本章我们主要学习以下内容:
- 阅读自动驾驶论文
- 采集数据
- 根据论文搭建自动驾驶神经网络
- 训练模型
- 在仿真环境中进行自动驾驶

论文介绍
本文参考自2016年英伟达发表的论文《End to End Learning for Self-Driving Cars》
end2end.pdf
论文的核心思想是以图像为特征,以方向盘的转向角度为标签,通过深度学习来学习画面对应的方向盘角度.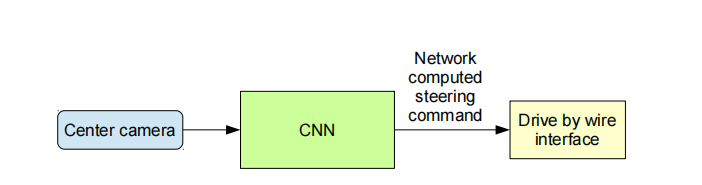
正如上图所示, 我们首先从中间摄像头中读取当前画面, 将读到的画面传输给卷积神经网络, 卷积神经网络提取到图片的特征,计算出方向盘转动的角度, 我们再根据角度控制汽车的方向盘.
在2016年自动驾驶研究火热的时候, 这是一篇相当有影响力的论文, 它现在已经成为入门自动驾驶必读的论文. 下面我们来看看它的网络结构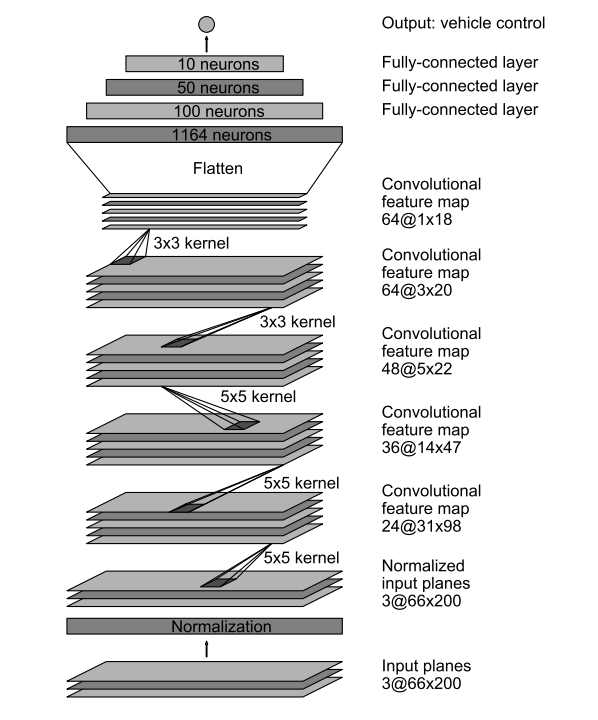
假设现在我们正在开车处于如下图所示的情况 作为一名经验丰富的老司机, 我们需要控制方向盘和油门. 很显然,在当前车道内,我们需要前方路口左转。 我们会控制方向盘往左转动, 同时我们需要降低油门,防止转弯速度过快跑出车道。
总结一下刚才老司机的步骤:
- 当前画面映入眼帘,
- 大脑飞速运转,得出需要左转的结论
- 手开始慢慢打方向盘
- 脚开始控制油门
这个过程如果用计算机来处理的话:
- 摄像头捕捉画面
- 画面经过神经网络处理,得出转弯角度
- 机械控制转弯角度
- 机械控制汽车速度
要想成为一名老司机,以应对各种可能出现的情况,我们要多开车,多见世面。 还是以开车为例,本地司机永远是最牛的司机,例如
- 武汉的公交司机,敢在水里开公交,因为他们频繁遭遇暴雨,已经掌握了开潜艇的技巧
- 重庆的出租车司机,完全不需要高德,百度的误导,因为这个地方他们比导航软件还熟
- 广州的出租车,在错综复杂的高架桥中高速穿行,因为他们已经积累到了丰富的经验,而新进广州的司机,可能分不清现在应该走在桥上还是桥下
我们要想让电脑成为一名老司机,我们需要按照如下步骤进行:
- 搜集数据: 画面 —— 转弯角度
- 训练模型:神经网络
- 验证模型:车里坐个人,时刻关注车辆运行的状态
数据采集
import torchimport csvimport cv2 as cvfrom utils.image_utils import preprocess_bgr# 自定义数据集class AutoDriveDataset(torch.utils.data.Dataset):def __init__(self,csv_path,image_dir,transform=None):super(AutoDriveDataset,self).__init__()# 读取csv文件里面的数据self.samples = []with open(csv_path) as csvfile:reader = csv.reader(csvfile)for line in reader:self.samples.append(line)# 图片文件夹路径self.image_dir = image_dir# 图像预处理self.transform = transformdef __getitem__(self, index):# 获取当前行的文本信息example = self.samples[index]# 图片路径center = example[0]# 方向盘的角度angle = example[3]# 获取图片信息image = cv.imread(center)image = preprocess_bgr(image)if self.transform:image = self.transform(image)return image,float(angle)def __len__(self):return len(self.samples)
