?
回答:其实一个service能不能处理得过来,能不能响应得过来,应该由调用方说了算。调用服务,快速处理了,处理能力跟得上;调用服务,处理超时了,处理能力很有可能跟不上了。
动态权重设计
1)用一个动态权重来标识每个service的处理能力,默认初始处理能力相同,即分配给每个service的概率相等;
2)每当service成功处理一个请求,认为service处理能力足够,权重动态+1
3)每当service超时处理一个请求,认为service处理能力可能要跟不上了,权重动态-10(权重下降会更快)
4)为了方便权重的处理,可以把权重的范围限定为[0, 100],把权重的初始值设为60分
举例说明:
假设service-ip1,service-ip2,service-ip3的动态权重初始值weight1=weight2=weight3=60,刚开始时,请求分配给这3台service的概率分别是60/180,60/180,60/180,即负载是均衡的。
随着时间的推移,处理能力强的service成功处理的请求越来越多,处理能力弱的service偶尔有超时,随着动态权重的增减,权重可能变化成了weight1=100,weight2=60,weight3=40,那么此时,请求分配给这3台service的概率分别是100/200,60/200,40/200,即处理能力强的service会被分配到更多的流量。
四、过载保护
提问:什么是过载保护?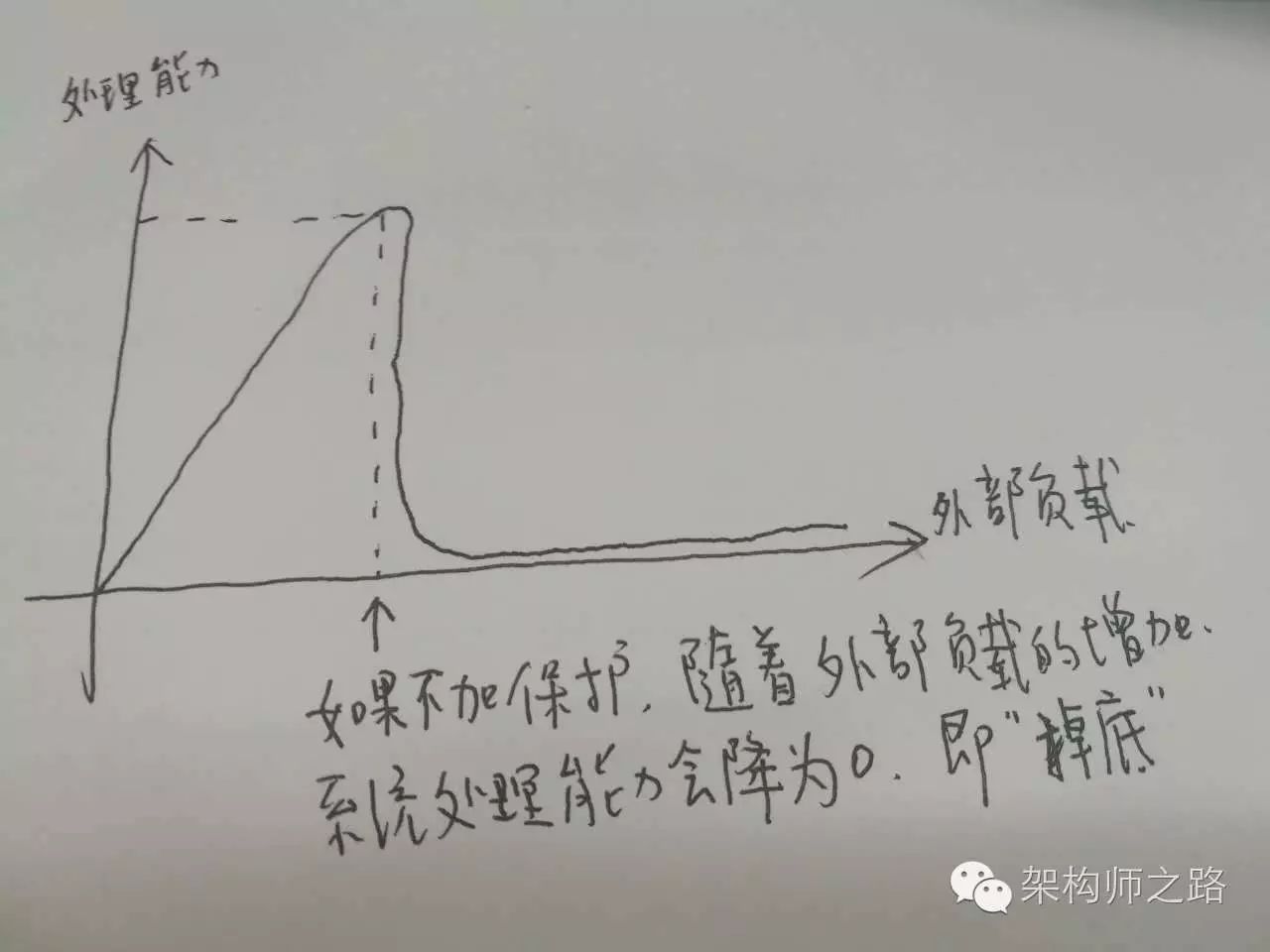
图示:无过载保护的负载与处理能力图(会掉底)
回答:互联网软件架构设计中所指的过载保护,是指当系统负载超过一个service的处理能力时,如果service不进行自我保护,可能导致对外呈现处理能力为0,且不能自动恢复的现象。而service的过载保护,是指即使系统负载超过一个service的处理能力,service让能保证对外提供有损的稳定服务。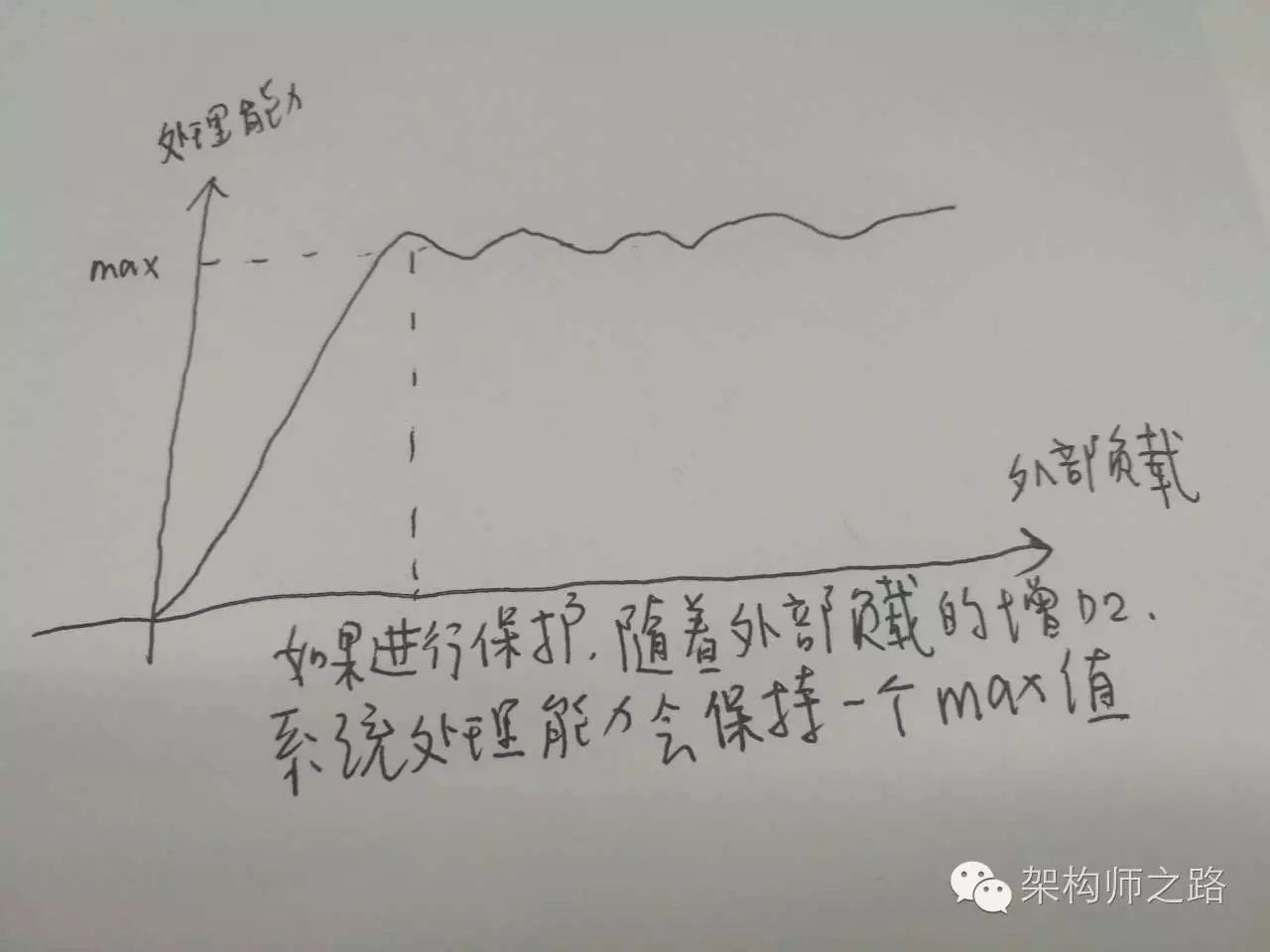
图示:有过载保护的负载与处理能力图(不会掉底)
提问:如何进行过载保护?
回答:最简易的方式,服务端设定一个负载阈值,超过这个阈值的请求压过来,全部抛弃。这个方式不是特别优雅。
五、如何借助“动态权重”来实施过载保护
动态权重是用来标识每个service的处理能力的一个值,它是RPC-client客户端连接池层面的一个东东。服务端处理超时,客户端RPC-client连接池都能够知道,这里只要实施一些策略,就能够对“疑似过载”的服务器进行降压,而不用服务器“抛弃请求”这么粗暴的实施过载保护。
应该实施一些什么样的策略呢,例如:
1)如果某一个service的连接上,连续3个请求都超时,即连续-10分三次,客户端就可以认为,服务器慢慢的要处理不过来了,得给这个service缓一小口气,于是设定策略:接下来的若干时间内,例如1秒(或者接下来的若干个请求),请求不再分配给这个service;
