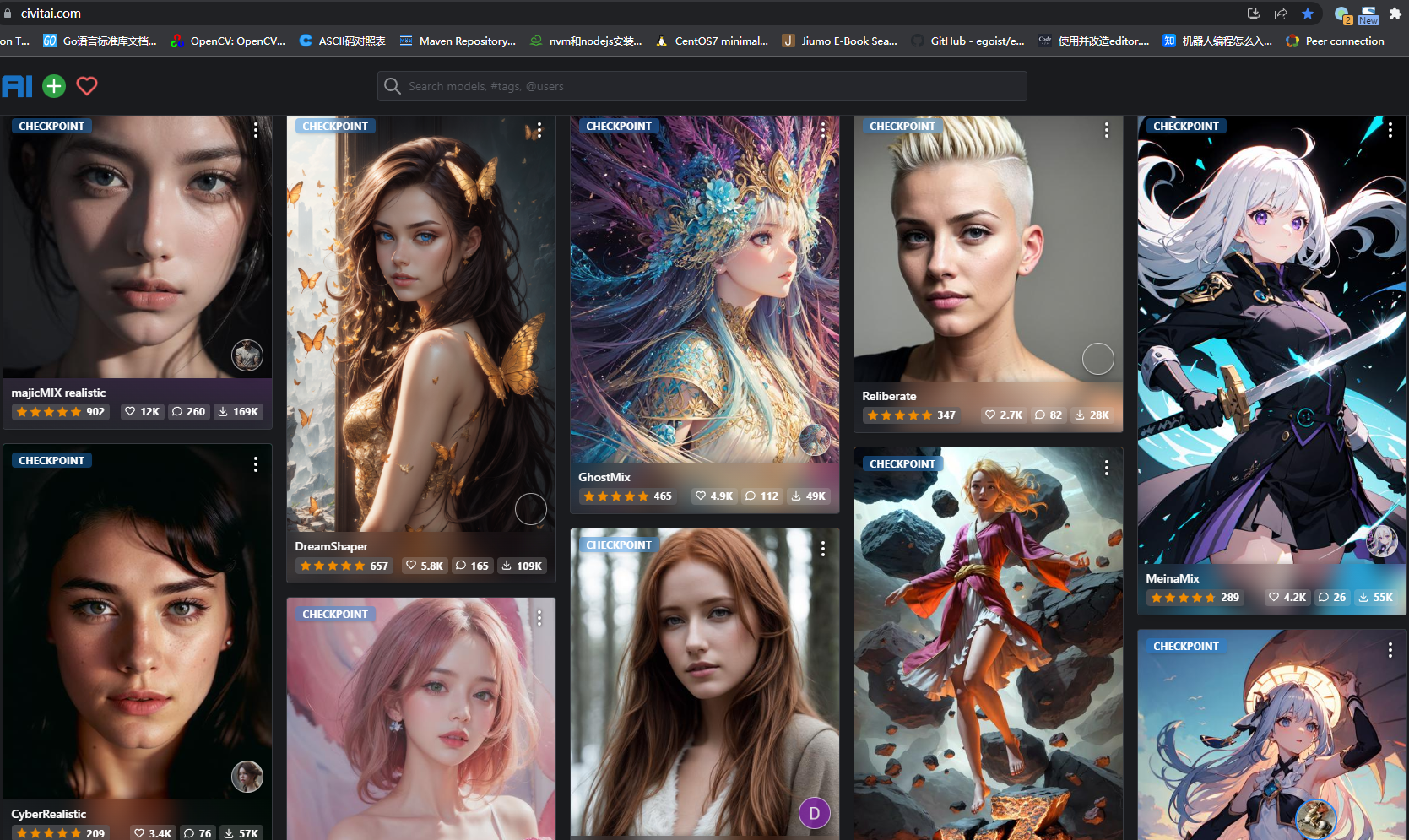
Stable Diffusion是一个文本到图像的潜在扩散模型,由CompVis、Stability AI和LAION的研究人员和工程师创建。它使用来自LAION-5B数据库子集的512x512图像进行训练。使用这个模型,可以生成包括人脸在内的任何图像,因为有开源的预训练模型,所以我们也可以在自己的机器上运行它。例如下面这张图就是由Stable Diffusion生成。
它的安装和使用都比较简单,我们在本地部署,只需要执行脚本,即可快速搭建它的环境。
安装
下载Stable Diffusion源码
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
执行
webui-user.bat- 使用虚拟目录中的pip安装依赖
