机器视觉概述
机器视觉是人工智能正在快速发展的一个分支。简单说来,机器视觉就是用机器代替人眼来做测量和判断。机器视觉系统是通过机器视觉产品(即图像摄取装置,分CMOS和CCD两种)将被摄取目标转换成图像信号,传送给专用的图像处理系统,得到被摄目标的形态信息,根据像素分布和亮度、颜色等信息,转变成数字化信号;图像系统对这些信号进行各种运算来抽取目标的特征,进而根据判别的结果来控制现场的设备动作。
OpenCV是一个基于BSD许可(开源)发行的跨平台计算机视觉库,可以运行在Linux、Windows、Android和Mac OS操作系统上。它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
面临的挑战
视角变化

光照变化

尺寸变化

形态变化
背景混淆

遮挡

类内物体的外观差异

Opencv入门案例
读取图片

本节我们将来学习,如何使用opencv显示一张图片出来,我们首先需要掌握一条图片读取的api
cv.imread("图片路径","读取的方式")# 图片路径: 需要在工程目录中,或者一个文件的绝对路径# 读取方式: 分别有如下三种:cv.IMREAD_COLOR : 以彩图的方式加载,会忽略透明度(默认方式)cv.IMREAD_GRAYSCALE: 以灰色图片方式加载cv.IMREAD_UNCHANGED: 直接加载,透明度会得到保留
示例代码如下:
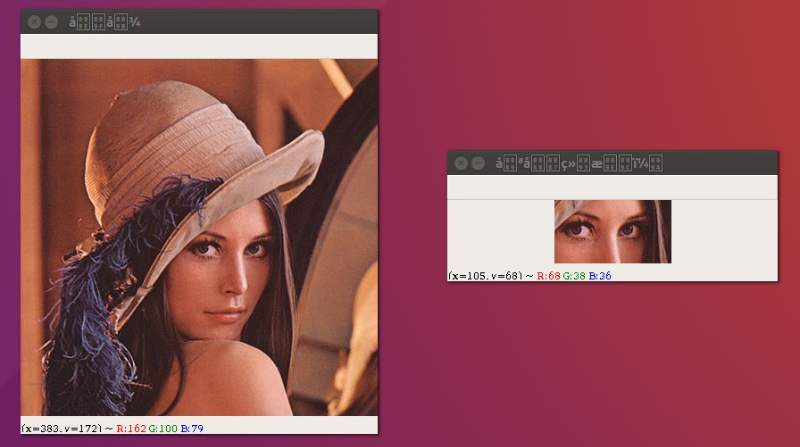
import cv2 as cv# 读取图片 参数1:图片路径, 参数2:读取的方式img = cv.imread("img/lena.png",cv.IMREAD_COLOR)# 显示窗口 参数1:窗口名称, 参数2:图片数据cv.imshow("src",img)# 让程序处于等待推出状态cv.waitKey(0)# 当程序推出时,释放所有窗口资源cv.destroyAllWindows()
写入文件
刚才我们知道,如何读取文件,接下来,我们来学习如何将内存中的图片数据写入到磁盘中!
暂时我们还没有学习,如何直接代码构建一张图片,为了演示,我们先读取一张图片,然后再将它写入到文件中,后面我们会学习如何直接内存中构建一张图片
import cv2 as cvimg = cv.imread("img/lena.png", cv.IMREAD_UNCHANGED)# 将图片写入到磁盘中,参数1: 图片写入路径,参数2: 图片数据cv.imwrite("img/lena_copy.png",img)cv.waitKey(0)cv.destroyAllWindows()
理解像素
![]()
当我们将一张图片不断放大之后,我们就可以看到这张图片上一个个小方块,这里面的每一个小方块我们就可以称之为像素点! 任何一张图片,都是有若干个这样的像素所构成的!
操作像素
为了便于大家能够理解像素,我们现在手工来创建一张图片,例如我们使用np.zeros这样的函数可以创建一个30x40的矩阵,那个这个矩阵其实就可以表示一张图片,矩阵中每一个元素都是一个像素点,每个像素点又由BGR三部分组成,这里我们需要强调一下Opencv中,颜色空间默认是BGR不是RGB,所以我们想表示红色需要使用(0,0,255),想表示绿色需要(0,255,0)
下面我们就来操作图片,在图片的正中央增加一根红色的线!
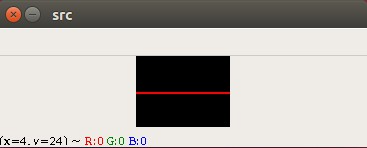
这里我直接给出示例代码,然后我们来看一下运行效果吧!
import cv2 as cvimport numpy as np# 构建一个空白的矩阵img = np.zeros((30,40,3),np.uint8)# 将第15行所有像素点全都改成红色for i in range(40):# 设置第15行颜色为红色img[15,i] = (0,0,255)# 显示图片cv.imshow("src",img)cv.waitKey(0)cv.destroyAllWindows()
就这样我们的图片正中间就多了一根红色的线
Opencv图像处理基础
图片的几何变换
图片剪切
正如我们前面所学到的,图片在程序中表示就是一个矩阵,我们要想操作图片,只需要操作矩阵元素就可以了.
接下来,我们要来完成图片的剪切案例,其实我们只需要想办法截取出矩阵的一部分即可!
在python中,矩阵的截取是很容易的一件事!例如如下代码
mat[起始行号:结束行号,开始列号:结束列号]
import cv2 as cv# 读取原图img = cv.imread("img/lena.jpg",cv.IMREAD_COLOR)cv.imshow("source",img)# 从图片(230,230) 截取一张 宽度130,高度70的图片dstImg = img[180:250,180:310]# 显示图片cv.imshow("result",dstImg)cv.waitKey(0)
图片镜像处理
图片的镜像处理其实就是将图像围绕某一个轴进行翻转,形成一幅新的图像. 我们经常可以通过某个小水坑看到天空中的云, 只不过这个云是倒着的! 这个就是我们称为的图片的镜像!
下面我们来看这样一个示例吧!我们将lena这张图片沿着x轴进行了翻转

