导读:百度交易中台作为集团移动生态战略的基础设施,面向收银交易与清分结算场景,为赋能业务提供高效交易生态搭建。目前支持百度体系内多个产品线,主要包含:小程序,地图打车,百家号,招财猫,好看视频等。本文主要介绍了百度交易中台的商户财务对账相关的帐房系统,主要从业务模型以及系统设计来介绍该系统。
一、系统介绍
帐房系统是建立在百度交易系统[1]下,收拢聚合了商家/平台/宿主等接入方的收入/支出流水的对账系统。商家通过该系统可直接看到自己的收入/其他款项/支出等流水信息,实现按天/月/年的财务对账。
二、业务场景
针对不同业务背景,交易清结算系统产生了不同的流水类型。目前主流的业务场景包含:1.直播带货等场景下的流量主带货[2]。2.小程序宿主内的宿主带货。3.地图打车等业务场景下的平台分帐。
图(2-1) 交易中台业务背景
这些业务场景下,交易流水产生的过程如图(2-2)所示。一个订单经过支付、支付通知(购物车拆子订单)、订单维度结算、结算流水推送商家资金池,最后资金池流水才会到帐房系统,交易流水产生在图(2-2)中的商家订单结算过程中,一个订单会产出多条交易流水,推送到下游资金池系统进行商家账户记账,同时产生了对应的资金池流水,帐房系统的数据来源就是资金池的流水记录。目前商家结算产出流水类型有以下几种:
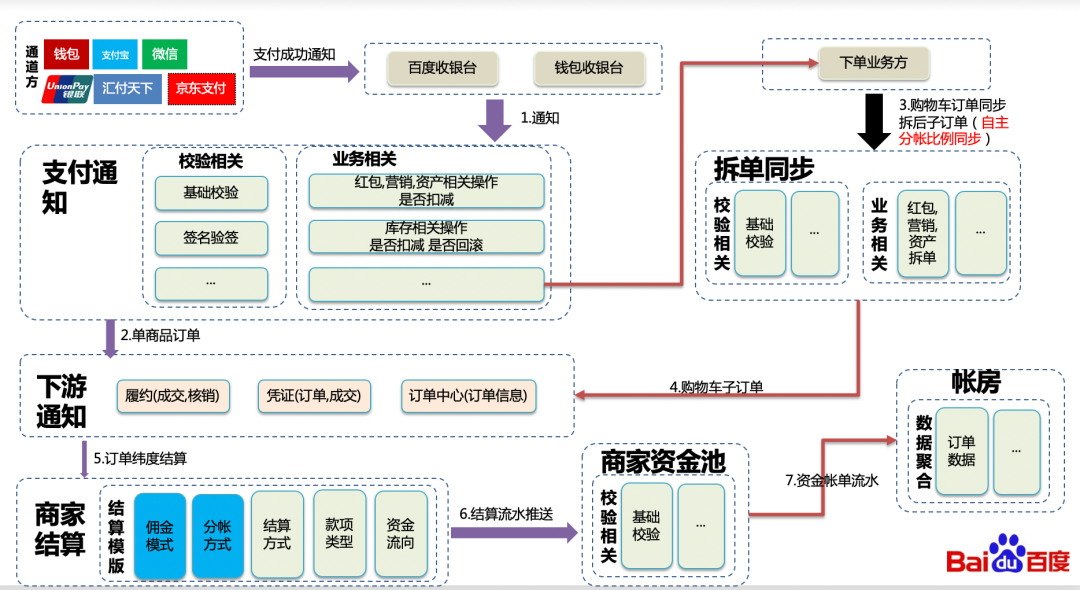
图(2-2) 交易流水产生流程
- 分帐流水(货款):对于入驻交易的平台方,平台方为商家提供了平台上的功能,平台方期望从商家售卖的货款中收取一定的佣金,作为平台的收入。基于这种业务场景,产生了平台的分帐流水。对应图(2-2)商家结算中的分帐方式产出,分帐方式包含:按照固定比例,按照固定金额,自主比例分帐以及多方分帐,接入方根据实际的业务场景选择对应的分帐方式。
- 技术服务费:技术服务费为交易中台(网讯主体)对使用收银台支付的商家,会收取一定比例的钱作为技术服务费,因此产生了对应的技术服务费流水,对应图(2-2)商家结算中的分帐方式的佣金模式产出,佣金模式包含:固定比例、固定金额以及按照渠道收取。对应商家的其他款项数据。
- 小程序带货流水:小程序带货流水为流量主收取的带货佣金,流量主为商家通过文章、视频、直播带货后,卖出的货款会分一部分给带货的流量主,从而产生了小程序带货流水。与分帐流水不同的时,分帐的流水是给入驻的平台,而带货流水最后的结算对象是个人。