2)如果某一个service的动态权重,降为了0(像连续10个请求超时,中间休息了3次还超时),客户端就可以认为,服务器完全处理不过来了,得给这个service喘一大口气,于是设定策略:接下来的若干时间内,例如1分钟(为什么是1分钟,根据经验,此时service一般在发生fullGC,差不多1分钟能回过神来),请求不再分配给这个service;
3)可以有更复杂的保护策略…
这样的话,不但能借助“动态权重”来实施动态自适应的异构服务器负载均衡,还能在客户端层面更优雅的实施过载保护,在某个下游service快要响应不过来的时候,给其喘息的机会。
需要注意的是:要防止客户端的过载保护引起service的雪崩,如果“整体负载”已经超过了“service集群”的处理能力,怎么转移请求也是处理不过来的,还得通过抛弃请求来实施自我保护。
六、总结
1)service的负载均衡、故障转移、超时处理通常是RPC-client连接池层面来实施的
2)异构服务器负载均衡,最简单的方式是静态权重法,缺点是无法自适应动态调整
3)动态权重法,可以动态的根据service的处理能力来分配负载,需要有连接池层面的微小改动
4)过载保护,是在负载过高时,service为了保护自己,保证一定处理能力的一种自救方法
5)动态权重法,还可以用做service的过载保护
单点系统架构的可用性与性能优化
一、需求缘起
明明架构要求高可用,为何系统中还会存在单点?
