转载自小鹏汽车技术中台实践
作者 | 小鹏汽车基础架构团队
“中台”这个概念火了一年多了,年初的时候又”火“了一次。相信任何事物都有它的两面性,正如我们做架构的时候其实也一直在做取舍。
小鹏汽车的技术中台(Logan)已经快两岁了,今天我们不讨论该不该做技术中台,只说说中台给我们带来了什么。
不管黑猫白猫,捉到老鼠就是好猫。
技术选型Eureka
一、背景
小鹏汽车的智能离不开复杂系统的支撑,其特有的互联网基因要求业务能够应对市场的迅速变化:快速响应、快速试错、快速创新。同时,为了给客户提供优质服务,系统需要更高的可靠性,降本增效也是公司快速发展过程中特别关注的。
技术中台正好契合了公司上述所有需求。在公司的引领和推动下,2018 年 4 月召开了小鹏汽车技术中台的启动会,同年 5 月底团队成立。技术中台团队始终坚持“兵不在多而在精”的原则,近两年高峰时期团队也未超过 10 人。
也许有人会怀疑,一支足球队规模的团队,到底能做出个什么样的中台来?
简单来说,小鹏汽车的技术中台主要由以下及部分组成:
- 基于 SpringCloud、Kubernetes 自研的微服务体系平台
- 遵循业界标准的自服务中间件平台
- 可监可控的高性能中间件 SDK
接入中台的应用不需要写一行业务代码,可以立即具备以下能力:
- 生产级应用:健康检查、节点部署反亲和性、自动扩缩容、JVM GC 参数调优、资源隔离、滚动部署
- 自动接入网关:限流、熔断、访问控制
- SpringBoot 使用最佳实践:配置调优、profile 标准化、线程池和连接池调优
- 自动化 CICD:自动化镜像生成、自动处理 git 的 tag、代码质量
- 丰富的问题定位手段:日志中心、注册中心、微服务全方位监控 (JVM/Trace/Metrics/ 告警)
- 系统级无埋点监控、业务 Metrics 提供扩展机制
- 调用链
- 数据可视化:丰富的研发数据展示
- 配置中心提供不停机,动态调整应用配置能力
对外保证:
- DevOps 提高效率:开发、部署、问题定位
- 生产可用性:弹性、容错
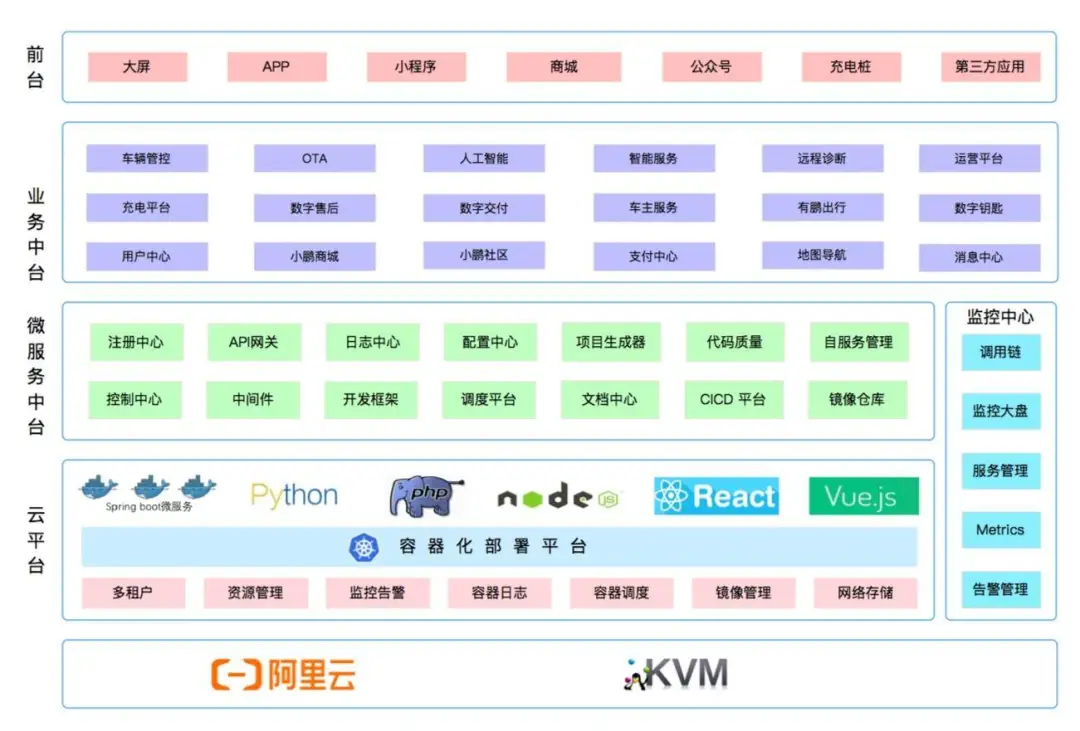
如上图,小鹏汽车的技术中台分为微服务中台和云平台两大部分:
- 云平台:为技术中台提供底层的基础支撑,基于主流的容器技术 Docker 和 K8s 构建,提升资源的利用率、降低运维成本;自研了容器化的部署平台,提供用户友好的 UI、日志聚合、跨集群部署、历史修订版;自定义 CRD 封装应用部署单元,以效率和可用性为目标,提供生产级应用最佳实践,简化应用在 Kubernetes 的生命周期管理;开发人员只需专注业务,通过 CICD 标准化构建部署到云平台;
- 微服务中台:基于 SpringCloud 打造,提供微服务的管理、治理、监控、统一标准化配置,助力系统微服务化,提升生产可用性;并通过研发中台提升研发、测试、问题定位效率。
本文主要分享微服务中台的实践经验。
二、微服务中台
1
历史背景:
- 微服务功能薄弱:原有部分服务统一使用 SpringBoot + Dubbo 架构,具备微服务的初步形态,历史负担小,但版本不统一;且当时的 Dubbo 生态,无法提供足够的监控和治理功能;
- 缺少有效的监控手段:运维监控平台使用 Zabbix 和 Open-Falcon,缺乏对应用自身的业务监控和告警;
- 问题排查效率低:目前有部分日志通过 agent(FileBeat)进行采集,大数据根据需要做分析,而应用无法实施查看系统日志;缺少调用链的支持,由于分布式系统的复杂性,出现问题较难定位;
- 无法运行时修改配置:需要重新打包或修改配置,重启应用:用户有感知、配置缺乏回滚、审批、灰度;
- 公共基础功能还没有统一:比如连接池使用、第三方依赖版本、代码文件编码、日志格式;
- 缺少项目脚手架:创建新项目多从旧项目中复制黏黏基础代码,无法保证持续的更新;
- 代码质量难度量:缺乏代码质量管理平台,大数项目缺乏单元测试。
鉴于以上原因,开源软件及产品被列入首选,同时结合现实情况及需求在开源的基础上进行功能的扩展开发。只有实在没有选择的情况下,我们才会考虑自造轮子。
- Netflix OSS 经过了大规模的生产级验证,功能强大,组件丰富
- SpringCloud 基于 SpringBoot,社区支持强大,有着开发效率高、更新频率快、等优势,且集成了 Netflix 的众多组件,降低了使用门槛,它能够与同样使用 SpringBoot 的原有服务完美兼容,降低接入的时间和人工成本。