- 宿主带货流水:业务背景是智能小程序开源联盟,为宿主和小程序共建生态。宿主为小程序提供分发流量及展现入口,有效提升小程序的使用时长及频次,基于此,宿主产生对在其 APP 上发生的交易进行抽佣的诉求,从而实现宿主新商业变现模式拓展,带动宿主商业收入增长。 宿主带货流水的产生方式与小程序带货类似,区别是宿主在交易进行和入驻,属于企业/公司类型。一个商家属于一个平台,也可以和宿主进行绑定,与二者同时进行分账。
- 打款流水:打款流水为给商家银行卡打款的流水。
- 调整款流水:指打款银行退汇的流水。
帐房系统将以上的流水划分为 3 个类别:收入、支出以及其他款项。
- 收入:指分帐流水
- 其他款项:包含交易中台收取的技术服务费、打款退回的流水、小程序带货流水以及宿主带货流水
- 支出:指打款流水
商家整体财务数据核对收支平衡的公式为:
总体对账公式:商家余额 = 收入 + 其他款项 - 支出
若公式成立则收支流水数据准确无误。若商家想要核对账期内的财务数据,则需要看两个账期之间的收入和支出是否一致。例如商家每隔 7 日进行一次打款(即是支出),则商家只需要核对这 7 天内的流水数据是否满足以下公式即可。
结算账期对账公式:收入 + 其他款项 - 支出= 0
例子说明
交易中台所支持的业务场景中,一个订单会产生多条流水,每一条流水的结算对象也不一样,因此,这里举例简单说明流水属于的对象。
例子:针对小程序带货的场景,一个订单金额为 100 元,带货流量主分佣 10%,平台分帐 5%,交易中台收取 6‰技术服务费。因此各个对象的流水金额如下:
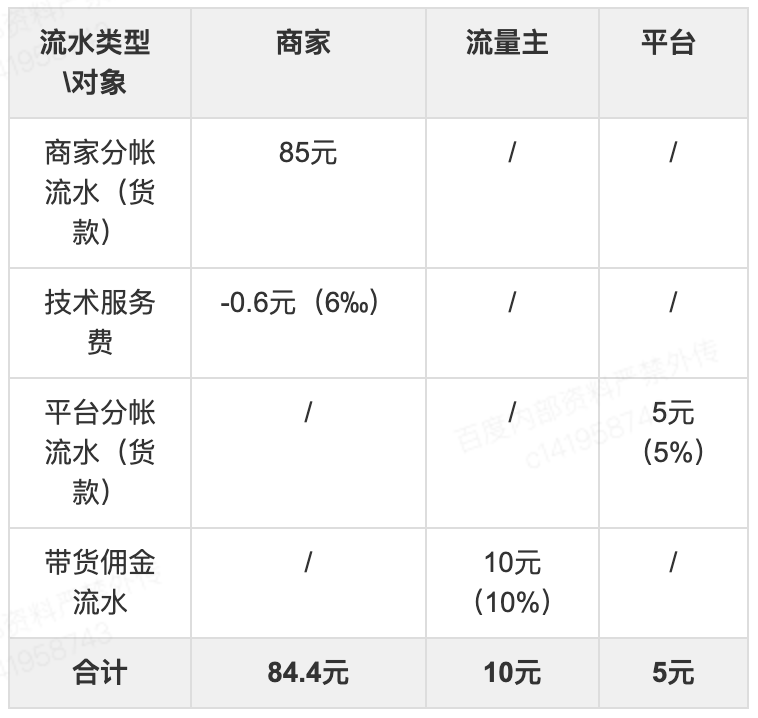
从表中可以看出最后的总金额只有 84.4+10+5=99.4 元,缺少的 0.6 元就是交易中台收取的技术服务费。技术服务费的收取是通过从商家口扣除 0.6 元实现的,而不是产生 0.6 元的流水给交易中台。如果打款周期到了,对应给结算对象的打款金额就分别为 84.4 元,10 元和 5 元,这样收入和支出就一致了。
三、系统构架
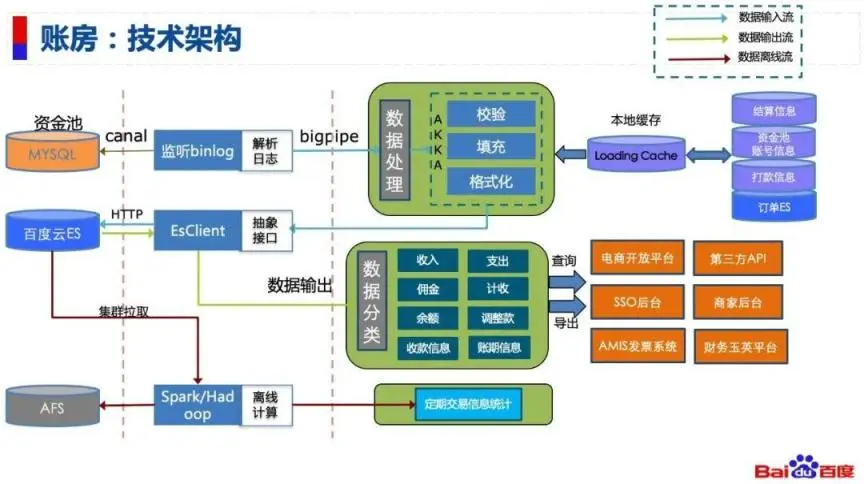
图(3-1) 帐房系统架构图
帐房的整体架构如图 3-1 所示,帐房的数据来源为上游的资金池流水数据,canal 监听 binlog,解析 binlog 日志将流水数据发布到 bigpipe,帐房系统通过监听 bigpipe 数据,拿到流水数据后通过 akka 完成数据的校验、补充,得到一条完备的流水数据。最后通过 esClient 将流水数据写入百度云 es,业务的查询以及导出功能都是基于百度云 es 的数据来完成的。