模型定义
import torchimport torch.nn as nn# 定义模型class AutoDriveNet(torch.nn.Module):def __init__(self): # 原始图片320*120super(AutoDriveNet, self).__init__()# 神经网络 外部输入的数据为 3*66*200# 卷积核5x5 半径2: 66 - 2*2--> 62 -步长->31self.conv_layers = nn.Sequential(nn.Conv2d(3,24,kernel_size=5,stride=2), # 66-4/2=31 200-4/2= 98 158nn.ReLU(),nn.Conv2d(24, 36, kernel_size=5, stride=2), # 31 - 4 13.5 26 98-4 /2=47 77nn.ReLU(),nn.Conv2d(36, 48, kernel_size=5, stride=2), # 13.5-4 /2 4.5 47-4 /2=21.5 37nn.ReLU(),nn.Conv2d(48, 64, kernel_size=3, stride=1),# 4.5-2=2.5 21.5-2=19.5 37-2 = 35nn.ReLU(),nn.Conv2d(64, 64, kernel_size=3, stride=1),# 2.5-2=0.5 19.5-2 = 17.5 35-2 =33nn.Dropout(p=0.5), # 防止过拟合)# 线性层self.linear_layers = nn.Sequential(nn.Linear(64*1*18,100),nn.ReLU(),nn.Linear(100, 50),nn.ReLU(),nn.Linear(50, 10),nn.Linear(10, 1))def forward(self,x):# 正向传播/前向传播 n 3*66*200out = x.view(x.size(0),3,66,200)out = self.conv_layers(out)# 将数据打平out = out.view(out.size(0),-1)out = self.linear_layers(out)return out
过拟合问题
过拟合是指模型只过分地匹配特定训练数据集,以至于对训练集外数据无良好地拟合及预测。其本质原因是模型从训练数据中学习到了一些统计噪声,即这部分信息仅是局部数据的统计规律,该信息没有代表性,在训练集上虽然效果很好,但未知的数据集(测试集)并不适用。
一句话讲就是过拟合在训练集中表现良好,但是在测试集中表现较差的一种现象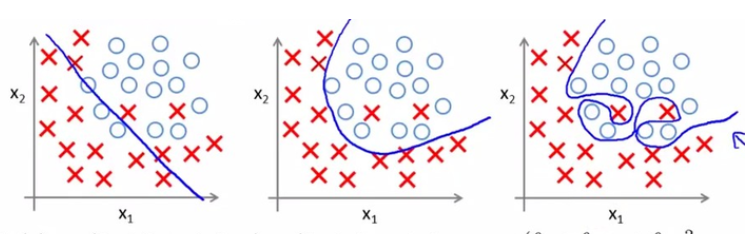
Dropout是正则化技术简单有趣且有效的方法,在神经网络很常用。其方法是:在每个迭代过程中,以一定概率p随机选择输入层或者隐藏层的(通常隐藏层)某些节点,并且删除其前向和后向连接(让这些节点暂时失效)。权重的更新不再依赖于有“逻辑关系”的隐藏层的神经元的共同作用,一定程度上避免了一些特征只有在特定特征下才有效果的情况,迫使网络学习更加鲁棒(指系统的健壮性)的特征,达到减小过拟合的效果。这也可以近似为机器学习中的集成bagging方法,通过bagging多样的的网络结构模型,达到更好的泛化效果。
torch.nn.Dropout(p=0.5, inplace=False)
训练过程中按照概率p随机地将输入张量中的元素置为0
evere channel will be zeroed out independently on every forward call.