如果我们想在一个窗口中显示出两张图片,那么我们就需要知道图片的宽高信息啦!
如何获取呢? 看下面的示例代码:
imgInfo = img.shapeimgInfo[0] : 表示高度imgInfo[1] : 表示宽度imgInfo[2] : 表示每个像素点由几个颜色值构成
知道了上述信息之后,我们就可以按照如下步骤实现啦!
实现步骤:
- 创建一个两倍于原图的空白矩阵
- 将图像的数据按照从前向后,从后向前进行绘制
代码实现
import cv2 as cvimport numpy as npimg = cv.imread("img/lena.jpg", cv.IMREAD_COLOR)imgInfo = img.shapeheight = imgInfo[0]width = imgInfo[1]# 创建一个两倍于原图大小的矩阵dstImg = np.zeros((height*2,width,3),np.uint8)# 向目标矩阵中填值for row in range(height):for col in range(width):# 上部分直接原样填充dstImg[row,col] = img[row,col]# 下半部分倒序填充dstImg[height*2-row-1,col] = img[row,col]# 显示图片出来cv.imshow("dstImg",dstImg)cv.waitKey(0)cv.destroyAllWindows()
图片缩放
对于图片的操作,我们经常会用到,放大缩小,位移,还有旋转,在接下来的课程中,我们将来学习这些操作!
首先,我们来学习一下图片的缩放
关于图片的缩放,常用有两种:
- 等比例缩放
- 任意比例缩放
要进行按比例缩放,我们需要知道图片的相关信息,我们可以通过
imgInfo = img.shapeimgInfo[0] : 表示高度imgInfo[1] : 表示宽度imgInfo[2] : 表示每个像素点由几个颜色值构成
图片缩放的常见算法:
- 最近领域插值
- 双线性插值
- 像素关系重采样
- 立方插值
默认使用的是双线性插值法,这里我们给出利用opencv提供的resize方法来进行图片的缩放
import cv2 as cv# 读取一张图片img = cv.imread("img/lena.jpg", cv.IMREAD_COLOR)# 获取图片信息imgInfo = img.shapeprint(imgInfo)# 获取图片的高度height = imgInfo[0]# 获取图片的宽度width = imgInfo[1]# 获取图片的颜色模式,表示每个像素点由3个值组成mode = imgInfo[2]# 定义缩放比例newHeight = int(height*0.5)newWidth = int(width*0.5)# 使用api缩放newImg = cv.resize(img, (newWidth, newHeight))# 将图片展示出来cv.imshow("result",newImg)cv.waitKey(0)cv.destroyAllWindows()
图片操作原理
我们在前面描述过一张图片,在计算机程序中,其实是用矩阵来进行描述的,如果我们想对这张图片进行操作,其实就是要对矩阵进行运算.
矩阵的运算相信大家在前面课程的学习中,已经学会了,下面我们来给大家列出常见的几种变换矩阵
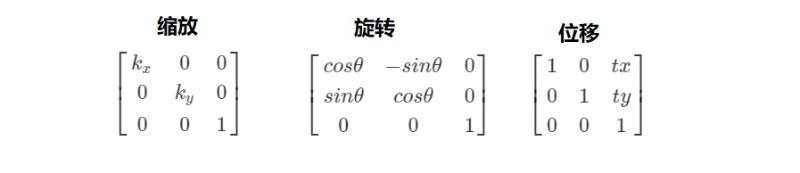
这里我给大家演示的是图片的位移操作,将一个矩阵的列和行看成坐标系中的x和y我们就可以轻易的按照前面我们所学过的内容来操作矩阵啦!
import cv2 as cvimport numpy as npimg = cv.imread("img/lena.jpg", cv.IMREAD_COLOR)imgInfo = img.shapeheight = imgInfo[0]width = imgInfo[1]# 创建一个和原图同样大小的矩阵dstImg = np.zeros((height,width,3),np.uint8)for row in range(height):for col in range(width):# 补成齐次坐标sourceMatrix = np.array([col,row,1])matrixB = np.array([[1,0,50],[0,1,100]])# 矩阵相乘dstMatrix = matrixB.dot(sourceMatrix.T)# 从原图中获取数据dstCol = int(dstMatrix[0])dstRow = int(dstMatrix[1])# 防止角标越界if dstCol < width and dstRow < height:dstImg[dstRow,dstCol] = img[row,col]# 显示图片出来cv.imshow("dstImg",dstImg)cv.waitKey(0)
图片移位
刚才我们采用的是纯手工的方式来操作图片,其实我们完全没必要那样做,opencv中已经帮我们提供好了相关的计算操作,我们只需提供变换矩阵就好啦!
cv.warpAffine(原始图像,变换矩阵,(高度,宽度))
下面是位移的示例代码:
import cv2 as cvimport numpy as npimg = cv.imread("img/lena.jpg",cv.IMREAD_COLOR)imgInfo = img.shapeheight = imgInfo[0]width = imgInfo[1]# 定义位移矩阵matrixShift = np.float32([[1,0,50],[0,1,100]])# 调用apidstImg = cv.warpAffine(img,matrixShift,(width,height))cv.imshow("dst",dstImg)cv.waitKey(0)
图片旋转
图片的旋转其实也是很简单的,只不过默认是以图片的左上角为旋转中心
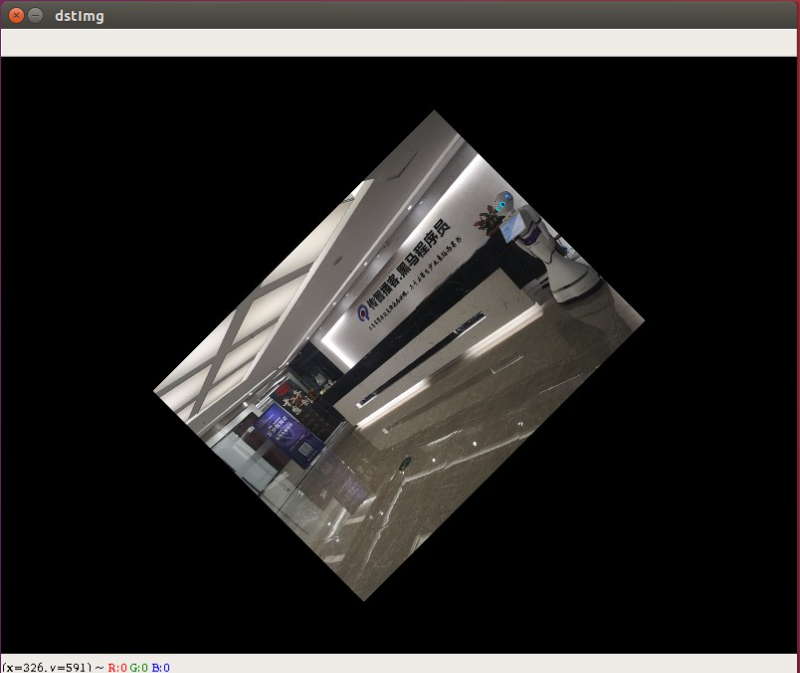
import cv2 as cvimg = cv.imread("img/itheima.jpg", cv.IMREAD_COLOR)imgInfo = img.shapeheight = imgInfo[0]width = imgInfo[1]# 定义仿射矩阵: 参数1:中心点, 参数2:旋转角度,参数3:缩放系数matrixAffine = cv.getRotationMatrix2D((width * 0.5, height * 0.5), 45, 0.5)# 进行仿射变换dstImg = cv.warpAffine(img, matrixAffine, (width, height))cv.imshow("dstImg",dstImg)cv.waitKey(0)
图片仿射变换
仿射变换是在几何上定义为两个向量空间之间的一个仿射变换或者仿射映射(来自拉丁语,affine,“和…相关”)由一个非奇异的线性变换(运用一次函数进行的变换)接上一个平移变换组成。
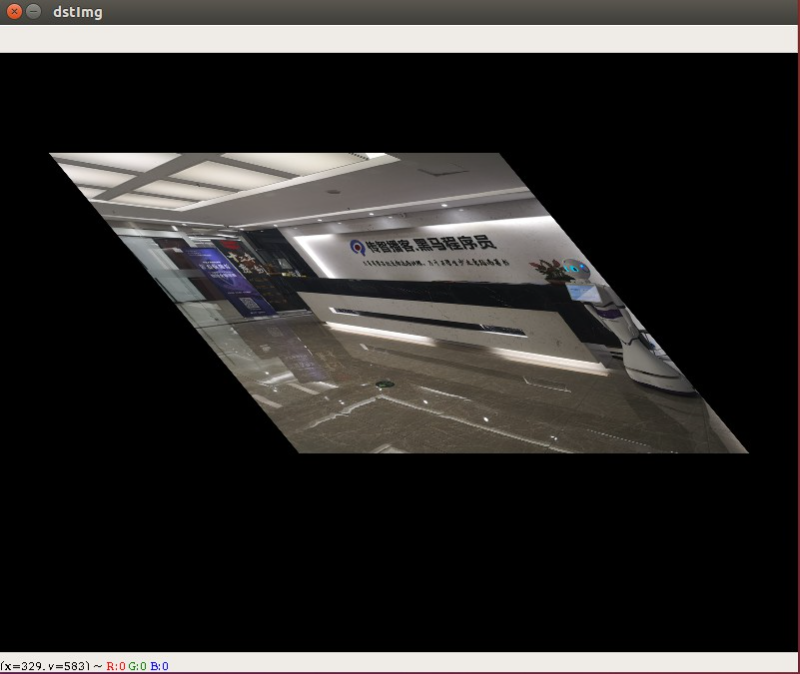
示例代码
import cv2 as cvimport numpy as npimg = cv.imread("img/itheima.jpg", cv.IMREAD_COLOR)imgInfo = img.shapeheight = imgInfo[0]width = imgInfo[1]# 定义图片 左上角,左下角 右上角的坐标matrixSrc = np.float32([[0,0],[0,height-1],[width-1,0]])# 将原来的点映射到新的点matrixDst = np.float32([[50,100],[300,height-200],[width-300,100]])# 将两个矩阵组合在一起,仿射变换矩阵matrixAffine = cv.getAffineTransform(matrixSrc,matrixDst)dstImg = cv.warpAffine(img,matrixAffine,(width,height))cv.imshow("dstImg", dstImg)cv.waitKey(0)
图像金字塔
图像金字塔是图像多尺度表达的一种,是一种以多分辨率来解释图像的有效但概念简单的结构。一幅图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,且来源于同一张原始图的图像集合。其通过梯次向下采样获得,直到达到某个终止条件才停止采样。我们将一层一层的图像比喻成金字塔,层级越高,则图像越小,分辨率越低。
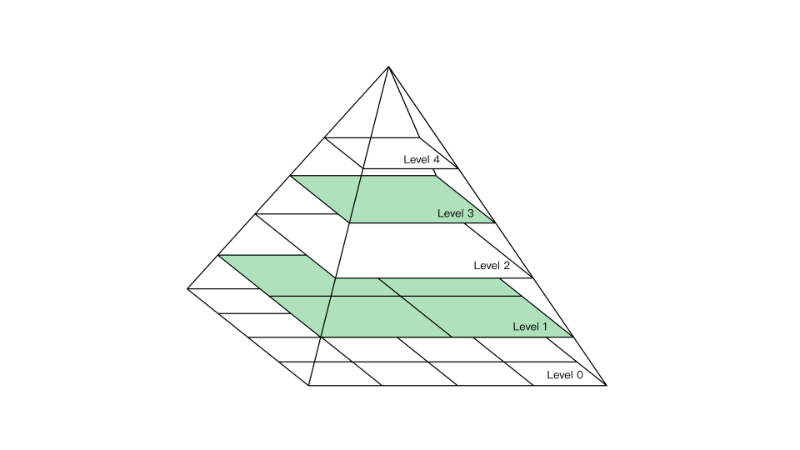
降低图像的分辨率,我们可以称为下采样
提高图像的分辨率,我们可以称为上采样
下面我们来测试一下采用这种采样操作进行缩放和我们直接进行resize操作他们之间有什么差别!
我们可以看到,当我们对图片进行下采样操作的时候,即使图片变得非常小,我们任然能够看到它的轮廓,这对后面我们进行机器学习是非常重要的一步操作
,而当我们直接使用resize进行操作的时候,我们发现图片似乎不能完全表示它原有的轮廓,出现了很多的小方块!
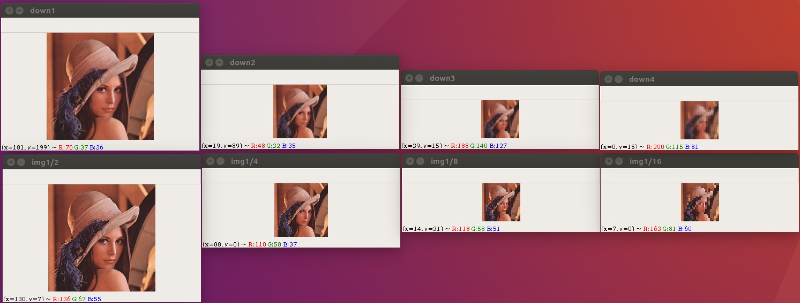
下面这里是我们当前案例的示例代码
import cv2 as cv;src_img = cv.imread("img/lena.jpg",cv.IMREAD_COLOR);imgInfo = src_img.shapeheight = imgInfo[0]width = imgInfo[1]pry_down1 = cv.pyrDown(src_img)cv.imshow("down1",pry_down1)pry_down2 = cv.pyrDown(pry_down1)cv.imshow("down2",pry_down2)pry_down3 = cv.pyrDown(pry_down2)cv.imshow("down3",pry_down3)pry_down4 = cv.pyrDown(pry_down3)cv.imshow("down4",pry_down4)pyr_up1 = cv.pyrUp(pry_down1)cv.imshow("up1",pyr_up1)pyr_up2 = cv.pyrUp(pry_down2)cv.imshow("up2",pyr_up2)pyr_up3 = cv.pyrUp(pry_down3)cv.imshow("up3",pyr_up3)pyr_up4 = cv.pyrUp(pry_down4)cv.imshow("up4",pyr_up4)# 对比resizeimg2 = cv.resize(src_img,(int(height/2),int(width/2)))cv.imshow("img1/2",img2)img4 = cv.resize(src_img,(int(height/4),int(width/4)))cv.imshow("img1/4",img4)img8 = cv.resize(src_img,(int(height/8),int(width/8)))cv.imshow("img1/8",img8)img16 = cv.resize(src_img,(int(height/16),int(width/16)))cv.imshow("img1/16",img16)cv.waitKey(0)cv.destroyAllWindows()
图像特效
图像融合
图像融合,即按照一定的比例将两张图片融合在一起!例如下面图一图二经过融合之后形成图三!
执行这样的融合需要用到opencv提供的如下api
cv.addWeighted(图像1,权重1,图像2,权重2,叠加之后的像素偏移值)注意:进行叠加的两张图片宽高应该相同叠加之后的像素偏移值如果填的话不要填太大,超过255会导致图像偏白
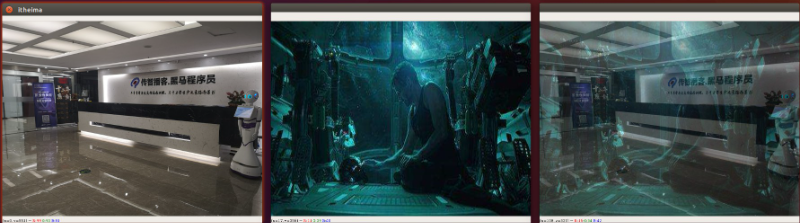
import cv2 as cvitheima = cv.imread("img/itheima.jpg", cv.IMREAD_COLOR)cv.imshow("itheima",itheima)tony = cv.imread("img/tony.jpg", cv.IMREAD_COLOR)cv.imshow("tony",tony)# 进行叠加时的插值dst = cv.addWeighted(itheima,0.5,tony,0.5,0)cv.imshow("dst",dst)cv.waitKey(0)cv.destroyAllWindows()
灰度处理
一张彩色图片通常是由BGR三个通道叠加而成,为了便于图像特征识别,我们通常会将一张彩色图片转成灰度图片来进行分析,当我们转成灰色图片之后,图片中边缘,轮廓特征仍然是能够清晰看到的,况且在这种情况下我们仅需要对单一通道进行分析,会简化很多操作!

