转自 时间轮(TimingWheel)算法总结
通过阅读篇文章您可以很容易理解平时所使用的开源框架是如何进行任务调度的。而且对于以后业务上碰到需要做时间任务调度的需求,也可以尝试着用实践论算法去实现。
一、时间轮的应用
其实早在1987年,时间轮算法的论文已经发布。论文名称:Hashed and Hierarchical Timing Wheels,公众号回复:TimingWheel,获取PDF版本。
时间轮(TimingWheel)算法应用范围非常广泛,各种操作系统的定时任务调度都有用到,我们熟悉的linux crontab,以及Java开发过程中常用的Dubbo、Netty、Akka、Quartz、ZooKeeper 、Kafka等,几乎所有和时间任务调度都采用了时间轮的思想。
二、时间轮算法的作用
时间轮是一种实现延迟功能(定时器)的巧妙算法。如果一个系统存在大量的任务调度,时间轮可以高效的利用线程资源来进行批量化调度。把大批量的调度任务全部都绑定时间轮上,通过时间轮进行所有任务的管理,触发以及运行。能够高效地管理各种延时任务,周期任务,通知任务等。相比于JDK自带的 Timer、DelayQueue + ScheduledThreadPool 来说,时间轮算法是一种非常高效的调度模型。
不过,时间轮调度器的时间精度可能不是很高,对于精度要求特别高的调度任务可能不太适合,后面我们会分享linux高精度任务调度的实现。因为时间轮算法的精度取决于时间段“指针”单元的最小粒度大小,比如时间轮的格子是一秒跳一次,那么调度精度小于一秒的任务就无法被时间轮所调度。
三、时间轮的实现
3.1 如何实现定时任务调度
**
定时的任务调度分两种:
- 一段时间后执行,即:相对时间
- 指定某个确定的时间执行,即:绝对时间
当然,这两者之间是可以相互转换的,例如当前时间是12点,定时在5分钟之后执行,其实绝对时间就是:12:05;定时在12:05执行,相对时间就是5分钟之后执行。