Parameters:
p(float):每个元素置为0的概率,默认是0.5
inplace(bool):是否对原始张量进行替换
模型训练
import torchimport numpy as npimport cv2 as cvimport torch.nn as nnimport csvfrom torch.utils.data.sampler import SubsetRandomSamplerclass AverageLoss(object):'''计算每轮训练的平均loss'''def __init__(self):self.reset()def reset(self):self.val = 0self.avg = 0self.sum = 0self.count = 0def update(self, val, n=1):self.val = valself.sum += val * nself.count += nself.avg = self.sum / self.countimport osimport torch.backends.cudnn as cudnnimport timefrom AutoDriveDataset import AutoDriveDatasetfrom AutoDriveNet import AutoDriveNetfrom torchvision.transforms import transformsfrom torch.utils.tensorboard import SummaryWriterif __name__ == '__main__':# 模型训练:CSV_PATH = "d:/DATA/ml/driving/3/driving_log.csv"IMAGE_PATH = "d:/DATA/ml/driving/3/IMG"# CSV_PATH = "d:/DATA/ml/driving/merge/driving_log.csv"# IMAGE_PATH = "d:/DATA/ml/driving/merge/IMG"transform = transforms.Compose([transforms.Lambda(lambda x:(x/127.5) - 1.0)])# 数据集dataset = AutoDriveDataset(CSV_PATH,IMAGE_PATH,transform)total_size = len(dataset)print("总共的数据量:",total_size)# 将数据进行打散# 获取所有的数据的索引indexes = list(range(total_size))print(indexes)np.random.seed(1234)np.random.shuffle(indexes)print(indexes)# 按照一定比例划分: 训练集0.8, 验证集:0.2splitRatio = 0.8trainSize = int(total_size*splitRatio)trainIndexes = indexes[0:trainSize]valIndexes = indexes[trainSize:]print("训练集的索引:",trainIndexes)print("验证集的索引:",valIndexes)# 随机采样trainSampler = SubsetRandomSampler(trainIndexes)valSampler = SubsetRandomSampler(valIndexes)# 数据加载器trainDataLoder = torch.utils.data.DataLoader(dataset,batch_size=400,sampler=trainSampler)valDataLoder = torch.utils.data.DataLoader(dataset,batch_size=400,sampler=valSampler)writer = SummaryWriter()# 获取当前支持的设备if torch.cuda.is_available():device = torch.device("cuda:0")cudnn.benchmark = Trueelse:device = torch.device("cpu")# 为了接着上一次的训练结果继续训练if os.path.exists("models/best-itheima_{}.pt"):model = torch.load("models/best-itheima.pt")else:model = AutoDriveNet()model.to(device)lossFunction = nn.MSELoss().to(device)optimzer = torch.optim.Adam(model.parameters(),lr=1e-4)best_loss = 10000.0for epoch in range(300):model.train()loss_epoch = AverageLoss()loss = None;for inputs,labels in trainDataLoder:# 为了提升运算效率,将数据的运算移动到GPU中inputs = inputs.float().to(device)labels = labels.float().to(device)# 1. 正向传播pred = model(inputs)# 2. 计算损失loss = lossFunction(pred,labels.unsqueeze(1))# 3. 反向传播loss.backward()# 4. 更新参数optimzer.step()# 5. 梯度清空optimzer.zero_grad()# 记录损失值loss_epoch.update(loss.item(), inputs.size(0))# 保存最有的lossif loss.item() < best_loss:best_loss = loss.item()value = int(time.time())torch.save(model,f"models/best-itheima{value}.pt")# 监控损失值变化writer.add_scalar('MSE_Loss', loss_epoch.avg, epoch)print('epoch:' + str(epoch) + ' MSE_Loss:' + str(loss_epoch.avg))print("训练已经完成...")torch.save(model,"last-itheima.pt")writer.close()