与此同时,交易中台也建立了离线计算系统,通过 spark 拉取 es 的集群数据,存储在 AFS 上,基于此完成离线数据统计的功能。 帐房系统以资金池流水数据为主,根据流水类型的不同,补充了来自其他不同系统的数据,丰富该条流水的信息,来满足业务侧查询的需求,补充的数据存储在 es 以及数据库中,针对热点的数据,系统使用 LoadingCache 本地缓存的方式提升处理速度。系统对外输出数据的方式有:第三方 API、电商开放平台、财务运营平台、业务商家后台以及 AMIS 发票系统。
四、系统功能拆解
4.1 基于 canal 的数据同步
帐房系统的数据来源为上游账户资金池系统的流水数据,资金池流水数据存储在 ddbs 数据库中。帐房需要实现准实时数据的获取,同时避免代码的侵入,因此采用了基于 cacal 监听 ddbs 数据库 binlog 日志的方式,进行数据的同步;由于每日的流水产生存在流量高峰,直接将数据请求下游帐房系统,可能会对帐房系统产生冲击,引起系统异常的问题。为了避免这种情况的出现,我们引入了中间件消息队列(bigpipe)进行流量削峰填谷处理,canal 将解析的库表变更数据发送到消息队列中,帐房系统采用监听者模式从消息队列中获取对应的数据,通过 java 的 akka 方式进行并发的数据处理。帐房系统通过异步消息以及 akka 并发的方式完成数据的异步化同步,解决流量高峰问题,实现了数据的准实时同步,当前系统的数据同步延时控制在秒级别。
4.2 Elasticsearch 数据存储
帐房系统业务需求为商家/用户对账需求,主要是为了满足商家/用户对于财务相关的对账数据的查询以及导出。基于这样的特点,需要查询大量的数据,同时需要完成各个维度的数据聚合,而且商家的流水数据量远大于订单的数据量,一个订单将会产生 2-6 条的流水。交易订单中心以及上游账户资金池系统的存储都是采用数据库分度分表的方式进行的,这样的方式并不适用于帐房系统,引入分表的方式会导致数据不均匀的情况产生,对于热点账户的问题难以解决,同时难以完成多维度的数据查询。基于此系统采用了 es 的存储方式,通过 es 支持对外的多维度、准实时的数据查询。