示例代码
import cv2 as cv# 方式一 : 直接以灰度图像的形式读取# img = cv.imread("img/itheima.jpg", cv.IMREAD_GRAYSCALE)# cv.imshow("dstImg",img)# cv.waitKey(0)# 方式二: 以彩图的方式读取img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)# 将原图的所有颜色转成灰色dstImg = cv.cvtColor(img, cv.COLOR_BGR2GRAY)cv.imshow("dstImg",dstImg)cv.waitKey(0)
原理演示
方式一: gray = (B+G+R)/3
img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)# 获取图片宽高信息imgInfo = img.shapeheight = imgInfo[0]width = imgInfo[1]# 定义一个与原图同样大小的矩阵dstImg = np.zeros(imgInfo,np.uint8)# 遍历dstImg,填充数据for row in range(height):for col in range(width):# 获取原来的像素值(b,g,r) = img[row,col]# 计算灰度gray = np.uint8((int(b)+int(g)+int(r))/3)print(gray)# 向目标矩阵中填值dstImg[row,col]=graycv.imshow("dstimg",dstImg)cv.waitKey(0)
方式二: 利用著名的彩色转灰色心理学公式: Gray = R*0.299 + G*0.587 + B*0.114
import cv2 as cvimport numpy as np# 将图片数据读取进来img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)# 获取图片宽高信息imgInfo = img.shapeheight = imgInfo[0]width = imgInfo[1]# 定义一个与原图同样大小的矩阵dstImg = np.zeros(imgInfo,np.uint8)# 遍历dstImg,填充数据for row in range(height):for col in range(width):# 获取原来的像素值(b,g,r) = img[row,col]# 计算灰度# gray = np.uint8((int(b)+int(g)+int(r))/3)# 采用心理学公式计算gray = b*0.114 + g*0.587 + r*0.299# 向目标矩阵中填值dstImg[row,col]=graycv.imshow("dstimg",dstImg)cv.waitKey(0)
颜色反转
灰图反转
例如在一张灰度图片中,某个像素点的灰度值为100, 然后我们进行颜色反转之后,灰度值变为255-100 = 155 , 从下图我们可以看出,进行颜色反转之后,整张图片看起来非常像我们小时候所看到的胶卷底片!

