正则表达式:是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
$ cat readme.txtWelcome to Biotrainee() !This is your personal account in our Cloud.Have a fun with it.Please feel free to contact with me( email to jmzeng1314@163.com )(http://www.biotrainee.com/thread-1376-1-1.html)
^ 行首匹配
$ cat readme.txt | grep '^T'

$行尾匹配
$ cat readme.txt | grep ')$'

. 任一单字符
$ cat readme.txt | grep 'f.el'

? 匹配之前项0次或者一次,必须有一个前项,后项常为筛选条件
$ cat readme.txt | grep 'f\?ee'

* 匹配前项0次或者多次,必须有一个前项,后项常为筛选条件
$ cat readme.txt | grep 'f*ee'

+ 匹配前项1次或者多次,必须有一个前项
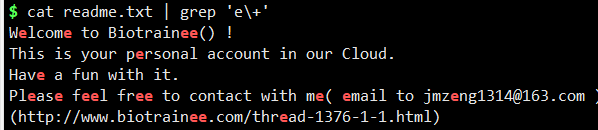
$ cat readme.txt | grep 'e\+'
{n} 匹配前项n次
$ cat readme2.txt | grep 'e\{2\}'

{n,} 匹配前项至少n次
$ cat readme2.txt | grep 'e\{2,\}'

{m,n} 匹配前项至少m,最多n
$ cat readme2.txt | grep 'e\{2,4\}'

[ ] 匹配任意一个字符
$ cat readme2.txt | grep [Hh]

[^] 排除某一个字符
$ cat readme2.txt | grep [^Hh]

| 或 ,在引号里面
cat readme2.txt | grep -E 'ee|We'

练习

1.精确匹配example.gtf中的gene,并统计
2.匹配exon的行,然后反向输出
3.匹配CDS或者UTR的行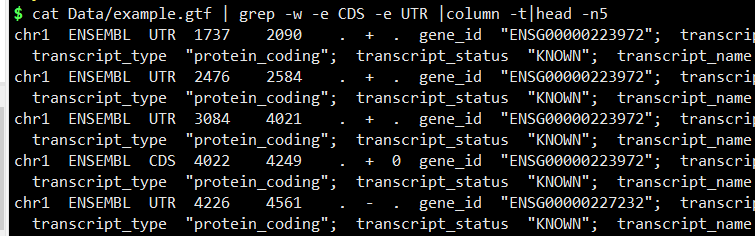
4.查找example.fq文件包含@ 的行并统计
5.查找example.fq文件以@开头的行并统计

若有收获,就点个赞吧
0 人点赞