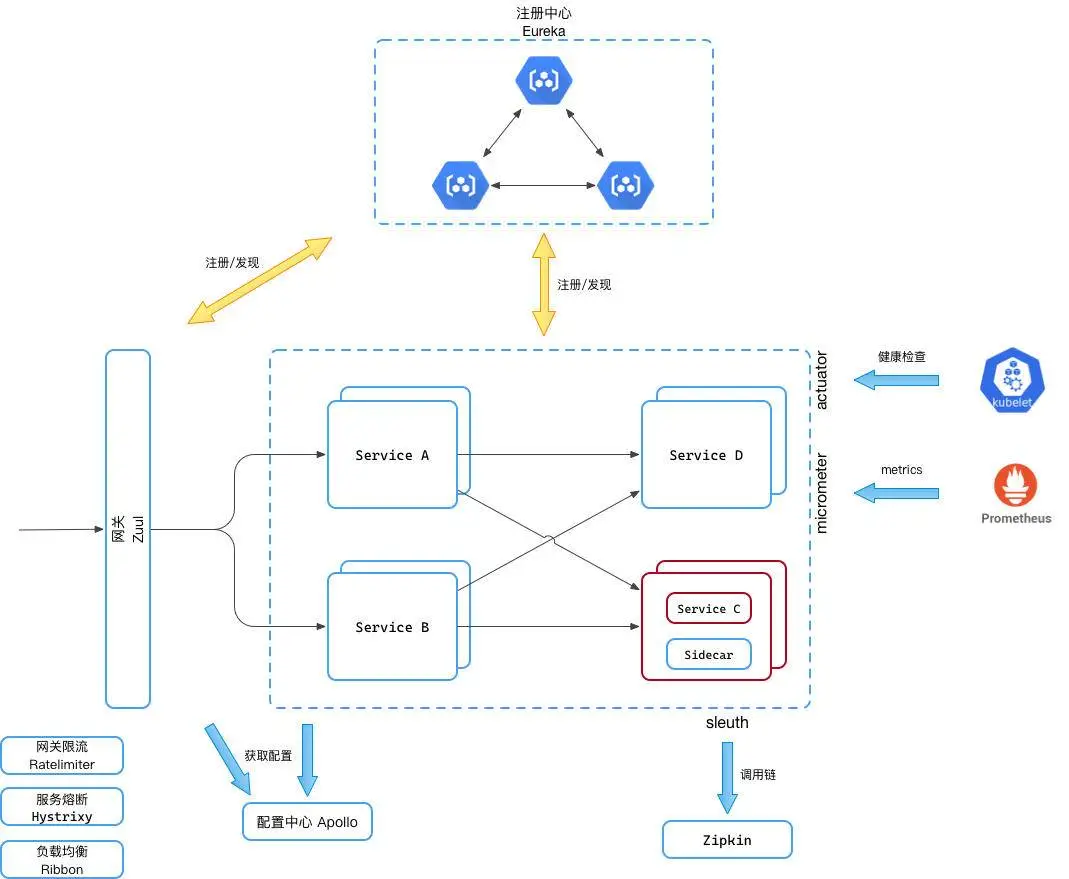
部分正在使用的组件:
- API 网关 Zuul
- 服务注册发现 Eureka:基于 AP 模型
- 客户端负载均衡 Ribbon
- 服务熔断 Hystrix
- 声明式的服务调用 Feign
- 边车 Sidecar:集成了服务注册和发现,以及 Zuul 用于实现跨语言的微服务调用
- 分布式跟踪 Sleuth & Zipkin:支持 OpenTracing 协议
- 网关限流 spring-cloud-zuul-ratelimit:结合 Zuul 一起使用,支持路径、请求源、用户等维读的请求限流
- 应用指标数据 Micrometer:支持 prometheus
- 扩展包 Actuator:提供管理接口
- 服务管理及监控 SpringBoot Admin
- 自动 API 文档 Auto Restdoc:减少代码侵入
- 配置中心 Apollo:携程出品的配置中心实现,支持配置的热更新(借助 SpringCloud 的 Context Refresh 概念
- 数据库连接池 Hikari:支持输出 metrics
- 自研项目生成器、文档中心等
- …
此外,中台通过自定义的 SDK 提供对上述功能开箱即用,包含组件的配置调优、Metrics 输出、统一日志、框架 Bug 的紧急修复以及功能扩展。
2
系统架构
三、可用性提升
参考官方的文档,跑个 DEMO 是很容易的,但是真正在生产级环境中使用又会踩不少坑。
可用性对于车企来说尤为重要,甚至说高于一切也毫不夸张,公司对这一方面也格外重视。
经过两年的不断踩坑填坑,同时借助云平台的能力(比如自我修复、滚动升级等功能)提升了系统的可用性;同时降低应用发布时对业务的影响:从原本的低峰时间版本升级,提升到随时部署升级,甚至部分服务已经可以实现自动扩缩容。
下面列出我们踩过的一部分坑,也是我们不断修炼提升可用性过程中关注的问题点。
1
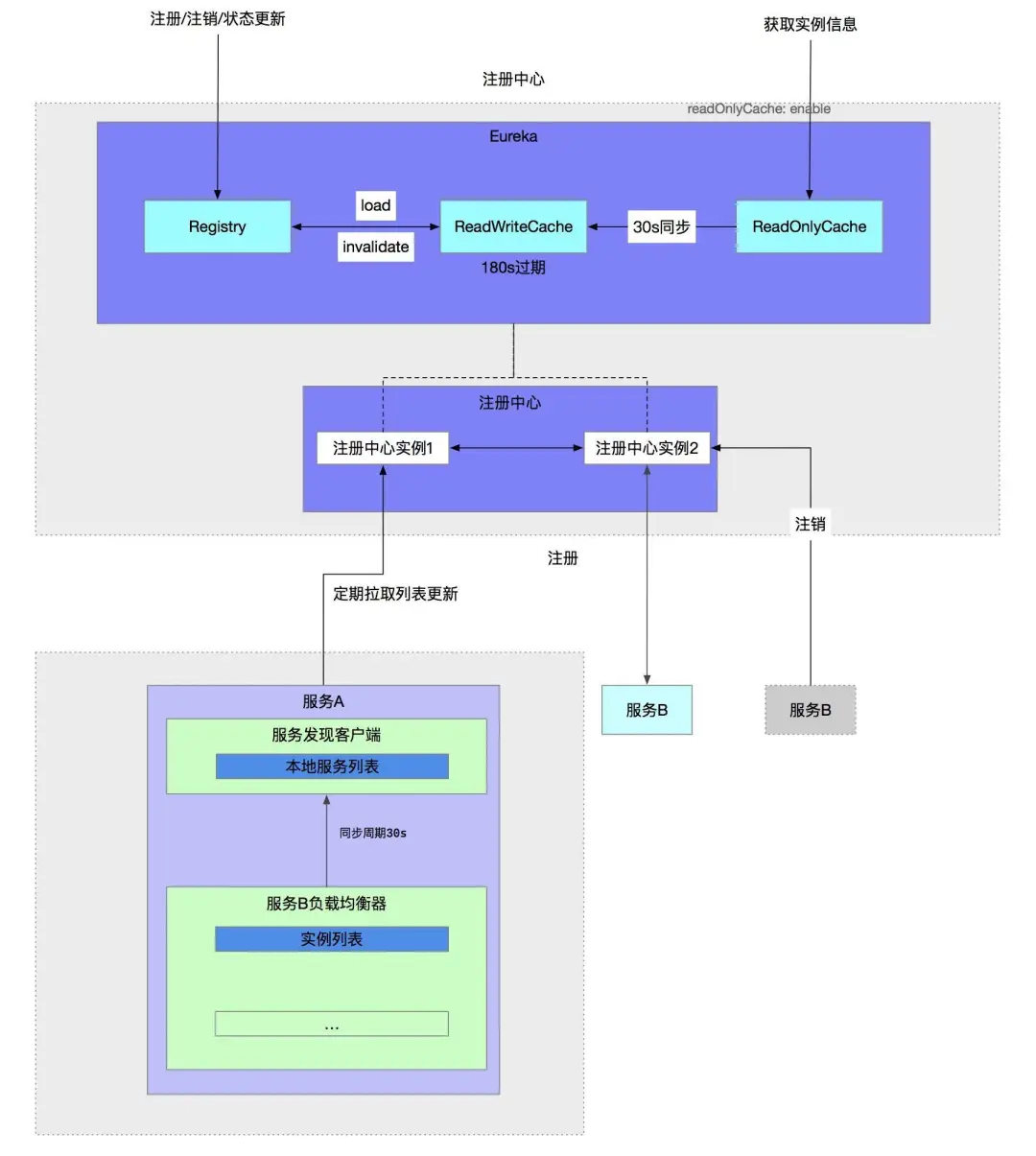
a. 服务实例上下线的被发现延迟
使用默认配置的情况下,实例正常上、下线的被发现延迟最大为 90s ,比如,服务 B(提供方)的一个实例上 / 下线,服务 A(调用方)在最长 90s 之后才会发现。这与 Netflix 的设计有关:
- Eureka 服务端的三级缓存模型
- a. registry :存储服务实例信息 (服务上下线实时更新)
- b. readWriteCacheMap :读写缓存 (实时从 registry 中更新,过期时间 180s )
- c. readOnlyCacheMap :只读缓存,默认从这里获取服务信息 (每隔 30s 从 readWriteCacheMap 更新)
- Eureka 消费端每隔 30s 请求 Eureka 服务端获取增量更新,然后更新本地服务列表
- Ribbon 客户端每隔 30s 从 Eureka 客户端的本地服务列表中
可通过修改配置缩短上下线的被发现延迟:
- 缩短 readOnlyCacheMap 的更新周期
- 缩短服务消费端获取增量更新的周期
- 缩短 Ribbon 客户端从 Eureka 客户端的本地服务列表的更新周期;或者将拉的模式,改成推的模式 (需要代码提供新的实现)
b. 非正常下线的被发现延迟
上面提到默认配置下被发现的延迟最大是 90s。运行过程中不可避免的会出现非正常下线的情况,比如进程被强杀(kill -9),实例来不及通知注册中心进行注销操作就退出了。这种情况下,此实例的信息会存在服务调用方的 Ribbon 、实例列表中最长达 240s。如果是 2 个实例的话,会有 50% 的请求受到影响。这同样源于 Netflix 的设计:
- 实例上线完成注册后,会每个 30s 向注册中心(Eureka 服务端)发送心跳请求
- 实例续约超时时间:实例超过 90s 未发送发送心跳才会被注册中心清理
- 注册中心的清理操作是个定时任务,间隔 60s
可通过修改配置缩短上下线的被发现延迟:
- 缩短心跳间隔
- 缩短实例约的超时时间
- 缩短清理任务的工作周期
c. 自我保护模式到底开不开?
Eureka 是基于 CAP 理论的 AP 模型,用于保证分区容错性,但这也导致注册信息在网络分区期间可能出现不一致,自我保护功能是为了尽可能减少这种不一致。
自我保护(self preservation)是 Eureka 的一项功能,Eureka 注册表在未收到实例的心跳情况超过一定阈值(默认:85%)时停止驱逐过期的实例。