帐房系统早期的数据写入时自定义了 routing,使用商家 id 作为 routing,随着业务发展,热点商户的数据量不断增加,从而导致 es 分片出现了数据倾斜的情况,进而会引发 es 聚合查询偶发超时以及偶现写入失败的情况。因此系统进行了 es 数据迁移,从而解决数据倾斜的问题。同时 Elasticsearch 使用一种称为倒排索引的结构,它适用于快速的全文搜索,因此 es 对于字段的变更修改无法直接在原来的索引上进行,都是重建索引,进行数据的迁移完成的。es 数据的迁移方式有很多(BOS 快照迁移、Logstash、通过 Spark 迁移数据、HDFS 快照迁移等),鉴于交易侧 es 数据量以及迁移的场景,使用了 Logstash 同步的方式进行了数据的迁移,迁移过程中将文档的 routing 设置去除,解决了数据倾斜的数据。
4.3 数据一致性保障
帐房系统其主要功能为商家的对账,因此商家的流水数据的缺失必然会导致商家财务数据的错误,给商家带来对账上的问题。因此保障帐房的数据与上游系统一致,是该系统重要且必须的能力。数据一致性的保障,帐房系统通过接入交易平台的一致性服务系统完成,其流程如图 4-1 所示。
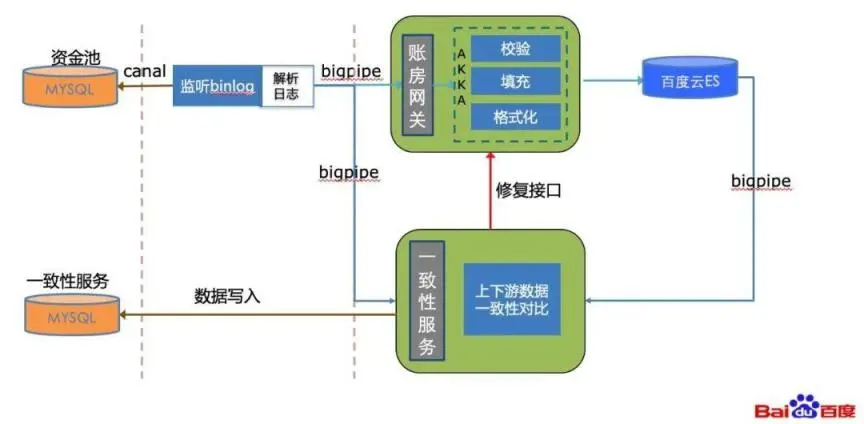
图(4-1) 数据一致性保障流程图
一致性服务通过接收来自上游 canal 发送的 bp 消息,以及帐房系统写入 es 成功后发送的 bp 消息,将二者的消息存储至 mysql 数据库中,每日定时对上下游系统的数据进行对比分析,得出对应的差异数据,然后通过调用对应的修复接口完成数据的修复。一致性服务留存了 7 日内的消息数据,过期定时清理,保证服务的数据量不会过大,不影响数据库性能。除了一致性服务的保障之外,每月会通过 spark 进行离线数据核对,确保当月的数据上下游一致。
4.4 数据聚合
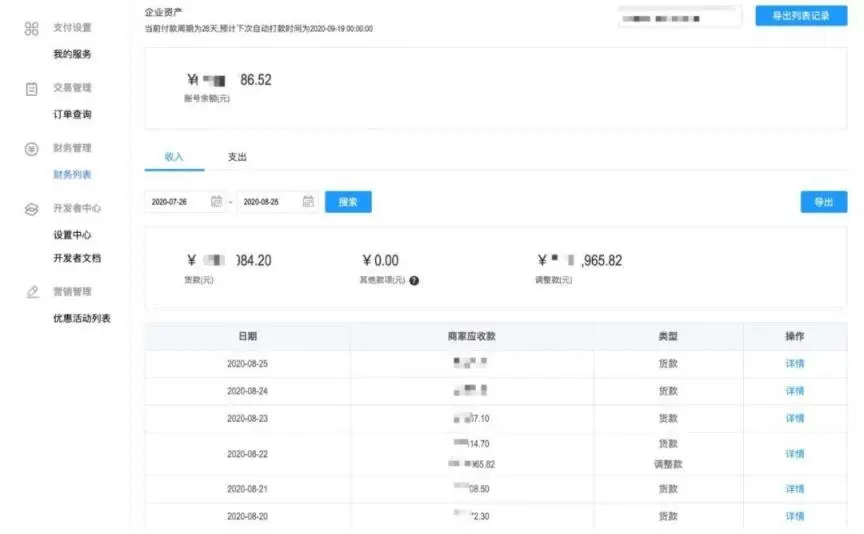
图(4-2)商家对账页面
商家对账的页面如图 4-2 所示,可以看出,对于帐房系统的要求是需要按照商家维度查询对应的财务数据,同时需要按照月份进行聚合,返回商家每一个月的收入/支出金额。在使用 es 进行聚合查询时,需要关注以下信息,保障查询的效率。
聚合查询字段,设置为 keyword,能够提升查询的效率。(当前系统数据量下,查询时间差异在 2 倍左右。)
es 查询时 must 和 filter 的使用,must 返回的文档必须满足 must 子句的条件,并且参与计算分值;filter 返回的文档必须满足 filter 子句的条件。但是跟 must 不一样的是,不会计算分值, 并且可以使用缓存。简单来讲,filter 查询效率高于 must,根据自己的实际业务场景选择合适的查询语句,在不需要相关性算分的查询场景,尽量使用 filter context 让查询更高效。(当前系统数据量下,查询时间差异在 2-4 倍左右。)