查看训练过程中的结果
pip install tensorboard
在命令行中启动tensorboard
tensorboard --logdir=runs
验证模型
"""验证当前模型是否能够完成自动驾驶"""import argparseimport base64from datetime import datetimeimport osimport shutilfrom AutoDriveNet import AutoDriveNetimport numpy as npimport socketioimport eventletimport eventlet.wsgifrom PIL import Imagefrom flask import Flaskfrom io import BytesIOimport torchimport torchvision.transforms as transformsimport cv2import cv2 as cvimport matplotlib.pyplot as pltimport tracebackeventlet.monkey_patch(socket=True, select=True)sio = socketio.Server(async_mode='eventlet')app = socketio.WSGIApp(sio)model = Noneprev_image_array = Nonetransformations = transforms.Compose([transforms.Lambda(lambda x: (x / 127.5) - 1.0)])IMAGE_HEIGHT, IMAGE_WIDTH, IMAGE_CHANNELS = 66, 200, 3def preprocess(image):"""对图像进行预处理"""image = image[60:-25, :, :]image = cv2.resize(image, (IMAGE_WIDTH, IMAGE_HEIGHT))image = cv2.cvtColor(image, cv2.COLOR_RGB2HSV)return image# set min/max speed for our autonomous carMAX_SPEED = 13MIN_SPEED = 3# and a speed limitspeed_limit = MAX_SPEEDdevice = torch.device("cuda")@sio.on('telemetry')def telemetry1(sid, data):if data:# 当前的方向角度steering_angle = float(data["steering_angle"])# 当前的油门throttle = float(data["throttle"])# 当前车速speed = float(data["speed"])# The current image from the center camera of the carimage = Image.open(BytesIO(base64.b64decode(data["image"])))try:with torch.no_grad():image = np.asarray(image) # from PIL image to numpy arrayimage = preprocess(image) # apply the preprocessingimage = np.array([image]) # the model expects 4D array#image = image.astype(np.float32)/255.0image = transformations(image)image = torch.Tensor(image).to(device)# 预测方向盘的角度steering_angle = model(image).view(-1).cpu().data.numpy()[0]global speed_limitif speed > speed_limit:speed_limit = MIN_SPEED # slow downelse:speed_limit = MAX_SPEED# throttle = controller.update(float(speed))throttle = 1.0 - steering_angle ** 2 - (speed / speed_limit) ** 2# steering_angle = steering_angle*180/3.1415926print('{} {} {}'.format(steering_angle, throttle, speed))send_control(steering_angle, throttle)except Exception as e:print(traceback.format_exc())else:sio.emit('manual', data={}, skip_sid=True)@sio.on('connect')def connect(sid, environ):print("connect ", sid)send_control(0, 0)def send_control(steering_angle, throttle):sio.emit("steer",data={'steering_angle': steering_angle.__str__(),'throttle': throttle.__str__()},skip_sid=True)"""pip install eventlet==0.29.1 --force-reinstallpip install python-socketio==4.5.1 --force-reinstallpip install python-engineio==3.11.2 --force-reinstall"""if __name__ == '__main__':model_path = "best-itheima.pt"model_path = "best-itheima222.pt"model_path = "models/best-itheima1697381912.pt"model = torch.load(model_path)model.eval()print(model)# 启动服务eventlet.wsgi.server(eventlet.listen(('', 4567)), app)

若有收获,就点个赞吧
0 人点赞