import cv2 as cvimport numpy as np# 将图片数据读取进来img = cv.imread("img/itheima.jpg",cv.IMREAD_GRAYSCALE)cv.imshow("img",img)# 获取原图信息imgInfo = img.shapeheight = imgInfo[0]width = imgInfo[1]# 创建一个和原图同样大小的矩阵dstImg = np.zeros((height,width,1),np.uint8)for row in range(height):for col in range(width):# 获取原图中的灰度值gray = img[row,col]# 反转newColor = 255 - gray# 填充dstImg[row,col]=newColorcv.imshow("dstimg",dstImg)cv.waitKey(0)
彩图反转
学会了前面灰度图片的反转,下面我们进一步来学习彩色图片的反转. 相对于灰度图片,彩色图片其实只是由3个灰度图片叠加而成,如果让彩色图片进行颜色反转,我们其实只需要让每个通道的灰度值进行反转即可!

import cv2 as cvimport numpy as np# 将图片数据读取进来img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)cv.imshow("img",img)# 获取原图信息imgInfo = img.shapeheight = imgInfo[0]width = imgInfo[1]# 创建一个和原图同样大小的矩阵dstImg = np.zeros((height,width,3),np.uint8)for row in range(height):for col in range(width):# 获取原图中的灰度值(b,g,r) = img[row,col]# 反转new_b = 255-bnew_g = 255-gnew_r = 255-r# 填充dstImg[row,col]=(new_b,new_g,new_r)cv.imshow("dstimg",dstImg)cv.waitKey(0)
马赛克效果
马赛克指现行广为使用的一种图像(视频)处理手段,此手段将影像特定区域的色阶细节劣化并造成色块打乱的效果,因为这种模糊看上去有一个个的小格子组成,便形象的称这种画面为马赛克。其目的通常是使之无法辨认。
下面,我们来介绍一下实现马赛克的思路!
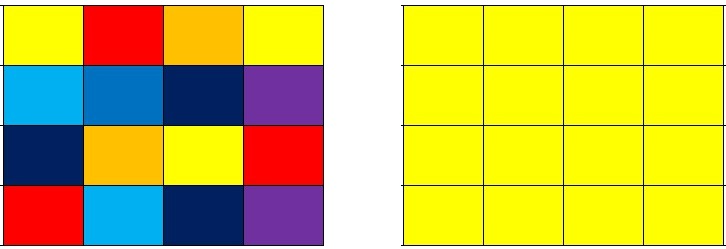
假设我们将要打马赛克的区域按照4x4进行划分,我们就会得到如下左图的样子!
接下来我们要干的就是让这个4x4块内的所有像素点的颜色值都和第一个像素点的值一样.
经过运算之后,我们整个4x4块内的所有像素点就都成了黄色! 从而掩盖掉了原来的像素内容!

import cv2 as cvimport numpy as np# 将图片数据读取进来img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)cv.imshow("img",img)# 获取原图信息imgInfo = img.shapeheight = imgInfo[0]width = imgInfo[1]# 遍历要打马赛克的区域 宽度430 高度220for row in range(160,240):for col in range(380,670):# 每10×10的区域将像素点颜色改成一致if row%10==0 and col%10==0:# 获取当前颜色值(b,g,r) = img[row,col]# 将10×10区域内的颜色值改成一致for i in range(10):for j in range(10):img[row+i,col+j]= (b,g,r)# 显示效果图cv.imshow('dstimg',img)cv.waitKey(0)
毛玻璃效果
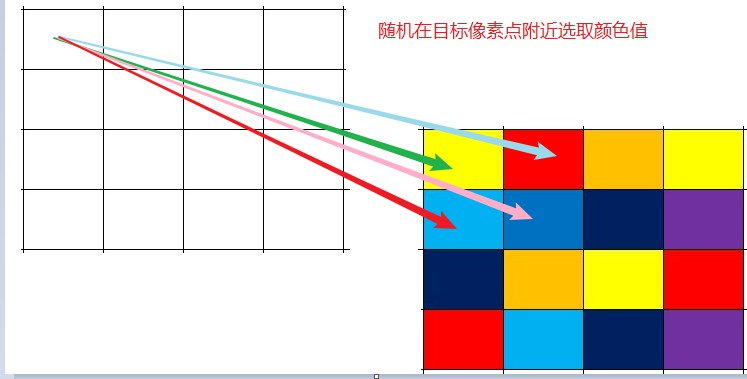
毛玻璃的效果和我们前面讲过的马赛克效果其实是非常相似的, 只不过毛玻璃效果是从附近的颜色块中,随机的去选择一个颜色值作为当前像素点的值!
我们还是以4x4的块大小为例,当我们去遍历每个像素点的时候, 当前像素点的颜色值,我们随机从它附近4x4的区域内选择一个颜色值作为当前像素点的值!