回答:单点master的设计,会大大简化系统设计,何况有时候避免不了单点
在哪些场景中会存在单点?先来看一下一个典型互联网高可用架构。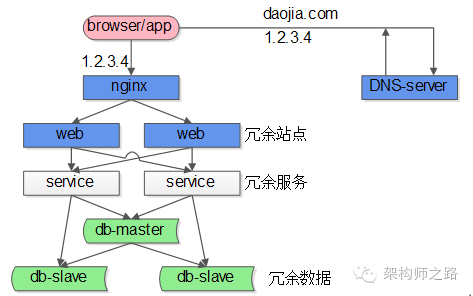
典型互联网高可用架构:
(1)客户端层,这一层是浏览器或者APP,第一步先访问DNS-server,由域名拿到nginx的外网IP
(2)负载均衡层,nginx是整个服务端的入口,负责反向代理与负载均衡工作
(3)站点层,web-server层,典型的是tomcat或者apache
(4)服务层,service层,典型的是dubbo或者thrift等提供RPC调用的后端服务
(5)数据层,包含cache和db,典型的是主从复制读写分离的db架构
在这个互联网架构中,站点层、服务层、数据库的从库都可以通过冗余的方式来保证高可用,但至少
(1)nginx层是一个潜在的单点
(2)数据库写库master也是一个潜在的单点
再举一个GFS(Google File System)架构的例子。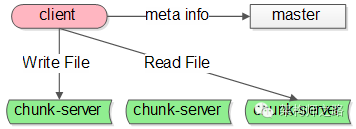
GFS的系统架构里主要有这么几种角色:
(1)client,就是发起文件读写的调用端
(2)master,这是一个单点服务,它有全局事业,掌握文件元信息
(3)chunk-server,实际存储文件额服务器
这个系统里,master也是一个单点的服务,Map-reduce系统里也有类似的全局协调的master单点角色。
系统架构设计中,像nginx,db-master,gfs-master这样的单点服务,会存在什么问题,有什么方案来优化呢,这是本文要讨论的问题。
二、单点架构存在的问题
单点系统一般来说存在两个很大的问题:
(1)非高可用:既然是单点,master一旦发生故障,服务就会受到影响
(2)性能瓶颈:既然是单点,不具备良好的扩展性,服务性能总有一个上限,这个单点的性能上限往往就是整个系统的性能上限
接下来,就看看有什么优化手段可以优化上面提到的两个问题
三、shadow-master解决单点高可用问题
shadow-master是一种很常见的解决单点高可用问题的技术方案。
“影子master”,顾名思义,服务正常时,它只是单点master的一个影子,在master出现故障时,shadow-master会自动变成master,继续提供服务。
shadow-master它能够解决高可用的问题,并且故障的转移是自动的,不需要人工介入,但不足是它使服务资源的利用率降为了50%,业内经常使用keepalived+vip的方式实现这类单点的高可用。

以GFS的master为例,master正常时:
(1)client会连接正常的master,shadow-master不对外提供服务
(2)master与shadow-master之间有一种存活探测机制
(3)master与shadow-master有相同的虚IP(virtual-IP)
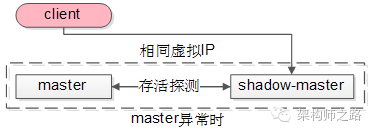
当发现master异常时:
shadow-master会自动顶上成为master,虚IP机制可以保证这个过程对调用方是透明的
除了GFS与MapReduce系统中的主控master,nginx亦可用类似的方式保证高可用,数据库的主库master(主库)亦可用类似的方式来保证高可用,只是细节上有些地方要注意: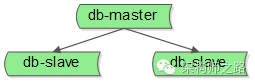
传统的一主多从,读写分离的db架构,只能保证读库的高可用,是无法保证写库的高可用的,要想保证写库的高可用,也可以使用上述的shadow-master机制: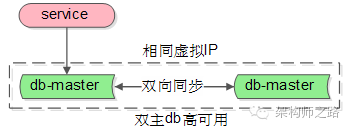
(1)两个主库设置相互同步的双主模式
(2)平时只有一个主库提供服务,言下之意,shadow-master不会往master同步数据
(3)异常时,虚IP漂移到另一个主库,shadow-master变成主库继续提供服务
需要说明的是,由于数据库的特殊性,数据同步需要时延,如果数据还没有同步完成,流量就切到了shadow-master,可能引起小部分数据的不一致。
四、减少与单点的交互,是存在单点的系统优化的核心方向
