单机限流
1.计数器
计数器算法是限流算法里最简单也是最容易实现的一种算法。比如我们规定,对于A接口来说,我们1分钟的访问次数不能超过100个。那么我们可以这么做:在一开 始的时候,我们可以设置一个计数器counter,每当一个请求过来的时候,counter就加1,如果counter的值大于100并且该请求与第一个 请求的间隔时间还在1分钟之内,那么说明请求数过多;如果该请求与第一个请求的间隔时间大于1分钟,且counter的值还在限流范围内,那么就重置 counter,具体算法的示意图如下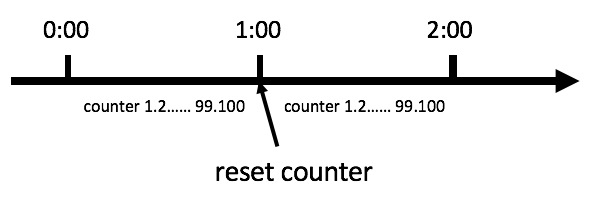
缺陷: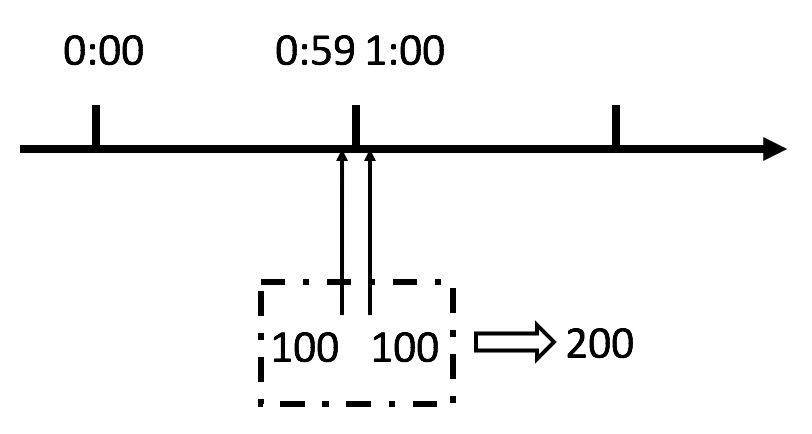
从上图中我们可以看到,假设有一个恶意用户,他在0:59时,瞬间发送了100个请求,并且1:00又瞬间发送了100个请求,那么其实这个用户在 1秒里面,瞬间发送了200个请求。我们刚才规定的是1分钟最多100个请求,也就是每秒钟最多1.7个请求,用户通过在时间窗口的重置节点处突发请求, 可以瞬间超过我们的速率限制。用户有可能通过算法的这个漏洞,瞬间压垮我们的应用。
聪明的朋友可能已经看出来了,刚才的问题其实是因为我们统计的精度太低。那么如何很好地处理这个问题呢?或者说,如何将临界问题的影响降低呢?我们可以看下面的滑动窗口算法。
计数器限流算法实现方式
采用AtomicInteger
使用AomicInteger来进行统计当前正在并发执行的次数,如果超过域值就简单粗暴的直接响应给用户,说明系统繁忙,请稍后再试或其它跟业务相关的信息。
弊端:使用 AomicInteger 简单粗暴超过域值就拒绝请求,可能只是瞬时的请求量高,也会拒绝请求。
import java.util.concurrent.atomic.AtomicLong;public class RateLimiter {private final static AtomicLong ZERO = new AtomicLong(0);private AtomicLong counter = ZERO;private static long timestamp = System.currentTimeMillis();private long permitsPerSecond;public RateLimiter(long permitsPerSecond) {this.permitsPerSecond = permitsPerSecond;}public boolean tryAcquire() {long now = System.currentTimeMillis();if (now - timestamp < 1000) {if (counter.get() < permitsPerSecond) {counter.incrementAndGet();return true;} else {return false;}} else {counter = ZERO;timestamp = now;return false;}}}
采用令牌Semaphore
使用Semaphore信号量来控制并发执行的次数,如果超过域值信号量,则进入阻塞队列中排队等待获取信号量进行执行。如果阻塞队列中排队的请求过多超出系统处理能力,则可以在拒绝请求。
相对Atomic优点:如果是瞬时的高并发,可以使请求在阻塞队列中排队,而不是马上拒绝请求,从而达到一个流量削峰的目的。
Semaphore俗称信用量,是JUC包下一个并发工具类,其实基于AQS实现的共享锁模式,包含非公平锁和公平锁实现,主要用用于控制多线程的并发访问次数,可做高并发下限流。
java模拟Smaphore限流:
public class SemaphoreDemo {//定义线程池private static ExecutorService executorService = Executors.newCachedThreadPool();public static void main(String[] args) {//定义一个信号量,限制3个同时执行线程Semaphore semaphore = new Semaphore(3);//模拟多线程for (int i = 0; i < 10; i++) {executorService.submit(() -> {try {//尝试获取信号量semaphore.acquire();System.out.println(Thread.currentThread().getName()+":开始执行");//模拟负责业务操作-休眠2秒TimeUnit.SECONDS.sleep(2);System.out.println(Thread.currentThread().getName()+":执行完成");} catch (InterruptedException e) {e.printStackTrace();}finally {//释放信号量semaphore.release();System.out.println(Thread.currentThread().getName()+":----------释放");}});}}}