import cv2 as cvimport numpy as npimport random# 将图片数据读取进来img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)cv.imshow("img",img)# 获取原图信息imgInfo = img.shapeheight = imgInfo[0]width = imgInfo[1]# 创建一个和原图同样大小的空白矩阵dstImg = np.zeros((height,width,3),np.uint8)# 定义偏移量,表示从后面6个像素中随机选取一个颜色值offset=6# 向空白矩阵中填入颜色值for row in range(height):for col in range(width):# 计算随机数index = int(random.random()*offset)# 计算随机行号randomRow = row + index if row+index<height else height-1# 计算随机列号randomCol = col + index if col+index<width else width-1# 选择附近的一个像素点颜色(b,g,r) = img[randomRow,randomCol]# 填充到空白矩阵中dstImg[row,col]=(b,g,r)# 显示效果图cv.imshow('dstimg',dstImg)cv.waitKey(0)
图片浮雕效果
梯度
前面我们做过一个毛玻璃效果的图片, 其实原理很简单对吧,我们只需要让当前像素点的颜色和附近像素点的颜色一致就可以了! 这样带来的效果其实是图片变得模糊.
那么模糊图片和清晰图片之间的差异是什么呢? 从视觉角度来讲, 图像模糊是因为图像中物体的边缘轮廓不明显,就好比一个近视的同学,摘下眼镜看东西,整个世界的轮廓都是模糊的. 再进一步理解就是物体边缘灰度变化不强烈,层次感不强造成的! 那么反过来, 如果物体轮廓边缘灰度变化明显些, 层次感强些图像不就是清晰一些了吗?
这种灰度变化明不明显强不强烈该如何定义呢 ? 我们学过微积分, 微分就是求函数的变化率,即导数(梯度). 其实梯度我们可以把它理解为颜色变化的强度, 更直白一点说梯度相当于是2个相邻像素之间的差值!

我们先看第一行数据, 在X轴方向上,颜色值都为100,我们并没有看到任何的边缘
但是在Y轴方向上, 我们可以看到100和50之间有明显的边缘,其实这个就是梯度
浮雕效果相信大家都有比较熟悉,在opencv中我们想要实现浮雕效果,只需套用如下公式即可:
gray = gray0-gray1+120
其中,相邻像素值之差可以体现边缘的突变或者称为梯度
末尾加上120只是为了增加像素值的灰度.
当然,在这个运算的过程中,我们还需要注意计算结果有可能小于0或者大于255

import cv2 as cvimport numpy as npimport random# 将图片数据读取进来img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)cv.imshow("img",img)imgInfo = img.shapeheight = imgInfo[0]width = imgInfo[1]# 将图片转成灰度图片grayImg = cv.cvtColor(img, cv.COLOR_BGR2GRAY)# 创建一张与原图相同大小的空白矩阵dstImg = np.zeros((height,width,1),np.uint8)# 向空白图片中填充内容for row in range(height):for col in range(width-1):# 获取当前像素值gray0 = grayImg[row,col]# 获取相邻一个像素点灰度gray1 = grayImg[row,col+1]# 计算新的灰度值gray = int(gray0)-int(gray1)+120# 校验gray是否越界gray = gray if gray<255 else 255gray = gray if gray>0 else 0# 将值填充到空白的矩阵中dstImg[row,col] = gray# 显示图片cv.imshow("dstimg",dstImg)cv.waitKey(0)
绘制图形
在这之前,我们学过的所有操作,其实都是在原图的基础上进行修改! 现在假设我们想在原图上绘制一些标记或者轮廓,那么我们就需要来学习一下opencv给我们提供的相应API,在这些API中,常见的有绘制直线,绘制圆,绘制矩形
# 绘制线段 参数2:起始点 参数3:结束点 参数4:颜色 参数5:线条宽度cv.line(图片矩阵,起始点,结束点,颜色值,线条的宽度,线条的类型)# 绘制一个矩形 参数2: 左上角 参数3:右下角 参数4:颜色 参数5:线条宽度,若为负数,则填充整个矩形cv.rectangle(dstImg,(250,90),(470,180),(0,255,0),-1)# 绘制圆形 参数2:圆心 参数3:半径 参数4:颜色 参数5:线条宽度cv.circle(dstImg,(450,280),90,(0,0,255),5)
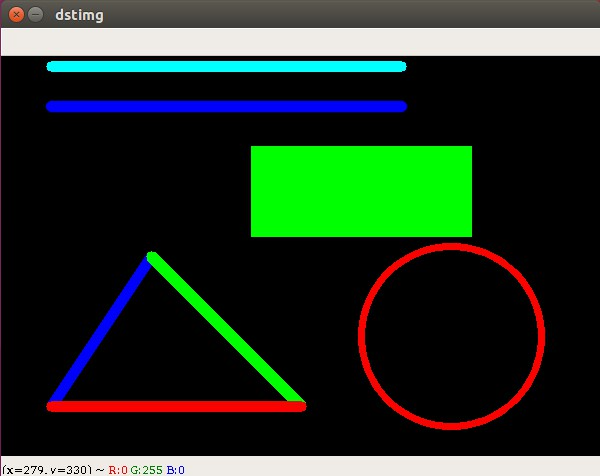
import cv2 as cvimport numpy as npimport random# 创建一个空白的矩阵dstImg = np.zeros((400,600,3),np.uint8)# 绘制线段 参数2:起始点 参数3:结束点 参数4:颜色 参数5:线条宽度cv.line(dstImg,(50,10),(400,10),(255,255,0),10)# 扛锯齿cv.line(dstImg,(50,50),(400,50),(255,0,0),10,cv.LINE_AA)# 绘制一个三角形cv.line(dstImg,(50,350),(150,200),(255,0,0),10)cv.line(dstImg,(150,200),(300,350),(0,255,0),10)cv.line(dstImg,(300,350),(50,350),(0,0,255),10)# 绘制一个矩形 参数2: 左上角 参数3:右下角 参数4:颜色 参数5:线条宽度,若为负数,则填充整个矩形cv.rectangle(dstImg,(250,90),(470,180),(0,255,0),-1)# 绘制圆形 参数2:圆心 参数3:半径 参数4:颜色 参数5:线条宽度cv.circle(dstImg,(450,280),90,(0,0,255),5)# 显示图片cv.imshow("dstimg",dstImg)cv.waitKey(0)
文字图片绘制
在图片上绘制文本,我们需要用到
# 绘制文字font = cv.FONT_HERSHEY_SIMPLEX# 参数2:文本 参数3:显示位置 参数4:字体 参数5:大小 参数6:颜色 参数7:粗细 参数8:线条类型cv.putText(img,'www.itheima.com',(395,138),font,1,(0,0,255),2,cv.LINE_AA)
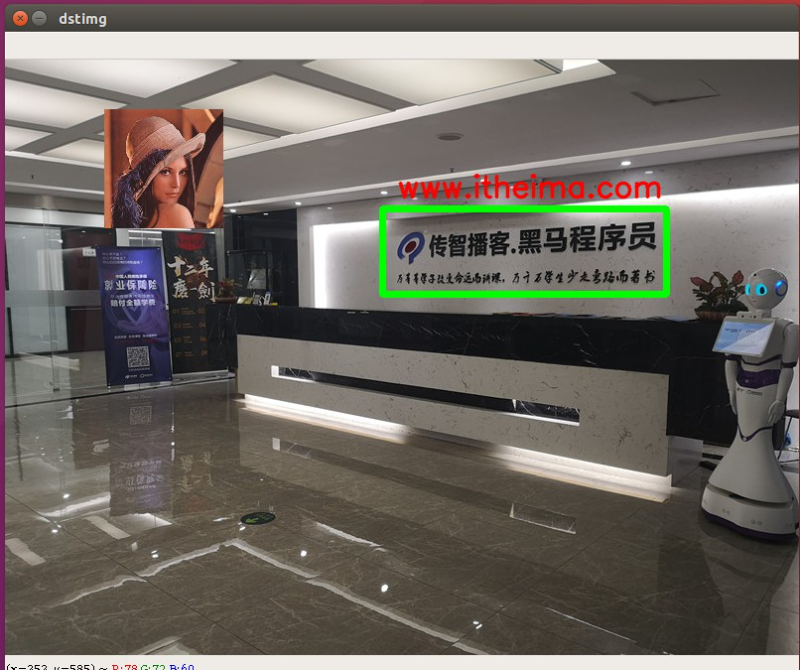
示例代码
# 将图片数据读取进来img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)cv.imshow("img",img)imgInfo = img.shapeheight = imgInfo[0]width = imgInfo[1]# 在图片上绘制矩形cv.rectangle(img,(380,150),(666,236),(0,255,0),5)# 绘制图片lenaImg = cv.imread("img/lena.jpg",cv.IMREAD_COLOR)# 获取图片信息imgInfo = lenaImg.shape# 计算缩放图片宽高scale = 0.3height = int(imgInfo[0]*scale)width = int(imgInfo[1]*scale)# 缩放图片newLenaImg = cv.resize(lenaImg,(height,width))# 遍历for row in range(height):for col in range(width):img[50+row,100+col]=newLenaImg[row,col]cv.imshow('dstimg',img)cv.waitKey(0)
注意: opencv不支持中文显示,若想显示中文,需要额外安装中文字体库
图片美化
亮度增强
亮度增强,其实就是将每个颜色值增大一点点
例如: color = color + 50 即可调亮图片
color = color - 50 即可调暗图片