既然知道单点存在性能上限,单点的性能(例如GFS中的master)有可能成为系统的瓶颈,那么,减少与单点的交互,便成了存在单点的系统优化的核心方向。
怎么来减少与单点的交互,这里提两种常见的方法。
批量写
批量写是一种常见的提升单点性能的方式。
例如一个利用数据库写单点生成做“ID生成器”的例子: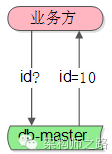
(1)业务方需要ID
(2)利用数据库写单点的auto increament id来生成和返回ID
这是一个很常见的例子,很多公司也就是这么生成ID的,它利用了数据库写单点的特性,方便快捷,无额外开发成本,是一个非常帅气的方案。
潜在的问题是:生成ID的并发上限,取决于单点数据库的写性能上限。
如何提升性能呢?批量写
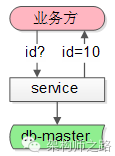
(1)中间加一个服务,每次从数据库拿出100个id
(2)业务方需要ID
(3)服务直接返回100个id中的1个,100个分配完,再访问数据库
这样一来,每分配100个才会写数据库一次,分配id的性能可以认为提升了100倍。
客户端缓存
客户端缓存也是一种降低与单点交互次数,提升系统整体性能的方法。
还是以GFS文件系统为例: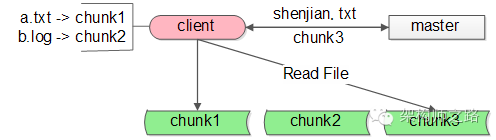
(1)GFS的调用客户端client要访问shenjian.txt,先查询本地缓存,miss了
(2)client访问master问说文件在哪里,master告诉client在chunk3上
(3)client把shenjian.txt存放在chunk3上记录到本地的缓存,然后进行文件的读写操作
(4)未来client要访问文件,从本地缓存中查找到对应的记录,就不用再请求master了,可以直接访问chunk-server。如果文件发生了转移,chunk3返回client说“文件不在我这儿了”,client再访问master,询问文件所在的服务器。
根据经验,这类缓存的命中非常非常高,可能在99.9%以上(因为文件的自动迁移是小概率事件),这样与master的交互次数就降低了1000倍。
五、水平扩展是提升单点系统性能的好方案
无论怎么批量写,客户端缓存,单点毕竟是单机,还是有性能上限的。
想方设法水平扩展,消除系统单点,理论上才能够无限的提升系统系统。
以nginx为例,如何来进行水平扩展呢?
第一步的DNS解析,只能返回一个nginx外网IP么?答案显然是否定的,“DNS轮询”技术支持DNS-server返回不同的nginx外网IP,这样就能实现nginx负载均衡层的水平扩展。

DNS-server部分,一个域名可以配置多个IP,每次DNS解析请求,轮询返回不同的IP,就能实现nginx的水平扩展,扩充负载均衡层的整体性能。
数据库单点写库也是同样的道理,在数据量很大的情况下,可以通过水平拆分,来提升写入性能。
遗憾的是,并不是所有的业务场景都可以水平拆分,例如秒杀业务,商品的条数可能不多,数据库的数据量不大,就不能通过水平拆分来提升秒杀系统的整体写性能(总不能一个库100条记录吧?)。
六、总结
今天的话题就讨论到这里,内容很多,占用大家宝贵的时间深表内疚,估计大部分都记不住,至少记住这几个点吧:
(1)单点系统存在的问题:可用性问题,性能瓶颈问题
(2)shadow-master是一种常见的解决单点系统可用性问题的方案
(3)减少与单点的交互,是存在单点的系统优化的核心方向,常见方法有批量写,客户端缓存
(4)水平扩展也是提升单点系统性能的好方案
集群信息管理,架构设计中最容易遗漏的一环
准备系统性介绍“技术体系规划”了,这是第一篇。
监控平台,服务治理,调用链跟踪,数据收集中心,自动化运维,自动化测试… 很多要讲,却没想好从哪里入手。
讲Z平台,可能需要提前介绍Y服务;讲Y服务,可能需要提前介绍X知识。
思来想去,准备从技术体系里,最容易被遗漏,非常基础,却又非常重要的“集群信息管理”开始介绍。
由于基础,可能部分同学会觉得简单;由于大家所在公司处于不同阶段,所以在实现上会介绍不同阶段的公司应该如何来实现。
还是一如既往的按照“架构师之路”的思路:
- 是什么
- 什么场景,为什么会用到,存在什么问题
- 常见方案及痛点
- 不同阶段公司,不同实现方案
希望大伙有收获。
一、啥是集群?