输出
pool-1-thread-1:开始执行 (同时执行)pool-1-thread-2:开始执行 (同时执行)pool-1-thread-3:开始执行 (同时执行)pool-1-thread-2:执行完成pool-1-thread-2:----------释放pool-1-thread-3:执行完成pool-1-thread-3:----------释放pool-1-thread-4:开始执行pool-1-thread-5:开始执行pool-1-thread-1:执行完成pool-1-thread-6:开始执行pool-1-thread-1:----------释放pool-1-thread-4:执行完成pool-1-thread-6:执行完成pool-1-thread-5:执行完成pool-1-thread-8:开始执行pool-1-thread-6:----------释放pool-1-thread-4:----------释放pool-1-thread-7:开始执行pool-1-thread-9:开始执行pool-1-thread-5:----------释放pool-1-thread-8:执行完成pool-1-thread-8:----------释放pool-1-thread-10:开始执行pool-1-thread-9:执行完成pool-1-thread-7:执行完成pool-1-thread-9:----------释放pool-1-thread-7:----------释放pool-1-thread-10:执行完成pool-1-thread-10:----------释放
Semaphore底层解析:
public Semaphore(int permits) {sync = new NonfairSync(permits);}
默认非公平锁实现:
static final class NonfairSync extends Sync {private static final long serialVersionUID = -2694183684443567898L;NonfairSync(int permits) {super(permits);}protected int tryAcquireShared(int acquires) {return nonfairTryAcquireShared(acquires);}}
CAS自旋获取锁
final int nonfairTryAcquireShared(int acquires) {for (;;) {//这个就是我们传参进来的限制数量3int available = getState();//当获取一次锁后state会累加1,释放一次锁则减1//判断剩余数量>0表示获取成功,否则自旋等待int remaining = available - acquires;if (remaining < 0 ||compareAndSetState(available, remaining))return remaining;}}
采用ThreadPoolExecutor java线程池
固定线程池大小,超出固定先线程池和最大的线程数,拒绝线程请求;
滑动窗口
滑动窗口,又称rolling window。为了解决这个问题,我们引入了滑动窗口算法。如果学过TCP网络协议的话,那么一定对滑动窗口这个名词不会陌生。下面这张图,很好地解释了滑动窗口算法: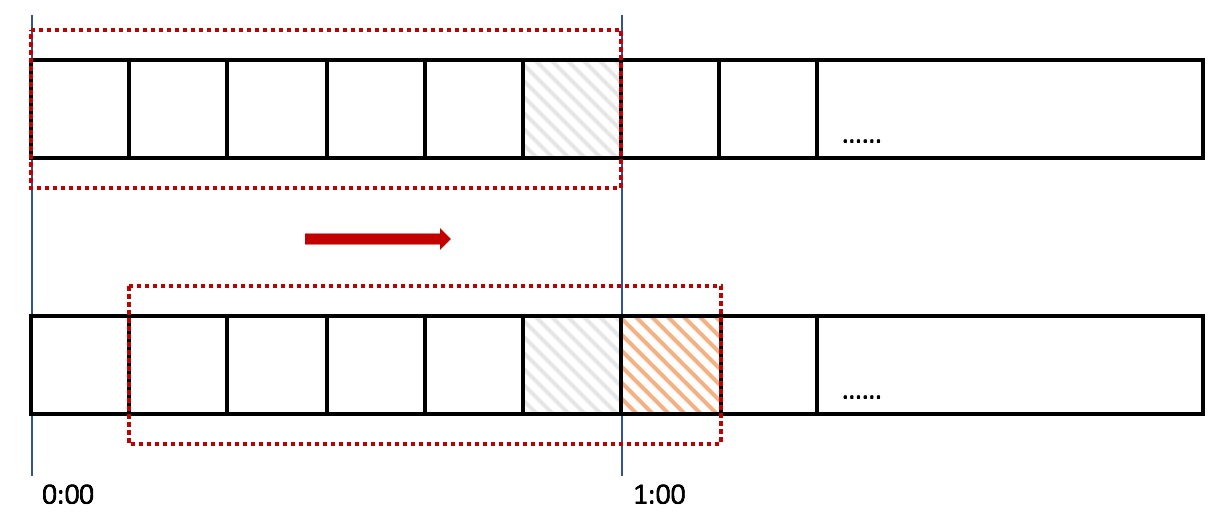
在上图中,整个红色的矩形框表示一个时间窗口,在我们的例子中,一个时间窗口就是一分钟。然后我们将时间窗口进行划分,比如图中,我们就将滑动窗口 划成了6格,所以每格代表的是10秒钟。每过10秒钟,我们的时间窗口就会往右滑动一格。每一个格子都有自己独立的计数器counter,比如当一个请求 在0:35秒的时候到达,那么0:30~0:39对应的counter就会加1。