3.2 时间轮的类型
3.2.1 概念
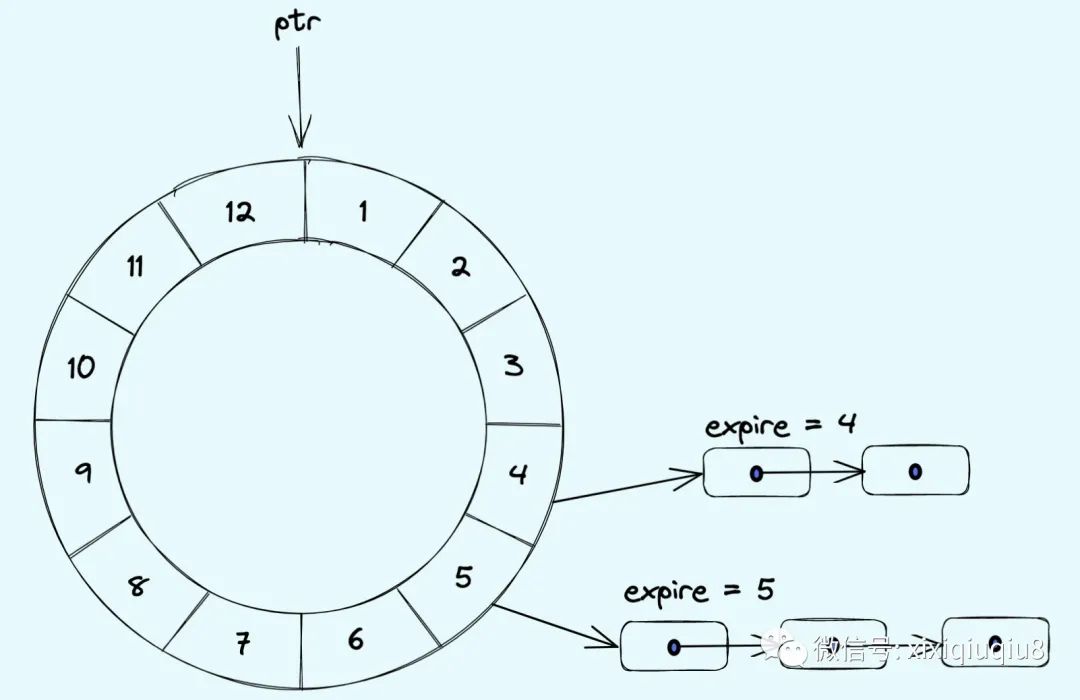
ptr : 指针,随着时间的推移,指针不停地向前移动。
bucket : 时间轮由bucket组成,如上图,有12个bucket。每个bucket都挂载了未来要到期的节点(即: 定时任务)。
slot : 指相邻两个bucket的时间间隔。
jiffy:slot的单位,1s(1HZ),如上图,总共12个bucket,那么两个相邻的bucket的时间间隔就是一秒。
3.2.2 简单的单时间轮
**
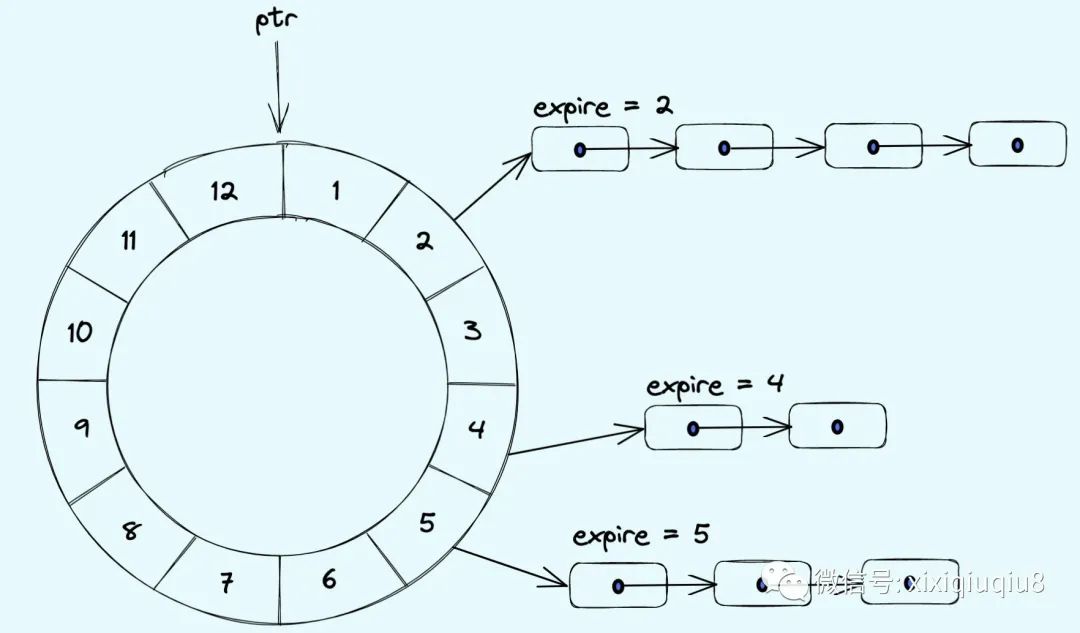
如上图中相邻bucket到期时间的间隔为slot=1s,从0s开始计时,1s时到期的定时任务挂在bucket[1]下,2s时到期的定时任务挂在bucket[2]下,当检查到时间过去了1s时,bucket[1]下所有节点执行超时动作,当时间到了2s时,bucket[2]下所有节点执行超时动作…….以此类推。
上图的时间轮通过数组实现,可以很方便地通过下标定位到定时任务链路,因此,添加、删除、执行定时任务的时间复杂度为O(1)。
这种单时间轮是存在限制的,只能设置定时任务到期时间在12s内的,这显然是无法满足实际的业务需求的。当然也可以通过扩充bucket的范围来实现,例如将bucket设置成 2^32个,但是这样会带来巨大的内存消耗,显然需要优化改进。
3.2.3 改进版单时间轮
**
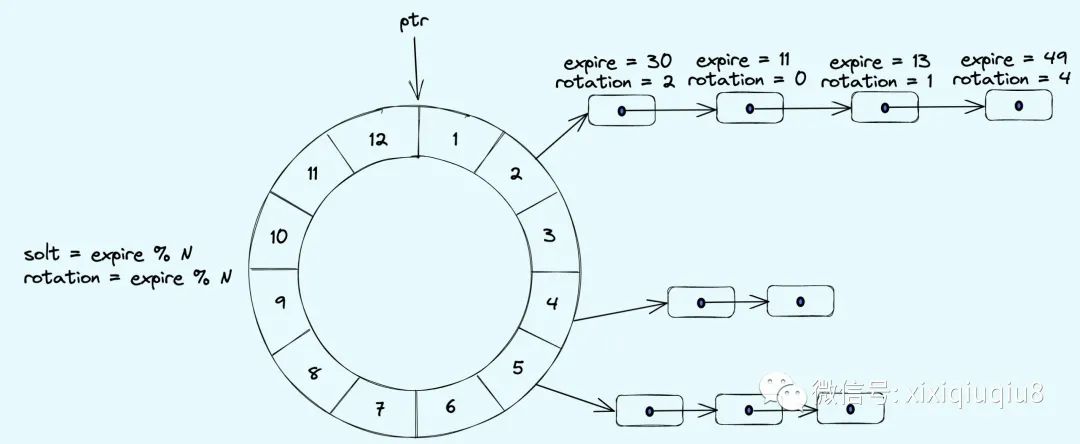
改进的单时间轮原理:每个bucket下不单单可以挂载到期时间expire=slot的定时任务,还可以挂载expire%N=slot的定时器(N为bucket个数),如上图,expire代表到期时间,rotation表示时间轮要在转动几圈之后才执行定时器,也就是说当指针转到某个bucket时,不能像简单的单时间轮那样直接执行bucket下所有的定时器。而且要去遍历该bucket下的链表,判断判断时间轮转动的次数是否等于节点中的rotation值,只有当expire和rotation都相同的情况下,才能执行定时器。