解决了 b 中的延迟问题,必然会导致自我保护模式不准确。
解释自我保护模式的工作原理,需要另开一篇文章来说。
d. 一个深坑
解决了 b 中的延迟问题,还会带来一个坑更深的坑:极低的概率下,实例启动后本地处于 UP 状态,而远端(注册中心)的状态持续处于 STARTING 状态,且无法更新。这会导致实例实际正常运行,而且对服务消费者不可见。
这种情况在 Kubernetes 环境下尤为恐怖:实例本地状态为 UP ,健康状态也为 UP 。在 Kubernetes 的滚动升级模式下,旧的实例为删除,新的实例正常运行,却对消费端不可见。
问题的分析、重现方式已经记录在 Netflix Eureka 的 issue(又是一长篇,目前只有英文)中,Pull Request 也已经合并到了 1.7.x 分支。不过嘛,呵呵,一直没有发布新版本。
注:在技术中台运行一年多,生产环境累计出现的次数不到 10 次,不是 2 个实例运行的情况下没有对请求出现影响。
2
Ribbon 的容错
Ribbon 大家常听到的就是负载均衡,但是除了负载均衡之外,它还提供容错的能力:重试 。
- 遇到异常时进行重试:默认是 ConnectException 和 SocketTimeoutException ;
- 重试次数:单个实例的重试次数( ribbon.MaxAutoRetries 默认:0),重试几个实例( ribbon.MaxAutoRetriesNextServer 默认:1)。怎么理解?比如 A 有 4 个实例:a1、a2、a3、a4。路由请求到 a1 的时报 ConnectException 异常,重试的时候不会再对 a1 进行重试(单个实例重试次数 0)。假如重试的对象 a2 也报同样的异常,则会放弃继续重试(重试 1 个实例);
- 是否对所有操作重试:ribbon.OkToRetryOnAllOperations (默认:false ,即只对满足条件的 GET 请求进行重试),其实对应的也就是常说的 HTTP 动词:GET 、 POST 、 DELTE 等等。
这里有个隐藏的坑,就是加入开启了对所有操作重试的情况下,且出现 SocketTimeoutException 时,可能会导致一致性的问题:
因为 SocketTimeoutException 不只是连接超时,还有读取超时 。假如一个 POST 请求会更新数据库,出现客户端的读取超时 ,但是服务端可能在客户端断开后完成的更新的操作。如果客户端进行重试,则会再次进行更新。
3
SpringBoot Tomcat
SpringBoot Tomcat 的优雅退出,不知为何官方没有实现,实在匪夷所思。
为什么需要优雅退出?当 Spring 上下文关闭时,假如有未处理完的请求,不等请求处理完毕就直接退出。从健壮性或者一致性方面考虑,并不是一个好的解决方案。
理想的方案:收到 Spring 上下文关闭事件,阻止 Connector 接受新的请求,然后对线程池执行 #shutdown() 的操作并等待队列中的请求处理完成。当然这里不能无限期的等待下去(滚动升级无法继续),设置一个超时时间比如 30s 或者 60s。如果还没执行完,那就是执行 #shutdownNow() ,让未完成的操作自求多福吧。
4
HttpClient 连接池的 Keep-Alive
,其中也提供 Keep-Alive 相关的配置:
keepAliveTimeout: 默认为 60s. 见 org.apache.coyote.http11.Constants#L28.
>maxKeepAliveRequests: 默认为 100. 设置为 1, 禁用 keep alive; 设置为 -1, 无限制.
SpringBoot 中通过 server.connectionTimeout 来设置 Tomcat 的 keepAliveTimeout ,如果未设置,则使用 Tomcat 的默认配置。
大写的但是 :Tomcat 并没有在响应头部带上 Keep-Alive:timeout=60 。
可通过增加过滤器 — 在响应头部增加 Keep-Alive 的 timeout 配置的方式来解决。
5
滚动升级时的可用性保障
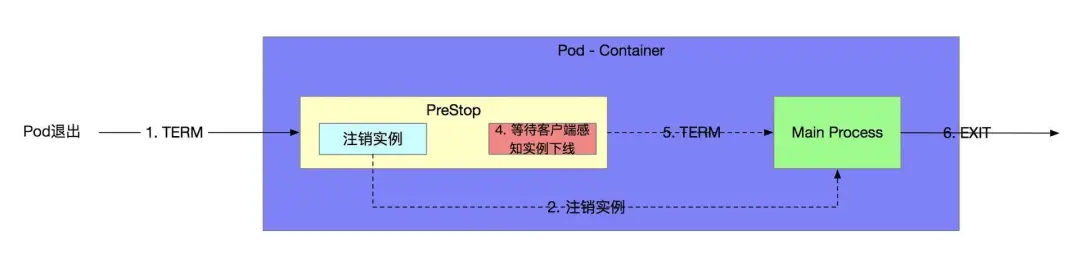
微服务中台运行于云平台之上,应用的升级模式为滚动升级:对服务进行升级时会先创建新版本的实例,待相应的检查(借助 Actuator 提供的 /health 接口)通过后,再将旧版本的实例下线。