那么滑动窗口怎么解决刚才的临界问题的呢?我们可以看上图,0:59到达的100个请求会落在灰色的格子中,而1:00到达的请求会落在橘黄色的格 子中。当时间到达1:00时,我们的窗口会往右移动一格,那么此时时间窗口内的总请求数量一共是200个,超过了限定的100个,所以此时能够检测出来触 发了限流。
我再来回顾一下刚才的计数器算法,我们可以发现,计数器算法其实就是滑动窗口算法。只是它没有对时间窗口做进一步地划分,所以只有1格。
由此可见,当滑动窗口的格子划分的越多,那么滑动窗口的滚动就越平滑,限流的统计就会越精确。
package com.example.demo1.service;import java.util.Iterator;import java.util.Random;import java.util.concurrent.ConcurrentLinkedQueue;import java.util.stream.IntStream;public class TimeWindow {private ConcurrentLinkedQueue<Long> queue = new ConcurrentLinkedQueue<Long>();/*** 间隔秒数*/private int seconds;/*** 最大限流*/private int max;public TimeWindow(int max, int seconds) {this.seconds = seconds;this.max = max;/*** 永续线程执行清理queue 任务*/new Thread(() -> {while (true) {try {// 等待 间隔秒数-1 执行清理操作Thread.sleep((seconds - 1) * 1000L);} catch (InterruptedException e) {e.printStackTrace();}clean();}}).start();}public static void main(String[] args) throws Exception {final TimeWindow timeWindow = new TimeWindow(10, 1);// 测试3个线程IntStream.range(0, 3).forEach((i) -> {new Thread(() -> {while (true) {try {Thread.sleep(new Random().nextInt(20) * 100);} catch (InterruptedException e) {e.printStackTrace();}timeWindow.take();}}).start();});}/*** 获取令牌,并且添加时间*/public void take() {long start = System.currentTimeMillis();try {int size = sizeOfValid();if (size > max) {System.err.println("超限");}synchronized (queue) {if (sizeOfValid() > max) {System.err.println("超限");System.err.println("queue中有 " + queue.size() + " 最大数量 " + max);}this.queue.offer(System.currentTimeMillis());}System.out.println("queue中有 " + queue.size() + " 最大数量 " + max);}}public int sizeOfValid() {Iterator<Long> it = queue.iterator();Long ms = System.currentTimeMillis() - seconds * 1000;int count = 0;while (it.hasNext()) {long t = it.next();if (t > ms) {// 在当前的统计时间范围内count++;}}return count;}/*** 清理过期的时间*/public void clean() {Long c = System.currentTimeMillis() - seconds * 1000;Long tl = null;while ((tl = queue.peek()) != null && tl < c) {System.out.println("清理数据");queue.poll();}}}
漏桶算法
上面所介绍的两种算法都不能非常平滑的过渡,下面就是漏桶算法登场了
什么是漏桶算法?