改进版单时间轮是时间和空间折中的方案,不像单时间轮那样有O(1)的时间复杂度,也不会像单时间轮那样,为了满足需求产生大量的bucket。
缺点:改进版的时间轮如果某个bucket上挂载的定时器特别多,那么需要花费大量的时间去遍历这些节点,如果bucket下的链表每个节点的rotation都不相同,那么一次遍历下来可能只有极少数的定时器需要立刻执行的,因此很难在时间和空间上都达到理想效果。
3.2.4 多时间轮
实现多时间轮算法可以借鉴了生活中水表的度量方法,通过低刻度走得快的轮子带动高一级刻度轮子走动的方法,达到了仅使用较少刻度即可表示很大范围度量值的效果。
下面以Linux实现的多时间轮算法为例,讲述多时间轮的实现,linux将时间轮分为5个级别的轮子(L1 ~ L5),L1的bucket大小是256,L2、L3、L4、L5的bucket大小是64,每一层的轮子都有一个指针在转动。规律是次级时间轮总和是上一级一个bucket的大小,例如:L1的bucket是256,每个slot的 1 jiffy,那么L2上每个slot大小就是 256 jiffy;这样就模拟了水表的量度规律,相邻的时间轮低级别的时间轮转一圈,比它高一个级别的轮子就要走一个bucket的效果。而且最高一级的时间轮L5的范围可以达到2^32 jiffies,基本能满足大部分业务场景的需求。如下图:
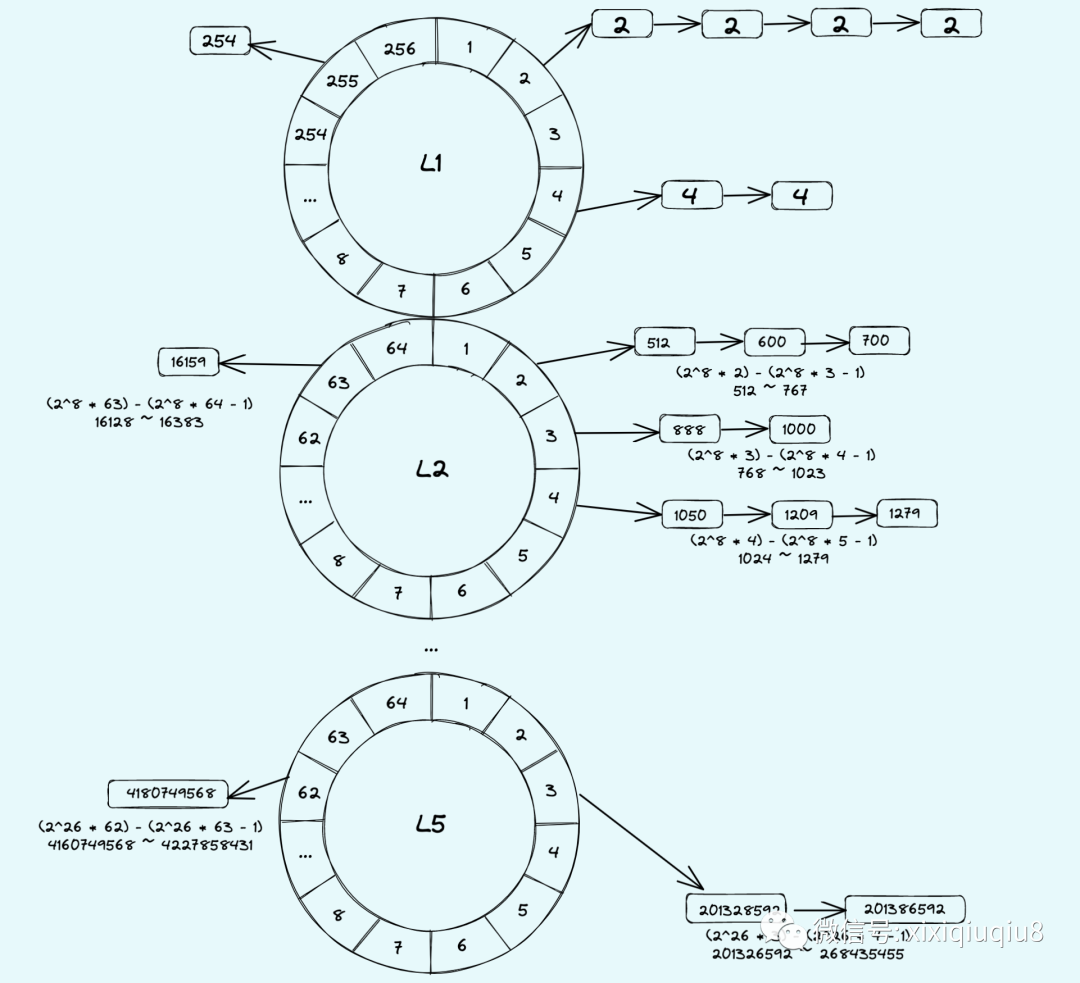
Linux时间轮定时器算法的关键在于添加定时器操作和时间轮进位迁移链表操作。先来说添加定时器。添加定时器的关键又在于知道每个时间轮每一个刻度所能表示的到期时间的范围。上图列出了每一级bucket能度量的jiffies的大小。假设有一个定时器在1000个jiffies后到期,根据上图容易看出其应该挂在L2轮上。L2轮每个刻度表示的大小为256个jiffies,则其应该挂在(1000/256)=3即第三个bucket上。