即使完成 3.1 中 a 和 b 两项的优化,旧的实例还会存在于消费端的本地缓存中一段时间,当然,借助 Ribbon 的容错可以避开这个问题,但是重试会降低吞吐。
借助 Kubernetes 的 Pod 的 preStop lifecycle hook,在 Pod 退出时会先调用 preStop 配置的脚本。在脚本中调用本地服务的 /service-registry/instance-status 接口,将实例的状态修改为 DOWN ,并等待一段时间(比如 30s)。之后才会将退出信号放行到容器中,完成后续的退出动作。以此来降低 Eureka AP 模型带来的不一致隐患。
四、功能扩展
1
跨语言的微服务调用
小鹏汽车的业务比较复杂,除了主要的 Java 技术栈之外,还有基于 CPU/GPU 的 Python 应用,以及 Node.js 应用和前端应用。
而中台的出发点是功能的复用,如何让非 Java 语言的应用使用到中台的能力?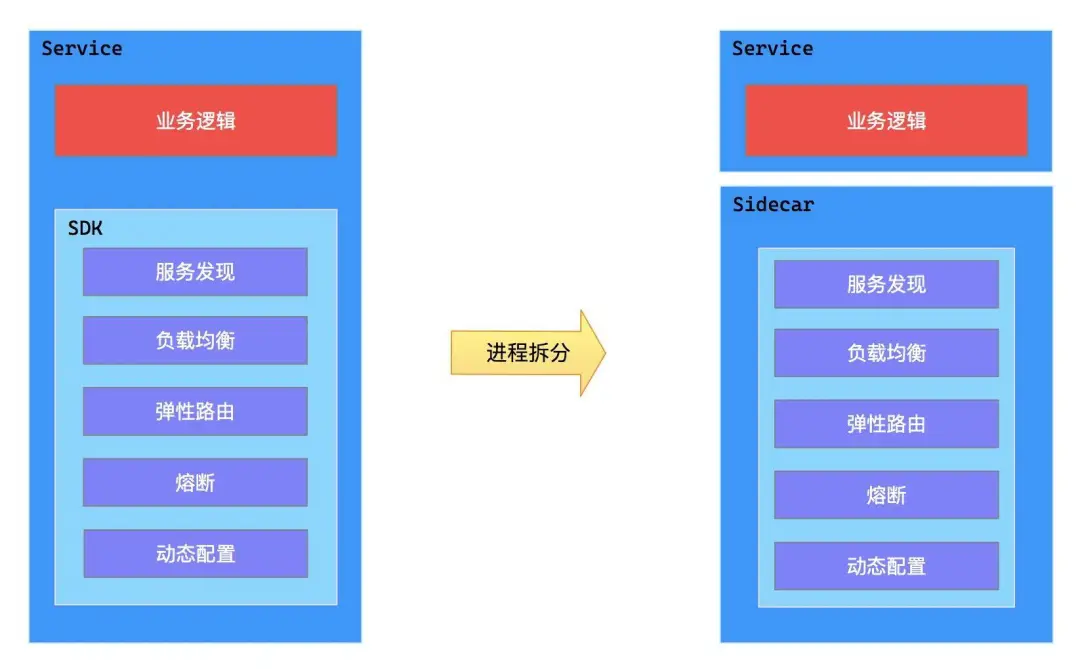
我们的做法是借助 Sidecar 模式实现基础功能下沉,与应用解耦,将 SDK 中的功能,下沉到独立进程中。
对于我们运行在 Kubernetes 上的应用来说,实现这一点就更容易了:在 Pod 中增加一个 Sidecar 的容器。
同时 Sidecar 还给我们带来了意想不到的效果:
- 通过抽象出与功能相关的共同基础设施到一个独立进程,降低了微服务代码的复杂度;
- 因为你不再需要编写相同的第三方组件配置文件和代码,所以能够降低微服务架构中的代码重复度;
- 降低应用程序代码和底层平台的耦合度,使应用聚焦于业务功能,也方便基础设施的迭代演进。
当然目前的实现也不是很完美,sidecar 的实现,我们用的是 spring-cloud-netflix-sidecar 。是的,Java 的实现很重,对资源还存在一定的浪费。但是战略有了,战术的选择是多样的,比如 C++ 实现的 Envoy 。
因此当前的方案 不只是一次尝试,也是一个布局 。
2
统一日志