漏桶算法以一个常量限制了出口流量速率,因此漏桶算法可以平滑突发的流量。其中漏桶作为流量容器我们可以看做一个FIFO的队列,当入口流量速率大于出口流量速率时,因为流量容器是有限的,当超出流量容器大小时,超出的流量会被丢弃。
下图比较形象的说明了漏桶算法的原理,其中水龙头是入口流量,漏桶是流量容器,匀速流出的水是出口流量。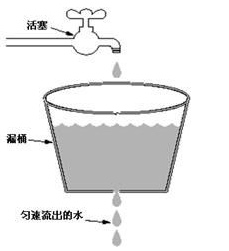
漏桶算法的特点
- 漏桶具有固定容量,出口流量速率是固定常量(流出请求)
- 入口流量可以以任意速率流入到漏桶中(流入请求)
- 如果入口流量超出了桶的容量,则流入流量会溢出(新请求被拒绝)
不过因为漏桶算法限制了流出速率是一个固定常量值,所以漏桶算法不支持出现突发流出流量。但是在实际情况下,流量往往是突发的。
public class LeakBucket {/*** 时间*/private long time;/*** 总量*/private Double total;/*** 水流出去的速度*/private Double rate;/*** 当前总量*/private Double nowSize;public boolean limit() {long now = System.currentTimeMillis();nowSize = Math.max(0, (nowSize - (now - time) * rate));time = now;if ((nowSize + 1) < total) {nowSize++;return true;} else {return false;}}}
令牌桶算法
令牌桶算法是漏桶算法的改进版,可以支持突发流量。不过与漏桶算法不同的是,令牌桶算法的漏桶中存放的是令牌而不是流量。
那么令牌桶算法是怎么突发流量的呢?
