作者:野鸽知了
链接:https://www.zhihu.com/question/406402493/answer/1333929146
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
关于这个问题,这里以 MySQL InnoDB 来说,先简单介绍下 MySQL InnoDB 的 B+ 树索引。
B+ 树索引主要可以分为两种索引,聚集索引和非聚集索引。
聚集索引:也就是平常我们说的主键索引,在 B+ 树中叶子节点存的是整行数据。
非聚集索引:也叫二级索引,也就是一般的普通索引,在 B+ 树中叶子节点存的是主键的值。
我们如果直接用主键查找,用的是聚集索引,能找到全部的数据。如果我们是用非聚集索引查找,如果索引里不包含全部要查找的字段,则需要根据索引叶子节点存的主键值,再到聚集索引里查找需要的字段,这个过程也叫做回表。
明白了回表的定义,我们来举个例子,先执行下面的语句
CREATE TABLE t_[back_table_test](https://www.zhihu.com/search?q=back_table_test&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra=%7B%22sourceType%22%3A%22answer%22%2C%22sourceId%22%3A1333929146%7D) ( id int(11) NOT NULL AUTOINCREMENT, c1 varchar(10) DEFAULT NULL, c2 varchar(10) DEFAULT NULL, PRIMARY KEY (id) USING BTREE, INDEX idx_c1(c1) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1; INSERT INTO t_back_table_test(id, c1, c2) VALUES (1, ‘aa’, ‘test1’); INSERT INTO `tback_table_test(id,c1,c2) VALUES (2, 'aa', 'test2'); INSERT INTOt_back_table_test(id,c1,c2) VALUES (3, 'bb', 'test3'); INSERT INTOt_back_table_test(id,c1,c2) VALUES (4, 'bb', 'test4'); INSERT INTOt_back_table_test(id,c1,c2`) VALUES (5, ‘cc’, ‘test5’);
可以看到,这里建了一张 t_back_table_test 表,并以字段 c1 建了一个非聚集索引 idx_c1,然后插入了一些测试数据,这样这张表就有一个聚集索引和一个非聚集索引,这时当我们执行下面的语句时
SELECT * FROM t_back_table_test WHERE c1 = ‘aa’;
由于这里要查询所有字段,但是索引 idx_c1 里没有 c2 字段,所以要通过回表,从聚集索引里获取c2 的值,查询过程如下图(这里只是简单画),这就是简单的回表过程。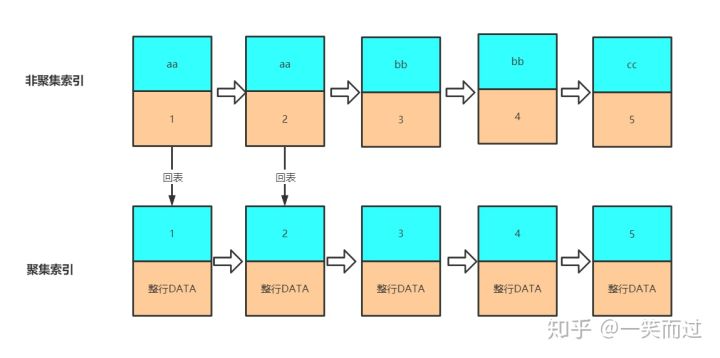
那我们应该如何避免回表,因为如果用到了回表,就需要二次查询的过程,效率肯定更慢,很简单,回表是因为要查询的字段在非聚集索引里没有,所以在满足需求的情况下,我们尽量使非聚集索引里有要查询的索引字段,比如下面的查询语句
EXPLAIN SELECT c1 FROM t_back_table_test WHERE c1 = ‘aa’;
这个查询语句只查询了 c1 字段,这个字段在非聚集索引 idx_c1 里有,所以不需要回表,查看执行计划如下,Extra 里的 Using index,代表的就是只用到非聚集索引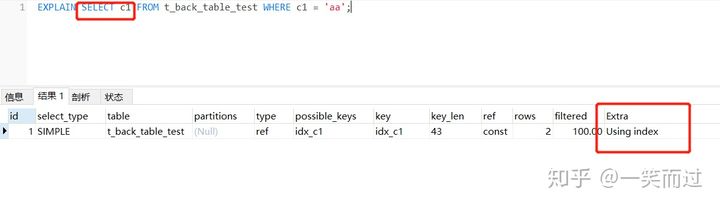
所以在查询时,可以尽量用聚集索引来查(也就是用主键来查询),或者根据业务需求,建好的索引,满足索引查询字段。但是实际业务中,很难建立一个索引就能满足所有查询要求,所以,正常情况,回表也没事,只要能用到索引也能大大加快查询速度。

若有收获,就点个赞吧
0 人点赞