代码实现
import cv2 as cvdef checkColor(value):value = value if value < 256 else 255value = value if value > 0 else 0return value# 将图片数据读取进来img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)cv.imshow('img',img)imgInfo = img.shapeheight = imgInfo[0]width = imgInfo[1]# 定义颜色改变的值count=35# 遍历每一个像素点for row in range(height):for col in range(width):# 获取每个像素点的颜色值(b,g,r) = img[row,col]# 增大当前颜色值newb = b + countnewg = g + countnewr = r + count# 校验每个像素值不能越界newb = checkColor(newb)newg = checkColor(newg)newr = checkColor(newr)img[row,col] = (newb,newg,newr)# 显示改变之后的图像cv.imshow('newimg',img)cv.waitKey(0)
灰度图片
直方图
统计每个灰度值出现的概率
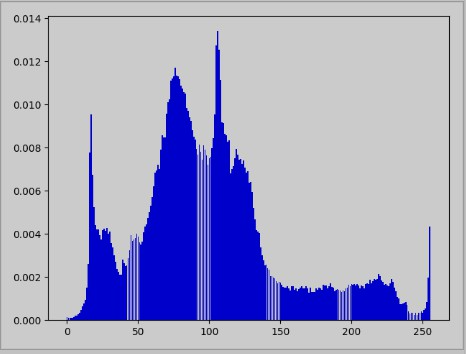
示例代码
import cv2 as cvimport numpy as npimport matplotlib.pyplot as plt# 将图片数据读取进来img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)# 将图片转成灰度图片grayImg = cv.cvtColor(img, cv.COLOR_BGR2GRAY)cv.imshow("gray",grayImg)# 计算直方图 , 注意这里需要用数组的方式传值hist = cv.calcHist([grayImg],[0],None,[256],[0.0,255.0])plt.plot(hist,color="green")plt.show()cv.waitKey(0)cv.destroyAllWindows()
备注: 使用matplotlib绘制直方图有两种方式
方式一:# 使用api将直方图数据计算好 图片 通道 掩膜 数量 值的范围hist = cv.calcHist([grayImg],[0],None,[256],[0.0,255.0])# 调用plot函数显示plt.plot(hist,color="green")plt.show()方式二:# 1.使用Img.ravel()将多行的矩阵转成单行的矩阵# 2. 然后调用matplot的hist函数自动计算直方图,bins表示像素区间数量plt.hist(grayImg.ravel(),color="red",bins=256)plt.show()
直方图均衡化
直方图均衡化是将原图象的直方图通过变换函数修正为均匀的直方图,然后按均衡直方图修正原图象。图象均衡化处理后,图象的直方图是平直的,即各灰度级具有相同的出现频数,那么由于灰度级具有均匀的概率分布,图象看起来就更清晰了。
经过直方图均衡化处理之后,我们整个图像的颜色变化就是一种平滑变化的状态
原始直方图 — 均衡化直方图的 变换函数 : 累积概率图
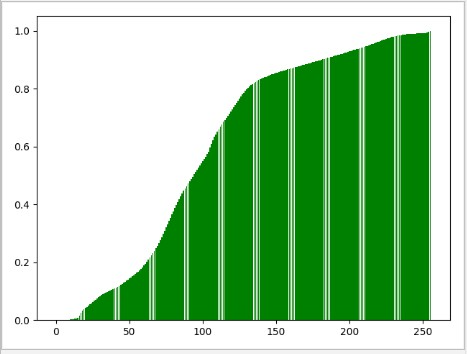
下面我们来看一下灰色图片经过直方图均衡化处理之后的对比

这里是均衡化前后图像直方图的对比
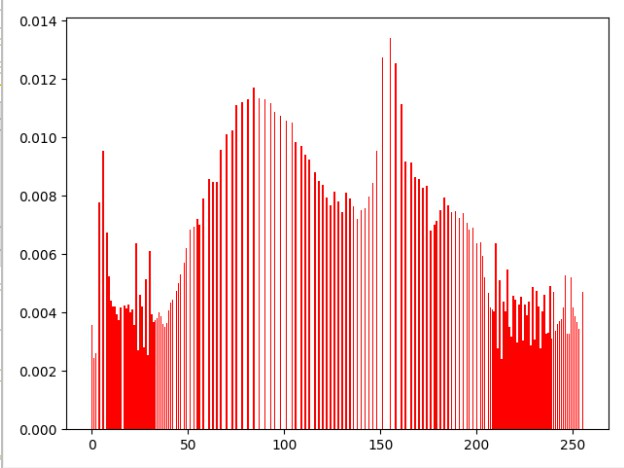
示例代码
import cv2 as cvimport numpy as npimport matplotlib.pyplot as plt# 将图片数据读取进来img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)# 将图片转成灰度图片grayImg = cv.cvtColor(img, cv.COLOR_BGR2GRAY)cv.imshow("gray",grayImg)# 计算直方图 , 注意这里需要用数组的方式传值hist = cv.calcHist([grayImg],[0],None,[256],[0.0,255.0])plt.plot(hist,color="green")plt.show()# 直方图均衡化# equalize_img = np.zeros(grayImg.shape,np.uint8)equalize_img = cv.equalizeHist(grayImg)cv.imshow("equalize img",equalize_img)# 会自己统计直方图,但是需要将多行数据转成单行数据plt.hist(equalize_img.ravel(),bins=256)plt.show()cv.waitKey(0)cv.destroyAllWindows()
彩色图片
直方图
在前面,我们计算灰度图片的直方图时,我们只需要统计灰色值出现的概率就可以了,现在我们要处理的是彩色图片,所以我们需要将(B,G,R)三种颜色值取出来,单独计算每种颜色的直方图