服务的容器化,允许我们在统一了日志格式后,将日志直接输出到标准输出 / 错误。通过 Docker 的 json-file driver 统一落盘到 Node(Kubernetes 的工作节点)上。再经由以 DaemonSet 方式运行采集器挂在日志目录对日志进行采集。
详细的工作方式及调优,请期待云平台实践篇(云平台的能力不仅限于此)。
五、CICD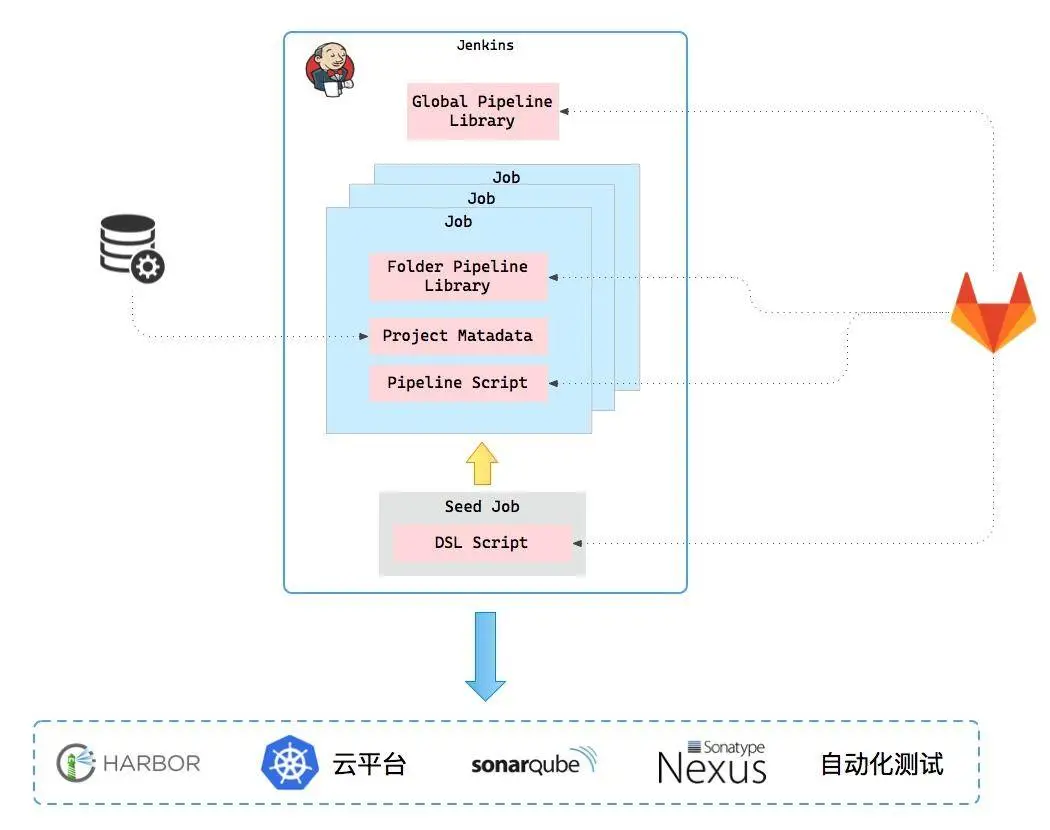
技术中台同样提供了基于 Jenkins 流水线(Pipeline)的 CICD 平台,经历过两个阶段:项目级的流水线和平台级的流水线。
这两个流水线有什么不同?这个跟平台的发展阶段相关。平台发展之初,由于团队规模小,在 CICD 平台上投入的成本相对较少。由于一开始接入的系统不多,流水线的脚本都放在各个项目的代码仓库中(项目级的流水线),每次脚本更新都要去各个项目中更新。随着接入的系统越来越多,更新的成本变得越来越高。
因此我们在后续的演进中进一步将流水线提升到平台级,即平台上的系统使用统一的流水线脚本,脚本保存在 GitLab 仓库中,并提供版本控制。
借助 Job DSL 插件,我们将抽象的项目元数据转化为 Jenkins 作业。在项目注册到平台时,会自动为其创建作业。
每个作业的结构基本一致,包含:
- Folder Pipeline Library:与 Global Pipeline Library 一样,都是 Shared Library 的实现。区别是前者包含的是项目相关的信息,比如所处的 Gitlab(存在多个 Gitlab)的访问信息。后者是所有作业共享的,包含了构建脚本;
- Project Metadata:抽象项目的元数据,比如名称、仓库地址、语言等;
- Pipeline Script:流水线的入口,启动之后使用 Global Pipeline Library 中的构建脚本进行构建。
外部对接云平台、Sonar、Nexus 以及自动化测试平台。
六、总结
微服务中台不仅仅是技术上的开发工作,还包括中台的落地,以及打造各种配套的功能设施,比如流程的简化、DevOps 还有表面上无法体现的各种优化和修复工作。
后续除了云平台,我们还会分享一些其他方向的经验。“生命不止,奋斗不息”,小鹏汽车的技术中台也会持续演进。

若有收获,就点个赞吧
0 人点赞