互联网典型分层架构如下: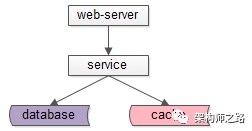
- web-server层
- service层
- db层与cache层
为了保证高可用,每一个站点、服务、数据库、缓存都会冗余多个实例,组成一个分布式的系统,集群则是一个分布式的物理形态。
额,好拗口,通俗的说,集群就是一堆机器,上面部署了提供相似功能的站点,服务,数据库,或者缓存。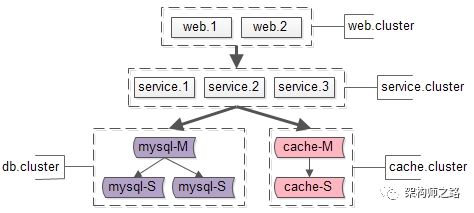
如上图:
- web集群,由web.1和web.2两个实例组成
- service集群,由service.1/service.2/service.3三个实例组成
- db集群,由mysql-M/mysql-S1/mysql-S2三个实例组成
- cache集群,由cache-M/cache-S两个实例组成
与“集群”相对应的是“单机”。
画外音:关于高可用架构,详见文章《究竟啥才是互联网架构“高可用”》。
画外音:缓存如果没有高可用要求,可能是单机架构,而不是集群。
二、集群信息
什么是集群信息?
一个集群,会包含若干信息(额,这tm算什么解释),例如:
- 集群名称
- IP列表
- 二进制目录
- 配置目录
- 日志目录
- 负责人列表
画外音:集群IP列表不建议直接使用IP,而建议使用内网域名,详见文章《小小的IP,大大的耦合》。
什么时候会用到集群信息呢?
很多场景,特别是线上操作,都会使用到各种集群信息,例如:
- 自动化上线
- 监控
- 日志清理
- 二进制与配置的备份
- 下游的调用(额,这个最典型)
这些场景,分别都是如何读取集群信息的?
一般来说,早期会把集群信息写在配置文件里。
例如,自动化上线,有一个配置文件,deploy.user.service.config,其内容是:
name : user.service
ip.list : ip1, ip2, ip3
bin.path : /user.service/bin/
ftp.path : ftp://192.168.0.1/USER_2_0_1_3/user.exe
自动化上线的过程,则是:
- 把可执行文件从ftp拉下来
- 读取集群IP列表
- 读取二进制应该部署的目录
- 把二进制部署到线上
- 逐台重启
画外音:啥,还没有实现自动化脚本部署?还处在运维ssh到线上,手动执行命令,逐台机器人肉部署的刀耕火种阶段?赶紧照着这个方案,做自动化改造吧。
又例如,web-X调用下游的user服务,又有一个配置文件,web-X.config,其内容配置了:
service.name : user.service
service.ip.list : ip1, ip2, ip3
service.port : 8080
web-X调用user服务的过程,则是:
- web-X启动
- web-X读取user服务集群的IP列表与端口
- web-X初始化user服务连接池
- web-X拿取user服务的连接,通过RPC接口调用user服务
日志清理,服务监控,二进制备份的过程,也都与上述类似。
三、存在什么问题?
上述业务场景,对于集群信息的使用,有两个最大的特点:
- 每个应用场景,所需集群信息都不一样(A场景需要集群abc信息,B场景需要集群def信息)
- 每个应用场景,集群信息都写在“自己”的配置文件里
一句话总结:集群信息管理分散化。
这里最大的问题,是耦合,当集群的信息发生变化的时候,有非常多的配置需要修改:
- deploy.user.service.config
- clean.log.user.service.config
- backup.bin.user.service.config
- monitor.config
- web-X.config
- …
这些配置里,user服务集群的信息都需要修改:
- 随着研发、测试、运维人员的流动,很多配置放在哪里,逐步就被遗忘了
- 随着时间的推移,一些配置就被改漏了
- 逐渐的,莫名其妙的问题出现了
画外音:ca,谁痛谁知道
如何解决上述耦合的问题呢?