ES 中的路由(routing)机制决定一个 document 存储到索引的哪个 shard 上面去,即文档到 shard 的路由。计算公式为:shard_num = hash(_routing) % num_primary_shards。一般情况下,不建议使用写入时设置 routing,如果 routing 设置的不合理,会导致数据倾斜的问题,数据倾斜会导致查询问题以及集群不稳定。若能够保证设置的 routing 分布均匀,且使用 routing 作为数据隔离方式,在这样的情况下,后面检索的时候,同样使用隔离参数作为 routing,就可以精准的从某个 shard 获取数据了,提升查询的效率。早期帐房系统使用商户 ID 作为 routing,在一定程度上提升了查询的效率,但是随着业务的增加,出现了热点商户的问题,导致了 es 数据倾斜问题,从而引起了一些问题,后续进行了数据的迁移,不再使用资金池 id 作为 routing,而是使用系统默认的文档 id 作为 routing。
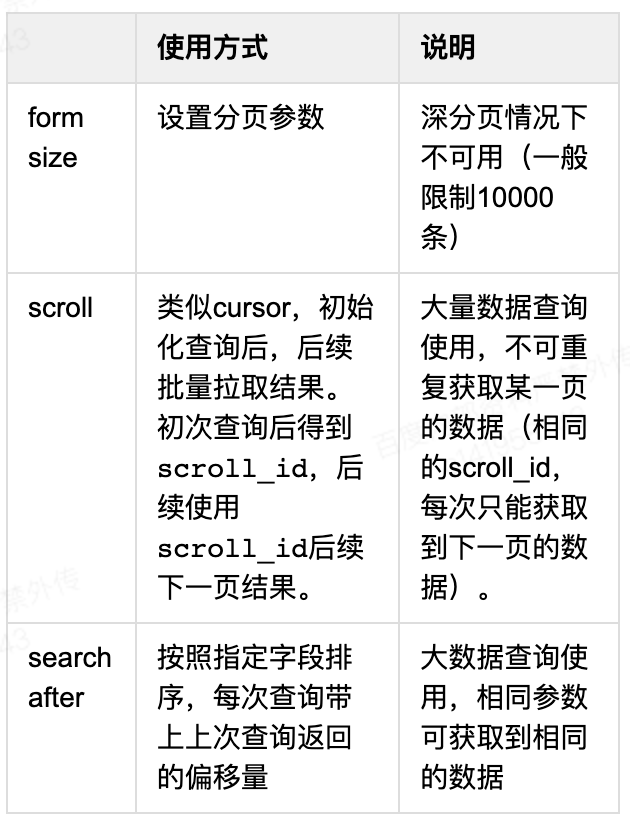
es 深分页问题,es 分页查询有三种方式:1.form size 。2.scroll 方式。3.search after 方式。这里简单做一下对比,查询速度上 scroll>search after>form size。帐房系统设计中三种查询方式均有使用,适用于不同的场景,form size 方式用于前端页面上的展示,仅仅展示少量的分页数据;scroll 查询方式用于大量数据的文件导致任务,快速完成文件的导出任务;search after 方式用于对外的 API 批量数据导出,业务侧可重复获取某一页数据进行处理。
五、结束语
基于当前交易中台所支撑的业务场景,建立了如上的帐房系统,我们也在不断的进行完善和升级,助力上游的业务不断的前进,提升商家的对账体验。随着业务的不断发展,帐房系统也在不断的进行升级改造,不断地完善自身。后续我们将持续升级系统,与业务共同发展成长。
参考资料
【1】百度交易中台之订单系统架构浅析
https://mp.weixin.qq.com/s/olILeDhU4imO2AR446lP9Q
【2】百度交易中台之商品推广流程构建以及实现
https://mp.weixin.qq.com/s/vY_TdNclvhtwxLxjKWfwrg

若有收获,就点个赞吧
0 人点赞