代码实现
import cv2 as cvimport matplotlib.pyplot as pltimg = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)colors = ["blue","green","red"]img_split = cv.split(img)for i,channel in enumerate(img_split):plt.hist(channel.ravel(),bins=256,color=colors[i])plt.show()cv.waitKey(0)cv.destroyAllWindows()
直方图均衡化

示例代码
import cv2 as cvimg = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)b,g,r = cv.split(img)b_dst = cv.equalizeHist(b)g_dst = cv.equalizeHist(g)r_dst = cv.equalizeHist(r)ret = cv.merge([b_dst,g_dst,r_dst])# 显示均衡化之后的图片cv.imshow("src",img)cv.imshow("equalize_img",ret)cv.waitKey(0)cv.destroyAllWindows()
视频处理
视频分解图片
在后面我们要学习的机器学习中,我们需要大量的图片训练样本,这些图片训练样本如果我们全都使用相机拍照的方式去获取的话,工作量会非常巨大, 通常的做法是我们通过录制视频,然后提取视频中的每一帧即可!
接下来,我们就来学习如何从视频中获取信息
ubuntu下摄像头终端可以安装: sudo apt-get install cheese 然后输入cheese即可打开摄像头
实现步骤:
- 加载视频
- 获取视频信息
- 解析视频
import cv2 as cvvideo = cv.VideoCapture("img/twotiger.avi")# 判断视频是否打开成功isOpened = video.isOpened()print("视频是否打开成功:",isOpened)# 获取图片的信息:帧率fps = video.get(cv.CAP_PROP_FPS)# 获取每帧宽度width = video.get(cv.CAP_PROP_FRAME_WIDTH)# 获取每帧的高度height = video.get(cv.CAP_PROP_FRAME_HEIGHT)print("帧率:{},宽度:{},高度:{}".format(fps,width,height))# 从视频中读取8帧信息count=0while count<8:count = count + 1# 读取成功or失败, 当前帧数据flag,frame = video.read()# 将图片信息写入到文件中if flag: # 保存图片的质量cv.imwrite("img/tiger%d.jpg"%count,frame,[cv.IMWRITE_JPEG_QUALITY,100])print("图片截取完成啦!")
HSV颜色模型
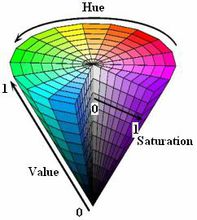
HSV(Hue, Saturation, Value)是根据颜色的直观特性由A. R. Smith在1978年创建的一种颜色空间, 也称六角锥体模型(Hexcone Model)。
这个模型中颜色的参数分别是:色调(H),饱和度(S),明度(V)
色调H
用角度度量,取值范围为0°~360°,从红色开始按逆时针方向计算,红色为0°,绿色为120°,蓝色为240°。它们的补色是:黄色为60°,青色为180°,品红为300°;
饱和度S
饱和度S表示颜色接近光谱色的程度。一种颜色,可以看成是某种光谱色与白色混合的结果。其中光谱色所占的比例愈大,颜色接近光谱色的程度就愈高,颜色的饱和度也就愈高。饱和度高,颜色则深而艳。光谱色的白光成分为0,饱和度达到最高。通常取值范围为0%~100%,值越大,颜色越饱和。
明度V
明度表示颜色明亮的程度,对于光源色,明度值与发光体的光亮度有关;对于物体色,此值和物体的透射比或反射比有关。通常取值范围为0%(黑)到100%(白)。
结论:
当S=1 V=1时,H所代表的任何颜色被称为纯色;
当S=0时,即饱和度为0,颜色最浅,最浅被描述为灰色(灰色也有亮度,黑色和白色也属于灰色),灰色的亮度由V决定,此时H无意义;
当V=0时,颜色最暗,最暗被描述为黑色,因此此时H(无论什么颜色最暗都为黑色)和S(无论什么深浅的颜色最暗都为黑色)均无意义。
注意: 在opencv中,H、S、V值范围分别是[0,180],[0,255],[0,255],而非[0,360],[0,1],[0,1];
这里我们列出部分hsv空间的颜色值, 表中将部分紫色归为红色

判断当前是白天还是晚上
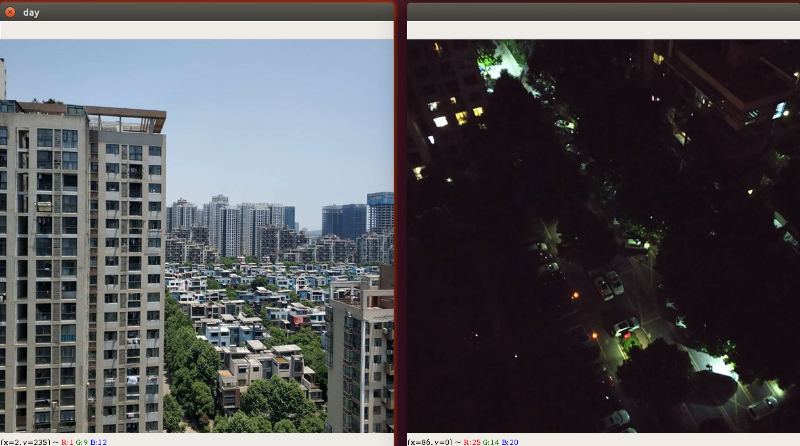
实现步骤
- 将图片从BGR颜色空间,转变成HSV颜色空间
- 获取图片的宽高信息
- 统计每个颜色点的亮度
- 计算整张图片的亮度平均值
注意,这仅仅只能做一个比较粗糙的判定,按照我们人的正常思维,在傍晚临界点我们也无法判定当前是属于晚上还是白天!
import cv2 as cvimport numpy as npdef average_brightness(img):"""封装一个计算图片平均亮度的函数"""imgInfo = img.shapeheight = imgInfo[0]width = imgInfo[1]hsv_img = cv.cvtColor(img, cv.COLOR_BGR2HSV)# 提取出v通道信息v_day = cv.split(hsv_img)[2]# 计算亮度之和result = np.sum(v_day)# 返回亮度的平均值return result/(height*width)# 计算白天的亮度平均值day_img = cv.imread("assets/day.jpg", cv.IMREAD_COLOR)brightness1 = average_brightness(day_img)print("day brightness1:",brightness1);# 计算晚上的亮度平均值night_img = cv.imread("assets/night.jpg", cv.IMREAD_COLOR)brightness2 = average_brightness(night_img)print("night brightness2:",brightness2)cv.waitKey(0)cv.destroyAllWindows()
颜色过滤
在一张图片中,如果某个物体的颜色为纯色,那么我们就可以使用颜色过滤inRange的方式很方便的来提取这个物体.
下面我们有一张网球的图片,并且网球的颜色为一定范围内的绿色,在这张图片中我们找不到其它颜色也为绿色的图片,所以我们可以考虑使用绿色来提取它!
图片的颜色空间默认为BGR颜色空间,如果我们想找到提取纯绿色的话,我们可能需要写(0,255,0)这样的内容,假设我们想表示一定范围的绿色就会很麻烦!
所以我们考虑将它转成HSV颜色空间,绿色的色调H的范围我们很容易知道,剩下的就是框定颜色的饱和度H和亮度V就可以啦!
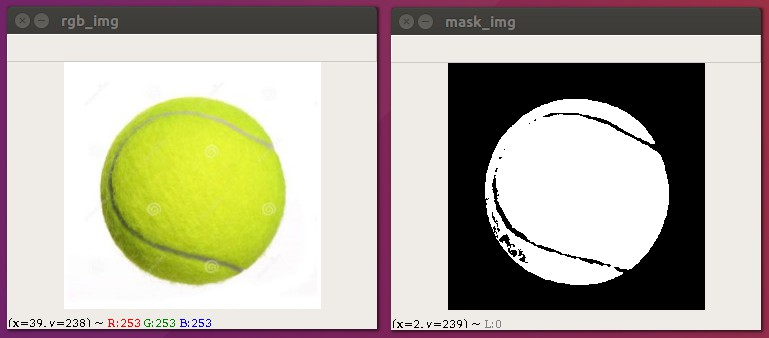
实现步骤:
- 读取一张彩色图片
- 将RGB转成HSV图片
- 定义颜色的范围,下限位(30,120,130),上限为(60,255,255)
- 根据颜色的范围创建一个mask
import cv2 as cv# 读取图片rgb_img = cv.imread("assets/tenis1.jpg", cv.IMREAD_COLOR)cv.imshow("rgb_img",rgb_img)# 将BGR颜色空间转成HSV空间hsv_img = cv.cvtColor(rgb_img, cv.COLOR_BGR2HSV)# 定义范围 网球颜色范围lower_color = (30,120,130)upper_color = (60,255,255)# 查找颜色mask_img = cv.inRange(hsv_img, lower_color, upper_color)# 在颜色范围内的内容是白色, 其它为黑色cv.imshow("mask_img",mask_img)cv.waitKey(0)cv.destroyAllWindows()
替换背景案例