最开始,令牌桶是空的,我们以恒定速率往令牌桶里加入令牌,令牌桶被装满时,多余的令牌会被丢弃。当请求到来时,会先尝试从令牌桶获取令牌(相当于从令牌桶移除一个令牌),获取成功则请求被放行,获取失败则阻塞拒绝请求。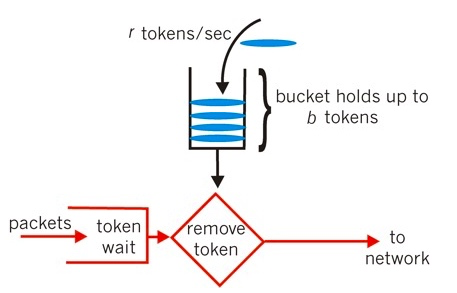
令牌桶算法的特点
- 最多可以存发b个令牌。如果令牌到达时令牌桶已经满了,那么这个令牌会被丢弃
- 请求到来时,如果令牌桶中少于n个令牌,那么不会删除令牌。该请求会被限流(阻塞活拒绝)
- 算法允许最大b(令牌桶大小)个请求的突发
令牌桶算法限制的是平均流量,因此其允许突发流量(只要令牌桶中有令牌,就不会被限流)
public class TokenBucket {/*** 时间*/private long time;/*** 总量*/private Double total;/*** token 放入速度*/private Double rate;/*** 当前总量*/private Double nowSize;public boolean limit() {long now = System.currentTimeMillis();nowSize = Math.min(total, nowSize + (now - time) * rate);time = now;if (nowSize < 1) {// 桶里没有tokenreturn false;} else {// 存在tokennowSize -= 1;return true;}}}

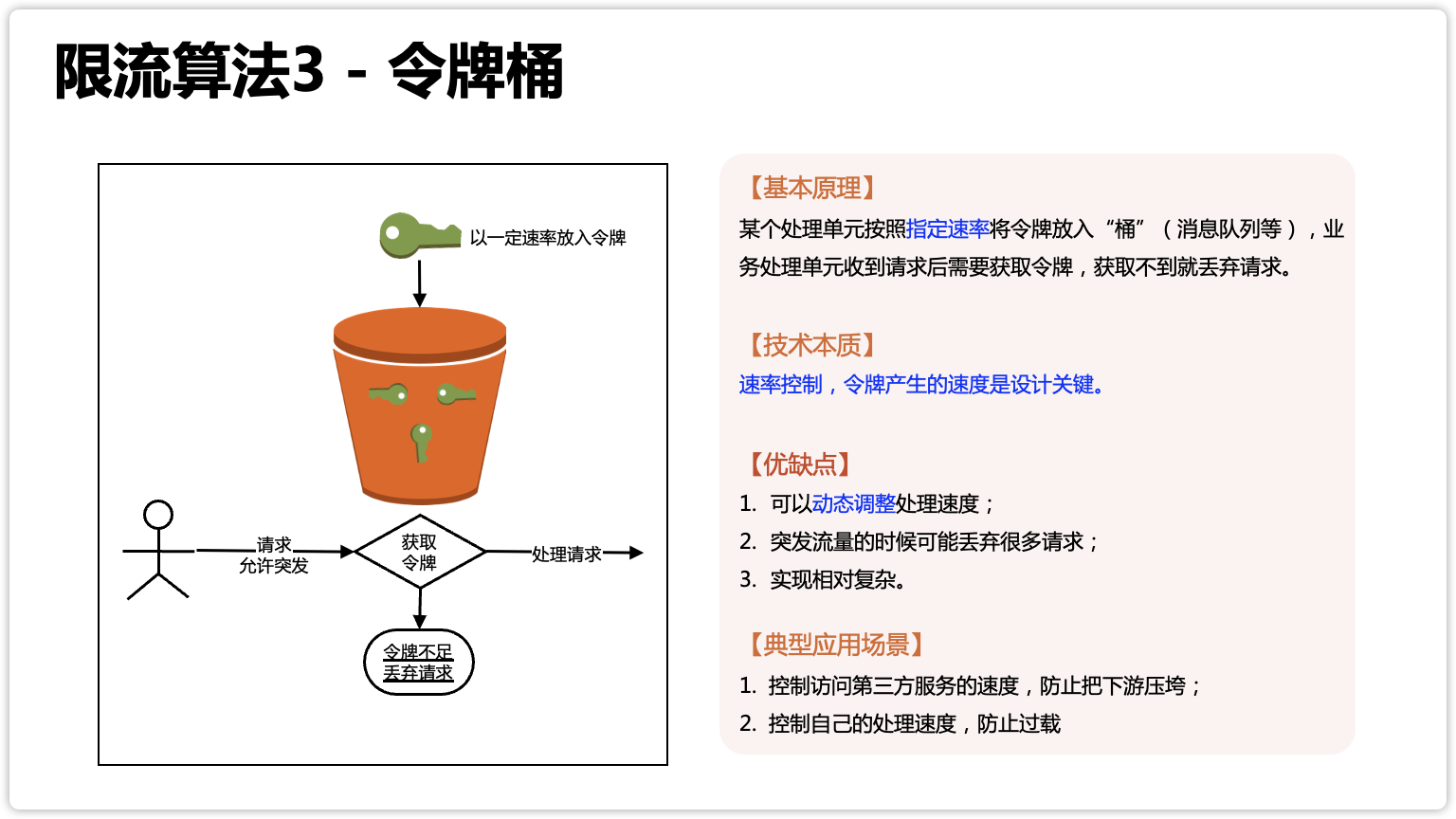
漏桶的本质是总量控制,令牌桶的本质是速率控制
网上的文章都说令牌桶更适合“突发流量”,为何你这里说漏桶更适合“瞬时高并发”?