参考安装视频教程venv\Scripts\Python.exe -m pip install -r requirements.txt
下载模型
模型安装
将下载下来的模型,放到stable duffusion工程目录下的stable-diffusion-webui\models\Stable-diffusion文件夹中,例如我的目录如下: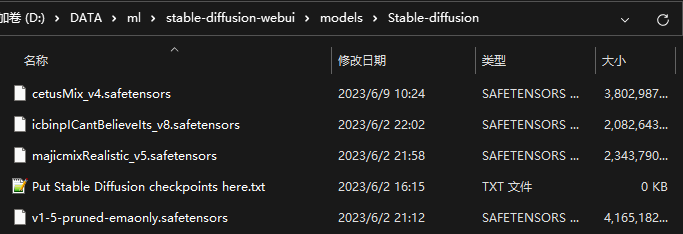
启动测试
- 在命令行中,执行
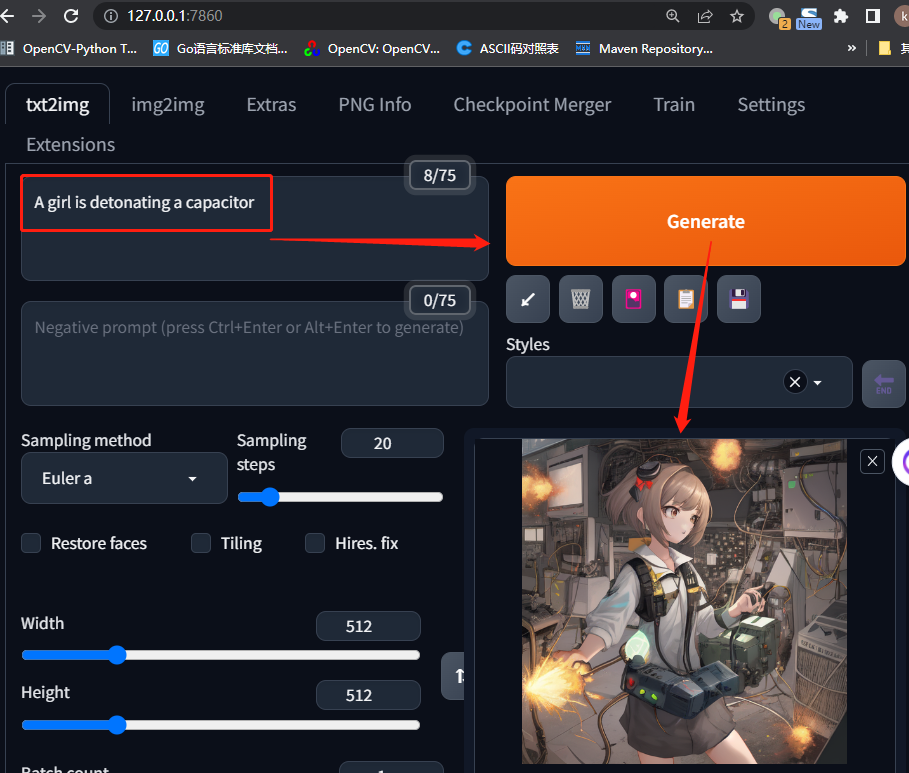
webui-user.bat - 启动成功之后,在浏览器中打开连接:http://127.0.0.1:7860
- 参考演示链接:https://www.bilibili.com/video/BV1Eh4y1R7tK/?vd_source=7f8db038f5b15fc65152acdd1a36198a

若有收获,就点个赞吧
0 人点赞