实现步骤
1. 从绿幕图片中过滤出绿幕
2. 将狮子从绿幕中抠出来
3. 在itheima图片上抠出狮子的位置
4. 将狮子和黑马图片进行相加得到最终的图片
import cv2 as cv# 1.读取绿幕图片green_img = cv.imread("assets/lion.jpg", cv.IMREAD_COLOR)hsv_img = cv.cvtColor(green_img,cv.COLOR_BGR2HSV)# 2. 定义绿幕的颜色范围lower_green = (35,43,60)upper_green = (77,255,255)# 3. 使用inrange找出所有的背景区域mask_green = cv.inRange(hsv_img, lower_green, upper_green)# 复制狮子绿幕图片mask_img = green_img.copy()# 将绿幕图片,对应蒙板图片中所有不为0的地方全部改成0mask_img[mask_green!=0]=(0,0,0)cv.imshow("dst",mask_img)# itheima图片 对应蒙板图片为0的地方全都改成0,抠出狮子要存放的位置itheima_img = cv.imread("assets/itheima.jpg", cv.IMREAD_COLOR)itheima_img[mask_green==0]=(0,0,0)cv.imshow("itheima",itheima_img)# 将抠出来的狮子与处理过的itheima图片加载一起result = itheima_img+mask_imgcv.imshow("result",result)cv.waitKey(0)cv.destroyAllWindows()
图像的二值化
图像二值化( Image Binarization)就是将图像上的像素点的灰度值设置为0或255,也就是将整个图像呈现出明显的黑白效果的过程。
在数字图像处理中,二值图像占有非常重要的地位,图像的二值化使图像中数据量大为减少,从而能凸显出目标的轮廓。
所使用的阈值,结果图片 = cv.threshold(img,阈值,最大值,类型)

| THRESH_BINARY | 高于阈值改为255,低于阈值改为0 |
|---|---|
| THRESH_BINARY_INV | 高于阈值改为0,低于阈值改为255 |
| THRESH_TRUNC | 截断,高于阈值改为阈值,最大值失效 |
| THRESH_TOZERO | 高于阈值不改变,低于阈值改为0 |
| THRESH_TOZERO_INV | 高于阈值该为0,低于阈值不改变 |
简单阈值
import cv2 as cv# 读取图像img = cv.imread("assets/car.jpg",cv.IMREAD_GRAYSCALE)# 显示图片cv.imshow("gray",img)# 获取图片信息imgInfo = img.shapeheight = imgInfo[0]width = imgInfo[1]# 定义阈值thresh = 60for row in range(height):for col in range(width):# 获取当前灰度值grayValue = img[row,col]if grayValue>thresh:img[row,col]=255else:img[row,col]=0# 直接调用api处理 返回值1:使用的阈值, 返回值2:处理之后的图像# ret,thresh_img = cv.threshold(img, thresh, 255, cv.THRESH_BINARY)# 显示修改之后的图片cv.imshow("thresh",img);cv.waitKey(0)cv.destroyAllWindows()
自适应阈值
我们使用一个全局值作为阈值。但是在所有情况下这可能都不太好,例如,如果图像在不同区域具有不同的照明条件。在这种情况下,自适应阈值阈值可以帮助。这里,算法基于其周围的小区域确定像素的阈值。因此,我们为同一图像的不同区域获得不同的阈值,这为具有不同照明的图像提供了更好的结果。
除上述参数外,方法cv.adaptiveThreshold还有三个输入参数:
该adaptiveMethod决定阈值是如何计算的:
- cv.ADAPTIVE_THRESH_MEAN_C:该阈值是该附近区域减去恒定的平均Ç。
- cv.ADAPTIVE_THRESH_GAUSSIAN_C:阈值是邻域值减去常数C的高斯加权和。
该BLOCKSIZE确定附近区域的大小和Ç是从平均值或附近的像素的加权和中减去一个常数。
import cv2 as cv# 读取图像img = cv.imread("assets/thresh1.jpg",cv.IMREAD_GRAYSCALE)# 显示图片cv.imshow("gray",img)# 获取图片信息imgInfo = img.shape# 直接调用api处理 参数1:图像数据 参数2:最大值 参数3:计算阈值的方法, 参数4:阈值类型 参数5:处理块大小 参数6:算法需要的常量Cthresh_img = cv.adaptiveThreshold(img,255,cv.ADAPTIVE_THRESH_GAUSSIAN_C,cv.THRESH_BINARY,11,5)# 显示修改之后的图片cv.imshow("thresh",thresh_img);cv.waitKey(0)cv.destroyAllWindows()
THRESH_OTSU
采用日本人大津提出的算法,又称作最大类间方差法,被认为是图像分割中阈值选取的最佳算法,采用这种算法的好处是执行效率高!

import cv2 as cv# 读取图像img = cv.imread("assets/otsu_test.png",cv.IMREAD_GRAYSCALE)cv.imshow("src",img)ret,thresh_img = cv.threshold(img, 225, 255, cv.THRESH_BINARY_INV)cv.imshow("normal", thresh_img);gaussian_img = cv.GaussianBlur(img,(5,5),0)cv.imshow("g",gaussian_img)ret,thresh_img = cv.threshold(gaussian_img, 0, 255, cv.THRESH_BINARY|cv.THRESH_OTSU)cv.imshow("otsu", thresh_img);print("阈值:",ret)cv.waitKey(0)cv.destroyAllWindows()

若有收获,就点个赞吧
0 人点赞