其实,令牌桶的“突发流量”跟我们通常理解的“业务高并发”并不一样。令牌桶的算法原本是用于网络设备控制传输速度的,而且它控制的目的是保证一段时间内的平均速率控制,之所以说令牌桶适合突发流量,是指在网络传输的时候,可以允许某段时间内(一般就几秒)超过平均传输速率,这在网络环境下常见的情况就是“网络抖动”,但这个短时间的突发流量是不会导致雪崩效应,网络设备也能够处理得过来。对应到令牌桶应用到业务处理的场景,就要求即使有突发流量来了,系统自己或者下游系统要真的能够处理的过来,否则令牌桶允许突发流量进来,结果系统或者下游处理不了,那还是会被压垮。
而我说漏桶算法更适合“突发流量”,是指秒杀、抢购、整点打卡签到、微博热点事件这种业务高并发场景,它不是由于“XX 抖动”引起的,而是由业务场景引起的,并且持续的事件可能是几分钟甚至几十分钟,这种业务场景为了用户体验和业务尽量少受损,优先采取的不是丢弃大量请求,而是缓存请求,避免系统出现雪崩效应。因此我们会看到,漏桶和令牌桶都有保护作用,但漏桶的保护是尽量缓存请求(缓存不下才丢),令牌桶的保护主要是丢弃请求(即使系统还能处理,只要超过指定的速率就丢弃,除非此时动态提高速率)。
其实,漏桶算法限流还是会丢请求,如果你觉得漏桶算法应对突发流量都还不够好,那就要更进一步,采取排队的方式来实现了,排队的方案其实就是一个更复杂的“漏桶”实现,例如下图中的“消息队列”,本质上就是一个“漏桶”: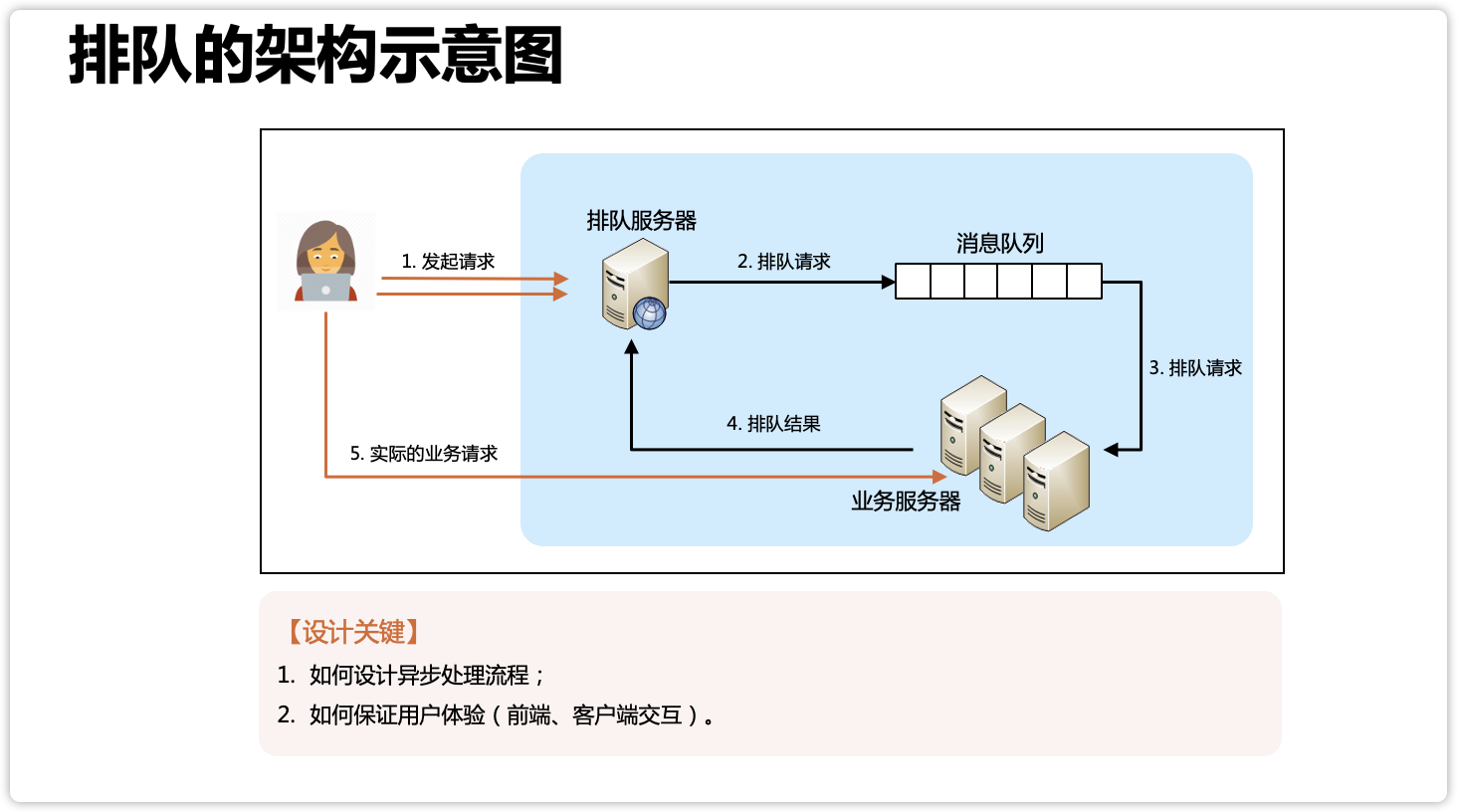
参考漏桶算法和令牌桶算法,区别到底在哪里
分布式限流
我们需要分布式限流和接入层限流来进行全局限流。
- redis+lua实现中的lua脚本
- 使用Nginx+Lua实现的Lua脚本
- 使用 OpenResty 开源的限流方案
- 限流框架,比如Sentinel实现降级限流熔断

若有收获,就点个赞吧
0 人点赞