Linux在定时器到期检查上的操作也实现得很巧妙。假设curr_time=0x12345678,那么下一个检查的时刻为0x12345679。如果L1.bucket[0x79]上链表非空,则下一个检查时刻L1.bucket[0x79]上的定时器节点超时。如果curr_time到了0x12345700,低8位为空,说明有进位产生,这时移出8~13位对应的定时器链表(即正好对应着L2轮),重新加入定时器系统,这就完成了一次进位迁移操作。同样地,当curr_time的第8-13位为0时,这表明L2轮对L3轮有进位发生,将curr_time第14-19位的值作为下标,移出L3中对应的定时器链表,然后将它们重新加入到定时器系统中来。L4,L5依次类推。之所以能够根据curr_time来检查超时链,是因为L1~L5轮的度量范围正好依次覆盖了整型的32位:L1(1-8位),L2(9-14位),L3(15-20位),L4(21-26位),L5(27-32位);而curr_time计数的递增中,低位向高位的进位正是低级时间轮转圈带动高级时间轮走动的过程。
根据上述的设计,最高一级的时间轮L5的范围可以达到2^32 jiffies,基本能满足大部分业务场景的需求。
四、总结
多级时间轮和单个简单时间轮的时间复杂度及空间复杂度:linux使用了总计256+64+64+64+64=512个bucket,即可实现[0,2^32) jiffies的超时范围。相比简单的单时间轮,时间上仅仅多了1/256次(约等于值,忽略了L2以上产生的进位操作)的链表迁移操作耗时。可以认为其添加、删除定时器节点及到期check的操作时间复杂度均为O(1)。接下来的文章将分享时间轮的Java版本实现和应用。

若有收获,就点个赞吧
0 人点赞