一句话回答:集群信息管理集中化。
四、如何集中化管理集群信息
如何集中化管理集群配置信息,不同发展阶段的公司,实现的方式不一样。
早期方案
通过全局配置文件,实现集群信息集中管理,举例global.config如下:
[user.service]
ip.list : ip1, ip2, ip3
port : 8080
bin.path : /user.service/bin/
log.path : /user.service/log/
conf.path : /user.service/conf/
ftp.path :ftp://192.168.0.1/USER_2_0_1_3/user.exe
owner.list : shenjian, zhangsan, lisi
[passport.web]
ip.list : ip11, ip22, ip33
port : 80
bin.path : /passport.web/bin/
log.path : /passport.web/log/
conf.path : /passport.web/conf/
ftp.path :ftp://192.168.0.1/PST_1_2_3_4/passport.jar
owner.list : shenjian, zui, shuaiqi
集中维护集群信息之后:
- 任何需要读取集群信息的场景,都从global.config里读取
- 任何集群信息的修改,只需要修改global.config一处
- global.config会部署到任何一台线上机器,维护和管理也很方便
画外音:额,当然,信息太多的话,global.config也要垂直拆分
中期方案
随着公司业务的发展,随着技术团队的扩充,随着技术体系的完善,通过集群信息管理服务,来维护集群信息的诉求原来越强烈。
画外音:慢慢的,配置太多了,通过global.config来修改配置太容易出错了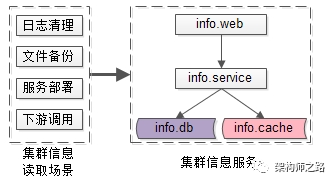
如上图,建立集群信息管理服务:
- info.db :存储集群信息
- info.cache :缓存集群信息
- info.service :提供集群信息访问的RPC接口,以及HTTP接口
- info.web :集群信息维护后台
服务的核心接口是:
Info InfoService::getInfo(String ClusterName);
Bool InfoService::setInfo(String ClusterName, String key, String value);
然后,统一通过服务来获取与修改集群信息:
- 所有需要获取集群信息的场景,都通过info.service提供的接口来读取集群信息
- 所有需要修改集群信息的场景,都通过info.web来操作
长期方案
集群信息服务可以解决大部分的耦合问题,但仍然有一个不足:集群信息变更时,无法反向实时通知关注方,集群信息发生了改变。更长远的,要引入配置中心来解决。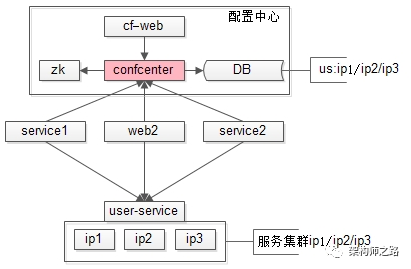
配置中心的细节,网上的分析很多,之前也撰文写过,细节就不再本文展开。
五、总结
集群信息管理,是架构设计中非常容易遗漏的一环,但又是非常基础,非常重要的基础设施,一定要在早期规划好:
- 传统的方式,分散化管理集群信息,容易导致耦合
- 集中管理集群信息,有全局配置,信息服务,配置中心三个阶段
六、调研
调研一、对于集群信息管理,你的感受是:
- ca,没考虑过这个问题,一直是分散式管理
- 在使用全局配置文件
- 在使用信息管理服务
- 在使用配置中心
调研二、对于自动化运维,你的感受是:
- ca,啥是运维,都是研发在线上乱搞
- 有专门的运维,但一直是人肉运维
- 运维在使用脚本,实现了自动化
- 运维都下岗了,在使用平台,实现了平台化

若有收获,就点个赞吧
0 人点赞
